干货满满的Python知识,学会这些你也能成为大牛
目录
1. 爬取网站数据
2. 数据清洗与处理
3. 数据可视化
4. 机器学习模型训练
5. 深度学习模型训练
6. 总结
1. 爬取网站数据
在我们的Python中呢,使用爬虫可以轻松地获取网站的数据。可以使用urllib、requests、BeautifulSoup等库进行数据爬取和处理。以下是一段爬取天气信息的示例代码,欧蕾欧蕾欧蕾蕾:
import requests
from bs4 import BeautifulSoupurl = 'https://www.weather.com/zh-CN/weather/hourbyhour/l/China+Beijing+Beijing?canonicalCityId=4a7d9ad7fc0cbd7f58d22b2f3d5c3cd9eb520a9b49f797290e3a8ae30e23f0e9'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'html.parser')for hour in soup.select('.twc-hourly-forecast__table .twc-sticky-col.hourly-time > span'):print(hour.text)
这段代码通过requests库获取网站的HTML内容,然后使用BeautifulSoup库解析HTML并进行数据提取。通过CSS选择器定位到需要的信息,并进行输出滴昂。
2. 数据清洗与处理
在获取到数据后,需要去对俺们的数据进行清洗和处理。这包括数据去重、缺失值填充、数据类型转换等。以下是一段简单的数据清洗和处理示例代码:

import pandas as pd
import numpy as np# 读取CSV文件
df = pd.read_csv('data.csv')# 去除重复数据
df.drop_duplicates(inplace=True)# 填充缺失值
df.fillna(value={'age': np.mean(df['age'])})# 数据类型转换
df['age'] = df['age'].astype(int)
这段代码使用pandas库读取CSV文件,并对数据进行去重、缺失值填充、数据类型转换等操作。这些操作可以帮助我们对数据进行清洗和处理,使得数据更加滴规范化和易于分析。
3. 数据可视化
在对数据进行清洗和处理后,我们需要对数据进行可视化。可视化可以帮助我们更好滴理解数据,并发现数据中的规律。以下是一段简单的数据可视化示例代码:
import matplotlib.pyplot as plt# 读取CSV文件
df = pd.read_csv('data.csv')# 绘制散点图
plt.scatter(df['age'], df['score'])# 设置图表标题和坐标轴标签
plt.title('Age vs. Score')
plt.xlabel('Age')
plt.ylabel('Score')# 显示图表
plt.show()
这段代码使用matplotlib库绘制了一个散点图,通过设置标题、坐标轴标签等属性,使得图表更加清晰易懂。这个简单的示例可以帮助我们了解如何在Python中进行数据可视化。
4. 机器学习模型训练
在Python中,使用机器学习模型可以对数据进行预测和分类。可以使用scikit-learn等库进行机器学习模型的构建和训练。以下是一个简单的线性回归模型训练示例:
from sklearn.linear_model import LinearRegression# 读取CSV文件
df = pd.read_csv('data.csv')# 提取特征和标签
X = df[['age']]
y = df['score']# 构建线性回归模型
model = LinearRegression()# 训练模型
model.fit(X, y)# 输出模型系数和截距
print(model.coef_)
print(model.intercept_)
这段代码使用scikit-learn库构建了一个线性回归模型,使用读取CSV文件提取特征和标签。然后使用fit()方法训练模型,并输出模型系数和截距。这个简单的示例可以帮助我们了解如何在Python中进行机器学习模型的训练。
5. 深度学习模型训练
在Python中,使用深度学习模型可以对更加复杂的数据进行预测和分类。可以使用TensorFlow、Keras等库进行深度学习模型的构建和训练。以下是一个简单的MNIST手写数字识别模型训练示例:
import tensorflow as tf
from tensorflow import keras# 读取MNIST数据集
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()# 将数据集归一化
x_train = x_train / 255.0
x_test = x_test / 255.0# 构建深度学习模型
model = keras.Sequential([keras.layers.Flatten(input_shape=(28, 28)),keras.layers.Dense(128, activation='relu'),keras.layers.Dropout(0.2),keras.layers.Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])# 训练模型
model.fit(x_train, y_train, epochs=5)# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test)
print('Test accuracy:', test_acc)
这段代码使用TensorFlow和Keras库构建了一个简单的MNIST手写数字识别模型。通过读取MNIST数据集,使用Sequential模型构建深度学习模型并编译模型。然后使用fit()方法训练模型,并使用evaluate()方法评估模型。这个示例可以帮助我们了解如何在Python中进行深度学习模型的训练。
6. 总结
我们的宝贝Python在数据处理、机器学习、深度学习等方面都有非常强大的应用。在使用Python进行编程时,我们可以使用各种各样的库来完成我们的任务。本文介绍了爬取网站数据、数据清洗与处理、数据可视化、机器学习模型训练和深度学习模型训练等几个示例。
制作不易
求三连喔
相关文章:
干货满满的Python知识,学会这些你也能成为大牛
目录 1. 爬取网站数据 2. 数据清洗与处理 3. 数据可视化 4. 机器学习模型训练 5. 深度学习模型训练 6. 总结 1. 爬取网站数据 在我们的Python中呢,使用爬虫可以轻松地获取网站的数据。可以使用urllib、requests、BeautifulSoup等库进行数据爬取和处理。以下是…...

【Leetcode】155. 最小栈、JZ31 栈的压入、弹出序列
作者:小卢 专栏:《Leetcode》 喜欢的话:世间因为少年的挺身而出,而更加瑰丽。 ——《人民日报》 155. 最小栈 155. 最小栈 题目描述; 设计一个支持 push ,pop ,top …...
网络安全(黑客技术)自学笔记
一、什么是网络安全?什么是黑客? 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。 无论网络、Web、移动、桌面、云等…...

iOS学习—制作全局遮罩
在.h文件中线声明show()方法 - (void)show; .m文件中添加全屏遮罩,在遮罩上添加了一个选择框并添加了底部弹出的动画,可自行在其中添加tableview、pickerview等其他视图,并添加了点击选择框视图外区域隐藏 #import "MaskView.h"…...

GRPC-连接池-GPT
gRPC Dart 管理优化 User grpc for dart 如何统一管理多个Client的创建和销毁,给我一个最优解 ChatGPT 对于在Dart中使用gRPC创建和销毁多个Client的统一管理,您可以使用一个单例模式的管理类来实现最优解。 首先,创建一个管理类,…...
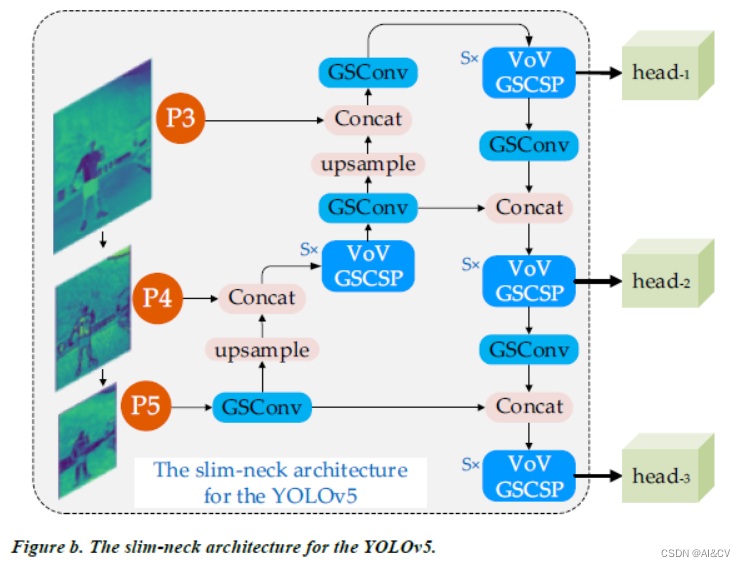
YOLOv5、YOLOv8改进: GSConv+Slim Neck
论文题目:Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles 论文:https://arxiv.org/abs/2206.02424 代码:https://github.com/AlanLi1997/Slim-neck-by-GSConv 在计算机视觉领域&#x…...

重发布选路问题
一、思路 ; 1.增加不优选路开销解决选路不佳问题 2.用增加开销的方式使R1 不将ASBR传的R7传给另一台ASBR解决R1、R2、R3、R4pingR7环回环路 二、操作 ------IP地址配置如图 1.ospf及rip的宣告 rip: [r1]rip 1 [r1-rip-1]version 2 [r1-rip-1]netw…...

LinearAlgebraMIT_9_LinearIndependence/SpanningASpace/Basis/Dimension
这节课我们主要学习一下(Linear Independence)线性无关,(spanning a space)生成空间,(basis)基和(dimension)维度。同时我们要注意这四个很重要的基本概念的描述对象,我们会说向量组线性无关,由一个向量组生成的空间,子…...

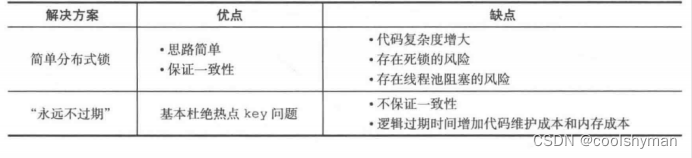
Redission 解锁异常:attempt to unlock lock, not locked by current thread by node id
标题:解锁异常:Redission中的"attempt to unlock lock, not locked by current thread by node id"问题分析与解决方案 在分布式系统中,锁是常用的同步机制,用于保护共享资源,避免并发冲突。Redission是一个…...

AIGC技术揭秘:探索火热背后的原因与案例
文章目录 什么是AIGC技术?为何AIGC技术如此火热?1. 提高效率与创造力的完美结合2. 拓展应用领域,创造商业价值3. 推动技术创新和发展 AIGC技术案例解析1. 艺术创作:生成独特的艺术作品2. 内容创作:实时生成各类内容3. …...

【Linux】总结1-命令工具
文章目录 基础指令shell命令以及运行原理Linux权限粘滞位工具 基础指令 ls、pwd、touch、mkdir、netstat、cp、mv、cd、tar、zip、unzip、grep、pstack、ps、rm、cat、more、less、head、tail、find、ulimit -a、clear、whoami、man touch:创建文件,也包…...

Git远程仓库
Git远程仓库 推送拉取git fetchgit pull 克隆 推送 Git是分布式版本控制系统,同一个Git仓库,可以分布到不同的机器上。那要怎么实现这种分布呢?我们可以找一台电脑充当服务器,也就是扮演远程仓库的角色,一直都处于开机…...
Redis缓存设计
缓存能够有效地加速应用的读写速度,同时也可以降低后端负载,对日常应用的开发至关重要。但是将缓存加入应用架构后也会带来一些问题,本文将针对这些问题介绍缓存使用技巧和设计方案。 1缓存的收益和成本 下图左侧为客户端直接调用存储层的架…...
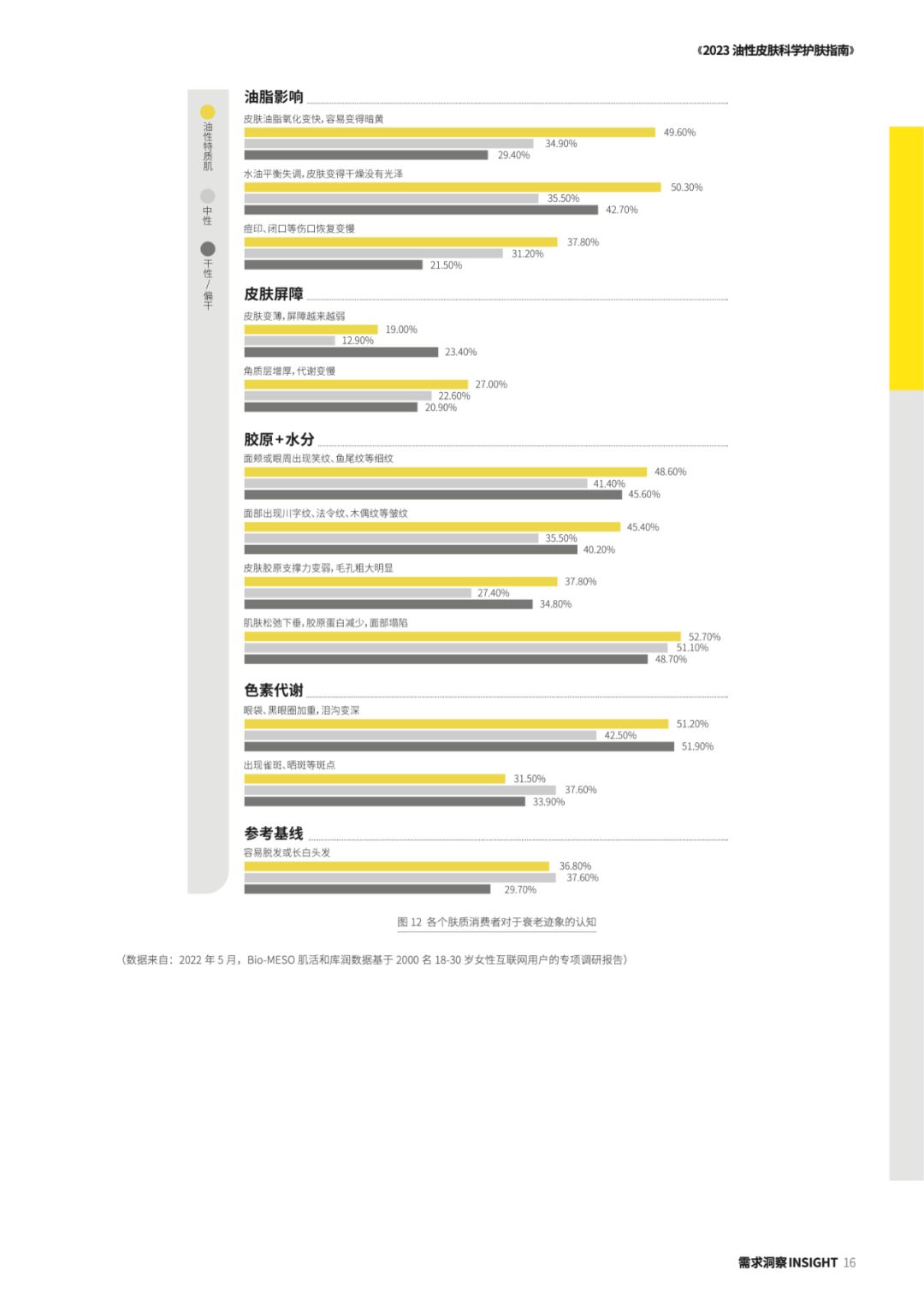
华熙生物肌活:2023年版Bio-MESO肌活油性皮肤科学护肤指南
关于报告的所有内容,公众【营销人星球】获取下载查看 核心观点 以悦己和尝鲜为消费动机的他们,已迅速崛起成为护肤行业的焦点人群。而在新生代护肤议题中,“油性皮肤护理”已经成为一个至关重要的子集。今天,中国新生代人口数量…...
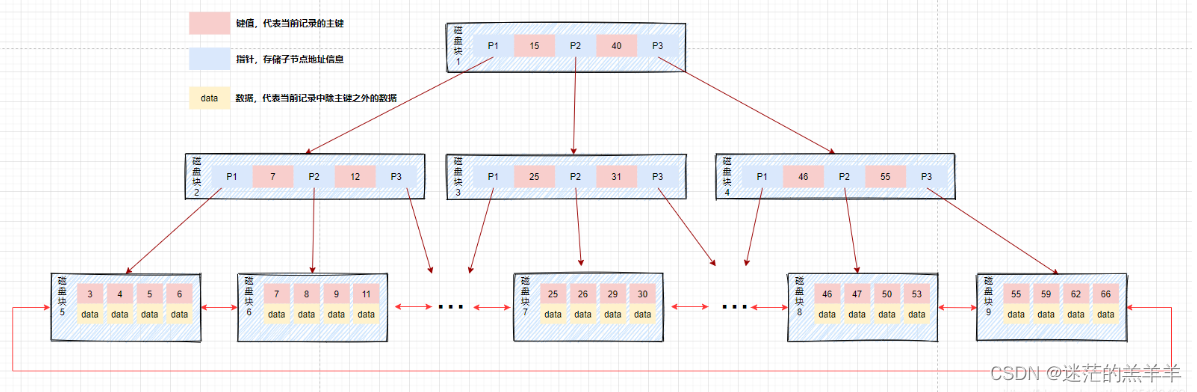
mysql索引介绍
索引可以提升查询速度,会影响where查询,以及order by排序。MySQL索引类型如下: 从索引存储结构划分:B Tree索引、Hash索引、全文索引 从应用层次划分:主键索引、唯一索引、单值索引、复合索引 从索引键值类型划分&am…...
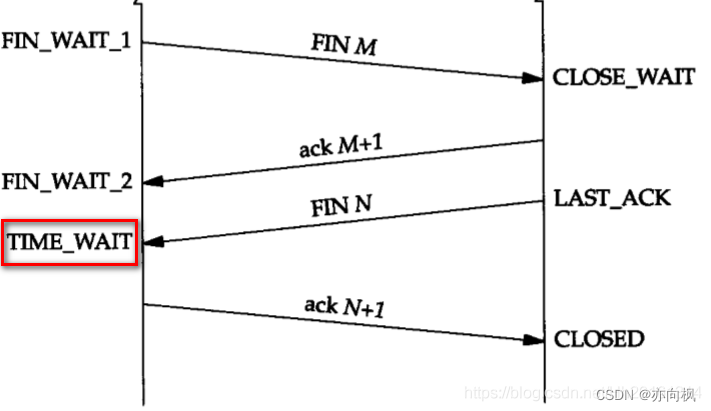
说一下什么是tcp的2MSL,为什么客户端在 TIME-WAIT 状态必须等待 2MSL 的时间?
1.TCP之2MSL 1.1 MSL MSL:Maximum Segment Lifetime报文段最大生存时间,它是任何报文段被丢弃前在网络内的最长时间 1.2为什么存在MSL TCP报文段以IP数据报在网络内传输,而IP数据报则有限制其生存时间的TTL字段,并且TTL的限制是基于跳数 1.3…...

更新spring boot jar包中的BOOT-INF/lib目录下的jar包
更新spring-boot jar包中的BOOT-INF/lib目录下的jar包 场景 需要更新lib目录下某个jar包的配置文件 失败的解决方法 用解压软件依次打开spring-boot jar包(设为a.jar)、BOOT-INF/lib目录下的jar包(设为b.jar),然后修改…...
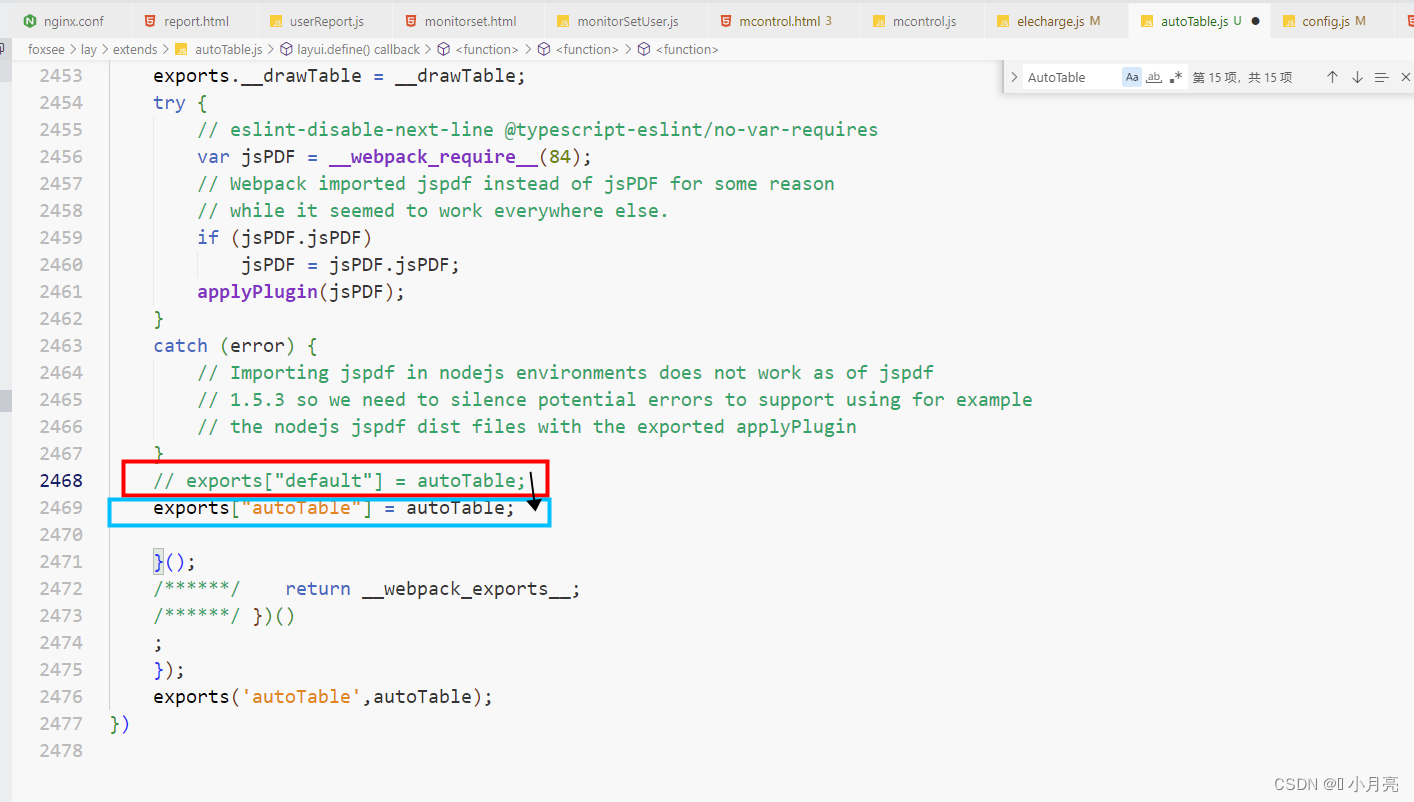
纯前端 -- html转pdf插件总结
一、html2canvasjsPDF(文字会被截断): 将HTML元素呈现给添加到PDF中的画布对象,不能仅使用jsPDF,需要html2canvas或rasterizeHTML html2canvasjsPDF的具体使用链接 二、html2pdf(内容显示不全文字会被截断…...

数据结构和算法基础
巩固基础,砥砺前行 。 只有不断重复,才能做到超越自己。 能坚持把简单的事情做到极致,也是不容易的。 数据结构和算法 程序 数据结构算法 数据结构是算法的基础 问题1:字符串匹配问题。str1 是否完全包含 str2 1)暴…...

JS二维数组转化为对象
将二维数组转化为对象的形式 转之前的数据: 转之后: const entries new Map([[foo, bar],[baz, 42],[beginNode, 202212151048010054],[beginNode, 202212151048447710],]); console.log(entries)const obj Object.fromEntries(entries);console.lo…...

告别javax.servlet:SpringBoot3项目整合knife4j 4.1.0接口文档的完整配置流程
SpringBoot3技术栈迁移实战:从javax.servlet到knife4j 4.1.0的完整升级指南 当SpringBoot3正式发布时,许多开发者发现原先运行良好的Swagger文档突然报出java.lang.ClassNotFoundException: javax.servlet.http.HttpServletRequest错误。这背后是Java EE…...

DLSS Swapper终极指南:3步轻松升级游戏DLSS版本
DLSS Swapper终极指南:3步轻松升级游戏DLSS版本 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 你是否遇到过这样的情况?新游戏更新后帧率暴跌,或者某个DLSS版本导致画面闪烁&#x…...

从零构建Android 12:AOSP源码编译实战与避坑指南
1. 环境准备:搭建Ubuntu编译环境 编译Android 12源码需要一台性能强劲的Linux机器,我推荐使用Ubuntu 20.04 LTS版本。这个版本不仅长期支持,而且对AOSP编译的兼容性最好。我的开发机是一台32核64GB内存的工作站,配了1TB SSD。如果…...

2025年MLOps必备的10个Python库解析
1. 为什么2025年的MLOps需要这10个Python库?三年前部署一个机器学习模型还需要手动编写数百行部署脚本,现在MLOps工具链的成熟度已经让模型部署变得像调用API一样简单。作为经历过完整MLOps演进周期的从业者,我亲历了从手工运维到自动化管道的…...

如何掌握Python元编程与装饰器:从入门到精通的终极指南
如何掌握Python元编程与装饰器:从入门到精通的终极指南 【免费下载链接】python-guide Python best practices guidebook, written for humans. 项目地址: https://gitcode.com/gh_mirrors/py/python-guide Python作为一门灵活且强大的编程语言,…...
)
告别数据缺失烦恼:手把手教你用SwatWeather为SWAT模型插补气象数据(附临洮站1970-2020年实战)
水文建模实战:用SwatWeather高效处理气象数据缺失问题 临洮站50年气象数据的完整插补方案 从事水文模型研究的朋友们都知道,气象数据的完整性和准确性直接影响着模拟结果的可靠性。在实际工作中,我们常常会遇到历史气象数据存在缺失的情况——…...

B站缓存视频终极转换指南:3分钟实现m4s到MP4的无损转换
B站缓存视频终极转换指南:3分钟实现m4s到MP4的无损转换 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾为B站缓存的视频无法…...

本科论文维普AI率80%,2026年4月率零2小时解决
本科论文维普AI率80%,2026年4月率零2小时解决 2026年4月中旬,本科毕业论文查重季进入最后冲刺阶段。一位就读于华东某二本院校的大四学生把论文交到维普检测系统后,屏幕上跳出一个让他愣在原地的数字:维普AI率80%。距离学院规定的…...

全球及中国定制线束市场现状调查及投资价值分析报告
2026-2032年全球及中国定制线束市场现状调查及投资价值分析报告定制线束是根据特定设备或系统需求设计和制造的电气连接组件,由导线、电缆、连接器、端子及保护材料等组成,用于实现电源和信号的传输与分配,广泛应用于汽车、工业设备、消费电子…...

Comsol介质超表面三次谐波非线性模型研究:倍频模型与转换效率计算文献赠予
Comsol介质超表面三次谐波非线性模型,包含功率依赖。 且倍频模型以及转换效率计算。打开COMSOL时总会被非线性光学模块的选项搞得头疼?今天咱们直接拿介质超表面的三次谐波模型开刀,聊聊如何让超薄结构产生高频光波。非线性效应这东西&#x…...