常见分布式ID解决方案总结:数据库、算法、开源组件
常见分布式ID解决方案总结
- 分布式ID
- 分布式ID方案之数据库
- 数据库主键自增
- 数据库号段模式
- Redis自增
- MongoDB
- 分布式ID方案之算法
- UUID
- Snowflake(雪花算法)
- 雪花算法的使用
- IdWorker工具类
- 配置分布式ID生成器
- 分布式ID方案之开源组件
- uid- generator(百度)
- Tinyid(滴滴)
- Leaf(美团)
- 三者比较
- Leaf组件的使用
- 源码打包
- 引入依赖
- Leaf配置参数
- 号段模式配置
- Snowflake模式配置
- 注解启动leaf
- API的使用
- 号段模式测试
- 雪花算法测试
分布式ID
分布式 ID(Distributed ID)是指在分布式系统中生成全局唯一的标识符,用于标识不同实体或数据对象。在分布式系统中,由于数据存储、计算和处理都分散在不同的节点上,因此需要一个可靠的方式来跟踪和标识这些数据对象。
分布式ID最低要求:
全局唯一 :ID 的全局唯一性肯定是首先要满足的高性能 : 分布式 ID 的生成速度要快,对本地资源消耗要小高可用 :生成分布式 ID 的服务要保证可用性无限接近于 100%方便易用 :拿来即用,使用方便,快速接入
优秀的分布式 ID
安全 :ID 中不包含敏感信息有序递增 :如果ID存放在数据库,ID的有序性可以提升数据库写入速度。有利于ID来进行排序有具体的业务含义 :生成的 ID 如果能有具体的业务含义,可以让定位问题以及开发更透明化(通过 ID 就能确定是哪个业务)独立部署 :分布式系统单独有一个发号器服务,专门用来生成分布式 ID
分布式ID方案之数据库
数据库主键自增
数据库自增ID是在数据库中创建表时,通过设置一个自增的ID字段来实现的。每当插入一条记录时,数据库会自动为该记录生成一个唯一的ID。
数据库自增ID可以很好地保证ID的唯一性,但在高并发和大规模的分布式系统中,容易出现瓶颈和性能问题。同时,由于数据库自增ID只能在单个数据库中保证唯一性,因此需要通过分库分表等方式来支持多台机器上的生成。
简言之:
简单方便,有序递增,方便排序和分页并发性能不高,受限于数据库性能分库分表,需改造,较复杂自增数据量泄露
数据库号段模式
数据库主键自增这种模式,每次获取 ID 都要访问一次数据库,数据库压力大。因此,可以批量获取,然后存在内存里面,需要用到的时候,直接从内存里面拿来使用
主键自增
1,2,3......
号段模式:每请求一次分配一个号段
100,200,3001...100,101...200,201...300
号段模式相比主键自增而言: 性能提高且自增
Redis自增
Redis 可以通过自增命令来实现分布式 ID 的生成。常用的方法是使用 Redis 的自增命令 INCR,将一个特定的 key 自增,并将其作为 ID 返回。这种方法是线程安全的,可以在分布式系统中使用
即使有AOF和RDB,但是依然会存在数据丢失的可能,有可能会造成ID重复性能不错并且生成的 ID 是有序递增的,但是自增存在数据量泄露
MongoDB
MongoDB ObjectId是MongoDB数据库中的一个内置数据类型,用于唯一标识MongoDB文档(Document)。
它由12个字节组成,其中前4个字节表示时间戳,接下来3个字节表示机器ID,然后2个字节表示进程ID,最后3个字节表示随机值。
优缺点:
生成的 ID 是有序递增的当机器时间不对的情况下,可能导致会产生重复 IDID生成有规律性,存在安全性问题
分布式ID方案之算法
UUID
UUID是一种通用唯一识别码,它是由一组算法和标准组成的,可以保证在全球范围内唯一性。UUID不依赖于任何中心节点,可以在分布式系统中很好地保证ID的唯一性。缺点是它生成的ID比较长,不利于索引和查询
开放软件基金会(OSF)规范定义了包括网卡MAC地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素。利用这些元素来生成UUID。
优缺点:
通过本地生成,没有经过网络I/O,性能较快无序,无法预测他的生成顺序存储消耗空间大(32 个字符串,128 位)不能生成递增有序的数字当机器时间不对的情况下,可能导致会产生重复 ID
Snowflake(雪花算法)
雪花算法是 Twitter 提出的一种分布式ID生成算法。雪花算法可以在多台机器上生成不重复的ID,支持高并发和大规模的分布式系统,但需要保证数据中心ID和机器ID的唯一性。
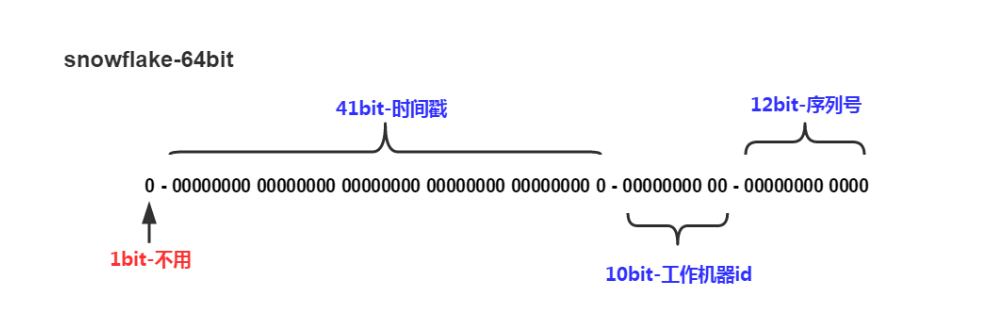
它的原理是将一个64位的long类型的ID分为4个部分:时间戳、数据中心ID、机器ID和序列号。
时间戳占用了42位,可以使用69年,数据中心ID和机器ID分别占用了5位,可以支持32个数据中心和32个机器,序列号占用了12位,可以支持每个节点每毫秒生成4096个ID。
细一点说:生成的64位ID可以分成5个部分:
1位符号位标识 - 41位时间戳 - 5位数据中心标识 - 5位机器标识 - 12位序列号
时间范围
2^41/(365*24*60*60*1000)=69年
工作进程数量
5+5 :区域+服务器标识2^10=1024
序列号数量
2^12=4096
| 分段 | 作用 | 说明 |
|---|---|---|
| 1bit | 保留不用 | long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1 |
| 41bit | 时间戳,精确到毫秒 | 存储的是时间截的差值(当前时间截 - 开始时间截),结果约等于69.73年 |
| 5bit | 数据中心 | 最多支持2的5次方(32)个节点 |
| 5bit | 机器id | 最多支持2的5次方(32)个节点 |
| 12bit | 毫秒内的计数器 | 每个节点每毫秒最多产生2的12次方(4096)个id |
默认情况下41bit的时间戳可以支持该算法使用到2082年,10bit的工作机器id可以支持1024台机器,序列号支持1毫秒产生4096个自增序列id 。SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,经测试,SnowFlake每秒能够产生26万ID左右
优缺点:
生成速度比较快、生成的 ID 有序递增、比较灵活依赖时间,当机器时间不对的情况下,可能导致会产生重复 ID
雪花算法的使用
IdWorker工具类
/*** Twitter的Snowflake JAVA实现方案* 分布式自增长ID*/
public class IdWorker {// 时间起始标记点,作为基准,一般取系统的最近时间(一旦确定不能变动)private final static long twepoch = 1288834974657L;// 机器标识位数private final static long workerIdBits = 5L;// 数据中心标识位数private final static long datacenterIdBits = 5L;// 机器ID最大值private final static long maxWorkerId = -1L ^ (-1L << workerIdBits);// 数据中心ID最大值private final static long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);// 毫秒内自增位private final static long sequenceBits = 12L;// 机器ID偏左移12位private final static long workerIdShift = sequenceBits;// 数据中心ID左移17位private final static long datacenterIdShift = sequenceBits + workerIdBits;// 时间毫秒左移22位private final static long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;private final static long sequenceMask = -1L ^ (-1L << sequenceBits);/* 上次生产id时间戳 */private static long lastTimestamp = -1L;// 0,并发控制private long sequence = 0L;private final long workerId;// 数据标识id部分private final long datacenterId;public IdWorker() {this.datacenterId = getDatacenterId(maxDatacenterId);this.workerId = getMaxWorkerId(datacenterId, maxWorkerId);}/*** @param workerId 工作机器ID* @param datacenterId 序列号*/public IdWorker(long workerId, long datacenterId) {if (workerId > maxWorkerId || workerId < 0) {throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));}if (datacenterId > maxDatacenterId || datacenterId < 0) {throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));}this.workerId = workerId;this.datacenterId = datacenterId;}/*** 获取下一个ID** @return*/public synchronized long nextId() {long timestamp = timeGen();if (timestamp < lastTimestamp) {throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));}if (lastTimestamp == timestamp) {// 当前毫秒内,则+1sequence = (sequence + 1) & sequenceMask;if (sequence == 0) {// 当前毫秒内计数满了,则等待下一秒timestamp = tilNextMillis(lastTimestamp);}} else {sequence = 0L;}lastTimestamp = timestamp;// ID偏移组合生成最终的ID,并返回IDlong nextId = ((timestamp - twepoch) << timestampLeftShift)| (datacenterId << datacenterIdShift)| (workerId << workerIdShift) | sequence;return nextId;}private long tilNextMillis(final long lastTimestamp) {long timestamp = this.timeGen();while (timestamp <= lastTimestamp) {timestamp = this.timeGen();}return timestamp;}private long timeGen() {return System.currentTimeMillis();}/*** <p>* 获取 maxWorkerId* </p>*/protected static long getMaxWorkerId(long datacenterId, long maxWorkerId) {StringBuffer mpid = new StringBuffer();mpid.append(datacenterId);String name = ManagementFactory.getRuntimeMXBean().getName();if (!name.isEmpty()) {/** GET jvmPid*/mpid.append(name.split("@")[0]);}/** MAC + PID 的 hashcode 获取16个低位*/return (mpid.toString().hashCode() & 0xffff) % (maxWorkerId + 1);}/*** <p>* 数据标识id部分* </p>*/protected static long getDatacenterId(long maxDatacenterId) {long id = 0L;try {InetAddress ip = InetAddress.getLocalHost();NetworkInterface network = NetworkInterface.getByInetAddress(ip);if (network == null) {id = 1L;} else {byte[] mac = network.getHardwareAddress();id = ((0x000000FF & (long) mac[mac.length - 1])| (0x0000FF00 & (((long) mac[mac.length - 2]) << 8))) >> 6;id = id % (maxDatacenterId + 1);}} catch (Exception e) {System.out.println(" getDatacenterId: " + e.getMessage());}return id;}public static void main(String[] args) {IdWorker idWorker = new IdWorker(0, 0);for (int i = 0; i < 10000; i++) {long nextId = idWorker.nextId();System.out.println(nextId);}}}
配置分布式ID生成器
application.ym添加配置
workerId: 0
datacenterId: 0
IdWorker添加到容器
@Value("${workerId}")private Integer workerId;
@Value("${datacenterId}")private Integer datacenterId;
@Beanpublic IdWorker idWorker(){return new IdWorker(workerId,datacenterId);}
分布式ID方案之开源组件
uid- generator(百度)
UidGenerator是百度开源的一款基于 Snowflake的唯一 ID 生成器,是对 Snowflake进行了改进
GitHub:https://github.com/baidu/uid-generator

Tinyid(滴滴)
Tinyid是滴滴开源的一款基于数据库号段模式的唯一 ID 生成器。
GitHub: https://github.com/didi/tinyid

Leaf(美团)
Leaf是美团开源的一个分布式 ID 解决方案。提供了号段模式 和 Snowflake这两种模式来生成分布式 ID。
目前Leaf覆盖了美团点评公司内部金融、餐饮、外卖、酒店旅游、猫眼电影等众多业务线。在4C8G VM基础上,通过公司RPC方式调用,QPS压测结果近5w/s,TP999 1ms。
Leaf 设计文档: https://tech.meituan.com/2017/04/21/mt-leaf.html
GitHub:https://github.com/meituan-diaNPing/leaf
三者比较
百度:只支持雪花算法滴滴:只支持数据库号段,多DB,高可用,java- client,适合对id有高可用需求美团:号段模式和 snowflake模,适合多种场景分布式id
Leaf组件的使用
源码打包
git clone git@github.com:Meituan-Dianping/Leaf.git
cd Leaf
git checkout feature/spring-boot-starter
mvn clean install -Dmaven.test.skip=true
引入依赖
目前Leaf最新使用2.0.1.RELEASE的starter版本
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.0.1.RELEASE</version></parent><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--引入源码编译打包安装到本地的Leaf--><dependency><artifactId>leaf-boot-starter</artifactId><groupId>com.sankuai.inf.leaf</groupId><version>1.0.1-RELEASE</version></dependency><!--zk--><dependency><groupId>org.apache.curator</groupId><artifactId>curator-recipes</artifactId><version>2.6.0</version><exclusions><exclusion><artifactId>log4j</artifactId><groupId>log4j</groupId></exclusion></exclusions></dependency></dependencies>
Leaf配置参数
Leaf 提供两种生成的ID的方式(号段模式和snowflake模式),可以同时开启两种方式,也可以指定开启某种方式(默认两种方式为关闭状态)。
| 配置项 | 含义 | 默认值 |
|---|---|---|
| leaf.name | leaf | 服务名 |
| leaf.segment.enable | 是否开启号段模式 | false |
| leaf.jdbc.url | mysql 库地址 | |
| leaf.jdbc.username | mysql 用户名 | |
| leaf.jdbc.password | mysql 密码 | |
| leaf.snowflake.enable | 是否开启snowflake模式 | false |
| leaf.snowflake.zk.address | snowflake模式下的zk地址 | |
| leaf.snowflake.port | snowflake模式下的服务注册端口 |
号段模式配置
如果使用号段模式,需要建立DB表,并配置leaf.jdbc.url, leaf.jdbc.username, leaf.jdbc.password如果不想使用该模式配置leaf.segment.enable=false即可。
CREATE DATABASE leafCREATE TABLE `leaf_alloc` (`biz_tag` varchar(128) NOT NULL DEFAULT '',`max_id` bigint(20) NOT NULL DEFAULT '1',`step` int(11) NOT NULL,`description` varchar(256) DEFAULT NULL,`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB;insert into leaf_alloc(biz_tag, max_id, step, description) values('leaf-segment-test', 1, 2000, 'Test leaf Segment Mode Get Id')
在classpath下配置leaf.properties
leaf.name=com.sankuai.leaf.opensource.test
leaf.segment.enable=true
leaf.segment.url=jdbc:mysql://127.0.0.1:3306/leaf
leaf.segment.username=root
leaf.segment.password=123456
Snowflake模式配置
算法取自twitter开源的snowflake算法。如果不想使用该模式配置leaf.snowflake.enable=false即可。
在classpath下配置leaf.properties
在leaf.properties中配置leaf.snowflake.zk.address,配置leaf 服务监听的端口leaf.snowflake.port。
leaf.snowflake.enable=true
leaf.snowflake.address=127.0.0.1
leaf.snowflake.port=2181
注解启动leaf
使用@EnableLeafServer注解启动leaf
@SpringBootApplication
@EnableLeafServer
public class DistributedIdApplication {public static void main(String[] args) {SpringApplication.run(DistributedIdApplication.class, args);}
}
API的使用
@RestController
public class IdContoller {@Autowiredprivate SegmentService segmentService;@Autowiredprivate SnowflakeService snowflakeService;@GetMapping("/segment")public Result segment() {
// segmentService.getId("leaf-segment-test").getId();return segmentService.getId("leaf-segment-test");}@GetMapping("/snowflake")public Result snowflake() {// 参数key无实际意义,受迫于统一接口的实现return snowflakeService.getId("snowflake");}
}
参数key无实际意义,受迫于统一接口的实现
public interface IDGen {Result get(String var1);boolean init();
}public Result getId(String key) {return this.idGen.get(key);}
号段模式中该参数key有着重要意义

号段模式测试
数据库表初始时

访问地址:http://localhost:8080/segment

请求获取id值后,号段模式提前加载

重启服务后再次访问,使用新的号段

号段模式再一次提前加载

雪花算法测试
访问地址:http://localhost:8080/snowflake

相关文章:
常见分布式ID解决方案总结:数据库、算法、开源组件
常见分布式ID解决方案总结 分布式ID分布式ID方案之数据库数据库主键自增数据库号段模式Redis自增MongoDB 分布式ID方案之算法UUIDSnowflake(雪花算法) 雪花算法的使用IdWorker工具类配置分布式ID生成器 分布式ID方案之开源组件uid- generator(百度)Tinyid(滴滴&…...

记录--Loading 用户体验 - 加载时避免闪烁
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 在切换详情页中有这么一个场景,点击上一条,会显示上一条的详情页,同理,点击下一条,会显示下一条的详情页。 伪代码如下所示: 我们…...

系统架构设计专业技能 · 软件工程之软件测试与维护(六)【系统架构设计师】
系列文章目录 系统架构设计专业技能 网络规划与设计(三)【系统架构设计师】 系统架构设计专业技能 系统安全分析与设计(四)【系统架构设计师】 系统架构设计高级技能 软件架构设计(一)【系统架构设计师…...

基于亚奈奎斯特采样和SOMP算法的平板脉冲响应空间插值matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部分核心程序 ...................................................................... %fine regular gr…...

柏睿向量数据库Rapids VectorDB赋能企业级大模型构建及智能应用
ChatGPT的问世,在为沉寂已久的人工智能重新注入活力的同时,也把长期默默无闻的向量数据库推上舞台。今年4月以来,全球已有4家知名向量数据库公司先后获得融资,更加印证了向量数据库在AI大模型时代的价值。 什么是向量数据库? 在认识向量数据库前,先来了解一下最常见的关…...
)
装备合成(牛客)
登录—专业IT笔试面试备考平台_牛客网 题目: 牛牛有x件材料a和y件材料b,用2件材料a和3件材料b可以合成一件装备,用4件材料a和1件材料b也可以合成一件装备。牛牛想要最大化合成的装备的数量,于是牛牛找来了你帮忙。 分析ÿ…...
C语言学习之一级指针二级指针
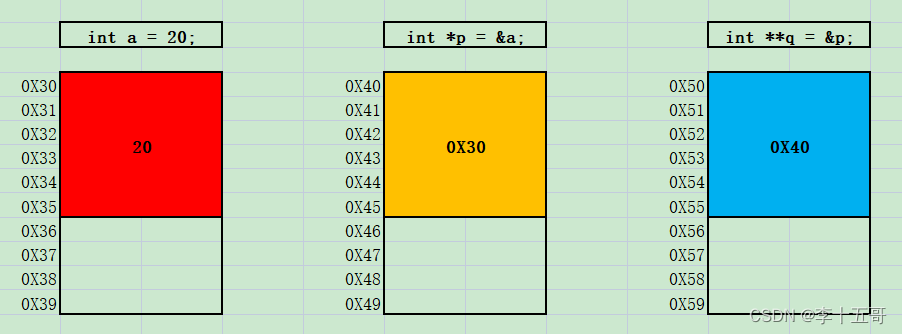
一级指针:内存中每个字节都有一个编号,这个编号就是指针,也称作地址;专门用来存储地址的变量,就是指针变量;定义一级指针变量并初始化: 数据类型 *指针变量名 &普通变量名; 数据类型 *指针…...

【腾讯云 Cloud Studio 实战训练营】使用 Cloud Studio 快速构建 Vue + Vite 完成律师 H5 页面
【腾讯云 Cloud Studio 实战训练营】使用 Cloud Studio 快速构建 Vue Vite 完成律师 H5 页面 前言一、基本介绍1.应用场景2.产品优势 二、准备工作1.注册 Cloud Studio2.进入 Vue 预置开发环境 三、使用 Cloud Studio 快速构建 Vue Vite 完成律师 H5 页面1.安装相关依赖包2.主…...

Vim常用指令
Vim常用指令 Vim是一个强大的文本编辑器,它在命令行界面下工作,拥有丰富的功能和快捷键。本文将介绍一些常用的Vim指令,帮助您更高效地使用Vim编辑器。 基本操作 以下是一些基本的Vim操作指令: i:进入插入模式&…...

24届近3年青岛理工大学自动化考研院校分析
今天给大家带来的是青岛理工大学控制考研分析 满满干货~还不快快点赞收藏 一、青岛理工大学 学校简介 青岛理工大学是一所以工为主,土木建筑、机械制造、环境能源学科特色鲜明,理工经管文法艺等学科协调发展的多科性大学。是国家首批地方…...

进入现代云技术的世界-APIGateway、ServiceMesh、OpenStack、异步化框架、云原生框架、命令式API与声明式API
目录 APIGateway Service Mesh OpenStack 异步化框架 云原生框架 命令式API与声明式API APIGateway API网关(API Gateway)是一个服务器——充当了客户端和内部服务之间的中间层。API网关负责处理API请求,将客户端的请求路由到相应的后端…...

Macbook 终端 git 命令补全和提示
Mac OS自带的终端,用起来虽然有些不太方便,界面也不够友好,关键是在windows上用习惯了自动补全功能,在Mac上一个个的拼写单词是真的难受,逼着我记英文单词。 经过一天的磨合,我实在忍不了,在网上…...
2024考研408-计算机网络 第六章-应用层学习笔记
文章目录 前言一、网络应用模型1.1、认识应用层功能和特点1.2、网络应用层模型:1.2.1、客户/服务器(C/S)模型1.2.2、P2P模型 二、DNS系统2.1、认识DNS与IP地址的关系2.2、DNS解析的大致流程2.3、域名的分类2.4、域名服务器的分类2.5、域名解析…...
使用阿里云服务器部署和使用GitLab
本文阿里云百科分享使用阿里云服务器部署和使用GitLab,GitLab是Ruby开发的自托管的Git项目仓库,可通过Web界面访问公开的或者私人的项目。本教程介绍如何部署和使用GitLab。 目录 准备工作 部署GitLab环境 使用GitLab 登录GitLab 生成密钥对文件并…...
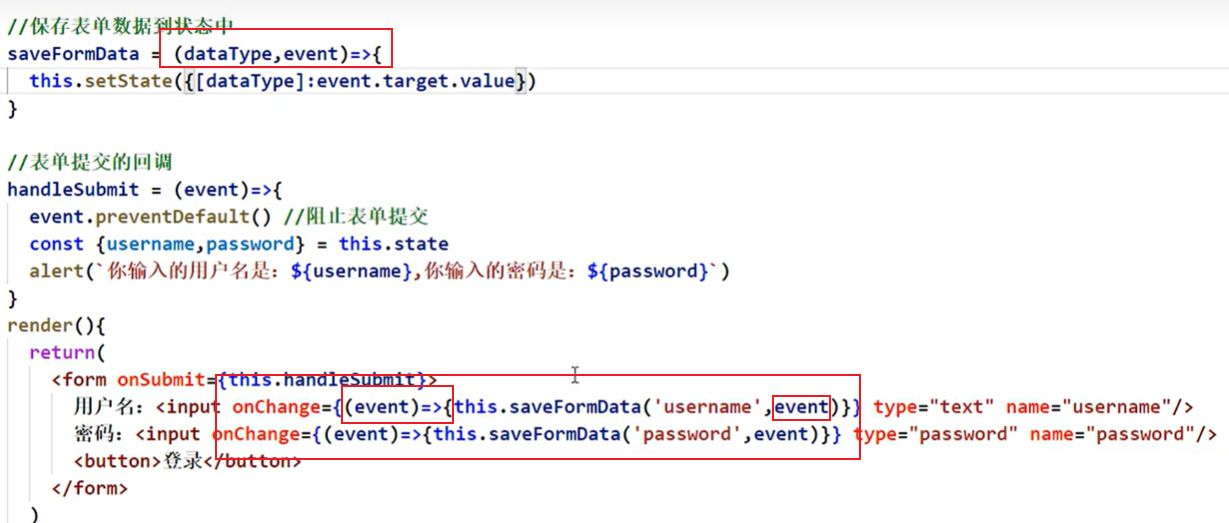
React入门学习笔记3
事件处理 通过onXxx属性指定事件处理函数(注意大小写) React使用的是自定义(合成)事件, 而不是使用的原生DOM事件——为了更好的兼容性 eg:οnclick》onClickReact中的事件是通过事件委托方式处理的(委托给组件最外层的元素)——为了更高效通过event.target得到发生…...
中断运行全景实例)
从零开始理解Linux中断架构(25)中断运行全景实例
前面我们基本理解了软中断处理的基本框架,为了对中断调用有一个全景的直观感受,我们在网卡驱动程序的中断函数dump_stack,观看一下各种情况下的软中断调用call Stack的情况。 (1)ksoftirqd处理软中断的情况 有线以太网卡NAPI轮询的调用栈 [ 106.374117] Hardware name: K…...
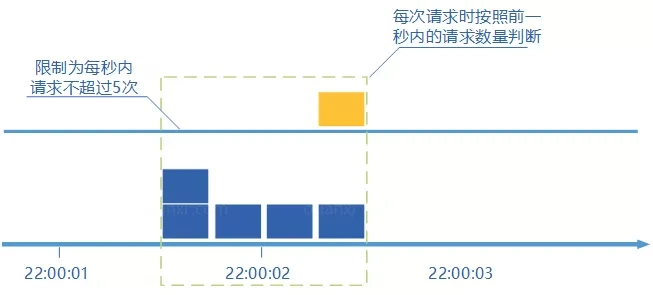
go-zero 是如何实现计数器限流的?
原文链接: 如何实现计数器限流? 上一篇文章 go-zero 是如何做路由管理的? 介绍了路由管理,这篇文章来说说限流,主要介绍计数器限流算法,具体的代码实现,我们还是来分析微服务框架 go-zero 的源…...

【考研复习】24王道数据结构课后习题代码|第3章栈与队列
文章目录 3.1 栈3.2 队列3.3 栈和队列的应用 3.1 栈 int symmetry(linklist L,int n){char s[n/2];lnode *pL->next;int i;for(i0;i<n/2;i){s[i]p->data;pp->next;}i--;if(n%21) pp->next;while(p&&s[i]p->data){i--;pp->next;}if(i-1) return 1;…...

java中excel文件下载
1、System.getProperty(user.dir) 获取的是启动项目的容器位置 2、 Files.copy(sourceFile.toPath(), destinationFile.toPath(), StandardCopyOption.REPLACE_EXISTING); StandardCopyOption.REPLACE_EXISTING 来忽略文件已经存在的异常,如果存在就去覆盖掉它Sta…...

29 | 广州美食店铺数据分析
广州美食店铺数据分析 一、数据分析项目MVP加/价值主张宣言 随着经济的快速发展以及新媒体的兴起,美食攻略、美食探店等一系列东西进入大众的眼球,而人们也会在各大平台中查找美食推荐,因此本项目做的美食店铺数据分析也是带有可行性的。首先通过对广东省的各市美食店铺数量…...

Java开发者快速上手:Phi-4-mini-reasoning本地API调用集成教程
Java开发者快速上手:Phi-4-mini-reasoning本地API调用集成教程 1. 开篇:为什么选择Phi-4-mini-reasoning 如果你是一名Java开发者,最近可能已经注意到AI模型集成正在成为后端开发的新常态。Phi-4-mini-reasoning作为一款轻量级推理模型&…...

别再傻傻用pip了!用Anaconda的conda管理Python环境,效率提升不止一点点
从pip到conda:Python环境管理的效率革命 在Python开发的世界里,环境管理一直是个让人头疼的问题。想象一下这样的场景:你正在开发一个新项目,需要特定版本的NumPy和Pandas,但你的另一个项目却依赖这些库的不同版本。传…...
)
你的AMOS模型总跑不好?可能是这3个‘坑’没避开(附SPSS数据预处理检查清单)
AMOS模型优化实战:避开三大陷阱的完整指南 每次点击"Calculate Estimates"按钮时,心跳加速的感觉是不是很熟悉?屏幕上一连串红色警告和离谱的适配度指标让多少研究者彻夜难眠。AMOS作为结构方程模型(SEM)分析的利器,用好…...


2026产线痛点终结者:Java+YOLOv11+ByteTrack,彻底解决光电计数不准的行业难题
一、前言:被光电传感器支配的工业计数噩梦 2026年的今天,绝大多数工厂的传送带零件计数,依然在靠几十年前的光电传感器硬扛。 上个月我接手了一家汽车零部件厂的计数系统改造项目,他们的情况几乎是整个行业的缩影:用了6年的欧姆龙E3Z光电传感器,只要零件出现重叠、倾斜…...

TypeScript的template literal types实现SQL查询的类型安全
在现代Web开发中,TypeScript因其强大的类型系统而备受青睐。数据库操作中的SQL查询仍然是一个容易出错的领域,尤其是拼接字符串时容易引发SQL注入或字段名错误。TypeScript 4.1引入的template literal types为解决这一问题提供了新思路,它允许…...

为什么传统预警系统仍滞后12分钟?AGI动态权重学习算法,让山洪预警准确率跃升至99.17%——SITS2026核心团队实测数据
第一章:SITS2026专家:AGI与灾害预警 2026奇点智能技术大会(https://ml-summit.org) 在SITS2026大会上,来自全球气候建模中心、神经符号AI实验室及联合国减灾署(UNDRR)的联合研究团队展示了首个具备自主推理能力的灾害…...

一份文档引发的连锁命令执行、从一个文档到全校三要素泄露和RCE
0x01 简介 某 211 高校业务系统的一次完整渗透测试。攻击者从系统公开的操作手册文档中获取关键账号规则,成功登录普通学生账号;随后通过修改角色 ID 实现垂直越权,新建管理员账号并进入后台,进一步构造数据包提权至超级管理员&a…...

3分钟实战指南:高效解决网易云音乐NCM格式播放难题
3分钟实战指南:高效解决网易云音乐NCM格式播放难题 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的NCM加密格式文件无法在其他设备播放而烦恼吗?ncmdump是一款专为解决NCM格式兼容性问…...

从LCD到MicroLED:手把手拆解主流显示技术演进史,看懂未来屏幕长啥样
从LCD到MicroLED:手把手拆解主流显示技术演进史,看懂未来屏幕长啥样 每次点亮手机屏幕时,你有没有想过——这些色彩斑斓的像素点是如何从实验室走向我们掌心的?显示技术的进化就像一场接力赛,每一代技术都在解决前代的…...