从零开始学python(十六)爬虫集群部署
前言
今天讲述Python框架源码专题最后一个部分,爬虫集群部署,前面更新了十五个从零开始学python的系列文章,分别是:
1.编程语法必修篇
2.网络编程篇
3.多线程/多进程/协程篇
4.MySQL数据库篇
5.Redis数据库篇
6.MongoDB数据库篇
7.机器学习篇
8.全栈开发篇
9.Numpy/pandas/matplotlib篇
10.Hadoop篇
11.Spark篇
12.爬虫工程师篇
13.爬虫工程师自动化和抓包篇
14.scrapy框架篇
15.feapder框架篇
本系列文根据以下学习路线展开讲述:
从零开始学python到高级进阶路线图主页


适用于零基础学习和进阶人群的python资源:
① 腾讯认证python完整项目实战教程笔记PDF
② 十几个大厂python面试专题PDF
③ python全套视频教程(零基础-高级进阶JS逆向)
④ 百个项目实战+源码+笔记
⑤ 编程语法-机器学习-全栈开发-数据分析-爬虫-APP逆向等全套项目+文档
三丶爬虫集群部署
一丶scrapyd框架
1.环境部署
Scrapyd是一个基于Twisted的Python框架,用于部署和运行Scrapy爬虫。它提供了一个Web服务,可以通过API来管理Scrapy爬虫的部署和运行。在Scrapyd中,爬虫可以被打包成一个egg文件,然后通过API上传到Scrapyd服务器上进行部署和运行。
以下是Scrapyd框架环境部署的详细步骤:
安装Python和pip
Scrapyd是基于Python的框架,因此需要先安装Python和pip。可以从Python官网下载Python安装包,然后使用命令行安装pip。
安装Scrapy和Scrapyd
使用pip安装Scrapy和Scrapyd:
pip install scrapy
pip install scrapyd
配置Scrapyd
Scrapyd的配置文件位于/etc/scrapyd/scrapyd.conf。可以使用以下命令来编辑配置文件:
sudo nano /etc/scrapyd/scrapyd.conf
在配置文件中,可以设置Scrapyd的端口号、日志文件路径、爬虫项目路径等。
启动Scrapyd
使用以下命令启动Scrapyd:
scrapyd
Scrapyd将会在默认端口6800上启动。可以在浏览器中访问http://localhost:6800/来查看Scrapyd的Web界面。
部署Scrapy爬虫
将Scrapy爬虫打包成一个egg文件,然后使用以下命令将其部署到Scrapyd服务器上:
curl -F project=myproject -F spider=myspider \-F eggfile=@myproject.egg \http://localhost:6800/schedule.json -o result.json
其中,project和spider参数分别指定爬虫所在的项目和爬虫名称,eggfile参数指定要上传的egg文件路径,最后的URL是Scrapyd的API地址。
查看爬虫运行状态
可以在Scrapyd的Web界面上查看爬虫的运行状态。也可以使用以下命令来查看爬虫的运行日志:
curl http://localhost:6800/logs/myproject/myspider/001
其中,myproject和myspider分别是爬虫所在的项目和爬虫名称,001是爬虫运行的任务ID。
以上就是Scrapyd框架环境部署的详细步骤。
2.scrapyd API处理爬虫
Scrapyd是一个用于部署和运行Scrapy爬虫的Python框架,它提供了一个基于HTTP的API,可以通过API管理和控制爬虫的运行。通过Scrapyd API,你可以与Scrapyd服务器进行通信,发送指令来管理爬虫的启动、停止、查看爬虫状态等操作。
下面是对Scrapyd API处理爬虫的详细解释:
安装Scrapyd:
首先,需要安装Scrapyd框架。可以使用pip命令进行安装:pip install scrapyd
启动Scrapyd服务器:
使用命令scrapyd启动Scrapyd服务器。默认情况下,Scrapyd服务器将在6800端口上运行。
创建Scrapy爬虫:
在使用Scrapyd API之前,需要先创建一个Scrapy爬虫。可以使用Scrapy命令行工具创建一个新的爬虫项目,并编写爬虫代码。
部署爬虫:
在项目根目录下运行命令scrapyd-deploy,将爬虫部署到Scrapyd服务器上。这将会生成一个scrapy.cfg配置文件,并将项目上传到Scrapyd服务器。
使用Scrapyd API:
Scrapyd API提供了一系列接口用于管理爬虫,包括启动爬虫、停止爬虫、获取爬虫状态等。
-
启动爬虫:使用/schedule.json接口来启动一个爬虫。需要提供爬虫名称和可选的参数。例如:http://localhost:6800/schedule.json -d project=myproject -d spider=myspider
-
停止爬虫:使用/cancel.json接口可以停止正在运行的爬虫。需要提供爬虫任务的ID。例如:http://localhost:6800/cancel.json -d project=myproject -d job=12345
-
查看爬虫状态:使用/listjobs.json接口可以获取当前运行中的爬虫任务列表及其状态。例如:http://localhost:6800/listjobs.json?project=myproject
解析API响应:
Scrapyd API的响应是JSON格式的数据。可以使用Python的requests库或其他HTTP请求库来发送API请求,并解析返回的JSON数据。
通过Scrapyd API,你可以通过程序化的方式管理和控制Scrapy爬虫的运行。这使得你可以方便地远程启动和监控爬虫任务。
3.scrapyd多任务管理
在Scrapyd中,多任务管理是指同时运行和管理多个Scrapy爬虫任务的能力。Scrapyd提供了一组API和工具,可以轻松地管理多个爬虫任务,包括启动、停止、监视任务状态以及获取任务结果等。下面是对Scrapyd多任务管理的详细解释:
创建多个爬虫项目:
首先,你需要创建多个独立的Scrapy爬虫项目。每个项目都在独立的目录中,并具有自己的爬虫代码、配置文件和依赖项。
部署爬虫项目:
使用Scrapyd的部署工具(如scrapyd-deploy命令)将各个爬虫项目部署到Scrapyd服务器上。确保你为每个项目指定唯一的项目名称。
启动多个任务:
使用Scrapyd API的/schedule.json接口来启动多个任务。你可以通过发送多个HTTP请求,每个请求对应一个任务,来实现同时启动多个任务。在每个请求中,指定项目名称和要启动的爬虫名称。
监视任务状态:
使用Scrapyd API的/listjobs.json接口来获取当前运行中的任务列表及其状态。你可以周期性地发送API请求以获取最新的任务状态信息。根据任务状态,可以判断任务是正在运行、已完成还是出现错误。
获取任务结果:
当任务完成后,可以使用Scrapyd API的/listjobs.json接口或/jobq/{job_id}/items.json接口来获取任务的结果数据。这些接口将返回爬虫任务的输出数据,如爬取的数据项或日志信息。
停止任务:
如果需要停止正在运行的任务,可以使用Scrapyd API的/cancel.json接口。提供项目名称和任务ID,即可停止相应的任务。
通过Scrapyd的多任务管理能力,你可以同时运行和管理多个独立的爬虫任务。这使得你可以处理大规模的爬取任务,提高效率并降低管理成本。
二丶gerapy部署爬虫
1.gerapy环境搭建
Gerapy是一个基于Scrapy的分布式爬虫管理框架,可以方便地管理多个Scrapy爬虫,并提供了Web界面进行可视化操作。下面是Gerapy环境搭建的详细讲解:
安装Python
Gerapy是基于Python开发的,因此需要先安装Python。可以从官网下载Python安装包,也可以使用包管理工具进行安装。
安装Scrapy
Gerapy是基于Scrapy的,因此需要先安装Scrapy。可以使用pip进行安装:
pip install scrapy
安装Gerapy
可以使用pip进行安装:
pip install gerapy
安装Redis
Gerapy使用Redis作为分布式任务队列和数据存储,因此需要先安装Redis。可以从官网下载Redis安装包,也可以使用包管理工具进行安装。
配置Gerapy
Gerapy的配置文件位于~/.gerapy/config.json,可以使用以下命令进行初始化:
gerapy init
然后编辑~/.gerapy/config.json文件,配置Redis和Gerapy的用户名和密码等信息。
启动Gerapy
可以使用以下命令启动Gerapy:
gerapy
然后在浏览器中访问http://localhost:8000,输入用户名和密码登录Gerapy的Web界面。
创建Scrapy项目
在Gerapy的Web界面中,可以创建Scrapy项目,并在项目中创建爬虫。Gerapy会自动将爬虫添加到任务队列中,可以在Web界面中查看任务状态和日志。
2.gerapy服务器部署
安装Python和Scrapy
在服务器上安装Python和Scrapy,可以使用以下命令:
sudo apt-get update
sudo apt-get install python3 python3-pip
sudo pip3 install scrapy
安装Gerapy
使用以下命令安装Gerapy:
sudo pip3 install gerapy
初始化Gerapy
使用以下命令初始化Gerapy:
gerapy init
这将创建一个名为gerapy的文件夹,其中包含Gerapy的配置文件和其他必要文件。
配置Gerapy
在gerapy文件夹中,打开config.py文件,配置Gerapy的相关参数,例如数据库连接信息、管理员账号等。
启动Gerapy
使用以下命令启动Gerapy:
gerapy runserver
这将启动Gerapy的Web界面,可以在浏览器中访问http://localhost:8000来管理爬虫。
部署爬虫
在Gerapy的Web界面中,可以添加、编辑和删除爬虫,并且可以在多台服务器上部署爬虫,实现分布式爬取。
3.gerapy打包框架项目
Gerapy是一个基于Scrapy的分布式爬虫管理框架,可以方便地管理多个Scrapy爬虫,并提供了Web界面进行操作和监控。在实际项目中,我们可能需要将Gerapy打包成可执行文件,以便在其他机器上部署和运行。本文将介绍如何打包Gerapy框架项目。
安装pyinstaller
pyinstaller是一个用于将Python代码打包成可执行文件的工具,可以通过pip进行安装:
pip install pyinstaller
打包Gerapy
在Gerapy项目根目录下执行以下命令:
pyinstaller -F gerapy.spec
其中,gerapy.spec是一个配置文件,用于指定打包的参数和选项。如果没有该文件,可以通过以下命令生成:
pyinstaller --name=gerapy -y --clean --windowed --icon=gerapy.ico --add-data=gerapy.ico;. gerapy/__main__.py
该命令将生成一个名为gerapy的可执行文件,使用了以下参数和选项:
- –name:指定生成的可执行文件名为gerapy;
- -y:自动覆盖已存在的输出目录;
- –clean:在打包前清理输出目录;
- –windowed:生成窗口应用程序,不显示命令行窗口;
- –icon:指定应用程序图标;
- –add-data:将gerapy.ico文件打包到可执行文件中。
运行Gerapy
打包完成后,在dist目录下会生成一个名为gerapy的可执行文件。将该文件复制到其他机器上,即可在该机器上运行Gerapy框架项目。
三丶feapder部署
1.feapder应用场景和原理
Feapder是一个基于Python开发的轻量级分布式爬虫框架,旨在提供简单、易用且高效的爬虫解决方案。它具有以下应用场景和原理:
应用场景:
-
数据采集:Feapder可以用于从各种网站和数据源中采集数据。无论是爬取结构化数据还是非结构化数据,Feapder都提供了丰富的功能和灵活的配置选项来满足不同数据采集的需求。
-
网站监测:Feapder可以周期性地监测网站内容的变化,并及时提醒用户。这在需要实时监控目标网站的情况下非常有用,比如新闻更新、价格变动等。
-
数据清洗和处理:Feapder支持自定义处理函数和管道来对爬取的数据进行清洗和处理。你可以使用Feapder提供的数据处理功能,比如去重、编码转换、数据过滤等,将爬取的原始数据转化为可用的结构化数据。
-
数据存储和导出:Feapder提供了多种数据存储选项,包括数据库存储、文件存储和消息队列等。你可以根据需求选择适合的存储方式,并支持数据导出到各种格式,如CSV、JSON等。
原理解析:
Feapder的核心原理是基于分布式的异步任务调度和处理。以下是Feapder的原理解析:
-
分布式架构:Feapder使用分布式架构来提高爬取效率和可扩展性。任务调度和数据处理分布在多个节点上,每个节点可以独立运行爬虫任务,并通过消息队列进行通信和数据传输。
-
异步任务调度:Feapder使用异步任务调度框架(比如Celery)来实现任务的并发执行。每个爬虫任务都被封装为一个可执行的异步任务,可以独立运行在任务调度器中,并通过消息队列接收和发送任务相关的消息。
-
任务调度和监控:Feapder提供了任务调度和监控的功能,可以实时监控任务的状态、进度和错误信息。你可以通过Feapder的管理界面或API,对任务进行启动、停止、暂停和重新调度等操作,以及实时查看任务的日志和统计信息。
-
数据处理和存储:Feapder支持自定义的数据处理函数和处理管道,可以对爬取的数据进行清洗、转换和处理。同时,Feapder提供了多种数据存储选项,可以将处理后的数据存储到数据库、文件系统或消息队列中,并支持数据导出和导入。
总结来说,Feapder通过分布式异步任务调度和处理的方式,实现了高效、灵活和可扩展的爬虫框架。它的设计使得用户可以简单地配置和管理爬虫任务,并方便地进行数据处理和存储。无论是小规模的数据采集还是大规模的分布式爬虫任务,Feapder都是一个强大的选择。
2.feapder镜像拉取
feapder是一个基于Python的分布式爬虫框架,它可以帮助用户快速构建高效、稳定的爬虫系统。在使用feapder之前,需要先拉取feapder的镜像。
镜像拉取命令如下:
docker pull feapder/feapder
这个命令会从Docker Hub上拉取feapder的最新版本镜像。拉取完成后,可以使用以下命令查看已经拉取的镜像:
docker images
feapder的镜像包含了所有需要的依赖和配置,可以直接使用。在使用feapder时,可以通过Docker运行feapder镜像,也可以将镜像部署到Kubernetes集群中。
使用Docker运行feapder镜像的命令如下:
docker run -it --name feapder feapder/feapder
这个命令会在Docker容器中启动feapder,并进入容器的交互式终端。在容器中可以使用feapder提供的命令行工具来创建、管理爬虫任务。
总之,feapder的镜像拉取非常简单,只需要执行一条命令即可。同时,feapder的镜像也非常方便使用,可以直接在Docker容器中运行,也可以部署到Kubernetes集群中。
3.docker部署feapder部署环境
feapder是一个基于Python的分布式爬虫框架,可以用于快速开发各种类型的爬虫。在使用feapder时,可以选择使用docker进行部署,以便更方便地管理和部署爬虫。
以下是使用docker部署feapder的详细步骤:
安装docker和docker-compose
在开始之前,需要先安装docker和docker-compose。可以参考官方文档进行安装。
拉取feapder镜像
可以使用以下命令从Docker Hub上拉取feapder镜像:
docker pull feapder/feapder
创建docker-compose.yml文件
在本地创建一个docker-compose.yml文件,用于定义feapder的容器和相关配置。以下是一个示例文件:
version: '3'services:redis:image: redis:latestports:- "6379:6379"volumes:- ./redis-data:/datamysql:image: mysql:latestenvironment:MYSQL_ROOT_PASSWORD: rootMYSQL_DATABASE: feapderports:- "3306:3306"volumes:- ./mysql-data:/var/lib/mysqlfeapder:image: feapder/feapderenvironment:- REDIS_HOST=redis- MYSQL_HOST=mysql- MYSQL_USER=root- MYSQL_PASSWORD=root- MYSQL_DATABASE=feapdervolumes:- ./feapder-data:/app/datadepends_on:- redis- mysql
在这个文件中,定义了三个服务:redis、mysql和feapder。其中,redis和mysql分别用于存储爬虫的任务队列和数据,feapder则是爬虫的运行环境。
启动容器
在本地的项目目录下,运行以下命令启动容器:
docker-compose up -d
这个命令会启动所有定义在docker-compose.yml文件中的服务,并在后台运行。
进入feapder容器
可以使用以下命令进入feapder容器:
docker exec -it feapder_feapder_1 /bin/bash
其中,feapder_feapder_1是容器的名称,可以使用docker ps命令查看。
运行爬虫
在feapder容器中,可以使用feapder命令来运行爬虫。例如,可以使用以下命令运行一个简单的爬虫:
feapder run spider demo
这个命令会运行名为demo的爬虫。
以上就是使用docker部署feapder的详细步骤。通过使用docker,可以更方便地管理和部署feapder爬虫。
4.feapder部署scrapy项目
Feapder是基于Scrapy框架开发的分布式爬虫框架,因此部署Feapder项目也需要先部署Scrapy项目。下面是部署Scrapy项目的详细步骤:
1. 创建Scrapy项目
使用Scrapy命令行工具创建一个新的Scrapy项目,例如:
scrapy startproject myproject
2. 编写Spider
在Scrapy项目中,Spider是爬虫的核心部分,负责定义如何抓取网站的数据。在Scrapy项目中,Spider通常是一个Python类,需要继承Scrapy提供的Spider类,并实现一些必要的方法。
例如,下面是一个简单的Spider示例:
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://www.example.com']def parse(self, response):# 解析网页内容pass
3. 配置Scrapy项目
Scrapy项目的配置文件是settings.py,其中包含了一些Scrapy的配置选项,例如爬虫的User-Agent、下载延迟等等。在配置文件中,还可以设置Scrapy使用的中间件、管道等等。
例如,下面是一个简单的配置文件示例:
BOT_NAME = 'myproject'SPIDER_MODULES = ['myproject.spiders']
NEWSPIDER_MODULE = 'myproject.spiders'USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'DOWNLOAD_DELAY = 3ITEM_PIPELINES = {'myproject.pipelines.MyPipeline': 300,
}
4. 运行Spider
使用Scrapy命令行工具运行Spider,例如:
scrapy crawl myspider
以上就是部署Scrapy项目的详细步骤。在部署Feapder项目时,可以将Scrapy项目作为Feapder的一个子项目,然后在Feapder中调用Scrapy项目的Spider来完成具体的爬取任务。

适用于零基础学习和进阶人群的python资源:
① 腾讯认证python完整项目实战教程笔记PDF
② 十几个大厂python面试专题PDF
③ python全套视频教程(零基础-高级进阶JS逆向)
④ 百个项目实战+源码+笔记
⑤ 编程语法-机器学习-全栈开发-数据分析-爬虫-APP逆向等全套项目+文档
相关文章:
从零开始学python(十六)爬虫集群部署
前言 今天讲述Python框架源码专题最后一个部分,爬虫集群部署,前面更新了十五个从零开始学python的系列文章,分别是: 1.编程语法必修篇 2.网络编程篇 3.多线程/多进程/协程篇 4.MySQL数据库篇 5.Redis数据库篇 6.MongoDB数据库篇 …...

flutter
1.dart语言基础 数据类型 //fluttenum a 10;double b 10.0;int x 10;num c 10.0;//字符串拼接方式。和kotlin的是一样的。 也可以和java中一样做拼接。String testString "aaaaaaaaaaaaaaaaaaaaaaaaaaaa";String bbbbb "aaaaaaaaaaaaaaccccc";S…...

iOS 开发-编译第三方库 openssl及curl
1、前提 iOS编译库需要三个架构,arm64,arm64e,x86_64,其中x86_64为模拟器所需 iOS编译库需要下载xcode及对应的command line tool(执行命令时可以自动下载),下载失败需要去官网搜索下载 2、openssl 参考iOS如何编译OpenSSL静态…...
运维监控学习笔记1
1、监控对象: 1、监控对象的理解;CPU是怎么工作的; 2、监控对象的指标:CPU使用率;上下文切换; 3、确定性能基准线:CPU负载多少才算高; 2、监控范围: 1、硬件监控&#x…...

由于找不到vcruntime140.dll,无法继续执行代码,三种修复方法
为什么我们很多人都遇到过打开电脑软件时候突然电脑就提示找不到vcruntime140.dll,或许vcruntime140.dll丢失,那么vcruntime140.dll到底是什么?为什么会丢失,丢失了要怎么解决修复呢?下面小编都会一一介绍给大家&#…...

【FPGA零基础学习之旅#10】按键消抖模块设计与验证(一段式状态机实现)
🎉欢迎来到FPGA专栏~按键消抖模块设计与验证 ☆* o(≧▽≦)o *☆嗨~我是小夏与酒🍹 ✨博客主页:小夏与酒的博客 🎈该系列文章专栏:FPGA学习之旅 文章作者技术和水平有限,如果文中出现错误,希望大…...
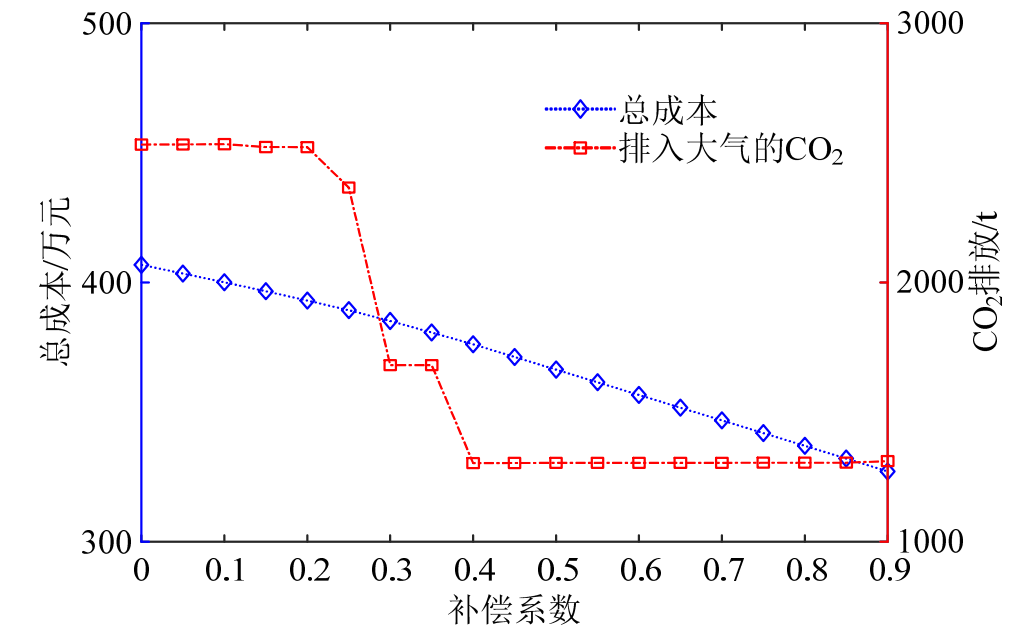
【EI复现】基于阶梯碳交易的含P2G-CCS耦合和燃气掺氢的虚拟电厂优化调度(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

高防cdn和高防服务器有什么不一样?
高防cdn: 相信很多看过我们文章的小伙伴对cdn已经很了解了,cdn的原理很简单,就是构建在网络上的很多个节点,为网站作内容 分发。使用户就近获取所需资源。且分配的cdn节点都是高防节点,每个节点都有防御功能。还…...
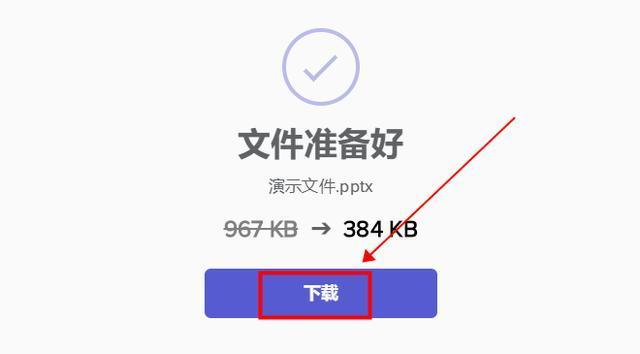
ppt怎么压缩?试试这样压缩文件
当PPT文件体积过大时,打开的速度就会很慢,演示的时候刘程度也会受到影响,其次,现在很多平台对于上传的文件是有大小限制的,比如超过100M的文件就无法上传、发送等等,那么,怎么才能压缩PPT文件呢…...
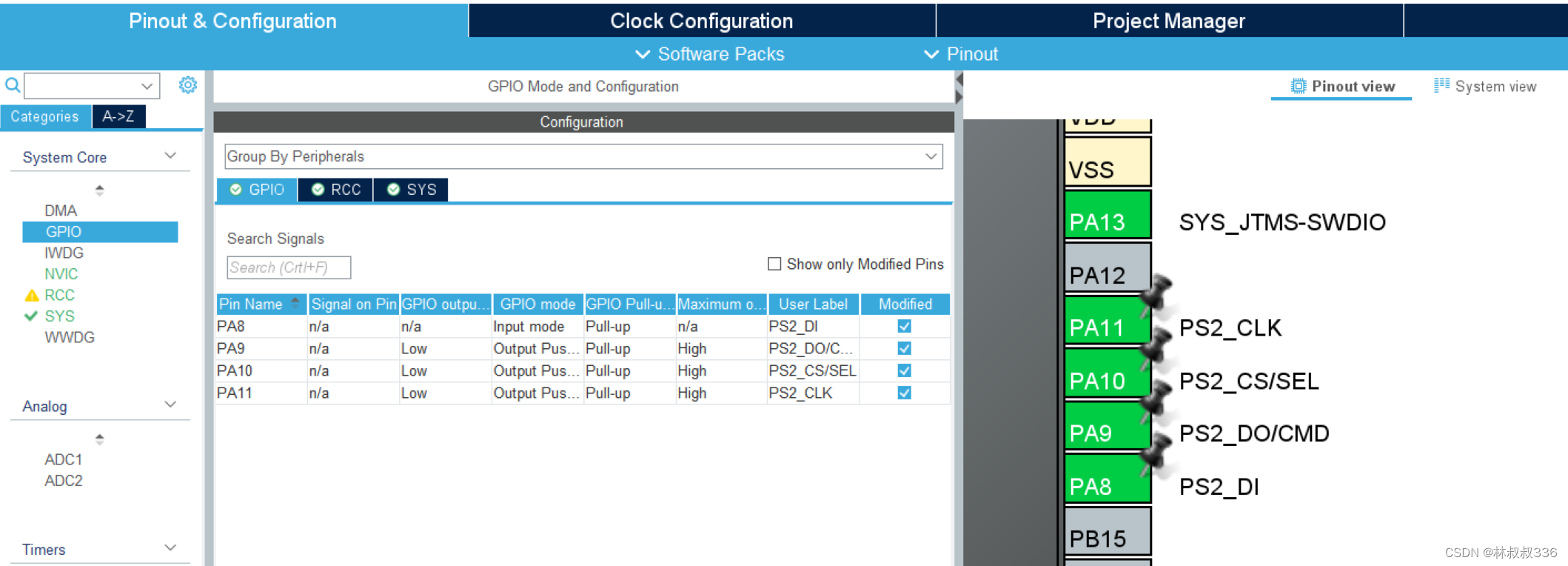
stm32 cubemx ps2无线(有线)手柄
文章目录 前言一、cubemx配置二、代码1.引入库bsp_hal_ps2.cbsp_hal_ps2.h 2.主函数 前言 本文讲解使用cubemx配置PS2手柄实现对手柄的按键和模拟值的读取。 很简单,库已经封装好了,直接就可以了。 文件 一、cubemx配置 这个很简单,不需要…...
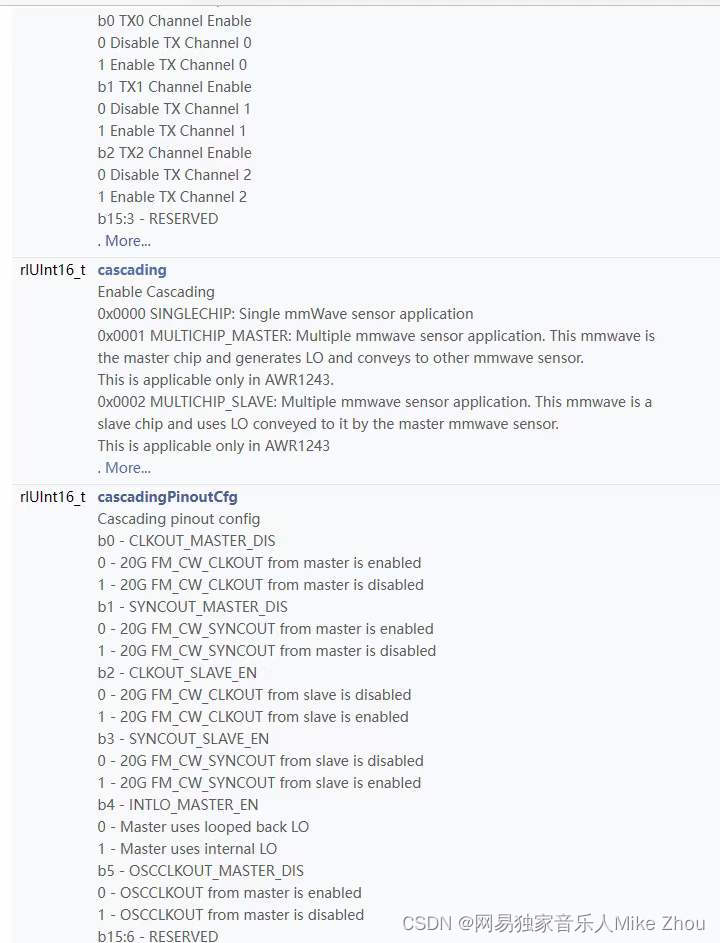
【TI毫米波雷达笔记】sdk传参时的type避坑
【TI毫米波雷达笔记】sdk传参时的type避坑 这个函数要传一个结构体进去 然后结构体里面有个adcoutcfg结构体变量 adcoutcfg结构体里面共有三个变量 一个adcbitformat结构体 另外两保留 点开adcbitformat结构体发现是个32位段 一共四级结构体 那么请问 为什么adcoutcfg变量不直…...

【算法挨揍日记】day02——双指针算法_快乐数、盛最多水的容器
202. 快乐数 202. 快乐数https://leetcode.cn/problems/happy-number/ 题目: 编写一个算法来判断一个数 n 是不是快乐数。 「快乐数」 定义为: 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。然后重复这个过程直到这个…...

【Hilog】鸿蒙系统日志源码分析
【Hilog】鸿蒙系统日志源码分析 Hilog采用C/S结构,Hilogd作为服务端提供日志功能。Client端通过API调用(最终通过socket通讯)与HiLogd打交道。简易Block图如下。 这里主要分析一下。Hilog的读、写、压缩落盘,以及higlog与android…...

keil下载程序具体过程4:flash下载算法
引言 本篇文章将介绍flash算法文件,阐述从jlink如何下载镜像文件写入到内部的falsh。 一、XIP 在谈flash下载算法文件时,先说明XIP是什么。 芯片的启动方式有很多种:可以从RAM中启动、内部的flash、外部的flash等等(还有从sd卡、…...

如何快速的让自己从月入2000变成月入两万?
从月入2000变成月入两万 前言我们可以这么做:1.提升自己的技能:2.寻找更好的工作机会:寻找更好的工作机会是一个重要的目标,以下是几个建议: 3.开展副业或兼职工作:4.创业或投资:5.构建个人品牌…...

使用 CycleGAN 进行图像到图像转换
介绍 在人工智能和计算机视觉领域,CycleGAN 是一项非凡的创新,它重新定义了我们感知和操作图像的方式。这种尖端技术彻底改变了图像到图像的转换,实现了领域之间的无缝转换,例如将马变成斑马或将夏日风景变成雪景。在本文中,我们将揭开 CycleGAN 的魔力,并探索其在各个领…...

Svg使用和注册components文件夹内部全部为全局组件
1.安装SVG依赖插件 pnpm install vite-plugin-svg-icons -D 2. 封装SvgIcon <template><div><svg :style"{ width: width, height: height }"><use :xlink:href"prefix name" :fill"color"></use></svg>…...
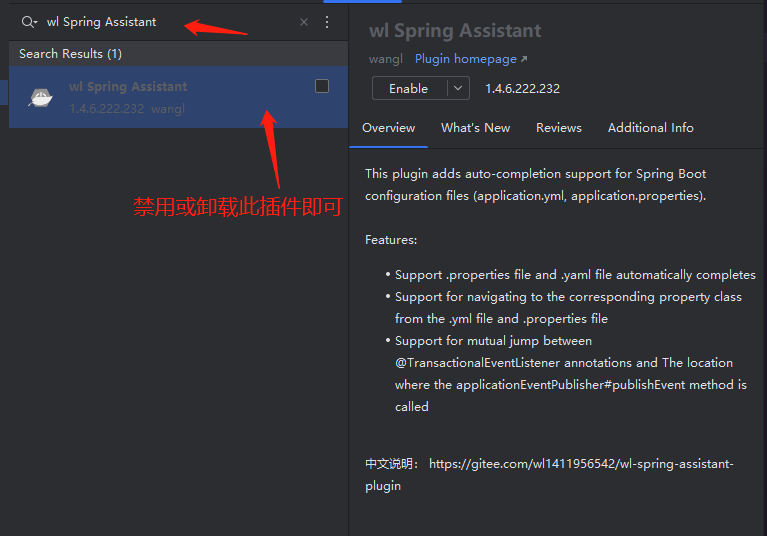
解决idea编辑application.yml文件或properties文件没有提示问题
注意:这里说的没有提示,是针对application.properties和application.yml文件 解决办法:在idea的插件面板中,禁用或卸载 wl Spring Assistant插件即可解决问题。...
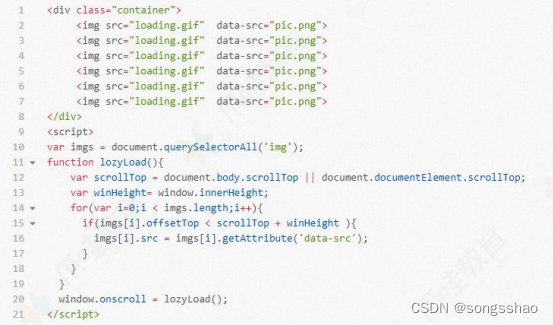
前端懒加载
懒加载的概念 懒加载也叫做延迟加载、按需加载,指的是在长网页中延迟加载图片数据,是一种较好的网页性能优化的方式。在比较长的网页或应用中,如果图片很多,所有的图片都被加载出来,而用户只能看到可视窗口的那一部分…...

【手动配置ip地址后,电脑仍自动分配ip的问题】
现象 手动给电脑分配了一个ipv4地址,但是电脑会自动分配一个169开头的ipv4,导致虽然可以上网,但访问不了局域网内其他的设备(我配置的另一个网关,所以可以上网) 原因 ip地址冲突了,把电脑的i…...

DeepSeek V4 这周发!梁文锋扛不住了
这几天两个事:DeepSeek 首轮融资来了,目标3亿美金,估值100亿美金;另一个就是,一位接近DeepSeek的业内人士说,V4 预计本周发布。下面就来聊聊。据外媒 The Information 报道,DeepSeek 正在与投资…...

告别重复操作:MAA明日方舟助手如何帮你找回游戏乐趣
告别重复操作:MAA明日方舟助手如何帮你找回游戏乐趣 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://gitco…...
)
别再手动调参了!用Auto Lidar2Cam Calibration搞定相机雷达标定(附ROS Melodic + Gazebo9避坑指南)
自动驾驶开发者的福音:Auto Lidar2Cam Calibration全流程实战解析 当激光雷达点云与相机图像无法完美对齐时,整个感知系统就像近视眼没戴眼镜——模糊不清。传统手动标定不仅耗时费力,结果还常常差强人意。Auto Lidar2Cam Calibration的出现&…...

【RAGFlow】如何通过API查询知识库内容
import requests import jsondata \{"dataset_ids": ["617892ce3d2111f1835f373a6cab5d12"],"question": "快乐8游戏中,总共有多少个号码?","top_k": 3}# 发送http请求 header {"Content-Type…...

Java NIO 与异步 IO 对比
Java NIO与异步IO对比:高并发场景下的技术选型 在当今高并发的网络应用中,如何高效处理I/O操作成为开发者关注的核心问题。Java NIO(Non-blocking I/O)和异步IO(如AIO)是两种主流的解决方案,它…...

染色设备数据采集远程监控系统方案
当前,纺织厂染色车间虽已实现PLC控制的自动化生产,涵盖化料、配料、加料及pH自动调节等环节,生产效率显著提升。但设备运行状态仍依赖人工巡检,pH、温度等关键工艺参数需定时抄录,最终再录入车间管理系统。此种模式存在…...

如何5步搞定RTAB-Map多相机视觉对齐:新手的完整实战指南
如何5步搞定RTAB-Map多相机视觉对齐:新手的完整实战指南 【免费下载链接】rtabmap RTAB-Map library and standalone application 项目地址: https://gitcode.com/gh_mirrors/rt/rtabmap RTAB-Map是一个强大的实时定位与建图开源库,特别擅长处理多…...

如何在浏览器中直接打开PPT文件:PPTXjs完整使用指南
如何在浏览器中直接打开PPT文件:PPTXjs完整使用指南 【免费下载链接】PPTXjs jquery plugin for convertation pptx to html 项目地址: https://gitcode.com/gh_mirrors/pp/PPTXjs 你是否曾经遇到过需要查看PPT文件,但电脑上没有安装Office软件的…...
)
别再折腾OpenVPN了!用Ubuntu 22.04 LTS快速搭建PPTP服务器(附Windows 11连接全流程)
Ubuntu 22.04 LTS下轻量级网络连接的替代方案 在远程办公和跨地域协作日益普遍的今天,安全稳定的网络连接成为刚需。虽然市场上有各种复杂的解决方案,但对于个人开发者和小型团队而言,往往需要的是快速部署、简单配置且资源占用低的连接方式。…...

HS2-HF_Patch:如何为《Honey Select 2》打造完整的本地化与功能增强体验?
HS2-HF_Patch:如何为《Honey Select 2》打造完整的本地化与功能增强体验? 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 如果你正在玩《…...