MySQL 窗口函数是什么,有这么好用
先看这段像天书一样的 SQL ,看着就头疼。
SELECTs1.name,s1.subject,s1.score,sub.avg_score AS average_score_per_subject,(SELECT COUNT(DISTINCT s2.score) + 1 FROM scores s2 WHERE s2.score > s1.score) AS score_rank
FROM scores s1
JOIN (SELECT subject, AVG(score) AS avg_scoreFROM scoresGROUP BY subject
) sub ON s1.subject = sub.subject
ORDER BY s1.score DESC;
这段SQL是干什么用的呢,就是为了计算一个成绩排名,简直大动干戈啊。
那有没有简化的方法呢?有的。
简化后的版本就是利用今天说的窗口函数。
SELECTname,subject,score,AVG(score) OVER (PARTITION BY subject) AS average_score_per_subject,RANK() OVER (ORDER BY score DESC) AS score_rank
FROM scores
ORDER BY score DESC;
是不是看上去就简洁清晰多了。
下面我们看看是什么样的功能。
首先创建一个表,包含姓名、学科、分数三个字段,用于后面功能的演示。
CREATE TABLE `scores` (`name` varchar(20) COLLATE utf8_bin NOT NULL,`subject` varchar(20) COLLATE utf8_bin NOT NULL,`score` int(3) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
然后向表中插入一些随机记录。
INSERT INTO scores (name, subject, score) VALUES ('Student1', '化学', 75);
INSERT INTO scores (name, subject, score) VALUES ('Student2', '生物', 92);
INSERT INTO scores (name, subject, score) VALUES ('Student3', '物理', 87);
INSERT INTO scores (name, subject, score) VALUES ('Student4', '数学', 68);
INSERT INTO scores (name, subject, score) VALUES ('Student5', '英语', 91);
INSERT INTO scores (name, subject, score) VALUES ('Student6', '化学', 58);
INSERT INTO scores (name, subject, score) VALUES ('Student7', '物理', 79);
INSERT INTO scores (name, subject, score) VALUES ('Student8', '数学', 90);
INSERT INTO scores (name, subject, score) VALUES ('Student9', '数学', 45);
##什么是窗口函数
在 MySQL 8.x 版本中,MySQL 提供了窗口函数,窗口函数是一种在查询结果的特定窗口范围内进行计算的函数。
很早以前用 Oracle 和 MS SQL 的时候会用到里面的窗口函数,但是用 MySQL 后才发现,MySQL 竟然没有窗口函数,以至于一些负责的统计查询都要用各种子查询、join,层层嵌套,看上去很简单的需求,结果搞得 SQL 语句写的是龙飞凤舞,别人一看跟天书似的。就一个字儿,懵。
窗口函数主要的应用场景是统计和计算,例如对查询结果进行分组、排序和计算聚合,通过各个函数的组合,可以实现各种复杂的逻辑,而且比起 MySQL 8.0之前用子查询、join 的方式,性能上要好得多。
OVER()
OVER() 是用于定义窗口函数的子句,它必须结合其他的函数才有意义,比如求和、求平均数。而它只用于指定要计算的数据范围和排序方式。
function_name(...) OVER ([PARTITION BY expr_list] [ORDER BY expr_list] [range]
)
PARTITION BY
用于指定分区字段,对不同分区进行分析计算,分区其实就列,可以指定一个列,也可以指定多个列。
ORDER BY
用于对分区内记录进行排序,排序后可以与「范围和滚动窗口」一起使用。
范围和滚动窗口
用于指定分析函数的窗口,包括范围和滚动窗口。
范围窗口(Range window)
指定窗口的起止行号,使用UNBOUNDED PRECEDING表示起点,UNBOUNDED FOLLOWING表示终点。
例如:
SUM(salary) OVER (ORDER BY id RANGE BETWEEN 5 PRECEDING AND 5 FOLLOWING)
这会计算当前行及之前5行和之后5行的salary总和。
滚动窗口(Row window)
使用了基于当前行的滚动窗口
例如:
SUM(salary) OVER (ORDER BY id ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING)
这会计算当前行及之前2行和之后2行的salary总和。
OVER()可搭配的函数:
聚合函数
MAX(),MIN(),COUNT(),SUM()等,用于生成每个分区的聚合结果。
排序相关
ROW_NUMBER(),RANK(),DENSE_RANK()等,用于生成每个分区的行号或排名。
窗口函数
LAG(),LEAD(),FIRST_VALUE(),LAST_VALUE()等,用于基于窗口框生成结果。
搭配聚合函数
1、按subject列进行分区,并求出某学科的最大最小值
获取分数和此学科最高分
SELECT subject,score, MAX(score) OVER (PARTITION BY subject) as `此学科最高分` FROM scores;
得出的结果是:
| subject | score | 此学科最高分 |
|---|---|---|
| 化学 | 75 | 75 |
| 化学 | 58 | 75 |
| 数学 | 68 | 90 |
| 数学 | 90 | 90 |
| 数学 | 45 | 90 |
| 物理 | 87 | 87 |
| 物理 | 79 | 87 |
| 生物 | 92 | 92 |
| 英语 | 91 | 91 |
2、获取学科的报名人数
SELECT subject,score, count(name) OVER (PARTITION BY subject) as `报名此学科人数` FROM scores;
得到的结果为:
| subject | score | 报名此学科人数 |
|---|---|---|
| 化学 | 75 | 2 |
| 化学 | 58 | 2 |
| 数学 | 68 | 3 |
| 数学 | 90 | 3 |
| 数学 | 45 | 3 |
| 物理 | 87 | 2 |
| 物理 | 79 | 2 |
| 生物 | 92 | 1 |
| 英语 | 91 | 1 |
3、求学科的总分
SELECT subject, SUM(score) OVER (PARTITION BY subject) as `此学科总分` FROM scores;
得到的结果:
| subject | 此学科总分 |
|---|---|
| 化学 | 133 |
| 化学 | 133 |
| 数学 | 203 |
| 数学 | 203 |
| 数学 | 203 |
| 物理 | 166 |
| 物理 | 166 |
| 生物 | 92 |
| 英语 | 91 |
4、使用 order by 求累加分数
SELECT name,subject,score, SUM(score) OVER (order BY score) as `累加分数` FROM scores;
得到的结果:
| name | subject | score | 累加分数 |
|---|---|---|---|
| Student9 | 数学 | 45 | 45 |
| Student6 | 化学 | 58 | 103 |
| Student4 | 数学 | 68 | 171 |
我们看这是怎么算出来的,OVER 函数里面是 order by 。
首先根据分数排序(默认升序),得到第一行分数是45,所以累加分数就是它自己,也就是45。
然后排序得到第二行 58,然后将第一行和第二行相加,这样得到累加分数就是45+58=103。
同理,第三行就是前三行的总和,也就是45+58+68=171。
以此类推,第 N 行就是1~N的累加和。
5、使用 order by + 范围
前面因为没有限定范围,所以就是前 N 行的累加,还可以限定范围。
SELECT name,subject,score, SUM(score) OVER (order BY `score` ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) as `累加分数` FROM scores;
这里的累加分数是指当前行+前一行+后一行的和。
获取的结果为:
| name | subject | score | 累加分数 |
|---|---|---|---|
| Student9 | 数学 | 45 | 103 |
| Student6 | 化学 | 58 | 171 |
| Student4 | 数学 | 68 | 201 |
| Student1 | 化学 | 75 | 222 |
| Student7 | 物理 | 79 | 241 |
| Student3 | 物理 | 87 | 256 |
| Student8 | 数学 | 90 | 268 |
| Student5 | 英语 | 91 | 273 |
第一行 103,是当前行 45+后一行(58)的和,等于103,因为没有前一行。
第二行171,是当前行58+前一行(45)+后一行(68)的和,等于171。
以此类型,后面的累加分数都是这样算出来的。
搭配排序相关函数
ROW_NUMBER()
ROW_NUMBER() 函数用于为结果集中的每一行分配一个唯一的排序。
如下,对成绩进行排名,分数高的排在前面,如果有两个人分数相同,那仍然是一个第一,另一个第二。
SELECT name,subject,score, ROW_NUMBER() OVER (order BY `score` desc) as `排名` FROM scores;
查询结果为:
| name | subject | score | 排名 |
|---|---|---|---|
| Student2 | 生物 | 92 | 1 |
| Student5 | 英语 | 91 | 2 |
| Student8 | 数学 | 90 | 3 |
| Student3 | 物理 | 87 | 4 |
| Student7 | 物理 | 79 | 5 |
如果不用 ROW_NUMBER(),比如在 MySQL 5.7的版本中,就会像下面这样:
SELECT s1.name, s1.subject, s1.score, COUNT(s2.score) + 1 AS `排名`
FROM scores s1
LEFT JOIN scores s2 ON s1.score < s2.score
GROUP BY s1.name, s1.subject, s1.score
ORDER BY s1.score DESC;
是不是比使用 ROW_NUMBER()复杂的多。
RANK()
RANK() 函数用于为结果集中的每一行分配一个排名值,它也是排名的,但是它和 ROW_NUMBER()有,RANK()函数在遇到相同值的行会将排名设置为相同的,就像是并列排名。
就像是奥运比赛,如果有两个人都是相同的高分,那可能就是并列金牌,但是这时候就没有银牌了,仅次于这两个人的排名就会变成铜牌。
SELECT name,subject,score, RANK() OVER (order BY `score` desc) as `排名` FROM scores;
查询结果为:
| name | subject | score | 排名 |
|---|---|---|---|
| Student1 | 化学 | 92 | 1 |
| Student2 | 生物 | 92 | 1 |
| Student5 | 英语 | 91 | 3 |
| Student8 | 数学 | 90 | 4 |
| Student3 | 物理 | 87 | 5 |
DENSE_RANK()
DENSE_RANK() 也是用作排名的,和 RANK()函数的差别就是遇到相同值的时候,不会跳过排名,比如两个人是并列金牌,排名都是1,那仅次于这两个人的排名就是2,而不像 RANK()那样是3。
SELECT name,subject,score, DENSE_RANK() OVER (order BY `score` desc) as `排名` FROM scores;
查询结果为:
| name | subject | score | 排名 |
|---|---|---|---|
| Student1 | 化学 | 92 | 1 |
| Student2 | 生物 | 92 | 1 |
| Student5 | 英语 | 91 | 2 |
| Student8 | 数学 | 90 | 3 |
配合其他窗口函数
NTILE()
NTILE() 函数用于将结果集划分为指定数量的组,并为每个组分配一个编号。例如,将分数倒序排序并分成4个组,相当于有了4个梯队。
SELECT name,subject,score, NTILE(4) OVER (order BY `score` desc) as `组` FROM scores;
查询结果为:
| name | subject | score | 组 |
|---|---|---|---|
| Student1 | 化学 | 92 | 1 |
| Student2 | 生物 | 92 | 1 |
| Student5 | 英语 | 91 | 1 |
| Student8 | 数学 | 90 | 2 |
| Student3 | 物理 | 87 | 2 |
| Student7 | 物理 | 79 | 3 |
| Student4 | 数学 | 68 | 3 |
| Student6 | 化学 | 58 | 4 |
| Student9 | 数学 | 45 | 4 |
LAG()
LAG() 函数用于在查询结果中访问当前行之前的行的数据。它允许您检索前一行的值,并将其与当前行的值进行比较或计算差异。LAG()函数对于处理时间序列数据或比较相邻行的值非常有用。
LAG()函数完整的表达式为 LAG(column, offset, default_value),包含三个参数:
column:就是列名,获取哪个列的值就是哪个列名,很好理解。
offset: 就是向前的偏移量,取当前行的前一行就是1,前前两行就是2。
default_value:是可选值,如果向前偏移的行不存在,就取这个默认值。
例如比较相邻两个排名的分数差,可以这样写:
SELECTname,subject,score,ABS(score - LAG(score, 1,score) OVER (ORDER BY score DESC)) AS `分值差`
FROMscores;
得到的结果为:
| name | subject | score | 分值差 |
|---|---|---|---|
| Student1 | 化学 | 92 | 0 |
| Student2 | 生物 | 92 | 0 |
| Student5 | 英语 | 91 | 1 |
| Student8 | 数学 | 90 | 1 |
| Student3 | 物理 | 87 | 3 |
| Student7 | 物理 | 79 | 8 |
| Student4 | 数学 | 68 | 11 |
LEAD()
LEAD() 函数和 LAG()的功能一致,只不过它的偏移量是向后偏移,也就是取当前行的后 N 行。
所以前面的比较相邻两行差值的逻辑,也可以向后比较。
SELECTname,subject,score,score - LEAD(score, 1,score) OVER (ORDER BY score DESC) AS `分值差`
FROMscores;
得到的结果:
| name | subject | score | 分值差 |
|---|---|---|---|
| Student1 | 化学 | 92 | 0 |
| Student2 | 生物 | 92 | 1 |
| Student5 | 英语 | 91 | 1 |
| Student8 | 数学 | 90 | 3 |
| Student3 | 物理 | 87 | 8 |
| Student7 | 物理 | 79 | 11 |
| Student4 | 数学 | 68 | 10 |
相关文章:

MySQL 窗口函数是什么,有这么好用
先看这段像天书一样的 SQL ,看着就头疼。 SELECTs1.name,s1.subject,s1.score,sub.avg_score AS average_score_per_subject,(SELECT COUNT(DISTINCT s2.score) 1 FROM scores s2 WHERE s2.score > s1.score) AS score_rank FROM scores s1 JOIN (SELECT subject, AVG(sco…...
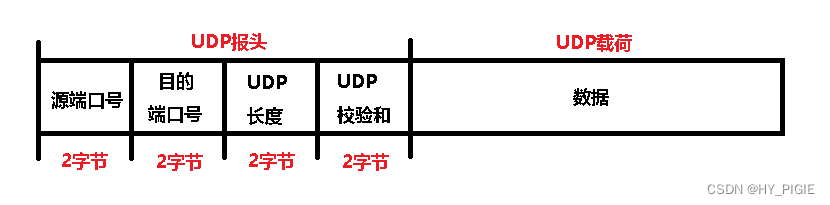
用户数据报协议UDP
UDP的格式 载荷存放的是:应用层完整的UDP数据报 报头结构: 源端口号:发出的信息的来源端口目的端口号:信息要到达的目的端口UDP长度:2个字节(16位),即UDP总长度为:2^16bit 2^10bit * 2^6bit 1KB * 64 64KB.所以一个UDP的最大长度为64KBUDP校验和:网络的传输并非稳定传输,…...

STM32F429IGT6使用CubeMX配置外部中断按键
1、硬件电路 2、设置RCC,选择高速外部时钟HSE,时钟设置为180MHz 3、配置GPIO引脚 4、NVIC配置 PC13相同 5、生成工程配置 6、部分代码 中断回调函数 /* USER CODE BEGIN 0 */void HAL_GPIO_EXTI_Callback(uint16_t GPIO_Pin) {if(GPIO_Pin GPIO_PIN_0){HAL_GPIO…...
时序预测 | Python实现LSTM长短期记忆网络时间序列预测(电力负荷预测)
时序预测 | Python实现LSTM长短期记忆网络时间序列预测(电力负荷预测) 目录 时序预测 | Python实现LSTM长短期记忆网络时间序列预测(电力负荷预测)效果一览基本描述模型结构程序设计参考资料效果一览...

[开发|前端] 路由守卫笔记
描述 vue-router提供的导航跳转或取消的api。 router.beforeEach 切换路由前调用 router.beforeResolve 组件内路由守卫解析之后调用,和beforeEach用法类似 router.afterEach 切换后调用 全局路由守卫有上面3个,调用时机不同 路由守卫都有3个参数 …...

网络基础——网络的由来与发展史
作者:Insist-- 个人主页:insist--个人主页 作者会持续更新网络知识和python基础知识,期待你的关注 目录 一、网络的由来 二、计算机网络的发展史 1、第一阶段 2、第二阶段 3、第三阶段 前言 每天都是使用网络,那么你知道网络…...
)
八数码(bfs)
思路: (1)用string来存储状态,用d<string,int>来记录状态变换次数; (2)在bfs过程中,先初始化(q,d);每次拿出队头状态,得到x的相对位置&am…...

CCLINK IE FIELD BASIC转MODBUS-TCP网关cclink与以太网的区别
协议的不同,数据读取困难,这是很多生产管理系统的难题。但是现在,捷米JM-CCLKIE-TCP通讯网关,让这个问题变得非常简单。这款通讯网关可以将各种MODBUS-TCP设备接入到CCLINK IE FIELD BASIC网络中,连接到MODBUS-TCP总线…...
【Rust】Rust学习 第十一章编写自动化测试
Rust 是一个相当注重正确性的编程语言,不过正确性是一个难以证明的复杂主题。Rust 的类型系统在此问题上下了很大的功夫,不过它不可能捕获所有种类的错误。为此,Rust 也在语言本身包含了编写软件测试的支持。 编写一个叫做 add_two 的将传递…...

关于使用pycharm遇到只能使用unittest方式运行,无法直接选择Run
相信大家可能都遇到过这个问题,使用pycharm直接运行脚本的时候,只能选择unittest的方式,能愁死个人 经过几次各种尝试无果之后,博主就放弃死磕了,原谅博主是个菜鸟 后来遇到这样的问题,往往也就直接使用cm…...
Docker+rancher部署SkyWalking8.5并应用在springboot服务中
1.Skywalking介绍 Skywalking是一个国产的开源框架,2015年有吴晟个人开源,2017年加入Apache孵化器,国人开源的产品,主要开发人员来自于华为,2019年4月17日Apache董事会批准SkyWalking成为顶级项目,支持Jav…...

代码随想录第45天 | 322. 零钱兑换、279. 完全平方数
322. 零钱兑换 动规五部曲分析如下: 确定dp数组以及下标的含义 dp[j]:凑足总额为j所需钱币的最少个数为dp[j] 确定递推公式 凑足总额为j - coins[i]的最少个数为dp[j - coins[i]],那么只需要加上一个钱币coins[i]即dp[j - coins[i]] 1就是…...

怎么加入Microsoft Cloud Partner Program?
目录 前言 加入Microsoft Cloud Partner Program 1、注册成为微软合作伙伴 2、完成合作伙伴资格要求...
LNMP简易搭建
目录 前言 一、拓扑图 二、NGINX配置 三、配置MySQL 四、配置php环境 五、部署应用 总结 前言 LNMP平台指的是将Linux、Nginx、MySQL和PHP(或者其他的编程语言,如Python、Perl等)集成在一起的一种Web服务器环境。它是一种常用的开发和部署网…...
CClink IE转Modbus TCP网关连接三菱FX5U PLC
捷米JM-CCLKIE-TCP 是自主研发的一款 CCLINK IE FIELD BASIC 从站功能的通讯网关。该产品主要功能是将各种 MODBUS-TCP 设备接入到 CCLINK IE FIELD BASIC 网络中。 捷米JM-CCLKIE-TCP网关连接到 CCLINK IE FIELD BASIC 总线中做为从站使用,连接到 MODBUS-TCP 总线…...

PyTorch 微调终极指南:第 1 部分 — 预训练模型及其配置
一、说明 如今,在训练深度学习模型时,通过在自己的数据上微调预训练模型来迁移学习已成为首选方法。通过微调这些模型,我们可以利用他们的专业知识并使其适应我们的特定任务,从而节省宝贵的时间和计算资源。本文分为四个部分&…...
GO学习之 微框架(Gin)
GO系列 1、GO学习之Hello World 2、GO学习之入门语法 3、GO学习之切片操作 4、GO学习之 Map 操作 5、GO学习之 结构体 操作 6、GO学习之 通道(Channel) 7、GO学习之 多线程(goroutine) 8、GO学习之 函数(Function) 9、GO学习之 接口(Interface) 10、GO学习之 网络通信(Net/Htt…...
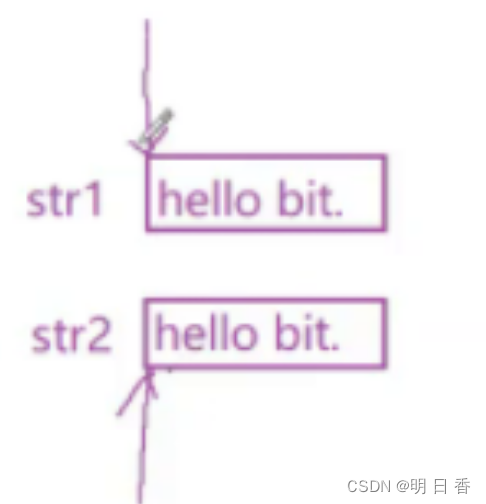
C语言 字符指针
1、介绍 概念: 字符指针,就是字符类型的指针,同整型指针,指针指向的元素表示整型一样,字符指针指向的元素表示的是字符。 假设: char ch a;char * pc &ch; pc 就是字符指针变量,字符指…...

Springboot所有的依赖
<properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><!-- 声明springboot的版本号 -->…...
Flutter BottomSheet 三段式拖拽
BottomSheetBehavior 追踪 BottomSheet系统默认实现效果准备要实现的功能点:定义三段式状态:BottomSheetBehavoir阀值定义1. 未达到滚动阀值,恢复状态2. 达到滚动阀值,更新状态 前面倒是有讲过Android原生的BottomSheetBehavior&a…...

Ubuntu Rockchip完整指南:为RK3588设备快速构建定制化Ubuntu系统
Ubuntu Rockchip完整指南:为RK3588设备快速构建定制化Ubuntu系统 【免费下载链接】ubuntu-rockchip Ubuntu for Rockchip RK35XX Devices 项目地址: https://gitcode.com/gh_mirrors/ub/ubuntu-rockchip Ubuntu Rockchip是一个社区驱动的开源项目,…...

5步掌握FanControl:Windows智能风扇控制终极指南
5步掌握FanControl:Windows智能风扇控制终极指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/FanC…...

告别嗡嗡声!用SWM120 MCU驱动24V单相BLDC风扇,实现静音正弦波控制保姆级教程
静音革命:基于SWM120 MCU的24V单相BLDC风扇正弦波控制实战指南 清晨的书房里,传统风扇的嗡嗡声总是打断思绪;卧室中,电机的高频啸叫让人辗转难眠——这些场景正是无数家电开发者和硬件爱好者试图攻克的难题。当市面大多数BLDC风扇…...

构建高性能HDF5数据可视化架构:ViTables模块化设计指南
构建高性能HDF5数据可视化架构:ViTables模块化设计指南 【免费下载链接】ViTables ViTables, a GUI for PyTables 项目地址: https://gitcode.com/gh_mirrors/vi/ViTables 在科学计算和大数据时代,HDF5格式已成为存储复杂结构化数据的行业标准&am…...
,并处理常见的网络与缓存问题)
实战:从URL直接加载PyTorch预训练权重(以torch.hub为例),并处理常见的网络与缓存问题
实战:从URL直接加载PyTorch预训练权重(以torch.hub为例),并处理常见的网络与缓存问题 在深度学习项目的实际开发中,我们经常需要加载预训练模型权重。传统做法是先将权重文件下载到本地,再通过torch.load(…...

深度实战指南:如何利用ExDark数据集构建完整的低光照视觉AI解决方案
深度实战指南:如何利用ExDark数据集构建完整的低光照视觉AI解决方案 【免费下载链接】Exclusively-Dark-Image-Dataset Exclusively Dark (ExDARK) dataset which to the best of our knowledge, is the largest collection of low-light images taken in very low-…...

如何为Calibre高效获取豆瓣图书元数据:New Douban插件完整指南
如何为Calibre高效获取豆瓣图书元数据:New Douban插件完整指南 【免费下载链接】calibre-douban Calibre new douban metadata source plugin. Douban no longer provides book APIs to the public, so it can only use web crawling to obtain data. This is a cal…...

Qwen3-8B应用案例:如何用它快速生成营销文案和产品介绍
Qwen3-8B应用案例:如何用它快速生成营销文案和产品介绍 1. 引言:当营销文案遇上AI助手 你有没有过这样的经历?产品经理催着要一份产品介绍,市场部急着要一篇营销文案,而你盯着空白的文档,大脑一片空白。传…...

别再只谈概念了!知识图谱在推荐系统里的实战:基于CKE的电影推荐项目搭建
别再只谈概念了!知识图谱在推荐系统里的实战:基于CKE的电影推荐项目搭建 推荐系统早已成为互联网产品的标配功能,但传统协同过滤算法面临冷启动、数据稀疏等瓶颈问题。最近在帮一家流媒体平台优化电影推荐时,我发现单纯依赖用户评…...

FontCenter:告别AutoCAD字体缺失烦恼的智能管理神器
FontCenter:告别AutoCAD字体缺失烦恼的智能管理神器 【免费下载链接】FontCenter AutoCAD自动管理字体插件 项目地址: https://gitcode.com/gh_mirrors/fo/FontCenter 你是否曾经在打开同事发来的AutoCAD图纸时,看到满屏的问号和乱码文字…...