PyTorch Lightning教程八:用模型预测,部署
关于Checkpoints的内容在教程2里已经有了详细的说明,在本节,需要用它来利用模型进行预测
加载checkpoint并预测
使用模型进行预测的最简单方法是使用LightningModule中的load_from_checkpoint加载权重。
model = LitModel.load_from_checkpoint("best_model.ckpt")
model.eval()
x = torch.randn(1, 64)with torch.no_grad():y_hat = model(x)
predict_step方法
加载检查点并进行预测仍然会在预测阶段的epoch留下许多boilerplate,LightningModule中的预测步骤删除了这个boilerplate 。
class MyModel(LightningModule):def predict_step(self, batch, batch_idx, dataloader_idx=0):return self(batch)
并将任何dataloader传递给Lightning Trainer
data_loader = DataLoader(...)
model = MyModel()
trainer = Trainer()
predictions = trainer.predict(model, data_loader)
预测逻辑
当需要向数据添加复杂的预处理或后处理时,使用predict_step方法。例如,这里我们使用Monte Carlo Dropout 进行预测
class LitMCdropoutModel(pl.LightningModule):def __init__(self, model, mc_iteration):super().__init__()self.model = modelself.dropout = nn.Dropout()self.mc_iteration = mc_iterationdef predict_step(self, batch, batch_idx):# enable Monte Carlo Dropoutself.dropout.train()# take average of `self.mc_iteration` iterationspred = [self.dropout(self.model(x)).unsqueeze(0) for _ in range(self.mc_iteration)]pred = torch.vstack(pred).mean(dim=0)return pred
启用分布式推理
通过使用Lightning中的predict_step,可以使用BasePredictionWriter进行分布式推理。
import torch
from lightning.pytorch.callbacks import BasePredictionWriterclass CustomWriter(BasePredictionWriter):def __init__(self, output_dir, write_interval):super().__init__(write_interval)self.output_dir = output_dirdef write_on_epoch_end(self, trainer, pl_module, predictions, batch_indices):# 在'output_dir'中创建N (num进程)个文件,每个文件都包含对其各自rank的预测torch.save(predictions, os.path.join(self.output_dir, f"predictions_{trainer.global_rank}.pt"))# 可以保存'batch_indices',以便从预测数据中获取有关数据索引的信息torch.save(batch_indices, os.path.join(self.output_dir, f"batch_indices_{trainer.global_rank}.pt"))# 可以设置writer_interval="batch"
pred_writer = CustomWriter(output_dir="pred_path", write_interval="epoch")
trainer = Trainer(accelerator="gpu", strategy="ddp", devices=8, callbacks=[pred_writer])
model = BoringModel()
trainer.predict(model, return_predictions=False)
也可以加载保存的checkpoint,把它当作一个普通的torch.nn.Module来使用。可以提取所有的torch.nn.Module,并在训练后使用LightningModule保存的checkpoint加载权重。建议从LightningModule的init和forward方法中复制明确的实现。
class Encoder(nn.Module):...class Decoder(nn.Module):...class AutoEncoderProd(nn.Module):def __init__(self):super().__init__()self.encoder = Encoder()self.decoder = Decoder()def forward(self, x):return self.encoder(x)class AutoEncoderSystem(LightningModule):def __init__(self):super().__init__()self.auto_encoder = AutoEncoderProd()def forward(self, x):return self.auto_encoder.encoder(x)def training_step(self, batch, batch_idx):x, y = batchy_hat = self.auto_encoder.encoder(x)y_hat = self.auto_encoder.decoder(y_hat)loss = ...return loss# 训练
trainer = Trainer(devices=2, accelerator="gpu", strategy="ddp")
model = AutoEncoderSystem()
trainer.fit(model, train_dataloader, val_dataloader)
trainer.save_checkpoint("best_model.ckpt")# 创建PyTorch模型并加载checkpoint权重
model = AutoEncoderProd()
checkpoint = torch.load("best_model.ckpt")
hyper_parameters = checkpoint["hyper_parameters"]# 恢复超参数
model = AutoEncoderProd(**hyper_parameters)model_weights = checkpoint["state_dict"]# 通过 dropping `auto_encoder.` 更新key值
for key in list(model_weights):model_weights[key.replace("auto_encoder.", "")] = model_weights.pop(key)model.load_state_dict(model_weights)
model.eval()
x = torch.randn(1, 64)with torch.no_grad():y_hat = model(x)
相关文章:

PyTorch Lightning教程八:用模型预测,部署
关于Checkpoints的内容在教程2里已经有了详细的说明,在本节,需要用它来利用模型进行预测 加载checkpoint并预测 使用模型进行预测的最简单方法是使用LightningModule中的load_from_checkpoint加载权重。 model LitModel.load_from_checkpoint("b…...

桂林小程序https证书
现在很多APP都相继推出了小程序,比如微信小程序、百度小程序等,这些小程序的功能也越来越复杂,不可避免的和网站一样会传输数据,因此小程序想要上线就要保证信息传输的安全性,也就是说各种类型的小程序也需要部署https…...

html input 设置不允许修改
要设置一个 HTML input 元素不允许修改,您可以添加 readonly 属性或将 disabled 属性设置为 true。这将禁用元素的编辑功能。 下面是几个示例: 使用 readonly 属性: <input type"text" readonly value"不允许修改的文本…...

BI技巧丨利用Index计算半累计
在实际的业务场景中,特别是财务模块和库存管理模块,经常需要我们针对每个月的期初期末进行相关指标计算,这也是我们之前曾经提到的Calculate基础应用——半累计计算。 现在我们也可以通过微软新推出的Index开窗函数来解决这一问题。 INDEX函…...
第三章:前端UI框架介绍
文章目录 一、Bootstrap1.1 Bootstrap简介及版本1.2 Bootstrap使用 二、AntDesign2.1 简介2.2 基本使用2.3 antd pro 三、ElementUI3.1 简介3.2 基本使用 四、Vant4.1 简介4.2 基本使用 一、Bootstrap 1.1 Bootstrap简介及版本 1、 简介 Bootstrap,来白 Twitter&a…...

javaScript:文档流写入和元素写入
目录 前言 文档流写入 把元素直接写入到文档流 注意编辑 注意 元素写入 注意 innerHTML 特点: 设置内容 获取内容 innerText 特点: 注意 相关代码 前言 在JavaScript中,文档流写入是指将内容直接写入到DOM(文档对…...

【BI系统】选型常见问题解答二
本文主要总结BI系统选型过程中遇见的常见问题,并针对性做出回答,希望能为即将选型,或正在选型BI系统的企业用户们提供一个快速了解通道。 有针对金蝶云星空的BI方案吗?能起到怎样的作用? 答:奥威BI系统拥…...

docker版jxTMS使用指南:使用jxTMS采集数据之一
本文讲解了如何jxTMS的数据采集与处理框架并介绍了如何用来采集数据,整个系列的文章请查看:docker版jxTMS使用指南:4.4版升级内容 docker版本的使用,请查看:docker版jxTMS使用指南 4.0版jxTMS的说明,请查…...

【js】日期、时间正则匹配
1、日期的正则表达式 格式:2023-08-11 var reg /^[1-9]\d{3}-(0[1-9]|1[0-2])-(0[1-9]|[1-2][0-9]|3[0-1])$/; var regExp new RegExp(reg); if(!regExp.test(value)){alert("日期格式不正确");return; }2、时间的正则表达式 格式:23:00:00…...

专利研读-SIMD系列-向量化引擎
专利研读-SIMD系列-向量化引擎 1、专利内容 阿里巴巴的专利:向量化处理数据的方法及装置,主要思想为:对于行存表或行、列存混合存储的查询场景,需要手工将行存表转换成列存表再在列存表基础上进行向量化处理,这种方式代…...

C#--设计模式之单例模式
单例模式大概是所有设计模式中最简单的一种,如果在面试时被问及熟悉哪些设计模式,你可能第一个答的就是单例模式。 单例模式的实现分为两种: 饿汉式:在静态构造函数执行时就立即实例化。懒汉式:在程序执行过程中第一…...

RWEQ风蚀方程模型与ArcGIS数据处理Python代码库添加结合理论研究和科研实践
RWEQ模型是应用比较普遍的能适应大区域定量估算风蚀量的模型。该模型是基于大量野外实验的一种经验模型,在实际测定风力导致的土壤侵蚀量以及当地的气象、地表植被、土壤湿度、地表的结皮和地表的可蚀性等因子的基础上得出的一个经验方程。 1、掌握土壤风蚀模型的原…...
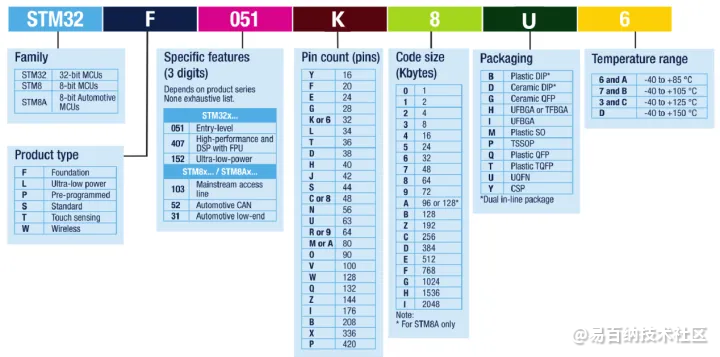
基于STM32微控制器的物联网(IoT)节点设计与实现
基于STM32微控制器的物联网(IoT)节点的设计和实现。我们讨论物联网节点的基本概念和功能,并详细介绍了STM32微控制器的特点和优势。然后,我们将探讨如何使用STM32开发环境和相关的硬件模块来设计和实现一个完整的物联网节点。最后,我们将提供一个示例代码,展示如何在STM3…...

篇二十一:中介者模式:解耦对象之间的交互
篇二十一:"中介者模式:解耦对象之间的交互" 开始本篇文章之前先推荐一个好用的学习工具,AIRIght,借助于AI助手工具,学习事半功倍。欢迎访问:http://airight.fun/。 另外有2本不错的关于设计模式…...
tomcat的多实例,动静分离(web服务基础结束)
多实例 多实例就是在一台服务器上有多个tomcat的服务(核心是改端口) 实验:多实例 安装步骤 1.安装好 jdk 2.安装 tomcat cd /opt tar zxvf apache-tomcat-9.0.16.tar.gz mkdir /usr/local/tomcat mv apache-tomcat-9.0.16 /usr/local/tomca…...
LeetCode150道面试经典题--判断子序列(简单)
1.题目 给定字符串 s 和 t ,判断 s 是否为 t 的子序列。 字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde"的一个子序…...

kubeadml 安装 k8s
目录 一:kubeadml 安装 k8s 1、网络环境 2、 环境准备 3、 所有节点安装docker 4、所有节点安装kubeadm,kubelet和kubectl 5、部署K8S集群 6、测试 二: 部署 Dashboard 一:kubeadml 安装 k8s 1、网络环境 master&am…...

考研C语言进阶题库——更新16-20题
目录 16计算t11/2...1/n-11/n 17计算1997! 18计算t1-122-133-...-1nn 19相传国际象棋是古印度舍罕王的宰相达依尔发明的.舍罕王十分喜爱象棋,决定让宰相自己选择何种赏赐. 这位聪明的宰相指着8*8共64格的象棋说:陛下,请您赏给我一些麦子吧. 就在棋盘的第1格放1粒…...
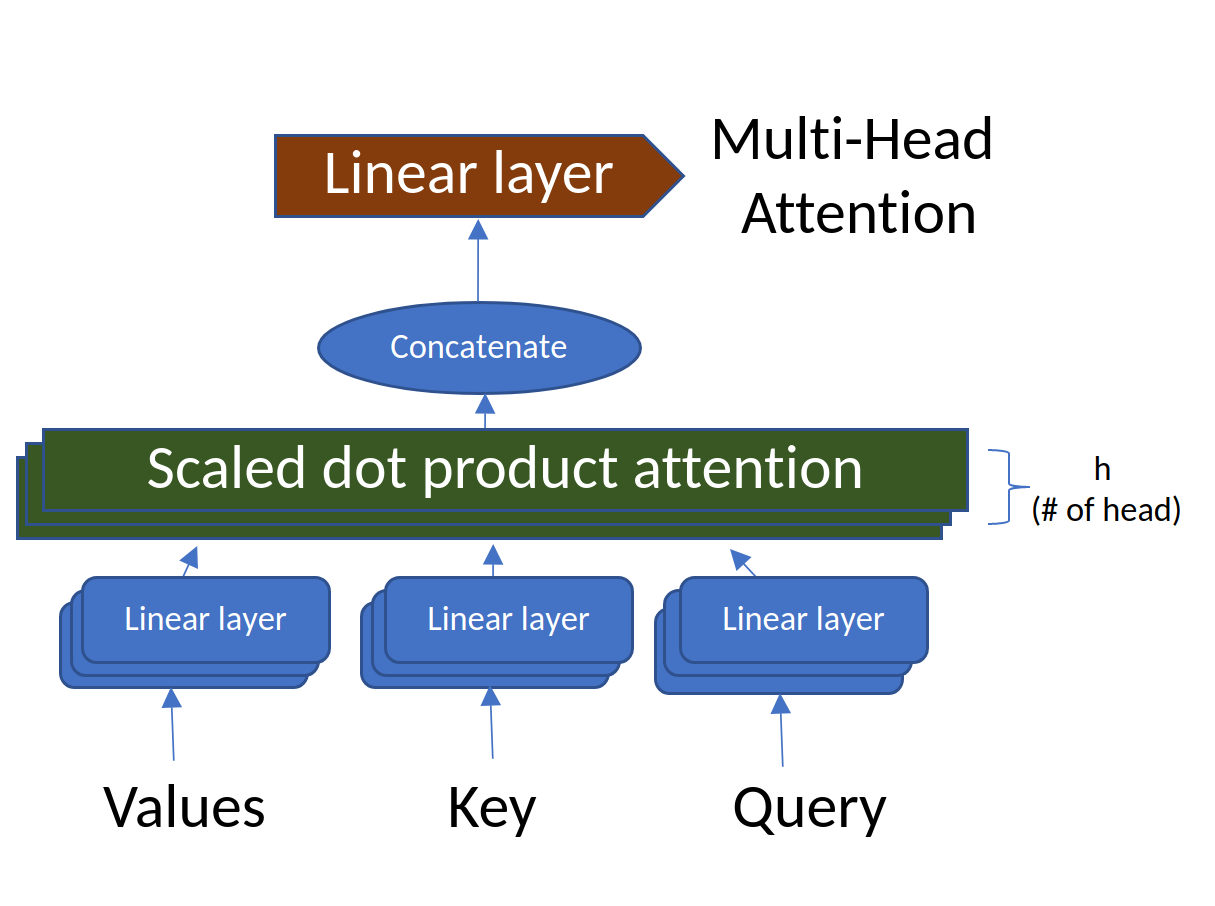
【变形金刚01】attention和transformer所有信息
图1.来源:Arseny Togulev在Unsplash上的照片 一、说明 这是一篇 长文 ,几乎讨论了人们需要了解的有关注意力机制的所有信息,包括自我注意、查询、键、值、多头注意力、屏蔽多头注意力和转换器,包括有关 BERT 和 GPT 的一些细节。因…...
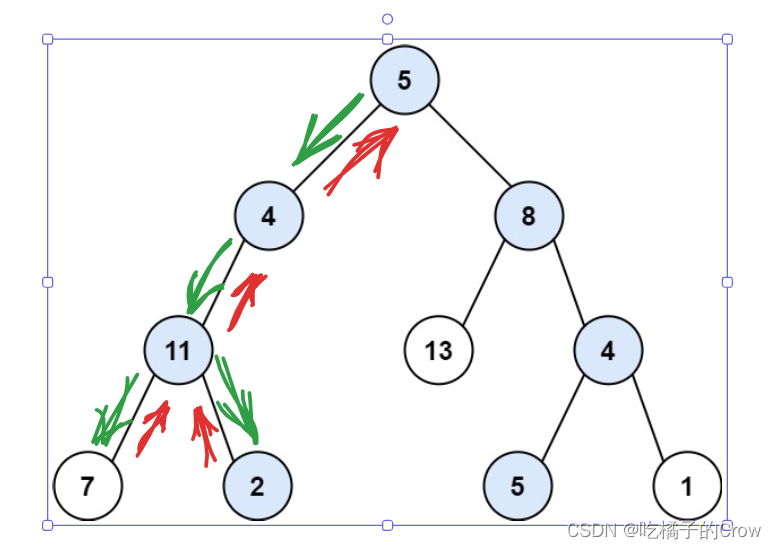
面试热题(路径总和II)
给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。 叶子节点 是指没有子节点的节点。 在这里给大家提供两种方法进行思考,第一种方法是递归,第二种方式使用回溯的方式进行爆…...
)
别急着重装!盘点搭建DNF服务端时最容易被误判的‘异常’(附数据库检查清单)
别急着重装!盘点搭建DNF服务端时最容易被误判的‘异常’(附数据库检查清单) 在搭建DNF服务端的过程中,许多开发者遇到报错的第一反应往往是"重装系统"或"换版本重来"。这种条件反射式的操作不仅浪费时间&…...

3D CNN 网络结构
在8.4节内容中,我们详细介绍了一种用于对时空数据进行特征提取的ConvLSTM模型,其有效地结合了RNN和CNN各自的优点对输入数据在时间和空间两个维度进行建模。在接下来的这节内容中将会介绍另外一种拓展自传统卷积网络的3D卷积模型来对时空数据进行特征提取…...

5分钟掌握FreeRouting:终极PCB自动布线工具完全指南
5分钟掌握FreeRouting:终极PCB自动布线工具完全指南 【免费下载链接】freerouting Advanced PCB auto-router 项目地址: https://gitcode.com/gh_mirrors/fr/freerouting FreeRouting是一款专业的开源PCB自动布线工具,能够与KiCad、Eagle等主流PC…...

虚拟手柄驱动架构深度解析:vJoy内核级输入模拟技术
虚拟手柄驱动架构深度解析:vJoy内核级输入模拟技术 【免费下载链接】vJoy Virtual Joystick 项目地址: https://gitcode.com/gh_mirrors/vj/vJoy 在游戏开发、模拟训练和人机交互领域,物理输入设备的局限性始终是技术创新的瓶颈。传统手柄硬件成本…...

C++ 多态编程与纯虚函数详解
C++ 多态编程与纯虚函数详解 多态(Polymorphism)是面向对象编程的核心特性之一,它允许同一接口表现出不同的行为。C++ 支持编译时多态(静态多态)和运行时多态(动态多态)。本文重点讲解运行时多态,以及实现它的关键工具——虚函数与纯虚函数。 一、多态的基本概念 静态…...

告别外挂交换机!手把手教你用KSZ9897芯片在嵌入式板卡上集成7口千兆交换
告别外挂交换机!KSZ9897芯片在嵌入式板卡上的7口千兆交换集成实战 在工业自动化、智能驾驶和机器视觉领域,多传感器数据并行传输已成为刚需。传统方案采用主控板外置交换机的架构,不仅占用宝贵机箱空间,线缆缠绕更成为EMI隐患。Mi…...

Mem Reduct:深入解析Windows系统内存优化工具的核心原理与实践指南
Mem Reduct:深入解析Windows系统内存优化工具的核心原理与实践指南 【免费下载链接】memreduct Lightweight real-time memory management application to monitor and clean system memory on your computer. 项目地址: https://gitcode.com/gh_mirrors/me/memre…...

Fan Control:Windows系统风扇控制软件全解析,轻松实现精准散热管理
Fan Control:Windows系统风扇控制软件全解析,轻松实现精准散热管理 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode…...
)
别再傻傻下载几十G源码了!这5个在线工具让你秒查Android系统源码(附优缺点对比)
高效查阅Android系统源码的5个在线工具全解析 作为一名长期与Android系统打交道的开发者,我深刻理解查阅系统源码时的痛点——动辄几十GB的源码下载不仅耗时耗力,还会占用宝贵的本地存储空间。更不用说不同版本间的切换和源码索引的维护,这些…...
)
为什么92%的C项目不敢升级?2026规范成本陷阱识别图谱(含GCC 14.2/Clang 18.1兼容性速查表)
第一章:现代 C 语言内存安全编码规范 2026 概览C 语言因其零开销抽象与硬件贴近性,仍在操作系统、嵌入式系统及高性能基础设施中占据核心地位。然而,传统 C 编程中普遍存在的缓冲区溢出、悬空指针、未初始化内存访问等缺陷,已成为…...