elasticsearch简单入门语法
基本操作
创建不同的分词器
ik_smart: 极简分词 ; ik_max_word: 最细力再度分词


基本的rest命令
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 查询文档通过文档id |
| POST | localhost:9200/索引名称/类型名称/_search | 查询所有数据 |
索引基本操作
查询所有索引

Elasticsearch 7.x 版本
# 返回一个仅包含索引名称的 JSON 数组
GET /_cat/indices?format=json&h=index
扩展:获取ES的其他信息
GET _cat/health # 查看健康值
GET _cat/indices?v #查看所有东西的版本信息
新增索引
# ElasticSearch的7.x.x版本PUT /索引名/类型名/文档id{请求体}# 创建索引
PUT test1{"mappings": {"properties": {"name": {"type": "text"},"age":{"type": "integer"}}}}# 创建加索引时同时添加数据,es会自动给属性设置type# ElasticSearch的8.x.x版本,类型已经弃用,默认写_doc。PUT /索引名/_doc/文档id{请求体}PUT test1/_doc/1{"name":"小明","age":23} # ElasticSearch的8.x.x版本,类型已经弃用,默认写_doc。PUT /索引名/_doc/文档id{请求体}
CreateIndexRequest request = new CreateIndexRequest(INDEX);CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);查看索引

name需要指定类型
官网类型文档地址:Keyword type family | Elasticsearch Guide [8.9] | Elastic
字符串类型 text、keyword
数值类型 long,integer,short,byte,double,float,half float,scaled float
日期类型 date
te布尔值类型 boolean·
二进制类型 binary
等等……
设置字段类型

修改索引
索引是不可修改的。一旦创建了索引,您不能直接修改其结构或字段的映射。如果要修改索引的结构,您需要重新创建索引并重新索引数据。
POST _reindex{"source": {"index": "your_old_index"},"dest": {"index": "new_index"}}新索引和旧索引的字段不一定需要完全一致。在重新创建索引和重新索引数据时,可以对字段进行修改、删除或添加新的字段。
如果字段在新索引中已经存在,则该字段的映射将被保留。如果字段在新索引中不存在,则会根据重新索引的数据动态创建字段的映射。
例如,假设旧索引中有一个 "field1" 字段,而新索引中没有。在重新索引数据时,如果数据中存在 "field1" 字段,Elasticsearch 将自动创建该字段的映射并将其添加到新索引中。
同样地,如果旧索引中存在一个 "field2" 字段,而新索引中也有一个名为 "field2" 的字段,那么在重新索引数据时,新索引中的 "field2" 字段的映射将保留不变。
需要注意的是,如果字段在新索引和旧索引中具有不兼容的类型或映射定义,可能会导致数据转换或丢失。因此,在进行索引结构修改时,请确保对数据和字段映射的变化有充分的了解和计划。
删除索引

关于文档的基本操作
基本操作
添加数据
PUT /index/_doc/1
{"name": "狂神说","age": 3,"desc": "工资2500","tags": ["直男","温暖","技术宅"]
}
PUT /index/_doc/2
{"name": "张三","age": 30,"desc": "没有工资","tags": ["渣男","旅游","交友"]
}查询数据
# 查询索引下,对应文档ID的数据 GET /index/_doc/1 GET /index/_doc/2

更新 PUT(不推荐)
PUT 修改数据,需要全属性字段都存在,否则会丢失缺失的属性字段
# 修改数据
put index/_doc/1
{"name": "杨光1","age": 3,"desc": "工资2500","tags": ["直男","温暖","技术宅"]
}
# PUT 修改时,会更新该ID下的所有字段,如果缺失字段,则会删除原有字段
put index/_doc/1
{"name": "杨光1","age": 3,"desc": "工资2500"
}
更新 POST(推荐)
# POST 更新,会修改该文档ID下对应属性的值
POST index/_update/1
{"doc": {"name":"杨光3"}
}
# POST 更新,会修改该文档ID下对应属性的值,不推荐这样写,ES8执行不支持这种语法
POST index/_doc/1/_update
{"doc": {"name":"杨光4"}
} 
条件查询
PUT /index/_doc/1
{"name": "杨光","age": 3,"desc": "工资2500","tags": ["直男","温暖","技术宅"]
}PUT /index/_doc/2
{"name": "张三","age": 30,"desc": "没有工资","tags": ["渣男","旅游","交友"]
}# 根据name查询
GET index/_search?q=name:张三
PUT index
{"mappings": {"properties": {"name":{"type": "keyword"},"xm":{"type": "text","analyzer": "ik_smart"},"age":{"type": "integer"},"desc":{"type": "text"},"tags":{"type": "text"}}}
}
# 测试数据
PUT /index/_doc/1
{"name": "杨光","xm": "杨光","age": 3,"desc": "工资2500","tags": ["直男","温暖","技术宅"]
}PUT /index/_doc/2
{"name": "张三","xm": "张三","age": 30,"desc": "没有工资","tags": ["渣男","旅游","交友"]
}PUT /index/_doc/3
{"name": "李三","xm": "李三","age": 23,"desc": "工资5000","tags": ["健身","旅游","购物"]
}PUT /index/_doc/4
{"name": "张三丰","xm": "张三丰","age": 10,"desc": "工资5000","tags": ["健身","旅游","购物"]
}PUT /index/_doc/5
{"name": "张","xm": "张","age": 10,"desc": "工资5000","tags": ["健身","旅游","购物"]
}PUT /index/_doc/6
{"name": "三","xm": "三","age": 10,"desc": "工资5000","tags": ["健身","旅游","购物"]
}match和term
Match查询和Term查询是Elasticsearch中常用的查询类型,它们有以下区别:
匹配方式:
Term查询:对查询条件不进行分词,直接按照完全匹配的方式进行查询。
Match查询:对查询条件进行分词,然后对分词后的词项进行匹配。
查询字段类型:
Term查询:适用于精确匹配的字段,如关键字(keyword)类型或未分词的文本类型(如"张三",不会被分词)。
Match查询:适用于全文本字段,如全文本(text)类型或已分词的文本类型(如"张三 张三",会被分词成两个词项"张三")。
匹配精度:
Term查询:精确匹配,只有完全匹配的词项才会被返回。
Match查询:默认为词项级别的匹配,可以根据分析器的分词规则进行模糊匹配。
执行效率:
Term查询:由于不进行分词,查询速度较快。
Match查询:需要对查询条件进行分词,可能会影响查询性能。
根据具体的查询需求,选择合适的查询类型可以提高查询的准确性和效率。如果需要精确匹配的查询,且不需要分词,可以选择Term查询;如果需要对分词后的文本进行匹配,可以选择Match查询。
match查询
# match 查询时,会对查询条件先分词
# 而name字段类型为keyword,不会分词,所以只能搜到name=张三的数据
GET index/_search
{"query": {"match": {"name": "张三"}},"_source": ["name","xm"]
}
# match 查询,会对查询条件先分词
# xm字段类型为text,用ik_max_smart分词,会分词,所以只能搜到文档xm字段分词后,结果为张三分词后的所有数据
GET index/_search
{"query": {"match": {"xm": "张三"}},"_source": ["name","xm"]
}


term查询
# term 查询时,不会对查询条件进行分词,name为keyword,所以只能完全匹配
GET index/_search
{"query": {"term": {"name": "张三"}}
}
# term 查询,不会对查询条件进行分词
# xm字段类型为text,用ik_max_smart分词,会分词,所以能查到文档分词后为张三的数据
GET index/_search
{"query": {"term": {"xm": "张三"}},"_source": ["name","xm"]
}

过滤字段查询
# 查询结果只展示 name和xm两个字段
GET index/_search
{"_source": ["name","xm"]
}
排序
# 查询结果排序
GET index/_search
{"_source": ["name", "age"], "sort": [{"age": {"order": "desc"}}]
}
分页查询
# 分页查询
GET index/_search
{"_source": ["name", "age"],"from": 0,"size": 2
}
多条件查询(布尔值查询)
must
类似sql中的 and
# 查询 name = 张三 并且 age = 30
GET index/_search
{"query": {"bool": {"must": [{"match": {"name": "张三"}},{"match": {"age": "30"}}]}}
}should
类似sql中的 or
# 查询 name = 张三 或者 name = 李三
GET index/_search
{"query": {"bool": {"should": [{"match": {"name": "张三"}},{"match": {"name": "李三"}}]}}
}
must_not
类似sql中的 not in
# 查询 name != 张三 并且 name != 李三
GET index/_search
{"query": {"bool": {"must_not": [{"match": {"name": "张三"}},{"match": {"name": "李三"}}]}}
}
filter
在Elasticsearch中,过滤器(Filter)是一种用于精确筛选文档的查询子句,主要用于限制搜索结果的范围。与查询(Query)不同,过滤器不会评分和排序结果,而是根据指定的条件进行筛选。这可以提高查询性能,特别是在过滤大量文档的情况下。
过滤器可以用于各种条件,如范围查询、存在性检查、逻辑运算等。常见的过滤器类型包括:
Term Filter:根据指定的词项进行精确匹配筛选。
Range Filter:通过指定的范围进行筛选,可以用于数值、日期等字段。
Exists Filter:检查字段是否存在于文档中。
Bool Filter:通过逻辑运算符(AND、OR、NOT)对其他过滤器进行组合。
Geo Distance Filter:通过指定的地理位置和距离范围进行地理位置过滤。
Script Filter:使用自定义脚本进行筛选。
过滤器可以单独使用,也可以与查询结合使用。如果需要对搜索结果进行精确的筛选,并且不需要评分和排序,建议使用过滤器来提高查询性能。
# 查询xm=张三,并且age < 30 且 age >= 10 ,并且age 倒序
GET index/_search
{"_source": ["xm","age"],"query": {"bool": {"must": [{"match": {"xm": "张三"}}], "filter": [{"range": {"age": {"gte": 10,"lt": 30}}}]}},"sort": [{"age": {"order": "desc"}}]
}# 查询xm=张三,并且age < 30 且 age >= 10 ,并且 xm 字段值
GET index/_search
{"_source": ["xm","age"],"query": {"bool": {"must": [{"match": {"xm": "张三"}}],"filter": [{"range": {"age": {"gte": 10,"lt": 30}}},{"exists": {"field": "xm"}}]}}
}

高亮查询
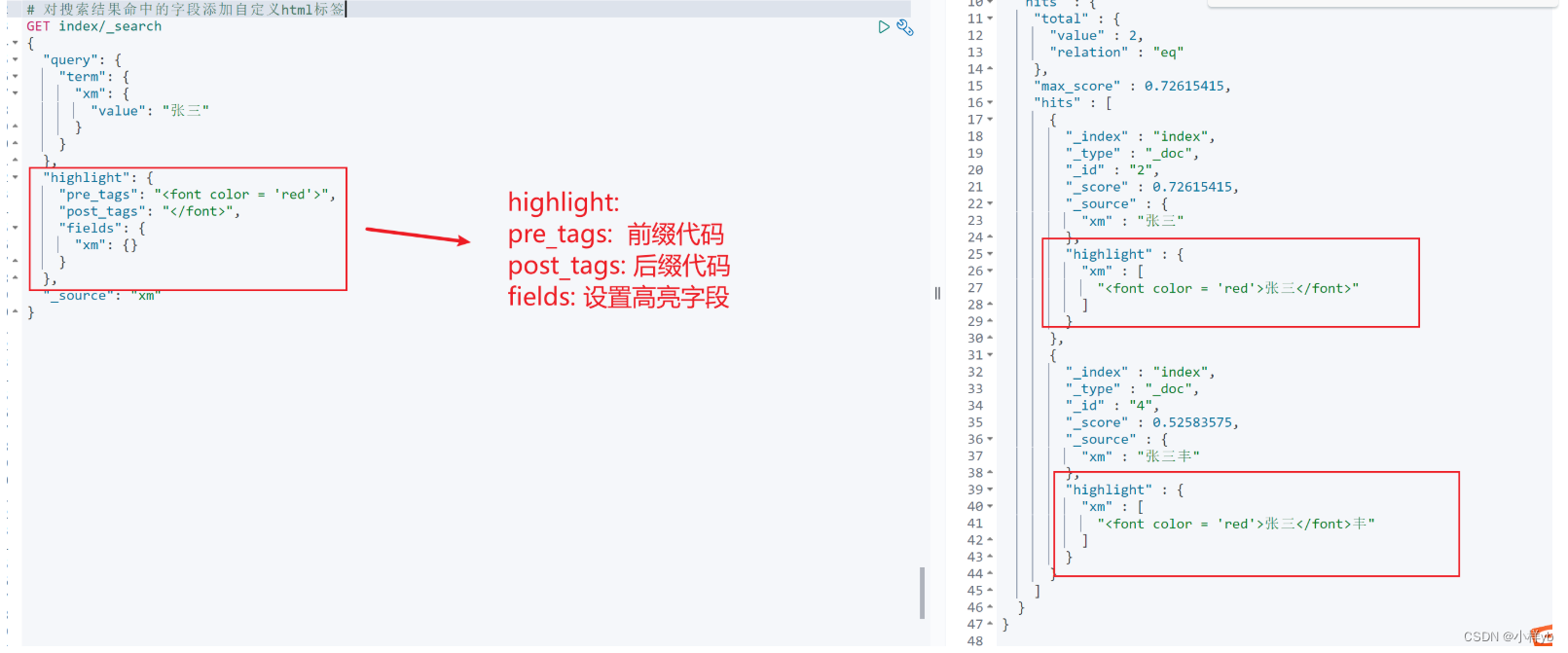
# 对搜索结果命中的字段添加自定义html标签
GET index/_search
{"query": {"term": {"xm": {"value": "张三"}}}, "highlight": {"pre_tags": "<font color = 'red'>","post_tags": "</font>", "fields": {"xm": {}}},"_source": "xm"
}
相关文章:
elasticsearch简单入门语法
基本操作 创建不同的分词器 ik_smart: 极简分词 ; ik_max_word: 最细力再度分词 基本的rest命令 methodurl地址描述PUTlocalhost:9200/索引名称/类型名称/文档id创建文档(指定文档id)POSTlocalhost:9200/索引名称/类型名称创建文…...

Python自动化测试用例:如何优雅的完成Json格式数据断言
目录 前言 直接使用 优化 封装 小结 进阶 总结 资料获取方法 前言 记录Json断言在工作中的应用进阶。 直接使用 很早以前写过一篇博客,记录当时获取一个多级json中指定key的数据: #! /usr/bin/python # coding:utf-8 """ aut…...

阿里云对象存储服务OSS
1、引依赖 <dependency><groupId>com.aliyun.oss</groupId><artifactId>aliyun-sdk-oss</artifactId><version>3.15.1</version> </dependency> <dependency><groupId>javax.xml.bind</groupId><artifa…...
第三节:在WORD为应用主窗口下关闭EXCEL的操作(1)
【分享成果,随喜正能量】夏日里的遗憾,一定都会被秋风温柔化解。吃素不难,难于不肯捨贪口腹之心。若不贪口腹,有何吃素之不便乎。虽吃华素,不吃素日,亦须少吃。以一切物类,皆是贪生怕死…...

mybatis 缓存
很久没有弄mybatis了,以至于今天在使用时忘记了一个很重事情(缓存),导致始终读取不数据库更新之后的最新的数据,后来折腾了小半天才想起缓存,所有小记住一下关闭mybatis的缓存 mybatis.configuration.cach…...
分布式Redis详解
目录 前言安装redis的俩种方法Redis 与 MySQL的区别Redis可以实现那些功能Redis常用的数据类型有序列表的底层是如何实现的?什么是跳跃表 Redis在Spring中的使用Redis 中为什么单线程比多线程快Redis的分布式锁如何实现Redis 分布式锁可能出现的问题Redis保持数据不丢失的方式…...
揭秘程序员和技师的7大共同点,最后一点绷不住了
大家好,这里是程序员晚枫,周末朋友出去放松回来,给我分析了一下程序员和技师的7个相同点,尤其是最后一点让我彻底绷不住了! 我也分享给大家。 1、都有工号。98号技师,380号技师大家都很熟悉了,…...
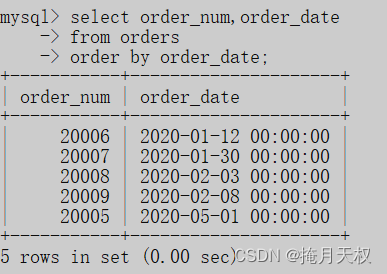
SQL | 使用函数处理数据
8-使用函数处理数据 8.1-函数 SQL可以用函数来处理数据。函数一般是在数据上执行的,为数据的转换和处理提供了方便。 8.1.1 函数带来的问题 每种DBMS都有特定的函数,只有很少一部分函数,是被所有主要的DBMS等同的支持。 虽然所有的类型的…...
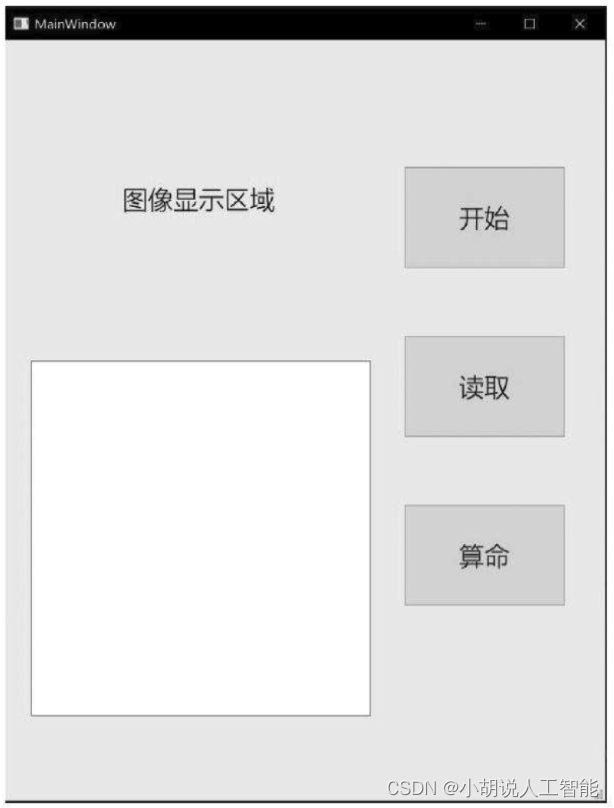
基于Dlib库+SVM+Tensorflow+PyQT5智能面相分析-机器学习算法应用(含全部工程源码)+训练及测试数据集
目录 前言总体设计系统整体结构图系统流程图模型流程 运行环境Python 环境TensorFlow环境界面编程环境 模块实现1. 数据预处理2. 模型构建1)定义模型结构2)交叉验证模型优化 3. 模型训练及保存4. 模型测试1)摄像头调用2)模型导入及…...

【Flutter】【packages】simple_animations 简单的实现动画
package:simple_animations 导入包到项目中去 可以实现简单的动画, 快速实现,不需要自己过多的设置 有多种样式可以实现[ ] 功能: 简单的用例:具体需要详细可以去 pub 链接地址 1. PlayAnimationBuilder PlayAnima…...
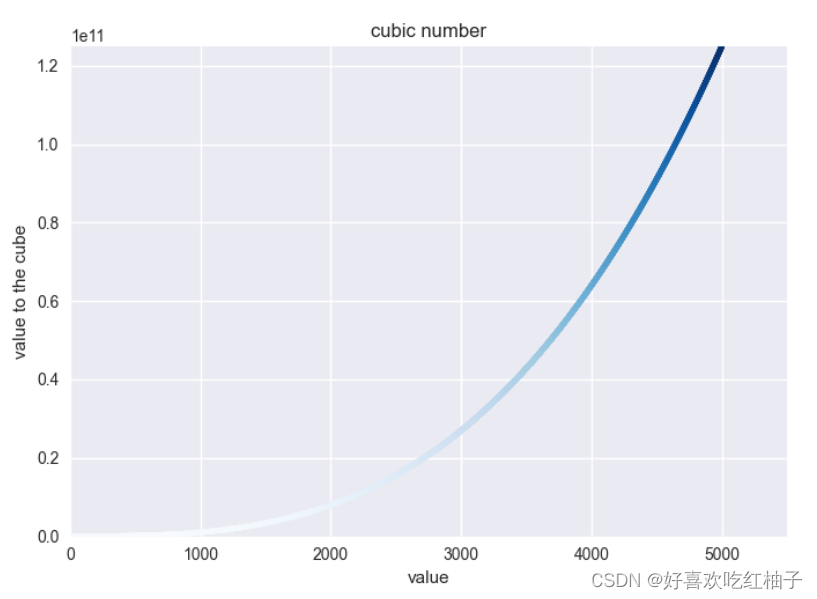
python之matplotlib入门初体验:使用Matplotlib进行简单的图形绘制
目录 绘制简单的折线图1.1 修改标签文字和线条粗细1.2 校正图形1.3 使用内置样式1.4 使用scatter()绘制散点图并设置样式1.5 使用scatter()绘制一系列点1.6 python循环自动计算数据1.7 自定义颜色1.8 使用颜色映射1.9 自动保存图表练习题 绘制简单的折线图 绘制一个简单折线图…...

[Linux kernel] [ARM64] boot 流程梳理
一、启动汇编代码部分 0. 链接文件找代码段入口 – _text arch/arm64/kernel/vmlinux.lds.S ENTRY(_text). KIMAGE_VADDR;.head.text : {_text .;HEAD_TEXT}.text : ALIGN(SEGMENT_ALIGN) { /* Real text segment */_stext .; /* Text and read-only data */IRQENTRY_TE…...

重建二叉树
输入一棵二叉树前序遍历和中序遍历的结果,请重建该二叉树。 注意: 二叉树中每个节点的值都互不相同;输入的前序遍历和中序遍历一定合法; 数据范围 树中节点数量范围 [0,100] 。 样例 给定: 前序遍历是:[3, 9, 2…...

支付整体架构
5.4 支付的技术架构 架构即未来,只有建立在技术架构设计良好的体系上,支付机构才能有美好的未来。如果支付的技术体系在架构上存在问题,那么就没有办法实现高可用性、高安全性、高效率和水平可扩展性。 总结多年来在海内外支付机构主持和参与…...

百度智能云:千帆大模型平台接入Llama 2等33个大模型,上线103个Prompt模板
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的…...
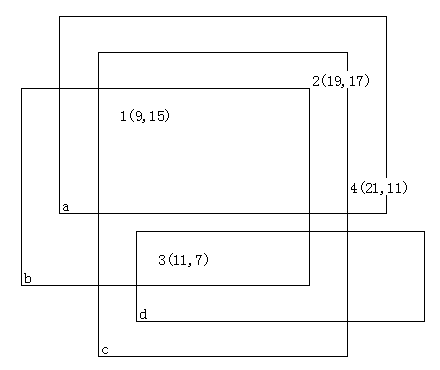
烦人的幻灯片——拓扑排序
烦人的幻灯片 烦人的幻灯片问题描述输入输出格式输入格式输出格式 输入输出样例输入样例:输入样例一:输入样例二: 输出样例:输出样例一:输出样例二: 正确做法拓扑排序 代码 烦人的幻灯片 问题描述 李教授…...

无涯教程-Perl - ord函数
描述 此函数返回EXPR指定的字符的ASCII数值,如果省略则返回$_。例如,ord(A)返回值为65。 语法 以下是此函数的简单语法- ord EXPRord返回值 该函数返回整数。 例 以下是显示其基本用法的示例代码- #!/usr/bin/perl -wprint("ord() ", ord(G), "\n"…...

Python爬虫:js逆向调式操作及调式中遇到debugger问题
Python爬虫:js逆向调式操作及调式中遇到debugger问题 1. 前言2. js逆向调式操作2.1 DOM事件断点2.2 XHR/提取断点(用于请求接口参数加密处理)2.3 请求返回的数据是加密的2.4 hook定位参数 3. 调式中遇到debugger问题3.1 解决方式(一律不在此处暂停)3.2 问题:点击一律…...

HTML网页制作技巧:打造出色的用户体验
HTML是构建网页的基础语言,掌握一些关键的技巧可以帮助您创建出色的用户体验。本文将介绍一些HTML网页制作的技巧,从布局和样式到交互和可访问性,为您提供有用的指导。无论您是初学者还是有经验的开发者,这些技巧都将对您的网页设…...

探究使用HTTP代理ip后无法访问网站的原因与解决方案
目录 访问网站的原理是什么 1. DNS解析 2. 建立TCP连接 3. 发送HTTP请求: 4. 服务器响应: 5. 浏览器渲染: 6. 页面展示: 使用代理IP后访问不了网站,有哪些方面的原因 1. 代理IP的可用性: 2. 代理…...

Go语言如何做API限流_Go语言令牌桶限流教程【深入】
<p>golang.org/x/time/rate 是 Go 官方推荐的令牌桶限流方案,核心为 rate.Limiter 和 rate.Limit;需按需动态创建实例隔离限流维度,配合 Retry-After 和 X-RateLimit- headers 提升兼容性,注意时钟依赖与性能边界。</p&g…...


Scroll Reverser:终极指南!解决macOS多设备滚动方向混乱的免费神器
Scroll Reverser:终极指南!解决macOS多设备滚动方向混乱的免费神器 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否在Mac上同时使用触控板和鼠标时…...
)
手把手教你用Kotlin实现一个完整的App Links跳转逻辑(含参数解析与场景处理)
手把手教你用Kotlin实现一个完整的App Links跳转逻辑(含参数解析与场景处理) 当用户在浏览器中点击一个链接时,如何让应用无缝跳转到对应页面?这背后离不开App Links技术的支持。不同于传统的Deep Link,App Links提供了…...

智能对话系统开发:从架构设计到生产部署
1. 构建智能对话系统的核心逻辑在开发一个真正实用的对话系统时,我们需要先理解其底层架构。现代对话系统通常由三个关键模块组成:自然语言理解(NLU)、对话管理(DM)和自然语言生成(NLG)。这就像人类对话时的"听懂-思考-回答"三个步骤。我见过很…...
)
告别手动标注!用CloudCompare的CANUPO插件,5分钟搞定点云自动分类(附最新.prm文件获取指南)
5分钟解锁点云智能分类:CloudCompare CANUPO插件实战指南 激光雷达点云数据分类一直是三维建模领域的痛点——传统手动标注方式不仅耗时费力,而且结果往往受主观因素影响。想象一下,面对数百万个无序点云,如何快速区分地面、植被…...

不止于画图:用GMT6脚本批量处理地形数据并添加自定义站点标记
不止于画图:用GMT6脚本批量处理地形数据并添加自定义站点标记 当监测站点数量从个位数跃升到上百个时,手动逐个标注坐标、调整图例的工作量会呈指数级增长。去年参与某地震监测项目时,我曾亲眼见证团队花费整整三天时间反复修改80多个台站的定…...

Boss-Key老板键:终极窗口隐身术,5秒保护你的数字隐私空间
Boss-Key老板键:终极窗口隐身术,5秒保护你的数字隐私空间 【免费下载链接】Boss-Key 老板来了?快用Boss-Key老板键一键隐藏静音当前窗口!上班摸鱼必备神器 项目地址: https://gitcode.com/gh_mirrors/bo/Boss-Key 你是否经…...

从Hystrix迁移到Sentinel:Spring Cloud微服务限流降级实战避坑指南
从Hystrix迁移到Sentinel:Spring Cloud微服务限流降级实战指南 微服务架构中,服务间的依赖关系错综复杂,一个服务的不可用可能导致级联故障,最终引发系统雪崩。作为保障系统稳定性的核心组件,熔断降级工具的选择直接影…...

2025届学术党必备的五大AI写作方案横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 用于辅助用户降低文本重复率从而提升原创性的降重网站得以存在,这类平台常常运用…...