在生产环境中部署Elasticsearch:最佳实践和故障排除技巧——聚合与搜索(三)
前言

「作者主页」:雪碧有白泡泡
「个人网站」:雪碧的个人网站
「推荐专栏」:
★java一站式服务 ★
★ React从入门到精通★
★前端炫酷代码分享 ★
★ 从0到英雄,vue成神之路★
★ uniapp-从构建到提升★
★ 从0到英雄,vue成神之路★
★ 解决算法,一个专栏就够了★
★ 架构咱们从0说★
★ 数据流通的精妙之道★
★后端进阶之路★

文章目录
- 前言
- 聚合和分析
- 执行聚合操作
- 1. 使用Java API执行聚合操作
- 2. 使用CURL命令执行聚合操作
- 执行度量操作
- 1. 使用Java API执行度量操作
- 2. 使用CURL命令执行度量操作
- 结论
- 搜索性能优化
- 使用缓存
- 调整分片大小和数量
- 使用搜索建议
- 结论
- 集群管理
- 节点发现
- 负载均衡
- 故障转移
- 结论
- 安全性和访问控制
- 访问控制
- 加密
- 身份验证
- 结论
- 应用程序集成
- REST API
- 客户端库
- 结论

聚合和分析
在Elasticsearch中执行聚合和度量操作可以帮助我们对数据进行更深入的分析。本文将介绍如何使用聚合和度量来执行复杂的数据分析操作,例如计数、平均值、百分位数和分组等。
执行聚合操作
1. 使用Java API执行聚合操作
可以使用Java API执行各种聚合操作。以下是使用RestHighLevelClient对象执行名为my_index的索引中的terms聚合操作的代码示例:
SearchRequest request = new SearchRequest("my_index");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
TermsAggregationBuilder aggregation =AggregationBuilders.terms("by_age").field("age");
sourceBuilder.aggregation(aggregation);
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
以上代码使用SearchRequest对象和SearchSourceBuilder对象执行terms聚合操作,并按年龄字段分组。
2. 使用CURL命令执行聚合操作
也可以使用CURL命令执行各种聚合操作。以下是使用名为my_index的索引中的terms聚合操作检索所有文档的示例:
curl -XGET 'localhost:9200/my_index/_search?pretty' -H 'Content-Type: application/json' -d'
{"aggs" : {"by_age" : {"terms" : { "field" : "age" }}}
}
'
执行度量操作
1. 使用Java API执行度量操作
可以使用Java API执行各种度量操作。以下是使用RestHighLevelClient对象执行名为my_index的索引中的avg度量操作的代码示例:
SearchRequest request = new SearchRequest("my_index");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
AvgAggregationBuilder aggregation =AggregationBuilders.avg("avg_age").field("age");
sourceBuilder.aggregation(aggregation);
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
以上代码使用SearchRequest对象和SearchSourceBuilder对象执行avg度量操作,并返回年龄字段的平均值。
2. 使用CURL命令执行度量操作
也可以使用CURL命令执行各种度量操作。以下是使用名为my_index的索引中的avg度量操作检索所有文档的示例:
curl -XGET 'localhost:9200/my_index/_search?pretty' -H 'Content-Type: application/json' -d'
{"aggs" : {"avg_age" : {"avg" : { "field" : "age" }}}
}
'
结论
本文介绍了如何使用聚合和度量来执行复杂的数据分析操作,例如计数、平均值、百分位数和分组等。使用Java API或CURL命令都可以对Elasticsearch索引中的数据进行聚合和度量操作,以便更好地理解和分析数据。在实际应用中,需要根据具体需求选择合适的聚合和度量操作来使用。
搜索性能优化
优化Elasticsearch的搜索性能是应用程序中非常重要的一部分。本文将介绍如何使用缓存、调整分片大小和数量,以及使用搜索建议等方式来优化Elasticsearch的搜索性能。
使用缓存
Elasticsearch中有两种类型的缓存:查询缓存和过滤器缓存。查询缓存为相同的查询结果提供快速的响应,而过滤器缓存则会缓存过滤器结果,以便在后续搜索中快速使用。以下是使用Java API启用过滤器缓存的代码示例:
SearchRequest request = new SearchRequest("my_index");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.termQuery("age", 30));
sourceBuilder.postFilter(QueryBuilders.termQuery("city", "New York"));
sourceBuilder.size(0);
sourceBuilder.aggregation(AggregationBuilders.avg("avg_age").field("age"));
sourceBuilder.aggregation(AggregationBuilders.terms("by_city").field("city"));
sourceBuilder.profile(true);
sourceBuilder.cache(true);
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
以上代码使用SearchSourceBuilder对象启用了过滤器缓存。
调整分片大小和数量
分片是Elasticsearch中数据的基本单元,并且将数据划分为多个分片可以使Elasticsearch更好地处理大型数据集。但是,如果分片过大或过小,都会影响搜索性能。以下是使用Java API设置索引分片数和备份数的代码示例:
CreateIndexRequest request = new CreateIndexRequest("my_index");
request.settings(Settings.builder().put("index.number_of_shards", 5).put("index.number_of_replicas", 1));
以上代码使用CreateIndexRequest对象设置名为my_index的索引的分片数为5,备份数为1。
使用搜索建议
搜索建议是Elasticsearch中一种重要的搜索优化技术。它可以在用户输入搜索查询时提供自动完成、拼写检查和相关性建议等功能。以下是使用Java API添加基于文本的完整推荐搜索建议的代码示例:
SearchRequest request = new SearchRequest("my_index");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
SuggestionBuilder termSuggestionBuilder =SuggestBuilders.termSuggestion("name").text("jonh");
SuggestBuilder suggestBuilder = new SuggestBuilder();
suggestBuilder.addSuggestion("suggest_name", termSuggestionBuilder);
sourceBuilder.suggest(suggestBuilder);
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
以上代码使用SearchSourceBuilder对象添加了一个基于文本的完整推荐搜索建议。
结论
本文介绍了如何使用缓存、调整分片大小和数量以及使用搜索建议等方法来优化Elasticsearch的搜索性能。使用这些技术可以提高搜索响应速度,并增强用户体验。在实际应用中,需要根据具体的搜索需求来选择合适的优化方式。
集群管理
配置和管理Elasticsearch集群是使大规模Elasticsearch应用程序成功运行的关键。本文将介绍如何进行节点发现、负载均衡和故障转移等操作来配置和管理Elasticsearch集群。
节点发现
节点发现是Elasticsearch中一个重要的概念,它允许新节点加入到已有的Elasticsearch集群中。以下是使用Java API启用节点发现功能的代码示例:
Settings settings = Settings.builder().put("discovery.seed_hosts", "host1:9300,host2:9300").put("cluster.name", "my_cluster_name").build();
TransportClient client = new PreBuiltTransportClient(settings);
以上代码使用Settings对象启用了节点发现功能,并将节点列表设置为host1和host2。
负载均衡
负载均衡是在分布式系统中非常重要的一部分,它可以确保系统中所有节点都平均地承载负载。以下是使用Java API添加负载均衡功能的代码示例:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")).setHttpClientConfigCallback(httpClientBuilder -> httpClientBuilder.addInterceptorLast(new ElasticsearchInterceptor())));
以上代码使用RestClient对象添加了一个名为ElasticsearchInterceptor的拦截器来实现负载均衡。
故障转移
故障转移是在Elasticsearch集群中必须考虑的问题。当某个节点发生故障时,需要立即采取行动将其替换为另一个节点。以下是使用Java API添加自动故障转移功能的代码示例:
Settings settings = Settings.builder().put("cluster.routing.allocation.enable", "all").put("cluster.routing.allocation.node_initial_primaries_recoveries", 20).put("cluster.routing.allocation.node_concurrent_recoveries", 2).put("indices.recovery.max_bytes_per_sec", "50mb").build();
以上代码启用了自动故障转移功能,并设置了一些相关参数,例如索引恢复速度和并发恢复数等。
结论
本文介绍了如何进行节点发现、负载均衡和故障转移等操作来配置和管理Elasticsearch集群。这些技术可以使Elasticsearch应用程序更稳定、可靠和高效。在实际应用中,需要选择合适的配置选项和管理方案来满足具体需求。
安全性和访问控制
保护Elasticsearch集群和数据是任何生产环境下应用程序的必要条件之一。本文将介绍如何使用访问控制、加密和身份验证等技术来提高Elasticsearch的安全性。
访问控制
访问控制是Elasticsearch中一个非常重要的概念,它可以确保只有经过授权的用户才能够访问Elasticsearch集群和数据。以下是使用Java API添加基于用户名/密码的访问控制的代码示例:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")).setHttpClientConfigCallback(httpClientBuilder -> httpClientBuilder.setDefaultCredentialsProvider(new BasicCredentialsProvider())).setRequestConfigCallback(requestConfigBuilder -> requestConfigBuilder.setConnectTimeout(5000).setSocketTimeout(60000)));
以上代码使用RestClient对象添加了一个BasicCredentialsProvider对象作为默认凭据提供者,以实现基于用户名/密码的访问控制。
加密
加密可以确保在Elasticsearch集群和数据传输过程中的安全性。以下是使用Java API启用HTTPS加密的代码示例:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "https")));
以上代码使用RestClient对象启用了HTTPS加密协议,以确保数据传输的安全性。
身份验证
身份验证是Elasticsearch中一个非常重要的概念,它可以确保只有经过授权的用户才能够访问和修改Elasticsearch集群和数据。以下是使用Java API添加基于X-Pack的身份验证功能的代码示例:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "https")).setHttpClientConfigCallback(httpClientBuilder -> httpClientBuilder.setDefaultCredentialsProvider(new BasicCredentialsProvider())).setRequestConfigCallback(requestConfigBuilder -> requestConfigBuilder.setConnectTimeout(5000).setSocketTimeout(60000)).setXpackBuilder(XPackClientBuilder.builder("username", "password")));
以上代码使用RestClient对象启用了基于X-Pack的身份验证功能,并将用户名和密码设置为"username"和"password"。
结论
本文介绍了如何使用访问控制、加密和身份验证等技术来提高Elasticsearch的安全性。这些技术可以确保Elasticsearch集群和数据的安全性,并保护其免受未经授权的访问和攻击。在实际应用中,需要根据具体需求来选择合适的安全措施。
应用程序集成
将Elasticsearch集成到应用程序中是实现数据搜索和分析的关键。本文将介绍如何使用REST API和各种客户端库来将Elasticsearch集成到应用程序中。
REST API
Elasticsearch提供了REST API,以便应用程序可以通过HTTP协议与Elasticsearch进行交互。以下是使用Java代码向Elasticsearch索引添加文档的示例:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));
IndexRequest request = new IndexRequest("my_index");
request.id("1");
String jsonString = "{" +"\"name\":\"John\"," +"\"age\":30," +"\"city\":\"New York\"" +"}";
request.source(jsonString, XContentType.JSON);
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
以上代码使用RestHighLevelClient对象向名为"my_index"的索引添加ID为1的文档。
客户端库
Elasticsearch也提供了各种语言的客户端库,以便应用程序可以更容易地与Elasticsearch交互。以下是使用Java API添加Elasticsearch客户端库的代码示例:
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.14.0</version>
</dependency>
以上代码将elasticsearch-rest-high-level-client客户端库添加到Java项目中。
以下是使用Java代码向Elasticsearch索引添加文档的客户端库示例:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));
IndexRequest request = new IndexRequest("my_index");
request.id("1");
Map<String, Object> jsonMap = new HashMap<>();
jsonMap.put("name", "John");
jsonMap.put("age", 30);
jsonMap.put("city", "New York");
request.source(jsonMap);
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
以上代码使用RestHighLevelClient对象和Elasticsearch客户端库向名为"my_index"的索引添加ID为1的文档。
结论
本文介绍了如何使用REST API和各种语言的客户端库将Elasticsearch集成到应用程序中。这些方法可以使应用程序更有效地与Elasticsearch交互,并实现数据搜索和分析等功能。在实际应用中,需要根据具体需求来选择合适的集成方式。
相关文章:
在生产环境中部署Elasticsearch:最佳实践和故障排除技巧——聚合与搜索(三)
前言 「作者主页」:雪碧有白泡泡 「个人网站」:雪碧的个人网站 「推荐专栏」: ★java一站式服务 ★ ★ React从入门到精通★ ★前端炫酷代码分享 ★ ★ 从0到英雄,vue成神之路★ ★ uniapp-从构建到提升★ ★ 从0到英雄ÿ…...

基于weka手工实现KNN
一、KNN模型 K最近邻(K-Nearest Neighbors,简称KNN)算法是一种常用的基于实例的监督学习算法。它可以用于分类和回归问题,并且是一种非常直观和简单的机器学习算法。 KNN算法的基本思想是:对于一个新的样本数据&…...

Lua 闭包
一、Lua 中的函数 Lua 中的函数是第一类值。意味着和其他的常见类型的值(例如数值和字符串)具有同等权限。 举个例子,函数也可以像其他类型一样存储起来,然后调用 -- 将 a.p 指向 print 函数 a { p print } -- 使用 a.p 函数…...
—— JVM篇)
Java技术整理(1)—— JVM篇
1、什么是JVM? JVM是一个可运行Java代码的虚拟计算机,包括一套字节码指令集,一组寄存器,一个栈,一个垃圾回收,堆和一个存储方式栈。JVM 是运行在操作系统之上,并不与操作系统直接交互。 2、运行…...
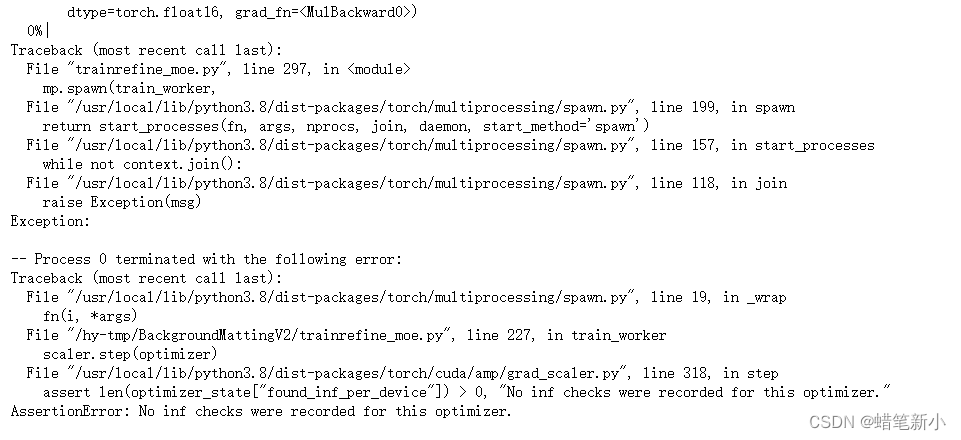
bug解决:AssertionError: No inf checks were recorded for this optimizer.
这真的是最恶心的一个error(比网络回传找哪层没有传播到还要恶心!),找了好久的问题所在之处,最后偶然发现了这篇文章: 解决pytorch半精度amp训练nan问题 - 知乎 然后发现自己用的混合精度训练,发…...

Django笔记之数据库查询优化汇总
1、性能方面 1. connection.queries 前面我们介绍过 connection.queries 的用法,比如我们执行了一条查询之后,可以通过下面的方式查到我们刚刚的语句和耗时 >>> from django.db import connection >>> connection.queries [{sql: S…...
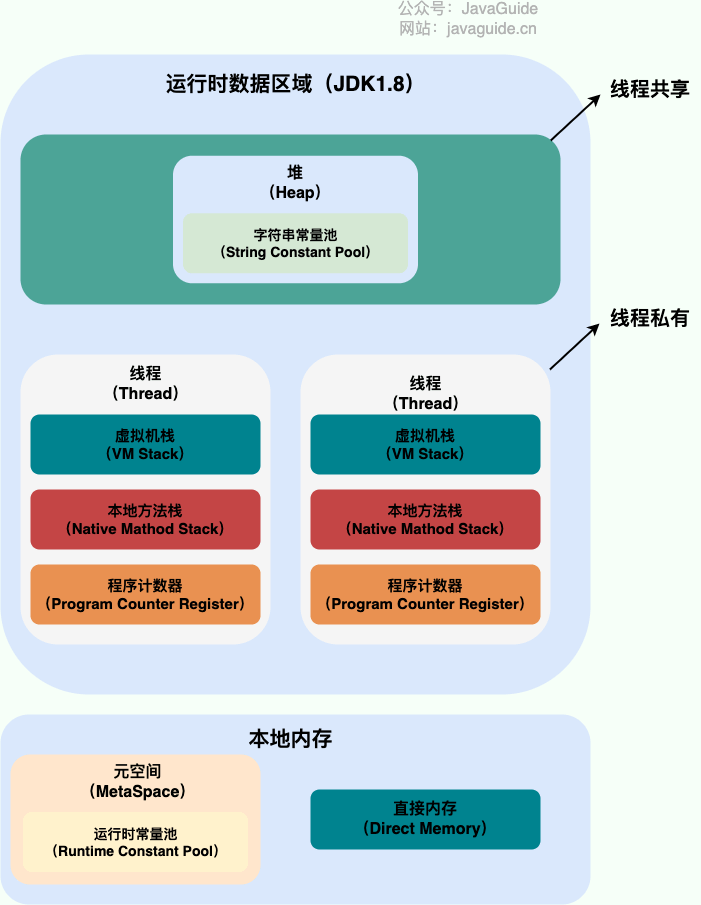
JVM内存区域
预备 为了更好的理解类加载和垃圾回收,先要了解一下JVM的内存区域(如果没有特殊说明,都是针对的是 HotSpot 虚拟机。)。 Java 源代码文件经过编译器编译后生成字节码文件,然后交给 JVM 的类加载器,加载完…...
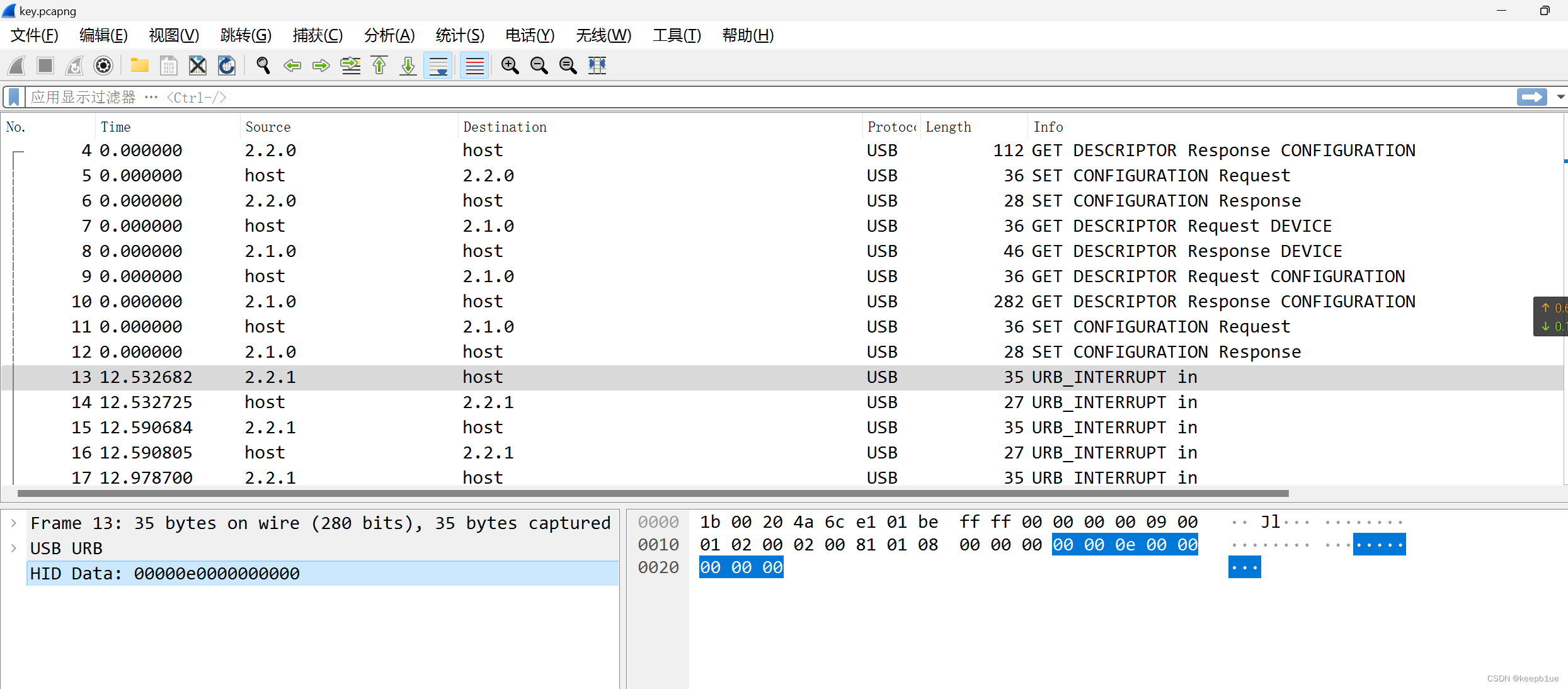
某行业CTF一道流量分析题
今晚看了一道题,记录学习下。 给了一个hacktrace.pcapng,分析主要内容如下: 上传两个文件,一个mouse.m2s,一个mimi.zip,将其导出。 mimi.zip中存放着secret.zip和key.pcapng 不过解压需要密码ÿ…...
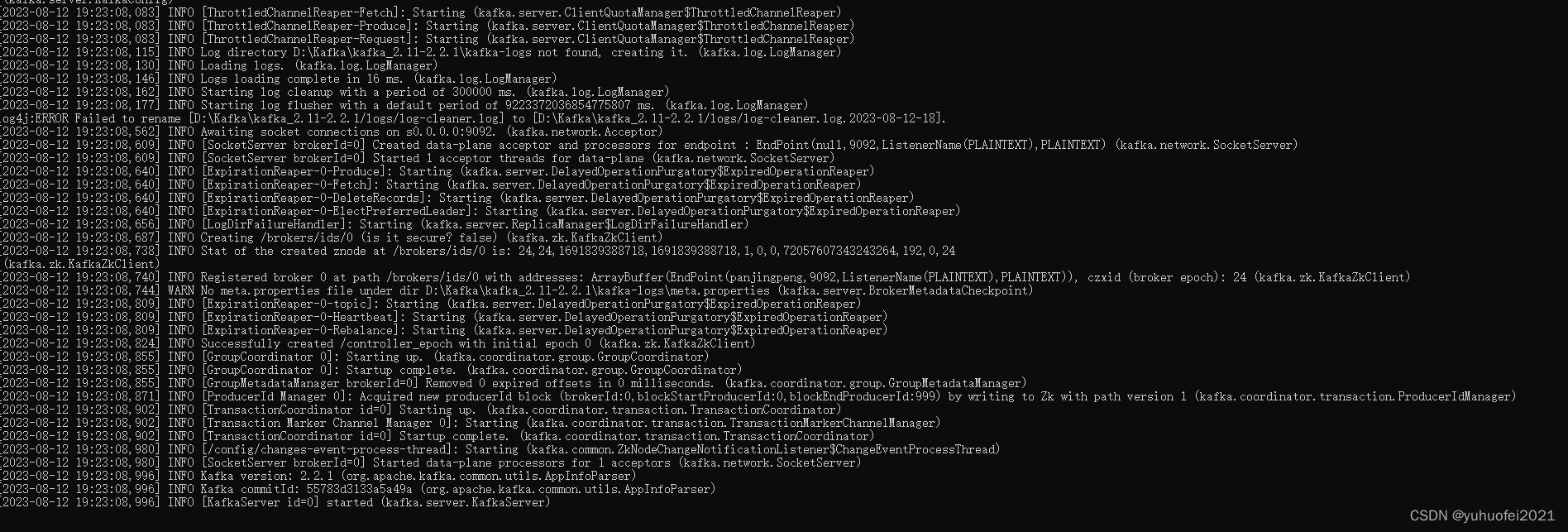
【Kafka】1.Kafka简介及安装
目 录 1. Kafka的简介1.1 使用场景1.2 基本概念 2. Kafka的安装2.1 下载Kafka的压缩包2.2 解压Kafka的压缩包2.3 启动Kafka服务 1. Kafka的简介 Kafka 是一个分布式、支持分区(partition)、多副本(replica)、基于 zookeeper 协调…...
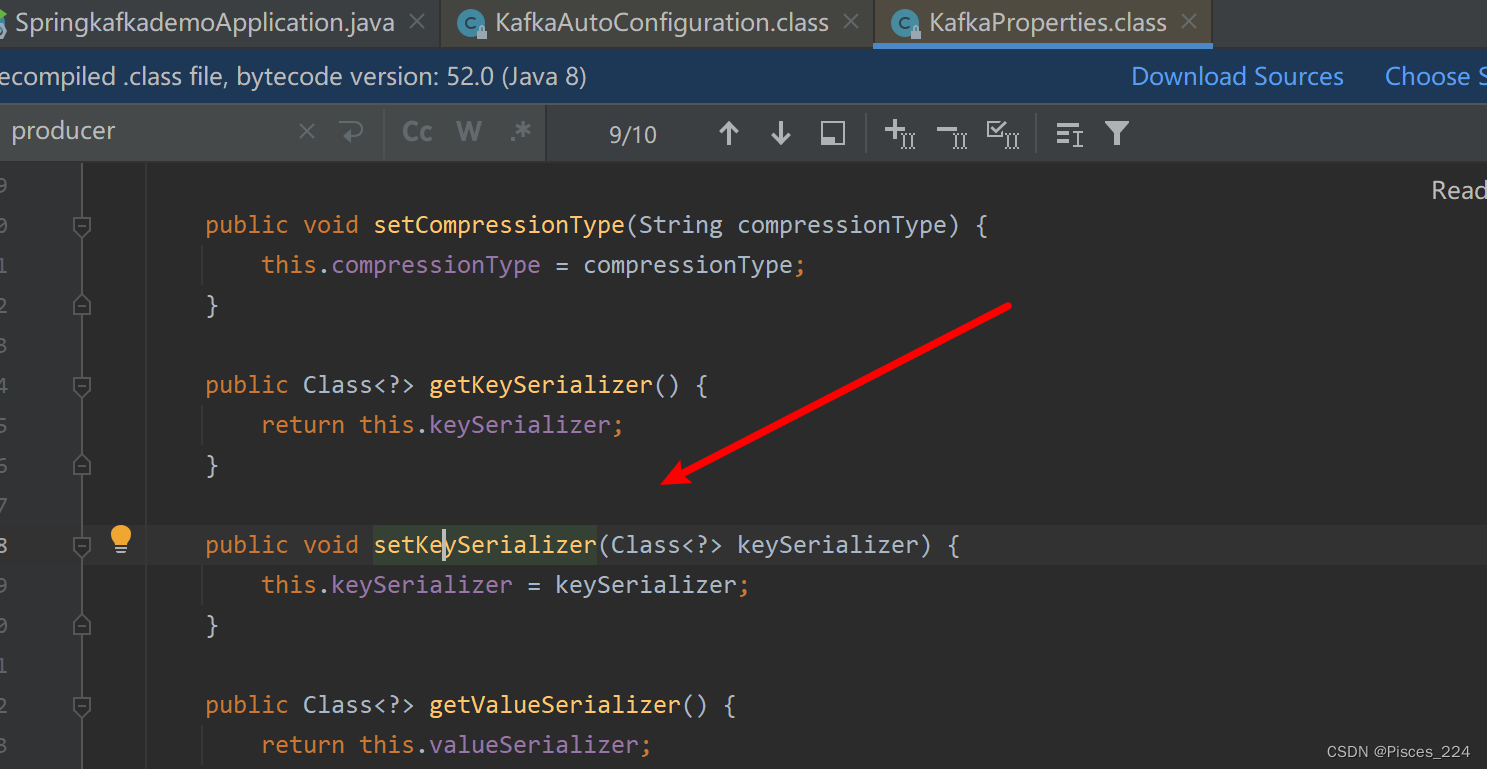
Kafka API与SpringBoot调用
文章目录 首先需要命令行创建一个名为cities的主题,并且创建该主题的订阅者。 1、使用Kafka原生API1.1、创建spring工程1.2、创建发布者1.3、对生产者的优化1.4、批量发送消息1.5、创建消费者组1.6 消费者同步手动提交1.7、消费者异步手动提交1.8、消费者同异步手动…...

JavaScript构造函数和类的区别
原文 构造函数 没有显式的创建对象创建对象时使用new操作符。所有属性和方法赋值给this对象。没有return语句按照惯例,构造函数的方法名首字母应该使用大写字母,用于区分普通函数,其实构造函数也是函数,其主要功能是用来创建对象…...
Spring与Spring Bean
Spring 原理 它是一个全面的、企业应用开发一站式的解决方案,贯穿表现层、业务层、持久层。但是 Spring 仍然可 以和其他的框架无缝整合。 Spring 特点 轻量级 控制反转 面向切面 容器 框架集合 Spring 核心组件 Spring 总共有十几个组件核心容器(Spring core) S…...
并发相关面试题
巩固基础,砥砺前行 。 只有不断重复,才能做到超越自己。 能坚持把简单的事情做到极致,也是不容易的。 如何理解volatile关键字 在并发领域中,存在三大特性:原子性、有序性、可见性。volatile关键字用来修饰对象的属性…...
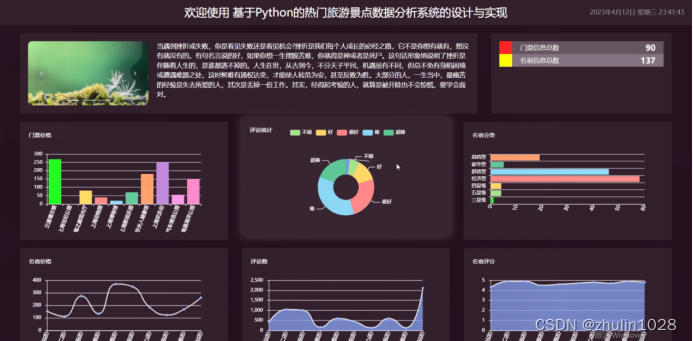
Hadoop+Python+Django+Mysql热门旅游景点数据分析系统的设计与实现(包含设计报告)
系统阐述的是使用热门旅游景点数据分析系统的设计与实现,对于Python、B/S结构、MySql进行了较为深入的学习与应用。主要针对系统的设计,描述,实现和分析与测试方面来表明开发的过程。开发中使用了 django框架和MySql数据库技术搭建系统的整体…...

php中nts和ts
PHP语言解析器:官方提供了2种类型的版本,线程安全(TS)版和非线程安全(NTS)版 TS: TS(Thread-Safety)即线程安全,多线程访问时,采用了加锁机制,当一个线程访问该类的某个数据时进行数据加锁保护,其他线程不能同时进行访…...
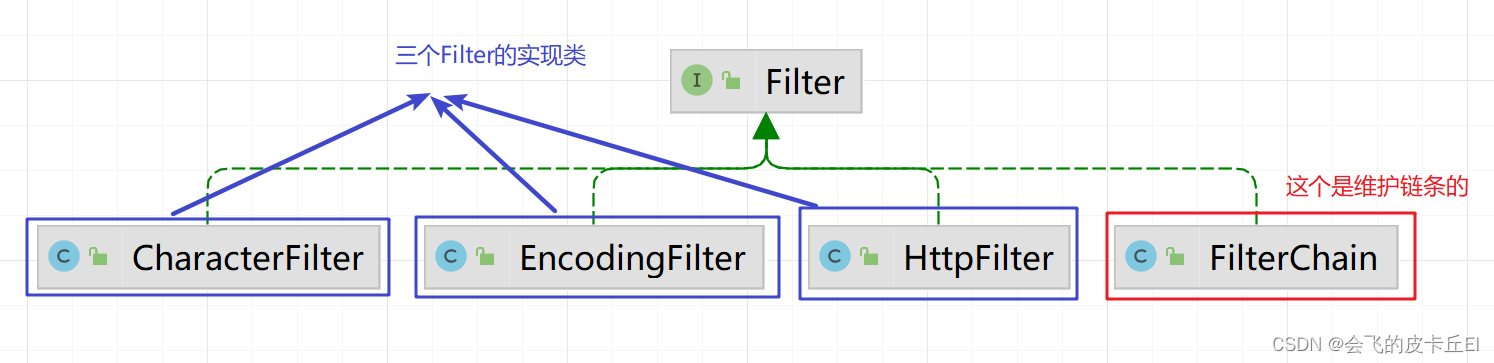
设计模式之责任链模式【Java实现】
责任链(Chain of Resposibility) 模式 概念 责任链(chain of Resposibility) 模式:为了避免请求发送者与多个请求处理者耦合在一起,于是将所有请求的处理者 通过前一对象记住其下一个对象的引用而连成一条…...

Android 12.0 系统systemui状态栏下拉左滑显示通知栏右滑显示控制中心模块的流程分析
1.前言 在android12.0的系统rom定制化开发中,在系统原生systemui进行自定义下拉状态栏布局的定制的时候,需要在systemui下拉状态栏下滑的时候,根据下滑坐标来 判断当前是滑出通知栏还是滑出控制中心模块,所以就需要根据屏幕宽度,来区分x坐标值为多少是左滑出通知栏或者右…...
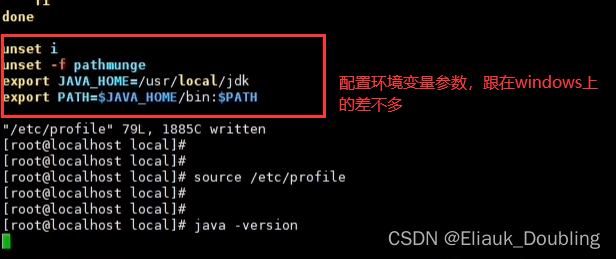
服务器安装JDK
三种方法 方法一: 方法二: 首先登录到Oracle官网下载JDK JDK上传到服务器中,记住文件上传的位置是在哪里(我放的位置在/www/java),然后看下面指示进行安装 方法三: 首先登录到Oracle官网下载…...

cpu查询
1.mpstat查看系统cpu状况 mpstat 1 1或者mpstat -P ALL查看每个cpu使用状态,(用户态cpu是用来,内核态cpu使用率,等待IO使用率) 2.vmstat 可以查看系统运行任务数(正在cpu运行进程和就绪队列进程࿰…...

【muduo】关于自动增长的缓冲区
目录 为什么需要缓冲区自动增长的缓冲区buffer数据结构buffer类 写详细比较费时间,就简单总结下。 总结自Linux 多线程服务端编程:使用 muduo C 网络库 Muduo网络编程: IO-multiplexnon-blocking 为什么需要缓冲区 Non-blocking IO 的核心…...
)
高精度计算插件 decimal.js 处理 JS 浮点数精度问题(. + . !== .)
OCP原则 ocp指开闭原则,对扩展开放,对修改关闭。是七大原则中最基本的一个原则。 依赖倒置原则(DIP) 什么是依赖倒置原则 核心是面向接口编程、面向抽象编程, 不是面向具体编程。 依赖倒置原则的目的 降低耦合度&#…...

抖音视频批量下载架构演进:从单点工具到企业级内容管理系统的技术突破
抖音视频批量下载架构演进:从单点工具到企业级内容管理系统的技术突破 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser…...

Stable Yogi Leather-Dress-Collection生成控制进阶:使用ControlNet精确约束服饰轮廓
Stable Yogi Leather-Dress-Collection生成控制进阶:使用ControlNet精确约束服饰轮廓 每次看到那些设计感十足的皮革连衣裙,我都会想,如果能把自己的草图直接变成高清效果图该多好。以前用AI生成图片,总像是在开盲盒——输入一段…...

千问3.5-2B惊艳效果:CAD图纸局部→尺寸标注识别+公差解析+材料属性提取
千问3.5-2B惊艳效果:CAD图纸局部→尺寸标注识别公差解析材料属性提取 1. 专业级CAD图纸解析能力展示 千问3.5-2B作为Qwen系列的小型视觉语言模型,在工程图纸解析方面展现出令人惊艳的专业能力。不同于普通OCR工具,它能真正理解CAD图纸的技术…...
技术草案)
Internet Protocol Version 8(IPv8)技术草案
注:本文为 “IPv8” 相关合辑。 图片清晰度受引文原图所限。 略作重排,如有内容异常,请看原文。 1. 引言 2026 年 4 月 14 日,IETF(Internet Engineering Task Force)Datatracker 发布了一份个人提交的 In…...

别再只盯着协议了!手把手教你用示波器实测MIPI D-PHY的HS/LP模式切换波形
示波器实战:深度解析MIPI D-PHY模式切换的波形捕获技巧 当你在调试一块搭载MIPI接口的摄像头模组时,是否遇到过图像传输不稳定、画面闪烁甚至完全无信号的问题?这些现象往往与D-PHY在高速模式(HS)和低功耗模式(LP)之间的切换时序异常有关。本…...

程序员的心理学学习笔记 - 逆火效应
逆火效应 1、基本介绍 逆火效应指的是当人们遇到与自己坚定信念相矛盾的证据时,不但不会改变想法,反而会更加坚信自己原来的观点,有如下原因威胁感:挑战某个信念等于挑战自我认同,大脑会启动防御认知失调:矛…...

用Python实战模糊粗糙集:从理论到代码,5步搞定高维数据降维
用Python实战模糊粗糙集:从理论到代码,5步搞定高维数据降维 当你的数据集包含数百个传感器读数或用户行为指标时,传统降维方法往往会丢失关键信息。我在处理电商用户画像数据时就遇到过这个问题——PCA处理后那些微妙的购买模式特征全都不见了…...

5分钟快速上手:Android Studio中文语言包完整配置指南
5分钟快速上手:Android Studio中文语言包完整配置指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为Android …...

Vue3 开发避坑指南:从 `no-mutating-props` 报错看单向数据流的正确实践
1. 为什么会出现 no-mutating-props 报错? 第一次在 Vue3 项目中看到这个报错时,我也是一头雾水。明明代码运行得好好的,突然就蹦出个 Unexpected mutation of "xxx" prop 的错误提示。后来仔细研究才发现,这其实是 Vue…...