机器学习基础之《特征工程(4)—特征降维》
一、什么是特征降维
降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程
1、降维
降低维度
ndarry
维数:嵌套的层数
0维:标量,具体的数0 1 2 3...
1维:向量
2维:矩阵
3维:多个二维数组嵌套
n维:继续嵌套下去
2、特征降维降的是什么
降的是二维数组,特征是几行几列的,几行有多少样本,几列有多少特征
降低特征的个数(就是列数)
二、降维的两种方式
1、特征选择
2、主成分分析(可以理解一种特征提取的方式)
三、什么是特征选择
1、定义
数据中包含冗余或相关变量(或称特征、属性、指标等),旨在从原有特征中找出主要特征
2、例子:想要对鸟进行类别的区分
特征?
(1)羽毛颜色
(2)眼睛宽度
(3)眼睛长度
(4)爪子长度
(5)体格大小
比如还有的特征:是否有羽毛、是否有爪子,那这些特征就没有意义
3、方法
Filter(过滤式):主要探究特征本身特点、特征与特征和目标值之间关联
(1)方差选择法:低方差特征过滤,过滤掉方差比较低的特征
(2)相关系数:特征与特征之间的相关程度
(3)方差选择法在文本分类中表现非常不好,对噪声的处理能力几乎为0,还删除了有用的特征
Embedded(嵌入式):算法自动选择特征(特征与目标值之间的关联)
(1)决策树:信息熵、信息增益
(2)正则化:L1、L2
(3)深度学习:卷积等
(4)对于Embedded方式,只能在讲解算法的时候再进行介绍,更好的去理解
4、模块
sklearn.feature_selection
四、低方差特征过滤
1、删除低方差的一些特征,前面讲过方差的意义。再结合方差的大小来考虑这个方式的角度
(1)特征方差小:某个特征大多样本的值比较相近
(2)特征方差大:某个特征很多样本的值都有差别
2、API
sklearn.feature_selection.VarianceThreshold(threshold = 0.0)
删除所有低方差特征,设置一个临界值,低于临界值的都删掉
Variance:方差
Threshold:阈值
3、Variance.fit_transform(X)
X:numpy array格式的数据[n_samples, n_features]
返回值:训练集差异低于threshold的特征将被删除。默认值是保留所有非零方差特征,即删除所有样本中具有相同值的特征
4、数据计算
我们对某些股票的指标特征之间进行一个筛选,数据在factor_returns.csv文件当中,除去index、date、return列不考虑(这些类型不匹配,也不是所需要的指标)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.feature_selection import VarianceThreshold
import jieba
import pandas as pddef datasets_demo():"""sklearn数据集使用"""#获取数据集iris = load_iris()print("鸢尾花数据集:\n", iris)print("查看数据集描述:\n", iris["DESCR"])print("查看特征值的名字:\n", iris.feature_names)print("查看特征值几行几列:\n", iris.data.shape)#数据集的划分x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)print("训练集的特征值:\n", x_train, x_train.shape)return Nonedef dict_demo():"""字典特征抽取"""data = [{'city': '北京','temperature':100},{'city': '上海','temperature':60},{'city': '深圳','temperature':30}]# 1、实例化一个转换器类transfer = DictVectorizer(sparse=False)# 2、调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new)print("特征名字:\n", transfer.get_feature_names())return Nonedef count_demo():"""文本特征抽取"""data = ["life is short,i like like python", "life is too long,i dislike python"]# 1、实例化一个转换器类transfer = CountVectorizer()# 2、调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new.toarray())print("特征名字:\n", transfer.get_feature_names()) return Nonedef count_chinese_demo():"""中文文本特征抽取"""data = ["我 爱 北京 天安门", "天安门 上 太阳 升"]# 1、实例化一个转换器类transfer = CountVectorizer()# 2、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new.toarray());print("特征名字:\n", transfer.get_feature_names())return Nonedef cut_word(text):"""进行中文分词"""return " ".join(list(jieba.cut(text))) #返回一个分词生成器对象,强转成list,再join转成字符串def count_chinese_demo2():"""中文文本特征抽取,自动分词"""# 1、将中文文本进行分词data = ["今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年前之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]data_new = []for sent in data:data_new.append(cut_word(sent))print(data_new)# 2、实例化一个转换器类transfer = CountVectorizer()# 3、调用fit_transform()data_final = transfer.fit_transform(data_new)print("data_final:\n", data_final.toarray())print("特征名字:\n", transfer.get_feature_names())return Nonedef tfidf_demo():"""用tf-idf的方法进行文本特征抽取"""# 1、将中文文本进行分词data = ["今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年前之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]data_new = []for sent in data:data_new.append(cut_word(sent))print(data_new)# 2、实例化一个转换器类transfer = TfidfVectorizer()# 3、调用fit_transform()data_final = transfer.fit_transform(data_new)print("data_final:\n", data_final.toarray())print("特征名字:\n", transfer.get_feature_names())return Nonedef minmax_demo():"""归一化"""# 1、获取数据data = pd.read_csv("dating.txt")#print("data:\n", data)data = data.iloc[:, 0:3] #行都要,列取前3列print("data:\n", data)# 2、实例化一个转换器transfer = MinMaxScaler()# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return Nonedef stand_demo():"""标准化"""# 1、获取数据data = pd.read_csv("dating.txt")#print("data:\n", data)data = data.iloc[:, 0:3] #行都要,列取前3列print("data:\n", data)# 2、实例化一个转换器transfer = StandardScaler()# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return Nonedef variance_demo():"""过滤低方差特征"""# 1、获取数据data = pd.read_csv("factor_returns.csv")#print("data:\n", data)data = data.iloc[:, 1:-2]print("data:\n", data)# 2、实例化一个转换器类transfer = VarianceThreshold(threshold=3)# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new, data_new.shape)return Noneif __name__ == "__main__":# 代码1:sklearn数据集使用#datasets_demo()# 代码2:字典特征抽取#dict_demo()# 代码3:文本特征抽取#count_demo()# 代码4:中文文本特征抽取#count_chinese_demo()# 代码5:中文文本特征抽取,自动分词#count_chinese_demo2()# 代码6: 测试jieba库中文分词#print(cut_word("我爱北京天安门"))# 代码7:用tf-idf的方法进行文本特征抽取#tfidf_demo()# 代码8:归一化#minmax_demo()# 代码9:标准化#stand_demo()# 代码10:低方差特征过滤variance_demo()
运行结果:
data:pe_ratio pb_ratio market_cap return_on_asset_net_profit du_return_on_equity ev earnings_per_share revenue total_expense
0 5.9572 1.1818 8.525255e+10 0.8008 14.9403 1.211445e+12 2.0100 2.070140e+10 1.088254e+10
1 7.0289 1.5880 8.411336e+10 1.6463 7.8656 3.002521e+11 0.3260 2.930837e+10 2.378348e+10
2 -262.7461 7.0003 5.170455e+08 -0.5678 -0.5943 7.705178e+08 -0.0060 1.167983e+07 1.203008e+07
3 16.4760 3.7146 1.968046e+10 5.6036 14.6170 2.800916e+10 0.3500 9.189387e+09 7.935543e+09
4 12.5878 2.5616 4.172721e+10 2.8729 10.9097 8.124738e+10 0.2710 8.951453e+09 7.091398e+09
... ... ... ... ... ... ... ... ... ...
2313 25.0848 4.2323 2.274800e+10 10.7833 15.4895 2.784450e+10 0.8849 1.148170e+10 1.041419e+10
2314 59.4849 1.6392 2.281400e+10 1.2960 2.4512 3.810122e+10 0.0900 1.731713e+09 1.089783e+09
2315 39.5523 4.0052 1.702434e+10 3.3440 8.0679 2.420817e+10 0.2200 1.789082e+10 1.749295e+10
2316 52.5408 2.4646 3.287910e+10 2.7444 2.9202 3.883803e+10 0.1210 6.465392e+09 6.009007e+09
2317 14.2203 1.4103 5.911086e+10 2.0383 8.6179 2.020661e+11 0.2470 4.509872e+10 4.132842e+10[2318 rows x 9 columns]
data_new:[[ 5.95720000e+00 1.18180000e+00 8.52525509e+10 ... 1.21144486e+122.07014010e+10 1.08825400e+10][ 7.02890000e+00 1.58800000e+00 8.41133582e+10 ... 3.00252062e+112.93083692e+10 2.37834769e+10][-2.62746100e+02 7.00030000e+00 5.17045520e+08 ... 7.70517753e+081.16798290e+07 1.20300800e+07]...[ 3.95523000e+01 4.00520000e+00 1.70243430e+10 ... 2.42081699e+101.78908166e+10 1.74929478e+10][ 5.25408000e+01 2.46460000e+00 3.28790988e+10 ... 3.88380258e+106.46539204e+09 6.00900728e+09][ 1.42203000e+01 1.41030000e+00 5.91108572e+10 ... 2.02066110e+114.50987171e+10 4.13284212e+10]] (2318, 8)
五、相关系数
1、皮尔逊相关系数(Pearson Correlation Coefficient)
反映变量之间相关关系密切程度的统计指标
2、公式计算案例
(1)公式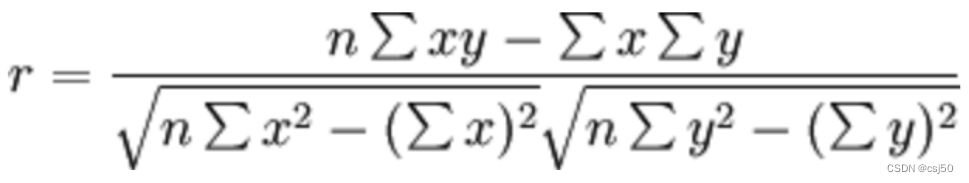
(2)比如说我们计算年广告费投入与月均销售额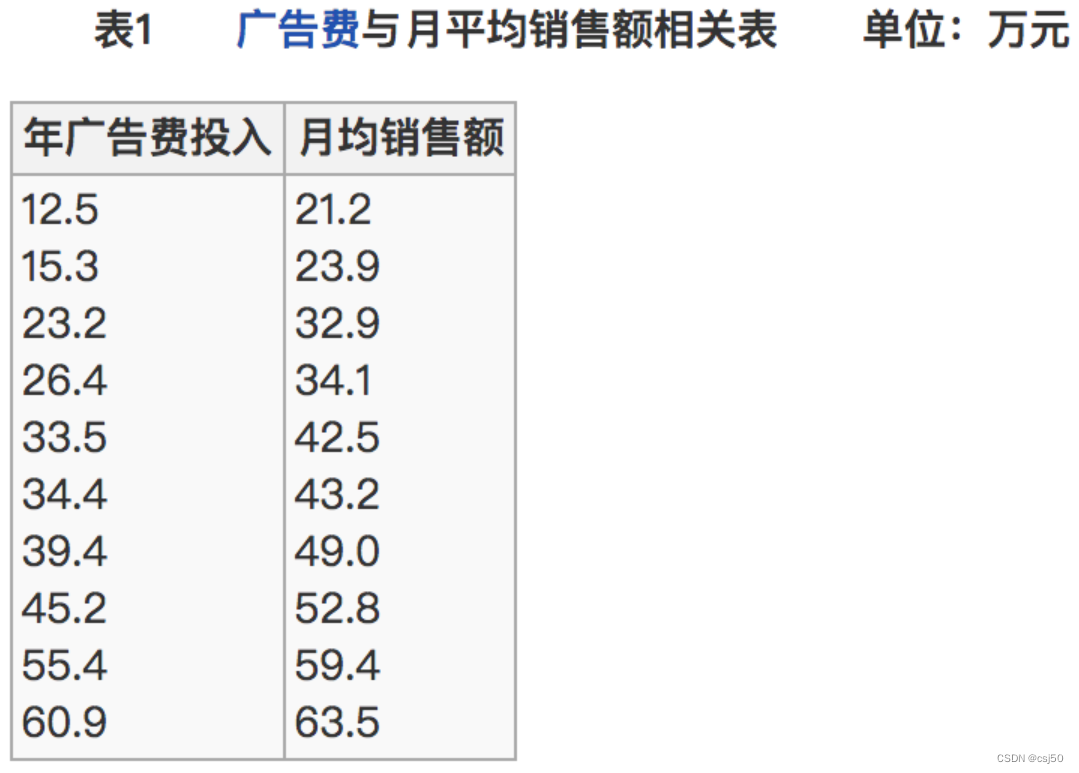
(3)那么之间的相关系数怎么计算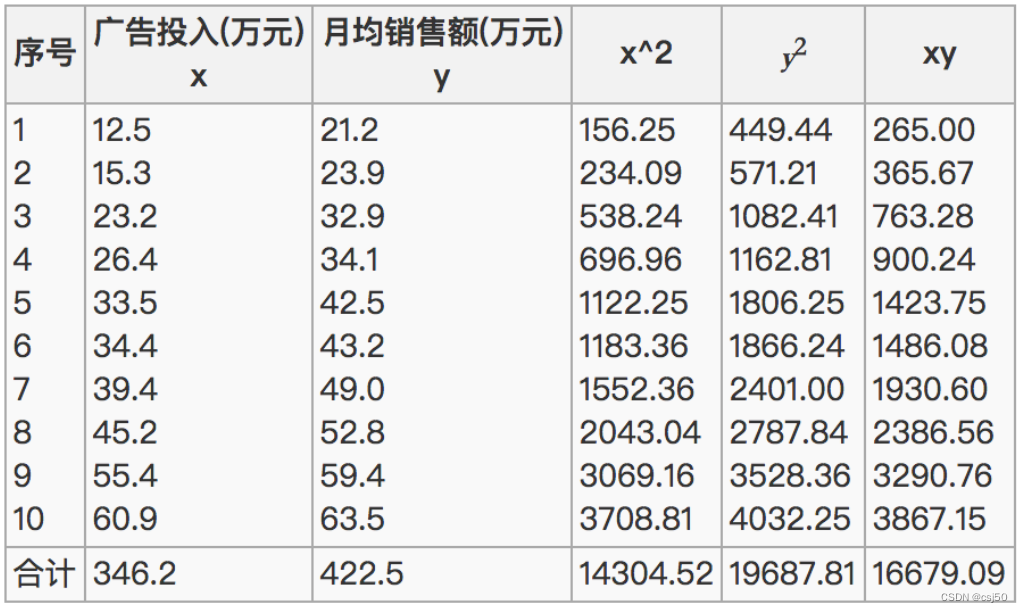
(4)最终计算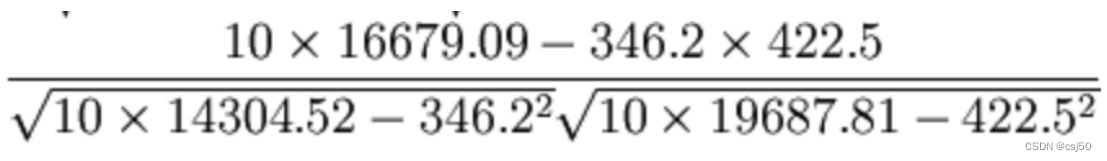
(5)结果=0.9942
所以我们最终得出结论是广告投入费与月平均销售额之间有高度的正相关关系
4、API
from scipy.stats import pearsonr
X:(N,) array_like
Y:(N,) array_like
Returns:(Pearson’s correlation coefficient, p-value),返回值是两个
注:pandas上面也有这个求相关系数的方法
5、案例:股票的财务指标相关性计算
计算某两个变量之间的相关系数
data [ ] 里面的关键字要用你自己表里面的列名
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.feature_selection import VarianceThreshold
from scipy.stats import pearsonr
import jieba
import pandas as pddef datasets_demo():"""sklearn数据集使用"""#获取数据集iris = load_iris()print("鸢尾花数据集:\n", iris)print("查看数据集描述:\n", iris["DESCR"])print("查看特征值的名字:\n", iris.feature_names)print("查看特征值几行几列:\n", iris.data.shape)#数据集的划分x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)print("训练集的特征值:\n", x_train, x_train.shape)return Nonedef dict_demo():"""字典特征抽取"""data = [{'city': '北京','temperature':100},{'city': '上海','temperature':60},{'city': '深圳','temperature':30}]# 1、实例化一个转换器类transfer = DictVectorizer(sparse=False)# 2、调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new)print("特征名字:\n", transfer.get_feature_names())return Nonedef count_demo():"""文本特征抽取"""data = ["life is short,i like like python", "life is too long,i dislike python"]# 1、实例化一个转换器类transfer = CountVectorizer()# 2、调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new.toarray())print("特征名字:\n", transfer.get_feature_names()) return Nonedef count_chinese_demo():"""中文文本特征抽取"""data = ["我 爱 北京 天安门", "天安门 上 太阳 升"]# 1、实例化一个转换器类transfer = CountVectorizer()# 2、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new.toarray());print("特征名字:\n", transfer.get_feature_names())return Nonedef cut_word(text):"""进行中文分词"""return " ".join(list(jieba.cut(text))) #返回一个分词生成器对象,强转成list,再join转成字符串def count_chinese_demo2():"""中文文本特征抽取,自动分词"""# 1、将中文文本进行分词data = ["今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年前之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]data_new = []for sent in data:data_new.append(cut_word(sent))print(data_new)# 2、实例化一个转换器类transfer = CountVectorizer()# 3、调用fit_transform()data_final = transfer.fit_transform(data_new)print("data_final:\n", data_final.toarray())print("特征名字:\n", transfer.get_feature_names())return Nonedef tfidf_demo():"""用tf-idf的方法进行文本特征抽取"""# 1、将中文文本进行分词data = ["今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年前之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]data_new = []for sent in data:data_new.append(cut_word(sent))print(data_new)# 2、实例化一个转换器类transfer = TfidfVectorizer()# 3、调用fit_transform()data_final = transfer.fit_transform(data_new)print("data_final:\n", data_final.toarray())print("特征名字:\n", transfer.get_feature_names())return Nonedef minmax_demo():"""归一化"""# 1、获取数据data = pd.read_csv("dating.txt")#print("data:\n", data)data = data.iloc[:, 0:3] #行都要,列取前3列print("data:\n", data)# 2、实例化一个转换器transfer = MinMaxScaler()# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return Nonedef stand_demo():"""标准化"""# 1、获取数据data = pd.read_csv("dating.txt")#print("data:\n", data)data = data.iloc[:, 0:3] #行都要,列取前3列print("data:\n", data)# 2、实例化一个转换器transfer = StandardScaler()# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return Nonedef variance_demo():"""过滤低方差特征"""# 1、获取数据data = pd.read_csv("factor_returns.csv")#print("data:\n", data)data = data.iloc[:, 1:-2]print("data:\n", data)# 2、实例化一个转换器类transfer = VarianceThreshold(threshold=3)# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new, data_new.shape)# 4、计算某两个变量之间的相关系数r = pearsonr(data["pe_ratio"], data["pb_ratio"])print("相关系数:\n", r)return Noneif __name__ == "__main__":# 代码1:sklearn数据集使用#datasets_demo()# 代码2:字典特征抽取#dict_demo()# 代码3:文本特征抽取#count_demo()# 代码4:中文文本特征抽取#count_chinese_demo()# 代码5:中文文本特征抽取,自动分词#count_chinese_demo2()# 代码6: 测试jieba库中文分词#print(cut_word("我爱北京天安门"))# 代码7:用tf-idf的方法进行文本特征抽取#tfidf_demo()# 代码8:归一化#minmax_demo()# 代码9:标准化#stand_demo()# 代码10:低方差特征过滤variance_demo()运行结果:
data:pe_ratio pb_ratio market_cap return_on_asset_net_profit du_return_on_equity ev earnings_per_share revenue total_expense
0 5.9572 1.1818 8.525255e+10 0.8008 14.9403 1.211445e+12 2.0100 2.070140e+10 1.088254e+10
1 7.0289 1.5880 8.411336e+10 1.6463 7.8656 3.002521e+11 0.3260 2.930837e+10 2.378348e+10
2 -262.7461 7.0003 5.170455e+08 -0.5678 -0.5943 7.705178e+08 -0.0060 1.167983e+07 1.203008e+07
3 16.4760 3.7146 1.968046e+10 5.6036 14.6170 2.800916e+10 0.3500 9.189387e+09 7.935543e+09
4 12.5878 2.5616 4.172721e+10 2.8729 10.9097 8.124738e+10 0.2710 8.951453e+09 7.091398e+09
... ... ... ... ... ... ... ... ... ...
2313 25.0848 4.2323 2.274800e+10 10.7833 15.4895 2.784450e+10 0.8849 1.148170e+10 1.041419e+10
2314 59.4849 1.6392 2.281400e+10 1.2960 2.4512 3.810122e+10 0.0900 1.731713e+09 1.089783e+09
2315 39.5523 4.0052 1.702434e+10 3.3440 8.0679 2.420817e+10 0.2200 1.789082e+10 1.749295e+10
2316 52.5408 2.4646 3.287910e+10 2.7444 2.9202 3.883803e+10 0.1210 6.465392e+09 6.009007e+09
2317 14.2203 1.4103 5.911086e+10 2.0383 8.6179 2.020661e+11 0.2470 4.509872e+10 4.132842e+10[2318 rows x 9 columns]
data_new:[[ 5.95720000e+00 1.18180000e+00 8.52525509e+10 ... 1.21144486e+122.07014010e+10 1.08825400e+10][ 7.02890000e+00 1.58800000e+00 8.41133582e+10 ... 3.00252062e+112.93083692e+10 2.37834769e+10][-2.62746100e+02 7.00030000e+00 5.17045520e+08 ... 7.70517753e+081.16798290e+07 1.20300800e+07]...[ 3.95523000e+01 4.00520000e+00 1.70243430e+10 ... 2.42081699e+101.78908166e+10 1.74929478e+10][ 5.25408000e+01 2.46460000e+00 3.28790988e+10 ... 3.88380258e+106.46539204e+09 6.00900728e+09][ 1.42203000e+01 1.41030000e+00 5.91108572e+10 ... 2.02066110e+114.50987171e+10 4.13284212e+10]] (2318, 8)
相关系数:(-0.004389322779936261, 0.8327205496564927)相关系数:
(-0.004389322779936261, 0.8327205496564927)
前面一个是相关系数,比较接近于0,说明这两者不太相关
后面是p-value,假设H0:x,y不相关,p-value越大,H0成立的概率越大。p-value值表示显著水平,越小越好
所以这里是说明前面的相关系数成立的可能性很大
6、特征与特征之间相关性很高怎么办
(1)选取其中一个
(2)加权求和
比如revenue和total_expense相关性高,各占50%
(3)主成分分析
7、用图片展示相关性
安装matplotlib
(1)先安装Pillow
参考资料:https://pillow.readthedocs.io/en/latest/installation.html
python3 -m pip install --upgrade pip
python3 -m pip install --upgrade Pillow
(2)再安装matplotlib
pip3 install matplotlib
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.feature_selection import VarianceThreshold
from scipy.stats import pearsonr
import jieba
import pandas as pd
import matplotlib.pyplot as pltdef datasets_demo():"""sklearn数据集使用"""#获取数据集iris = load_iris()print("鸢尾花数据集:\n", iris)print("查看数据集描述:\n", iris["DESCR"])print("查看特征值的名字:\n", iris.feature_names)print("查看特征值几行几列:\n", iris.data.shape)#数据集的划分x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)print("训练集的特征值:\n", x_train, x_train.shape)return Nonedef dict_demo():"""字典特征抽取"""data = [{'city': '北京','temperature':100},{'city': '上海','temperature':60},{'city': '深圳','temperature':30}]# 1、实例化一个转换器类transfer = DictVectorizer(sparse=False)# 2、调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new)print("特征名字:\n", transfer.get_feature_names())return Nonedef count_demo():"""文本特征抽取"""data = ["life is short,i like like python", "life is too long,i dislike python"]# 1、实例化一个转换器类transfer = CountVectorizer()# 2、调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new.toarray())print("特征名字:\n", transfer.get_feature_names()) return Nonedef count_chinese_demo():"""中文文本特征抽取"""data = ["我 爱 北京 天安门", "天安门 上 太阳 升"]# 1、实例化一个转换器类transfer = CountVectorizer()# 2、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new.toarray());print("特征名字:\n", transfer.get_feature_names())return Nonedef cut_word(text):"""进行中文分词"""return " ".join(list(jieba.cut(text))) #返回一个分词生成器对象,强转成list,再join转成字符串def count_chinese_demo2():"""中文文本特征抽取,自动分词"""# 1、将中文文本进行分词data = ["今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年前之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]data_new = []for sent in data:data_new.append(cut_word(sent))print(data_new)# 2、实例化一个转换器类transfer = CountVectorizer()# 3、调用fit_transform()data_final = transfer.fit_transform(data_new)print("data_final:\n", data_final.toarray())print("特征名字:\n", transfer.get_feature_names())return Nonedef tfidf_demo():"""用tf-idf的方法进行文本特征抽取"""# 1、将中文文本进行分词data = ["今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年前之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]data_new = []for sent in data:data_new.append(cut_word(sent))print(data_new)# 2、实例化一个转换器类transfer = TfidfVectorizer()# 3、调用fit_transform()data_final = transfer.fit_transform(data_new)print("data_final:\n", data_final.toarray())print("特征名字:\n", transfer.get_feature_names())return Nonedef minmax_demo():"""归一化"""# 1、获取数据data = pd.read_csv("dating.txt")#print("data:\n", data)data = data.iloc[:, 0:3] #行都要,列取前3列print("data:\n", data)# 2、实例化一个转换器transfer = MinMaxScaler()# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return Nonedef stand_demo():"""标准化"""# 1、获取数据data = pd.read_csv("dating.txt")#print("data:\n", data)data = data.iloc[:, 0:3] #行都要,列取前3列print("data:\n", data)# 2、实例化一个转换器transfer = StandardScaler()# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return Nonedef variance_demo():"""过滤低方差特征"""# 1、获取数据data = pd.read_csv("factor_returns.csv")#print("data:\n", data)data = data.iloc[:, 1:-2]print("data:\n", data)# 2、实例化一个转换器类transfer = VarianceThreshold(threshold=3)# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new, data_new.shape)# 4、计算某两个变量之间的相关系数r1 = pearsonr(data["pe_ratio"], data["pb_ratio"])print("相关系数:\n", r1)r2 = pearsonr(data["revenue"], data["total_expense"])print("revenue与total_expense之间的相关性:\n", r2)#用图片展示相关性plt.figure(figsize=(20, 8), dpi=100)plt.scatter(data['revenue'], data['total_expense'])plt.show()return Noneif __name__ == "__main__":# 代码1:sklearn数据集使用#datasets_demo()# 代码2:字典特征抽取#dict_demo()# 代码3:文本特征抽取#count_demo()# 代码4:中文文本特征抽取#count_chinese_demo()# 代码5:中文文本特征抽取,自动分词#count_chinese_demo2()# 代码6: 测试jieba库中文分词#print(cut_word("我爱北京天安门"))# 代码7:用tf-idf的方法进行文本特征抽取#tfidf_demo()# 代码8:归一化#minmax_demo()# 代码9:标准化#stand_demo()# 代码10:低方差特征过滤variance_demo()
六、主成分分析
1、什么是主成分分析(PCA)
定义:高维数据转化为低维数据的过程,在此过程中可能会舍弃原有数据、创造新的变量
作用:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息
应用:回归分析或者聚类分析当中
2、如何最好的对一个立体的物体二维表示
现实中是一个水壶,拍成照片就是平面的
相当于将三维降到二维,在这个过程中可能就会有信息的损失
如何去衡量信息损失有多少,直观的检验方法是能不能通过二维的图像,能够还原出它还是一个水壶
从这四个图片中可以看到,最后一个能识别出是水壶,也就是说最后一个从三维降到二维它损失的信息是最少的
3、PCA计算过程
找到一个合适的直线,通过一个矩阵运算得出主成分分析的结果
PCA是一种数据降维的技术,它并不是将数据拟合到一个模型中,而是通过线性变换将原始的高维数据投影到一个低维的子空间中,使得投影后的数据仍然尽可能地保留原始数据的信息,同时减少了特征的数量和减少了冗余性
4、API
sklearn.decomposition.PCA(n_components=None)
将数据分解为较低维数空间
n_components:
如果传小数:表示保留百分之多少的信息
如果传整数:减少到多少特征
5、PCA.fit_transform(X)
X:numpy array格式的数据[n_samples, n_features]
返回值:转换后指定维度的array
6、数据计算
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.feature_selection import VarianceThreshold
from scipy.stats import pearsonr
from sklearn.decomposition import PCA
import jieba
import pandas as pd
import matplotlib.pyplot as pltdef datasets_demo():"""sklearn数据集使用"""#获取数据集iris = load_iris()print("鸢尾花数据集:\n", iris)print("查看数据集描述:\n", iris["DESCR"])print("查看特征值的名字:\n", iris.feature_names)print("查看特征值几行几列:\n", iris.data.shape)#数据集的划分x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)print("训练集的特征值:\n", x_train, x_train.shape)return Nonedef dict_demo():"""字典特征抽取"""data = [{'city': '北京','temperature':100},{'city': '上海','temperature':60},{'city': '深圳','temperature':30}]# 1、实例化一个转换器类transfer = DictVectorizer(sparse=False)# 2、调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new)print("特征名字:\n", transfer.get_feature_names())return Nonedef count_demo():"""文本特征抽取"""data = ["life is short,i like like python", "life is too long,i dislike python"]# 1、实例化一个转换器类transfer = CountVectorizer()# 2、调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new.toarray())print("特征名字:\n", transfer.get_feature_names()) return Nonedef count_chinese_demo():"""中文文本特征抽取"""data = ["我 爱 北京 天安门", "天安门 上 太阳 升"]# 1、实例化一个转换器类transfer = CountVectorizer()# 2、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new.toarray());print("特征名字:\n", transfer.get_feature_names())return Nonedef cut_word(text):"""进行中文分词"""return " ".join(list(jieba.cut(text))) #返回一个分词生成器对象,强转成list,再join转成字符串def count_chinese_demo2():"""中文文本特征抽取,自动分词"""# 1、将中文文本进行分词data = ["今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年前之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]data_new = []for sent in data:data_new.append(cut_word(sent))print(data_new)# 2、实例化一个转换器类transfer = CountVectorizer()# 3、调用fit_transform()data_final = transfer.fit_transform(data_new)print("data_final:\n", data_final.toarray())print("特征名字:\n", transfer.get_feature_names())return Nonedef tfidf_demo():"""用tf-idf的方法进行文本特征抽取"""# 1、将中文文本进行分词data = ["今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年前之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]data_new = []for sent in data:data_new.append(cut_word(sent))print(data_new)# 2、实例化一个转换器类transfer = TfidfVectorizer()# 3、调用fit_transform()data_final = transfer.fit_transform(data_new)print("data_final:\n", data_final.toarray())print("特征名字:\n", transfer.get_feature_names())return Nonedef minmax_demo():"""归一化"""# 1、获取数据data = pd.read_csv("dating.txt")#print("data:\n", data)data = data.iloc[:, 0:3] #行都要,列取前3列print("data:\n", data)# 2、实例化一个转换器transfer = MinMaxScaler()# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return Nonedef stand_demo():"""标准化"""# 1、获取数据data = pd.read_csv("dating.txt")#print("data:\n", data)data = data.iloc[:, 0:3] #行都要,列取前3列print("data:\n", data)# 2、实例化一个转换器transfer = StandardScaler()# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return Nonedef variance_demo():"""过滤低方差特征"""# 1、获取数据data = pd.read_csv("factor_returns.csv")#print("data:\n", data)data = data.iloc[:, 1:-2]print("data:\n", data)# 2、实例化一个转换器类transfer = VarianceThreshold(threshold=3)# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new, data_new.shape)# 4、计算某两个变量之间的相关系数r1 = pearsonr(data["pe_ratio"], data["pb_ratio"])print("相关系数:\n", r1)r2 = pearsonr(data["revenue"], data["total_expense"])print("revenue与total_expense之间的相关性:\n", r2)#用图片展示相关性plt.figure(figsize=(20, 8), dpi=100)plt.scatter(data['revenue'], data['total_expense'])plt.show()return Nonedef pca_demo():"""PCA降维"""data = [[2,8,4,5], [6,3,0,8], [5,4,9,1]]# 1、实例化一个转换器类transfer = PCA(n_components=3)# 2、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)# 1、实例化一个转换器类transfer2 = PCA(n_components=0.9)# 2、调用fit_transformdata_new2 = transfer2.fit_transform(data)print("data_new2:\n", data_new2)return Noneif __name__ == "__main__":# 代码1:sklearn数据集使用#datasets_demo()# 代码2:字典特征抽取#dict_demo()# 代码3:文本特征抽取#count_demo()# 代码4:中文文本特征抽取#count_chinese_demo()# 代码5:中文文本特征抽取,自动分词#count_chinese_demo2()# 代码6: 测试jieba库中文分词#print(cut_word("我爱北京天安门"))# 代码7:用tf-idf的方法进行文本特征抽取#tfidf_demo()# 代码8:归一化#minmax_demo()# 代码9:标准化#stand_demo()# 代码10:低方差特征过滤#variance_demo()# 代码11:PCA降维pca_demo()运行结果:
data_new:[[ 1.28620952e-15 3.82970843e+00 5.26052119e-16][ 5.74456265e+00 -1.91485422e+00 5.26052119e-16][-5.74456265e+00 -1.91485422e+00 5.26052119e-16]]
data_new2:[[ 1.28620952e-15 3.82970843e+00][ 5.74456265e+00 -1.91485422e+00][-5.74456265e+00 -1.91485422e+00]]相关文章:
机器学习基础之《特征工程(4)—特征降维》
一、什么是特征降维 降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程 1、降维 降低维度 ndarry 维数:嵌套的层数 0维:标量,具体的数0 1 2 3... …...
)
学生管理系统(Python版本)
class Student:def __init__(self, id, name, age):self.id idself.name nameself.age ageclass StudentManagementSystem:def __init__(self):self.students []def add_student(self, student):self.students.append(student)print("学生信息添加成功!&qu…...

Linux下快速创建大文件的4种方法总结
1、使用 dd 命令创建大文件 dd 命令用于复制和转换文件,它最常见的用途是创建实时 Linux USB。dd 命令是实际写入硬盘,文件产生的速度取决于硬盘的读写速度,根据文件的大小,该命令将需要一些时间才能完成。 假设我们要创建一个名…...

用 Rufus 制作 Ubuntu 系统启动盘时,选择分区类型为MBR还是GPT?
当使用 Rufus 制作 Ubuntu 系统启动盘时,您可以根据您的需求选择分区类型,MBR(Master Boot Record)还是 GPT(GUID Partition Table)。 MBR 是传统的分区表格式,适用于大多数旧版本的操作系统和旧…...
Nodejs+vue+elementui汽车租赁管理系统_1ma2x
语言 node.js 框架:Express 前端:Vue.js 数据库:mysql 数据库工具:Navicat 开发软件:VScode 前端nodejsvueelementui, 课题主要分为三大模块:即管理员模块、用户模块和普通管理员模块,主要功能包括&#…...
Prometheus入门
Prometheus(普罗米修斯) 是一种 新型监控告警工具,Kubernetes 的流行带动了 Prometheus 的应用。 全文参考自 prometheus 学习笔记(1)-mac 单机版环境搭建[1] Mac 上安装 Prometheus brew install prometheus 安装路径在 /usr/local/Cellar/prometheus/2.20.1, 配置文件在 /usr…...

RISC-V云测平台:Compiling The Fedora Linux Kernel Natively on RISC-V
注释:编译Fedora,HS-2 64核RISC-V服务器比Ryzen5700x快两倍! --- 以下是blog 正文 --- # Compiling The Fedora Linux Kernel Natively on RISC-V ## Fedora RISC-V Support There is ongoing work to Fedora to support RISC-V hardwar…...

Vim学习(三)—— Git Repo Gerrit
Git、Gerrit、Repo三者的概念及使用 三者各自作用: git:版本管理库,在git库中没有中心服务器的概念,真正的分布式。 repo:repo就是多个git库的管理工具。如果是多个git库同时管理,可以使用repo。当然使用…...

论坛项目之用户部分
注册接口 实现思路 1.特殊字段检查(比如性别没有给出需要给出默认值) 2.对比检查两次输入的密码是否一致,不一致报错 3.利用UUID生成随机‘盐’值,并使用密码进行MD5加密后与‘盐’进行拼接,生成加密后的密码 4.创建U…...

golang内存对齐
为什么要内存对齐? CPU访问内存时,以CPU的位数为单位进行访问。 如果访问未对齐的内存,处理器需要做两次内存访问,对齐的内存的访问可能仅需要一次,利用内存对齐后提升读取速度。 golang结构体内存对齐规则 在代码编译…...

【CheatSheet】Python、R、Julia数据科学编程极简入门
《Python、R、Julia数据科学编程极简入门》PDF版,是我和小伙伴一起整理的备忘清单,帮助大家10分钟快速入门数据科学编程。 另外,最近 TIOBE 公布了 2023 年 8 月的编程语言排行榜。 Julia 在本月榜单中实现历史性突破,成功跻身 …...
【golang】怎样判断一个变量的类型?
怎样判断一个变量的类型? package mainimport "fmt"var container []string{"zero", "one", "two"} func main() {container : map[int]string{0: "zero", 1: "one", 2: "two"}fmt.Printf…...

怎么学习AJAX相关技术? - 易智编译EaseEditing
学习AJAX(Asynchronous JavaScript and XML)相关技术可以让你实现网页的异步数据交互,提升用户体验。以下是一些学习AJAX技术的步骤和资源: HTML、CSS和JavaScript基础: 首先,确保你已经掌握了基本的HTML…...

JDK、JRE、JVM:揭秘Java的关键三者关系
文章目录 JDK:Java开发工具包JRE:Java运行环境JVM:Java虚拟机关系概述 案例示例:Hello World结语 在Java世界中,你可能经常听到JDK、JRE和JVM这几个概念,它们分别代表了Java开发工具包、Java运行环境和Java…...

【reactNative混合安卓开发~使用问题持续更】
reactNative混合安卓开发 reactNative开发移动端reactNative界面开发前端init.bat文件部分组件第三方组件解析1、定义theme主题shopify/restyle;菜单导航react-navigation/drawer、react-navigation/native; RN问题记录1、使用theme.js写的公共组件报错&…...

OCR的发明人是谁?
OCR的发明背景可以追溯到早期计算机科学和图像处理的研究。随着计算机技术的不断发展,人们开始探索如何将印刷体文字转换为机器可读的文本。 OCR(Optical Character Recognition,光学字符识别)的发明涉及多个人的贡献,…...

笔记本电脑连上WiFi之后的IP为什么会变?如何让它不变固定住?
笔记本连上WiFi后获取IP地址的过程,通常是通过DHCP (动态主机配置协议) 来完成的。默认情况下,DHCP会根据连接设备和网络状态动态地分配IP地址,因此你会看到IP地址可能经常改变。 如果你希望电脑的IP地址固定,可以尝试设置静态IP…...
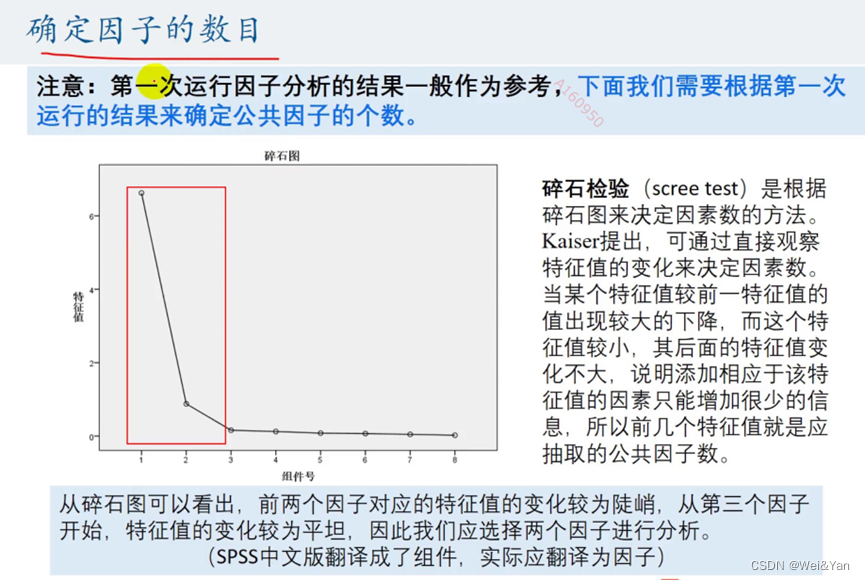
【数学建模】--因子分析模型
因子分析有斯皮尔曼在1904年首次提出,其在某种程度上可以被看成时主成分分析的推广和扩展。 因子分析法通过研究变量间的相关稀疏矩阵,把这些变量间错综复杂的关系归结成少数几个综合因子,由于归结出的因子个数少于原始变量的个数,…...

RAM不够?CUBEIDE使用CCMRAM
RAM不够?使用CCMRAM 文章目录 RAM不够?使用CCMRAM打开连接LD文件:添加代码添加标识宏使用 打开连接LD文件: 添加代码 在SECTIONS段最后加上下面代码: _siccmram LOADADDR(.ccmram); /* CCM-RAM section * * IMPORTAN…...
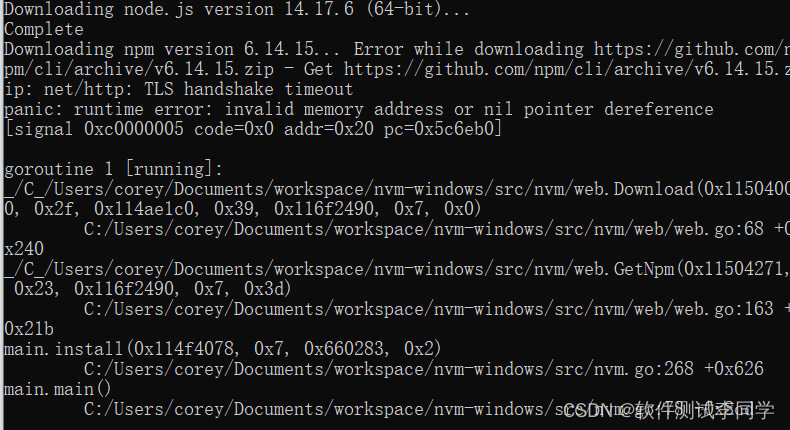
npm ERR! code ERESOLVEnpm ERR! ERESOLVE unable to resolve dependency tree
拉取项目到本地 执行 npm install 报错 遇到这个问题首先确认的就是版本是不是太高了,降一下版本。或者通过yarn命令替代npm install命令安装,同理,启动也可以采用yarn dev 启动代替npm run dev 下面教大家用一个NVM工具,这个工…...
)
UniApp + ECharts实战:手把手教你打造一个可复用的自定义图表组件(附完整代码)
UniApp ECharts组件化实战:构建高复用性图表组件的完整指南 在当今数据驱动的移动应用开发中,数据可视化已成为提升用户体验的关键要素。对于UniApp开发者而言,将强大的ECharts图表库封装成可复用的组件,不仅能显著提升开发效率&…...

Onekey终极指南:5分钟搞定Steam清单下载的完整教程
Onekey终极指南:5分钟搞定Steam清单下载的完整教程 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 还在为复杂的Steam Depot清单下载而烦恼吗?Onekey就是你的救星&#x…...

从哲学到机器学习:非科班转型的实践指南
1. 从哲学系毕业生到机器学习实践者的转型之路2015年,35岁的Brian Thomas坐在保险公司的服务器机房,盯着满屏的PowerShell脚本。这位哲学系毕业的IT管理员突然意识到:自己每天重复的自动化脚本工作,与真正改变世界的技术之间&…...

2026届毕业生推荐的六大AI辅助写作神器横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在学术写作范围内,针对紧迫的截止时间以及繁重的文献整理任务,研究人…...

终极Windows激活方案:KMS_VL_ALL_AIO智能激活脚本完全解析
终极Windows激活方案:KMS_VL_ALL_AIO智能激活脚本完全解析 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活而烦恼吗?每次重装系统后面对"需要…...

告别VisionMaster原生界面:用C#和VM SDK 4.2打造你的专属视觉检测上位机
从零构建工业级视觉检测上位机:C#与VisionMaster SDK深度整合实战 在工业自动化领域,视觉检测系统正逐渐成为质量管控的核心环节。然而,标准化的视觉软件往往难以满足企业对界面交互、数据整合和品牌一致性的高阶需求。本文将带你深入探索如何…...

量子强化学习在TSP问题中的参数优化与应用
1. 量子强化学习在TSP问题中的应用概述量子强化学习(Quantum Reinforcement Learning, QRL)作为量子计算与强化学习的交叉领域,为解决组合优化问题提供了全新的技术路径。在旅行商问题(Traveling Salesman Problem, TSP࿰…...

ROS与ABB机器人联调避坑实录:从RoboStudio仿真到MoveIt运动规划,我踩过的那些“信号”与“连接”的坑
ROS与ABB机器人联调避坑实录:从RoboStudio仿真到MoveIt运动规划实战指南 当仿真环境中的IRB 1600机械臂突然停止响应MoveIt的运动规划指令时,示教器上闪烁的"Execution Error"信号让我意识到——工业机器人与ROS的深度集成远不止配置文件修改…...
)
大模型编程实战:从工具类开发到氛围编程,小白也能轻松掌握(收藏版)
本文分享了个人使用AI编程的真实体验,涵盖编写工具类、写单元测试等实用场景。结合“氛围编程”在仿真平台上的实践,提炼出核心流程。同时,针对AI编码中存在的幻觉问题、边界条件处理不足等挑战进行分析,并提出AI时代开发者应如何…...

Office自定义界面编辑器:3步打造你的专属Office工作区
Office自定义界面编辑器:3步打造你的专属Office工作区 【免费下载链接】office-custom-ui-editor Standalone tool to edit custom UI part of Office open document file format 项目地址: https://gitcode.com/gh_mirrors/of/office-custom-ui-editor 你是…...