Titanic--细节记录三
目录
image
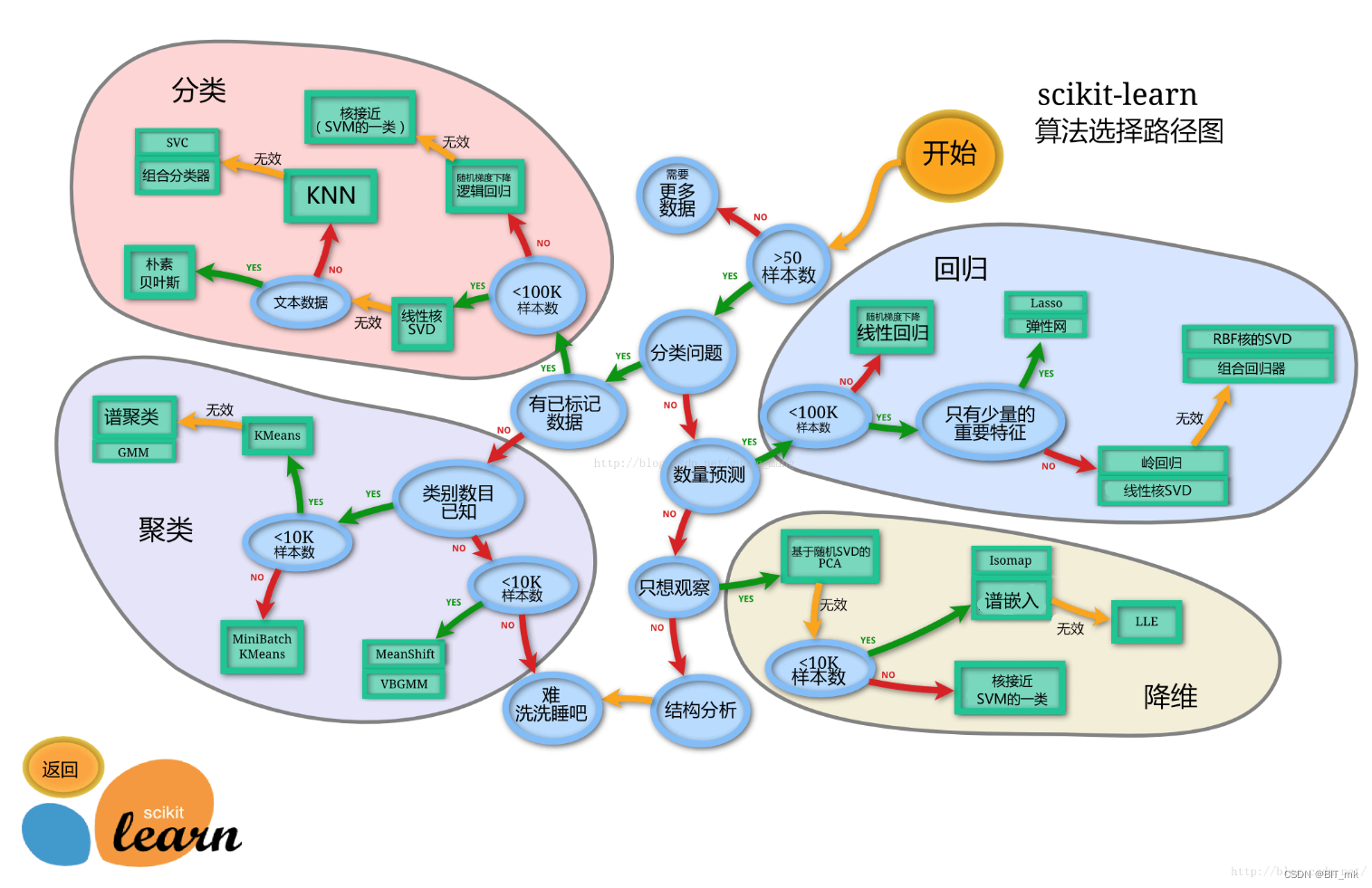
sklearn模型算法选择路径图
留出法划分数据集
‘留出’的含义
基本步骤和解释
具体例子
创造一个数据集
留出法划分
预测结果可视化
分层抽样
设置方法
划分数据集的常用方法
train_test_split
什么情况下切割数据集的时候不用进行随机选取
逻辑回归模型
随机森林分类模型
训练集和测试集的得分
重要注意事项
为什么线性模型可以进行分类任务,背后是怎么样的数学关系
对于多分类问题,线性模型是怎么进行分类的
预测标签
标签概率
标签概率的作用
模型评估
交叉验证
k折越多的情况带来的影响
混淆矩阵
准确率
召回率
精确度
f-分数
ROC曲线
多分类问题绘制ROC曲线
例子
ROC曲线的作用
image
库通常可能指的是Python的PIL(Python Imaging Library)的子模块,也称为Pillow。它是一个用于打开、操作和保存许多不同图像文件格式的库。以下是一些image库(或PIL.Image模块)的主要用途:
-
打开和保存图像:可以读取多种格式的图像,并将它们保存为不同的文件类型。
-
图像处理:可以进行图像裁剪、调整大小、旋转、滤波等操作。
-
图像增强:可以改变图像的亮度、对比度、饱和度等。
-
绘制图像:可以在图像上绘制文字、线条和其他形状。
-
图像分析:可以获取图像的某些统计信息,例如直方图。
-
格式转换:可以在不同的图像文件格式之间进行转换。
-
动画支持:可以创建和编辑动态图像,例如GIF。
-
与NumPy和其他库集成:可以方便地与NumPy数组进行互操作,与其他科学和数据分析库集成。
sklearn模型算法选择路径图
留出法划分数据集
‘留出’的含义
在将数据分为训练集和测试集时,你“留出”了一部分数据(例如20%),而不用它们来训练模型。这部分留出的数据用于测试,从而可以在模型训练完成后,评估其在未见过的数据上的性能。
基本步骤和解释
-
训练集和测试集的划分:原始数据集被分为训练集和测试集两部分。常见的划分比例是70% - 30%、80% - 20%等,但这可以根据具体情况进行调整。
-
训练模型:训练集用于训练机器学习模型。这意味着模型将尝试从训练数据中学习模式和关系。
-
评估模型:测试集用于评估模型。由于测试数据在训练过程中未被模型看到,因此它们提供了一种评估模型在未见过的数据上性能的公正方式。
-
(可选)验证集的使用:有时,数据还可以被进一步分为验证集,用于模型选择、调整超参数等。这样可以确保测试集完全保留,用于最终的性能评估。
具体例子
假设我们有一个包含100个样本的数据集,并且我们想要用线性回归模型预测一个连续的目标变量。
我们可以使用80-20的划分来进行训练和测试:
-
划分数据:从100个样本中,选择80个样本作为训练集,剩下的20个样本作为测试集。
-
训练模型:使用训练集(80个样本)训练线性回归模型。在这个阶段,模型将尝试找到特征和目标变量之间的最佳线性关系。
-
评估模型:使用测试集(20个样本)评估模型的性能。由于这些样本在训练过程中未被模型看到,因此它们提供了对模型在未见过数据上性能的合理估计。
创造一个数据集
假设我们有一个线性关系,其中目标变量 y 由两个特征 x1 和 x2 通过下面的公式决定:
留出法划分
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt# 创建数据集
np.random.seed(42)
x1 = np.random.uniform(0, 10, 100)
x2 = np.random.uniform(0, 10, 100)
y = 3 * x1 + 5 * x2 + np.random.normal(0, 3, 100)
data = pd.DataFrame({'x1': x1, 'x2': x2, 'y': y})# 分离特征和目标变量
X = data[['x1', 'x2']]
y = data['y']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=42)# 创建并拟合线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)# 在测试集上进行预测
y_pred = model.predict(X_test)# 使用均方误差评估模型性能
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error on Test Set:", mse)plt.scatter(y_test, y_pred)
plt.xlabel('Actual Values')
plt.ylabel('Predicted Values')
plt.title('Actual vs Predicted Values')
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'k--', lw=2) # 绘制y=x的线,理想预测
plt.show()![]()
预测结果可视化
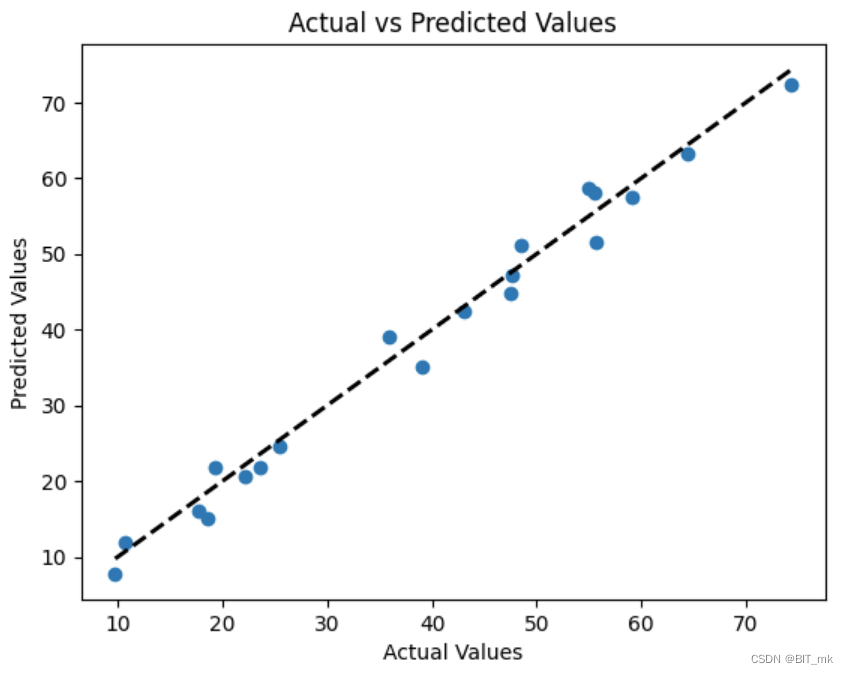
散点图上的点表示每个样本的实际目标值与模型预测的目标值。黑色虚线表示理想预测,其中预测值等于实际值。如果模型的预测非常准确,那么点应该接近这条线。
分层抽样
在分类问题中,在划分数据集时常使用分层抽样。分层抽样确保训练集和测试集中的每个类别的比例与整个数据集中的比例相同。这样做可以确保划分后的训练和测试集在类别分布上与整个数据集代表性一致,特别是当某些类别的样本数量较少时。通过这种方式,分层抽样有助于提供更准确和可靠的模型评估,因为它考虑了类别间可能的不均衡。
分层抽样是对于目标变量(也就是标签)来进行的。
设置方法
设置stratify参数
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)划分数据集的常用方法
-
留出法(Holdout Method): 数据被分为训练集和测试集。常见的划分比例有70/30或80/20。
-
k折交叉验证(k-Fold Cross-Validation): 数据被分为k个等大小的子集。训练-测试过程重复k次,每次使用一个不同的子集作为测试集,其余的作为训练集。最终的评估是k次迭代的平均值。
-
留一交叉验证(Leave-One-Out Cross-Validation): 特殊的k折交叉验证,其中k等于样本数量。每次只留下一个样本作为测试集。
-
分层k折交叉验证(Stratified k-Fold Cross-Validation): 与k折交叉验证相似,但每个子集内的类分布与整个数据集的类分布相同。
-
时间序列交叉验证(Time Series Cross-Validation): 适用于时间序列数据,确保训练集中的所有数据都早于测试集中的数据。
-
随机拆分(Random Split): 随机分配数据到训练和测试集。可以重复多次。
-
自助法(Bootstrapping): 通过有放回抽样生成训练集,未被抽取的样本用作测试集。
-
分组k折交叉验证(Group k-Fold Cross-Validation): 如果数据中有相关的组结构(例如,多个观察来自同一患者),则使用组作为划分依据。
train_test_split
train_test_split是一个来自sklearn.model_selection模块的函数,用于将数据集划分为训练集和测试集。
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X: 特征矩阵,包含你想要用于训练的样本。y: 目标变量或标签。test_size: 测试集的比例或绝对数量。例如,0.2表示20%的数据将作为测试集。random_state: 随机数种子,确保每次运行都能得到相同的划分结果。stratify: 可用于分类问题中的分层抽样。将此参数设置为目标变量y,可以确保训练和测试集中的类别比例与整个数据集中的比例相同。
返回值:
X_train,X_test: 划分后的特征矩阵。y_train,y_test: 划分后的目标变量。
什么情况下切割数据集的时候不用进行随机选取
-
时间序列数据: 如果你的数据有时间依赖性,你通常不会想要随机划分数据集。例如,如果你在尝试预测未来股票价格,你不会想要将未来的数据包括在训练集中。在这种情况下,你可能会按时间顺序划分数据,以确保测试集仅包括训练期之后的数据。
-
已预先排序或分组的数据: 如果数据已按某些特定顺序或分组排列,并且你希望在训练和测试集中保留这种结构,则可能不会进行随机选取。
-
数据量很小: 如果你的数据量非常小,并且随机划分可能导致训练或测试集中某些类别的样本数量太少或没有,你可能希望更精心地划分数据。
-
使用k折交叉验证: 在使用k折交叉验证时,你会将整个数据集均匀划分为k个子集或折叠。然后,你会轮流使用k-1个折叠进行训练,使用剩下的一个折叠进行测试。这种方法不涉及随机选取,除非在划分折叠之前进行了随机洗牌。
-
数据具有固有的顺序或分组关系: 如果数据具有某种固有的顺序或分组关系,随机选取可能会破坏这种关系。在这种情况下,你可能需要根据特定的业务逻辑或问题需求来划分数据。
逻辑回归模型
逻辑回归是一种用于二分类问题(或者多分类问题的推广)的统计模型。它用于预测某个事件的发生概率,并将其输出为一个概率值,该值可以进一步转化为分类预测。

随机森林分类模型
随机森林是一种集成学习方法,通过组合多个决策树的预测来提高模型的精度和鲁棒性。随机森林可以用于分类和回归任务。
参数
随机森林的主要参数包括:
n_estimators:森林中树的数量。max_features:每次分裂时考虑的特征数量。max_depth:树的最大深度。min_samples_split:节点分裂所需的最小样本数。min_samples_leaf:叶节点所需的最小样本数。
from sklearn.ensemble import RandomForestClassifiermodel = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
predictions = model.predict(X_test)
随机森林其实是决策树集成为了降低决策树过拟合的情况。
训练集和测试集的得分
训练集和测试集的得分通常是衡量机器学习模型性能的指标。
-
训练集得分:训练集是用来训练机器学习模型的数据集。训练集得分衡量了模型在训练数据上的性能。这可能包括准确率、召回率、精确率、F1分数等,具体取决于任务和所选评估指标。一个较高的训练得分通常表示模型在训练数据上的拟合良好。
-
测试集得分:测试集是用来评估模型泛化能力的独立数据集,即模型在未见过的数据上的性能。与训练集得分类似,测试集得分也可以使用各种指标来测量,如准确率、均方误差等。测试集得分为你提供了关于模型如何适用于新数据的见解。
重要注意事项
-
过拟合:如果训练集得分远高于测试集得分,可能是过拟合的迹象。这意味着模型过于复杂,并且学习了训练数据中的噪声,而不仅仅是潜在的模式。
-
欠拟合:如果训练集和测试集的得分都较低,或者测试集得分高于训练集得分,这可能是欠拟合的迹象。这表示模型可能过于简单,并未捕捉到数据中的基本模式。
训练集和测试集的得分提供了评估模型拟合数据能力和泛化能力的方法。理想情况下,两者之间的得分应该相近,而且都相对较高,这表明模型既没有过拟合也没有欠拟合。
为什么线性模型可以进行分类任务,背后是怎么样的数学关系
线性模型可以执行分类任务的关键在于它们能够划分特征空间的不同区域,并将这些区域映射到不同的类别。

对于多分类问题,线性模型是怎么进行分类的

预测标签
pred = lr.predict(X_train)array([0, 1, 1, 1, 0, 0, 1, 0, 1, 1])标签概率
pred_proba = lr.predict_proba(X_train)array([[0.60870022, 0.39129978],[0.17725433, 0.82274567],[0.40750365, 0.59249635],[0.18925851, 0.81074149],[0.87973912, 0.12026088],[0.91374559, 0.08625441],[0.13293198, 0.86706802],[0.90560801, 0.09439199],[0.05283987, 0.94716013],[0.10936016, 0.89063984]])标签概率的作用
-
决策阈值的调整:在二元分类中,概率输出允许你自定义决策阈值,而不仅仅是使用0.5。这对于需要平衡精确率和召回率的任务特别重要。
-
风险评估:在某些应用中,如金融和医疗领域,了解预测的不确定性可能非常重要。概率可以提供关于模型确定性的信息。
-
多类别分类:在多类别分类中,概率输出可以提供每个类别的置信度,这有助于了解模型对不同类别的倾向性。
-
排序和推荐:概率可以用于对实例进行排序,例如在推荐系统中选择最有可能的推荐项。
-
模型校准:概率输出可以用于模型校准,以确保预测的概率真实反映了实际发生的概率。这对于许多任务至关重要,例如气象预报。
-
人工干预和解释:概率预测可以方便人工分析和解释。当一个实例的预测概率接近于阈值时,人们可能希望手动审查该实例。
-
集成学习:在集成多个模型时,概率输出可以提供更丰富的信息用于组合不同模型的预测。
-
成本敏感学习:在成本敏感的任务中,不同类型的错误可能有不同的成本。概率允许你根据特定的成本函数自定义决策阈值。
模型评估
- 模型评估是为了知道模型的泛化能力。
- 交叉验证(cross-validation)是一种评估泛化性能的统计学方法,它比单次划分训练集和测试集的方法更加稳定、全面。
- 在交叉验证中,数据被多次划分,并且需要训练多个模型。
- 最常用的交叉验证是 k 折交叉验证(k-fold cross-validation),其中 k 是由用户指定的数字,通常取 5 或 10。
- 准确率(precision)度量的是被预测为正例的样本中有多少是真正的正例
- 召回率(recall)度量的是正类样本中有多少被预测为正类
- f-分数是准确率与召回率的调和平均
交叉验证
交叉验证(Cross-Validation)是一种统计学中评估估计器性能的方法。在交叉验证中,数据集被分成几个部分,然后多次进行训练和验证,以便更准确地评估模型的性能。
常见的交叉验证方法包括:
-
k-折交叉验证(k-Fold Cross-Validation): 数据集被分成k个大小相等的折叠(folds)。对于k次迭代,每次迭代都选择一个折叠作为验证集,其余的k-1个折叠作为训练集。这个过程重复k次,每个折叠都被用作验证集一次。最后,这k次迭代的结果被平均,以得到最终的评估得分。
-
留一交叉验证(Leave-One-Out Cross-Validation, LOOCV): 这是k-折交叉验证的特殊情况,其中k等于样本的数量。每次迭代中,只有一个样本用作验证集,其余样本用作训练集。
-
分层k-折交叉验证(Stratified k-Fold Cross-Validation): 在这种方法中,数据被分成k个折叠,但与标准的k-折交叉验证不同的是,每个折叠中的类别分布与整个数据集中的类别分布相同。这对于类别不平衡的数据集特别有用。
交叉验证的优点包括:
- 减少过拟合风险:由于模型在k个不同的训练集和验证集上进行训练和测试,因此交叉验证能更好地评估模型的泛化能力。
- 更有效地利用数据:与单次数据划分相比,交叉验证更有效地利用了可用数据,因为每个样本都被用作验证一次。
交叉验证的缺点可能是计算成本较高,因为模型需要在k个不同的训练集上进行训练和测试。
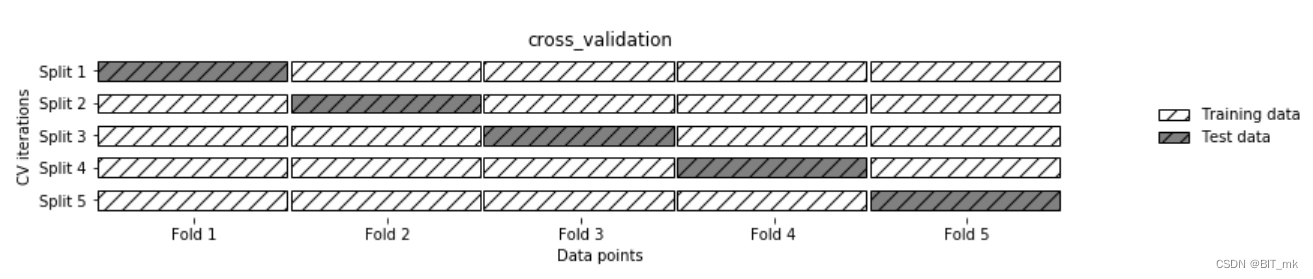
k折越多的情况带来的影响
-
计算成本增加:k越大意味着需要进行更多次的训练和验证迭代。这会增加计算时间和资源的消耗。
-
方差增加,偏差减少:k值增大,每次迭代的训练集与整体数据集更相似,可能减少模型对训练集的偏差,但由于训练集之间的重叠度增加,可能增加评估的方差。
-
对不平衡数据的敏感度增加:当k值非常大时,每个验证集中的样本数量减少,这可能导致验证集中某些类别的样本数量非常少,对不平衡数据的敏感度增加。
-
泛化能力评估更准确:由于使用了更多的不同训练集和验证集组合,k越大,对模型的泛化能力的评估通常更准确。
-
特殊情况的留一法:当k等于样本数量时,就是留一法。这种情况下,方差可能会非常高,每次只有一个样本用作验证集,评估可能会受到噪声的较大影响。
-
常用的是5或10
混淆矩阵
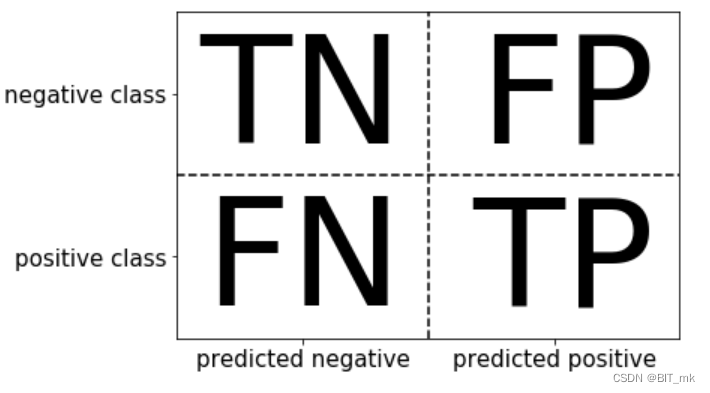
准确率
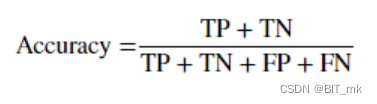
召回率

精确度
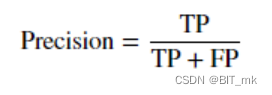
f-分数
![]()
ROC曲线
ROC曲线(Receiver Operating Characteristic Curve)是一种用于评估二元分类器性能的图形化工具。通过将真正例率(True Positive Rate, TPR)和假正例率(False Positive Rate, FPR)相对于不同决策阈值的变化绘制在坐标图上,可以形成ROC曲线。
-
真正例率(TPR):也称为召回率,表示实际正类样本中被正确分类为正类的比例。计算公式为:
-
假正例率(FPR):表示实际负类样本中被错误分类为正类的比例。计算公式为:
ROC曲线的横坐标是FPR,纵坐标是TPR。随着分类器阈值的变化,TPR和FPR会有所变化,从而在图上形成一条曲线。曲线下方的面积称为AUC(Area Under the Curve),表示模型的分类能力。
- 若ROC曲线接近左上角,则说明分类器的性能很好。
- 若ROC曲线接近对角线,则说明分类器的性能一般,相当于随机猜测。
- ROC曲线下面所包围的面积越大越好。
ROC曲线的优点是不受类别不平衡的影响,可以用于比较不同模型的性能或选择合适的阈值。
多分类问题绘制ROC曲线
对于多分类问题,可以通过一对多(One-vs-All)或一对一(One-vs-One)的策略绘制ROC曲线。以下是一对多策略的常见做法:
-
将每个类别作为正类,其他所有类别作为负类:对于有N个类别的问题,可以构建N个二元分类器,并针对每个类别计算ROC曲线。
-
计算各类别的TPR和FPR:对于每个类别,可以计算真正例率(TPR)和假正例率(FPR),并在相应的坐标上绘制ROC曲线。
-
绘制多条ROC曲线:在同一坐标系上绘制N条ROC曲线,每条曲线对应一个类别作为正类的情况。或者,可以计算每个类别的微平均ROC曲线,它是通过汇总每个类别的FPR和TPR并取平均值得到的。
-
计算AUC:可以计算每条ROC曲线下的面积(AUC)以量化模型对各个类别的分类性能。
例子
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, auc
from sklearn.preprocessing import label_binarize
from sklearn.multiclass import OneVsRestClassifier
import matplotlib.pyplot as plt
import numpy as np# 创建一个三分类问题的数据集
X, y = make_classification(n_samples=1000, n_features=20, n_classes=3, n_clusters_per_class=1, n_informative=3, random_state=42)# 将标签二值化
y = label_binarize(y, classes=[0, 1, 2])
n_classes = y.shape[1]# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=42)# 创建并训练一对多的模型
classifier = OneVsRestClassifier(LogisticRegression(max_iter=10000))
y_score = classifier.fit(X_train, y_train).decision_function(X_test)# 为每个类别计算ROC曲线和AUC
plt.figure()
for i in range(n_classes):fpr, tpr, _ = roc_curve(y_test[:, i], y_score[:, i])roc_auc = auc(fpr, tpr)plt.plot(fpr, tpr, label='Class %d (AUC = %0.2f)' % (i, roc_auc))plt.plot([0, 1], [0, 1], 'k--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Multi-class ROC')
plt.legend(loc="lower right")
plt.show()
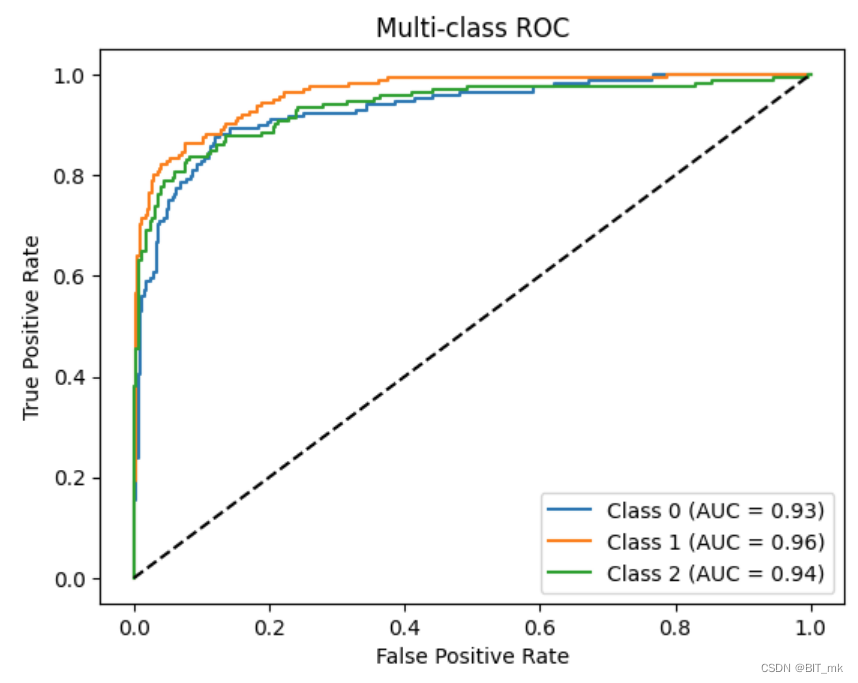
ROC曲线的作用
-
模型选择:如果有多个候选模型,可以通过比较它们的ROC曲线和AUC值来选择最佳模型。
-
阈值调整:可以根据特定业务需求(如最大化精确度或敏感度)来选择合适的阈值。
-
诊断模型的弱点:ROC曲线的形状可能揭示模型的某些弱点。例如,如果曲线接近对角线,可能意味着模型性能不佳。
-
处理不平衡数据:在类别不平衡的情况下,ROC曲线提供了一种不受类别分布影响的性能评估方法。
-
改进模型性能:通过分析ROC曲线,您可以更好地理解模型在不同阈值下的性能,可能会促使您尝试不同的特征工程或模型调整方法来改进性能。
-
业务决策支持:在某些情况下,业务需求可能强调特定类型的错误(如假正率或假负率)的重要性。ROC曲线可以帮助您量化不同阈值下这些错误的权衡,从而支持有针对性的业务决策。
-
增强解释性:通过可视化模型的ROC曲线,可以向非技术干系人更清晰地解释模型的性能和选择。
相关文章:
Titanic--细节记录三
目录 image sklearn模型算法选择路径图 留出法划分数据集 ‘留出’的含义 基本步骤和解释 具体例子 创造一个数据集 留出法划分 预测结果可视化 分层抽样 设置方法 划分数据集的常用方法 train_test_split 什么情况下切割数据集的时候不用进行随机选取 逻辑回归…...

k8s-----集群调度
目录 一:调度约束 二:Pod 启动创建过程 三:k8s调度过程 1、Predicate 有一系列的常见的算法 2、常见优先级选项 3、指定调度节点 (1)nodeName指定 (2)nodeSelector指定 四:亲和…...

01-Spark环境部署
1 Spark的部署方式介绍 Spark部署模式分为Local模式(本地模式)和集群模式(集群模式又分为Standalone模式、Yarn模式和Mesos模式) 1.1 Local模式 Local模式常用于本地开发程序与测试,如在idea中 1.2 Standalone模…...

HOT86-单词拆分
leetcode原题链接:单词拆分 题目描述 给你一个字符串 s 和一个字符串列表 wordDict 作为字典。请你判断是否可以利用字典中出现的单词拼接出 s 。注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。 示例 1:…...

开源数据集分类汇总(医学,卫星,分割,分类,人脸,农业,姿势等)
本文汇总了医学图像、卫星图像、语义分割、自动驾驶、图像分类、人脸、农业、打架识别等多个方向的数据集资源,均附有下载链接。 该文章仅用于学习记录,禁止商业使用! 1.医学图像 疟疾细胞图像数据集 下载链接:http://suo.nz/2V…...

Linux:Firewalld防火墙
目录 绪论 1、firewalld配置模式 2、预定义服务:系统自带 3端口管理 绪论 firewalld 防火墙,包过滤防火墙,工作在网络层,centos7自带的默认的防火墙 作用是为了取代iptables 1、firewalld配置模式 运行时配置 永久配置 i…...

mysql死锁;锁表排查
概述 有时候提前终止了navicat执行线程,但是实际mysql还在执行这个线程, 需要通过mysql本身去终止. mysql:8.0 三板斧第一斧 捞点网上线程现成的执行命令 1.查询是否锁表 show OPEN TABLES where In_use > 0;2.查询进程(如果您有SUP…...
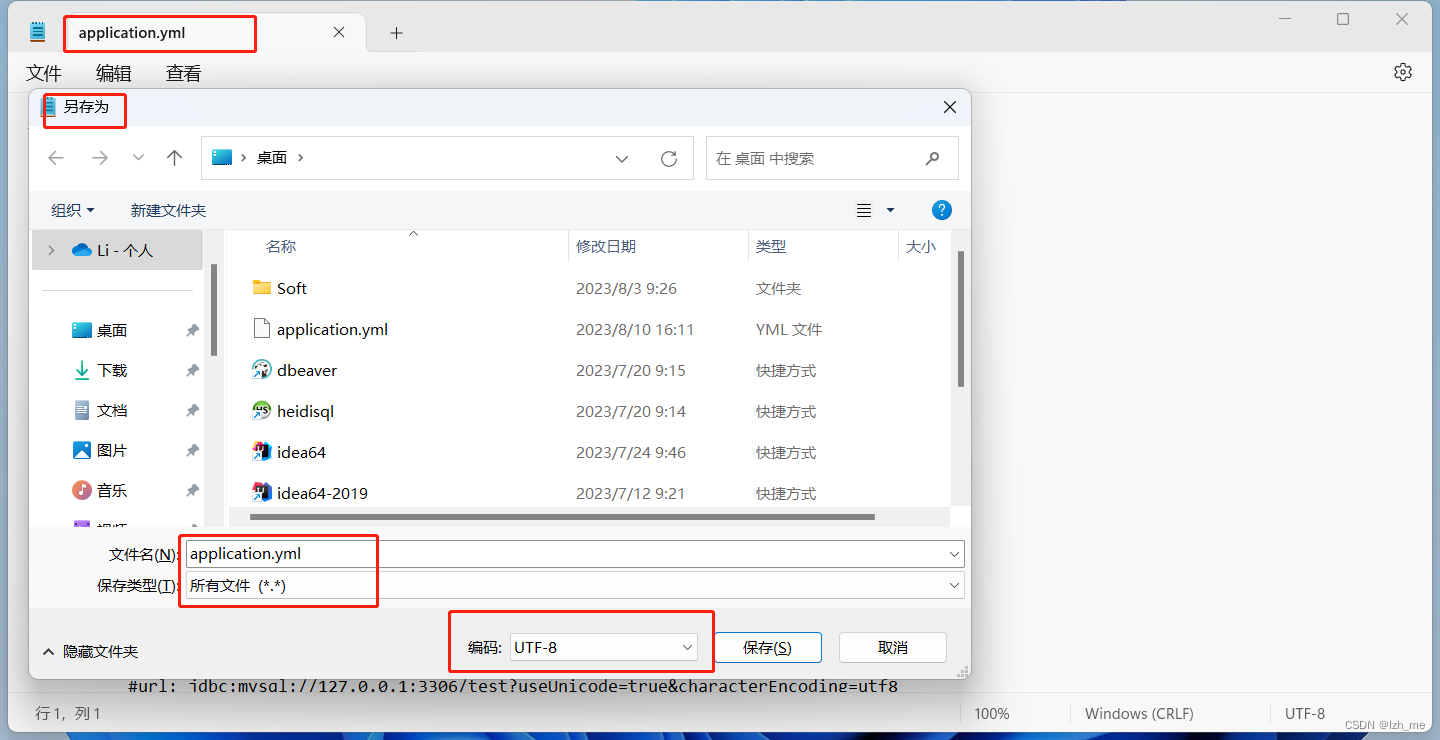
YAMLException: java.nio.charset.MalformedInputException: Input length = 1
springboot项目启动的时候提示这个错误:YAMLException: java.nio.charset.MalformedInputException: Input length 1 根据异常信息提示,是YAML文件有问题。 原因是yml配置文件的编码有问题。 需要修改项目的编码格式,一般统一为UTF-8。 或…...

无需求文档,保障测试质量的可行性做法
这篇文章,内容是:无需求文档的情况下,作为一个测试人员,应该如何做 ,才能保障测试质量不出问题,以及如何不背锅 ? 001 没有需求文档3种可能情况 : 1、公司都没产品经理࿰…...

SpringBoot项目学习笔记
第一章 SpringBoot有哪些优点? Spring Boot作为Java开发的框架和工具集,具有许多优点,这些优点有助于简化开发过程并提高效率。以下是一些主要的优点: 简化配置: Spring Boot采用约定优于配置的原则,通过自…...

如何在Vue表单处理中实现表单字段的文件下载
Vue.js 是一种流行的JavaScript框架,用于构建用户界面。在Vue应用中,我们经常需要处理表单操作,其中一个常见需求是实现文件下载。以下介绍如何在Vue表单处理中实现表单字段的文件下载,大家共同交流。 一、使用HTML的a标签实现文…...

SSL证书DV和OV的区别?
SSL证书是在互联网通信中保护数据传输安全的一种加密工具。它能够确保客户端和服务器之间的通信得以加密,防止第三方窃听或篡改信息。在选择SSL证书时,常见的有DV证书和OV证书,它们在验证标准和信任级别上有所不同。那么SSL证书DV和OV的有哪些…...

计算机竞赛 GRU的 电影评论情感分析 - python 深度学习 情感分类
1 前言 🔥学长分享优质竞赛项目,今天要分享的是 🚩 GRU的 电影评论情感分析 - python 深度学习 情感分类 🥇学长这里给一个题目综合评分(每项满分5分) 难度系数:3分工作量:3分创新点:4分 这…...
论文阅读 - Neutral bots probe political bias on social media
论文链接:Neutral bots probe political bias on social media | EndNote Click 试图遏制滥用行为和错误信息的社交媒体平台被指责存在政治偏见。我们部署中立的社交机器人,它们开始关注 Twitter 上的不同新闻源,并跟踪它们以探究平台机制与用…...
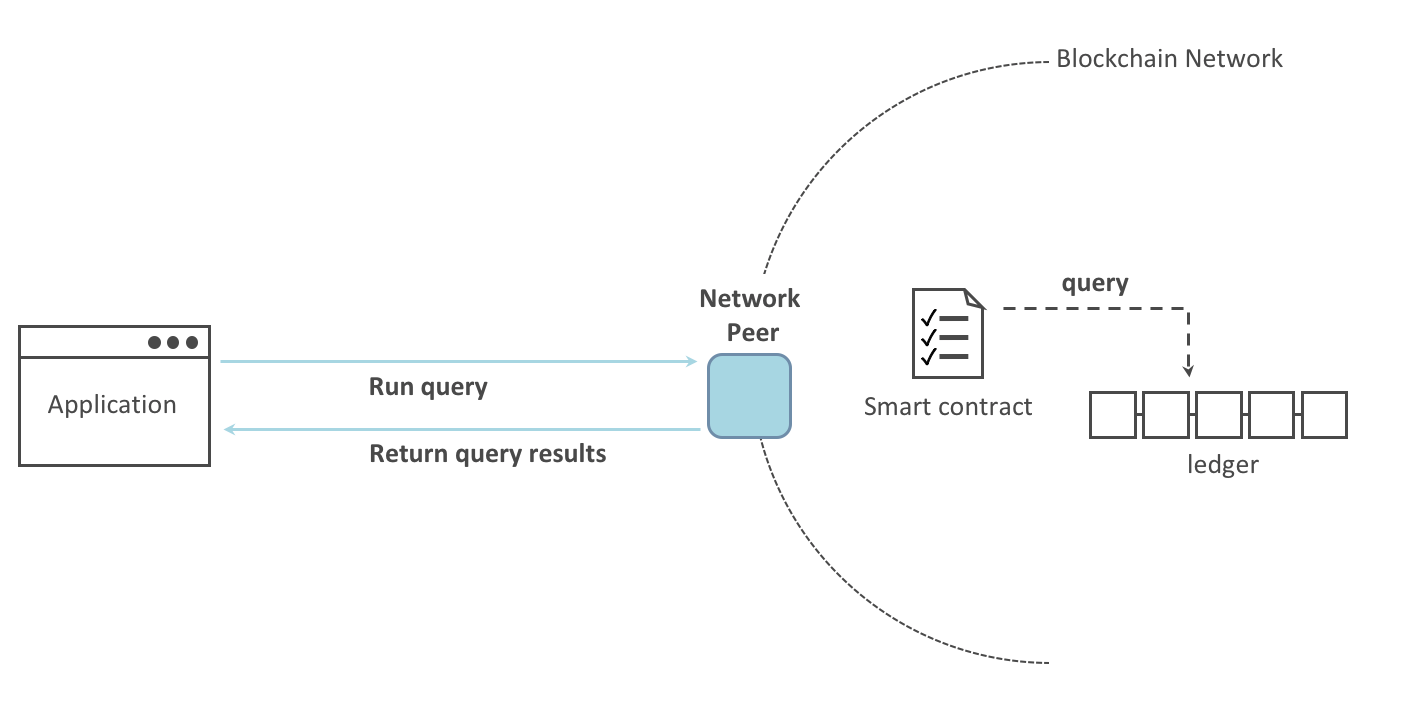
Fabric系列 - 知识点整理
知识点 源码编译 主机编译 容器编译 手动部署(docker-compose) 单peer 多peer 中途加peer 多主机多peer 链码 语法, 接口 (go版) 命令行调用 ca server 在DApp中使用SDK调用 (js版) 部署的几个阶段 部署1排序和1节点, 1组织1通道 光部署能Dapp 带ca server (每个组织一个)…...
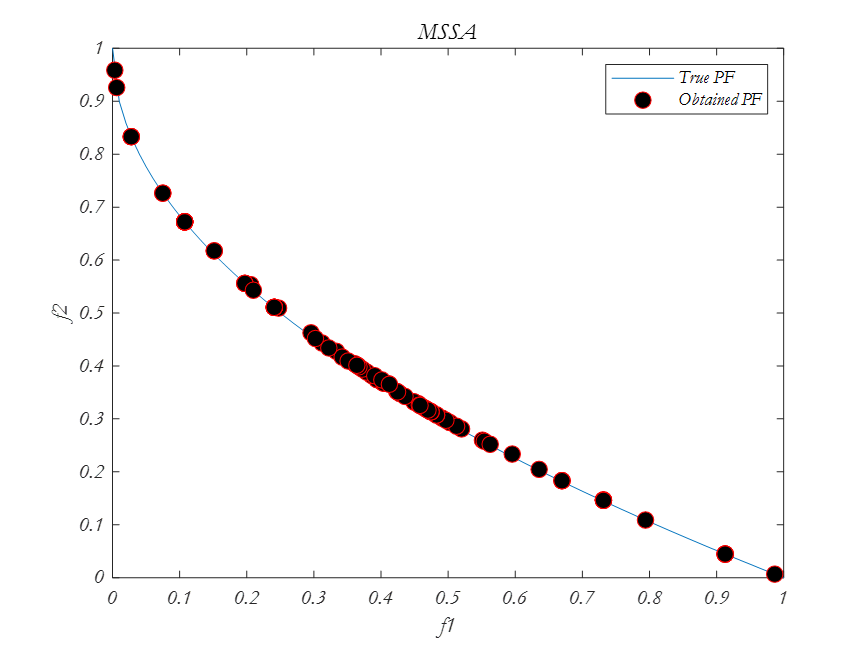
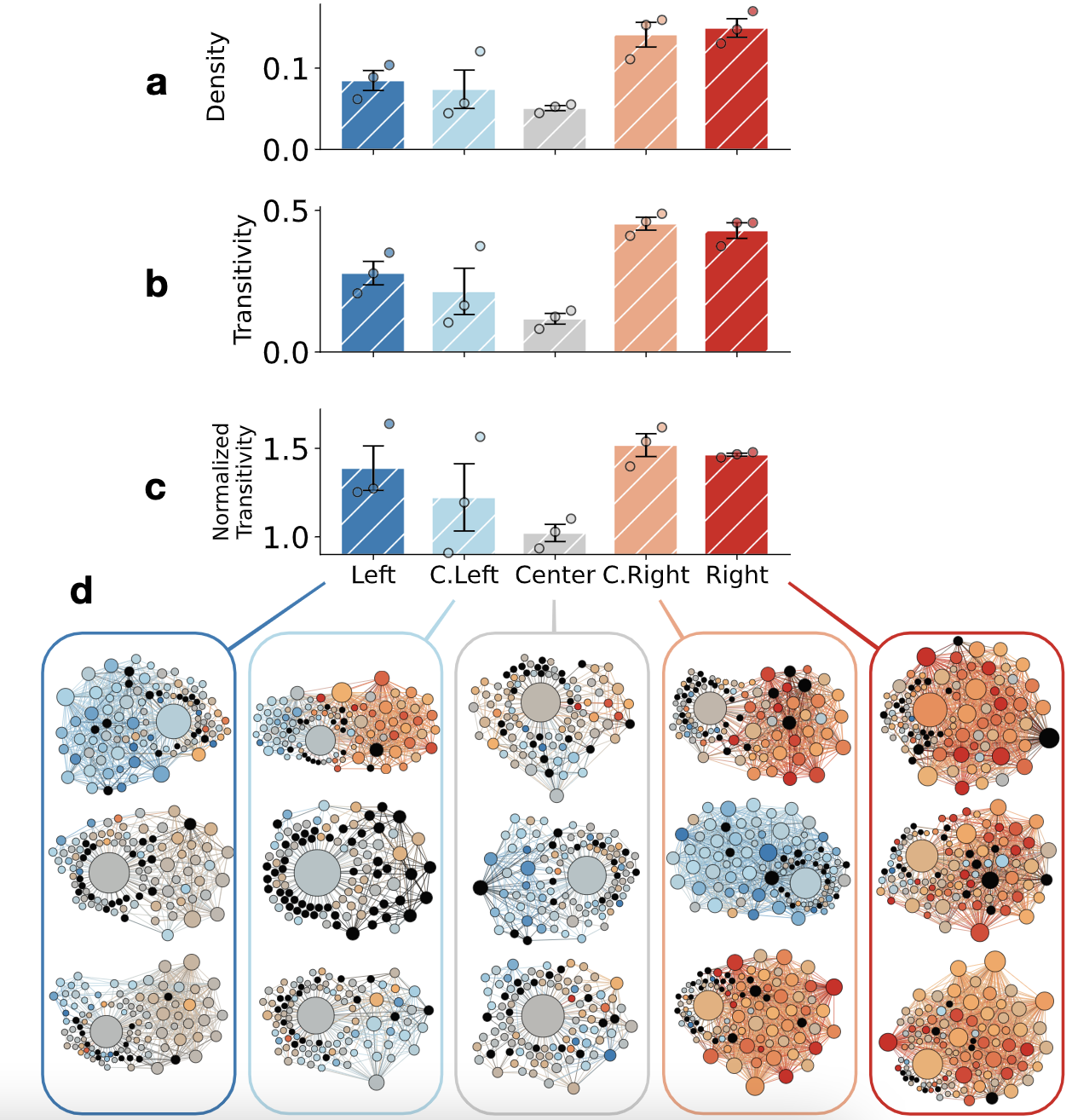
多目标优化算法之樽海鞘算法(MSSA)
樽海鞘算法的主要灵感是樽海鞘在海洋中航行和觅食时的群聚行为。相关文献表示,多目标优化之樽海鞘算法的结果表明,该算法可以逼近帕雷托最优解,收敛性和覆盖率高。 通过给SSA算法配备一个食物来源库来解决第一个问题。该存储库维护了到目前为…...
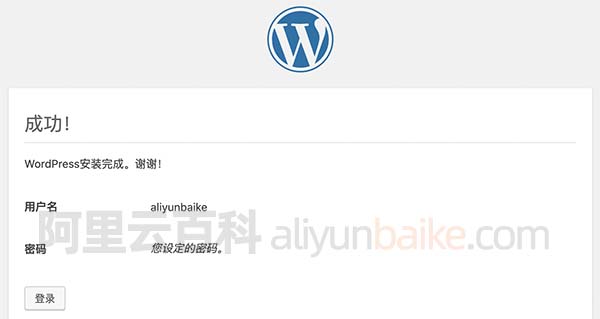
阿里云轻量应用服务器使用教程_创建配置_远程连接_网站上线
阿里云轻量应用服务器怎么使用?阿里云百科分享轻量应用服务器从选择创建、配置建站环境、轻量服务器应用服务器远程连接、开端口到网站上线全流程: 目录 阿里云轻量应用服务器使用教程 步骤一:购买一台轻量应用服务器 步骤二:…...

自监督学习的概念
Self-Supervised Learning (SSL)的主要思想是解决先验任务来学习特征提取器,在不使用标签的情况下生成有用的表示。 这里先验任务是指, 先使用原始数据和特征提取器来提取出 数据的有效表示. 对比方法(即对比学习, Contrastiv…...
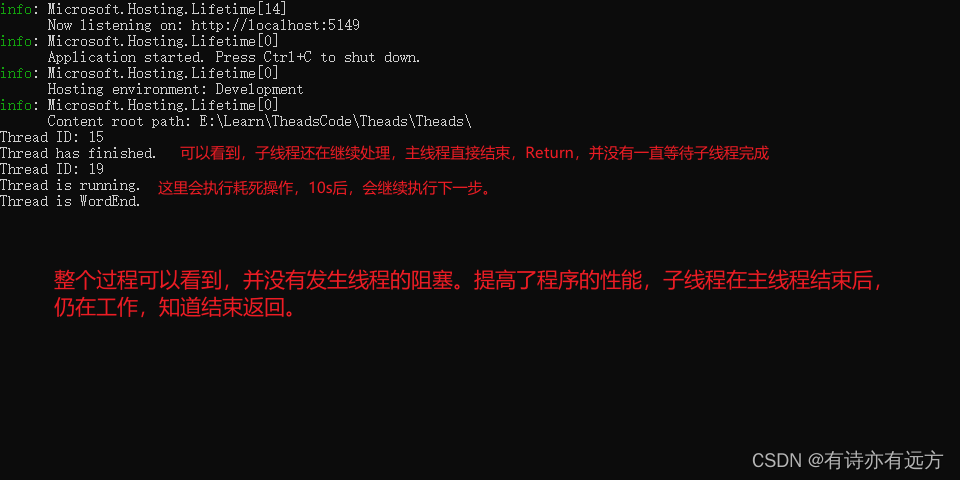
C#多线程开发详解
C#多线程开发详解 持续更新中。。。。。一、为什么要使用多线程开发1.提高性能2.响应性3.资源利用4.任务分解5.并行计算6.实时处理 二、多线程开发缺点1.竞态条件2.死锁和饥饿3.调试复杂性4.上下文切换开销5.线程安全性 三、多线程开发涉及的相关概念常用概念(1)lock(2)查看当前…...

Linux 基础篇(六)sudo和添加信任用户
一、sudo 1.是什么? 给被信任的普通用户授权,让被信任的普通用户能执行root用户才能执行的命令的一个命令。 2.为什么? 很多时候我们要在被信任的普通用户下执行一些root用户才能执行的命令,如 yum… 所以需要有一个命令能给普通用…...

15分钟掌握TEKLauncher:方舟生存进化MOD管理与服务器部署终极指南
15分钟掌握TEKLauncher:方舟生存进化MOD管理与服务器部署终极指南 【免费下载链接】TEKLauncher Launcher for ARK: Survival Evolved 项目地址: https://gitcode.com/gh_mirrors/te/TEKLauncher TEKLauncher是一款专为《方舟:生存进化》设计的智…...

【多模态大模型推理加速终极指南】:20年AI基础设施专家亲授7大实战优化路径,90%团队尚未掌握的低延迟部署密钥
第一章:多模态大模型推理加速技术对比 2026奇点智能技术大会(https://ml-summit.org) 多模态大模型(如LLaVA、Qwen-VL、Fuyu-8B)在视觉-语言联合推理中面临显著的计算瓶颈,尤其在实时交互场景下,推理延迟与显存占用成…...

Windows11轻松设置:极简设计理念,小白也能轻松驾驭
在软件设计领域,真正的功力往往体现在如何让复杂的功能变得简单易用。 Windows11轻松设置软件正是这样一款产品,它将复杂的系统配置操作简化为直观的点击。 无论是初次接触的电脑小白还是经验丰富的专业用户,都能快速上手并从中受益。 软件…...

小白程序员必备:收藏!从运维到网络安全,开启高薪新篇章
小白程序员必备:收藏!从运维到网络安全,开启高薪新篇章 运维是确保IT系统高效稳定运行的核心岗位,工作内容包括系统监控、故障排查、性能优化、安全防护等。随着网络安全人才缺口达70万,运维转型网络安全成为高薪新趋势…...

Qwen3-VL-8B Web界面交互效果集:消息流加载动画与断线重连体验
Qwen3-VL-8B Web界面交互效果集:消息流加载动画与断线重连体验 1. 项目概述 Qwen3-VL-8B AI聊天系统是一个完整的Web端智能对话解决方案,基于通义千问大语言模型构建。系统采用现代化的前后端分离架构,为用户提供流畅、稳定的聊天体验。 这…...

医学影像AI新突破:拆解MedSegDiff-V2如何用‘频域魔法’解决分割边界模糊难题
医学影像AI新突破:拆解MedSegDiff-V2如何用‘频域魔法’解决分割边界模糊难题 当医生面对一张模糊的脑部MRI影像时,肿瘤与正常组织的分界线往往如同雾里看花。这种边界模糊问题长期困扰着医学影像分析领域,尤其在器官移植规划、肿瘤体积测算等…...

Rust194发布-6倍编译提速与RISC-V嵌入式实战
Rust 1.94 发布:6 倍编译提速与 29 项 RISC-V 特性稳定,嵌入式开发者的春天来了Rust 1.94 于2026年4月正式发布,代号"(无特殊代号)"。本次更新最大的亮点是编译速度提升高达 6 倍,以及 29 项 RIS…...
)
SSH连接报错?手把手教你用ssh-keygen清理known_hosts文件(附常见场景解析)
SSH密钥验证失败?深度解析known_hosts文件管理与安全实践 当你兴冲冲地准备通过SSH连接远程服务器部署最新代码时,终端突然弹出一串红色警告:"WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED!"。这种场景对于开发者和运维人员来…...

百度网盘直链解析实战指南:破解企业文件传输速度瓶颈的完整解决方案
百度网盘直链解析实战指南:破解企业文件传输速度瓶颈的完整解决方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 在数字化办公时代,企业文件传输效率…...

Meta:AIRA2系统突破AI科研Agent瓶颈
📖标题:AIRA_2: Overcoming Bottlenecks in AI Research Agents 🌐来源:arXiv, 2603.26499v1 🌟摘要 现有的研究已经确定了人工智能研究代理中的三个结构性性能瓶颈:(1)同步单GPU执行…...