机器学习深度学习——seq2seq实现机器翻译(数据集处理)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er
🌌上期文章:机器学习&&深度学习——从编码器-解码器架构到seq2seq(机器翻译)
📚订阅专栏:机器学习&&深度学习
希望文章对你们有所帮助
在理解了seq2seq以后,开始用它来实现一个机器翻译的模型。我们先要进行机器翻译的数据集的选择以及处理,在之后将正式使用seq2seq来进行训练。
seq2seq实现机器翻译
- 机器翻译与数据集
- 下载和预处理数据集
- 词元化
- 词表
- 加载数据集
- 训练模型
机器翻译与数据集
语言模型是自然语言处理的关键,而机器翻译是语言模型最成功的基准测试。因为机器翻译正是将输入序列转换成输出序列的序列转换模型的核心问题。
机器翻译指的是将序列从一种语言自动翻译成另一种语言。我们这里的关注点是神经网络机器翻译方法,强调的是端到端的学习。机器翻译的数据集是由源语言和目标语言的文本序列对组成的。我们需要将预处理后的数据加载到小批量中用于训练。
import os
import torch
from d2l import torch as d2l
下载和预处理数据集
下载一个“英-法”数据集,数据集中每一行都是都是制表符分隔的文本序列对,序列对由英文文本序列和翻译后的法语文本序列组成(每个文本序列可以是一个句子, 也可以是包含多个句子的一个段落)。在这个将英语翻译成法语的机器翻译问题中, 英语是源语言,法语是目标语言。
#@save
d2l.DATA_HUB['fra-eng'] = (d2l.DATA_URL + 'fra-eng.zip','94646ad1522d915e7b0f9296181140edcf86a4f5')#@save
def read_data_nmt():"""载入“英语-法语”数据集"""data_dir = d2l.download_extract('fra-eng')with open(os.path.join(data_dir, 'fra.txt'), 'r',encoding='utf-8') as f:return f.read()raw_text = read_data_nmt()
我们可以打印查看一下:
print(raw_text[:75])
输出结果:
Go. Va !
Hi. Salut !
Run! Cours !
Run! Courez !
Who? Qui ?
Wow! Ça alors !
下载数据集后,原始文本数据需要经过几个预处理步骤。例如,我们用空格代替不间断空格,使用小写字母替换大写字母,并在单词和标点符号之间插入空格。
#@save
def preprocess_nmt(text):"""预处理“英语-法语”数据集"""def no_space(char, prev_char):return char in set(',.!?') and prev_char != ' '# 使用空格替换不间断空格# 使用小写字母替换大写字母text = text.replace('\u202f', ' ').replace('\xa0', ' ').lower()# 在单词和标点符号之间插入空格out = [' ' + char if i > 0 and no_space(char, text[i - 1]) else charfor i, char in enumerate(text)]return ''.join(out)text = preprocess_nmt(raw_text)
可以输出查看:
print(text[:80])
运行结果:
go . va !
hi . salut !
run ! cours !
run ! courez !
who ? qui ?
wow ! ça alors !
词元化
在机器翻译中,我们更喜欢单词级词元化。下面的tokenize_nmt函数对前num_examples个文本序列对进行词元,其中每个词元要么是一个词,要么是一个标点符号。
此数返回两个词元列表:source和target,source[i]是源语言(也就是这里的英语)第i个文本序列的词元列表,target[i]是目标语言(这里是法语)第i个文本序列的词元列表。
#@save
def tokenize_nmt(text, num_examples=None):"""词元化“英语-法语”数据数据集"""source, target = [], []for i, line in enumerate(text.split('\n')):if num_examples and i > num_examples:breakparts = line.split('\t')if len(parts) == 2:source.append(parts[0].split(' '))target.append(parts[1].split(' '))return source, targetsource, target = tokenize_nmt(text)
可以输出查看验证:
print(source[:6], target[:6])
运行结果:
[[‘go’, ‘.’], [‘hi’, ‘.’], [‘run’, ‘!’], [‘run’, ‘!’], [‘who’, ‘?’], [‘wow’, ‘!’]]
[[‘va’, ‘!’], [‘salut’, ‘!’], [‘cours’, ‘!’], [‘courez’, ‘!’], [‘qui’, ‘?’], [‘ça’, ‘alors’, ‘!’]]
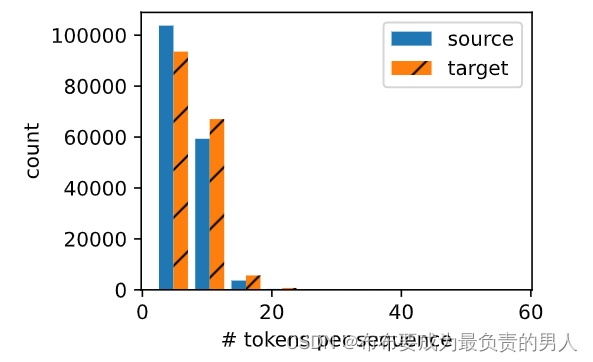
我们可以绘制每个文本序列所包含的词元数量的直方图,在这个数据集中,大多数文本序列的词元数量少于20个。
#@save
def show_list_len_pair_hist(legend, xlabel, ylabel, xlist, ylist):"""绘制列表长度对的直方图"""d2l.set_figsize()_, _, patches = d2l.plt.hist([[len(l) for l in xlist], [len(l) for l in ylist]])d2l.plt.xlabel(xlabel)d2l.plt.ylabel(ylabel)for patch in patches[1].patches:patch.set_hatch('/')d2l.plt.legend(legend)show_list_len_pair_hist(['source', 'target'], '# tokens per sequence','count', source, target)
d2l.plt.show()
词表
由于机器翻译数据集由语言对组成,因此我们可以分别为源语言和目标语言构建两个词表。
使用单词级词元化时,词表大小将明显大于使用字符级词元化时的词表大小。为了缓解这一问题,我们做一个处理方法,将一些低频率的词元视为相同的未知词元unk,在这里我们将出现次数少于2次视为低频率词元。
此外,我们还指定了额外的特定词元,例如在小批量时用于将序列填充到相同长度的填充词元pad,以及序列的开始词元bos和结束词元eos。
例如:
src_vocab = d2l.Vocab(source, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])
print(len(src_vocab))
输出结果:
10012
加载数据集
在之前,我们做过语言模型的处理,而语言模型中的序列样本都有一个固定的长度,这个固定长度由num_steps(时间步数或词元数量)来决定的。而在机器翻译中,每个样本都是由源和目标组成的文本序列对,其中的每个文本序列可能具有不同的长度。
为了提高计算效率,我们仍然可以通过截断和填充方式实现一次只处理一个小批量的文本序列。假设同一个小批量中的每个序列都应该具有相同的长度num_steps。那么若词元数目数目少于num_steps,我们就在末位填充pad词元;否则我们就截断词元取前num_steps个。只要每个文本序列具有相同的长度,就方便以相同形状的小批量进行加载。
我们定义一个函数来实现对文本序列的截断或填充。
#@save
def truncate_pad(line, num_steps, padding_token):"""截断或填充文本序列"""if len(line) > num_steps:return line[:num_steps] # 截断return line + [padding_token] * (num_steps - len(line)) # 填充
验证一下:
print(truncate_pad(src_vocab[source[0]], 10, src_vocab['<pad>']))
运行结果:
[47, 4, 1, 1, 1, 1, 1, 1, 1, 1]
可以分析一下这个运行结果,source[0]里面有两个词元,按照词元的出现频率来进行排序,分别是第47和第4,此时我们需要10个词元,那就需要填充,理所当然要填充最常见的那种词,造成的概率是最小的,所以其对应着词表中的都是频率最高的。
如果语料corpus、词表这类概念忘记了,可以看我之前的这篇文章:
机器学习&&深度学习——文本预处理
现在我们定义一个函数,可以将文本序列转换成小批量数据集用于训练。我们将eos词元添加到所有序列的末尾,用于表示序列的结束。当模型通过一个词元接一个词元地生成序列进行预测时,生成的eos词元说明完成了序列的输出工作。此外,我们还记录了每个文本序列的初始长度(排除了填充词元的长度),后序会用到。
#@save
def build_array_nmt(lines, vocab, num_steps):"""将机器翻译的文本序列转换成小批量"""lines = [vocab[l] for l in lines]lines = [l + [vocab['<eos>']] for l in lines]array = torch.tensor([truncate_pad(l, num_steps, vocab['<pad>']) for l in lines])valid_len = (array != vocab['<pad>']).type(torch.int32).sum(1) # 统计原始长度return array, valid_len
训练模型
接下来就可以定义load_data_nmt函数来返回数据迭代器,以及源语言和目标语言的两种词表:
#@save
def load_data_nmt(batch_size, num_steps, num_examples=600):"""返回翻译数据集的迭代器和词表"""text = preprocess_nmt(read_data_nmt())source, target = tokenize_nmt(text, num_examples)src_vocab = d2l.Vocab(source, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])tgt_vocab = d2l.Vocab(target, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])src_array, src_valid_len = build_array_nmt(source, src_vocab, num_steps)tgt_array, tgt_valid_len = build_array_nmt(target, tgt_vocab, num_steps)data_arrays = (src_array, src_valid_len, tgt_array, tgt_valid_len)data_iter = d2l.load_array(data_arrays, batch_size)return data_iter, src_vocab, tgt_vocab
我们可以读出数据集中的第一个小批量数据:
train_iter, src_vocab, tgt_vocab = load_data_nmt(batch_size=2, num_steps=8)
for X, X_valid_len, Y, Y_valid_len in train_iter:print('X:', X.type(torch.int32))print('X的有效长度:', X_valid_len)print('Y:', Y.type(torch.int32))print('Y的有效长度:', Y_valid_len)break
运行结果:
X: tensor([[ 17, 119, 4, 3, 1, 1, 1, 1],
[ 6, 124, 4, 3, 1, 1, 1, 1]], dtype=torch.int32)
X的有效长度: tensor([4, 4])
Y: tensor([[11, 0, 4, 3, 1, 1, 1, 1],
[ 6, 27, 7, 0, 4, 3, 1, 1]], dtype=torch.int32)
Y的有效长度: tensor([4, 6])
相关文章:
机器学习深度学习——seq2seq实现机器翻译(数据集处理)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——从编码器-解码器架构到seq2seq(机器翻译) 📚订阅专栏:机…...
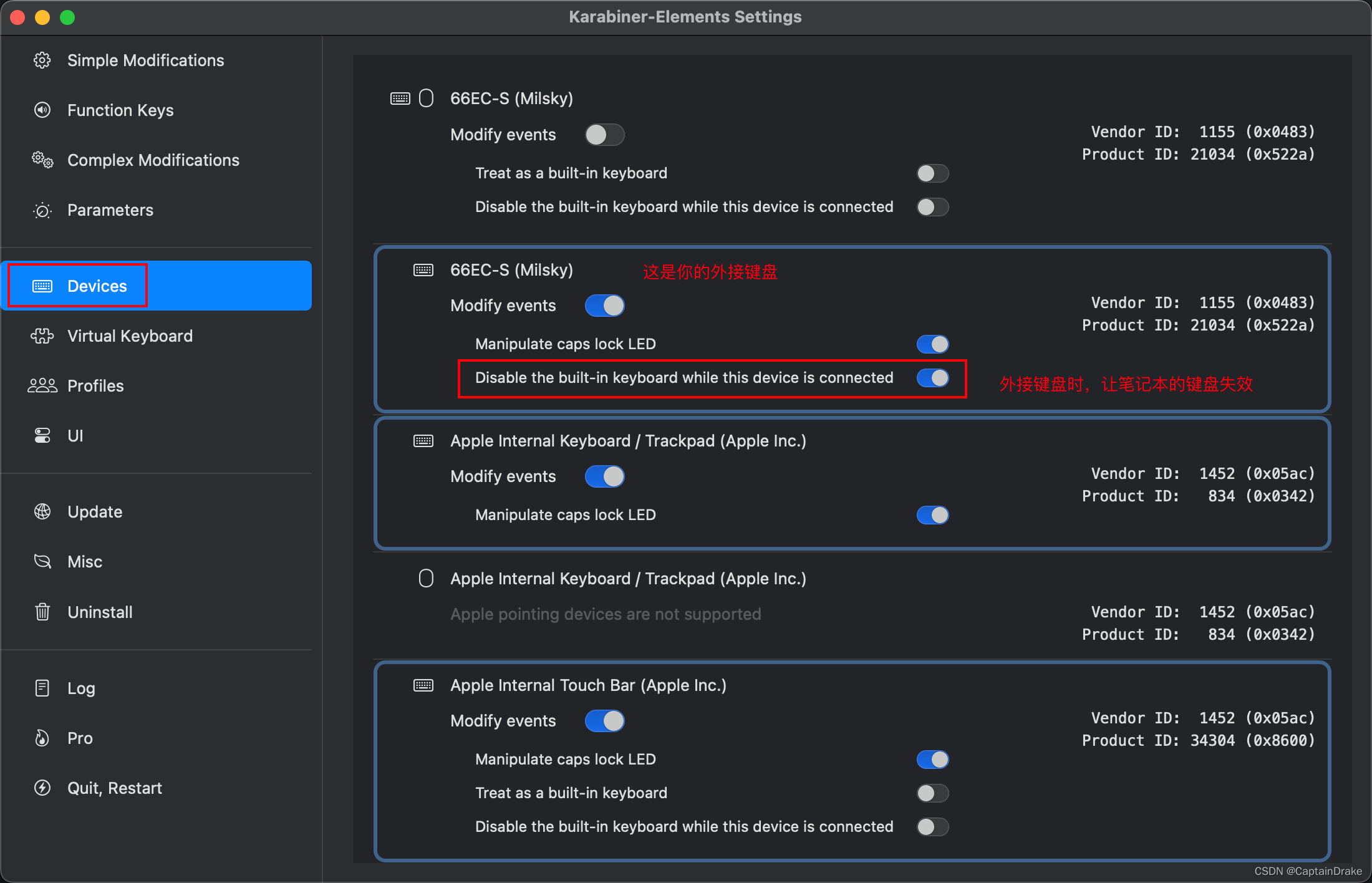
锁定Mac的内置键盘,防止外接键盘时的误触
场景:把你的外接键盘放在mac上,然后打字时,发现外接键盘误触mac键盘,导致使用体验极差 解决方案:下载Karabiner-Elements这款软件,并给它开启相关权限。 地址:https://github.com/pqrs-org/Ka…...
由于找不到d3dx9_42.dll,无法继续执行代码。重新安装程序可能会解决此问题
d3dx9_42.dll是一个动态链接库文件,它是Microsoft DirectX 9的一部分。这个文件包含了DirectX 9的一些函数和资源,用于支持计算机上运行基于DirectX 9的应用程序和游戏。它通常用于提供图形、音频和输入设备的支持,以及其他与图形和游戏相关的…...

解决Vue+Element UI使用el-dropdown(下拉菜单)国际化时菜单label信息没有刷新的情况
说明:该篇博客是博主一字一码编写的,实属不易,请尊重原创,谢谢大家! 问题描述 在默认中文时,点击布局大小下拉菜单正常显示中文,此时切换至英文时,再次点击下拉菜单,还…...

Prometheus技术文档-概念
Prometheus是一个开源的项目连接如下: Prometheus首页、文档和下载 - 服务监控系统 - OSCHINA - 中文开源技术交流社区 基本概念: Prometheus是一个开源的系统监控和告警系统,由Google的BorgMon监控系统发展而来。它主要用于监控和度量各种…...
是否选中和获取选中值方法总结)
JQuery判断radio(单选框)是否选中和获取选中值方法总结
使用checked属性判断选中、jquery获取radio单选按钮的值、获取一组radio被选中项的值、设置单选按钮被选中等,详细如下: 一、利用获取选中值判断选中 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.…...

Effective Python 读书笔记
文章目录 前言第1章:用Pythonic方式来思考 1. 用Pythonic方式来思考 2. 遵循PEP8风格3. 了解bytes, str, unicode区别4. 用辅助函数取代复杂表达式5. 了解切割序列的方法6. 单次切片操作内,不要同时指定start, end, stride 7. 用列表推导取代map, filter…...
Monge矩阵
Monge矩阵 对一个m*n的实数矩阵A,如果对所有i,j,k和l,1≤ i<k ≤ m和1≤ j<l ≤ n,有 A[i,j]A[k,l] ≤ A[i,l]A[k,j] 那么,此矩阵A为Monge矩阵。 换句话说,每当我们从矩阵中挑…...
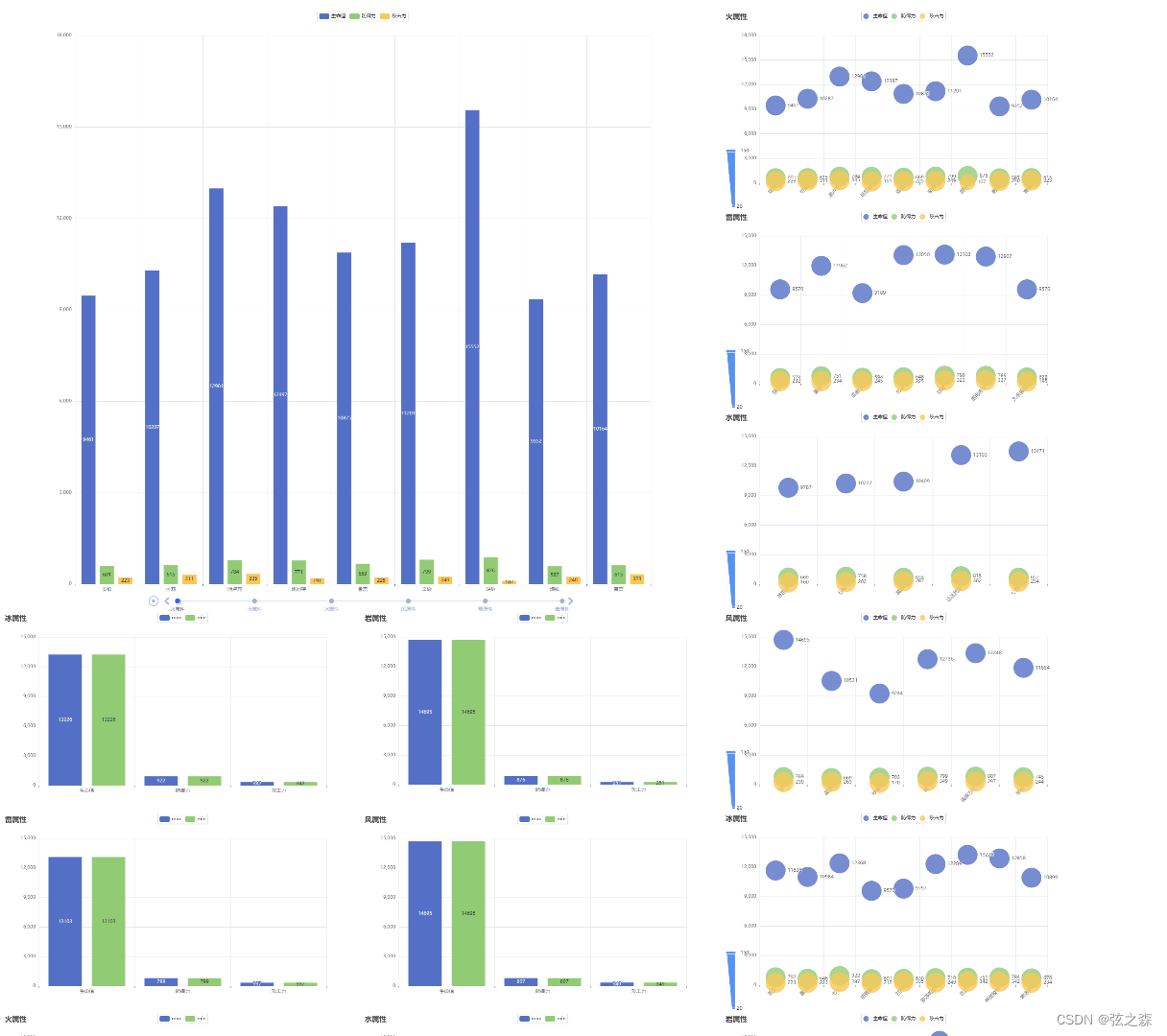
(5)所有角色数据分析页面的构建-5
所有角色数据分析页面,包括一个时间轴柱状图、六个散点图、六个柱状图(每个属性角色的生命值/防御力/攻击力的max与min的对比)。 """绘图""" from pyecharts.charts import Timeline from find_type import FindType import pandas …...
:专利撰写资料汇总)
专利进阶(三):专利撰写资料汇总
文章目录 一、前言二、资料汇总三、拓展阅读 一、前言 在专利撰写前,需要首先了解专利撰写所需遵守的基本规则。可以借助的撰写工具是什么。文献检索在哪里?注意事项是什么?本篇博文会就以上问题进行逐一解答。 专利撰写基本原则࿱…...

maven编译始终提示无效的目标发行版的解决方法
摘自个人印象笔记2021-05-07:https://app.yinxiang.com/fx/55e1d5f4-aeea-446a-a768-0f1a48195f5b(图显示不完整可查看原笔记内容)1:确保IDE中的编译版本正确 在idea中,主要看项目属性中和setting的java compiler中对应的jdk版本是否正确&…...

系统架构设计高级技能 · 软件可靠性分析与设计(三)【系统架构设计师】
系列文章目录 系统架构设计高级技能 软件架构概念、架构风格、ABSD、架构复用、DSSA(一)【系统架构设计师】 系统架构设计高级技能 系统质量属性与架构评估(二)【系统架构设计师】 系统架构设计高级技能 软件可靠性分析与设计…...
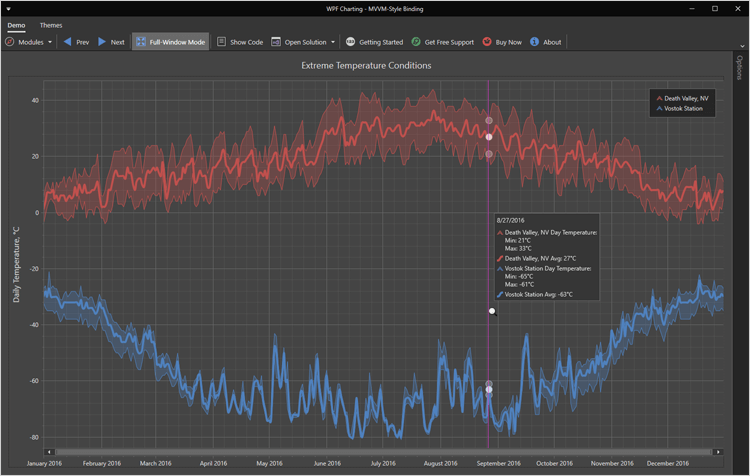
界面控件DevExpress WPF Chart组件——拥有超快的数据可视化库!
DevExpress WPF Chart组件拥有超大的可视化数据集,并提供交互式仪表板与高性能WPF图表库。DevExpress Charts提供了全面的2D / 3D图形集合,包括数十个UI定制和数据分析/数据挖掘选项。 PS:DevExpress WPF拥有120个控件和库,将帮助…...

【网络安全】等保测评安全物理环境
【网络安全】等保测评&安全物理环境 前言第1章 安全物理环境1.1 物理位置选择1.2 物理访问控制(高风险项)1.3 防盗窃1.4 防雷击1.5 防火1.6 防水防潮1.7 防静电1.8 温湿度控制1.9 电力供应1.10 电磁防护 前言 等级保护对象是由计算机或其他信息终端…...
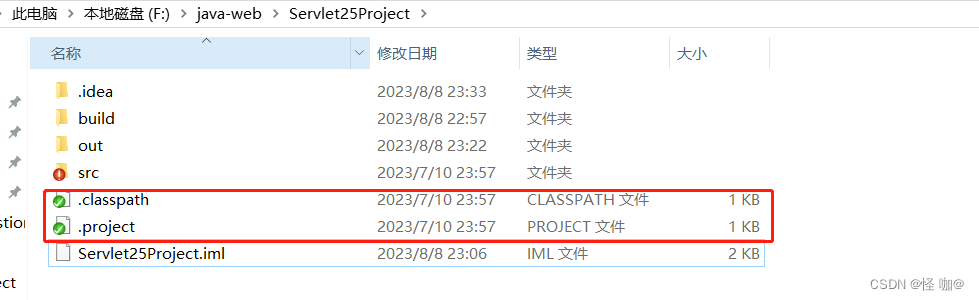
Intellij IDEA 导入 eclipse web 项目详细操作
Eclipse当中的web项目都会有这两个文件。但是idea当中应该是没有的,所以导入会出现兼容问题。但是本篇文章会教大家如何导入,并且导入过后还能使用tomcat运行。文章尽可能以图片的形式进行演示。我的idea使用的版本是2022.3.3版本。当然按正常来说版本之…...

安卓java A应用切换到B应用,来回切换不执行OnCreate
需求:安卓java如何做到A应用切换到B应用,如果B应用没启动就启动,如果B应用已经启动就仅仅切换到B应用。B应用再切换回A应用,不要重复执行OnCreate! 在 A 应用中的: 在 A 应用中,如果你希望在切换回 B 应用…...

【Linux】批量恢复文件权限
批量恢复文件权限 Linux 中,如果意外误操作将根目录目录权限批量设置,比如 chmod -R 777 / ,系统中的大部分服务以及命令将无法使用,这时候可以通过系统自带的 getfacl 命令来拷贝和还原系统权限,若是其他系统目录被误…...
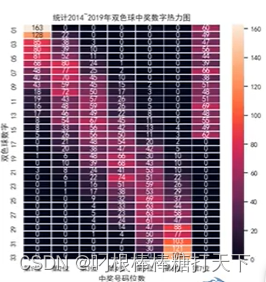
数据可视化(八)堆叠图,双y轴,热力图
1.双y轴绘制 #双Y轴可视化数据分析图表 #add_subplot() dfpd.read_excel(mrbook.xlsx) x[i for i in range(1,7)] y1df[销量] y2df[rate] #用来正常显示负号 plt.rcParams[axes.unicode_minus]False figplt.figure() ax1fig.add_subplot(1,1,1)#一行一列,第一个区域…...

前台自动化测试:基于敏捷测试驱动开发(TDD)的自动化测试原理
一、自动化测试概述 自动化测试主要应用到查询结果的自动化比较,把借助自动化把相同的数据库数据的相同查询条件查询到的结果同理想的数据进行自动化比较或者同已经保障的数据进行不同版本的自动化比较,减轻人为的重复验证测试。多用户并发操作需要自动…...

基于SLAM的规划算法仿真复现|SLAM|智能规划
图片来自百度百科 前言 那么这里博主先安利一些干货满满的专栏了! 首先是博主的高质量博客的汇总,这个专栏里面的博客,都是博主最最用心写的一部分,干货满满,希望对大家有帮助。 高质量博客汇总https://blog.csdn.n…...
了!盘点Pandas中DataFrame与字符串互转的5种方法及适用场景)
别再只用to_string()了!盘点Pandas中DataFrame与字符串互转的5种方法及适用场景
Pandas数据序列化全指南:5种DataFrame与字符串互转方法深度解析 在数据分析的日常工作中,我们经常需要在DataFrame和字符串格式之间进行转换——无论是为了临时存储、跨系统传输,还是向非技术同事展示数据。虽然df.to_string()是最为人熟知的…...

Netty如何处理闲置连接?
Netty 处理闲置连接主要依赖于 IdleStateHandler 这个处理器,它用于检测连接的空闲状态并执行相应的操作。Netty 的 IdleStateHandler 可以帮助我们检测 读空闲、写空闲 和 读写空闲 等状态的连接。具体来说,Netty 处理闲置连接的流程和机制如下…...

Xilinx UltraRAM实战:用xpm_memory_tdpram做个图像缓存,仿真综合避坑指南
Xilinx UltraRAM实战:用xpm_memory_tdpram构建高效图像缓存系统 在视频处理流水线设计中,图像缓存是实现实时处理的关键组件。Xilinx UltraScale器件提供的UltraRAM(URAM)资源以其大容量、高带宽特性,成为构建帧缓冲的…...

Qt桌面应用界面进阶:我把Ribbon菜单和AdvancedDocking拖拽停靠‘焊’在了一起
Qt桌面应用界面进阶:Ribbon菜单与AdvancedDocking无缝整合实战 在开发复杂桌面应用时,如何平衡功能密度与界面灵活性一直是UI设计的核心挑战。想象一下,你正在构建一款专业级CAD软件——用户既需要快速访问数百个工具命令,又要求自…...

小米社区自动化任务终极指南:如何用Python脚本解放你的双手
小米社区自动化任务终极指南:如何用Python脚本解放你的双手 【免费下载链接】miui-auto-tasks 一个自动化完成小米社区任务的脚本 项目地址: https://gitcode.com/gh_mirrors/mi/miui-auto-tasks 还在为每天重复的小米社区签到任务而烦恼吗?你是否…...

GetQzonehistory:一键拯救你消失的青春记忆!QQ空间历史说说终极备份指南
GetQzonehistory:一键拯救你消失的青春记忆!QQ空间历史说说终极备份指南 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否曾经在深夜翻看QQ空间,…...

终极指南:3分钟解锁鸣潮120FPS体验的免费工具箱
终极指南:3分钟解锁鸣潮120FPS体验的免费工具箱 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 鸣潮工具箱是一款专为《鸣潮》玩家设计的开源性能优化工具,能够轻松突破游戏内置的6…...

WPS-Zotero终极指南:5分钟实现WPS与Zotero无缝文献管理
WPS-Zotero终极指南:5分钟实现WPS与Zotero无缝文献管理 【免费下载链接】WPS-Zotero An add-on for WPS Writer to integrate with Zotero. 项目地址: https://gitcode.com/gh_mirrors/wp/WPS-Zotero 还在为学术论文的文献引用而烦恼吗?WPS-Zoter…...

AI Agent Harness Engineering 与大模型微调:如何让智能体更适配特定行业场景
AI Agent Harness Engineering 与大模型微调:如何让智能体更适配金融、医疗等强约束特定行业场景第一部分:引言与基础 (Introduction & Foundation) 1. 引人注目的标题 主标题:AI Agent Harness Engineering 领域微调:破解强…...

读者 30+ 问合集:从“多 Agent 调度不准“到 AI 团队协作避坑指南
上篇文章评论区积攒了几十个问题,挑了最高频的几类,一篇讲完。从概念混淆、环境配置、到多角色协作、国内模型接入,系统梳理。 一、最容易混的三个概念(搞清楚这个,80% 的问题就消解了) 很多朋友把下面三件…...