PyTorch翻译官网教程-FAST TRANSFORMER INFERENCE WITH BETTER TRANSFORMER
官网链接
Fast Transformer Inference with Better Transformer — PyTorch Tutorials 2.0.1+cu117 documentation
使用 BETTER TRANSFORMER 快速的推理TRANSFORMER
本教程介绍了作为PyTorch 1.12版本的一部分的Better Transformer (BT)。在本教程中,我们将展示如何使用更好的Transformer与torchtext进行生产推理。Better Transformer是一个具备生产条件fastpath并且可以加速在CPU和GPU上具有高性能的Transformer模型的部署。对于直接基于PyTorch核心nn.module或基于torchtext的模型,fastpath功能可以透明地工作。
使用PyTorch核心torch.nn.module类TransformerEncoder, TransformerEncoderLayer和MultiHeadAttention的模型,可以通过Better Transformer fastpath 执行加速。此外,torchtext已经更新为使用核心库模块,以受益于fastpath加速。(将来可能会启用其他模块的fastpath执行。)
Better Transformer提供两种类型的加速:
- 实现CPU和GPU的Native multihead attention(MHA),提高整体执行效率。
- 利用NLP推理中的稀疏性。由于输入长度可变,输入令牌可能包含大量填充令牌,可以跳过处理,从而显著提高速度。
Fastpath执行受制于一些标准。最重要的是,模型必须在推理模式下执行,并且在不收集梯度信息的输入张量上运行(例如,使用torch.no_grad运行)。
本教程中Better Transformer 特点
- 加载预训练模型(1.12之前没有Better Transformer)
- 在CPU上并且没有BT fastpath(仅本机MHA))的情况下 运行和基准测试推断
- 在设备(可配置)上并且没有BT fastpath(仅本机MHA))的情况下 运行和基准测试推断
- 启用稀疏性支持
- 在设备(可配置)上并且没有BT fastpath(仅本机MHA+稀疏性))的情况下 运行和基准测试推断
额外的信息
关于Better Transformer的其他信息可以在PyTorch.Org 博客中找到。A Better Transformer for Fast Transformer Inference.
设置
加载预训练模型
我们按照torchtext.models中的说明从预定义的torchtext模型下载XLM-R模型。我们还将DEVICE设置为执行加速器上的测试。(根据您的环境适当启用GPU执行。)
import torch
import torch.nn as nnprint(f"torch version: {torch.__version__}")DEVICE = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")print(f"torch cuda available: {torch.cuda.is_available()}")import torch, torchtext
from torchtext.models import RobertaClassificationHead
from torchtext.functional import to_tensor
xlmr_large = torchtext.models.XLMR_LARGE_ENCODER
classifier_head = torchtext.models.RobertaClassificationHead(num_classes=2, input_dim = 1024)
model = xlmr_large.get_model(head=classifier_head)
transform = xlmr_large.transform()数据集搭建
我们设置了两种类型的输入:一个小的输入批次和一个具有稀疏性的大的输入批次。
small_input_batch = ["Hello world","How are you!"
]
big_input_batch = ["Hello world","How are you!","""`Well, Prince, so Genoa and Lucca are now just family estates of the
Buonapartes. But I warn you, if you don't tell me that this means war,
if you still try to defend the infamies and horrors perpetrated by
that Antichrist- I really believe he is Antichrist- I will have
nothing more to do with you and you are no longer my friend, no longer
my 'faithful slave,' as you call yourself! But how do you do? I see
I have frightened you- sit down and tell me all the news.`It was in July, 1805, and the speaker was the well-known Anna
Pavlovna Scherer, maid of honor and favorite of the Empress Marya
Fedorovna. With these words she greeted Prince Vasili Kuragin, a man
of high rank and importance, who was the first to arrive at her
reception. Anna Pavlovna had had a cough for some days. She was, as
she said, suffering from la grippe; grippe being then a new word in
St. Petersburg, used only by the elite."""
]接下来,我们选择小批量或大批量输入,对输入进行预处理并测试模型。
input_batch=big_input_batchmodel_input = to_tensor(transform(input_batch), padding_value=1)
output = model(model_input)
output.shape最后,我们设置基准迭代计数:
ITERATIONS=10执行
在CPU上并且没有BT fastpath(仅本机MHA)的情况下 运行和基准测试推断
我们在CPU上运行模型,并收集概要信息:
- 第一次运行使用传统方式(“slow path”)执行。
- 第二次运行通过使用model.eval()将模型置于推理模式来启用BT fastpath执行,并使用torch.no_grad()禁用梯度收集。
当模型在CPU上执行时,您可以看到改进(其大小取决于CPU模型)。注意,fastpath配置文件显示了本机TransformerEncoderLayer实现aten::_transformer_encoder_layer_fwd.中的大部分执行时间。
print("slow path:")
print("==========")
with torch.autograd.profiler.profile(use_cuda=False) as prof:for i in range(ITERATIONS):output = model(model_input)
print(prof)model.eval()print("fast path:")
print("==========")
with torch.autograd.profiler.profile(use_cuda=False) as prof:with torch.no_grad():for i in range(ITERATIONS):output = model(model_input)
print(prof)
在设备(可配置)上并且没有BT fastpath(仅本机MHA))的情况下 运行和基准测试推断
我们检查BT 稀疏性设置:
model.encoder.transformer.layers.enable_nested_tensor我们禁用BT 稀疏性:
model.encoder.transformer.layers.enable_nested_tensor=False
我们在DEVICE上运行模型,并收集DEVICE上本机MHA执行的配置文件信息:
- 第一次运行使用传统方式(“slow path”)执行。
- 第二次运行通过使用model.eval()将模型置于推理模式来启用BT fastpath执行,并使用torch.no_grad()禁用梯度收集。
当在GPU上执行时,你应该看到一个显著的加速,特别是对于包含稀疏性的大输入批处理设置:
model.to(DEVICE)
model_input = model_input.to(DEVICE)print("slow path:")
print("==========")
with torch.autograd.profiler.profile(use_cuda=True) as prof:for i in range(ITERATIONS):output = model(model_input)
print(prof)model.eval()print("fast path:")
print("==========")
with torch.autograd.profiler.profile(use_cuda=True) as prof:with torch.no_grad():for i in range(ITERATIONS):output = model(model_input)
print(prof)总结
在本教程中,我们介绍了使用 Better Transformer fastpath快速的transformer 推理,在torchtext 中使用PyTorch核心的 Better Transformer包支持Transformer Encoder 模型。在确认BT fastpath可用性的前提下,我们已经演示了 Better Transformer 的使用。我们已经演示并测试了BT fastpath 执行模式·、本机MHA执行和BT稀疏性加速的使用。
相关文章:
PyTorch翻译官网教程-FAST TRANSFORMER INFERENCE WITH BETTER TRANSFORMER
官网链接 Fast Transformer Inference with Better Transformer — PyTorch Tutorials 2.0.1cu117 documentation 使用 BETTER TRANSFORMER 快速的推理TRANSFORMER 本教程介绍了作为PyTorch 1.12版本的一部分的Better Transformer (BT)。在本教程中,我们将展示如…...
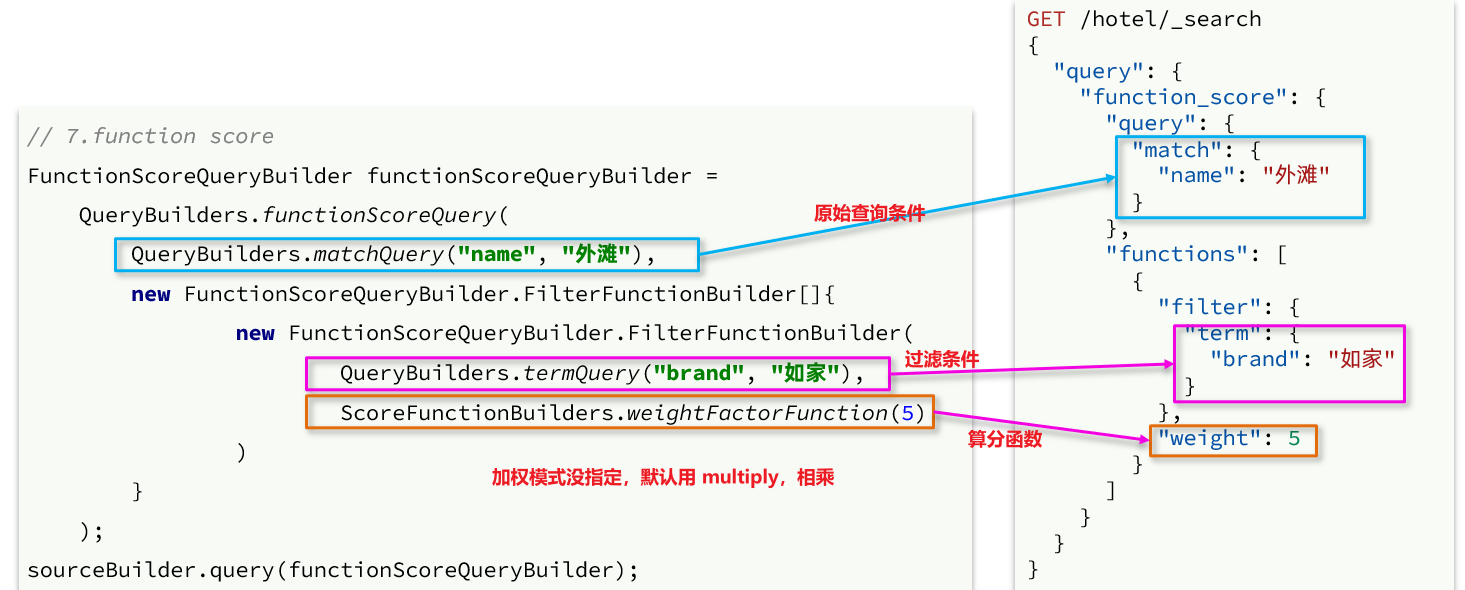
SpringCloud实用篇6——elasticsearch搜索功能
目录 1 DSL查询文档1.1 DSL查询分类1.2 全文检索查询1.2.1 使用场景1.2.2 基本语法1.2.3 示例1.2.4 总结 1.3 精准查询1.3.1 term查询1.3.2 range查询1.3.3 总结 1.4.地理坐标查询1.4.1 矩形范围查询1.4.2 附近查询 1.5 复合查询1.5.1 相关性算分1.5.2 算分函数查询1࿰…...

质量小议29 -- 循证
1. 循证 Evidence-Based遵循证据基于证据慎重、准确和明智地应用当前所能获得的最好研究依据利用证据追求实践科学化和专业化的价值观,重视证据指导实践的理念,运用证据解决实践中问题的思维,基于证据开展专业实践活动的指导原则,…...

微服务与Nacos概述-3
流量治理 在微服务架构中将业务拆分成一个个的服务,服务与服务之间可以相互调用,但是由于网络原因或者自身的原因,服务并不能保证服务的100%可用,如果单个服务出现问题,调用这个服务就会出现网络延迟,此时…...

Java 面试八股文
参考: 2023年 Java 面试八股文(20w字)_json解析失败_leader_song的博客-CSDN博客...

NPM与外部服务的集成(上)
目录 1、关于访问令牌 1.1 关于传统令牌 1.2 关于粒度访问令牌 2、创建和查看访问令牌 2.1 创建访问令牌 在网站上创建传统令牌 在网站上创建粒度访问令牌 使用CLI创建令牌 CIDR限制令牌错误 查看访问令牌 在网站上查看令牌 在CLI上查看令牌 令牌属性 1、关于访问令…...

React Router 6
1.概述 React Router 以三个不同的包发布到 npm 上,它们分别为: react-router: 路由的核心库,提供了很多的:组件、钩子。 react-router-dom: 包含react-router所有内容,并添加一些专门用于 DOM 的组件,例如…...
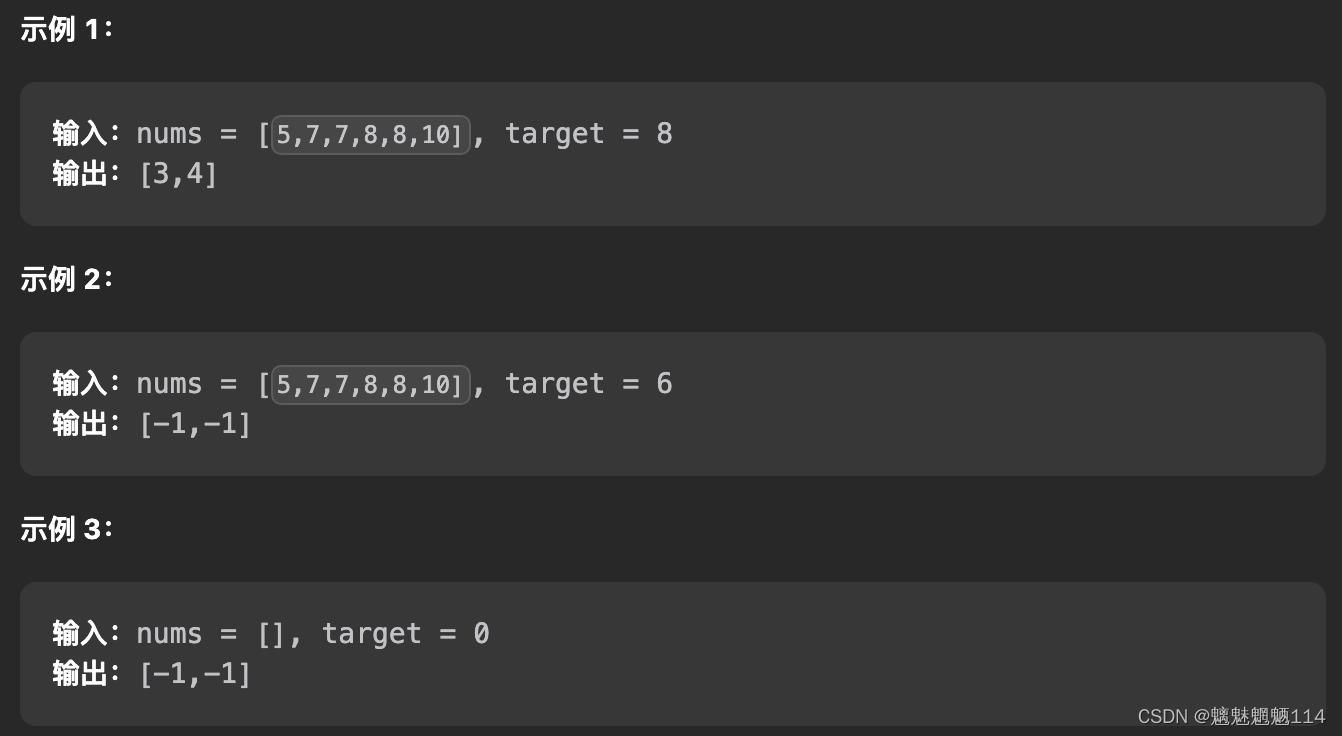
Leetcode34 在排序数组中查找元素的第一个和最后一个位置
给你一个按照非递减顺序排列的整数数组 nums,和一个目标值 target。请你找出给定目标值在数组中的开始位置和结束位置。 如果数组中不存在目标值 target,返回 [-1, -1]。 你必须设计并实现时间复杂度为 O(log n) 的算法解决此问题。 代码: c…...
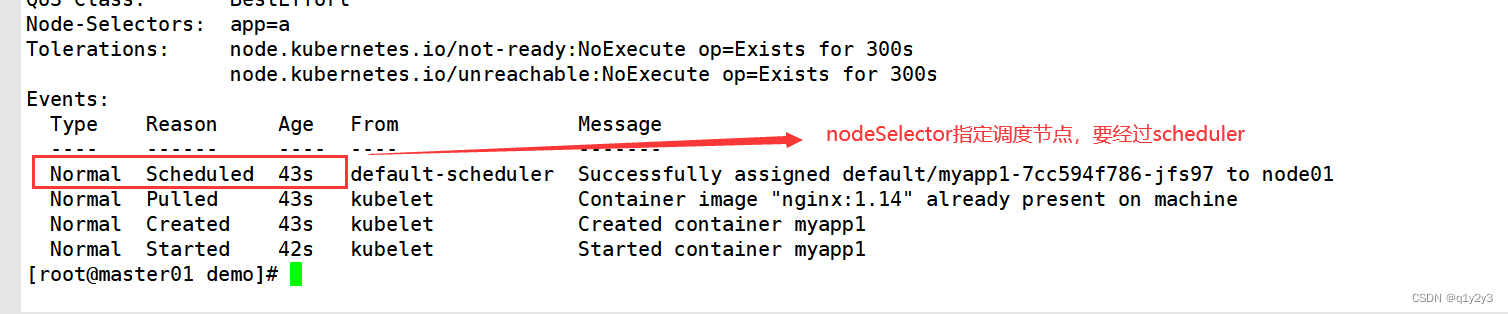
Kubernetes 调度约束(亲和性、污点、容忍)
目录 一、Pod启动典型创建过程 二、调度流程 三、指定调度节点 1.使用nodeName字段指定调度节点 2.使用nodeSelector指定调度节点 2.1给对应的node节点添加标签 2.2修改为nodeSelector调度方式 3.通过亲和性来指定调度节点 3.1节点亲和性 3.2Pod亲和性与反亲和性 3.2…...
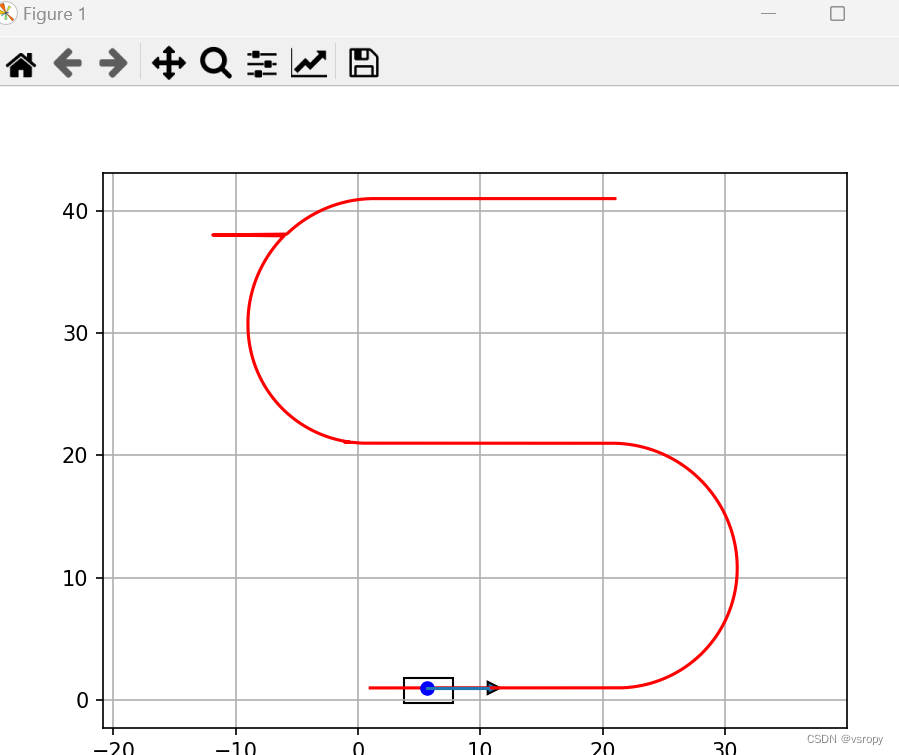
按轨迹运行
文章目录 import math import timeimport numpy as np import matplotlib.pyplot as pltdef plot_arrow(x, y, yaw, length=5, width=1):dx = length * math.cos(yaw)dy = length * math.sin(yaw)plt.arrow(x, y, dx, dy, head_length=width, head_width=width)plt.plot([x, x …...
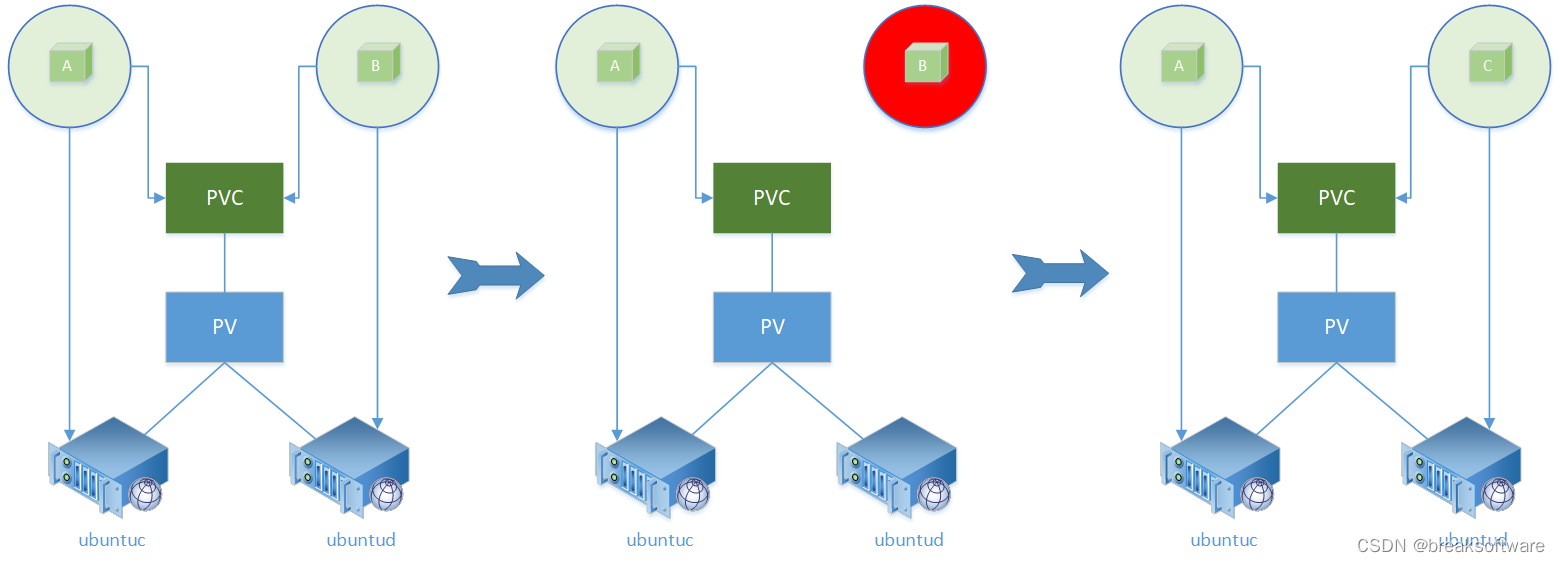
研发工程师玩转Kubernetes——通过PV的节点亲和性影响Pod部署
在《研发工程师玩转Kubernetes——PVC通过storageClassName进行延迟绑定》一文中,我们利用Node亲和性,让Pod部署在节点ubuntud上。因为Pod使用的PVC可以部署在节点ubuntuc或者ubuntud上,而系统为了让Pod可以部署成功,则让PVC与Pod…...
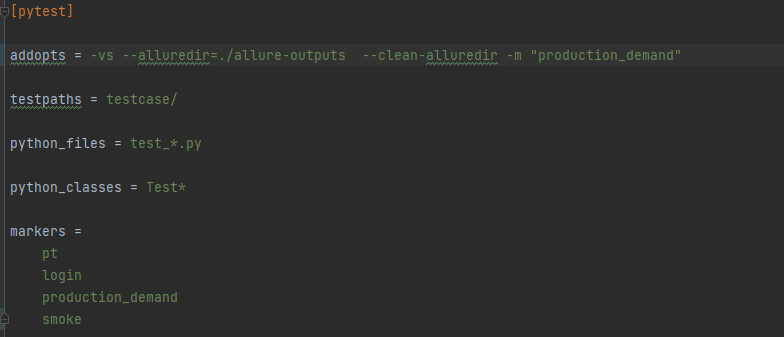
Pytest三种运行方式
Pytest 运行方式共有三种: 1、主函数模式 运行所有 pytest.main() 指定模块 pytest.main([-vs],,./testcase/test_day1.py) 只运行testcase 下的test_day1.py 文件 指定目录 pytest.main([-vs]),./testcase) 只运行testcase 目录下的文件 通过nodeid指定用例…...
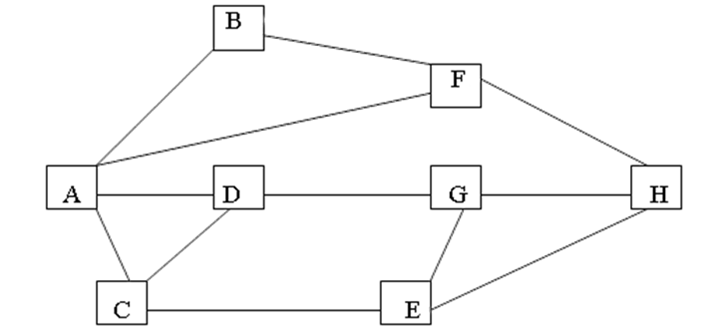
城市最短路
题目描述 下图表示的是从城市A到城市H的交通图。从图中可以看出,从城市A到城市H要经过若干个城市。现要找出一条经过城市最少的一条路线。 输入输出格式 输入格式: 无 输出格式: 倒序输出经过城市最少的一条路线 输入输出样例 输入样例…...
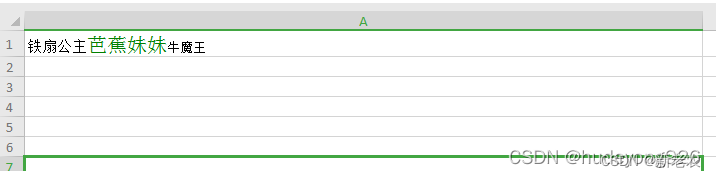
phpspreadsheet excel导入导出
单个sheet页Excel2003版最大行数是65536行。Excel2007开始的版本最大行数是1048576行。Excel2003的最大列数是256列,2007以上版本是16384列。 xlswriter xlswriter - PHP 高性能 Excel 扩展,功能类似phpspreadsheet。它能够处理非常大的文件࿰…...

自动驾驶传感器选型
360的场景,避免有盲区,长距离 Lidar(激光雷达) 典型特点一圈一圈的,轮廓和很高的位置精度 禾赛的机械雷达 速腾的固态雷达 固态雷达是车规级的,车规级的意思是可以装到量产车上 Radar(毫米…...
)
4.利用matlab符号矩阵的四则运算(matlab程序)
1.简述 符号对象的建立 sym函数 sym函数用于建立单个符号对象,其常用调用格式为: 符号对象名sym(A) 1 将由A来建立符号对象,其中,A可以是一个数值常量、数值矩阵或数值表达式(不加单引号),此时符号对象为一个符号常量;…...
Go context.WithCancel()的使用
WithCancel可以将一个Context包装为cancelCtx,并提供一个取消函数,调用这个取消函数,可以Cancel对应的Context Go语言context包-cancelCtx 疑问 context.WithCancel()取消机制的理解 父母5s钟后出门,倒计时,父母在时要学习,父母一走就可以玩 …...

STM32 F103C8T6学习笔记6:IIC通信__驱动MPU6050 6轴运动处理组件—一阶互补滤波
今日主要学习一款倾角传感器——MPU6050,往后对单片机原理基础讲的会比较少,更倾向于简单粗暴地贴代码,因为经过前些日子对MSP432的学习,对原理方面也有些熟络了,除了在新接触它时会对其引脚、时钟、总线等进行仔细一些的研究之外…...

Ubantu安装Docker(完整详细)
先在官网上查看对应的版本:官网 然后根据官方文档一步一步跟着操作即可 必要准备 要成功安装Docker Desktop,必须: 满足系统要求 拥有64位版本的Ubuntu Jammy Jellyfish 22.04(LTS)或Ubuntu Impish Indri 21.10。 Docker Deskto…...

【从零开始学习JAVA | 第四十一篇】深入JAVA锁机制
目录 前言: 引入: 锁机制: CAS算法: 乐观锁与悲观锁: 总结: 前言: 在多线程编程中,线程之间的协作和资源共享是一个重要的话题。当多个线程同时操作共享数…...

Dual Thrust策略在A股和商品期货上的表现差异有多大?一个参数对比实验
Dual Thrust策略在A股与商品期货中的参数优化实战 第一次接触Dual Thrust策略时,我被它简洁优雅的设计所吸引——仅用开盘价和价格波动区间就能构建完整的交易信号系统。但真正将其应用到实盘时,却发现同样的参数设置在不同市场表现天差地别。本文将分享…...

题解:洛谷 AT_abc389_d [ABC389D] Squares in Circle
本文分享的必刷题目是从蓝桥云课、洛谷、AcWing等知名刷题平台精心挑选而来,并结合各平台提供的算法标签和难度等级进行了系统分类。题目涵盖了从基础到进阶的多种算法和数据结构,旨在为不同阶段的编程学习者提供一条清晰、平稳的学习提升路径。 欢迎大家订阅我的专栏:算法…...

终极指南:如何安全处理跨源链接的noopener最佳实践
终极指南:如何安全处理跨源链接的noopener最佳实践 【免费下载链接】developer.chrome.com The frontend, backend, and content source code for developer.chrome.com 项目地址: https://gitcode.com/gh_mirrors/de/developer.chrome.com 在Web开发中&…...

SketchUp STL插件技术解析:3D打印工作流效率提升85%的架构设计与实现方案
SketchUp STL插件技术解析:3D打印工作流效率提升85%的架构设计与实现方案 【免费下载链接】sketchup-stl A SketchUp Ruby Extension that adds STL (STereoLithography) file format import and export. 项目地址: https://gitcode.com/gh_mirrors/sk/sketchup-s…...

mysql如何优化索引以减少扫描_mysql高效索引设计原则
MySQL索引失效主因是最左前缀原则被破坏:范围查询或跳过中间列会导致右侧列无法使用索引;ORDER BY需满足最左连续列且排序方向一致;索引过多拖慢写入,应评估选择性与实际使用率;EXPLAIN中key_len和Extra比type更能反映…...

内容即世界,世界即产品:HappyOyster。即将开启创作者经济新范式
4月16日,阿里 ATH 创新事业部的 HappyOyster 正式开放内测[1]。这不是一款普通的产品升级——它把"建造一个世界"这件事,第一次放进了普通创作者的能力范围[2] [3]。一个根本性的问题随之浮现:如果每一个创作者都能建造自己的世界&…...

别再死记模块了!一张图看懂AUTOSAR CAN信号流:普通、诊断、XCP、NM报文到底怎么走?
AUTOSAR CAN信号流全景解析:从报文属性到配置落地的完整逻辑链 在汽车电子开发领域,AUTOSAR架构下的CAN通信配置一直是工程师们面临的难点之一。许多开发者虽然熟悉各个独立模块的功能,但当面对实际项目配置时,却常常陷入"只…...

深入NRF52832 ESB协议栈:从状态机到PPI,剖析与NRF24L01通信的底层时序与避坑指南
深入NRF52832 ESB协议栈:从状态机到PPI的通信稳定性实战指南 1. 无线通信系统的核心挑战 在物联网和智能硬件领域,2.4GHz无线通信已成为设备互联的基础技术。NRF52832作为Nordic Semiconductor的旗舰级蓝牙低功耗SoC,其内置的Enhanced ShockB…...

别再瞎调了!NRF52832蓝牙发射功率实战指南:从-40dBm到+4dBm,手把手教你平衡距离与功耗
NRF52832蓝牙发射功率调优实战:从理论到场景化配置的艺术 在物联网设备开发中,蓝牙低功耗(BLE)技术的应用越来越广泛,而NRF52832作为Nordic Semiconductor的明星芯片,其灵活的发射功率调节功能常常被开发者忽视或误用。很多工程师…...
)
FPGA--Verilog 实现乒乓操作:从原理到工程实践(附完整代码)
1. 什么是乒乓操作? 乒乓操作是FPGA设计中一种经典的数据缓冲技术,它的核心思想就像打乒乓球一样,两个存储单元轮流接收和输出数据。想象一下有两个水桶,当一个水桶在接水时,另一个水桶在倒水,如此反复交替…...