栈和队列详解
目录
栈
栈的概念及结构:
栈的实现:
代码实现:
Stack.h
stack.c
队列:
概念及结构:
队列的实现:
代码实现:
Queue.h
Queue.c
拓展:
循环队列(LeetCode题目链接):
-
栈
栈的概念及结构:
栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。
进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。
栈中的数据元素遵守“先进后出/后进先出”的原则。
压栈:栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。
出栈:栈的删除操作叫做出栈。出数据也在栈顶。
“先进后出/后进先出”示意图: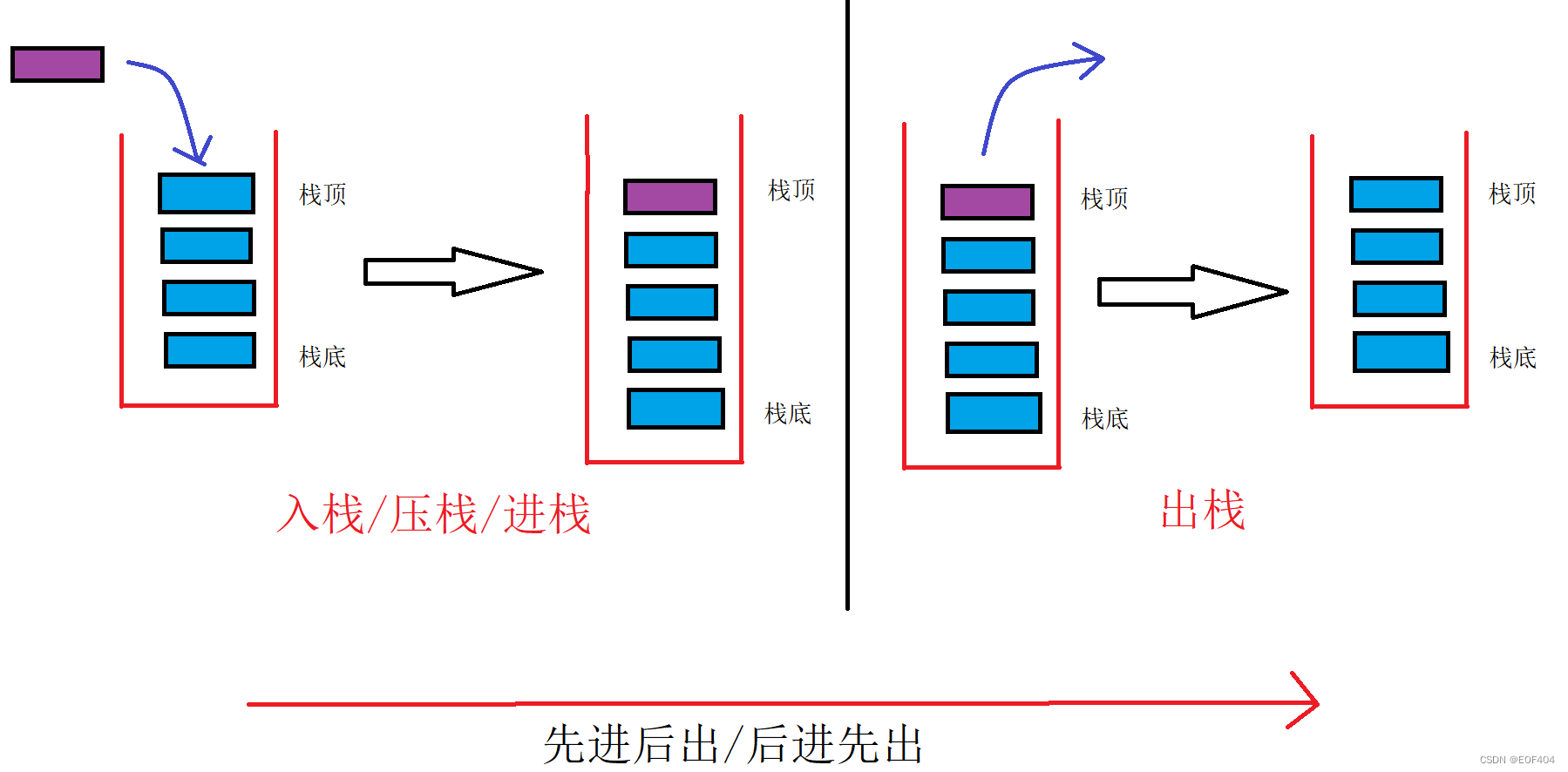
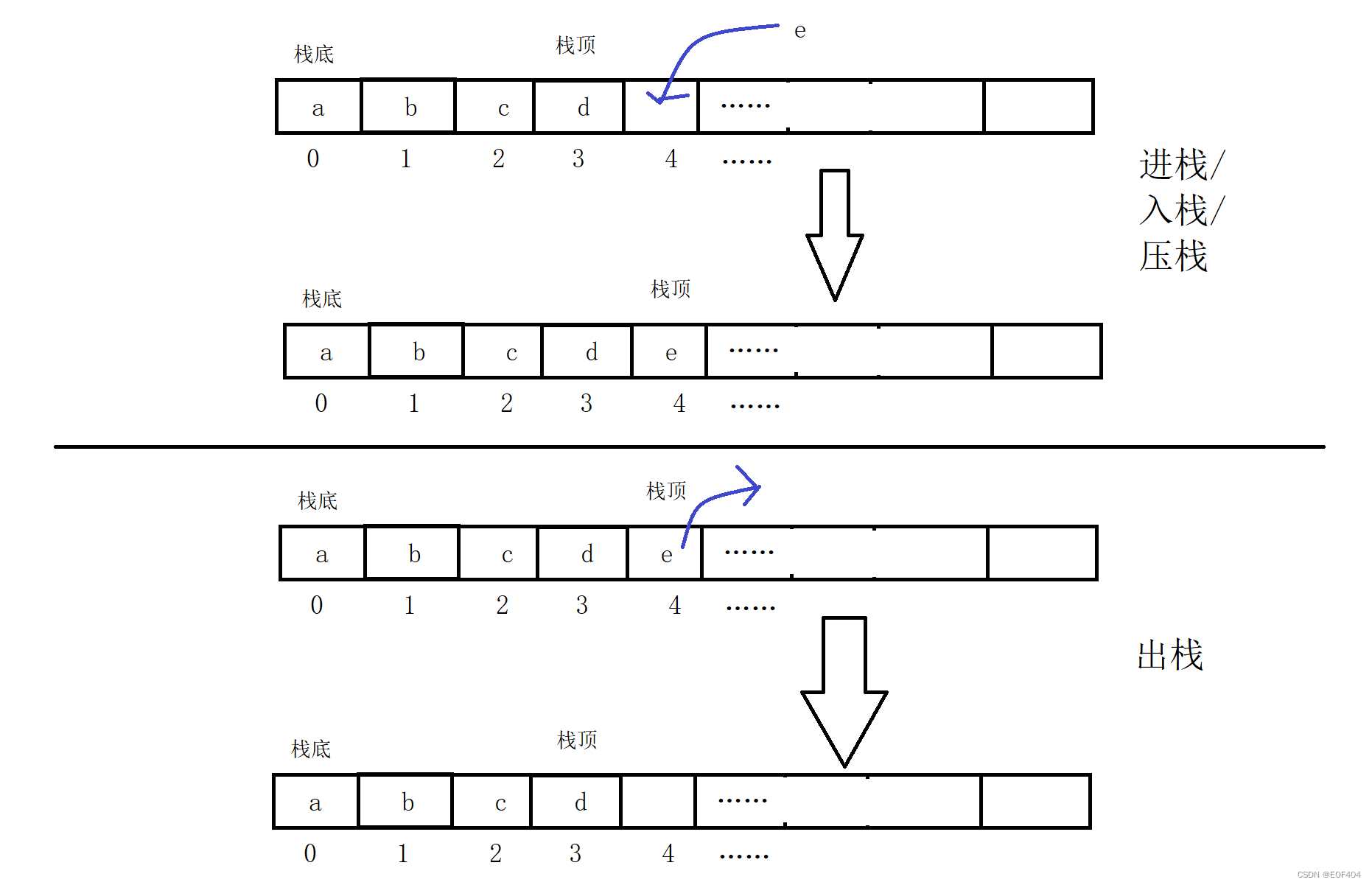
栈的实现:
一般可以使用数组或者链表实现,相对而言数组的结构实现更优一些。因为数组在尾上插入数据的代价比较小。
代码实现:
Stack.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>typedef int STDataType;
typedef struct Stack
{STDataType* a;int top;//栈顶int capacity;//容量
}ST;
//初始化
void STInit(ST* ps);
//销毁
void STDestroy(ST* ps);
//入栈
void STPush(ST* ps, STDataType x);
//出栈
void STPop(ST* ps);
//取栈顶元素
STDataType STTop(ST* ps);
//数据个数
int STSize(ST* ps);
//判空
bool STEmpty(ST* ps);stack.c
#include"Stack.h"
//初始化
void STInit(ST* ps)
{assert(ps);ps->a = NULL;ps->capacity = 0;ps->top = 0;
}
//销毁
void STDestroy(ST* ps)
{free(ps->a);ps->a = NULL;ps->capacity = 0;ps->top = 0;
}
//入栈
void STPush(ST* ps, STDataType x)
{assert(ps);if (ps->capacity == ps->top){int newcapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;STDataType* p = (STDataType*)realloc(ps->a, sizeof(STDataType) * newcapacity);ps->a = p;ps->capacity = newcapacity;}ps->a[ps->top] = x;ps->top++;
}//出栈
void STPop(ST* ps)
{assert(ps);assert(ps->a);assert(!STEmpty(ps));ps->top--;
}
//取栈顶元素
STDataType STTop(ST* ps)
{assert(ps);assert(ps->a);assert(!STEmpty(ps));return ps->a[ps->top - 1];
}
//数据个数
int STSize(ST* ps)
{assert(ps);assert(ps->a);return ps->top;
}
//判空
bool STEmpty(ST* ps)
{assert(ps);return ps->top == 0;
}测试代码:
#include"Stack.h"
int main()
{ST p1;STInit(&p1);int i = 0;//入栈for (i = 1; i <= 10; i++){STPush(&p1, i);}printf("栈中数据数量:%d\n", STSize(&p1));//出栈for (i = 0; i < 5; i++){STDataType a = STTop(&p1);printf("%d ", a);STPop(&p1);}printf("\n");printf("栈顶元素:%d\n", STTop(&p1));printf("栈中数据数量:%d\n", STSize(&p1));STDestroy(&p1);return 0;
}运行结果:

队列:
概念及结构:
队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有“先 进先出/后进后出”的特点。
入队列:进行插入操作的一端称为队尾。
出队列:进行删除操作的一端称为队头。
“先进先出/后进后出”示意图:
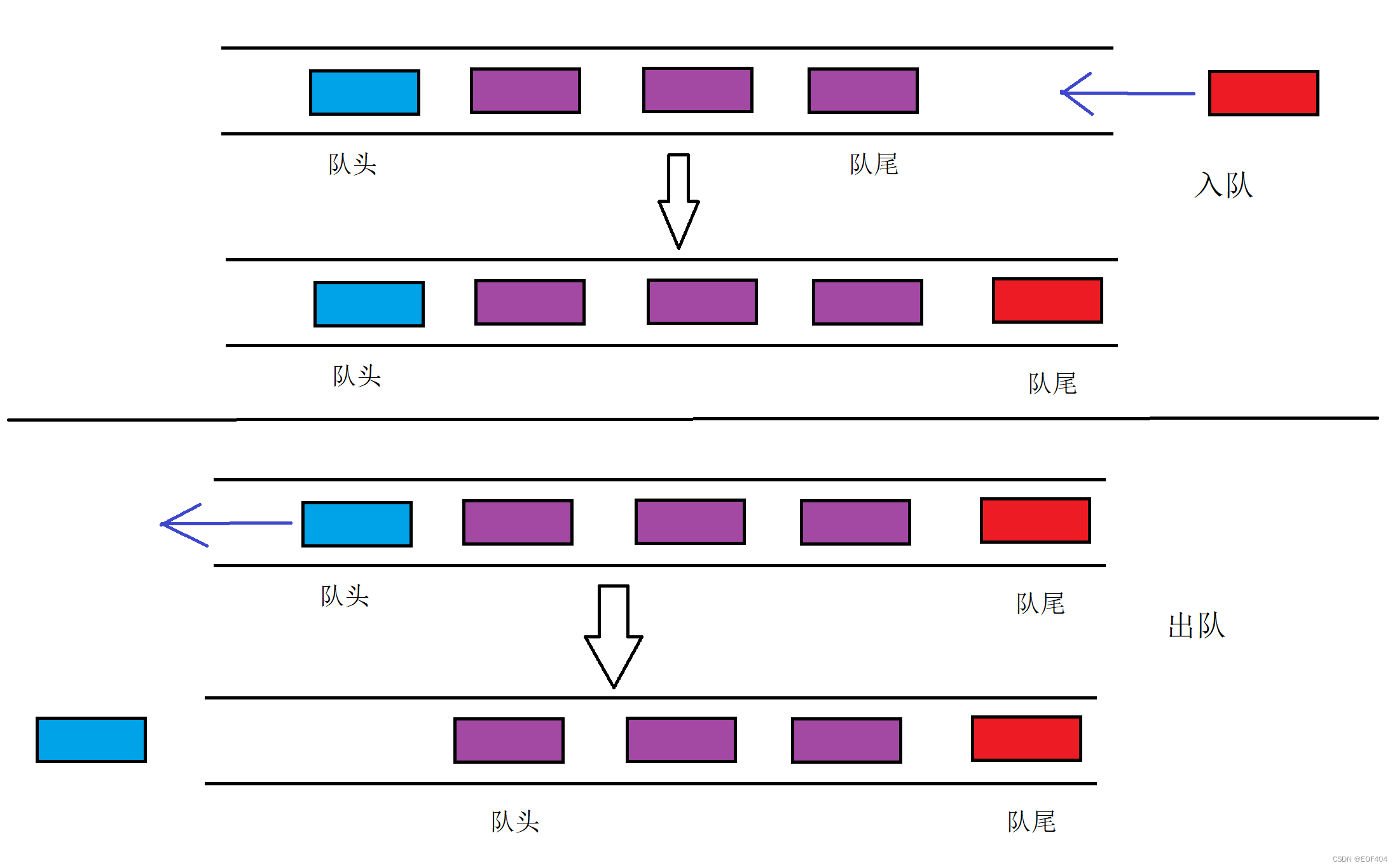
队列的实现:
队列也可以数组和链表的结构实现,使用链表的结构实现更优一些,因为如果使用数组的结构在出队时的效率会比较低。
代码实现:
Queue.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>typedef int QDataType;
typedef struct QueueNode
{struct QueueNode* next;QDataType data;
}QNode;typedef struct Queue
{QNode* head;QNode* tail;int size;
}Que;
//初始化
void QueueInit(Que* pq);
//销毁
void QueueDestroy(Que* pq);
//入队
void QueuePush(Que* pq, QDataType x);
//出队
void QueuePop(Que* pq);
//取队头
QDataType QueueFront(Que* pq);
//取队尾
QDataType QueueBack(Que* pq);
//判空
bool QueueEmpty(Que* pq);
//有效数据
int QueueSize(Que* pq);Queue.c
#include"Queue.h"//初始化
void QueueInit(Que* pq)
{assert(pq);pq->head = NULL;pq->tail = NULL;pq->size = 0;
}
//销毁
void QueueDestroy(Que* pq)
{assert(pq);QNode* cur = pq->head;while (cur){QNode* p = cur->next;free(cur);cur = p;}pq->head = NULL;pq->tail = NULL;pq->size = 0;
}
//入队
void QueuePush(Que* pq, QDataType x)
{assert(pq);QNode* newnode = (QNode*)malloc(sizeof(QNode));if (newnode == NULL){perror("malloc failed");exit(-1);}newnode->data = x;newnode->next = NULL;if (pq->head == NULL){pq->head = newnode;pq->tail = newnode;}else{pq->tail->next = newnode;pq->tail = newnode;}pq->size++;
}
//出队
void QueuePop(Que* pq)
{assert(pq);assert(!QueueEmpty(pq));//要有数据if (pq->head->next == NULL)//只有一个节点{free(pq->head);pq->head = NULL;pq->tail = NULL;}else{QNode* cur = pq->head->next;free(pq->head);pq->head = cur;}pq->size--;
}
//取队头
QDataType QueueFront(Que* pq)
{assert(pq);assert(!QueueEmpty(pq));return pq->head->data;
}
//取队尾
QDataType QueueBack(Que* pq)
{assert(pq);assert(!QueueEmpty(pq));return pq->tail->data;
}
//判空 :空返回1,非空返回0
bool QueueEmpty(Que* pq)
{assert(pq);return pq->head == NULL;
}
//有效数据
int QueueSize(Que* pq)
{assert(pq);return pq->size;
}代码测试:
#include"Queue.h"
int main()
{Que p2;QueueInit(&p2);int i = 0;//入队for (i = 11; i <= 20; i++){QueuePush(&p2, i);}printf("队列中数据数量:%d\n", QueueSize(&p2));//出队for (i = 0; i < 7; i++){QDataType a = QueueFront(&p2);printf("%d ", a);QueuePop(&p2);}printf("\n");printf("队头元素:%d 队尾元素:%d\n", QueueFront(&p2), QueueBack(&p2));printf("队列中数据数量:%d\n", QueueSize(&p2));QueueDestroy(&p2);return 0;
}运行实例:

拓展:
循环队列(LeetCode题目链接):
循环队列是一种线性数据结构,其操作表现基于普通队列“先进先出”原则并且队尾被连接在队首之后以形成一个循环。它也被称为“环形缓冲器”。
循环队列的一个好处是我们可以利用这个队列之前用过的空间。在一个普通队列里,一旦一个队列满了,我们就不能插入下一个元素,即使在队列前面仍有空间。但是使用循环队列,我们能使用这些空间去存储新的值。
循环队列可以使用数组实现,也可以使用循环链表实现。
以循环链表实现为例:
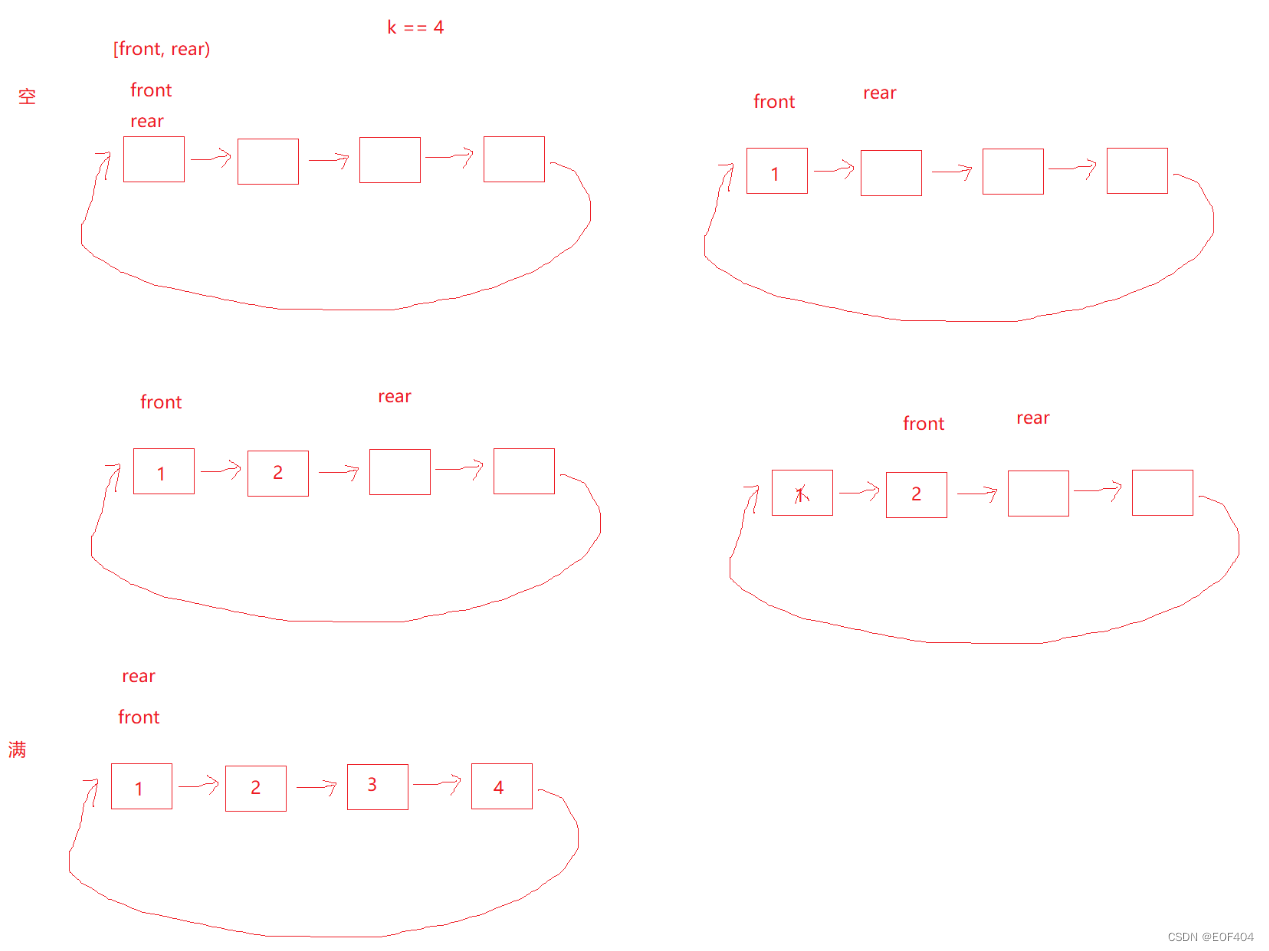
若仅仅是需要几个空间就创建几个空间,则空和满两种情况将无法区分,因此我们可以比实际需要多创建一个空间,这一个多创建出来空间不存储数据,则有如下情况:
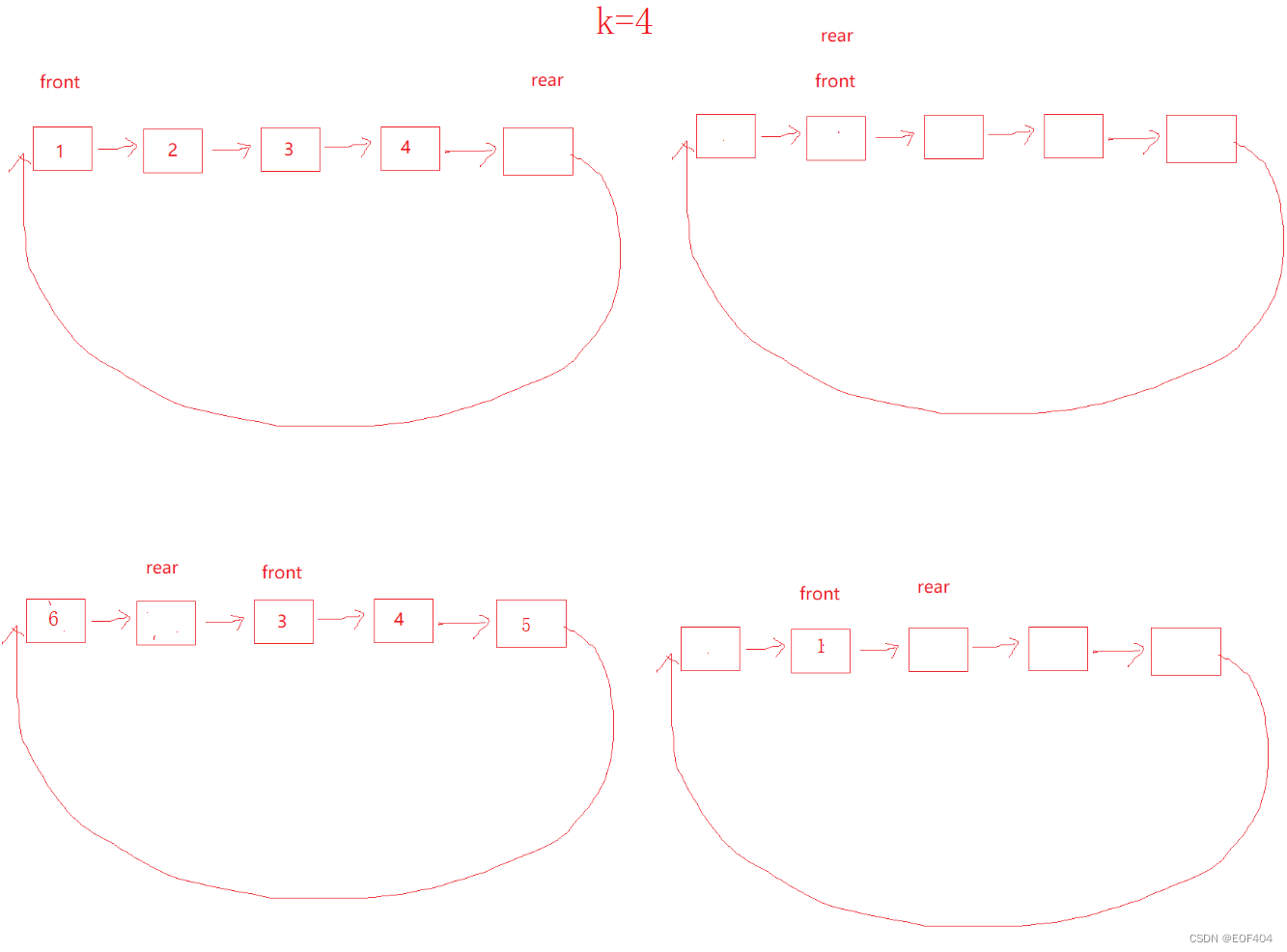
则满和空两种情况就可以区分出来了:front=rear-->空
rear的下一个=front-->满
同时为了方便取队尾数据,可以定义一个全局变量指向队尾位置(即rear指向位置的前一个)。
具体代码实现:
typedef struct List
{int val;struct List*next;
}list;
typedef struct
{list*front;list*rear;
} MyCircularQueue;
list*tail;//定义一个全局变量记录rear的前一个
MyCircularQueue* myCircularQueueCreate(int k)
{MyCircularQueue* obj = (MyCircularQueue*)malloc(sizeof(MyCircularQueue));if (obj == NULL){perror("malloc failed");exit(-1);}obj->front = NULL;obj->rear = NULL;int n = k + 1;while (n--){list* new = (list*)malloc(sizeof(list));if (new == NULL){perror("malloc failed");exit(-1);}new->val = 0;new->next = obj->front;if (obj->front == NULL){obj->front = new;obj->rear = new;}else{obj->rear->next = new;tail=new;obj->rear = obj->rear->next;}} obj->rear=obj->front;return obj;
}
//判空:空返回真,非空返回假
bool myCircularQueueIsEmpty(MyCircularQueue* obj)
{return obj->front==obj->rear;
}
//是否已满:已满返回真,不满返回假
bool myCircularQueueIsFull(MyCircularQueue* obj)
{return obj->rear->next==obj->front;
}
//插入数据:插入成功返回真,失败返回假
bool myCircularQueueEnQueue(MyCircularQueue* obj, int value)
{assert(obj);if(myCircularQueueIsFull(obj))//已满{return false;}else{obj->rear->val=value;obj->rear=obj->rear->next;tail=tail->next;return true;}
}
//从队列中删除元素
bool myCircularQueueDeQueue(MyCircularQueue* obj)
{assert(obj);if(myCircularQueueIsEmpty(obj)){return false;}else{obj->front=obj->front->next;return true;}
}
//获取对首元素
int myCircularQueueFront(MyCircularQueue* obj)
{assert(obj);if(myCircularQueueIsEmpty(obj)){return -1;}return obj->front->val;
}
//获取队尾元素
int myCircularQueueRear(MyCircularQueue* obj)
{assert(obj);if(myCircularQueueIsEmpty(obj)){return -1;}/*list*cur=obj->front;while(cur->next!=obj->rear){cur=cur->next;}return cur->val;*/return tail->val;
}
//释放空间
void myCircularQueueFree(MyCircularQueue* obj)
{while(obj->front!=obj->rear){list*Next=obj->front->next;free(obj->front);obj->front=Next;}free(obj->rear);free(obj);
}利用数组也可以实现,与链表类似在创建空间是同样需要多创建一个,但是因为队头、队尾没有链接关系,所以利用数组实现时与利用循环链表实现会有所不同:
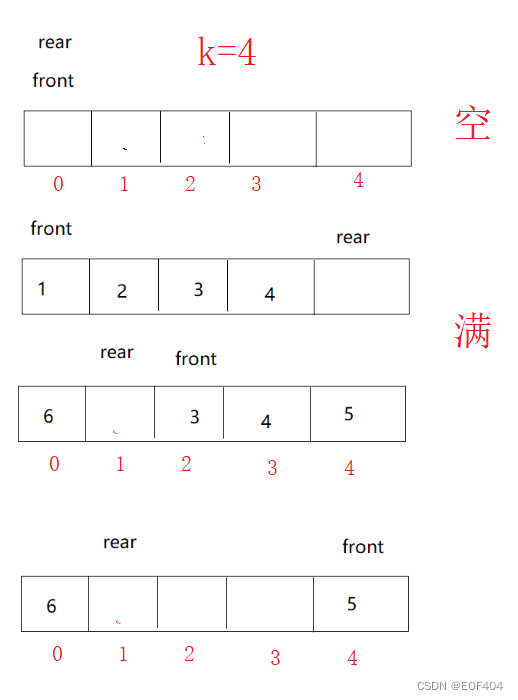
与循环链表类似,用数组实现循环队列时,当rear=front时,队列为空;在判断队列是否满时,虽然也是用rear的下一个等于front(即rear+1==front),但是不能单单使用 rear+1==front 判断,因为数组实现时,队首和队尾没有链接关系,当rear在数组最后一个位置时,循环队列已满,但rear+1会越界往后访问,且当front在数组最后一个位置时,删除数据后执行front+1也会出现越界访问的问题,出现错误,因此应想办法让rear和front都在数组范围内变化。
观察数组下标,可以让rear+1和front+1都模上k+1,问题就能很好解决。
具体代码实现:
typedef struct
{int k;int front;int rear;int* queue;
} MyCircularQueue;MyCircularQueue* myCircularQueueCreate(int k)
{MyCircularQueue* obj = (MyCircularQueue*)malloc(sizeof(MyCircularQueue));if (obj == NULL){perror("malloc failed");exit(-1);}obj->k = k;obj->front = 0;obj->rear = 0;obj->queue = (int*)malloc(sizeof(int) * (k + 1));if (obj->queue == NULL){perror("malloc failed");exit(-1);}return obj;
}
//判空:空返回真,非空返回假
bool myCircularQueueIsEmpty(MyCircularQueue* obj)
{return obj->rear == obj->front;
}
//是否已满:已满返回真,不满返回假
bool myCircularQueueIsFull(MyCircularQueue* obj)
{return (obj->rear + 1) % (obj->k + 1) == obj->front;
}
//插入数据:插入成功返回真,失败返回假
bool myCircularQueueEnQueue(MyCircularQueue* obj, int value)
{assert(obj);if (myCircularQueueIsFull(obj))//已满{return false;}else{obj->queue[obj->rear] = value;obj->rear = (obj->rear + 1) % (obj->k + 1);return true;}
}
//从队列中删除元素
bool myCircularQueueDeQueue(MyCircularQueue* obj)
{assert(obj);if (myCircularQueueIsEmpty(obj)){return false;}else{obj->front = (obj->front + 1) % (obj->k + 1);return true;}
}
//获取对首元素
int myCircularQueueFront(MyCircularQueue* obj)
{assert(obj);if (myCircularQueueIsEmpty(obj)){return -1;}return obj->queue[obj->front];
}
//获取队尾元素
int myCircularQueueRear(MyCircularQueue* obj)
{assert(obj);if (myCircularQueueIsEmpty(obj)){return -1;}return obj->queue[(obj->rear + obj->k) % (obj->k + 1)];
}
//释放空间
void myCircularQueueFree(MyCircularQueue* obj)
{free(obj->queue);obj->queue = NULL;free(obj);
}相关文章:
栈和队列详解
目录 栈 栈的概念及结构: 栈的实现: 代码实现: Stack.h stack.c 队列: 概念及结构: 队列的实现: 代码实现: Queue.h Queue.c 拓展: 循环队列(LeetCode题目链接࿰…...
数据结构 | 树的定义及实现
目录 一、树的术语及定义 二、树的实现 2.1 列表之列表 2.2 节点与引用 一、树的术语及定义 节点: 节点是树的基础部分。它可以有自己的名字,我们称作“键”。节点也可以带有附加信息,我们称作“有效载荷”。有效载荷信息对于很多树算法…...
Delphi7通过VB6之COM对象调用FreeBASIC写的DLL功能
VB6写ActiveX COM组件比较方便,不仅PowerBASIC与VB6兼容性好,Delphi7与VB6兼容性也不错,但二者与FreeBASIC兼容性在字符串处理上差距比较大,FreeBASIC是C化的语言,可直接使用C指令。下面还是以实现MKI/CVI, MKL/CVL, M…...
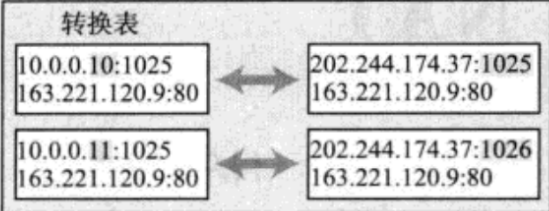
【Linux 网络】NAT技术——缓解IPv4地址不足
NAT技术 NAT 技术背景NAT IP转换过程NAPTNAT 技术的缺陷 NAT(Network Address Translation,网络地址转换)技术,是解决IP地址不足的主要手段,并且能够有效地避免来自网络外部的攻击,隐藏并保护网络内部的计算…...
协议)
Flink 两阶段提交(Two-Phase Commit)协议
Flink 两阶段提交(Two-Phase Commit)是指在 Apache Flink 流处理框架中,为了保证分布式事务的一致性而采用的一种协议。它通常用于在流处理应用中处理跨多个分布式数据源的事务性操作,确保所有参与者(数据源或计算节点…...

【Docker晋升记】No.2 --- Docker工具安装使用、命令行选项及构建、共享和运行容器化应用程序
文章目录 前言🌟一、Docker工具安装🌟二、Docker命令行选项🌏2.1.docker run命令选项:🌏2.2.docker build命令选项:🌏2.3.docker images命令选项:🌏2.4.docker ps命令选项…...

[OnWork.Tools]系列 00-目录
OnWork.Tools系列文章目录 OnWork.Tools系列 01-简介_末叶的博客-CSDN博客OnWork.Tools系列 02-安装_末叶的博客-CSDN博客OnWork.Tools系列 03-软件设置_末叶的博客-CSDN博客OnWork.Tools系列 04-快捷启动_末叶的博客-CSDN博客OnWork.Tools系列 05-系统工具_末叶的博客-CSDN博…...

Cadvisor+InfluxDB+Grafan+Prometheus(详解)
目录 一、CadvisorInfluxDBGrafan案例概述 (一)Cadvisor Cadvisor 产品特点: (二)InfluxDB InfluxDB应用场景: InfluxDB主要功能: InfluxDB主要特点: (三&#…...
AtcoderABC222场
A - Four DigitsA - Four Digits 题目大意 给定一个整数N,其范围在0到9999之间(包含边界)。在将N转换为四位数的字符串后,输出它。如果N的位数不足四位,则在前面添加必要数量的零。 思路分析 可以使用输出流的格式设…...
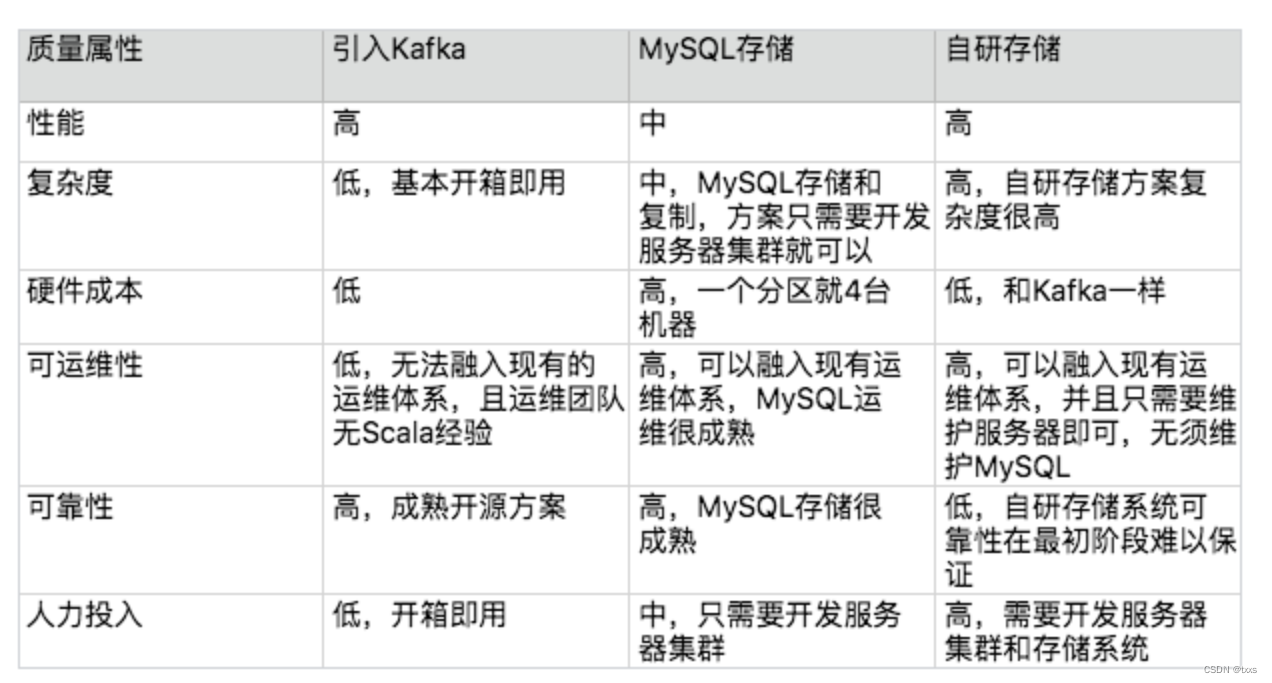
架构实践方法
一、识别复杂度 将主要的复杂度问题列出来,然后根据业务、技术、团队等综合情况进行排序,优先解决当前面临的最主要的复杂度问题。对于按照复杂度优先级解决的方式,存在一个普遍的担忧:如果按照优先级来解决复杂度,可…...
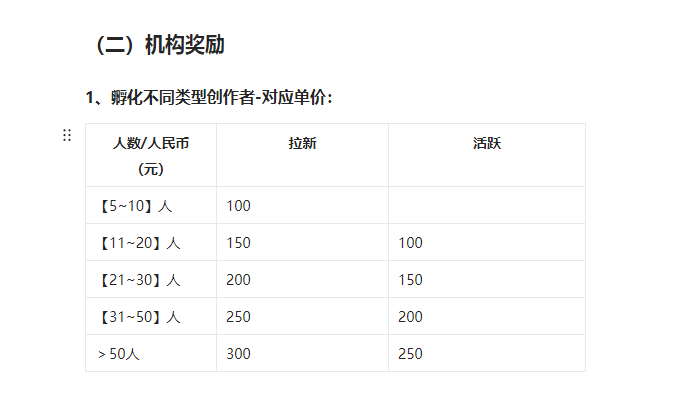
点淘的MCN机构申请详细入驻指南!
消费趋势的变化,来自消费人群的变化。 后疫情时代,经济复苏的反弹力度不足,人们开始怀疑我们正从前几年的消费升级,跌入消费降级的时代,但这并不能准确概括消费市场的变化。 仔细翻看各大奢侈品集团的财报࿰…...
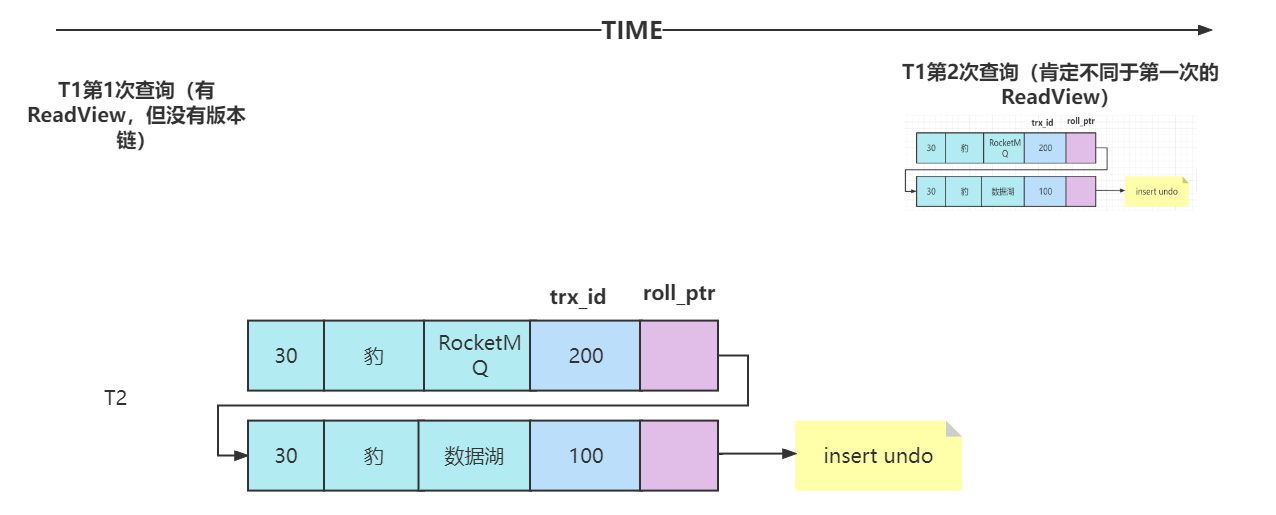
事务和事务的隔离级别
1.4.事务和事务的隔离级别 1.4.1.为什么需要事务 事务是数据库管理系统(DBMS)执行过程中的一个逻辑单位(不可再进行分割),由一个有限的数据库操作序列构成(多个DML语句,select语句不包含事务&…...
)
每日一题 34在排序数组中查找元素的第一个和最后一个位置(二分查找)
题目 给你一个按照非递减顺序排列的整数数组 nums,和一个目标值 target。请你找出给定目标值在数组中的开始位置和结束位置。 如果数组中不存在目标值 target,返回 [-1, -1]。 你必须设计并实现时间复杂度为 O(log n) 的算法解决此问题。 示例 1&…...
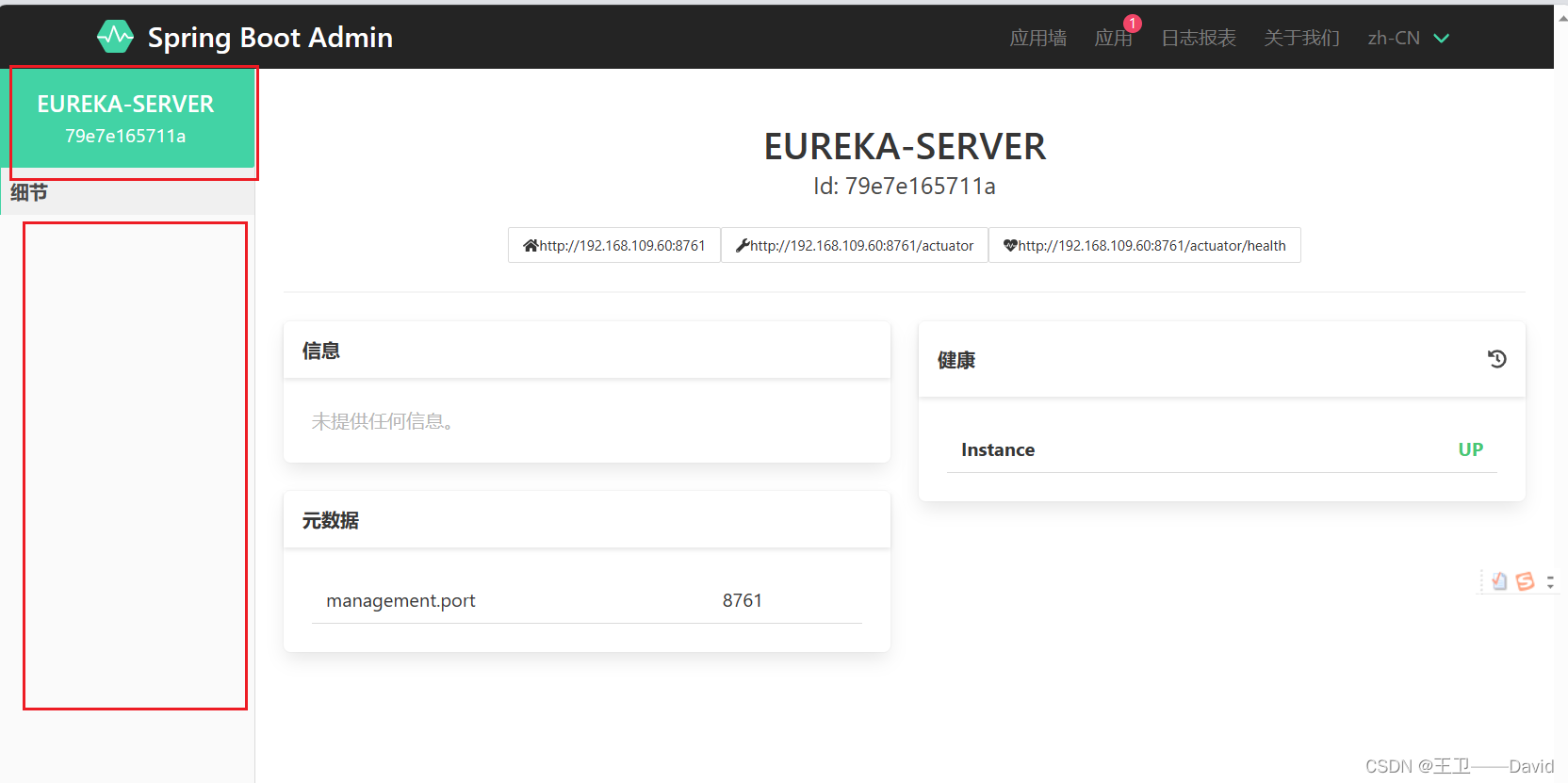
Spring Boot Admin 环境搭建与基本使用
Spring Boot Admin 环境搭建与基本使用 一、Spring Boot Admin是什么二、提供了那些功能三、 使用Spring Boot Admin3.1搭建Spring Boot Admin服务pom文件yml配置文件启动类启动admin服务效果 3.2 common-apipom文件feignhystrix 3.3服务消费者pom文件yml配置文件启动类control…...
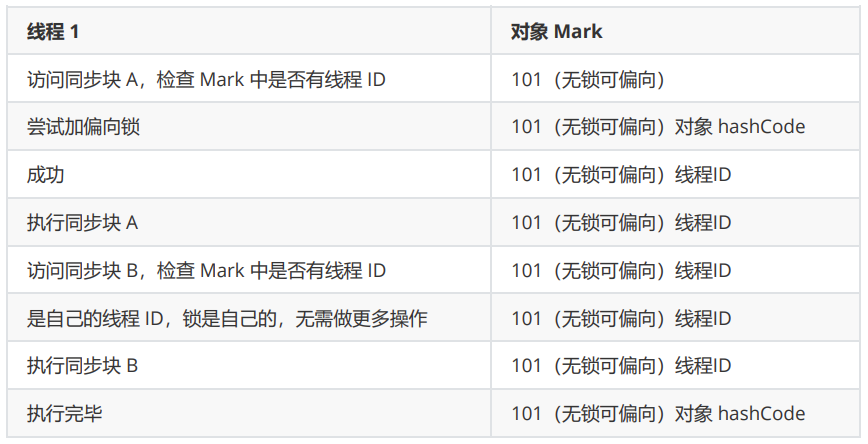
JVM之内存模型
1. Java内存模型 很多人将Java 内存结构与java 内存模型傻傻分不清,java 内存模型是 Java Memory Model(JMM)的意思。 简单的说,JMM 定义了一套在多线程读写共享数据时(成员变量、数组)时,对数据…...

音视频 vs2017配置FFmpeg
vs2017 ffmpeg4.2.1 一、首先我把FFmpeg整理了一下,放在C盘 二、新建空项目 三、添加main.cpp,将bin文件夹下dll文件拷贝到cpp目录下 #include<stdio.h> #include<iostream>extern "C" { #include "libavcodec/avcodec.h&…...

【项目管理】PMP备考宝典-第二章《环境》
第一节:概述 1.项目所处的组织环境 (1)事业环境因素(EEFs) 组织内部的事业环境因素: 企业都会有愿景、使命、价值观,这些决定了企业的发展方向。不忘初心,坚定地走自己的路&#…...
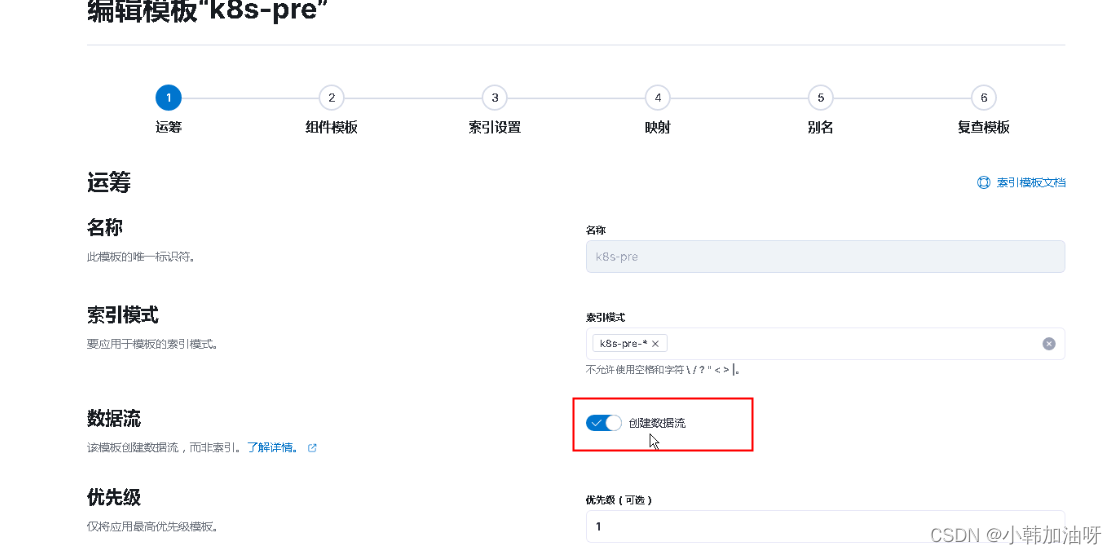
ELK 将数据流转换回常规索引
ELK 将数据流转换回常规索引 现象:创建索引模板是打开了数据流,导致不能创建常规索引,并且手动修改、删除索引模板失败 "reason" : "composable template [logs_template] with index patterns [new-pattern*], priority [2…...
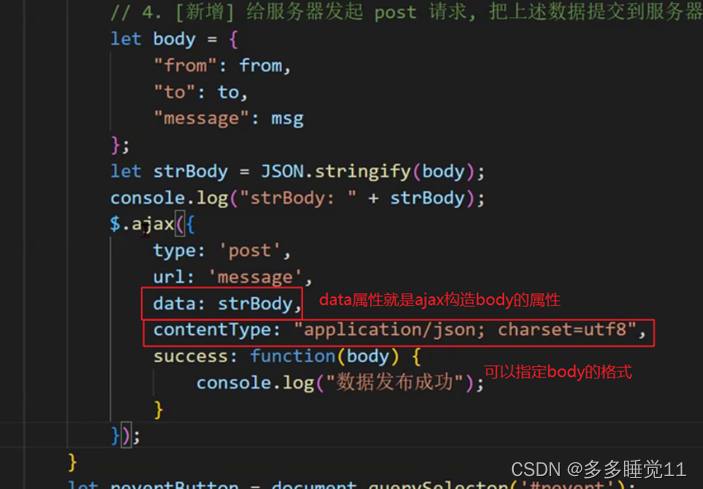
jackson库收发json格式数据和ajax发送json格式的数据
一、jackson库收发json格式数据 jackson库是maven仓库中用来实现组织json数据功能的库。 json格式 json格式一个组织数据的字符文本格式,它用键值对的方式存贮数据,json数据都是有一对对键值对组成的,键只能是字符串,用双引号包…...

ubuntu安装和卸载CLion
安装 在https://www.jetbrains.com/clion/download/#sectionlinux下载相应版本的安装包,解压之后,找到解压文件夹中的bin文件夹运行./clion.sh 卸载 使用sudo rm -rf删除以下内容;并把刚刚解压的文件删掉 ~/.config/JetBrains ~/.local/s…...
)
STM32CUBEIDE实战:手把手教你为Bootloader和App分区,搞定双程序烧录(附完整配置流程)
STM32CUBEIDE实战:手把手教你为Bootloader和App分区,搞定双程序烧录(附完整配置流程) 在嵌入式开发中,实现固件在线升级(OTA)或双程序分区是提升产品可靠性和维护性的关键。想象一下这样的场景:你的设备已经…...

智能修复中的缺陷检测与修补建议
智能修复中的缺陷检测与修补建议 随着人工智能技术的快速发展,智能修复系统在软件开发、工业制造等领域发挥着越来越重要的作用。缺陷检测与修补是智能修复的核心环节,能够帮助开发者快速发现并修复代码或产品中的问题,提高效率并降低成本。…...

PAT乙级刷题避坑指南:避开“说反话”的栈陷阱和“成绩排名”的结构体误区
PAT乙级真题高效解法:避开常见思维陷阱与代码优化实战 在准备PAT乙级考试的过程中,许多考生虽然能够完成题目要求,却常常陷入一些典型的思维陷阱和代码效率瓶颈。本文将聚焦三个经典题目("说反话"、"成绩排名"…...

JimuReport:企业级开源报表工具的技术架构与实施路径分析
JimuReport:企业级开源报表工具的技术架构与实施路径分析 【免费下载链接】JimuReport 开源的报表工具与BI大屏,完美替代帆软和Tableau,提供强大的报表能力。一款类似Excel的报表设计器和大屏设计!完全在线傻瓜式拖拽设计…...

如何永久保存你的数字记忆:WeChatMsg个人数据管理终极指南
如何永久保存你的数字记忆:WeChatMsg个人数据管理终极指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/W…...
滤镜效果)
Layui弹出层layer如何实现窗口背景的模糊(Blur)滤镜效果
应给页面根容器(如#app)动态添加filter类实现模糊,而非作用于body;需用计数器管理多层弹窗的blur状态,并为IE/旧Edge提供opacity遮罩降级方案。layer.open 里直接加 CSS filter 会失效?因为 Layui 的弹出层…...

Windows PDF处理终极指南:零依赖的Poppler工具集
Windows PDF处理终极指南:零依赖的Poppler工具集 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 还在为Windows系统上的PDF处理工具烦恼…...
RV1126B rknn-toolkit-lite2使用方法)
瑞芯微(EASY EAI)RV1126B rknn-toolkit-lite2使用方法
1. rknn-toolkit-lite2介绍 RKNN-Toolkit-Lite2 是瑞芯微(Rockchip)专为旗下RK系列芯片(如RV1126B、RK3576、RK3588等)打造的轻量级 AI 模型部署工具包,聚焦边缘 / 嵌入式设备的模型推理场景。它无需复杂的环境依赖&a…...

Honey Select 2 进阶体验:从基础API到画质优化的必备插件指南
1. 基础框架搭建:插件系统的核心组件 当你第一次打开Honey Select 2的mod文件夹时,可能会被各种.dll文件和压缩包搞得晕头转向。别担心,我们先从最基础的框架开始搭建。就像盖房子需要打地基一样,这些核心组件是所有高级功能的前提…...
)
【收藏备用】2026年AI人才市场需求爆发,企业更看重实践能力而非学历(小白/程序员必看大模型学习指南)
2026年,AI行业迎来新一轮爆发式增长,大模型技术的普及的落地,让AI人才成为企业争抢的核心资源。不同于以往“唯学历论”的招聘导向,今年多数企业在AI人才招聘中,更看重求职者的实践能力、项目经验和技术落地能力&#…...