使用 Python 和 Flask 构建简单的 Restful API 第 1 部分

一、说明
我将把这个系列分成 3 或 4 篇文章。在本系列的最后,您将了解使用flask构建 restful API 是多么容易。在本文中,我们将设置环境并创建将显示“Hello World”的终结点。
我假设你的电脑上安装了python 2.7和pip。我已经在python 2.7上测试了本文中介绍的代码,尽管在python 3.4或更高版本上可能没问题。
二、 安装flask
a. Installing flask
Flask是python的微框架。微框架中的“微”意味着Flask旨在保持核心简单但可扩展(http://flask.pocoo.org/docs/0.12/foreword/#what-does-micro-mean)。您可以使用以下命令安装flask:
$ pip install Flask
b.准备您的 IDE
实际上,您可以使用所有类型的文本编辑器来构建python应用程序,但是如果您使用IDE,则会容易得多。就我个人而言,我更喜欢使用jetbrains(PyCharm: the Python IDE for Professional Developers by JetBrains)的Pycharm。
c. 在flask中创造“你好世界”
首先,您需要创建项目文件夹,在本教程中,我将它命名为“flask_tutorial”。如果您使用的是 pycharm,您可以通过从菜单中选择文件和新项目来创建项目文件夹。
之后,您可以设置项目位置和解释器。无论如何,您的计算机都可以有一些python解释器。
设置项目后,在pycharm上右键单击您的项目文件夹,然后选择新建-> Python文件并将其命名为“app.py”。
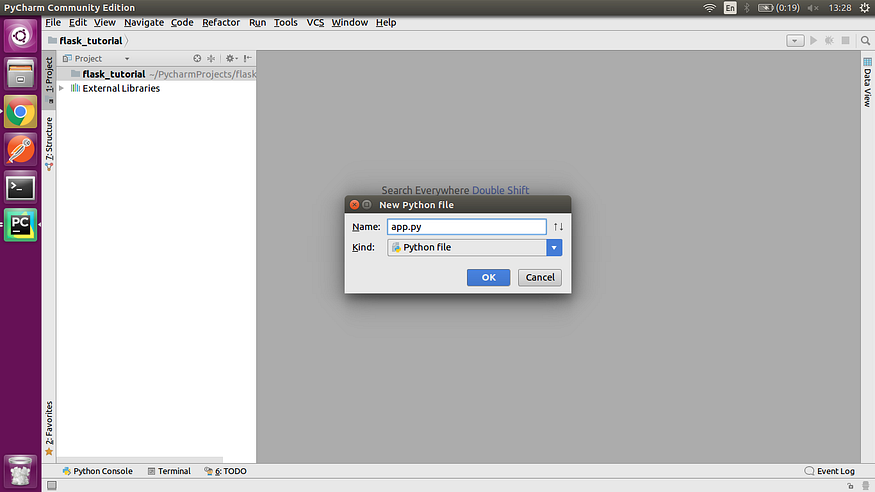
在 app.py 上写下下面的代码。
from flask import Flaskapp = Flask(__name__)@app.route("/")
def hello():return "Hello World!"if __name__ == '__main__':app.run(debug=True)从终端运行它。您可以使用命令行或从pycharm单击位于左下角的终端选项卡并在下面编写代码。
$ python app.py
打开浏览器并访问本地主机:5000。瞧,现在您有了第一个烧瓶应用:)

好的,现在让我们看一下代码。
from flask import Flask此行要求应用程序从烧瓶包导入烧瓶模块。用于创建 Web 应用程序实例的烧瓶。
app = Flask(__name__)此行创建 Web 应用程序的实例。__name__是 python 中的一个特殊变量,如果模块(python 文件)作为主程序执行,它将等于“__main__”。
@app.route("/")此行定义路由。例如,如果我们像上面一样将路由设置为“/”,如果我们访问 localhost:5000/,代码将被执行。您可以将路由设置为“/hello”,如果我们访问localhost:5000 / hello,将显示我们的“hello world”。
def hello():return "Hello World!"这条线定义了如果我们访问路由时将执行的函数。
if __name__ == '__main__':app.run(debug=True) 此行表示如果我们从 app.py 运行,您的烧瓶应用将运行。另请注意,我们将参数设置为 。这将在网页上打印出可能的 Python 错误,帮助我们跟踪错误。debug true
好的,这就是第 1 部分的全部内容,接下来我们将尝试使用 flask 在 SQLLite 上进行 CRUD 操作。
三、使用flask和SQLite构建简单的restful api
在本文中,我将向您展示如何使用flask和SQLite构建简单的restful api,这些api具有从数据库中创建,读取,更新和删除数据的功能。
3.1 安装 flask-sqlalchemy and flask-marshmallow
SQLAlchemy 是 python SQL 工具包和 ORM,可为开发人员提供 SQL 的全部功能和灵活性。其中 flask-sqlalchemy 是 flask 扩展,它添加了对 SQLAlchemy 的支持到 flask 应用程序 (Flask-SQLAlchemy — Flask-SQLAlchemy Documentation (2.x))。
另一方面,flask-marshmallow 是 Flask 扩展,用于将 Flask 与 Marshmallow(对象序列化/反序列化库)集成。在本文中,我们使用flask-marshmallow 来渲染json 响应。
您可以使用 pip 轻松安装 flask-sqlalchemy 和 flask-marshmallow,使用以下命令:
$ pip install flask_sqlalchemy
$ pip install flask_marshmallow
$ pip install marshmallow-sqlalchemy3.2.准备代码
在名为 crud.py 的文件夹上创建新的flask_tutorial python文件。在 crud.py 中记下以下代码。
from flask import Flask, request, jsonify
from flask_sqlalchemy import SQLAlchemy
from flask_marshmallow import Marshmallow
import osapp = Flask(__name__)
basedir = os.path.abspath(os.path.dirname(__file__))
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///' + os.path.join(basedir, 'crud.sqlite')
db = SQLAlchemy(app)
ma = Marshmallow(app)class User(db.Model):id = db.Column(db.Integer, primary_key=True)username = db.Column(db.String(80), unique=True)email = db.Column(db.String(120), unique=True)def __init__(self, username, email):self.username = usernameself.email = emailclass UserSchema(ma.Schema):class Meta:# Fields to exposefields = ('username', 'email')user_schema = UserSchema()
users_schema = UserSchema(many=True)# endpoint to create new user
@app.route("/user", methods=["POST"])
def add_user():username = request.json['username']email = request.json['email']new_user = User(username, email)db.session.add(new_user)db.session.commit()return jsonify(new_user)# endpoint to show all users
@app.route("/user", methods=["GET"])
def get_user():all_users = User.query.all()result = users_schema.dump(all_users)return jsonify(result.data)# endpoint to get user detail by id
@app.route("/user/<id>", methods=["GET"])
def user_detail(id):user = User.query.get(id)return user_schema.jsonify(user)# endpoint to update user
@app.route("/user/<id>", methods=["PUT"])
def user_update(id):user = User.query.get(id)username = request.json['username']email = request.json['email']user.email = emailuser.username = usernamedb.session.commit()return user_schema.jsonify(user)# endpoint to delete user
@app.route("/user/<id>", methods=["DELETE"])
def user_delete(id):user = User.query.get(id)db.session.delete(user)db.session.commit()return user_schema.jsonify(user)if __name__ == '__main__':app.run(debug=True)对于短代码,上面的代码将具有 5 个端点,具有创建新记录、从数据库中获取所有记录、按 id 获取记录详细信息、更新所选记录和删除所选记录的功能。同样在此代码中,我们为数据库定义模型。
让我们逐部分看一下代码
from flask import Flask, request, jsonify
from flask_sqlalchemy import SQLAlchemy
from flask_marshmallow import Marshmallow
import os 在这一部分,我们导入应用程序所需的所有模块。我们导入 Flask 来创建 Web 应用程序的实例,请求获取请求数据,jsonify 将 JSON 输出转换为具有应用程序/json mimetype 的对象,从 flask_sqlalchemy 到 访问数据库的 SQAlchemy,以及从flask_marshmallow到序列化对象的 Marshmallow。Response
app = Flask(__name__)
basedir = os.path.abspath(os.path.dirname(__file__))
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///' + os.path.join(basedir, 'crud.sqlite')这部分创建我们的 Web 应用程序的实例并设置我们的 SQLite uri 的路径。
db = SQLAlchemy(app)
ma = Marshmallow(app)在这一部分,我们将SQLAlchemy和棉花糖绑定到我们的烧瓶应用程序中。
class User(db.Model):id = db.Column(db.Integer, primary_key=True)username = db.Column(db.String(80), unique=True)email = db.Column(db.String(120), unique=True)def __init__(self, username, email):self.username = usernameself.email = email导入 SQLAlchemy 并将其绑定到我们的烧瓶应用程序后,我们可以声明我们的模型。在这里,我们声明名为 User 的模型,并用它的属性定义它的字段。
class UserSchema(ma.Schema):class Meta:# Fields to exposefields = ('username', 'email')user_schema = UserSchema()
users_schema = UserSchema(many=True)这部分定义了端点的响应结构。我们希望所有终结点都具有 JSON 响应。在这里,我们定义我们的 JSON 响应将有两个键(用户名和电子邮件)。此外,我们将user_schema定义为UserSchema的实例,user_schemas定义为UserSchema列表的实例。
# endpoint to create new user
@app.route("/user", methods=["POST"])
def add_user():username = request.json['username']email = request.json['email']new_user = User(username, email)db.session.add(new_user)db.session.commit()return jsonify(new_user)在这一部分,我们定义端点以创建新用户。首先,我们将路由设置为“/user”,并将HTTP方法设置为POST。设置路由和方法后,我们定义在访问此端点时将执行的函数。在此函数中,我们首先从请求数据中获取用户名和电子邮件。之后,我们使用请求数据中的数据创建新用户。最后,我们将新用户添加到数据库中,并以JSON形式显示新用户作为响应。
# endpoint to show all users
@app.route("/user", methods=["GET"])
def get_user():all_users = User.query.all()result = users_schema.dump(all_users)return jsonify(result.data)在这一部分中,我们定义端点以获取所有用户的列表,并将结果显示为JSON响应。
# endpoint to get user detail by id
@app.route("/user/<id>", methods=["GET"])
def user_detail(id):user = User.query.get(id)return user_schema.jsonify(user)就像这部分的前一部分一样,我们定义了端点来获取用户数据,但不是在这里获取所有用户,我们只是根据 id 从一个用户那里获取数据。如果仔细查看路由,可以看到此终结点的路由上有不同的模式。像“<id>”这样的父亲是参数,所以你可以用你想要的一切来改变它。这个参数应该放在函数参数上(在本例中为 def user_detail(id)),这样我们就可以在函数中获取这个参数值。
# endpoint to update user
@app.route("/user/<id>", methods=["PUT"])
def user_update(id):user = User.query.get(id)username = request.json['username']email = request.json['email']user.email = emailuser.username = usernamedb.session.commit()return user_schema.jsonify(user)在这一部分中,我们定义端点以更新用户。首先,我们调用与参数上的给定 id 相关的用户。然后,我们使用请求数据中的值更新此用户的用户名和电子邮件值。
# endpoint to delete user
@app.route("/user/<id>", methods=["DELETE"])
def user_delete(id):user = User.query.get(id)db.session.delete(user)db.session.commit()return user_schema.jsonify(user)最后,我们定义要删除用户的端点。首先,我们调用与参数上的给定 id 相关的用户。然后我们删除它。
四、 生成 SQLite 数据库
在上一步中,您已经编写了代码来处理SQLite的CRUD操作,但是如果您运行此python文件并尝试访问端点(您可以尝试访问localhost:5000 /user),您将收到类似于以下内容的错误消息
操作错误: (sqlite3.操作错误) 没有这样的表: 用户 [SQL: u'SELECT user.id AS user_id, user.username AS user_username, user.email AS user_email \nFROM user']
出现此错误消息的原因是您尝试从 SQLite 获取数据,但您还没有 SQLite 数据库。因此,在此步骤中,我们将在运行应用程序之前先生成SQLite数据库。您可以使用以下步骤在 crud.py 中基于您的模型生成 SQLite 数据库。
- 进入 Python 交互式外壳
首先,您需要在终端中使用以下命令进入python交互式shell:
$ 蟒蛇
2. 导入数据库对象并生成SQLite数据库
在 python 交互式 shell 中使用以下代码
从原油导入数据库
>>> db.create_all()>>>
crud.sqlite将在您的flask_tutorial文件夹中生成。
五、 运行flask应用
现在,在生成 sqlite 数据库后,我们就可以运行我们的烧瓶应用程序了。从终端运行以下命令以运行应用程序。
$ python crud.py
我们已经准备好尝试我们的烧瓶应用。要在我们的烧瓶应用程序中尝试端点,我们可以使用 API 开发工具,例如 curl 或 postman。就我个人而言,我喜欢 api 开发的邮递员(Postman)。在本文中,我将使用邮递员来访问端点。
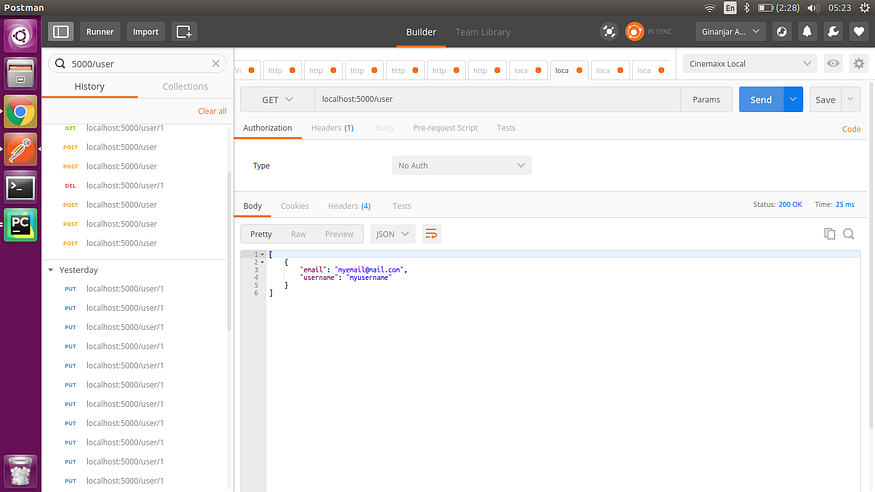
- 创建新用户
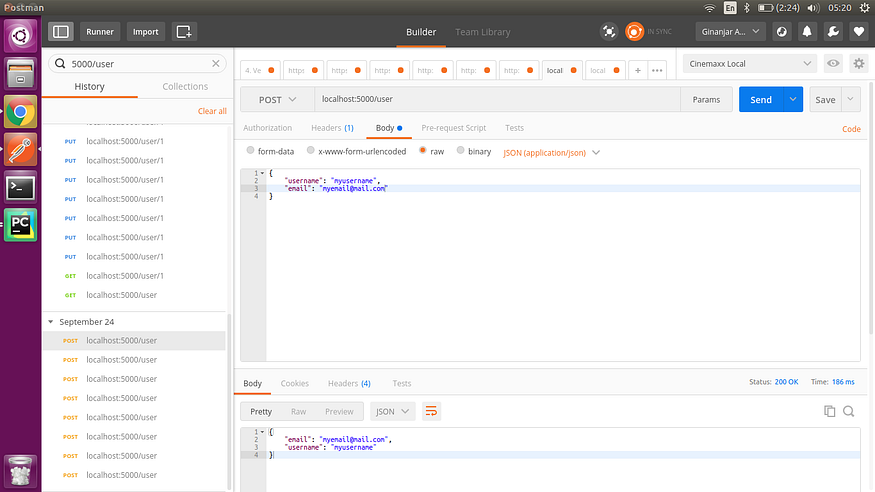
2. 获取所有用户

3. 通过 id 获取用户
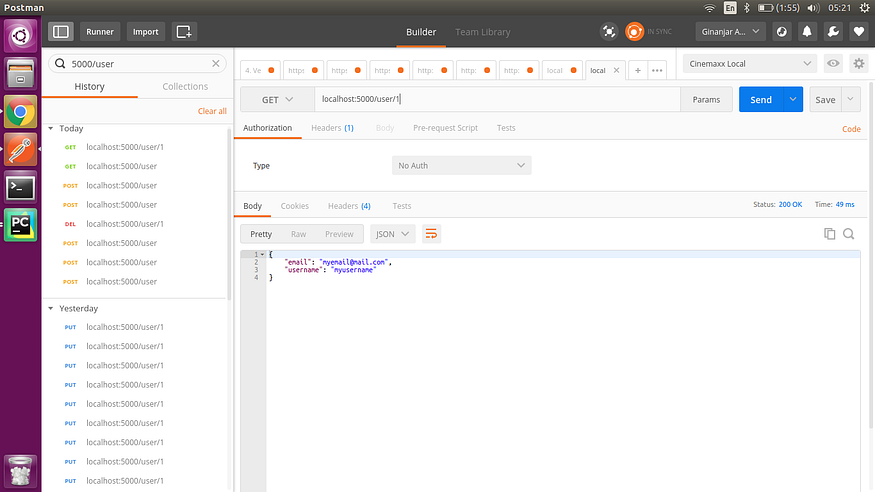
4. 更新用户
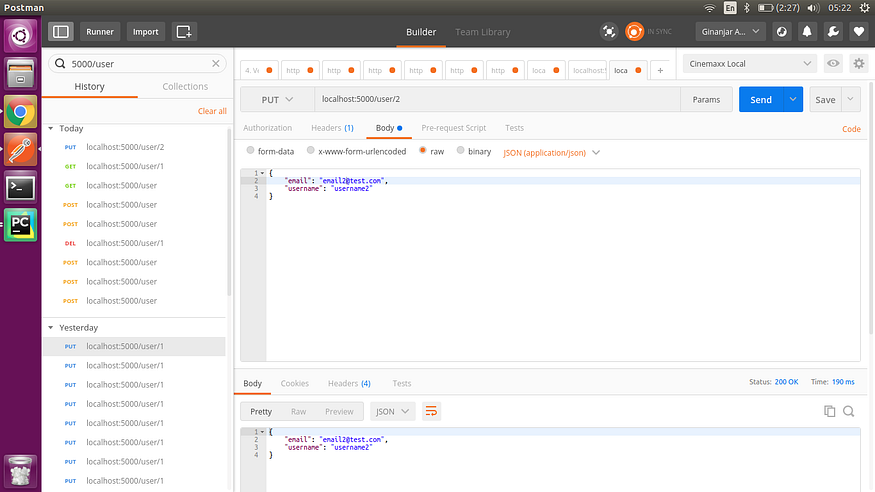

5. 删除用户

六、后记
这就是本文的全部内容。接下来,我计划使用 pytest 编写小型测试。
相关文章:
使用 Python 和 Flask 构建简单的 Restful API 第 1 部分
一、说明 我将把这个系列分成 3 或 4 篇文章。在本系列的最后,您将了解使用flask构建 restful API 是多么容易。在本文中,我们将设置环境并创建将显示“Hello World”的终结点。 我假设你的电脑上安装了python 2.7和pip。我已经在python 2.7上测试了本文…...
)
【深度学习所有损失函数】在 NumPy、TensorFlow 和 PyTorch 中实现(2/2)
一、说明 在本文中,讨论了深度学习中使用的所有常见损失函数,并在NumPy,PyTorch和TensorFlow中实现了它们。 (二-五)见 六、稀疏分类交叉熵损失 稀疏分类交叉熵损失类似于分类交叉熵损失,但在真实标签作为整数而不是独热编码提…...

Hazel 引擎学习笔记
目录 Hazel 引擎学习笔记学习方法思考引擎结构创建工程程序入口点日志系统Premake\MD没有 cpp 文件的项目会出错include 到某个库就要包含这个库的路径,注意头文件展开 事件系统 获取和利用派生类信息预编译头文件抽象窗口类和 GLFWgit submodule addpremake 脚本禁…...
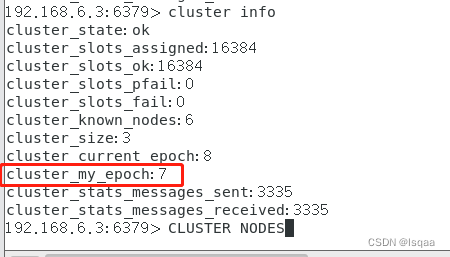
Linux系统下Redis3.2集群
本节主要学习reids主从复制的概念,作用,缺点,流程,搭建,验证,reids哨兵模式的概念,作用,缺点,结构,搭建,验证等。 文章目录 一、redis主从复制 …...
Android图形-合成与显示-SurfaceTestDemo
目录 引言: 主程序代码: 结果呈现: 小结: 引言: 通过一个最简单的测试程序直观Android系统的native层Surface的渲染显示过程。 主程序代码: #include <cutils/memory.h> #include <utils/L…...

高压放大器怎么设计(高压放大器设计方案)
高压放大器是一种用于将低电压信号转换成高电压信号的电子设备,广泛应用于通信、雷达、医疗设备等领域。在设计高压放大器时,需要考虑多种因素,如输入输出信号的特性、电路结构的选择、电源和负载匹配等。本文将介绍高压放大器的设计方法和注…...

SpringBoot yml配置注入
yaml语法学习 1、配置文件 SpringBoot使用一个全局的配置文件 , 配置文件名称是固定的 application.properties 语法结构 :keyvalue application.yml 语法结构 :key:空格 value 配置文件的作用:修改SpringBoot自动…...

中科亿海微乘法器(LPMMULT)
引言 FPGA(可编程逻辑门阵列)是一种可在硬件级别上重新配置的集成电路。它具有灵活性和可重构性,使其成为处理各种应用的理想选择,包括数字信号处理、图像处理、通信、嵌入式系统等。在FPGA中,乘法器是一种重要的硬件资…...
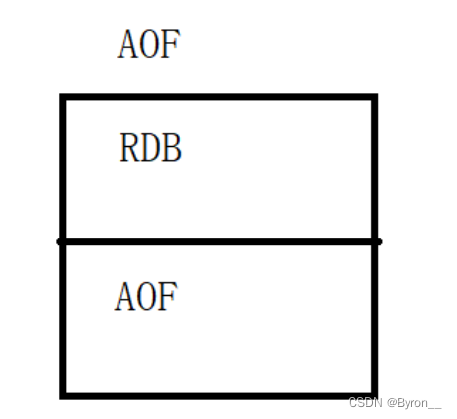
Redis_持久化(AOF、RDB)
6. Redis AOF 6.1 简介 目前,redis的持久化主要应用AOF(Append Only File)和RDF两大机制,AOF以日志的形式来记录每个写操作(增量保存),将redis执行过的所有指令全部安全记录下来(读…...
开源数据库Mysql_DBA运维实战 (部署服务篇)
前言❀ 1.数据库能做什么 2.数据库的由来 数据库的系统结构❀ 1.数据库系统DBS 2.SQL语言(结构化查询语言) 3.数据访问技术 部署Mysql❀ 1.通过rpm安装部署Mysql 2.通过源码包安装部署Mysql 前言❀ 1.数据库能做什么 a.不论是淘宝,吃鸡,爱奇艺…...
【Java学习】System.Console使用
背景 在自学《Java核心技术卷1》的过程中看到了对System.Console的介绍,编写下列测试代码, public class ConsoleTest {public static void main(String[] args) {Console cs System.console();String name cs.readLine("AccountInfo: ");…...

从零学算法154
154.已知一个长度为 n 的数组,预先按照升序排列,经由 1 到 n 次 旋转 后,得到输入数组。例如,原数组 nums [0,1,4,4,5,6,7] 在变化后可能得到: 若旋转 4 次,则可以得到 [4,5,6,7,0,1,4] 若旋转 7 次&#…...

95 | Python 设计模式 —— 策略模式
策略模式(Strategy Pattern) 引言 策略模式是一种行为型设计模式,它定义了一系列的算法,并将每个算法封装在独立的策略类中,使得这些算法可以相互替换,而不影响客户端的使用。策略模式可以让客户端根据不同的需求选择不同的算法,从而使得系统更加灵活和可扩展。 在本…...
)
【BASH】回顾与知识点梳理(十九)
【BASH】回顾与知识点梳理 十九 十九. 循环 (loop)19.1 while do done, until do done (不定循环)19.2 for...do...done (固定循环)19.3 for...do...done 的数值处理(C写法)19.4 搭配随机数与数组的实验19.5 shell script 的追踪与 debug19.6 what_to_eat-2.sh debug结果解析 该…...
Selenium之css怎么实现元素定位?
世界上最远的距离大概就是明明看到一个页面元素站在那里,但是我却定位不到!! Selenium定位元素的方法有很多种,像是通过id、name、class_name、tag_name、link_text等等,但是这些方法局限性太大, 随着自动…...
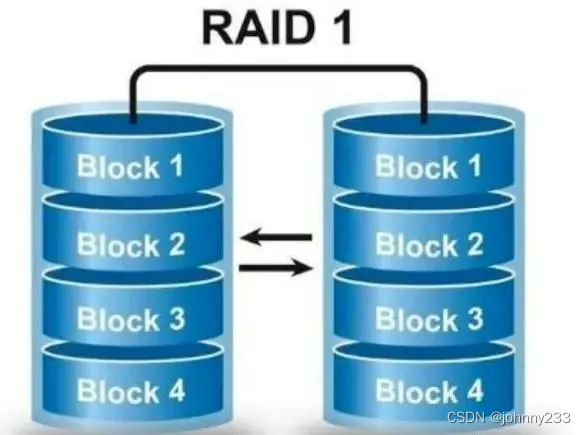
计算机基础之RAID技术
概述 RAID,Redundant Array of Independent Disks,独立磁盘冗余阵列,一种把多块独立的硬盘(物理硬盘)按不同的方式组合起来形成一个硬盘组(逻辑硬盘),从而提供比单个硬盘更高的存储…...

辽宁线上3D三维虚拟工厂生产仿真系统应用场景及优势
工厂虚拟仿真是一种基于计算机技术和虚拟现实技术的数字化解决方案,它可以通过模拟工厂中的设备、流程和操作,来为工程师和操作人员提供了一个沉浸式的虚拟环境,帮助他们更好地了解和优化工厂生产过程。 工厂VR三维可视化技术为工业生产提供了…...
、扩展默认的auth_user表)
csrf跨站请求的相关装饰器、Auth模块(模块的使用、相关方法、退出系统、修改密码功能、注册功能)、扩展默认的auth_user表
一、csrf跨站请求的相关装饰器 django.middleware.csrf.CsrfViewMiddlewareDjango中有一个中间件对csrf跨站做了验证,我只要把csrf的这个中间件打开, 那就意味着所有的方法都要被验证 在所有的视图函数中:只有几个视图函数做验证只有几个函数…...
论文阅读-Detecting Social Media Manipulation in Low-ResourceLanguages)
(WWW2023)论文阅读-Detecting Social Media Manipulation in Low-ResourceLanguages
论文链接:https://arxiv.org/pdf/2011.05367.pdf 摘要 社交媒体被故意用于恶意目的,包括政治操纵和虚假信息。大多数研究都集中在高资源语言上。然而,恶意行为者会跨国家/地区和语言共享内容,包括资源匮乏的语言。 在这里…...

centos-stream-9 centos9 配置国内yum源 阿里云源
源配置 tips: yum配置文件路径 /etc/yum.repos.d/centos.repo 1.备份源配置 [Very Important!]mv /etc/yum.repos.d/centos.repo /etc/yum.repos.d/centos.repo.backup2.Clean Cache: yum clean all3.Backup the Old CentOS-Base.repo If exist this file.cd /etc/yum.repos.…...
)
别再重装环境了!手把手教你迁移Python虚拟环境(解决Fatal error in launcher报错)
Python虚拟环境迁移实战:彻底解决路径依赖与Fatal error报错 每次接手同事的Python项目或从GitHub克隆代码时,最让人头疼的莫过于那个精心配置却无法正常激活的虚拟环境。特别是当看到Fatal error in launcher: Unable to create process using...这样的…...

nli-MiniLM2-L6-H768企业实操:用自定义标签实现多语种产品评论归类
nli-MiniLM2-L6-H768企业实操:用自定义标签实现多语种产品评论归类 1. 工具概述 cross-encoder/nli-MiniLM2-L6-H768 是一款轻量级NLI(自然语言推理)模型,特别适合企业级文本分类任务。这个工具的最大特点是实现了零样本学习能力…...
)
MySQL 5.7和8.0大不同:手把手教你用两种方法给查询结果加序号(附避坑点)
MySQL 5.7与8.0查询结果序号生成实战指南 在数据库查询结果中为每行添加序号是数据分析、报表生成和前端展示的常见需求。MySQL作为最流行的开源关系型数据库,其5.7和8.0版本在实现这一功能时存在显著差异。本文将深入探讨两种主流方法的技术实现、性能对比和实际应…...

麒麟KYLINOS软件安装全攻略:从新手到高手的五种进阶路径
1. 初识麒麟KYLINOS:从Windows/macOS迁移者的第一课 第一次打开麒麟KYLINOS的桌面环境,那种既熟悉又陌生的感觉让我想起十年前第一次用Linux的场景。作为从Windows转战过来的用户,最迫切的问题就是:软件怎么装?在Windo…...

【5G NR】从同步栅格到SSB:解码5G小区搜索的物理层基石
1. 5G小区搜索:从频域扫描到时间同步的起点 当你打开5G手机时,屏幕上瞬间跳出的信号图标背后,隐藏着一场精密的物理层对话。这个过程就像在黑夜里用手电筒寻找路标——终端设备需要快速锁定基站位置,建立稳定的通信链路。5G NR的小…...

BurpGPT部署与排错指南:解决API连接与配置问题的终极方案
BurpGPT部署与排错指南:解决API连接与配置问题的终极方案 【免费下载链接】burpgpt A Burp Suite extension that integrates OpenAIs GPT to perform an additional passive scan for discovering highly bespoke vulnerabilities and enables running traffic-bas…...

终极指南:如何在Windows 10/11上完美修复ViPER4Windows音频增强工具
终极指南:如何在Windows 10/11上完美修复ViPER4Windows音频增强工具 【免费下载链接】ViPER4Windows-Patcher Patches for fix ViPER4Windows issues on Windows-10/11. 项目地址: https://gitcode.com/gh_mirrors/vi/ViPER4Windows-Patcher 厌倦了Windows 1…...

Windows系统优化终极指南:如何用WinUtil实现一键式高效管理
Windows系统优化终极指南:如何用WinUtil实现一键式高效管理 【免费下载链接】winutil Chris Titus Techs Windows Utility - Install Programs, Tweaks, Fixes, and Updates 项目地址: https://gitcode.com/GitHub_Trending/wi/winutil 对于Windows用户而言&…...

单片机数码管显示字母b?手把手教你用Keil5和Proteus搞懂0x7C和0x83的秘密
从0x7C到0x83:单片机数码管显示字母b的完整实践指南 当你第一次在单片机代码中看到P00x7C这样的语句时,是否感到一头雾水?这个看似随意的十六进制数字,实际上隐藏着数码管显示字母"b"的全部秘密。本文将带你从零开始&am…...

如何按优先级控制 Flex 容器内子元素的截断顺序
本文详解如何通过 flex-shrink 属性实现多列 Flex 布局中按指定优先级依次截断文本内容,确保次要元素(如按钮)先收缩至最小宽度,主内容(如标签)最后才被截断,彻底解决多元素同步压缩导致的 UI 不…...