数据归一化:优化数据处理的必备技巧
文章目录
- 🍀引言
- 🍀数据归一化的概念
- 🍀数据归一化的应用
- 🍀数据归一化的注意事项与实践建议
- 🍀代码演示
- 🍀在sklearn中使用归一化
- 🍀结语
🍀引言
在当今数据驱动的时代,数据的质量和准确性成为决策的关键因素。然而,由于不同特征之间的度量单位和尺度不同,数据的分布可能会出现偏差,从而影响建模和分析的结果。为了解决这个问题,数据归一化成为优化数据处理的重要技巧。本文将介绍数据归一化的概念、常用方法以及它在机器学习和数据分析中的应用
🍀数据归一化的概念
数据归一化(Normalization)是一种常见的数据预处理技术,通过对数据进行数学变换,将其映射到特定的范围内,使得不同特征之间具有可比性。数据归一化的目标是消除数据中的量纲差异,使得数据更容易进行比较和分析。
数据归一化可以分为以下几种常见的方法:
-
最小-最大归一化(Min-Max Normalization):将数据线性映射到[0, 1]区间,公式如下:
X_normalized = (X - X_min) / (X_max - X_min),其中X_min和X_max分别表示数据的最小值和最大值。 -
Z-Score归一化(Standardization):基于数据的均值和标准差进行归一化,公式如下:
X_normalized = (X - X_mean) / X_std,其中X_mean和X_std分别表示数据的均值和标准差。 -
小数定标归一化(Decimal Scaling):通过移动小数点的位置进行归一化,公式如下:
X_normalized = X / (10 ^ j),其中j是使得数据的绝对值最大的位数。
🍀数据归一化的应用
机器学习中的特征缩放
在机器学习算法中,特征缩放是一个重要的预处理步骤。通过对输入特征进行归一化,可以防止某些特征对模型的训练结果产生过大的影响,从而提高模型的性能和稳定性。常见的机器学习算法,如线性回归、逻辑回归和支持向量机等,都受益于数据归一化的应用。
数据可视化和分析
在数据可视化和分析过程中,数据归一化可以帮助我们更好地理解数据的分布和趋势。通过将数据映射到相同的尺度范围内,不同特征之间的关系和变化将更容易观察和解释。例如,在绘制折线图或散点图时,归一化的数据可以更清晰地展示特征之间的关系。
数据聚类和分类
在聚类和分类算法中,数据归一化可以改善模型的收敛速度和准确性。通过使特征之间具有可比性,聚类算法可以更好地识别数据的簇结构,而分类算法则可以更准确地判别样本的类别。
🍀数据归一化的注意事项与实践建议
-
选择适当的归一化方法
在选择数据归一化方法时,需要根据数据类型和具体任务来决定。最小-最大归一化适合处理受限范围的数据,而Z-Score归一化适用于具有正态分布的数据。此外,小数定标归一化对于非常大或非常小的数值范围也很有效。了解数据的特点和需求,选择合适的归一化方法是关键。 -
注意异常值的处理
在进行数据归一化时,需要注意异常值的存在。异常值可能对归一化后的数据产生较大的影响,因此需要先对异常值进行处理。可以采用删除异常值、替换为均值或使用离群值检测算法进行处理,确保归一化的稳定性和准确性。 -
归一化的顺序和范围
在多个特征需要进行归一化时,需要考虑归一化的顺序和范围。一般情况下,可以先对连续型的特征进行归一化,再对离散型的特征进行处理。另外,确保所有特征都在相同的范围内(如[0, 1]或[-1, 1]),以避免某个特征对结果的影响过大。 -
考虑归一化的影响
数据归一化可能改变原始数据的分布,因此需要在使用归一化数据前后进行比较和分析。特别是在进行数据可视化和解释模型结果时,需要注意归一化的影响,并将其纳入考量。
🍀代码演示
本节主要介绍最值归一化和均值方差归一化
首先是最值归一化,在进行代码演示前,我们需要了解一下基本公式

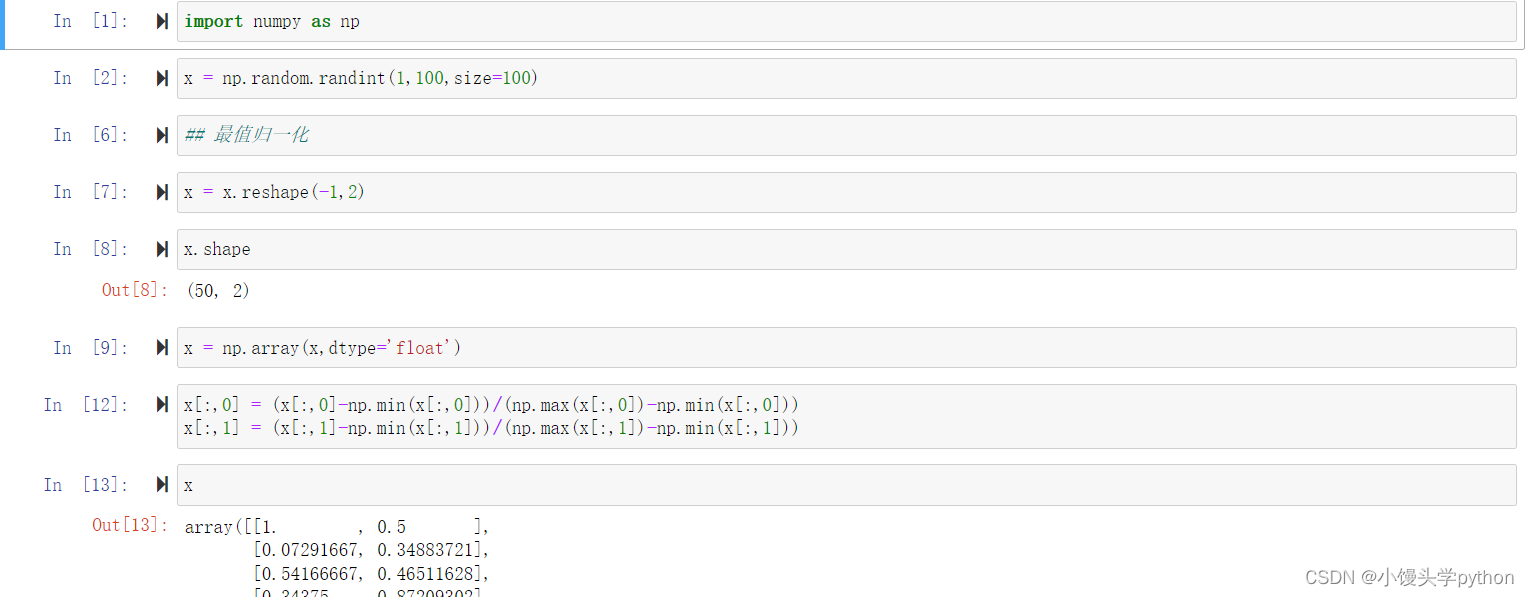
完整代码如下
import numpy as np
x = np.random.randint(1,100,size=100)
x = x.reshape(-1,2)
x = np.array(x,dtype='float')
x[:,0] = (x[:,0]-np.min(x[:,0]))/(np.max(x[:,0])-np.min(x[:,0]))
x[:,1] = (x[:,1]-np.min(x[:,1]))/(np.max(x[:,1])-np.min(x[:,1]))
均值归一化公式如下图

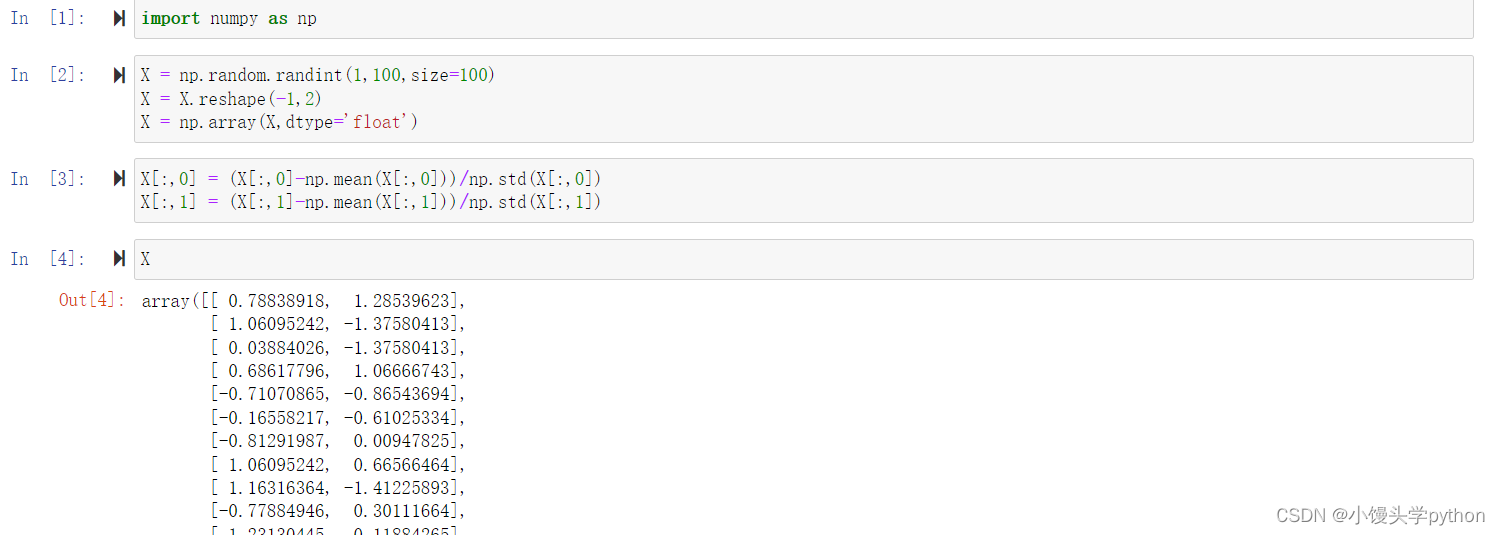
完整代码如下
import numpy as np
X = np.random.randint(1,100,size=100)
X = X.reshape(-1,2)
X = np.array(X,dtype='float')
X[:,0] = (X[:,0]-np.mean(X[:,0]))/np.std(X[:,0])
X[:,1] = (X[:,1]-np.mean(X[:,1]))/np.std(X[:,1])
🍀在sklearn中使用归一化
StandardScaler是用于特征标准化的scikit-learn库中的一个类。通过该类可以对数据进行标准化处理,使得数据的均值为0,方差为1。
在给定的代码中,X1是输入的数据集。fit方法用于计算数据集的均值和标准差,并将其保存为StandardScaler对象的属性。这些统计信息将用于之后的数据转换。
fit方法将根据数据集X1计算并保存均值和方差。之后,你可以使用transform方法将其他数据集进行标准化,使其具有与X1相同的标准化规则。
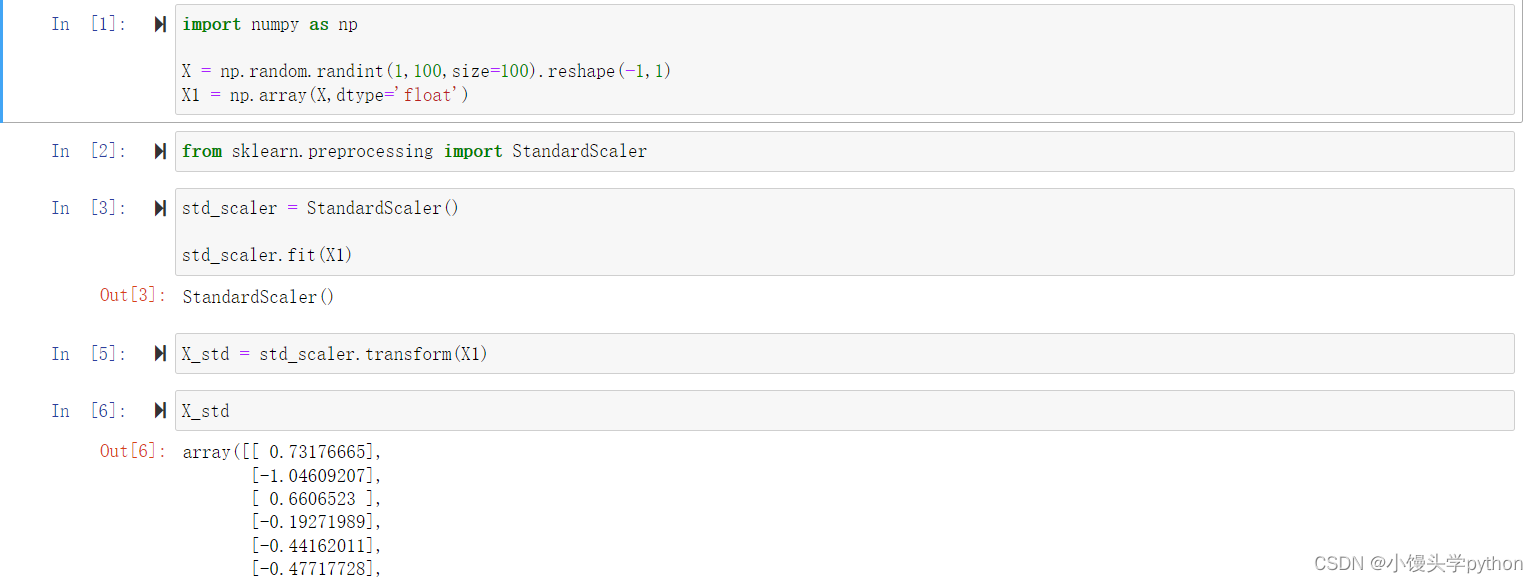
完整代码如下
import numpy as np
X = np.random.randint(1,100,size=100).reshape(-1,1)
X1 = np.array(X,dtype='float')
from sklearn.preprocessing import StandardScaler
std_scaler = StandardScaler()
std_scaler.fit(X1)
X_std = std_scaler.transform(X1)
🍀结语
数据归一化是优化数据处理的必备技巧,它使得不同特征之间具有可比性,提高模型的性能和稳定性。在实践中,我们应根据数据类型和任务需求选择合适的归一化方法,并注意处理异常值、归一化顺序和范围,以及考虑归一化的影响。通过合理和正确地应用数据归一化,我们能够充分挖掘数据的潜力,做出更准确和可靠的决策。

挑战与创造都是很痛苦的,但是很充实。
相关文章:
数据归一化:优化数据处理的必备技巧
文章目录 🍀引言🍀数据归一化的概念🍀数据归一化的应用🍀数据归一化的注意事项与实践建议🍀代码演示🍀在sklearn中使用归一化🍀结语 🍀引言 在当今数据驱动的时代,数据的…...
常量池-JVM(十九)
上篇文章说gc日志以及arthas。 Arthas & GC日志-JVM(十八) 一、常量池 常量池主要放两大类:字面量和符号引用。 字面量就是由字母、数字等构成的字符串或者数值常量。 符号引用主要包含三类常量。 类和接口的全限定名。字段的名称和…...

java+springboot+mysql智能社区管理系统
项目介绍: 使用javaspringbootmysql开发的社区住户综合管理系统,系统包含超级管理员、管理员、住户角色,功能如下: 超级管理员:管理员管理;住户管理;房屋管理(楼栋、房屋ÿ…...

pve组网实现公网访问pve,访问电脑,访问pve中的openwrt同时经过openwrt穿透主路由地址nginx全公网访问最佳办法测试研究...
一台路由器 做主路由 工控机 装pve虚拟机 虚拟机里面装一个openwrt, 外网可以直接访问pve,可以访问pve里的openwrt 一台主机 可选择连 有4个口,分别eth0,eth1,eth2,eth3 pve有管理口 这个情况下 ,没有openwrt 直接电脑和pve管理口连在一起就能进pve管理界…...
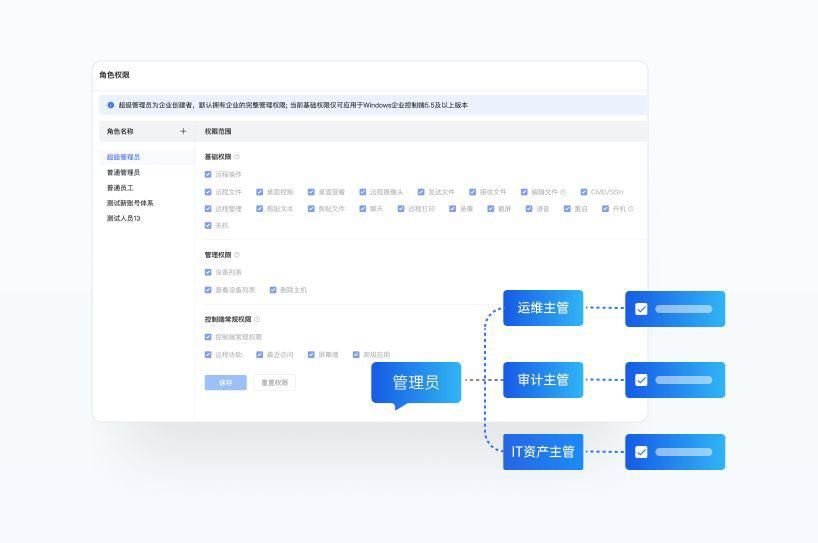
远程运维大批量IT设备?向日葵批量部署、分组授权与安全功能解析
数字化转型的不断推进,给予了企业全方位的赋能,但任何发展都伴随着成本与代价,比如在数字化转型过程中企业内部办公与外部业务所需的不断增加的IT设备数量,就为日常的运维工作提出了更大的挑战。 针对企业面对海量IT设备时的运维…...

Harbor内网离线安装使用HTTPS访问
重要提醒:使用的是域名形式访问Harbor。通过https://harbor.top访问网址。 1、首先在自己windows电脑 “此磁盘C->Windows->System32->drivers->etc” 修改hosts文件 添加“ip harbor.top”例如:“172.33.33.33 harbor.top” 2、进入内网服务…...

Python“牵手”京东工业商城商品详情数据方法介绍
京东工业平台(imall.jd.com)是一个 B2B 电商平台,提供了丰富的工业品类商品,涵盖了机械、化工、建材、劳保用品等品类。如果您需要采集京东工业平台的商品详情数据,可以尝试以下步骤: 选定目标品类和 SKU …...

接口测试意义及工作流程
一、为什么要做接口测试? 一)、接口测试的作用 1、接口测试主要用于检测外部系统与系统之间以及内部各个子系统之间的交互。 2、测试的重点是要检查数据的交换,传递和控制管理过程,以及系统间的相互逻辑依赖关系等。 二&#…...

QT-如何使用RS232进行读写通讯
以下是一个使用Qt进行RS232通讯的具体示例,包括读取和写入数据的操作: #include <QCoreApplication> #include <QDebug> #include <QSerialPort> #include <QTimer>QSerialPort serial; // 串口对象void readData() {QByteArra…...
)
05 神经网络语言模型(独热编码+词向量的起源)
博客配套视频链接: https://space.bilibili.com/383551518?spm_id_from=333.1007.0.0 b 站直接看 配套 github 链接:https://github.com/nickchen121/Pre-training-language-model 配套博客链接:https://www.cnblogs.com/nickchen121/p/15105048.html 统计语言模型 统计+语…...

PyTorch Lightning教程八:用模型预测,部署
关于Checkpoints的内容在教程2里已经有了详细的说明,在本节,需要用它来利用模型进行预测 加载checkpoint并预测 使用模型进行预测的最简单方法是使用LightningModule中的load_from_checkpoint加载权重。 model LitModel.load_from_checkpoint("b…...

桂林小程序https证书
现在很多APP都相继推出了小程序,比如微信小程序、百度小程序等,这些小程序的功能也越来越复杂,不可避免的和网站一样会传输数据,因此小程序想要上线就要保证信息传输的安全性,也就是说各种类型的小程序也需要部署https…...

html input 设置不允许修改
要设置一个 HTML input 元素不允许修改,您可以添加 readonly 属性或将 disabled 属性设置为 true。这将禁用元素的编辑功能。 下面是几个示例: 使用 readonly 属性: <input type"text" readonly value"不允许修改的文本…...

BI技巧丨利用Index计算半累计
在实际的业务场景中,特别是财务模块和库存管理模块,经常需要我们针对每个月的期初期末进行相关指标计算,这也是我们之前曾经提到的Calculate基础应用——半累计计算。 现在我们也可以通过微软新推出的Index开窗函数来解决这一问题。 INDEX函…...
第三章:前端UI框架介绍
文章目录 一、Bootstrap1.1 Bootstrap简介及版本1.2 Bootstrap使用 二、AntDesign2.1 简介2.2 基本使用2.3 antd pro 三、ElementUI3.1 简介3.2 基本使用 四、Vant4.1 简介4.2 基本使用 一、Bootstrap 1.1 Bootstrap简介及版本 1、 简介 Bootstrap,来白 Twitter&a…...

javaScript:文档流写入和元素写入
目录 前言 文档流写入 把元素直接写入到文档流 注意编辑 注意 元素写入 注意 innerHTML 特点: 设置内容 获取内容 innerText 特点: 注意 相关代码 前言 在JavaScript中,文档流写入是指将内容直接写入到DOM(文档对…...

【BI系统】选型常见问题解答二
本文主要总结BI系统选型过程中遇见的常见问题,并针对性做出回答,希望能为即将选型,或正在选型BI系统的企业用户们提供一个快速了解通道。 有针对金蝶云星空的BI方案吗?能起到怎样的作用? 答:奥威BI系统拥…...

docker版jxTMS使用指南:使用jxTMS采集数据之一
本文讲解了如何jxTMS的数据采集与处理框架并介绍了如何用来采集数据,整个系列的文章请查看:docker版jxTMS使用指南:4.4版升级内容 docker版本的使用,请查看:docker版jxTMS使用指南 4.0版jxTMS的说明,请查…...

【js】日期、时间正则匹配
1、日期的正则表达式 格式:2023-08-11 var reg /^[1-9]\d{3}-(0[1-9]|1[0-2])-(0[1-9]|[1-2][0-9]|3[0-1])$/; var regExp new RegExp(reg); if(!regExp.test(value)){alert("日期格式不正确");return; }2、时间的正则表达式 格式:23:00:00…...

专利研读-SIMD系列-向量化引擎
专利研读-SIMD系列-向量化引擎 1、专利内容 阿里巴巴的专利:向量化处理数据的方法及装置,主要思想为:对于行存表或行、列存混合存储的查询场景,需要手工将行存表转换成列存表再在列存表基础上进行向量化处理,这种方式代…...

三指数平滑与网格搜索在时间序列预测中的实践
1. 时间序列预测中的三指数平滑方法解析三指数平滑(Triple Exponential Smoothing),又称Holt-Winters方法,是时间序列预测中最经典的技术之一。我在实际业务预测项目中多次使用这种方法,特别是在处理具有明显趋势和季节…...

《为什么说Ozon是跨境选品的“图片金矿”?配合1688以图搜图威力有多大?》
🔥 Ozon1688:跨境选品的“核武器级”组合如果说传统选品是“撒网捕鱼”,那么Ozon1688的“以图搜图”就是“精准爆破”。💎 一、为什么Ozon是“图片金矿”?Ozon图片的四个独特价值维度1. 审美金矿:未被全球化…...

Qwen3.5-2B模型在Keil5嵌入式开发中的实战应用
Qwen3.5-2B模型在Keil5嵌入式开发中的实战应用 1. 嵌入式开发的智能助手时代 作为一名嵌入式开发工程师,你是否经常遇到这样的场景:深夜调试代码时卡在一个寄存器配置问题上,翻遍手册却找不到明确答案;或者面对一个新的外设驱动…...

5分钟极速转换:m4s-converter无损视频格式转换解决方案
5分钟极速转换:m4s-converter无损视频格式转换解决方案 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否遇到过这样的情况&…...

AI安全进阶面试:高阶安全技术面试题与解析
AI安全进阶面试:高阶安全技术面试题与解析📝 本章学习目标:本章聚焦职业发展,帮助读者规划AI安全合规治理的学习与职业路径。通过本章学习,你将全面掌握"AI安全进阶面试:高阶安全技术面试题与解析&quo…...
)
预算编制怎么做?一文读懂预算编制六大步骤(附流程图)
月底了,又到了财务人最怕的预算编制时刻。说实话,你之所以怕做预算、总觉得做不好,根本原因还是流程出了问题。预算编制本身是一套严谨的管理流程,是有方法可循的。今天,我会按照最基础的六个步骤,一步步教…...
)
告别官方模板!手把手教你从零搭建CH32V003自定义工程(附目录结构规划)
从零构建CH32V003工程架构:打造可维护的嵌入式开发基石 当官方模板无法满足复杂项目需求时,如何从零开始构建一个既规范又灵活的工程结构?这不仅是技术问题,更是项目管理智慧的体现。对于使用CH32V003这类RISC-V内核MCU的中级开发…...

如何高效管理个人数字记忆:WeChatMsg聊天记录分析与归档实用指南
如何高效管理个人数字记忆:WeChatMsg聊天记录分析与归档实用指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trendin…...

想学无人机编程但怕炸机?试试这个Unity模拟方案:从零配置飞行控制与传感器数据可视化
无人机编程新思路:用Unity打造零风险仿真训练平台 当螺旋桨的呼啸声在耳边响起,新手开发者最担心的往往是价值数万元的设备变成"空中炸弹"。传统无人机算法开发需要反复试飞调试,每一次失误都可能意味着昂贵的维修费用,…...

PCCIndex优化:分布式缓存一致性挑战与解决方案
1. 项目概述:PCCIndex优化背景与核心挑战在分布式系统和新型硬件架构快速发展的今天,缓存一致性(Cache Coherence)的设计面临着前所未有的挑战。传统基于硬件的缓存一致性协议(如MESI)在多核处理器场景下表…...