Django笔记之数据库查询优化汇总
1、性能方面
1. connection.queries
前面我们介绍过 connection.queries 的用法,比如我们执行了一条查询之后,可以通过下面的方式查到我们刚刚的语句和耗时
>>> from django.db import connection
>>> connection.queries
[{'sql': 'SELECT polls_polls.id, polls_polls.question, polls_polls.pub_date FROM polls_polls',
'time': '0.002'}]
仅仅当系统的 DEBUG 参数设为 True,上述命令才可生效,而且是按照查询的顺序排列的一个数组
数组的每一个元素都是一个字典,包含两个 Key:sql 和 time
sql 为查询转化的查询语句
time 为查询过程中的耗时
因为这个记录是按照时间顺序排列的,所以 connection.queries[-1] 总能查询到最新的一条记录。
多数据库操作
如果系统用的是多个数据库,那么可以通过 connections['db_alias'].queries 来操作,比如我们使用的数据库的 alias 为 user:
>>> from django.db import connections
>>> connections['user'].queries
如果想清空之前的记录,可以调用 reset_queries() 函数:
from django.db import reset_queries
reset_queries()
2. explain
我们也可以使用 explain() 函数来查看一条 QuerySet 的执行计划,包括索引以及联表查询的的一些信息
这个操作就和 MySQL 的 explain 是一样的。
>>> print(Blog.objects.filter(title='My Blog').explain())
Seq Scan on blog (cost=0.00..35.50 rows=10 width=12)Filter: (title = 'My Blog'::bpchar)
也可以加一些参数来查看更详细的信息:
>>> print(Blog.objects.filter(title='My Blog').explain(verbose=True, analyze=True))
Seq Scan on public.blog (cost=0.00..35.50 rows=10 width=12) (actual time=0.004..0.004 rows=10 loops=1)Output: id, titleFilter: (blog.title = 'My Blog'::bpchar)
Planning time: 0.064 ms
Execution time: 0.058 ms
之前在使用 Django 的过程中还使用到一个叫 silk 的工具,它可以用来分析一个接口各个步骤的耗时,有兴趣的可以了解一下。
2、使用标准的数据库优化技术
数据库优化技术指的是在查询操作中 SQL 底层本身的优化,不涉及 Django 的查询操作
比如使用 索引 index,可以使用 Meta.indexes 或者字段里的 Field.db_index 来添加索引
如果频繁的使用到 filter()、exclude()、order_by() 等操作,建议为其中查询的字段添加索引,因为索引能帮助加快查询
3、理解 QuerySet
1. 理解 QuerySet 获取数据的过程
1) QuerySet 的懒加载
一个查询的创建并不会访问数据库,直到获取这条查询语句的具体数据的时候,系统才会去访问数据库:
>>> q = Entry.objects.filter(headline__startswith="What") # 不访问数据库
>>> q = q.filter(pub_date__lte=datetime.date.today()) # 不访问数据库
>>> q = q.exclude(body_text__icontains="food") # 不访问数据库
>>> print(q) # 访问数据库
比如上面四条语句,只有最后一步,系统才会去查询数据库。
2) 数据什么时候被加载
迭代、使用步长分片、使用len()函数获取长度以及使用list()将QuerySet 转化成列表的时候数据才会被加载
这几点情况在我们的第九篇笔记中都有详细的描述。
3) 数据是怎么被保存在内存中的
每一个 QuerySet 都会有一个缓存来减少对数据库的访问操作,理解其中的运行原理能帮助我们写出最有效的代码。
当我们创建一个 QuerySet 的之后,并且数据第一次被加载,对数据库的查询操作就发生了。
然后 Django 会保存 QuerySet 查询的结果,并且在之后对这个 QuerySet 的操作中会重复使用,不会再去查询数据库。
当然,如果理解了这个原理之后,用得好就OK,否则会对数据库进行多次查询,造成性能的浪费,比如下面的操作:
>>> print([e.headline for e in Entry.objects.all()])
>>> print([e.pub_date for e in Entry.objects.all()])
上面的代码,同样一个查询操作,系统会查询两遍数据库,而且对于数据来说,两次的间隔期之间,Entry 表可能的某些数据库可能会增加或者被删除造成数据的不一致。
为了避免此类问题,我们可以这样复用这个 QuerySet :
>>> queryset = Entry.objects.all()
>>> print([p.headline for p in queryset]) # 查询数据库
>>> print([p.pub_date for p in queryset]) # 从缓存中直接使用,不会再次查询数据库
这样的操作系统就只执行了一遍查询操作。
使用数组的切片或者根据索引(即下标)不会缓存数据
QuerySet 也并不总是缓存所查询的结果,如果只是获取一个 QuerySet 部分数据,会查询有是否这个 QuerySet 的缓存
有的话,则直接从缓存中获取数据,没有的话,后续也不会将这部分数据缓存到系统中。
举个例子,比如下面的操作,在缓存整个 QuerySet 数据前,查询一个 QuerySet 的部分数据时,系统会重复查询数据库:
>>> queryset = Entry.objects.all()
>>> print(queryset[5]) # 查询数据库
>>> print(queryset[5]) # 再次查询数据库
而在下面的操作中,整个 QuerySet 都被提前获取了,那么根据索引的下标获取数据,则能够从缓存中直接获取数据:
>>> queryset = Entry.objects.all()
>>> [entry for entry in queryset] # 查询数据库
>>> print(queryset[5]) # 使用缓存
>>> print(queryset[5]) # 使用缓存
如果一个 QuerySet 已经缓存到内存中,那么下面的操作将不会再次查询数据库:
>>> [entry for entry in queryset]
>>> bool(queryset)
>>> entry in queryset
>>> list(queryset)
2. 理解 QuerySet 的缓存
除了 QuerySet 的缓存,单个 model 的 object 也有缓存的操作。
我们这里简单理解为外键和多对多的关系。
比如下面外键字段的获取,blog 是 Entry 的一个外键字段:
>>> entry = Entry.objects.get(id=1)
>>> entry.blog # Blog 的实例被查询数据库获得
>>> entry.blog # 第二次获取,使用缓存信息,不会查询数据库
而多对多关系的获取每次都会被重新去数据库获取数据:
>>> entry = Entry.objects.get(id=1)
>>> entry.authors.all() # 查询数据库
>>> entry.authors.all() # 再次查询数据库
当然,以上的操作,我们都可以通过 select_related() 和 prefetch_related() 的方式来减少数据库的访问,这个的用法在前面的笔记中有介绍。
4、操作尽量在数据库中完成而不是在内存中
举几个例子:
- 在大多数查询中,使用 filter() 和 exclude() 在数据库中做过滤,而不是在获取所有数据之后在 Python 里的 for 循环里筛选数据
- 在同一个 model 的操作中,如果有涉及到其他字段的操作,可以用到 F 表达式
- 使用 annotate 函数在数据库中做聚合(aggregate)的操作
如果某些查询比较复杂,可以使用原生的 SQL 语句,这个操作也在前面有过一篇完整的笔记介绍过
5、使用唯一索引来查询单个对象
在使用 get() 来查询单条数据的时候,有两个理由使用唯一索引(unique)或 普通索引(db_index)
一个是基于数据库索引,查询会更快,
另一个是如果多条数据都满足查询条件,查询会慢得多,而在唯一索引的约束下则保证这种情况不会发生
所以使用下面的 id 进行匹配 会比 headline 字段匹配快得多,因为 id 字段在数据库中有索引且是唯一的:
entry = Entry.objects.get(id=10)entry = Entry.objects.get(headline="News Item Title")
而下面的操作可能会更慢:
entry = Entry.objects.get(headline__startswith="News")
首先, headline 字段上没有索引,会导致数据库获取速度慢
其次,查询并不能保证只返回一个对象,如果匹配上来多个对象,且从数据库中检索并返回数百数千条记录,后果会很严重,其实就会报错,get() 能接受的返回只能是一个实例数据。
6、如果知道需要什么数据,那么就立刻查出来
能一次性查询所有需要的相关的数据的话,就一次性查询出来,不要在循环中做多次查询,因为那样会多次访问数据库
所以这就需要理解并且用到 select_related() 和 prefetch_related() 函数
7、不要查询你不需要的数据
1. 使用 values() 和 values_list() 函数
如果需求仅仅是需要某几个字段的数据,可以用到的数据结构为 dict 或者 list,可以直接使用这两个函数来获取数据
2. 使用 defer() 和 only()
如果明确知道只需要,或者不需要什么字段数据,可以使用这两个方法,一般常用在 textfield 上,避免加载大数据量的 text 字段
3. 使用 count()
如果想要获取总数,使用 count() 方法,而不是使用 len() 来操作,如果数据有一万条,len() 操作会导致这一万条数据都加载到内存里,然后计数。
4. 使用 exists()
如果仅仅是想查询数据是否至少存在一条可以使用 if QuerySet.exists() 而不是 if queryset 的形式
5. 使用 update() 和 delete()
能够批量更新和删除的操作就使用批量的方法,挨个去加载数据,更新数据,然后保存是不推荐的
6. 直接使用外键的值
如果需要外键的值,直接调用早就在这个 object 中的字段,而不是加载整个关联的 object 然后取其主键id
比如推荐:
entry.blog_id
而不是:
entry.blog.id
7. 如果不需要排序的结果,就不要order_by()
每一个字段的排序都是数据库的操作需要额外消耗性能的,所以如果不需要的话,尽量不要排序
如果在 Meta.ordering 中有一个默认的排序,而你不需要,可以通过 order_by() 不添加任何参数的方法来取消排序
为数据库添加索引,可以帮助提高排序的性能
8、使用批量的方法
1. 批量创建
对于多条 model 数据的创建,尽可能的使用 bulk_create() 方法,这是要优于挨个去 create() 的
2. 批量更新
bulk_update 方法也优于挨个数据在 for 循环中去 save()
3. 批量 insert
对于 ManyToMany 方法,使用 add() 方法的时候添加多个参数一次性操作比多次 add 要好
my_band.members.add(me, my_friend)
要优于:
my_band.members.add(me)
my_band.members.add(my_friend)
4. 批量 remove
当去除 ManyToMany 中的数据的时候,也是能一次性操作就一次性操作:
my_band.members.remove(me, my_friend)
要好于:
my_band.members.remove(me)
my_band.members.remove(my_friend)相关文章:

Django笔记之数据库查询优化汇总
1、性能方面 1. connection.queries 前面我们介绍过 connection.queries 的用法,比如我们执行了一条查询之后,可以通过下面的方式查到我们刚刚的语句和耗时 >>> from django.db import connection >>> connection.queries [{sql: S…...
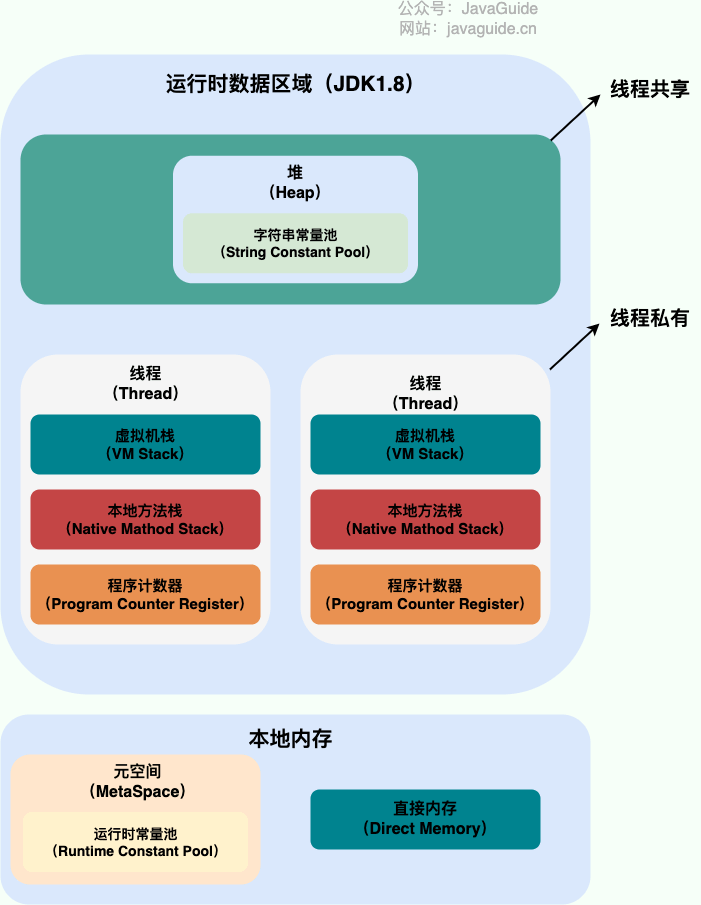
JVM内存区域
预备 为了更好的理解类加载和垃圾回收,先要了解一下JVM的内存区域(如果没有特殊说明,都是针对的是 HotSpot 虚拟机。)。 Java 源代码文件经过编译器编译后生成字节码文件,然后交给 JVM 的类加载器,加载完…...
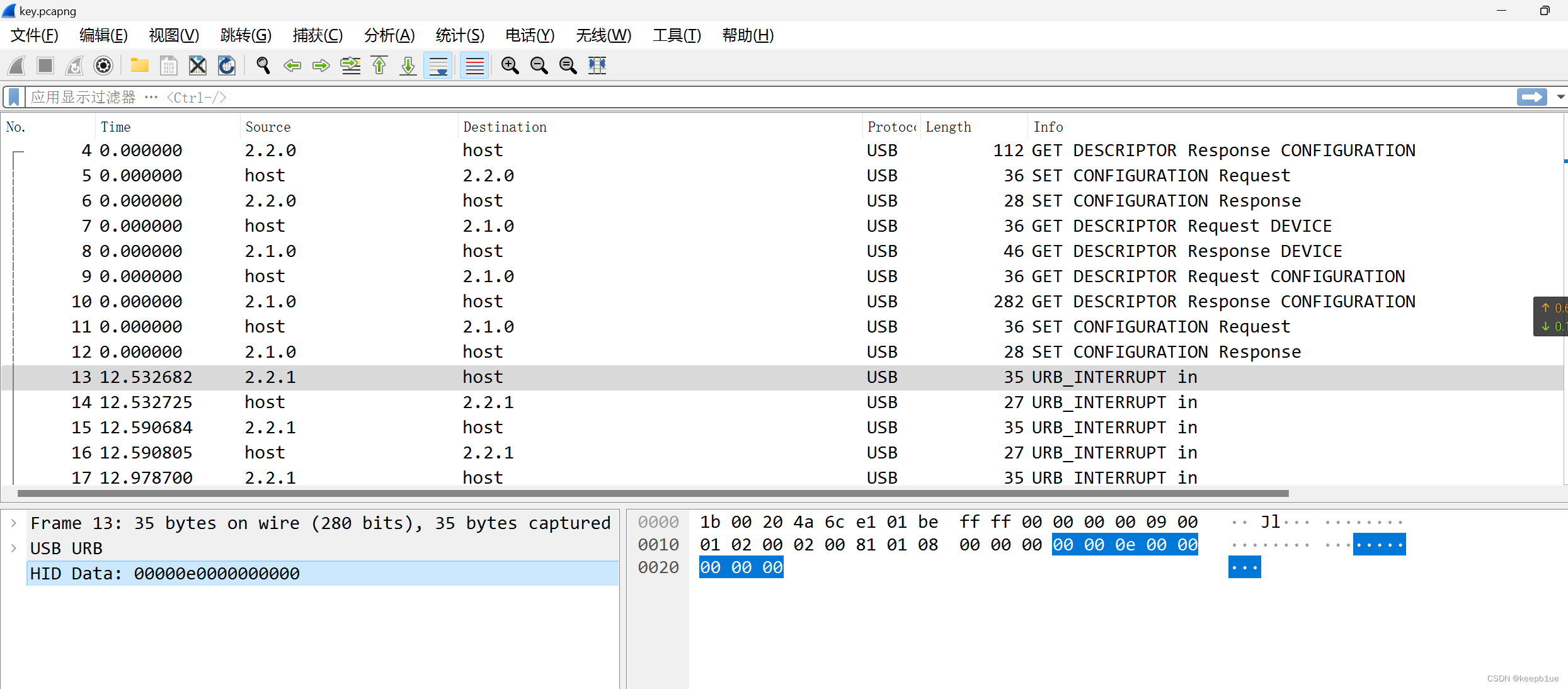
某行业CTF一道流量分析题
今晚看了一道题,记录学习下。 给了一个hacktrace.pcapng,分析主要内容如下: 上传两个文件,一个mouse.m2s,一个mimi.zip,将其导出。 mimi.zip中存放着secret.zip和key.pcapng 不过解压需要密码ÿ…...
【Kafka】1.Kafka简介及安装
目 录 1. Kafka的简介1.1 使用场景1.2 基本概念 2. Kafka的安装2.1 下载Kafka的压缩包2.2 解压Kafka的压缩包2.3 启动Kafka服务 1. Kafka的简介 Kafka 是一个分布式、支持分区(partition)、多副本(replica)、基于 zookeeper 协调…...
Kafka API与SpringBoot调用
文章目录 首先需要命令行创建一个名为cities的主题,并且创建该主题的订阅者。 1、使用Kafka原生API1.1、创建spring工程1.2、创建发布者1.3、对生产者的优化1.4、批量发送消息1.5、创建消费者组1.6 消费者同步手动提交1.7、消费者异步手动提交1.8、消费者同异步手动…...

JavaScript构造函数和类的区别
原文 构造函数 没有显式的创建对象创建对象时使用new操作符。所有属性和方法赋值给this对象。没有return语句按照惯例,构造函数的方法名首字母应该使用大写字母,用于区分普通函数,其实构造函数也是函数,其主要功能是用来创建对象…...
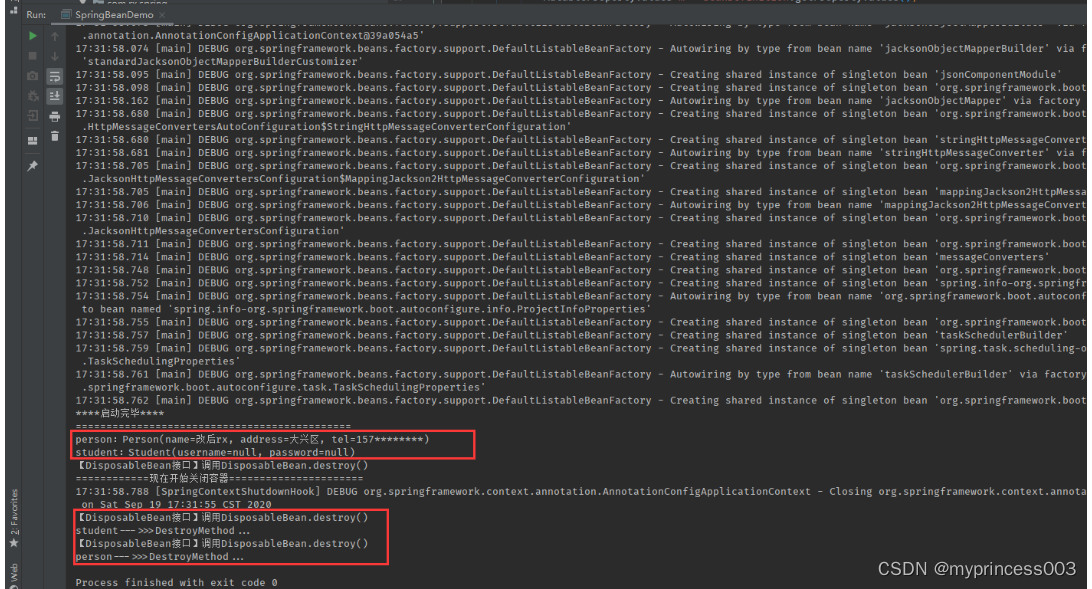
Spring与Spring Bean
Spring 原理 它是一个全面的、企业应用开发一站式的解决方案,贯穿表现层、业务层、持久层。但是 Spring 仍然可 以和其他的框架无缝整合。 Spring 特点 轻量级 控制反转 面向切面 容器 框架集合 Spring 核心组件 Spring 总共有十几个组件核心容器(Spring core) S…...
并发相关面试题
巩固基础,砥砺前行 。 只有不断重复,才能做到超越自己。 能坚持把简单的事情做到极致,也是不容易的。 如何理解volatile关键字 在并发领域中,存在三大特性:原子性、有序性、可见性。volatile关键字用来修饰对象的属性…...
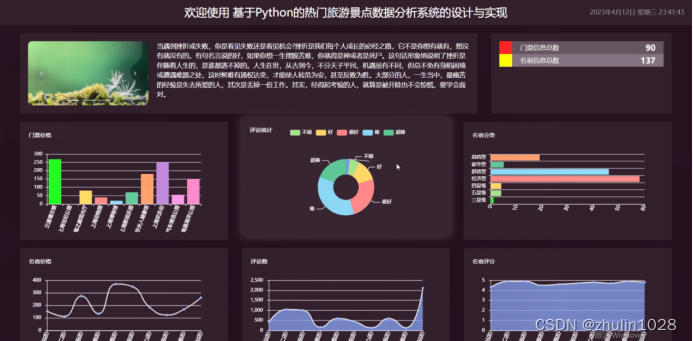
Hadoop+Python+Django+Mysql热门旅游景点数据分析系统的设计与实现(包含设计报告)
系统阐述的是使用热门旅游景点数据分析系统的设计与实现,对于Python、B/S结构、MySql进行了较为深入的学习与应用。主要针对系统的设计,描述,实现和分析与测试方面来表明开发的过程。开发中使用了 django框架和MySql数据库技术搭建系统的整体…...

php中nts和ts
PHP语言解析器:官方提供了2种类型的版本,线程安全(TS)版和非线程安全(NTS)版 TS: TS(Thread-Safety)即线程安全,多线程访问时,采用了加锁机制,当一个线程访问该类的某个数据时进行数据加锁保护,其他线程不能同时进行访…...
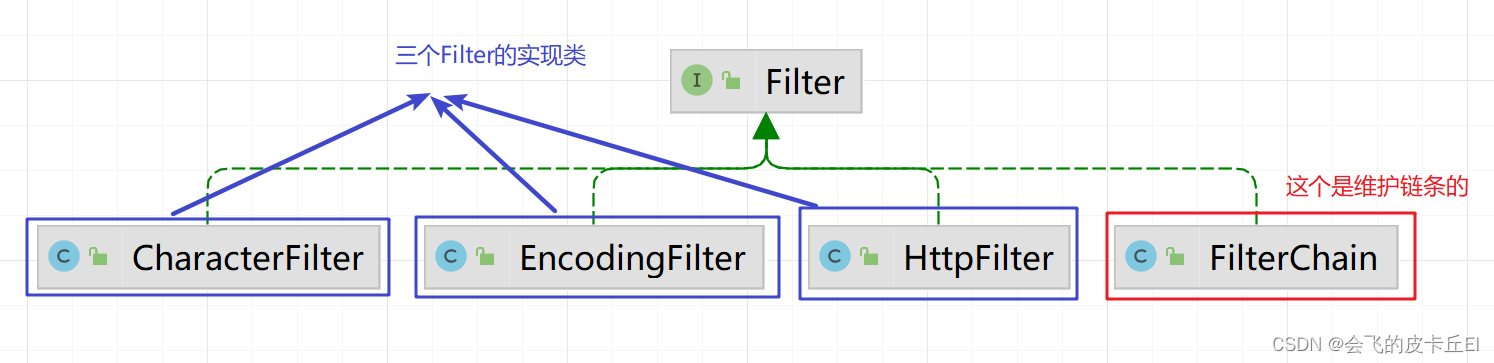
设计模式之责任链模式【Java实现】
责任链(Chain of Resposibility) 模式 概念 责任链(chain of Resposibility) 模式:为了避免请求发送者与多个请求处理者耦合在一起,于是将所有请求的处理者 通过前一对象记住其下一个对象的引用而连成一条…...

Android 12.0 系统systemui状态栏下拉左滑显示通知栏右滑显示控制中心模块的流程分析
1.前言 在android12.0的系统rom定制化开发中,在系统原生systemui进行自定义下拉状态栏布局的定制的时候,需要在systemui下拉状态栏下滑的时候,根据下滑坐标来 判断当前是滑出通知栏还是滑出控制中心模块,所以就需要根据屏幕宽度,来区分x坐标值为多少是左滑出通知栏或者右…...
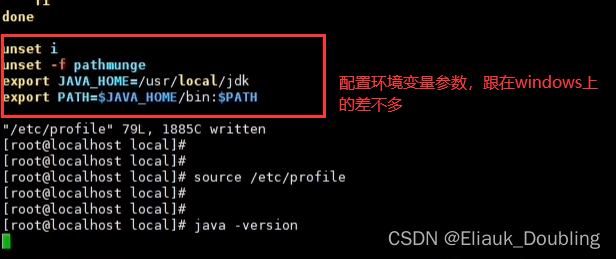
服务器安装JDK
三种方法 方法一: 方法二: 首先登录到Oracle官网下载JDK JDK上传到服务器中,记住文件上传的位置是在哪里(我放的位置在/www/java),然后看下面指示进行安装 方法三: 首先登录到Oracle官网下载…...

cpu查询
1.mpstat查看系统cpu状况 mpstat 1 1或者mpstat -P ALL查看每个cpu使用状态,(用户态cpu是用来,内核态cpu使用率,等待IO使用率) 2.vmstat 可以查看系统运行任务数(正在cpu运行进程和就绪队列进程࿰…...

【muduo】关于自动增长的缓冲区
目录 为什么需要缓冲区自动增长的缓冲区buffer数据结构buffer类 写详细比较费时间,就简单总结下。 总结自Linux 多线程服务端编程:使用 muduo C 网络库 Muduo网络编程: IO-multiplexnon-blocking 为什么需要缓冲区 Non-blocking IO 的核心…...
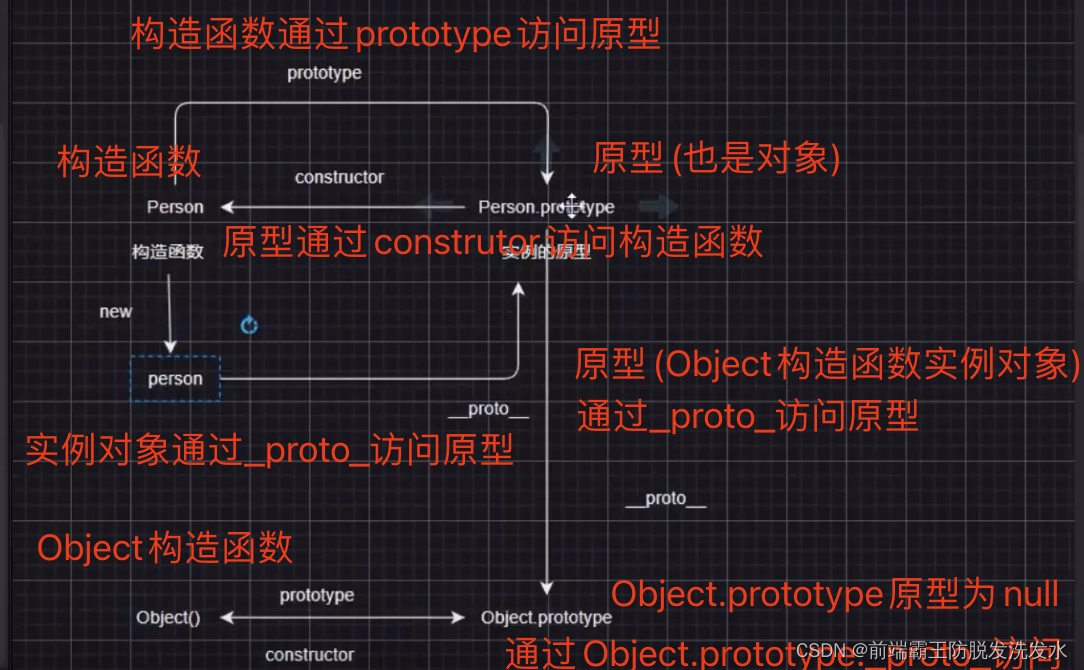
原型和原型链理解
这个图大概能概括原型和原型链的关系 1.对象都是通过 _proto_ 访问原型 2.原型都是通过constructor 访问构造函数 3.原型是构造函数的 prototype 4.原型也是对象实例 也是通过 _proto_ 访问原型(Object.prototype) 5.Object.prototype的原型通过 _proto_ 访问 为null 那么…...

CSS:弹性盒子模型详解(用法 + 例子 + 效果)
目录 弹性盒子模型flex-direction 排列方式 主轴方向换行排序控制子元素缩放比例缩放是如何实现的? 控制子元素的对其方式justify-content 横向 对齐方式align-items 纵向 对齐方式 align-content 多行 对齐方式 弹性盒子模型 flex-direction 排列方式 主轴方向 f…...
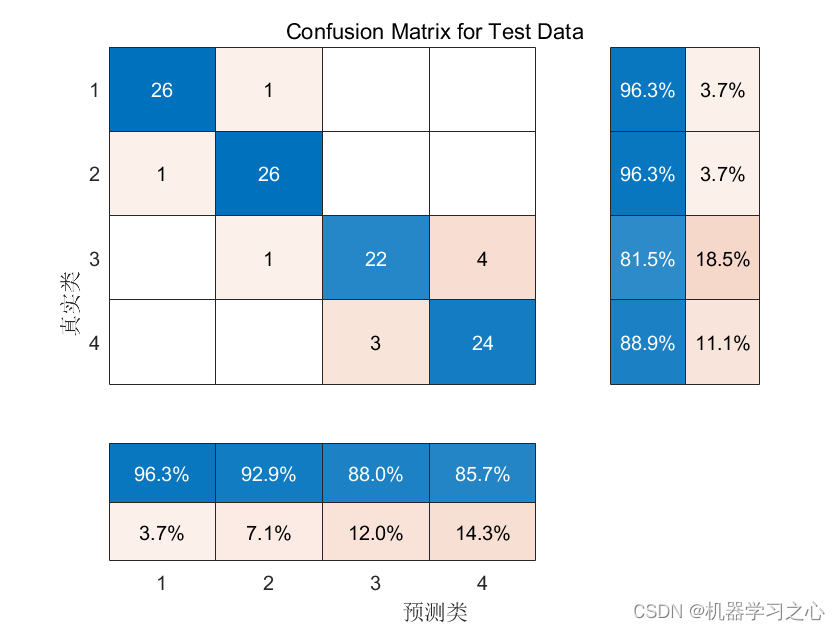
分类预测 | Matlab实现基于MIC-BP最大互信息系数数据特征选择算法结合BP神经网络的数据分类预测
分类预测 | Matlab实现基于MIC-BP最大互信息系数数据特征选择算法结合BP神经网络的数据分类预测 目录 分类预测 | Matlab实现基于MIC-BP最大互信息系数数据特征选择算法结合BP神经网络的数据分类预测效果一览基本介绍研究内容程序设计参考资料 效果一览 基本介绍 Matlab实现基于…...

拜读苏神-1-深度学习+文本情感分类
一、闲聊神经网络与深度学习 参考链接:https://www.kexue.fm/archives/3331 分类模型本质上是在做拟合——模型其实就是一个函数(或者一簇函数),里边有一些待定的参数,根据已有的数据,确定损失函数&#x…...

【uniapp 小程序开发语法篇】资源引入 | 语法介绍 | UTS 语法支持(链接格式)
博主:_LJaXi Or 東方幻想郷 专栏: uni-app | 小程序开发 开发工具:HBuilderX 小程序开发语法篇 引用组件easycom Js文件引入NPM支持 Css文件引入静态资源引入css 引入静态资源如何引入字体图标?css 引入字体图标示例nvue 引入字体…...

如何快速获取网盘直链下载地址:8大平台完整解析指南
如何快速获取网盘直链下载地址:8大平台完整解析指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云…...

DouyinLiveRecorder智能文字提取:如何轻松获取40+平台直播关键信息
DouyinLiveRecorder智能文字提取:如何轻松获取40平台直播关键信息 【免费下载链接】DouyinLiveRecorder 可循环值守和多人录制的直播录制软件,支持抖音、TikTok、Youtube、快手、虎牙、斗鱼、B站、小红书、pandatv、sooplive、flextv、popkontv、twitcas…...

Windows系统清理终极指南:5分钟解决C盘爆满问题
Windows系统清理终极指南:5分钟解决C盘爆满问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否每天都要面对那个令人焦虑的红色警告࿱…...

eslint-plugin-security常见问题解决方案:从安装到配置的全方位排错
eslint-plugin-security常见问题解决方案:从安装到配置的全方位排错 【免费下载链接】eslint-plugin-security ESLint rules for Node Security 项目地址: https://gitcode.com/gh_mirrors/es/eslint-plugin-security eslint-plugin-security是一款专注于Nod…...

SDMatte效果对比展示:普通抠图vs SDMatte+,叶片锯齿消除与羽化自然度
SDMatte效果对比展示:普通抠图vs SDMatte,叶片锯齿消除与羽化自然度 1. 效果展示概览 SDMatte作为一款专业级AI抠图工具,在处理复杂边缘和半透明物体方面展现出显著优势。本文将重点对比标准版SDMatte与增强版SDMatte在处理叶片锯齿和羽化效…...

Qwen3-TTS-12Hz-1.7B-CustomVoice效果展示:意大利语歌剧念白+西班牙语弗拉门戈解说
Qwen3-TTS-12Hz-1.7B-CustomVoice效果展示:意大利语歌剧念白西班牙语弗拉门戈解说 想象一下,你正在策划一场国际艺术节,需要为意大利歌剧片段和西班牙弗拉门戈舞蹈制作多语言解说。传统的配音方案要么成本高昂,要么音色生硬&…...

彻底告别网盘限速:八大平台直链下载助手完整指南
彻底告别网盘限速:八大平台直链下载助手完整指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 …...

OpenUserJS.org 新手快速上手指南:轻松搭建用户脚本平台
OpenUserJS.org 新手快速上手指南:轻松搭建用户脚本平台 【免费下载链接】OpenUserJS.org The home of FOSS user scripts. 项目地址: https://gitcode.com/gh_mirrors/op/OpenUserJS.org OpenUserJS.org 是一个开源的用户脚本托管平台,为开发者提…...

软件规模-功能点分析法
功能点分析法是在20世纪70年代中期由IBM委托 Allan Albrecht 工程师和他的同事为解决代码行度量法所产生的问题和局限性而研究发布,发表于1979年,随后被国际功能点用户协会继承。该方法基于应用软件的外部,内部特性以及软件性能进行一系列间接…...

【卷卷观察】Vibe Coding 时代:有些人已经在用 AI 写代码,有些人还在争论 AI 能不能写代码
结论先说:Vibe Coding 这事,已经不是"趋势"了,是既成事实。92% 的美国开发者每天在用,41% 的代码是 AI 生成的。但这篇文章不想重复这些数字——数字你网上随便都能查到。我想聊的是:这事到底意味着什么&…...