分布式学习最佳实践:从分布式系统的特征开始
正文
在延伸feature(分布式系统需要考虑的特性)的时候,我逐渐明白,这是因为要满足这些feature,才设计了很多协议与算法,也提出了一些理论。比如说,这是因为要解决去中心化副本的一致性问题,才引入了Paxos(raft)协议。而每一个分布式系统,如分布式存储、分布式计算、分布式消息队列、分布式RPC框架,根据业务的不同,会使用不同的方法来满足这些feature,对这些feature的支持也可能会有权衡,比如一致性与可用性的权衡。
所有,我觉得从分布式的特性出发,来一步步学习分布式是一种可行的方式。
从分布式系统的特征出发
分布式的世界中涉及到大量的协议(raft、2pc、lease、quorum等)、大量的理论(FLP, CAP等)、大量的系统(GFS、MongoDB、MapReduce、Spark、RabbitMQ等)。这些大量的知识总是让我们无从下手,任何一个东西都需要花费大量的时间,特别是在没有项目、任务驱动的时候,没有一个明确的目标,真的很难坚持下去。
所以,我一直在思考,能有什么办法能把这些东西串起来?当我掌握了知识点A的时候,能够自然地想到接下来要学习B知识,A和B的关系,也许是递进的,也许是并列的。我也这样尝试了,那就是《什么是分布式系统,如何学习分布式系统》一文中我提到的,思考一个大型网站的架构,然后把这些协议、理论串起来。按照这个想法,我的计划就是去逐个学习这些组件。
但是,其实在这里有一个误区,我认为一个大型网站就是一个分布式系统,包含诸多组件,这些组件是分布式系统的组成部分;而我现在认为,一个大型网站包含诸多组件,每一个组件都是一个分布式系统,比如分布式存储就是一个分布式系统,消息队列就是一个分布式系统。
为什么说从思考分布式的特征出发,是一个可行的、系统的、循序渐进的学习方式呢,因为:
(1)先有问题,才会去思考解决问题的办法
由于我们要提高可用性,所以我们才需要冗余;由于需要扩展性,所以我们才需要分片
(2)解决一个问题,常常会引入新的问题
比如,为了提高可用性,引入了冗余;而冗余又带来了副本之间的一致性问题,所以引入了中心化副本协议(primary/secondary);那么接下来就要考虑primary(节点)故障时候的选举问题。。。
(3)这是一个金字塔结构,或者说,也是一个深度优先遍历的过程。
在这个过程中,我们始终知道自己已经掌握了哪些知识;还有哪些是已经知道,但未了解的知识;也能知道,哪些是空白,即我们知道这里可能有很多问题,但是具体是什么,还不知道。
那么,各个分布式系统如何与这些特征相关联呢?不难发现,每个分布式系统都会或多或少的体现出这些特征,只是使用的方法、算法可能不大一样。所以,我们应该思考,某一个问题,在某个特定系统中是如何解决的。比如元数据管理的强一致性,在MongoDB中是如何实现的,在HDFS中是如何实现的。这也指导了我们如何去学习一个具体的分布式系统:带着问题,只关注关心的部分,而不是从头到尾看一遍。
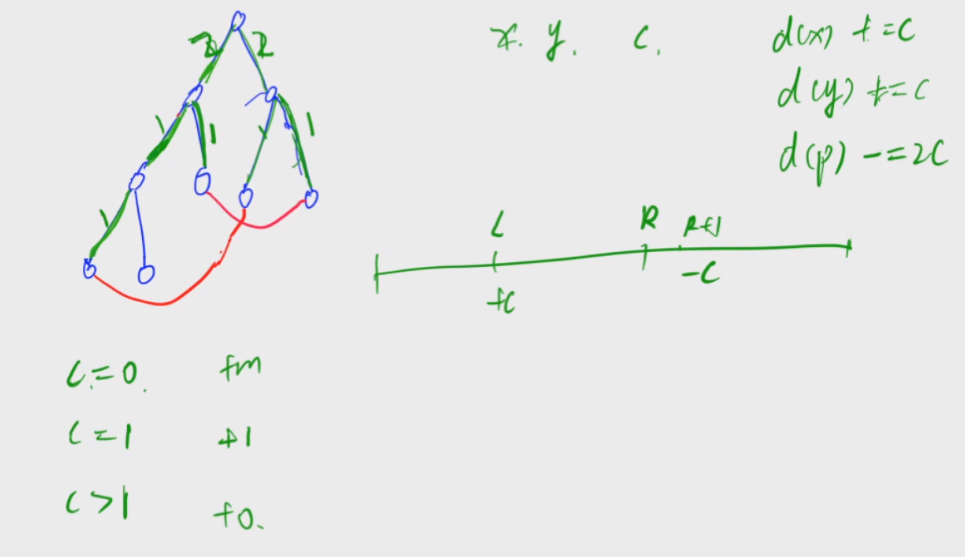
下面是,到目前为止,我对分布式特征的思维导图
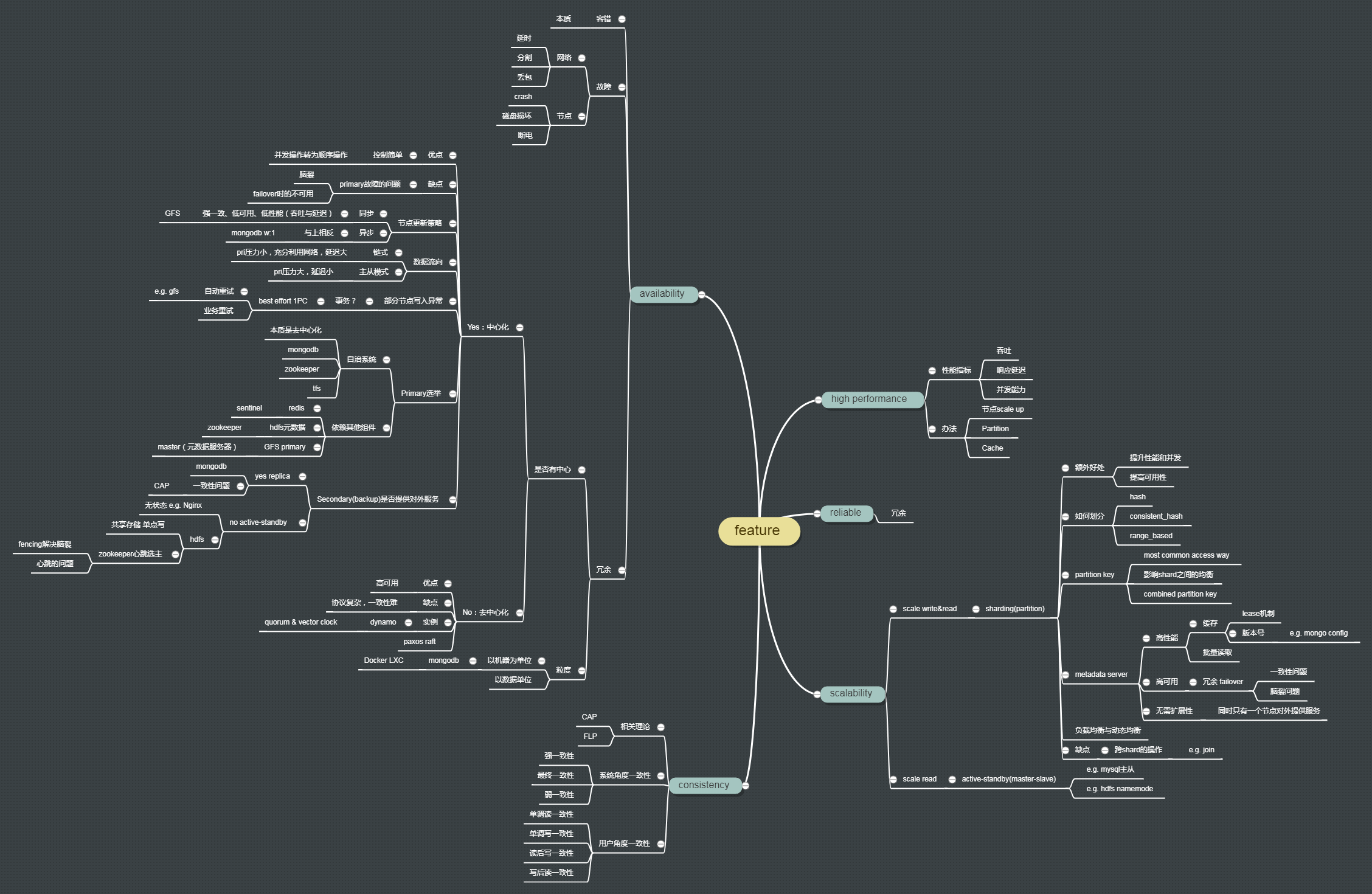
对于上图,需要声明的是,第一:不一定完全正确,第二:不完整。这是因为,我自己也在学习中,可以看到,很多分支很短(比如去中心化副本协议),不是因为这一块没有内容,而是我压根儿还没去了解,还没去学习。
我会持续跟新这幅脑图的!
下一章,介绍一下分布式系统的各个特征。
分布式系统的一般特征
任何介绍分布式系统的文章或者书籍都会提到分布式系统的几个特性:可扩展性、高性能、高可用、一致性。这几个特性也是分布式系统的衡量指标,正是为了在不同的程度上满足这些特性(或者说达到这些指标),才会设计出各种各样的算法、协议,然后根据业务的需求在这些特性间平衡。
那么本章节简单说明,为什么要满足这些特性,要满足这些特性需要解决什么问题,有什么好的解决方案。
可扩展性

Scalability is the capability of a system, network, or process to handle a growing amount of work, or its potential to be enlarged to accommodate that growth.
可扩展性是指当系统的任务(work)增加的时候,通过增加资源来应对任务增长的能力。可扩展性是任何分布式系统必备的特性,这是由分布式系统的概念决定的:
分布式系统是由一组通过网络进行通信、为了完成共同的任务而协调工作的计算机节点组成的系统
分布式系统的出现是为了解决单个计算机无法完成的计算、存储任务。那么当任务规模增加的时候,必然就需要添加更多的节点,这就是可扩展性。
扩展性的目标是使得系统中的节点都在一个较为稳定的负载下工作,这就是负载均衡,当然,在动态增加节点的时候,需要进行任务(可能是计算,可能是数据存储)的迁移,以达到动态均衡。
那么首先要考虑的问题就是,如何对任务进行拆分,将任务的子集分配到每一个节点,我们称这个过程问题Partition(Sharding)
第一:分片分式,即按照什么算法对任务进行拆分
常见的算法包括:哈希(hash),一致性哈希(consistency hash),基于数据范围(range based)。每一种算法有各自的优缺点,也就有各自的适用场景。
第二:分片的键,partition key
partition key是数据的特征值,上面提到的任何分片方式都依赖于这个partition key,那么该如何选择呢
based on what you think the primary access pattern will be
partition key会影响到任务在分片之间的均衡,而且一些系统中(mongodb)几乎是不能重新选择partition key的,因此在设计的时候就得想清楚
第三:分片的额外好处
提升性能和并发:不同的请求分发到不同的分片
提高可用性:一个分片挂了不影响其他的分片
第四:分片带来的问题
如果一个操作需要跨越多个分片,那么效率就会很低下,比如数据中的join操作
第五:元数据管理
元数据记录了分片与节点的映射关系、节点状态等核心信息,分布式系统中,有专门的节点(节点集群)来管理元数据,我们称之为元数据服务器。元数据服务器有以下特点:
高性能:cache
高可用:冗余 加 快速failover
强一致性(同时只有一个节点对外提供服务)
第六:任务的动态均衡
为了达到动态均衡,需要进行数据的迁移,如何保证在迁移的过程中保持对外提供服务,这也是一个需要精心设计的复杂问题。
可用性

可用性(Availability)是系统不间断对外提供服务的能力,可用性是一个度的问题,最高目标就是7 * 24,即永远在线。但事实上做不到的,一般是用几个9来衡量系统的可用性,如下如所示:
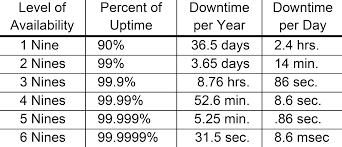
也就是如果要达到4个9的可用度(99.99%),那么一年之中只能有52.6分钟不可用,这是个巨大的挑战
为什么分布式系统中必须要考虑可用性呢,这是因为分布式系统中故障的概率很高。分布式系统由大量异构的节点和网络组成,节点可能会crash、断电、磁盘损坏,网络可能丢包、延迟、网络分割。系统的规模放大了出故障的概率,因此分布式系统中,故障是常态。那么分布式系统的其中一个设计目标就是容错,在部分故障的情况下仍然对外提供服务,这就是可用性。
冗余是提高可用性、可靠性的法宝。
冗余就是说多个节点负责相同的任务,在需要状态维护的场景,比如分布式存储中使用非常广泛。在分布式计算,如MapReduce中,当一个worker运行异常缓慢时,master会将这个worker上的任务重新调度到其它worker,以提高系统的吞吐,这也算一种冗余。但存储的冗余相比计算而言要复杂许多,因此主要考虑存储的冗余。
维护同一份数据的多个节点称之为多个副本。我们考虑一个问题,当向这个副本集写入数据的时候,怎么保证并发情况下数据的一致性,是否有一个节点有决定更新的顺序,这就是中心化、去中心话副本协议的区别。
中心化与去中心化
中心化就是有一个主节点(primary master)负责调度数据的更新,其优点是协议简单,将并发操作转变为顺序操作,缺点是primar可能成为瓶颈,且在primary故障的时候重新选举会有一段时间的不可用。
去中心化就是所有节点地位平等,都能够发起数据的更新,优点是高可用,缺点是协议复杂,要保证一致性很难。
提到去中心化,比较有名的是dynamo,cassandra,使用了quorum、vector clock等算法来尽量保证去中心化环境下的一致性。对于去中心化这一块,目前还没怎么学习,所以下面主要讨论中心化副本集。
节点更新策略
primary节点到secondary节点的数据时同步还是异步,即客户端是否需要等待数据落地到副本集中的所有节点。
同步的优点在于强一致性,但是可用性和性能(响应延迟)比较差;异步则相反。
数据流向
即数据是如何从Primary节点到secondary节点的,有链式和主从模式。
链式的优点时充分利用网络带宽,减轻primary压力,但缺点是写入延迟会大一些。GFS,MongoDB(默认情况下)都是链式。
部分节点写入异常
理论上,副本集中的多个节点的数据应该保持一致,因此多个数据的写入理论上应该是一个事务:要么都发生,要么都不发生。但是分布式事务(如2pc)是一个复杂的、低效的过程,因此副本集的更新一般都是best effort 1pc,如果失败,则重试,或者告诉应用自行处理。
primary的选举
在中心化副本协议中,primary节点是如何选举出来的,当primary节点挂掉之后,又是如何选择出新的primary节点呢,有两种方式:自治系统,依赖其他组件的系统。(ps,这两个名字是我杜撰的 。。。)
所谓的自治系统,就是节点内部自行投票选择,比如mongodb,tfs,zookeeper
依赖其他组件的系统,是指primary由副本集之后的组件来任命,比如GFS中的primary由master(GFS的元数据服务器)任命,hdfs的元数据namenode由zookeeper心跳选出。
secondary是否对外提供服务(读服务)
中心化复制集中,secondary是否对外提供读服务,取决于系统对一致性的要求。
比如前面介绍到节点更新策略时,可能是异步的,那么secondary上的数据相比primary会有一定延迟,从secondary上读数据的话无法满足强一致性要求。
比如元数据,需要强一致性保证,所以一般都只会从primary读数据。而且,一般称主节点为active(master),从节点为standby(slave)。在这种情况下,是通过冗余 加上 快速的failover来保证可用性。
一致性
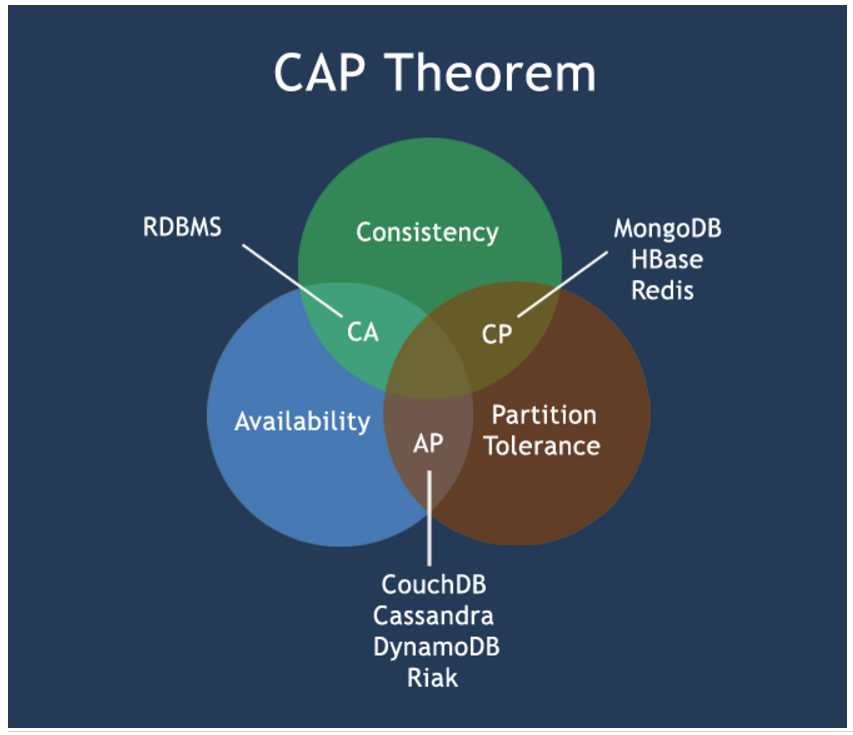
从上面可以看到,为了高可用性,引入了冗余(副本)机制,而副本机制就带来了一致性问题。当然,如果没有冗余机制,或者不是数据(状态)的冗余,那么不会出现一致性问题,比如MapReduce。
一致性与可用性在分布式系统中的关系,已经有足够的研究,形成了CAP理论。CAP理论就是说分布式数据存储,最多只能同时满足一致性(C,Consistency)、可用性(A, Availability)、分区容错性(P,Partition Tolerance)中的两者。但一致性和可用性都是一个度的问题,是0到1,而不是只有0和1两个极端。详细可以参考之前的文章《CAP理论与MongoDB一致性,可用性的一些思考》
一致性从系统的角度和用户的角度有不同的等级。
系统角度的一致性
强一致性、若一致性、最终一致性
用户角度的一致性
单调读一致性,单调写一致性,读后写一致性,写后读一致性
高性能

正式因为单个节点的scale up不能完成任务,因此我们才需要scale out,用大量的节点来完成任务,分布式系统的理想目标是任务与节点按一定的比例线性增长。
衡量指标
高并发
高吞吐
低延迟
不同的系统关注的核心指标不一样,比如MapReduce,本身就是离线计算,无需低延迟
可行的办法
单个节点的scaleup
分片(partition)
缓存:比如元数据
短事务
相关文章:
分布式学习最佳实践:从分布式系统的特征开始
正文 在延伸feature(分布式系统需要考虑的特性)的时候,我逐渐明白,这是因为要满足这些feature,才设计了很多协议与算法,也提出了一些理论。比如说,这是因为要解决去中心化副本的一致性问题&…...
第三章 图论 No.8最近公共祖先lca, tarjan与次小生成树
文章目录 lcaTarjan板子题:1172. 祖孙询问lca或tarjan:1171. 距离356. 次小生成树352. 闇の連鎖 lca O ( m l o g n ) O(mlogn) O(mlogn),n为节点数量,m为询问次数,lca是一种在线处理询问的算法 自己也是自己的祖先 倍…...
[Kubernetes]Kubeflow Pipelines - 基本介绍与安装方法
1. 背景 近些年来,人工智能技术在自然语言处理、视觉图像和自动驾驶方面都取得不小的成就,无论是工业界还是学术界大家都在惊叹一个又一个的模型设计。但是对于真正做过算法工程落地的同学,在惊叹这些模型的同时,更多的是在忧虑如…...
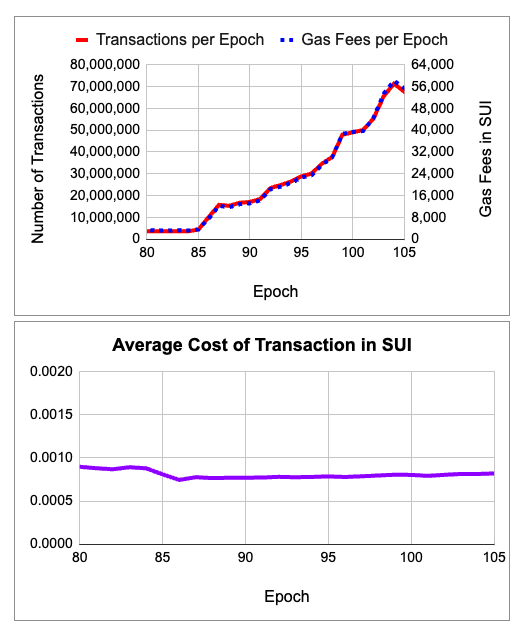
Sui网络的稳定性和高性能
Sui的最初的协议开发者设计了可扩展的网络,通过水平扩展的方式来保持可负担得起的gas费用。其他区块链与之相比,则使用稀缺性和交易成本来控制网络活动。 Sui主网上线前90天的数据指标证明了这一设计概念,在保持100%正常运行的同…...
RabbitMQ 安装教程
RabbitMQ 安装教程 特殊说明 因为RabbitMQ基于Erlang开发,所以安装时需要先安装Erlang RabbitMQ和Erlang版本对应关系 查看地址:www.rabbitmq.com/which-erlan… 环境选择 Erlang: 23.3及以上 RabbitMQ: 3.10.1Windows 安装 1. 安装Erlang 下载地…...

STM32F429IGT6使用CubeMX配置GPIO点亮LED灯
1、硬件电路 2、设置RCC,选择高速外部时钟HSE,时钟设置为180MHz 3、配置GPIO引脚 4、生成工程配置 5、部分代码 6、实验现象...

DOM的节点操作+事件高级+DOM事件流+事件对象
一.节点操作 1.父节点: node.parentNode 得到的是离元素最近的父级节点 2.子节点: parentNode.childNodes 所有的子节点 包含元素节点 文本节点等等parentNode.children (非标准) 获取所有的子元素节点,实际开发常用 parentNode.firstChild 获取…...
云端剪切板,让你的数据同步无界
云端剪切板,让你的数据同步无界! 每个人都应该保护自己的数据,同时使它易于访问和共享。这就是我们的云剪切板网站诞生的原因!无论你在哪里,只要登录我们的网站,就可以随时随地使用你的剪切板数据。 你可…...

Location匹配与Rewrite重写
一、常见的Nginx正则表达式 ^ :匹配输入字符串的起始位置 $ :匹配输入字符串的结束位置 * :匹配前面的字符零次或多次。如“ol*”能匹配“o”及“ol”、“oll”:匹配前面的字符一次或多次。如“ol”能匹配“ol”及“oll”、“oll…...
Docker源码阅读 - goland环境准备
docker 源码分为两部分 cli 和 moby(docker) tips: docker是从moby拷贝过去的;docker整体是一个C-S架构,cli客户端,docker服务端 docker-ce:https://github.com/docker/docker-ce cli:https://…...

数据库信息速递 -- MariaDB 裁员后,前景不确定 (翻译)
开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请加 liuaustin3微信号 ,在新加的朋友会分到3群ÿ…...

4.1 Windows终端安全
数据参考:CISP官方 目录 安全安装保护账户安全本地安全策略安全中心系统服务安全其他安全设置软件安全获取 一、安全安装(以安装windows系统为例) 选择合适的版本 商业版本:家庭版、专业版、专业工作站版、企业版特殊版本&…...
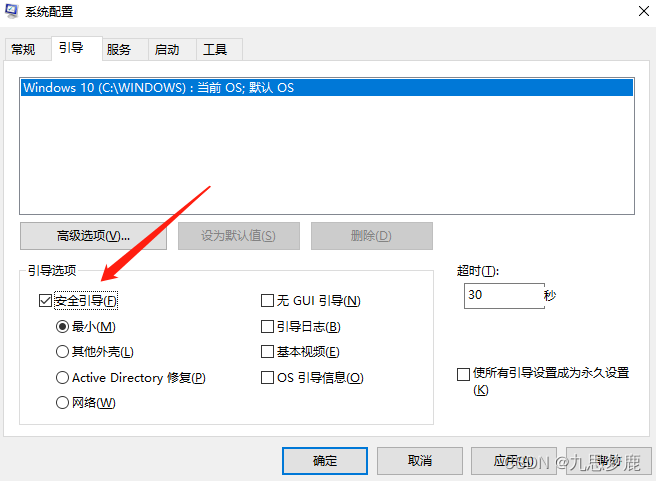
win10强制卸载奇安信天擎
1、win r 打开运行 2、输入msconfig进入系统配置面板 3、点击引导,修改安全引导配置项 4、重启系统(桌面会变成纯黑背景,符合预期,莫紧张) 5、删除安装的文件夹 若是安装天擎时选择的自定义安装,则配置…...

npm常用命令
npm -v:查看 npm 版本 npm init:初始化后会出现一个 Package.json 配置文件,可以在后面加上 -y,快速跳到问答界面 npm install:会根据项目中的 package.json 文件自动给下载项目中所需的全部依赖 npm insall 包含 -…...
创建型设计模式:4、原型模式(Prototype Pattern))
(一)创建型设计模式:4、原型模式(Prototype Pattern)
目录 1、原型模式的含义 2、C实现原型模式的简单实例 1、原型模式的含义 通过复制现有对象来创建新对象,而无需依赖于显式的构造函数或工厂方法,同时又能保证性能。 The prototype pattern is a creational design pattern in software development. …...
【算法学习】高级班九
这种互为旋变串: 给定两个字符串,判断是否互为旋变串 代码: 打表法: 每一层内的数字不互相依赖,只依赖它下面的层但实际上size会约束L1和L2的值,即L1和L2<N-size 思路:设置一个窗口…...
数据安全加固:深入解析滴滴ES安全认证技术方案
前文分别介绍了滴滴自研的ES强一致性多活是如何实现的、以及如何提升ES的性能潜力。由于ES具有强大的搜索和分析功能,同时也因其开源和易于使用而成为黑客攻击的目标。近些年,业界ES数据泄露事件频发, 以下是一些比较严重的数据泄露案件: 202…...

Typescript第九/十章 前后端框架,命名空间和模块
第九章 前后端框架 9.1 前端框架 Typescript特别适合用于开发前端应用。Typescript对JSX有很好的支持,而且能安全地建模不可变性,从而提升应用的结构和安全性,写出的代码正确性高,便于维护。 9.1.1 React JSX/TSX内容等 详情…...

LLM - argparse 解析脚本参数
目录 一.引言 二.argparse 解析 shell 参数 1.使用步骤 2.python 侧示例 3.shell 侧示例 一.引言 CUDA_VISIBLE_DEVICES0 python src/train_bash.py \--stage pt \--model_name_or_path path_to_your_model \--do_train \--dataset wiki_demo \--template default \--fin…...

谈一谈在两个商业项目中使用MVI架构后的感悟
作者:leobertlan 前言 当时项目采用MVP分层设计,组员的代码风格差异也较大,代码中类职责赋予与封装风格各成一套,随着业务急速膨胀,代码越发混乱。试图用 MVI架构 单向流 形成 掣肘 带来一致风格。 但这种做法不够以…...

2026年论文摘要和引言AI率偏高攻略:开篇内容降AI完整处理方案
2026年论文摘要和引言AI率偏高攻略:开篇内容降AI完整处理方案 从AI率73%到6%,我花了不到一个晚上。论文摘要降AI完整经历记录。 核心工具:嘎嘎降AI(www.aigcleaner.com),4.8元,达标率99.26%。…...

MPC-HC免费开源媒体播放器:Windows平台终极配置指南
MPC-HC免费开源媒体播放器:Windows平台终极配置指南 【免费下载链接】mpc-hc MPC-HCs main repository. For support use our Trac: https://trac.mpc-hc.org/ 项目地址: https://gitcode.com/gh_mirrors/mpc/mpc-hc 在众多媒体播放器中,MPC-HC&a…...

常见排序算法性能对比
排序算法是计算机科学中将一个数据集合按照特定顺序(如升序或降序)重新排列的算法。根据是否通过比较元素来决定次序,主要分为比较排序和非比较排序两大类 。 常见排序算法对比 下表对几种主流排序算法的核心特性进行了对比 : …...
)
电池销售系统|基于java + vue电池销售系统(源码+数据库+文档)
电池销售系统 目录 基于springboot vue电池销售系统 一、前言 二、系统功能演示 三、技术选型 四、其他项目参考 五、代码参考 六、测试参考 七、最新计算机毕设选题推荐 八、源码获取: 基于springboot vue电池销售系统 一、前言 博主介绍:✌…...

简单三步:用MyTV-Android让老旧电视焕发新生的终极解决方案
简单三步:用MyTV-Android让老旧电视焕发新生的终极解决方案 【免费下载链接】mytv-android 使用Android原生开发的视频播放软件 项目地址: https://gitcode.com/gh_mirrors/my/mytv-android 还在为家中老旧Android电视无法安装现代直播应用而烦恼吗ÿ…...

LightGBM核心原理与工业级应用实战指南
1. 初识LightGBM:当GBDT遇见效率革命第一次接触LightGBM是在处理一个包含数百万条记录的电商用户行为数据集时。当时我正苦于XGBoost的训练速度无法满足迭代需求,直到发现了这个微软开源的梯度提升框架。与传统GBDT(Gradient Boosting Decisi…...

R语言实现惩罚回归:从原理到实践
1. 惩罚回归概述:从线性回归到正则化在机器学习实践中,线性回归是最基础也最常用的算法之一。但传统最小二乘法在面对高维数据或存在多重共线性的数据时,往往会遇到过拟合问题。这时惩罚回归(Penalized Regression)就成…...

Whiz:基于大语言模型的终端自然语言命令生成工具
1. 项目概述:为你的终端装上“副驾驶” 如果你和我一样,每天有超过一半的工作时间是在终端(Terminal)里度过的,那你一定也经历过这样的时刻:面对一个复杂的命令组合,需要反复查阅手册ÿ…...

如何完整备份你的QQ空间历史说说:GetQzonehistory终极指南
如何完整备份你的QQ空间历史说说:GetQzonehistory终极指南 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否担心QQ空间里那些记录青春岁月的说说、照片和评论会随着时间…...

Mem Reduct:深入解析Windows内存管理优化实践
Mem Reduct:深入解析Windows内存管理优化实践 【免费下载链接】memreduct Lightweight real-time memory management application to monitor and clean system memory on your computer. 项目地址: https://gitcode.com/gh_mirrors/me/memreduct 在Windows系…...