【目标检测系列】YOLOV1解读
前言
从R-CNN到Fast-RCNN,之前的目标检测工作都是分成两阶段,先提供位置信息在进行目标分类,精度很高但无法满足实时检测的要求。
而YoLo将目标检测看作回归问题,输入为一张图片,输出为S*S*(5*B+C)的三维向量。该向量结果既包含位置信息,又包含类别信息。可通过损失函数,将目标检测与分类同时进行,能够满足实时性要求。
接下来给出YOLOV1的网络结构图

核心思想
YOLO将目标检测问题作为回归问题。会将输入图像分为S*S的网格,如果一个物体的中心点落到一个cell中,那么该cell就要负责预测该物体,一个格子只能预测一个物体,同时会生成B个预测框。
对于每个cell:
-
含有B个预测边界框,这些框大小尺寸等等都随便,只有一个要求,就是生成框的中心点必须在cell中,每个框都有一个置信度分数(confidence score)。这些框的置信度分数反映了该模型对某个框内是否含有目标的置信度,以及它对自己的预测的准确度的估量。
-
每个cell还预测了C类的条件概率,即每个单元格只存在一组类别概率,而不考虑框B的数量。
-
每个预测边界框包含5个元素:(x,y,w,h, c) 其中 x,y,w,h表示该框中心位置, c为该框的置信度
-
不管框B的数量多少,该cell只负责预测一个目标
综上,S*S个网格,每个网格要预测B个bounding box,还要预测C个类。网络输出为S*S*(5*B+C)。 (S*S个网络,每个网络都有B个预测框,每个框又有五个参数,在加上每个网格都有C个类别)
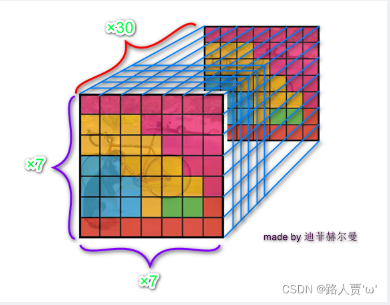
最终的预测特征由边界框位置、边框的置信度得分以及类别概率,即S*S*(5*B+C), 这里是 7*7*(2*5+20)
训练过程
对于一个网络模型,损失函数的目的是要缩小预测值和标签之间的差距。对于YOLOV1网络来说,每个cell含有5*B+C个预测值,我们在训练过程中该如何获得与之对应的label.
这5*B+C个预测值的含义在上面已经给出(S*S个网络,每个网络都有B个预测框,每个框又有五个参数,在加上每个网格都有C个类别),因此我们实际需要给出的label为每个预测框的四个坐标及其置信度,和每个cell对应的类别。
-
每个预测框的四个坐标(x, y, w, h)的label为该预测框所在cell中目标物体的坐标
-
每个预测框的置信度c,反映了该模型对某个框内是否含有目标的置信度,以及它对自己的预测的准确度的估量,是让网络学会自我评价候选框的功能。因此它所对应的label计算相对复杂。我们将置信度定义为
。 Pr(Object)=[0, 1], 如果该单元格内不存在目标(即Pr(Object)=0),则置信度分数为0。 如果单元格内存在目标,即(Pr(Object)=1),我们希望置信度分数等于预测框和真实框之间的交并比(IOU)。
-
每个cell对应的类别概率C,参数数量与该模型类别数量保持一致,label为one-hot编码。
-
此外,根据公式推算,我们发现用置信度*某一类别的概率=
即得到了一个特殊的置信度分数,表示每个预测框中具体某个类别的置信度
损失函数
YOLOV1的损失函数被分为坐标损失、置信度损失和网格类别损失三种

坐标损失

简要介绍下四个坐标(x,y,w,h)的含义,x,y表示预测框中心点坐标,w,h表示预测框的宽高。
表示第i个cell中的第j个预测框是否负责检测物体,同一个cell中仅有IOU值最高的一个框会负责检测物体,并约束其坐标
第一行表示中心点的坐标损失,第二行表示宽高的损失,至于为何对宽高加根号,是为了消除大小框不同的影响。
举个例子,以预测框的宽度为例,不加根号的话,若目标框宽为100,预测结果为90,差值为10,误差为10%,损失为(90-100)^2 = 100; 若目标框宽10,预测结果为9,差值为1,误差为10%,损失为(9-10)^2=1。可以看出,同样的预测差值,产生了同样的损失,但是这个差值给大小框带来的误差差了10倍,而如何利用这个损失值去修正误差的话,对大的预测框来说,微调10%,对小的预测框来说,重调100%。
而加了根号之后,若目标框宽为100,预测结果为90,差值为10,误差为10%,损失为0.263;若目标框宽10,预测结果为9,差值为1,误差为10%,损失为0.0263。同样的误差,对于大小框之间的惩罚从原来的百倍差距,降为10倍差距,即提升了对小框的惩罚力度,毕竟对于小的预测框,一点点偏差都会产生很大的影响。(模型对大小框的约束能力能存在十倍差距,是否可以进一步改进)
置信度损失

表示第i个cell中的第j个预测框是否负责检测物体,
表示第i个cell中的第j个预测框是否不负责检测物体,两个数值含义相反。 表示该预测框的真实置信度,通过上述公式计算得出, 表示模型预测的置信度,此部分损失函数是为了让模型掌握自我评价的能力,为测试过程选择最佳预测框用。
第一行表示负责检测物体的框的置信度损失,第二行表示不负责检测物体的框的置信度损失 (问:两种置信度之间有什么区别)
分类损失

表示第i个cell内是否存在目标物体
测试过程
测试过程就非常简单了,对于一次前向传播得到的S * S *B个预测框,根据各个候选框对应的置信度分数,利用非极大值自抑(NMS),最终得到所有预测结果。
非极大值自抑制(NMS):所有预测框,按照置信度分数从大到小排序。第一轮,选择置信度最高的预测框作为基准,然后所有其他预测框按顺序依次计算与基准预测框的IOU值(提前设置一个阈值,当IOU大于这个阈值,则认为两个预测框高度重合,预测的是同一个物体),对于和基准预测框重合的则直接淘汰。一轮结束后,排除上一轮的基准,重新选择新的预测框作为基准重复上述步骤。
缺点
-
每个cell只能预测一类物体,对于密度大的小物体无法预测
-
定位损失占比较大(包括坐标损失和置信度损失),致使模型更加侧重定位物体,分类能力相对较弱
-
测试时,如果同意物体的长宽比发生变化,则难以泛化。
论文链接:You Only Look Once: Unified, Real-Time Object Detection
源码地址:mirrors / alexeyab / darknet
参考内容:【YOLO系列】YOLOv1论文超详细解读(翻译 +学习笔记)
下一篇:【目标检测系列】YOLOV2解读_怀逸%的博客-CSDN博客
相关文章:
【目标检测系列】YOLOV1解读
前言 从R-CNN到Fast-RCNN,之前的目标检测工作都是分成两阶段,先提供位置信息在进行目标分类,精度很高但无法满足实时检测的要求。 而YoLo将目标检测看作回归问题,输入为一张图片,输出为S*S*(5*BC)的三维向量。该向量…...

Sentieon | 每周文献-Multi-omics(多组学)-第九期
多组学系列文章-1 标题(英文): Prediction of axillary lymph node metastasis in triple-negative breast cancer by multi-omics analysis and an integrated model标题(中文): 基于多组学分析和综合模型…...

CSDN竞赛70期
CSDN竞赛70期 CSDN竞赛70期1.小张的手速大比拼分析代码 2.坐公交分析代码 3.三而竭分析代码 4.争风吃醋的豚鼠分析代码 CSDN竞赛70期 1.小张的手速大比拼 在很久很久以前,小张找到了一颗有 N 个节点的有根树 T 。 树上的节点编号在 1 到 N 范围内。 他很快发现树上…...
mac安装vscode 配置git
1、安装vscode 官网地址 下载mac稳定版安装很慢的解决办法 (转自) mac电脑如何解决下载vscode慢的问题 选择谷歌浏览器右上角的3个点,选择下载内容,右键选择复制链接地址,在新窗口粘贴地址, 把地址中的一段替换成下面的vscode.cd…...
UI自动化环境的搭建(python+pycharm+selenium+chrome)
最近在做一些UI自动化的项目,为此从环境搭建来从0到1,希望能够帮助到你,同时也是自我的梳理。将按照如下进行开展: 1、python的下载、安装,python环境变量的配置。 2、pycharm开发工具的下载安装。 3、selenium的安装。…...
AbstractQueuedSynchronizer
目录 AQS是什么AQS什么样内部类成员变量方法public如果不使用AQS会怎样 AQS的应用ReentrantLockSyncNonfairSyncFairSync 其他实现 AQS是什么 AbstractQueuedSynchronizer(AQS)是Java中的一个并发工具,位于java.util.concurrent.locks包中&a…...

谈谈什么是云计算?以及它的应用
作者:Insist-- 个人主页:insist--个人主页 作者会持续更新网络知识和python基础知识,期待你的关注 目录 编辑 一、什么是云计算 二、云计算的优势与劣势? 1、云计算的优势 ①提高资源利用率 ②提升效率 ③降低成本 2、云…...
)
【BASH】回顾与知识点梳理(十六)
【BASH】回顾与知识点梳理 十六 十六. 十二至十五章知识点总结及练习16.1 总结16.2 练习16.3 简答题 该系列目录 --> 【BASH】回顾与知识点梳理(目录) 十六. 十二至十五章知识点总结及练习 16.1 总结 绝对路径:『一定由根目录 / 写起』…...
docsify gitee 搭建个人博客
docsify & gitee 搭建个人博客 文章目录 docsify & gitee 搭建个人博客1.npm 安装1.1 在Windows上安装npm:1.2 在macOS上安装npm:1.3 linux 安装npm 2. docsify2.1 安装docsify2.2 自定义配置2.2.1 通过修改index.html,定制化开发页面…...

SpringBoot2-Tomcat部署
1.排除内置 Tomcat 在pom.xml文件中的下添加以下代码,用于排除SpringBoot内置Tomcat <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><exclusions><exclusion&…...

Docker查看、创建、进入容器相关的命令
1.查看、创建、进入容器的指令 用-it指令创建出来的容器,创建完成之后会立马进入容器。退出之后立马关闭容器。 docker run -it --namec1 centos:7 /bin/bash退出容器: exit查看现在正在运行的容器命令: docker ps查看历史容器࿰…...

leetcode1. 两数之和
题目:leetcode1. 两数之和 描述: 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中…...
温室花卉种植系统springboot框架jsp鲜花养殖智能管理java源代码
本项目为前几天收费帮学妹做的一个项目,Java EE JSP项目,在工作环境中基本使用不到,但是很多学校把这个当作编程入门的项目来做,故分享出本项目供初学者参考。 一、项目描述 基于Git无线传感网络的温室花卉种植智能控制系统 系统…...
测试老鸟经验总结,Jmeter性能测试-重要指标与性能结果分析(超细)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 Aggregate Report …...
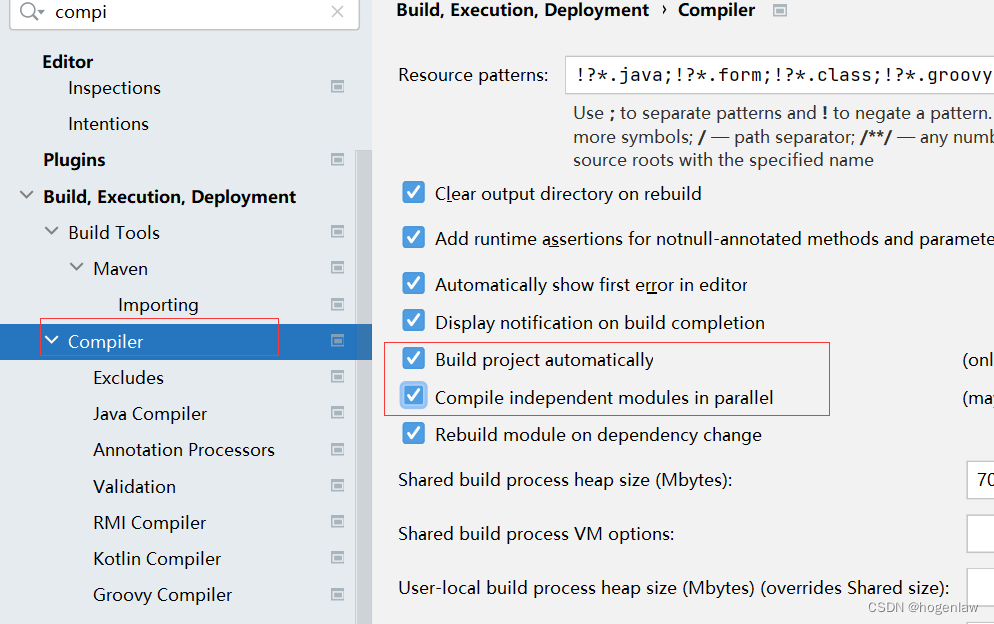
IDEA设置Maven自动编译model
IDEA设置Maven自动编译model 项目工程结构IDEA maven设置 项目工程结构 假设我们的项目结构是下图这样,也就是一个父工程下包含多个子模块,其中dubbo-01-api是公共模块,其它两个模块要想使用必须在pom文件中引入。 本地开发要想不会报错&am…...

关于本地mockjs的使用
安装mockjs npm install mockjs -s在src下新建目录mockData,所有mock请求可以放该文件夹下面。例如在mockData文件夹下新建一个home.js文件。用来处理首页的请求数据 home.js export default {getHomeData:()>{return{code:200,data:{tableData:[{name:张三,se…...

hive 中最常用日期处理函数
hive 常用日期处理函数 在工作中,日期函数是提取数据计算数据必须要用到的环节。哪怕是提取某个时间段下的明细数据也得用到日期函数。今天和大家分享一下常用的日期函数。为什么说常用呢?其实这些函数在数据运营同学手上是几乎每天都在使用的。 技术交…...
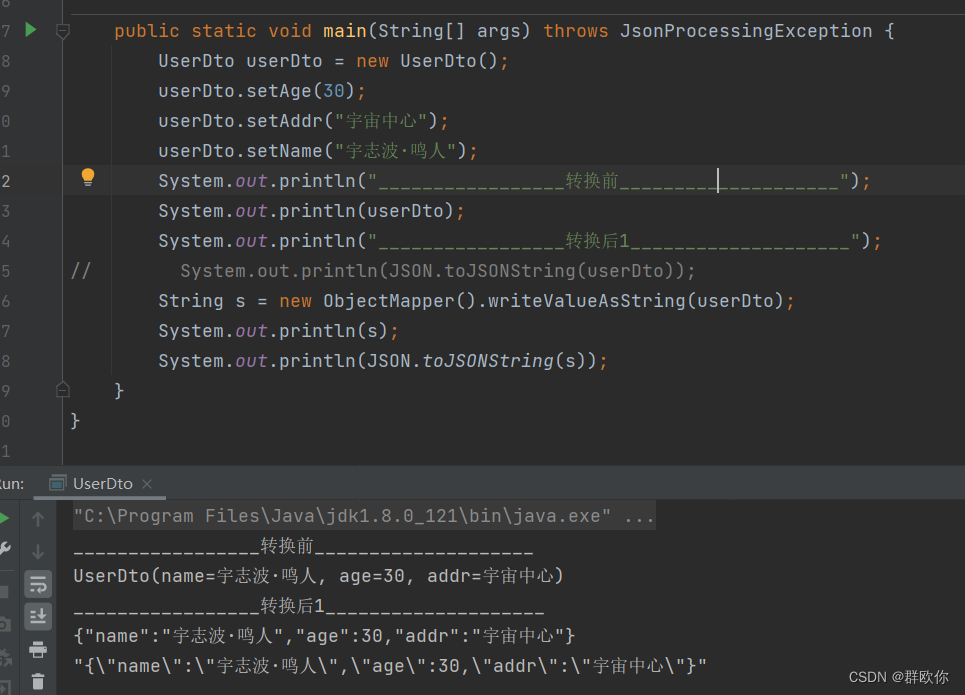
记录一下Java实体转json字段顺序问题
特殊需求,和C交互他们那边要求字段顺序要和他们定义的一致(批框架) 如下: Data public class UserDto {private String name;private Integer age;private String addr; }未转换前打印: 转换后打印: 可以看到转换为json顺序打印…...
)
微积分入门:总结归纳汇总(一)
基础 标准符号约定: ( s i n x ) n (sinx)^n (sinx)...

ubuntu python虚拟环境venv搭配systemd服务实战(禁用缓存下载--no-cache-dir)
文章目录 参考文章目录结构步骤安装venv查看python版本创建虚拟环境激活虚拟环境运行我们程序看缺少哪些依赖库,依次安装它们接下来我们配置python程序启动脚本,脚本中启动python程序前需先激活虚拟环境配置.service文件然后执行部署脚本,成功…...

SillyTavern终极指南:从零开始打造你的AI对话前端
SillyTavern终极指南:从零开始打造你的AI对话前端 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern SillyTavern是一款专为高级用户设计的LLM前端界面,提供强大的AI对…...

gh_mirrors/ad/advice项目社区支持体系:如何获得申请过程中的帮助与指导
gh_mirrors/ad/advice项目社区支持体系:如何获得申请过程中的帮助与指导 【免费下载链接】advice A repository of links with advice related to grad school applications, research, phd etc 项目地址: https://gitcode.com/gh_mirrors/ad/advice gh_mirr…...

别再死记硬背MobileNet了!用GhostNet+SE模块在树莓派上部署轻量级图像识别模型
在树莓派上实战GhostNetSE:轻量级图像识别的工程优化指南 当你在树莓派的资源限制下挣扎着运行MobileNet时,是否想过还有更优雅的解决方案?GhostNet的出现彻底改变了我们对轻量化网络的认知——它不再只是简单地削减参数,而是通过…...

SpringBoot+Redis 点赞系统源码:高并发写入削峰实现
点赞这个功能,代码写起来不复杂,但一旦出现热点内容,很容易把数据库拖垮。接口延迟抖动、慢SQL堆积、连接池打满,这些问题基本都出在“写路径没有控制”。 在“仿小红书”这类内容社区里,点赞属于典型的高频操作。湖南…...

Audiveris终极指南:5分钟学会免费开源乐谱识别,轻松将纸质乐谱转为数字格式
Audiveris终极指南:5分钟学会免费开源乐谱识别,轻松将纸质乐谱转为数字格式 【免费下载链接】audiveris Latest generation of Audiveris OMR engine 项目地址: https://gitcode.com/gh_mirrors/au/audiveris 你是否曾面对一堆纸质乐谱发愁&#…...

避开这些坑,你的蓝桥杯C/C++就能多拿20分:从‘送分题’失分到稳定省二的复盘
蓝桥杯C/C竞赛避坑指南:从手滑失分到稳拿省二的实战策略 第一次参加蓝桥杯时,我盯着屏幕上那道"送分题"足足愣了五分钟——明明是个简单的进制转换,提交后系统却显示答案错误。直到赛后复盘才发现,题目要求输出字母必须…...

6 文件保存功能优化
6 文件保存功能优化 6.1 开发流程 流程说明 实现保存文件的功能,包含以下逻辑: 检查当前是否有已打开的文件如果没有打开的文件,弹出保存文件对话框让用户选择保存位置将文本编辑框中的内容写入到文件中 代码实现 void Widget::on_btnSave_cl…...

你的Mac还缺这个窗口管理神器吗?告别频繁切换,工作效率翻倍!
你的Mac还缺这个窗口管理神器吗?告别频繁切换,工作效率翻倍! 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 你是否曾经在视…...

一物一码有哪些公司:快消企业如何选择合适服务商
一物一码有哪些公司:快消企业如何选择合适服务商在快消行业,渠道费用越来越高、终端动销越来越难、消费者触达越来越分散,已经成为许多企业的共同感受。相比单点式促销工具,一物一码正在从“营销活动手段”演变为“渠道、用户与产…...

AbMole 丨 FIN56 通过降解 GPX4 与调控 CoQ10 诱导铁死亡
FIN56(AbMole,M6731)是一种铁死亡(ferroptosis)诱导剂[1],其作用机理具有双重性:一方面,FIN56通过诱导谷胱甘肽过氧化物酶4(GPX4)蛋白的降解来触发铁死亡&…...