架构实践方法
一、识别复杂度
将主要的复杂度问题列出来,然后根据业务、技术、团队等综合情况进行排序,优先解决当前面临的最主要的复杂度问题。对于按照复杂度优先级解决的方式,存在一个普遍的担忧:如果按照优先级来解决复杂度,可能会出现解决了优先级排在前面的复杂度后,解决后续复杂度的方案需要将已经落地的方案推倒重来。这个担忧理论上是可能的,但现实中几乎是不可能出现的,原因在于软件系统的可塑性和易变性。对于同一个复杂度问题,软件系统的方案可以有多个,总是可以挑出综合来看性价比最高的方案。
二、设计备选方案
架构师的工作并不神秘,成熟的架构师需要对已经存在的技术非常熟悉,对已经经过验证的架构模式烂熟于心,然后根据自己对业务的理解,挑选合适的架构模式进行组合,再对组合后的方案进行修改和调整。
新技术都是在现有技术的基础上发展起来的,现有技术又来源于先前的技术。将技术进行功能性分组,可以大大简化设计过程,这是技术“模块化”的首要原因。技术的“组合”和“递归”特征,将彻底改变我们对技术本质的认识。
1.第一种常见的错误:设计最优秀的方案。
根据架构设计原则中“合适原则”和“简单原则“的要求,挑选合适自己业务、团队、技术能力的方案才是好方案;否则要么浪费大量资源开发了无用的系统(例如,之前提过的“亿级用户平台”的案例,设计了 TPS 50000 的系统,实际 TPS 只有 500),要么根本无法实现(例如,10 个人的团队要开发现在的整个淘宝系统)。
2.第二种常见的错误:只做一个方案。
这样做有很多弊端:
心里评估过于简单,可能没有想得全面,只是因为某一个缺点就把某个方案给否决了,而实际上没有哪个方案是完美的,某个地方有缺点的方案可能是综合来看最好的方案。
架构师再怎么牛,经验知识和技能也有局限,有可能某个评估的标准或者经验是不正确的,或者是老的经验不适合新的情况,甚至有的评估标准是架构师自己原来就理解错了。
单一方案设计会出现过度辩护的情况,即架构评审时,针对方案存在的问题和疑问,架构师会竭尽全力去为自己的设计进行辩护,经验不足的设计人员可能会强词夺理。
因此,架构师需要设计多个备选方案,但方案的数量可以说是无穷无尽的,架构师也不可能穷举所有方案,那合理的做法应该是什么样的呢?
备选方案的数量以 3 ~ 5 个为最佳。少于 3 个方案可能是因为思维狭隘,考虑不周全;多于 5 个则需要耗费大量的精力和时间,并且方案之间的差别可能不明显。
备选方案的差异要比较明显。例如,主备方案和集群方案差异就很明显,或者同样是主备方案,用 ZooKeeper 做主备决策和用 Keepalived 做主备决策的差异也很明显。但是都用 ZooKeeper 做主备决策,一个检测周期是 1 分钟,一个检测周期是 5 分钟,这就不是架构上的差异,而是细节上的差异了,不适合做成两个方案。
备选方案的技术不要只局限于已经熟悉的技术。设计架构时,架构师需要将视野放宽,考虑更多可能性。很多架构师或者设计师积累了一些成功的经验,出于快速完成任务和降低风险的目的,可能自觉或者不自觉地倾向于使用自己已经熟悉的技术,对于新的技术有一种不放心的感觉。就像那句俗语说的:“如果你手里有一把锤子,所有的问题在你看来都是钉子”。例如,架构师对 MySQL 很熟悉,因此不管什么存储都基于 MySQL 去设计方案,系统性能不够了,首先考虑的就是 MySQL 分库分表,而事实上也许引入一个 Memcache 缓存就能够解决问题。
3.第三种常见的错误:备选方案过于详细。
有的架构师或者设计师在写备选方案时,错误地将备选方案等同于最终的方案,每个备选方案都写得很细。这样做的弊端显而易见:
耗费了大量的时间和精力。
将注意力集中到细节中,忽略了整体的技术设计,导致备选方案数量不够或者差异不大。
评审的时候其他人会被很多细节给绕进去,评审效果很差。例如,评审的时候针对某个定时器应该是 1 分钟还是 30 秒,争论得不可开交。
正确的做法是备选阶段关注的是技术选型,而不是技术细节,技术选型的差异要比较明显。例如,采用 ZooKeeper 和 Keepalived 两种不同的技术来实现主备,差异就很大;而同样都采用 ZooKeeper,一个方案的节点设计是 /service/node/master,另一个方案的节点设计是 /company/service/master,这两个方案并无明显差异,无须在备选方案设计阶段作为两个不同的备选方案,至于节点路径究竟如何设计,只要在最终的方案中挑选一个进行细化即可。
三、评估和选择备选方案
上在完成备选方案设计后,如何挑选出最终的方案也是一个很大的挑战,主要原因有:
每个方案都是可行的,如果方案不可行就根本不应该作为备选方案。
没有哪个方案是完美的。例如,A 方案有性能的缺点,B 方案有成本的缺点,C 方案有新技术不成熟的风险。
评价标准主观性比较强,比如设计师说 A 方案比 B 方案复杂,但另外一个设计师可能会认为差不多,因为比较难将“复杂”一词进行量化
正因为选择备选方案存在这些困难,所以实践中很多设计师或者架构师就采取了下面几种错误的指导思想:
最简派:设计师挑选一个看起来最简单的方案。例如,我们要做全文搜索功能,方案 1 基于 MySQL,方案 2 基于 Elasticsearch。MySQL 的查询功能比较简单,而 Elasticsearch 的倒排索引设计要复杂得多,写入数据到 Elasticsearch,要设计 Elasticsearch 的索引,要设计 Elasticsearch 的分布式……全套下来复杂度很高,所以干脆就挑选 MySQL 来做吧。
最牛派:最牛派的做法和最简派正好相反,设计师会倾向于挑选技术上看起来最牛的方案。例如,性能最高的、可用性最好的、功能最强大的,或者淘宝用的、微信开源的、Google 出品的等。
最熟派:设计师基于自己的过往经验,挑选自己最熟悉的方案。我以编程语言为例,假如设计师曾经是一个 C++ 经验丰富的开发人员,现在要设计一个运维管理系统,由于对 Python 或者 Ruby on Rails 不熟悉,因此继续选择 C++ 来做运维管理系统。
领导派:领导派就更加聪明了,列出备选方案,设计师自己拿捏不定,然后就让领导来定夺,反正最后方案选的对那是领导厉害,方案选的不对怎么办?那也是领导“背锅”。
正确的做法是:列出我们需要关注的质量属性点,然后分别从这些质量属性的维度去评估每个方案,再综合挑选适合当时情况的最优方案。
常见的方案质量属性点有:性能、可用性、硬件成本、项目投入、复杂度、安全性、可扩展性等。在评估这些质量属性时,需要遵循架构设计原则 1“合适原则”和原则 2“简单原则”,避免贪大求全,基本上某个质量属性能够满足一定时期内业务发展就可以了。
按优先级选择,即架构师综合当前的业务发展情况、团队人员规模和技能、业务发展预测等因素,将质量属性按照优先级排序,首先挑选满足第一优先级的,如果方案都满足,那就再看第二优先级……以此类推。那会不会出现两个或者多个方案,每个质量属性的优缺点都一样的情况呢?理论上是可能的,但实际上是不可能的。在做备选方案设计时,不同的备选方案之间的差异要比较明显,差异明显的备选方案不可能所有的优缺点都是一样的。如:
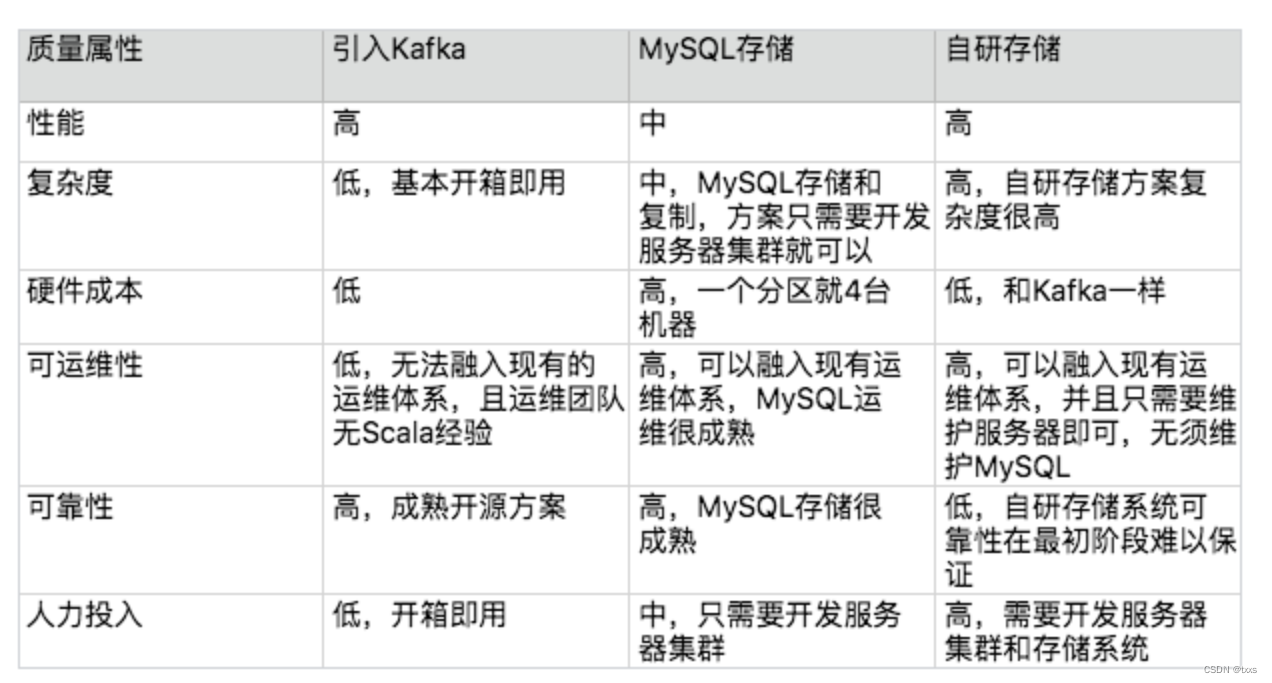 架构师经过思考后,给出了最终选择备选方案 2,原因有:
架构师经过思考后,给出了最终选择备选方案 2,原因有:
排除备选方案 1 的主要原因是可运维性,因为再成熟的系统,上线后都可能出问题,如果出问题无法快速解决,则无法满足业务的需求;并且 Kafka 的主要设计目标是高性能日志传输,而我们的消息队列设计的主要目标是业务消息的可靠传输。
排除备选方案 3 的主要原因是复杂度,目前团队技术实力和人员规模(总共 6 人,还有其他中间件系统需要开发和维护)无法支撑自研存储系统(参考架构设计原则 2:简单原则)。
备选方案 2 的优点就是复杂度不高,也可以很好地融入现有运维体系,可靠性也有保障。
针对备选方案 2 的缺点,架构师解释是:
备选方案 2 的第一个缺点是性能,业务目前需要的性能并不是非常高,方案 2 能够满足,即使后面性能需求增加,方案 2 的数据分组方案也能够平行扩展进行支撑(参考架构设计原则 3:演化原则)。
备选方案 2 的第二个缺点是成本,一个分组就需要 4 台机器,支撑目前的业务需求可能需要 12 台服务器,但实际上备机(包括服务器和数据库)主要用作备份,可以和其他系统并行部署在同一台机器上。
备选方案 2 的第三个缺点是技术上看起来并不很优越,但我们的设计目的不是为了证明自己(参考架构设计原则 1:合适原则),而是更快更好地满足业务需求。
四、详细方案设计
详细设计方案阶段可能遇到的一种极端情况就是在详细设计阶段发现备选方案不可行,一般情况下主要的原因是备选方案设计时遗漏了某个关键技术点或者关键的质量属性。这种情况可以通过下面方式有效地避免:
架构师不但要进行备选方案设计和选型,还需要对备选方案的关键细节有较深入的理解。例如,架构师选择了 Elasticsearch 作为全文搜索解决方案,前提必须是架构师自己对 Elasticsearch 的设计原理有深入的理解,比如索引、副本、集群等技术点;而不能道听途说 Elasticsearch 很牛,所以选择它,更不能成为把“细节我们不讨论”这句话挂在嘴边的“PPT 架构师”。
通过分步骤、分阶段、分系统等方式,尽量降低方案复杂度,方案本身的复杂度越高,某个细节推翻整个方案的可能性就越高,适当降低复杂性,可以减少这种风险。
如果方案本身就很复杂,那就采取设计团队的方式来进行设计,博采众长,汇集大家的智慧和经验,防止只有 1~2 个架构师可能出现的思维盲点或者经验盲区。
相关文章:
架构实践方法
一、识别复杂度 将主要的复杂度问题列出来,然后根据业务、技术、团队等综合情况进行排序,优先解决当前面临的最主要的复杂度问题。对于按照复杂度优先级解决的方式,存在一个普遍的担忧:如果按照优先级来解决复杂度,可…...
点淘的MCN机构申请详细入驻指南!
消费趋势的变化,来自消费人群的变化。 后疫情时代,经济复苏的反弹力度不足,人们开始怀疑我们正从前几年的消费升级,跌入消费降级的时代,但这并不能准确概括消费市场的变化。 仔细翻看各大奢侈品集团的财报࿰…...
事务和事务的隔离级别
1.4.事务和事务的隔离级别 1.4.1.为什么需要事务 事务是数据库管理系统(DBMS)执行过程中的一个逻辑单位(不可再进行分割),由一个有限的数据库操作序列构成(多个DML语句,select语句不包含事务&…...
)
每日一题 34在排序数组中查找元素的第一个和最后一个位置(二分查找)
题目 给你一个按照非递减顺序排列的整数数组 nums,和一个目标值 target。请你找出给定目标值在数组中的开始位置和结束位置。 如果数组中不存在目标值 target,返回 [-1, -1]。 你必须设计并实现时间复杂度为 O(log n) 的算法解决此问题。 示例 1&…...
Spring Boot Admin 环境搭建与基本使用
Spring Boot Admin 环境搭建与基本使用 一、Spring Boot Admin是什么二、提供了那些功能三、 使用Spring Boot Admin3.1搭建Spring Boot Admin服务pom文件yml配置文件启动类启动admin服务效果 3.2 common-apipom文件feignhystrix 3.3服务消费者pom文件yml配置文件启动类control…...
JVM之内存模型
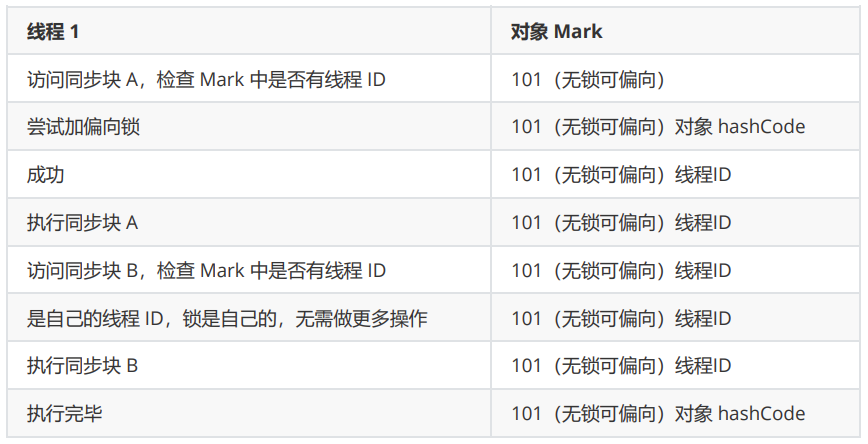
1. Java内存模型 很多人将Java 内存结构与java 内存模型傻傻分不清,java 内存模型是 Java Memory Model(JMM)的意思。 简单的说,JMM 定义了一套在多线程读写共享数据时(成员变量、数组)时,对数据…...

音视频 vs2017配置FFmpeg
vs2017 ffmpeg4.2.1 一、首先我把FFmpeg整理了一下,放在C盘 二、新建空项目 三、添加main.cpp,将bin文件夹下dll文件拷贝到cpp目录下 #include<stdio.h> #include<iostream>extern "C" { #include "libavcodec/avcodec.h&…...

【项目管理】PMP备考宝典-第二章《环境》
第一节:概述 1.项目所处的组织环境 (1)事业环境因素(EEFs) 组织内部的事业环境因素: 企业都会有愿景、使命、价值观,这些决定了企业的发展方向。不忘初心,坚定地走自己的路&#…...
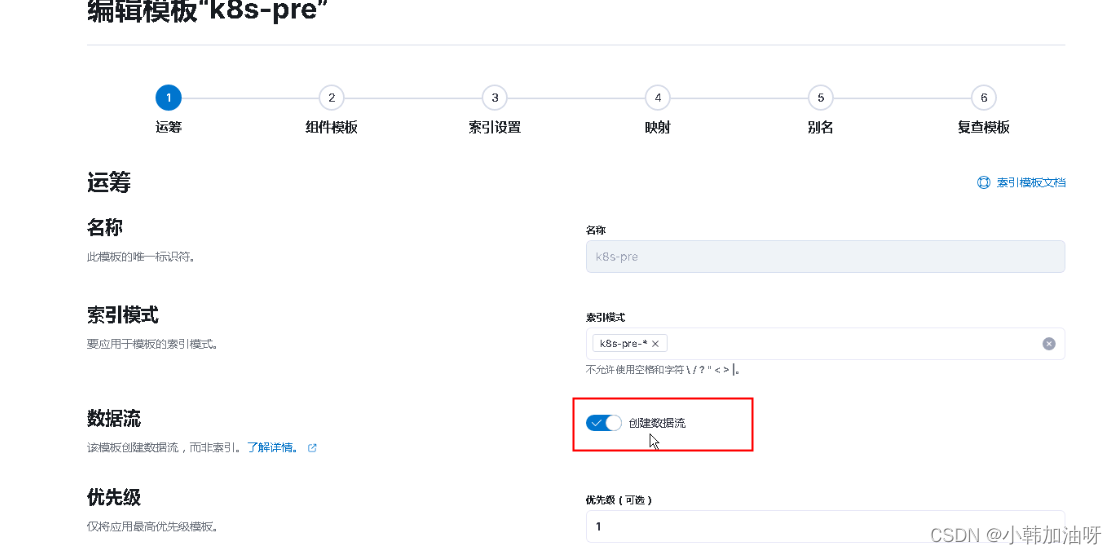
ELK 将数据流转换回常规索引
ELK 将数据流转换回常规索引 现象:创建索引模板是打开了数据流,导致不能创建常规索引,并且手动修改、删除索引模板失败 "reason" : "composable template [logs_template] with index patterns [new-pattern*], priority [2…...
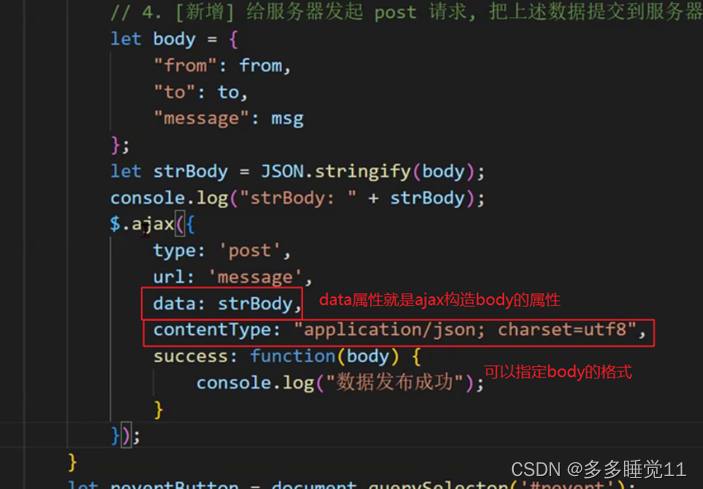
jackson库收发json格式数据和ajax发送json格式的数据
一、jackson库收发json格式数据 jackson库是maven仓库中用来实现组织json数据功能的库。 json格式 json格式一个组织数据的字符文本格式,它用键值对的方式存贮数据,json数据都是有一对对键值对组成的,键只能是字符串,用双引号包…...

ubuntu安装和卸载CLion
安装 在https://www.jetbrains.com/clion/download/#sectionlinux下载相应版本的安装包,解压之后,找到解压文件夹中的bin文件夹运行./clion.sh 卸载 使用sudo rm -rf删除以下内容;并把刚刚解压的文件删掉 ~/.config/JetBrains ~/.local/s…...
Petrel解释二维浅地层数据
Petrel是斯伦贝谢开发的一款地质解释和建模软件,有点像地理信息系统的ArcGIS,主要用于数据分析和展示。它不是用来处理原始数据的,而是集成各种处理后的结果数据进行特征分析和目标拾取。当然,它也能读取原始数据,比如…...
分布式任务调度平台XXL-JOB使用
说明:分布式任务调度平台XXL-JOB,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用(官方语)。 本文介绍使用XXL-JOB实现定时执行代码,可用于项目中…...

自考本科汉语言文学专业真的太难了吗
自考本科汉语言文学专业的难度和就业前景都需要综合考虑。目前,自考汉语言文学专业通过率是比较高的,与其他专业比较,难度会低一些,主要考验考生的记忆能力。 自学考试汉语言文学难度怎么样 本科自学考试汉语言文学难度还是比较简…...

STM32CubeMX之freeRTOS信号量
队列可以传输数据,任务之间和任务和中断之间,消息队列用来传数据,占用时间也长 但哦我们有时候只需要传递状态,只需要一个数值表示 如果我们屏幕按固定刷新,就会很消耗资源,如果我们数据变化了࿰…...

react-spring,一个react的动画库的使用
介绍 React Spring 是一个 spring physics based animation library 用于 React。它可以轻松地在 React 中实现弹性、渐变等动画效果。 使用 安装依赖: 使用npm: npm install react-spring 使用yarn: yarn add react-spring 导入和使用&a…...

Python中的lambda函数
前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! Python中的lambda函数 在Python中,我们使用lambda关键字来声明一个匿名函数, 这就是为什么我们将它们称为“lambda函数”。 匿名函数是指没有声明函数名称的函数。 尽管它们在语法上看起来不同&a…...

Ajax入门
文章目录 axios体验axios-查询参数常用请求方法数据提交 axios错误处理 axios体验 引入axios库 使用axios语法 axios({url: 目标资源地址 }).then((result)>{// 对服务器返回的数据做后续处理 })完整实例 <!DOCTYPE html> <html lang"en"><head&g…...
MapReduce基础原理、MR与MPP区别
MapReduce概述 MapReduce(MR)本质上是一种用于数据处理的编程模型;MapReduce用于海量数据的计算,HDFS用于海量数据的存储(Hadoop Distributed File System,Hadoop分布式文件系统)。Hadoop MapR…...

位运算符让人反胃
A60 B13 二进制下 A00111100 B00001101 &(同1为1) A00111100 & B00001101 X00001100 X12 |(有1为1) A00111100 | B00001101 X00111101 X61 ^(不同为1) A00111100 ^ B00001101 X00110001 X49 ~&…...

Kimi K2.6实战评测:如何让AI连续工作13小时?
13小时不间断编码,4000行代码修改,性能提升185%。这不是科幻,是今天的AI。01 4月20日深夜,月之暗面悄悄发布了Kimi K2.6,并宣布同步开源。 开源地址:https://huggingface.co/moonshotai/Kimi-K2.6ÿ…...

Phi-mini-MoE-instruct真实生成效果:MATH竞赛题分步推导+LaTeX公式渲染效果展示
Phi-mini-MoE-instruct真实生成效果:MATH竞赛题分步推导LaTeX公式渲染效果展示 1. 模型能力概览 Phi-mini-MoE-instruct是一款轻量级混合专家(MoE)指令型小语言模型,在多个基准测试中展现出卓越性能: 代码能力&…...
)
葡萄园小型开沟机的设计(说明书+14张CAD图纸+开题报告+任务书……)
葡萄园小型开沟机的设计,聚焦于解决传统人工开沟效率低、深度不均等问题,通过机械结构优化与动力匹配,实现葡萄园土壤管理的精准化与高效化。其核心作用体现在三方面:一是提升作业效率,机械开沟速度较人工提升数倍&…...

计算化学效率翻倍:Multiwfn结合ORCA进行高通量筛选的完整工作流指南
计算化学效率翻倍:Multiwfn结合ORCA进行高通量筛选的完整工作流指南 在材料科学和药物研发领域,高通量计算筛选已成为加速发现过程的关键技术。传统的手动处理分子结构、逐个生成输入文件的方式,在面对数百甚至数千个候选分子时显得力不从心。…...

Phi-3.5-mini-instruct新手入门:3步完成模型部署与简单对话测试
Phi-3.5-mini-instruct新手入门:3步完成模型部署与简单对话测试 1. 环境准备与快速部署 Phi-3.5-mini-instruct是微软推出的轻量级开源指令微调大模型,在长上下文代码理解(RepoQA)、多语言MMLU等基准上表现优异。它特别适合本地…...

SVG核心属性解析与动态交互实现
1. SVG核心属性深度解析 SVG作为矢量图形的标准格式,其强大之处在于丰富的属性系统。这些属性不仅能定义图形外观,更能通过动态修改实现复杂的交互效果。我们先从几个关键属性入手,看看它们如何成为动态交互的基石。 viewBox属性堪称SVG的&qu…...

209K轻量级文件加密神器OEMexe:零安装跨格式全支持的技术解析
在信息安全日益受到重视的当下,文件加密已成为个人用户与企业用户的刚性需求。 市面上多数加密软件存在体积庞大、安装繁琐、依赖环境复杂等问题,严重影响了用户的使用体验。 OEMexe的出现为这一痛点提供了优雅的解决方案。 该软件以极致轻量化为核心…...

如何轻松实现跨平台词库迁移:深蓝词库转换工具完整指南
如何轻松实现跨平台词库迁移:深蓝词库转换工具完整指南 【免费下载链接】imewlconverter ”深蓝词库转换“ 一款开源免费的输入法词库转换程序 项目地址: https://gitcode.com/gh_mirrors/im/imewlconverter 你是否曾因更换输入法而丢失多年积累的词库&#…...

VR党建蛋椅|以沉浸式体验推动党建学习方式创新
在信息化、数字化不断发展的背景下,党建学习方式也在持续升级。传统的集中学习、展板阅读虽然依然发挥着重要作用,但在互动性、沉浸感和吸引力方面存在一定局限。VR党建蛋椅正是在这一背景下诞生的一种创新型党建学习设备,通过虚拟现实技术与…...

5分钟掌握KeymouseGo:零编程实现鼠标键盘自动化操作
5分钟掌握KeymouseGo:零编程实现鼠标键盘自动化操作 【免费下载链接】KeymouseGo 类似按键精灵的鼠标键盘录制和自动化操作 模拟点击和键入 | automate mouse clicks and keyboard input 项目地址: https://gitcode.com/gh_mirrors/ke/KeymouseGo 还在为每天…...