压缩20M文件从30秒到1秒的优化过程
压缩20M文件从30秒到1秒的优化过程
有一个需求需要将前端传过来的10张照片,然后后端进行处理以后压缩成一个压缩包通过网络流传输出去。之前没有接触过用Java压缩文件的,所以就直接上网找了一个例子改了一下用了,改完以后也能使用,但是随着前端所传图片的大小越来越大的时候,耗费的时间也在急剧增加,最后测了一下压缩20M的文件竟然需要30秒的时间。压缩文件的代码如下。
public static void zipFileNoBuffer() {File zipFile = new File(ZIP_FILE);try (ZipOutputStream zipOut = new ZipOutputStream(new FileOutputStream(zipFile))) {//开始时间long beginTime = System.currentTimeMillis();for (int i = 0; i < 10; i++) {try (InputStream input = new FileInputStream(JPG_FILE)) {zipOut.putNextEntry(new ZipEntry(FILE_NAME + i));int temp = 0;while ((temp = input.read()) != -1) {zipOut.write(temp);}}}printInfo(beginTime);} catch (Exception e) {e.printStackTrace();}
}
这里找了一张2M大小的图片,并且循环十次进行测试。打印的结果如下,时间大概是30秒。
fileSize:20M
consum time:29599
第一次优化过程-从30秒到2秒
进行优化首先想到的是利用缓冲区BufferInputStream。在FileInputStream中read()方法每次只读取一个字节。源码中也有说明。
/*** Reads a byte of data from this input stream. This method blocks* if no input is yet available.** @return the next byte of data, or <code>-1</code> if the end of the* file is reached.* @exception IOException if an I/O error occurs.*/
public native int read() throws IOException;
这是一个调用本地方法与原生操作系统进行交互,从磁盘中读取数据。每读取一个字节的数据就调用一次本地方法与操作系统交互,是非常耗时的。例如我们现在有30000个字节的数据,如果使用FileInputStream那么就需要调用30000次的本地方法来获取这些数据,而如果使用缓冲区的话(这里假设初始的缓冲区大小足够放下30000字节的数据)那么只需要调用一次就行。因为缓冲区在第一次调用read()方法的时候会直接从磁盘中将数据直接读取到内存中。随后再一个字节一个字节的慢慢返回。
> BufferedInputStream内部封装了一个byte数组用于存放数据,默认大小是8192
优化过后的代码如下
public static void zipFileBuffer() {File zipFile = new File(ZIP_FILE);try (ZipOutputStream zipOut = new ZipOutputStream(new FileOutputStream(zipFile));BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(zipOut)) {//开始时间long beginTime = System.currentTimeMillis();for (int i = 0; i < 10; i++) {try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream(JPG_FILE))) {zipOut.putNextEntry(new ZipEntry(FILE_NAME + i));int temp = 0;while ((temp = bufferedInputStream.read()) != -1) {bufferedOutputStream.write(temp);}}}printInfo(beginTime);} catch (Exception e) {e.printStackTrace();}
}
输出
------Buffer
fileSize:20M
consum time:1808
可以看到相比较于第一次使用FileInputStream效率已经提升了许多了
第二次优化过程-从2秒到1秒
使用缓冲区buffer的话已经是满足了我的需求了,但是秉着学以致用的想法,就想着用NIO中知识进行优化一下。
使用Channel
为什么要用Channel呢?因为在NIO中新出了Channel和ByteBuffer。正是因为它们的结构更加符合操作系统执行I/O的方式,所以其速度相比较于传统IO而言速度有了显著的提高。Channel就像一个包含着煤矿的矿藏,而ByteBuffer则是派送到矿藏的卡车。也就是说我们与数据的交互都是与ByteBuffer的交互。
在NIO中能够产生FileChannel的有三个类。分别是FileInputStream、FileOutputStream、以及既能读又能写的RandomAccessFile。
源码如下
public static void zipFileChannel() {//开始时间long beginTime = System.currentTimeMillis();File zipFile = new File(ZIP_FILE);try (ZipOutputStream zipOut = new ZipOutputStream(new FileOutputStream(zipFile));WritableByteChannel writableByteChannel = Channels.newChannel(zipOut)) {for (int i = 0; i < 10; i++) {try (FileChannel fileChannel = new FileInputStream(JPG_FILE).getChannel()) {zipOut.putNextEntry(new ZipEntry(i + SUFFIX_FILE));fileChannel.transferTo(0, FILE_SIZE, writableByteChannel);}}printInfo(beginTime);} catch (Exception e) {e.printStackTrace();}
}
我们可以看到这里并没有使用ByteBuffer进行数据传输,而是使用了transferTo的方法。这个方法是将两个通道进行直连。
This method is potentially much more efficient than a simple loop
* that reads from this channel and writes to the target channel. Many
* operating systems can transfer bytes directly from the filesystem cache
* to the target channel without actually copying them.
这是源码上的描述文字,大概意思就是使用transferTo的效率比循环一个Channel读取出来然后再循环写入另一个Channel好。操作系统能够直接传输字节从文件系统缓存到目标的Channel中,而不需要实际的copy阶段。
> copy阶段就是从内核空间转到用户空间的一个过程
可以看到速度相比较使用缓冲区已经有了一些的提高。
------Channel
fileSize:20M
consum time:1416
内核空间和用户空间
那么为什么从内核空间转向用户空间这段过程会慢呢?首先我们需了解的是什么是内核空间和用户空间。在常用的操作系统中为了保护系统中的核心资源,于是将系统设计为四个区域,越往里权限越大,所以Ring0被称之为内核空间,用来访问一些关键性的资源。Ring3被称之为用户空间。
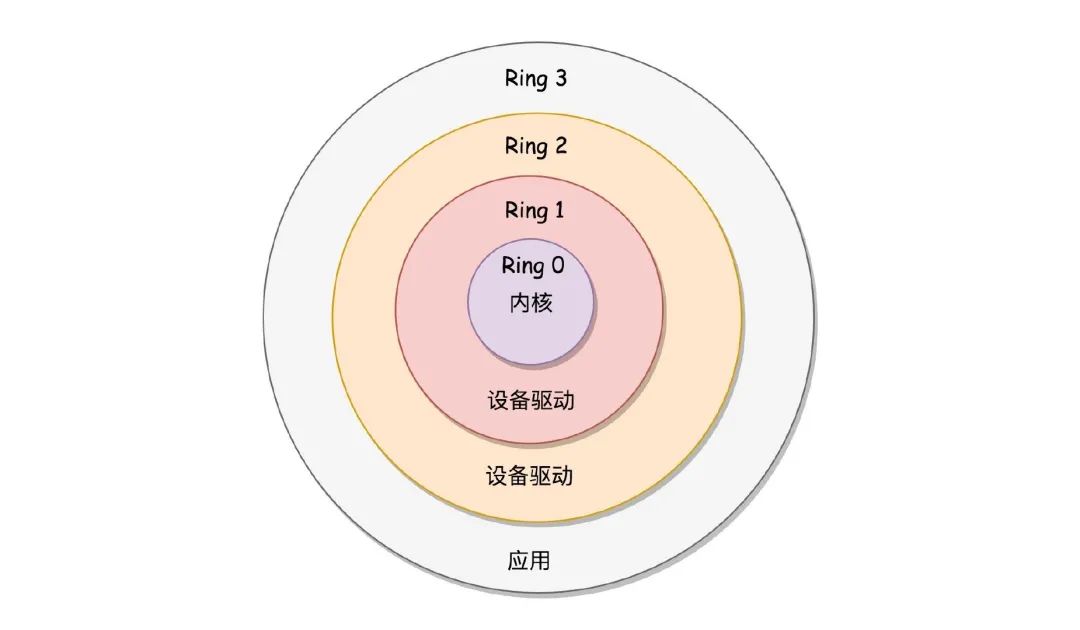
> 用户态、内核态:线程处于内核空间称之为内核态,线程处于用户空间属于用户态
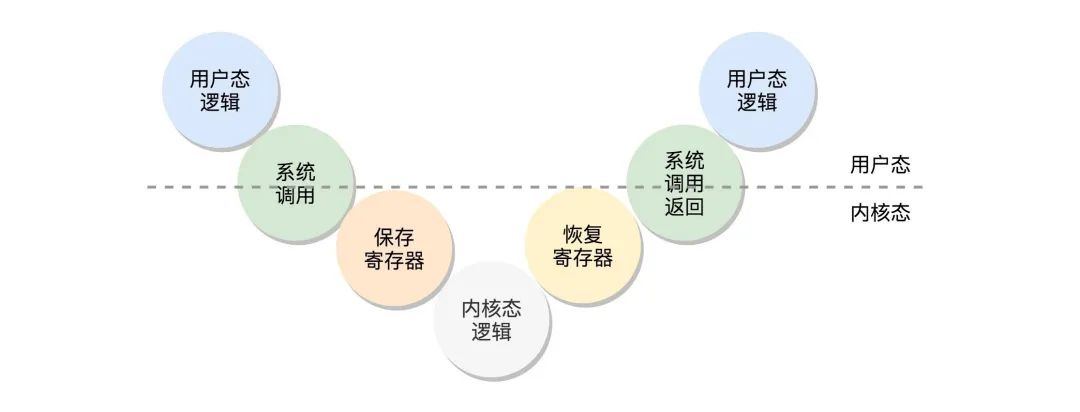
那么我们如果此时应用程序(应用程序是都属于用户态的)需要访问核心资源怎么办呢?那就需要调用内核中所暴露出的接口用以调用,称之为系统调用。例如此时我们应用程序需要访问磁盘上的文件。此时应用程序就会调用系统调用的接口open方法,然后内核去访问磁盘中的文件,将文件内容返回给应用程序。大致的流程如下
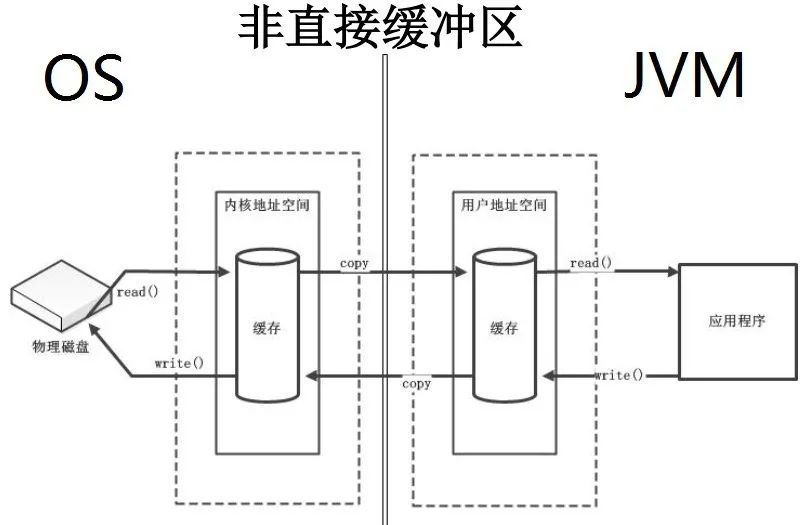
直接缓冲区和非直接缓冲区
既然我们要读取一个磁盘的文件,要废这么大的周折。有没有什么简单的方法能够使我们的应用直接操作磁盘文件,不需要内核进行中转呢?有,那就是建立直接缓冲区了。
-
非直接缓冲区:非直接缓冲区就是我们上面所讲内核态作为中间人,每次都需要内核在中间作为中转。
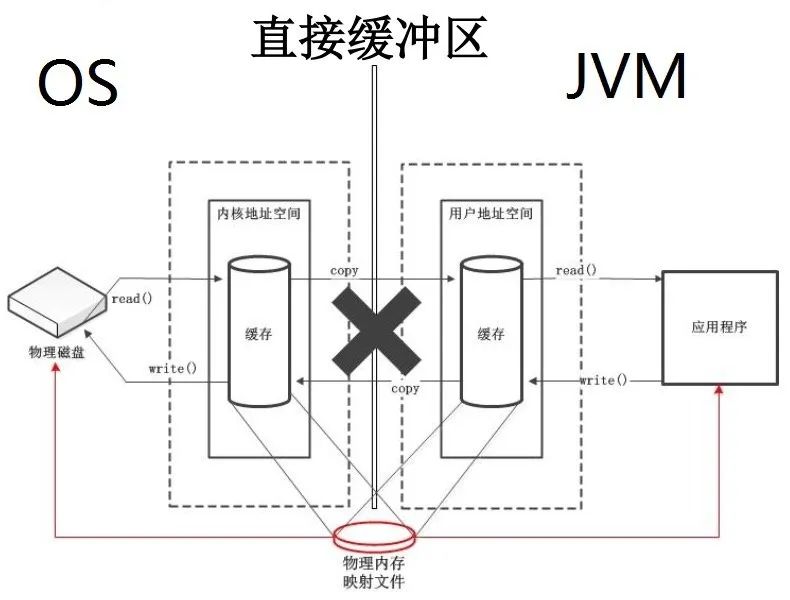
-
直接缓冲区:直接缓冲区不需要内核空间作为中转copy数据,而是直接在物理内存申请一块空间,这块空间映射到内核地址空间和用户地址空间,应用程序与磁盘之间数据的存取通过这块直接申请的物理内存进行交互。
既然直接缓冲区那么快,我们为什么不都用直接缓冲区呢?其实直接缓冲区有以下的缺点。直接缓冲区的缺点:
-
不安全
-
消耗更多,因为它不是在JVM中直接开辟空间。这部分内存的回收只能依赖于垃圾回收机制,垃圾什么时候回收不受我们控制。
-
数据写入物理内存缓冲区中,程序就丧失了对这些数据的管理,即什么时候这些数据被最终写入从磁盘只能由操作系统来决定,应用程序无法再干涉。
> 综上所述,所以我们使用transferTo方法就是直接开辟了一段直接缓冲区。所以性能相比而言提高了许多
使用内存映射文件
NIO中新出的另一个特性就是内存映射文件,内存映射文件为什么速度快呢?其实原因和上面所讲的一样,也是在内存中开辟了一段直接缓冲区。与数据直接作交互。源码如下
//Version 4 使用Map映射文件
public static void zipFileMap() {//开始时间long beginTime = System.currentTimeMillis();File zipFile = new File(ZIP_FILE);try (ZipOutputStream zipOut = new ZipOutputStream(new FileOutputStream(zipFile));WritableByteChannel writableByteChannel = Channels.newChannel(zipOut)) {for (int i = 0; i < 10; i++) {zipOut.putNextEntry(new ZipEntry(i + SUFFIX_FILE));//内存中的映射文件MappedByteBuffer mappedByteBuffer = new RandomAccessFile(JPG_FILE_PATH, "r").getChannel().map(FileChannel.MapMode.READ_ONLY, 0, FILE_SIZE);writableByteChannel.write(mappedByteBuffer);}printInfo(beginTime);} catch (Exception e) {e.printStackTrace();}
}
打印如下
---------Map
fileSize:20M
consum time:1305
可以看到速度和使用Channel的速度差不多的。
使用Pipe
Java NIO 管道是2个线程之间的单向数据连接。Pipe有一个source通道和一个sink通道。其中source通道用于读取数据,sink通道用于写入数据。可以看到源码中的介绍,大概意思就是写入线程会阻塞至有读线程从通道中读取数据。如果没有数据可读,读线程也会阻塞至写线程写入数据。直至通道关闭。
Whether or not a thread writing bytes to a pipe will block until anotherthread reads those bytes
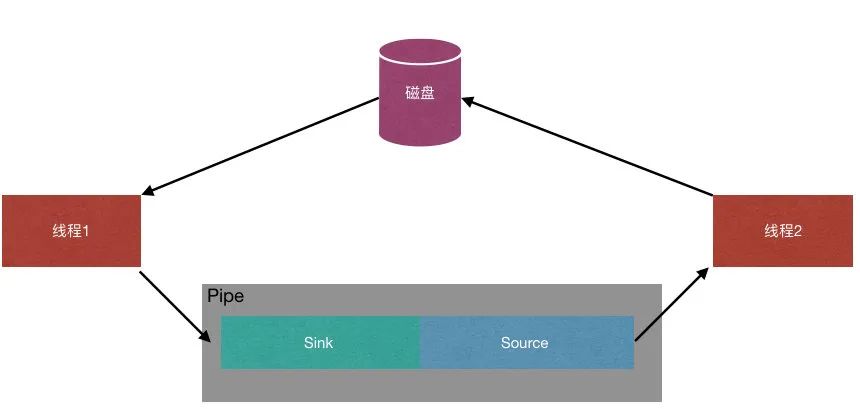
我想要的效果是这样的。源码如下
//Version 5 使用Pip
public static void zipFilePip() {long beginTime = System.currentTimeMillis();try(WritableByteChannel out = Channels.newChannel(new FileOutputStream(ZIP_FILE))) {Pipe pipe = Pipe.open();//异步任务CompletableFuture.runAsync(()->runTask(pipe));//获取读通道ReadableByteChannel readableByteChannel = pipe.source();ByteBuffer buffer = ByteBuffer.allocate(((int) FILE_SIZE)*10);while (readableByteChannel.read(buffer)>= 0) {buffer.flip();out.write(buffer);buffer.clear();}}catch (Exception e){e.printStackTrace();}printInfo(beginTime);}//异步任务
public static void runTask(Pipe pipe) {try(ZipOutputStream zos = new ZipOutputStream(Channels.newOutputStream(pipe.sink()));WritableByteChannel out = Channels.newChannel(zos)) {System.out.println("Begin");for (int i = 0; i < 10; i++) {zos.putNextEntry(new ZipEntry(i+SUFFIX_FILE));FileChannel jpgChannel = new FileInputStream(new File(JPG_FILE_PATH)).getChannel();jpgChannel.transferTo(0, FILE_SIZE, out);jpgChannel.close();}}catch (Exception e){e.printStackTrace();}
}
总结
-
生活处处都需要学习,有时候只是一个简单的优化,可以让你深入学习到各种不同的知识。所以在学习中要不求甚解,不仅要知道这个知识也要了解为什么要这么做。
-
知行合一:学习完一个知识要尽量应用一遍。这样才能记得牢靠。
源码地址: https://www.oschina.net/action/GoToLink?url=https%3A%2F%2Fgithub.com%2Fmodouxiansheng%2FDoraemon
相关文章:
压缩20M文件从30秒到1秒的优化过程
压缩20M文件从30秒到1秒的优化过程 有一个需求需要将前端传过来的10张照片,然后后端进行处理以后压缩成一个压缩包通过网络流传输出去。之前没有接触过用Java压缩文件的,所以就直接上网找了一个例子改了一下用了,改完以后也能使用࿰…...

如何选择合适的固态继电器?
如何选择合适的固态继电器? 在选择固态继电器(SSR)时,应根据实际应用条件和SSR性能参数,特别要考虑到使用中的过流和过压条件以及SSR的负载能力,这有助于实现固态继电器的长寿命和高可靠性。然后࿰…...

SAP 忘记SAP系统Client 000的所有账号密码
忘记SAP系统Client 000的所有账号密码。 Solution 在SAP系统DB中删除账号SAP*,SAP系统会自动创建SAP*这个账号,然后初始密码是“PASS”,这样就获得Client 000 SAP*账号。 Step by Step 以Oracle数据库为例: 1.以<SID>ADM账…...

Connext DDS可扩展类型Extensible Types指南
RTI Connext DDS 可扩展类型Extensible Types指南 可扩展类型Extensible TypesConnextDDSv6.1.1版本,包含了对OMG“DDS的可扩展和动态主题类型Extensible andDynamic Topic Types for DDS”规范1.3版的部分支持,该规范来自对象管理组OMG。这种支持,允许系统以更灵活的方式定义…...

Docker简单使用
文章目录1、安装配置2、服务启动3、Docker镜像下载4、Docker启动容器5、容器的常用命令6、Docker进入容器内部7、宿主机与容器交换文件8、查看日志官网地址:1、安装配置 sudo yum install -y yum-utils 设置镜像地址 sudo yum-config-manager \--add-repo \https:…...
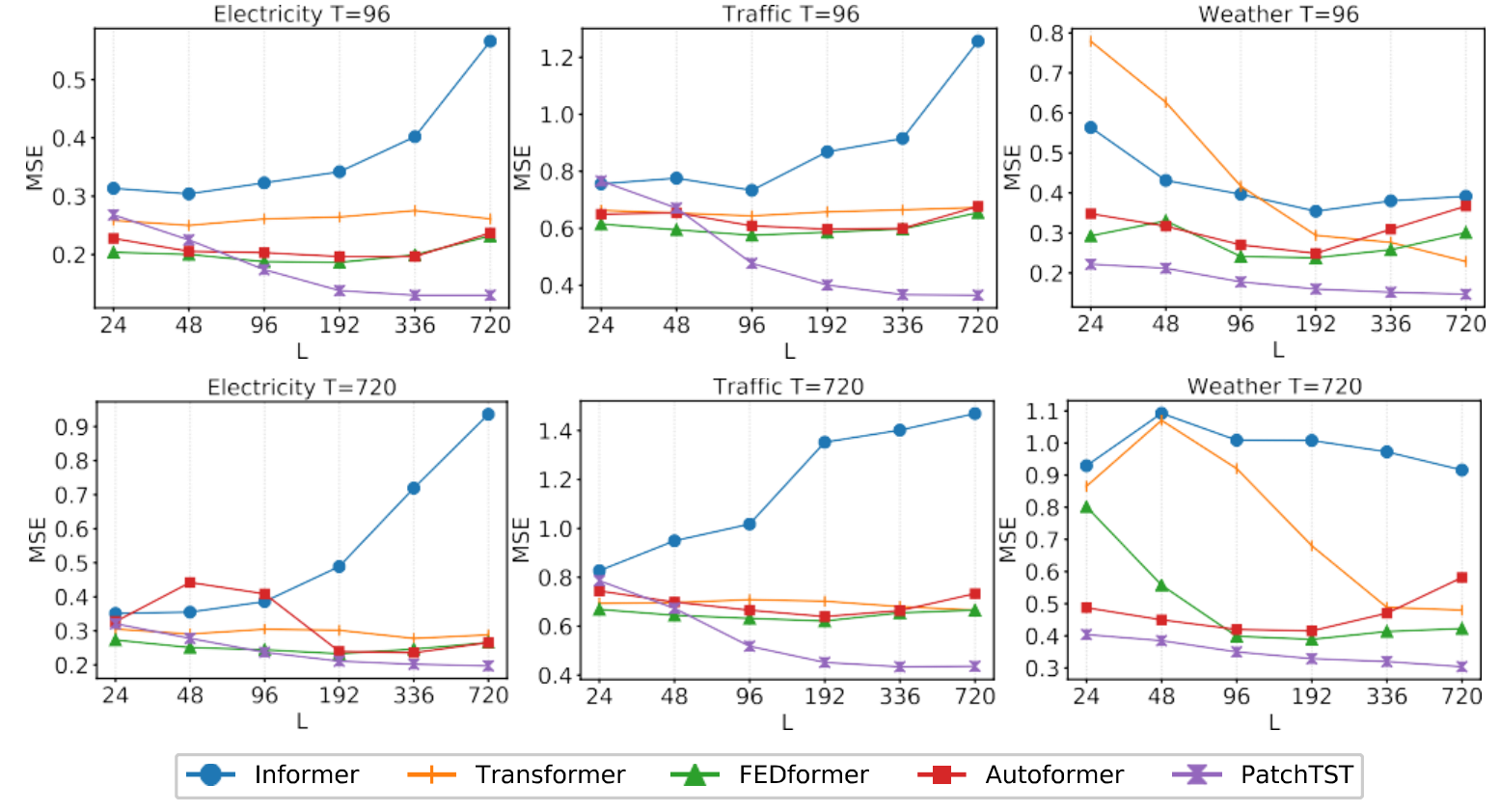
A Time Series is Worth 64 Words(PatchTST模型)论文解读
摘要 我们提出了一种高效的基于Transformer设计的模型,用于多变量时间序列预测和自我监督表征学习(self-supervised learning)。它基于两个关键部分:1、将时间序列分隔成子序列级别的patches,作为Transformer的输入&a…...
微服务学习:SpringCloud+RabbitMQ+Docker+Redis+搜索+分布式
目录 一、高级篇 二、面试篇 实用篇 day05-Elasticsearch01 安装elasticsearch 1.部署单点es 2.部署kibana 一、高级篇 二、面试篇 实用篇 day05-Elasticsearch01 安装elasticsearch 1.部署单点es 1.1.创建网络 因为我们还需要部署kibana容器,因此需要…...

nginx平滑升级
1.平滑升级操作1.1 备份安装目录下的nginxcd /usr/local/nginx/sbin mv nginx nginx.bak1.2 复制objs目录下的nginx到当前sbin目录下cp /opt/software/nginx/nginx-1.20.2/objs/nginx /usr/local/nginx/sbin/1.3 发送信号user2给nginx老版本对应的进程kill -user2 more /usr/lo…...
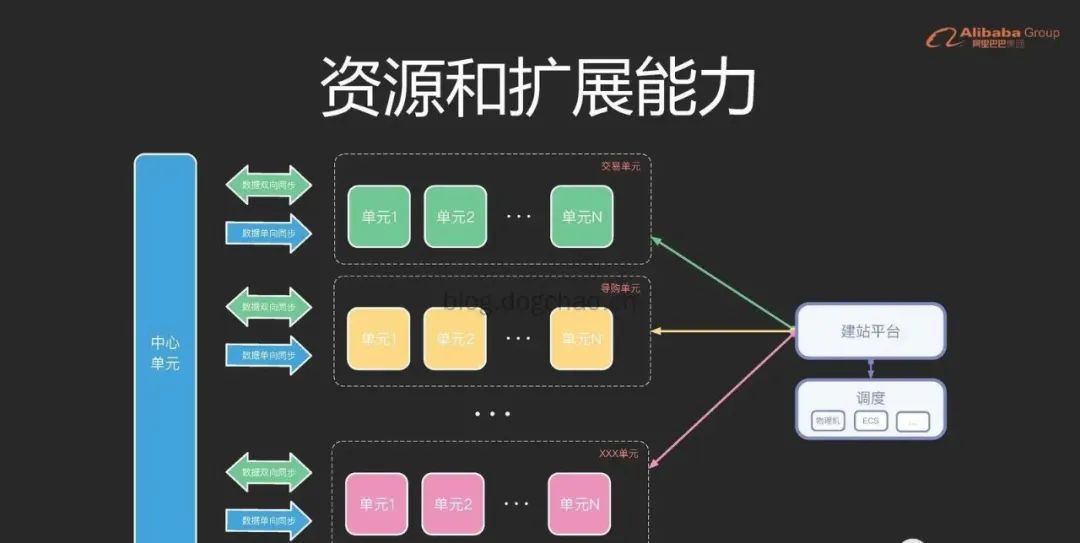
高可用的“异地多活”架构设计
前言 后台服务可以划分为两类,有状态和无状态。高可用对于无状态的应用来说是比较简单的,无状态的应用,只需要通过 F5 或者任何代理的方式就可以很好的解决。后文描述的主要是针对有状态的服务进行分析。 服务端进行状态维护主要是通过磁盘…...
【面试题】Map和Set
1. Map和Object的区别 形式不同 // Object var obj {key1: hello,key2: 100,key3: {x: 100} } // Map var m new Map([[key1, hello],[key2, 100],[key3, {x: 100}] ])API不同 // Map的API m.set(name, 小明) // 新增 m.delete(key2) // 删除 m.has(key3) // …...

Spring之事务底层源码解析
Spring之事务底层源码解析 1、EnableTransactionManagement工作原理 开启 Spring 事务本质上就是增加了一个 Advisor,当我们使用 EnableTransactionManagement 注解来开启 Spring 事务时,该注解代理的功能就是向 Spring 容器中添加了两个 Bean…...

【华为OD机试真题 Python】创建二叉树
前言:本专栏将持续更新华为OD机试题目,并进行详细的分析与解答,包含完整的代码实现,希望可以帮助到正在努力的你。关于OD机试流程、面经、面试指导等,如有任何疑问,欢迎联系我,wechat:steven_moda;email:nansun0903@163.com;备注:CSDN。 题目描述 请按下列描达构建…...
RuoYi-Vue-Plus搭建(若依)
项目简介 1.RuoYi-Vue-Plus 是重写 RuoYi-Vue 针对 分布式集群 场景全方位升级(不兼容原框架)2.环境安装参考:https://blog.csdn.net/tongxin_tongmeng/article/details/128167926 JDK 11、MySQL 8、Redis 6.X、Maven 3.8.X、Nodejs > 12、Npm 8.X3.IDEA环境配置…...

uboot和linux内核移植流程简述
一、移植uboot流程 1、从半导体芯片厂下载对应的demo,然后编译测试demo版的uboot 开发板基本都是参考半导体厂商的 dmeo 板,而半导体厂商会在他们自己的开发板上移植好 uboot、linux kernel 和 rootfs 等,最终制作好 BSP包提供给用户。我们可…...

【CS224W】(task2)传统图机器学习和特征工程
note 和CS224W课程对应,将图的基本表示写在task1笔记中了;传统图特征工程:将节点、边、图转为d维emb,将emb送入ML模型训练Traditional ML Pipeline Hand-crafted feature ML model Hand-crafted features for graph data Node-l…...
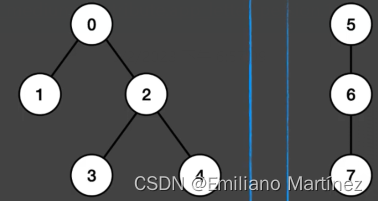
【算法基础】并查集⭐⭐⭐⭐⭐【思路巧,代码短,面试常考】
并查集,在一些有N个元素的集合应用问题中,我们通常是在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组的元素所在的集合合并,其间要反复查找一个元素在哪个集合中。这一类问题近几年来反复出现在信息学的国际国内赛题中。其特点是看似并不复杂,但数据量…...

人工智能轨道交通行业周刊-第34期(2023.2.13-2.19)
本期关键词:智慧地铁、枕簧检测选配机器人、智慧工地、接触网检修、工业缺陷检测 1 整理涉及公众号名单 1.1 行业类 RT轨道交通人民铁道世界轨道交通资讯网铁路信号技术交流北京铁路轨道交通网上榜铁路视点ITS World轨道交通联盟VSTR铁路与城市轨道交通RailMetro…...
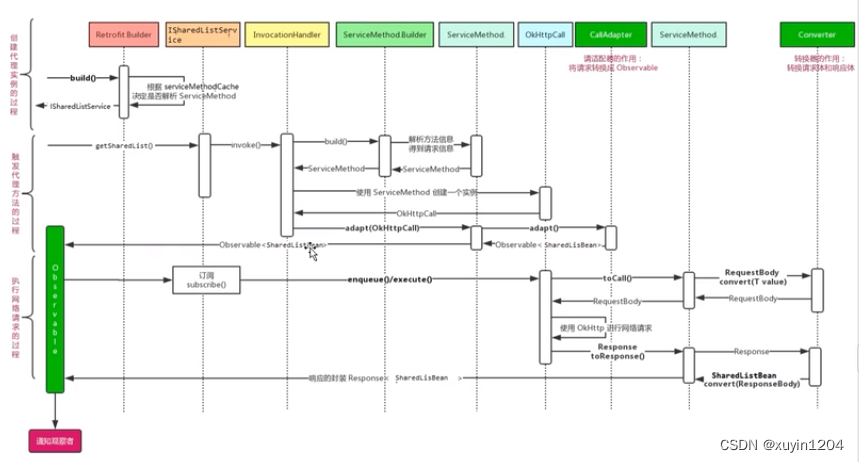
Retrofit 网络框架源码解析(二)
目录一、Okhttp请求二、Retrofit 请求retrofit是如何封装请求的三、Retrofit的构建过程四、Retrofit构建IxxxService对象的过程(Retrofit.create())4.1 动态代理4.2 ServiceMethod4.3 okHttpCall4.4 callAdapter五、Retrofit网络请求操作一、Okhttp请求 …...
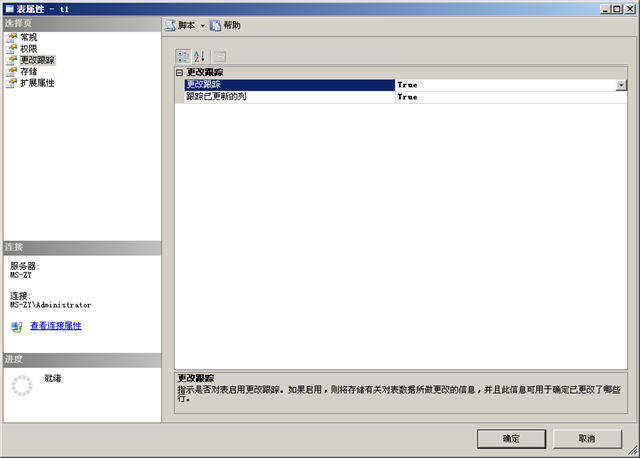
SQL Server 2008新特性——更改跟踪
在大型的数据库应用中,经常会遇到部分数据的脱机和多个数据库的合并问题。比如现在有一个全省范围使用的应用程序,每个市都部署了单独的相同的应用程序服务器和数据库服务器,每个月需要将全省所有市的数据全部汇总起来用于出全省的报表&#…...

四六级真题长难句分析与应用
一、基本结构的长难句 基本结构的长难句主要考点:断开和简化 什么是长难句? 其实就是多件事连在了一块,这时候句子就变长、变难了 分析步骤: 第一件事就是要把长难句给断开,把多件事断开成一件一件的事情࿰…...

嘎嘎降AI和率零哪个更适合毕业论文:2026年性价比达标率用户口碑完整横评测试报告
嘎嘎降AI和率零哪个更适合毕业论文:2026年性价比达标率用户口碑完整横评测试报告 帮几个不同专业的同学处理过论文AI率,用过的工具加起来也有六七款了。 综合看,嘎嘎降AI(www.aigcleaner.com)是最稳的选择࿰…...

【Midjourney胶片摄影风格终极指南】:20年影像工程师亲授7种不可外传的参数组合与暗房逻辑复刻法
更多请点击: https://intelliparadigm.com 第一章:胶片摄影的数字复刻本质与Midjourney底层成像机制 胶片摄影的“颗粒感”“色偏”“晕影”并非缺陷,而是光化学反应在银盐乳剂中非线性响应的物理印记;Midjourney 并不模拟胶片&a…...

3步掌握ADB驱动安装:Windows平台最简Android连接方案
3步掌握ADB驱动安装:Windows平台最简Android连接方案 【免费下载链接】Latest-adb-fastboot-installer-for-windows A Simple Android Driver installer tool for windows (Always installs the latest version) 项目地址: https://gitcode.com/gh_mirrors/la/Lat…...

从MHC到MCC:PIC32项目迁移实战指南与问题排查
1. 项目概述:从MHC到MCC的迁移之路如果你是一位长期使用Microchip PIC32系列微控制器的嵌入式开发者,那么“MPLAB Harmony配置器(MHC)”这个名字你一定不陌生。它曾经是Harmony框架下图形化配置工具的核心,帮助我们快速…...
)
KUKA机器人FSoE安全地址丢了别慌!手把手教你用WorkVisual手动找回(附KRC4标准柜地址表)
KUKA机器人FSoE安全地址丢失应急恢复指南:从诊断到修复的全流程解析 当产线突然因KUKA机器人安全通信故障停机时,控制柜屏幕上闪烁的FSoE地址错误提示往往让现场工程师心跳加速。不同于常规故障,安全地址丢失直接切断设备间的安全信号传输&am…...

基于RAG的代码库智能问答工具:askyourgit部署与实战指南
1. 项目概述:当代码库成为你的对话伙伴在软件开发与团队协作的日常中,我们常常面临一个看似简单却异常耗时的问题:“这段代码是谁写的?当时为什么要这么改?”或者“我们项目里有没有处理过类似‘用户登录超时’的逻辑&…...

3分钟快速解决iPhone USB网络共享问题:实用高效驱动安装指南
3分钟快速解决iPhone USB网络共享问题:实用高效驱动安装指南 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.com/…...

观察Taotoken在多日连续调用中的延迟与稳定性表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多日连续调用中的延迟与稳定性表现 在需要连续多日、高频率调用大模型API的场景中,例如持续性的内容生成…...

c++ 端口扫描程序实现案例
第一、原理端口扫描的原理很简单,就是建立socket通信,切换不通端口,通过connect函数,如果成功则代表端口开发者,否则端口关闭。所有需要多socket程序熟悉,本内容是在window环境下的第二、单线程实现方式123…...
)
别再只抄电路图了!深入剖析DC-DC变换器电流采样与ADC保护的硬件细节(以国赛A题为例)
深入解析DC-DC变换器电流采样与ADC保护的硬件设计精髓 在功率电子系统的设计中,电流采样和ADC输入保护往往被视为"配角",但正是这些看似次要的环节,常常成为系统可靠性的致命弱点。我曾在一个工业电源项目中,因为忽视了…...