8.1.tensorRT高级(3)封装系列-模型编译过程封装,简化模型编译代码
目录
- 前言
- 1. 模型编译过程封装
- 2. 问答环节
- 总结
前言
杜老师推出的 tensorRT从零起步高性能部署 课程,之前有看过一遍,但是没有做笔记,很多东西也忘了。这次重新撸一遍,顺便记记笔记。
本次课程学习 tensorRT 高级-模型编译过程封装,简化模型编译代码
课程大纲可看下面的思维导图

1. 模型编译过程封装
我们来开始学习 tensorRT 的封装
1. 对 tensorRT 的封装,更像是对推理引擎的封装
2. 封装的意义在于对技术的标准化、工具化,能够使得使用时更加便利,效率更高,定制更多的默认行为
3. 封装推理引擎的思想,还可以应用到更多其它地方,嵌入式等等。由于大多推理引擎提供的默认方式不够友好,对其进行包装,能够很好的使得自己的代码具有复用性,一套代码多处用
4. 还可以实现同样的封装,通过简单的配置,切换不同的推理后端,这都取决于需求
5. 我们的唯一目的就是让工作更简单,让代码复用性更强,让技术可以沉淀
这节课我们主要学习对 builder 进行封装,使得编译的接口足够简单
我们来看代码,首先是关于 cuda 小工具的封装,代码如下:
cuda-tools.hpp
#ifndef CUDA_TOOLS_HPP
#define CUDA_TOOLS_HPP#include <cuda_runtime.h>
#include <string>#define checkRuntime(call) CUDATools::check_runtime(call, #call, __LINE__, __FILE__)#define checkKernel(...) \__VA_ARGS__; \do{cudaError_t cudaStatus = cudaPeekAtLastError(); \if (cudaStatus != cudaSuccess){ \INFOE("launch failed: %s", cudaGetErrorString(cudaStatus)); \}} while(0);namespace CUDATools{bool check_runtime(cudaError_t e, const char* call, int iLine, const char *szFile);bool check_device_id(int device_id);int current_device_id();std::string device_description();// 自动切换当前的deviceid,并在析构的时候切换回去class AutoDevice{public:AutoDevice(int device_id = 0);virtual ~AutoDevice();private:int old_ = -1;};
}#endif // CUDA_TOOLS_HPP
cuda-tools.cpp
/** 系统关于CUDA的功能函数*/#include "cuda-tools.hpp"
#include <stdio.h>
#include <stdarg.h>
#include <string>
#include <simple-logger.hpp>using namespace std;namespace CUDATools{bool check_runtime(cudaError_t e, const char* call, int line, const char *file){if (e != cudaSuccess) {INFOE("CUDA Runtime error %s # %s, code = %s [ %d ] in file %s:%d", call, cudaGetErrorString(e), cudaGetErrorName(e), e, file, line);return false;}return true;}bool check_device_id(int device_id){int device_count = -1;checkRuntime(cudaGetDeviceCount(&device_count));if(device_id < 0 || device_id >= device_count){INFOE("Invalid device id: %d, count = %d", device_id, device_count);return false;}return true;}static std::string format(const char* fmt, ...) {va_list vl;va_start(vl, fmt);char buffer[2048];vsnprintf(buffer, sizeof(buffer), fmt, vl);return buffer;}string device_description(){cudaDeviceProp prop;size_t free_mem, total_mem;int device_id = 0;checkRuntime(cudaGetDevice(&device_id));checkRuntime(cudaGetDeviceProperties(&prop, device_id));checkRuntime(cudaMemGetInfo(&free_mem, &total_mem));return format("[ID %d]<%s>[arch %d.%d][GMEM %.2f GB/%.2f GB]",device_id, prop.name, prop.major, prop.minor, free_mem / 1024.0f / 1024.0f / 1024.0f,total_mem / 1024.0f / 1024.0f / 1024.0f);}int current_device_id(){int device_id = 0;checkRuntime(cudaGetDevice(&device_id));return device_id;}AutoDevice::AutoDevice(int device_id){cudaGetDevice(&old_);checkRuntime(cudaSetDevice(device_id));}AutoDevice::~AutoDevice(){checkRuntime(cudaSetDevice(old_));}
}
CUDA 工具集的封装,首先是两个宏定义:
checkRuntime(call): 这是一个用于检查 CUDA 运行时函数调用的宏。它会记录函数的名称、文件名和行号,并在发生错误时输出错误信息。
checkKernel(…): 这个宏用于检查 CUDA 核函数的执行。它首先执行核函数,然后检查其执行是否有任何错误,如果有,它将输出错误信息。
命名空间 CUDATools 中实现了一些函数和类:
- check_runtime:这个函数检查 CUDA 运行时错误,并打印详细的错误信息,包括文件名、行号、错误代码和错误字符串
- check_device_id: 这个函数检查给定的设备 ID 是否有效,即是否在有效的范围内
- current_device_id:这个函数返回当前 CUDA 设备的 ID
- AutoDevice 类:这是一个 RAII 风格的类,用于自动设置和恢复 CUDA 设备。当你创建这个类的对象时,它会设置指定的设备 ID(默认为0),并在其析构函数中恢复原始的设备 ID
我们再来看下 logger 日志的封装,代码如下:
simple-logger.hpp
#ifndef SIMPLE_LOGGER_HPP
#define SIMPLE_LOGGER_HPP#include <stdio.h>#define INFOD(...) SimpleLogger::__log_func(__FILE__, __LINE__, SimpleLogger::LogLevel::Debug, __VA_ARGS__)
#define INFOV(...) SimpleLogger::__log_func(__FILE__, __LINE__, SimpleLogger::LogLevel::Verbose, __VA_ARGS__)
#define INFO(...) SimpleLogger::__log_func(__FILE__, __LINE__, SimpleLogger::LogLevel::Info, __VA_ARGS__)
#define INFOW(...) SimpleLogger::__log_func(__FILE__, __LINE__, SimpleLogger::LogLevel::Warning, __VA_ARGS__)
#define INFOE(...) SimpleLogger::__log_func(__FILE__, __LINE__, SimpleLogger::LogLevel::Error, __VA_ARGS__)
#define INFOF(...) SimpleLogger::__log_func(__FILE__, __LINE__, SimpleLogger::LogLevel::Fatal, __VA_ARGS__)namespace SimpleLogger{enum class LogLevel : int{Debug = 5,Verbose = 4,Info = 3,Warning = 2,Error = 1,Fatal = 0};void set_log_level(LogLevel level);LogLevel get_log_level();void __log_func(const char* file, int line, LogLevel level, const char* fmt, ...);}; // SimpleLogger#endif // SIMPLE_LOGGER_HPP
simple-logger.cpp
#include "simple-logger.hpp"
#include <string>
#include <stdarg.h>using namespace std;namespace SimpleLogger{static LogLevel g_level = LogLevel::Info;const char* level_string(LogLevel level){switch (level){case LogLevel::Debug: return "debug";case LogLevel::Verbose: return "verbo";case LogLevel::Info: return "info";case LogLevel::Warning: return "warn";case LogLevel::Error: return "error";case LogLevel::Fatal: return "fatal";default: return "unknow";}}void set_log_level(LogLevel level){g_level = level;}LogLevel get_log_level(){return g_level;}string file_name(const string& path, bool include_suffix){if (path.empty()) return "";int p = path.rfind('/');p += 1;//include suffixif (include_suffix)return path.substr(p);int u = path.rfind('.');if (u == -1)return path.substr(p);if (u <= p) u = path.size();return path.substr(p, u - p);}string time_now(){char time_string[20];time_t timep; time(&timep); tm& t = *(tm*)localtime(&timep);sprintf(time_string, "%04d-%02d-%02d %02d:%02d:%02d", t.tm_year + 1900, t.tm_mon + 1, t.tm_mday, t.tm_hour, t.tm_min, t.tm_sec);return time_string;}void __log_func(const char* file, int line, LogLevel level, const char* fmt, ...){if(level > g_level) return;va_list vl;va_start(vl, fmt);char buffer[2048];auto now = time_now();string filename = file_name(file, true);int n = snprintf(buffer, sizeof(buffer), "[%s]", now.c_str());if (level == LogLevel::Fatal or level == LogLevel::Error) {n += snprintf(buffer + n, sizeof(buffer) - n, "[\033[31m%s\033[0m]", level_string(level));}else if (level == LogLevel::Warning) {n += snprintf(buffer + n, sizeof(buffer) - n, "[\033[33m%s\033[0m]", level_string(level));}else if (level == LogLevel::Info) {n += snprintf(buffer + n, sizeof(buffer) - n, "[\033[35m%s\033[0m]", level_string(level));}else if (level == LogLevel::Verbose) {n += snprintf(buffer + n, sizeof(buffer) - n, "[\033[34m%s\033[0m]", level_string(level));}else {n += snprintf(buffer + n, sizeof(buffer) - n, "[%s]", level_string(level));}n += snprintf(buffer + n, sizeof(buffer) - n, "[%s:%d]:", filename.c_str(), line);vsnprintf(buffer + n, sizeof(buffer) - n, fmt, vl);fprintf(stdout, "%s\n", buffer);if(level == LogLevel::Fatal || level == LogLevel::Error){fflush(stdout);abort();}}
};
上面是一个简单的日志工具封装。通过定义不同的宏,它为我们提供了方便的日志记录功能
- 我们是通过使用一些宏 (INFOD, INFOV, INFO, INFOW, INFOE, INFOF),开发者可以轻松地在代码中添加日志消息。
- 每个宏都将当前的文件名 (__FILE__)、行号 (__LINE__)、日志级别以及日志消息传递给 __log_func 函数。
- __log_func 是执行实际日志记录的函数。它使用变参列表 (va_list) 和 vsnprintf 函数格式化日志消息,根据日志级别,它为日志消息添加颜色
这个日志工具提供了一个简单而有效的方法来在应用程序中添加日志记录功能。其设计允许开发者轻松地添加、修改和控制日志消息。对于使用者来说找 bug 也好找,对于大型项目来讲 logger 这种基本组件肯定是要有的,不然到时候出了问题调试都操心得很
我们来看下核心的 tensorRT 模型编译的封装部分,代码如下:
trt_builder.hpp
#ifndef TRT_BUILDER_HPP
#define TRT_BUILDER_HPP#include <string>
#include <vector>
#include <functional>namespace TRT {enum class Mode : int {FP32,FP16};const char* mode_string(Mode type);bool compile(Mode mode,unsigned int maxBatchSize,const std::string& source,const std::string& saveto,const size_t maxWorkspaceSize = 1ul << 30 // 1ul << 30 = 1GB);
};#endif //TRT_BUILDER_HPP
trt_builder.cpp
#include "trt_builder.hpp"#include <cuda_runtime_api.h>
#include <cublas_v2.h>
#include <NvInfer.h>
#include <NvInferPlugin.h>
//#include <NvCaffeParser.h>
#include <onnx-tensorrt/NvOnnxParser.h>
#include <string>
#include <vector>
#include <iostream>
#include <memory>
#include <sstream>
#include <assert.h>
#include <stdarg.h>
#include "cuda-tools.hpp"
#include "simple-logger.hpp"
#include <chrono>using namespace nvinfer1;
using namespace std;
//using namespace nvcaffeparser1 ;class Logger : public ILogger {
public:virtual void log(Severity severity, const char* msg) noexcept override {if (severity == Severity::kINTERNAL_ERROR) {INFOE("NVInfer INTERNAL_ERROR: %s", msg);abort();}else if (severity == Severity::kERROR) {INFOE("NVInfer: %s", msg);}else if (severity == Severity::kWARNING) {INFOW("NVInfer: %s", msg);}else if (severity == Severity::kINFO) {INFOD("NVInfer: %s", msg);}else {INFOD("%s", msg);}}
};static Logger gLogger;namespace TRT {static string join_dims(const vector<int>& dims){stringstream output;char buf[64];const char* fmts[] = {"%d", " x %d"};for(int i = 0; i < dims.size(); ++i){snprintf(buf, sizeof(buf), fmts[i != 0], dims[i]);output << buf;}return output.str();}bool save_file(const string& file, const void* data, size_t length){FILE* f = fopen(file.c_str(), "wb");if (!f) return false;if (data && length > 0){if (fwrite(data, 1, length, f) not_eq length){fclose(f);return false;}}fclose(f);return true;}static string format(const char* fmt, ...) {va_list vl;va_start(vl, fmt);char buffer[10000];vsprintf(buffer, fmt, vl);return buffer;}static string dims_str(const nvinfer1::Dims& dims){return join_dims(vector<int>(dims.d, dims.d + dims.nbDims));}static const char* padding_mode_name(nvinfer1::PaddingMode mode){switch(mode){case nvinfer1::PaddingMode::kEXPLICIT_ROUND_DOWN: return "explicit round down";case nvinfer1::PaddingMode::kEXPLICIT_ROUND_UP: return "explicit round up";case nvinfer1::PaddingMode::kSAME_UPPER: return "same supper";case nvinfer1::PaddingMode::kSAME_LOWER: return "same lower";case nvinfer1::PaddingMode::kCAFFE_ROUND_DOWN: return "caffe round down";case nvinfer1::PaddingMode::kCAFFE_ROUND_UP: return "caffe round up";}return "Unknow padding mode";}static const char* pooling_type_name(nvinfer1::PoolingType type){switch(type){case nvinfer1::PoolingType::kMAX: return "MaxPooling";case nvinfer1::PoolingType::kAVERAGE: return "AveragePooling";case nvinfer1::PoolingType::kMAX_AVERAGE_BLEND: return "MaxAverageBlendPooling";}return "Unknow pooling type";}static const char* activation_type_name(nvinfer1::ActivationType activation_type){switch(activation_type){case nvinfer1::ActivationType::kRELU: return "ReLU";case nvinfer1::ActivationType::kSIGMOID: return "Sigmoid";case nvinfer1::ActivationType::kTANH: return "TanH";case nvinfer1::ActivationType::kLEAKY_RELU: return "LeakyRelu";case nvinfer1::ActivationType::kELU: return "Elu";case nvinfer1::ActivationType::kSELU: return "Selu";case nvinfer1::ActivationType::kSOFTSIGN: return "Softsign";case nvinfer1::ActivationType::kSOFTPLUS: return "Parametric softplus";case nvinfer1::ActivationType::kCLIP: return "Clip";case nvinfer1::ActivationType::kHARD_SIGMOID: return "Hard sigmoid";case nvinfer1::ActivationType::kSCALED_TANH: return "Scaled tanh";case nvinfer1::ActivationType::kTHRESHOLDED_RELU: return "Thresholded ReLU";}return "Unknow activation type";}static string layer_type_name(nvinfer1::ILayer* layer){switch(layer->getType()){case nvinfer1::LayerType::kCONVOLUTION: return "Convolution";case nvinfer1::LayerType::kFULLY_CONNECTED: return "Fully connected";case nvinfer1::LayerType::kACTIVATION: {nvinfer1::IActivationLayer* act = (nvinfer1::IActivationLayer*)layer;auto type = act->getActivationType();return activation_type_name(type);}case nvinfer1::LayerType::kPOOLING: {nvinfer1::IPoolingLayer* pool = (nvinfer1::IPoolingLayer*)layer;return pooling_type_name(pool->getPoolingType());}case nvinfer1::LayerType::kLRN: return "LRN";case nvinfer1::LayerType::kSCALE: return "Scale";case nvinfer1::LayerType::kSOFTMAX: return "SoftMax";case nvinfer1::LayerType::kDECONVOLUTION: return "Deconvolution";case nvinfer1::LayerType::kCONCATENATION: return "Concatenation";case nvinfer1::LayerType::kELEMENTWISE: return "Elementwise";case nvinfer1::LayerType::kPLUGIN: return "Plugin";case nvinfer1::LayerType::kUNARY: return "UnaryOp operation";case nvinfer1::LayerType::kPADDING: return "Padding";case nvinfer1::LayerType::kSHUFFLE: return "Shuffle";case nvinfer1::LayerType::kREDUCE: return "Reduce";case nvinfer1::LayerType::kTOPK: return "TopK";case nvinfer1::LayerType::kGATHER: return "Gather";case nvinfer1::LayerType::kMATRIX_MULTIPLY: return "Matrix multiply";case nvinfer1::LayerType::kRAGGED_SOFTMAX: return "Ragged softmax";case nvinfer1::LayerType::kCONSTANT: return "Constant";case nvinfer1::LayerType::kRNN_V2: return "RNNv2";case nvinfer1::LayerType::kIDENTITY: return "Identity";case nvinfer1::LayerType::kPLUGIN_V2: return "PluginV2";case nvinfer1::LayerType::kSLICE: return "Slice";case nvinfer1::LayerType::kSHAPE: return "Shape";case nvinfer1::LayerType::kPARAMETRIC_RELU: return "Parametric ReLU";case nvinfer1::LayerType::kRESIZE: return "Resize";}return "Unknow layer type";}static string layer_descript(nvinfer1::ILayer* layer){switch(layer->getType()){case nvinfer1::LayerType::kCONVOLUTION: {nvinfer1::IConvolutionLayer* conv = (nvinfer1::IConvolutionLayer*)layer;return format("channel: %d, kernel: %s, padding: %s, stride: %s, dilation: %s, group: %d", conv->getNbOutputMaps(),dims_str(conv->getKernelSizeNd()).c_str(),dims_str(conv->getPaddingNd()).c_str(),dims_str(conv->getStrideNd()).c_str(),dims_str(conv->getDilationNd()).c_str(),conv->getNbGroups());}case nvinfer1::LayerType::kFULLY_CONNECTED:{nvinfer1::IFullyConnectedLayer* fully = (nvinfer1::IFullyConnectedLayer*)layer;return format("output channels: %d", fully->getNbOutputChannels());}case nvinfer1::LayerType::kPOOLING: {nvinfer1::IPoolingLayer* pool = (nvinfer1::IPoolingLayer*)layer;return format("window: %s, padding: %s",dims_str(pool->getWindowSizeNd()).c_str(),dims_str(pool->getPaddingNd()).c_str()); }case nvinfer1::LayerType::kDECONVOLUTION:{nvinfer1::IDeconvolutionLayer* conv = (nvinfer1::IDeconvolutionLayer*)layer;return format("channel: %d, kernel: %s, padding: %s, stride: %s, group: %d", conv->getNbOutputMaps(),dims_str(conv->getKernelSizeNd()).c_str(),dims_str(conv->getPaddingNd()).c_str(),dims_str(conv->getStrideNd()).c_str(),conv->getNbGroups());}case nvinfer1::LayerType::kACTIVATION:case nvinfer1::LayerType::kPLUGIN:case nvinfer1::LayerType::kLRN:case nvinfer1::LayerType::kSCALE:case nvinfer1::LayerType::kSOFTMAX:case nvinfer1::LayerType::kCONCATENATION:case nvinfer1::LayerType::kELEMENTWISE:case nvinfer1::LayerType::kUNARY:case nvinfer1::LayerType::kPADDING:case nvinfer1::LayerType::kSHUFFLE:case nvinfer1::LayerType::kREDUCE:case nvinfer1::LayerType::kTOPK:case nvinfer1::LayerType::kGATHER:case nvinfer1::LayerType::kMATRIX_MULTIPLY:case nvinfer1::LayerType::kRAGGED_SOFTMAX:case nvinfer1::LayerType::kCONSTANT:case nvinfer1::LayerType::kRNN_V2:case nvinfer1::LayerType::kIDENTITY:case nvinfer1::LayerType::kPLUGIN_V2:case nvinfer1::LayerType::kSLICE:case nvinfer1::LayerType::kSHAPE:case nvinfer1::LayerType::kPARAMETRIC_RELU:case nvinfer1::LayerType::kRESIZE:return "";}return "Unknow layer type";}static bool layer_has_input_tensor(nvinfer1::ILayer* layer){int num_input = layer->getNbInputs();for(int i = 0; i < num_input; ++i){auto input = layer->getInput(i);if(input == nullptr)continue;if(input->isNetworkInput())return true;}return false;}static bool layer_has_output_tensor(nvinfer1::ILayer* layer){int num_output = layer->getNbOutputs();for(int i = 0; i < num_output; ++i){auto output = layer->getOutput(i);if(output == nullptr)continue;if(output->isNetworkOutput())return true;}return false;} template<typename _T>shared_ptr<_T> make_nvshared(_T* ptr){return shared_ptr<_T>(ptr, [](_T* p){p->destroy();});}const char* mode_string(Mode type) {switch (type) {case Mode::FP32:return "FP32";case Mode::FP16:return "FP16";default:return "UnknowTRTMode";}}static nvinfer1::Dims convert_to_trt_dims(const std::vector<int>& dims){nvinfer1::Dims output{0};if(dims.size() > nvinfer1::Dims::MAX_DIMS){INFOE("convert failed, dims.size[%d] > MAX_DIMS[%d]", dims.size(), nvinfer1::Dims::MAX_DIMS);return output;}if(!dims.empty()){output.nbDims = dims.size();memcpy(output.d, dims.data(), dims.size() * sizeof(int));}return output;}static string align_blank(const string& input, int align_size, char blank = ' '){if(input.size() >= align_size) return input;string output = input;for(int i = 0; i < align_size - input.size(); ++i)output.push_back(blank);return output;}static long long timestamp_now() {return chrono::duration_cast<chrono::milliseconds>(chrono::system_clock::now().time_since_epoch()).count();}static double timestamp_now_float() {return chrono::duration_cast<chrono::microseconds>(chrono::system_clock::now().time_since_epoch()).count() / 1000.0;}bool compile(Mode mode,unsigned int maxBatchSize,const string& source,const string& saveto,const size_t maxWorkspaceSize) {INFO("Compile %s %s.", mode_string(mode), source.c_str());auto builder = make_nvshared(createInferBuilder(gLogger));if (builder == nullptr) {INFOE("Can not create builder.");return false;}auto config = make_nvshared(builder->createBuilderConfig());if (mode == Mode::FP16) {if (!builder->platformHasFastFp16()) {INFOW("Platform not have fast fp16 support");}config->setFlag(BuilderFlag::kFP16);}shared_ptr<INetworkDefinition> network;//shared_ptr<ICaffeParser> caffeParser;const auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);network = make_nvshared(builder->createNetworkV2(explicitBatch));shared_ptr<nvonnxparser::IParser> onnxParser = make_nvshared(nvonnxparser::createParser(*network, gLogger));if (onnxParser == nullptr) {INFOE("Can not create parser.");return false;}if (!onnxParser->parseFromFile(source.c_str(), 1)) {INFOE("Can not parse OnnX file: %s", source.c_str());return false;}auto inputTensor = network->getInput(0);auto inputDims = inputTensor->getDimensions();INFO("Input shape is %s", join_dims(vector<int>(inputDims.d, inputDims.d + inputDims.nbDims)).c_str());INFO("Set max batch size = %d", maxBatchSize);INFO("Set max workspace size = %.2f MB", maxWorkspaceSize / 1024.0f / 1024.0f);INFO("Base device: %s", CUDATools::device_description().c_str());int net_num_input = network->getNbInputs();INFO("Network has %d inputs:", net_num_input);vector<string> input_names(net_num_input);for(int i = 0; i < net_num_input; ++i){auto tensor = network->getInput(i);auto dims = tensor->getDimensions();auto dims_str = join_dims(vector<int>(dims.d, dims.d+dims.nbDims));INFO(" %d.[%s] shape is %s", i, tensor->getName(), dims_str.c_str());input_names[i] = tensor->getName();}int net_num_output = network->getNbOutputs();INFO("Network has %d outputs:", net_num_output);for(int i = 0; i < net_num_output; ++i){auto tensor = network->getOutput(i);auto dims = tensor->getDimensions();auto dims_str = join_dims(vector<int>(dims.d, dims.d+dims.nbDims));INFO(" %d.[%s] shape is %s", i, tensor->getName(), dims_str.c_str());}int net_num_layers = network->getNbLayers();INFO("Network has %d layers:", net_num_layers);for(int i = 0; i < net_num_layers; ++i){auto layer = network->getLayer(i);auto name = layer->getName();auto type_str = layer_type_name(layer);auto input0 = layer->getInput(0);if(input0 == nullptr) continue;auto output0 = layer->getOutput(0);auto input_dims = input0->getDimensions();auto output_dims = output0->getDimensions();bool has_input = layer_has_input_tensor(layer);bool has_output = layer_has_output_tensor(layer);auto descript = layer_descript(layer);type_str = align_blank(type_str, 18);auto input_dims_str = align_blank(dims_str(input_dims), 18);auto output_dims_str = align_blank(dims_str(output_dims), 18);auto number_str = align_blank(format("%d.", i), 4);const char* token = " ";if(has_input)token = " >>> ";else if(has_output)token = " *** ";INFOV("%s%s%s %s-> %s%s", token, number_str.c_str(), type_str.c_str(),input_dims_str.c_str(),output_dims_str.c_str(),descript.c_str());}builder->setMaxBatchSize(maxBatchSize);config->setMaxWorkspaceSize(maxWorkspaceSize);auto profile = builder->createOptimizationProfile();for(int i = 0; i < net_num_input; ++i){auto input = network->getInput(i);auto input_dims = input->getDimensions();input_dims.d[0] = 1;profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMIN, input_dims);profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kOPT, input_dims);input_dims.d[0] = maxBatchSize;profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMAX, input_dims);}// not need// for(int i = 0; i < net_num_output; ++i){// auto output = network->getOutput(i);// auto output_dims = output->getDimensions();// output_dims.d[0] = 1;// profile->setDimensions(output->getName(), nvinfer1::OptProfileSelector::kMIN, output_dims);// profile->setDimensions(output->getName(), nvinfer1::OptProfileSelector::kOPT, output_dims);// output_dims.d[0] = maxBatchSize;// profile->setDimensions(output->getName(), nvinfer1::OptProfileSelector::kMAX, output_dims);// }config->addOptimizationProfile(profile);// error on jetson// auto timing_cache = shared_ptr<nvinfer1::ITimingCache>(config->createTimingCache(nullptr, 0), [](nvinfer1::ITimingCache* ptr){ptr->reset();});// config->setTimingCache(*timing_cache, false);// config->setFlag(BuilderFlag::kGPU_FALLBACK);// config->setDefaultDeviceType(DeviceType::kDLA);// config->setDLACore(0);INFO("Building engine...");auto time_start = timestamp_now();auto engine = make_nvshared(builder->buildEngineWithConfig(*network, *config));if (engine == nullptr) {INFOE("engine is nullptr");return false;}INFO("Build done %lld ms !", timestamp_now() - time_start);// serialize the engine, then close everything downauto seridata = make_nvshared(engine->serialize());return save_file(saveto, seridata->data(), seridata->size());}
}; //namespace TRTBuilder
模型编译封装内容主要可分为以下几部分:(from chatGPT)
1. 日志处理:
- 一个自定义的 Logger 类,该类继承自 ILogger,用于处理 TensorRT 的日志消息。
- 根据消息的严重性,它将打印不同类型的日志消息。
2. 实用函数:
- join_dims:格式化张量的维度为字符串。
- save_file:将给定数据保存到文件。
- format:一个简单的字符串格式化函数。
- dims_str:将 nvinfer1::Dims 对象转换为字符串表示。
3. compile 编译函数
4. 其他功能:文件中还包含一些其他辅助功能和工具,如时间戳获取、CUDA错误处理等。
5. 错误处理:在整个编译过程中,都有对可能出现的错误的检查,如解析错误、文件写入错误等,并在出错时返回相应的错误信息。
上述封装提供了一个从 ONNX 模型到优化后的 TensorRT 推理引擎的完整流程。其主要目的是简化 TensorRT 的使用,让用户只需调用一个函数即可完成模型的导入、优化和序列化。
我们来重点关注 compile 函数中的内容,主要有以下几部分:
1. TensorRT 构建器初始化
函数首先创建一个 TensorRT 构建器实例,并为其设置日志。这个构建器是 TensorRT 框架中用来创建推理引擎的主要组件。
auto builder = make_nvshared(nvinfer1::createInferBuilder(gLogger));
2. 配置设置
设置 TensorRT 构建器的最大批处理大小和最大工作空间大小。这些参数对于控制推理引擎的资源使用和性能至关重要。
builder->setMaxBatchSize(maxBatchSize);
builder->setMaxWorkspaceSize(maxWorkspaceSize);
3. 精度模式
根据传入的模式(FP16或FP32)来设置构建器的精度模式。如果选择 FP16 模式,构建器会使用半精度浮点数进行计算,这可能会提高性能但牺牲一些精度。
if (mode == Mode::FP16) {builder->setFp16Mode(true);
}
4. 导入ONNX模型
使用 TensorRT 的 ONNX 解析器导入模型。这里从文件中读取 ONNX 模型并将其解析成 TensorRT 可以理解的格式。
auto parser = make_nvshared(nvonnxparser::createParser(*network, gLogger));
if (!parser->parseFromFile(source.c_str(), static_cast<int>(ILogger::Severity::kWARNING))) {return false;
}
5. 优化配置文件
为网络的输入创建优化配置文件。这些配置文件定义了输入的不同大小,从而使 TensorRT 能够为不同大小的输入优化引擎。
auto profile = builder->createOptimizationProfile();
for (int i = 0; i < net_num_input; ++i) {auto input = network->getInput(i);auto input_dims = input->getDimensions();input_dims.d[0] = 1;profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMIN, input_dims);profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kOPT, input_dims);input_dims.d[0] = maxBatchSize;profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMAX, input_dims);
}
config->addOptimizationProfile(profile);
6. 构建引擎
使用前面的配置和网络信息构建 TensorRT 引擎。这是一个耗时的过程,因为 TensorRT 会尝试多种优化技术来提高模型的推理速度。
auto engine = make_nvshared(builder->buildEngineWithConfig(*network, *config));
7. 序列化引擎
最后,构建好的引擎被序列化,这样就可以在没有原始模型和配置的情况下重新加载它。序列化后的引擎被保存到文件中。
auto seridata = make_nvshared(engine->serialize());
return save_file(saveto, seridata->data(), seridata->size());
这个模型编译的封装代码涵盖了从原始 ONNX 模型到优化后的 TensorRT 推理引擎的整个过程。其简化了 TensorRT 模型编译过程,让用户只需要调用一个函数即可完成模型的编译工作。
二话不说先去执行一下,执行效果如下所示:

可以看到它会打印一个时间,然后是日志级别,然后是文件名和行号,这是 logger 起到的作用
在编译过程我们也可以获取到它的详细信息,带网络结构的详细信息,如下所示:

以上就是关于 builder 的封装,虽然有很多废代码对于性能的提升没有半毛钱关心,但是它有利于我们调试,
2. 问答环节
以下内容是来自于博主与 chatGPT 之间的对话。
问题1:我比较好奇宏定义 checkRuntime 中像 call #call __LINE__ __FILE__ 这种变量没有定义,代码是如何识别的呢?
回答:这些是 C/C++ 预处理器的特性。在宏定义中,您可以使用一些特殊的宏运算符来实现额外的功能。让我们详细解释 checkRuntime 宏中使用的这些元素:
1. call:
- 在宏定义中,call 是一个宏参数。当您使用这个宏并传入一个参数时,call 会被替换为该参数的值。例如,如果您写 checkRuntime(cudaMalloc(…));,那么在宏扩展中,所有的 call 都会被替换为 cudaMalloc(…)。
2. #call:
- # 是一个宏运算符,称为 “字符串化” 运算符。当它出现在宏定义中并放在一个宏参数前面时,它会将该参数转换为一个字符串字面量。因此,#call 会将 call 参数转换为一个字符串。例如,如果 call 是 cudaMalloc(…),那么 #call 就是 “cudaMalloc(…)”。
3. __LINE__ 和 __FILE__:
- 这些是预定义的宏。它们不需要手动定义。
- __LINE__ 会被替换为当前的源代码行号。
- __FILE__ 会被替换为当前的源文件名。
所以,当在代码中写 checkRuntime(cudaMalloc(…)); 时,预处理器会将其扩展为:
CUDATools::check_runtime(cudaMalloc(...), "cudaMalloc(...)", 当前行号, "当前文件名");这样就可以在 check_runtime 函数中获取到调用的具体函数、行号和文件名,从而使错误报告更加详细和有用。
问题2:在checkKernel中 … 和 __VA_ARGS__ 这两个变量代表又代表啥意思呢?
回答:在 C++ 宏中,… 和 __VA_ARGS__ 用于处理可变数量的参数。这是 C++11 引入的变参宏(Variadic Macros)的一部分。
1. …:
- 在宏定义的参数列表中,… 用于表示该宏可以接受可变数量的参数。
- 使用 … 允许您为宏提供任意数量的参数。
2. __VA_ARGS__:
- 在宏的替换部分,您可以使用 __VA_ARGS__ 来引用传递给宏的可变参数。
- __VA_ARGS__ 将被替换为传递给宏的所有参数(除了已经明确命名的参数之外)。
… 允许 checkKernel 接受任何数量的参数。然后,宏的替换部分使用 __VA_ARGS__ 来执行这些参数。这允许您直接在 checkKernel 宏前放置 CUDA 核函数调用。
因此当你写下面的代码时:
checkKernel(myKernel<<<blocks, threads>>>(arg1, arg2));宏会被扩展为:
myKernel<<<blocks, threads>>>(arg1, arg2); do {cudaError_t cudaStatus = cudaPeekAtLastError();if (cudaStatus != cudaSuccess){INFOE("launch failed: %s", cudaGetErrorString(cudaStatus));} } while(0);因此,… 和 __VA_ARGS__ 允许您为宏提供可变数量的参数,并在宏的定义中使用这些参数。这为宏提供了更大的灵活性,并允许它们处理各种不同的情况。
总结
本次课程学习了 builder 的封装,tensorRT 的模型编译过程其实很多地方都是通用的,我们完全可以将其封装起来。首先我们封装了一个 cuda-tools 的小工具,里面包含检查 cuda runtime 函数以及 cuda kernel 核函数是否执行成功的定义,另外包含了一些 device 信息的小工具;然后我们封装了一个 logger 日志文件,这个日志文件可以输出对应的时间、日志级别、文件名、行号等,非常有利于我们的调试工作;最后是我们的核心,关于 builder 的封装,我们重点关注了 compile 函数的实现,也就是把我们平时的 tensorRT 编译模型的过程给封装了起来,其中我们通过 logger 日志工具输出了许多信息,甚至可以打印出网络结构的详细信息,非常实用。
相关文章:
8.1.tensorRT高级(3)封装系列-模型编译过程封装,简化模型编译代码
目录 前言1. 模型编译过程封装2. 问答环节总结 前言 杜老师推出的 tensorRT从零起步高性能部署 课程,之前有看过一遍,但是没有做笔记,很多东西也忘了。这次重新撸一遍,顺便记记笔记。 本次课程学习 tensorRT 高级-模型编译过程封装…...

化工行业案例 | 甄知科技助力万华化学重构IT服务价值,打造信息中心ERP!
随着科技的发展,新材料的应用领域与日俱增,近年来,全球化工新材料产业发展整体步入高技术引领、产品迭代速度快、产业规模和需求不断扩大的阶段。一体化协同与数字化转型策略是实现化工新材料生产原料自给、节能降耗、降低排放和物料成本的重…...
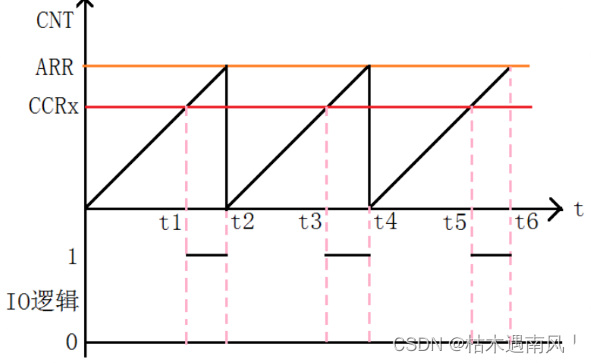
day6 STM32时钟与定时器
STM32时钟系统的概述 概念 时钟系统是由振荡器(信号源)、定时唤醒器、分频器等组成的电路。 常用的信号有晶体振荡器和RC振荡器。 意义 时钟是嵌入式系统的脉搏,处理器内核在时钟驱动下完成指令执行,状态变换等动作ÿ…...

【JavaEE进阶】SpringBoot 配置文件
文章目录 SpringBoot配置文件1. 配置文件的作用2. 配置文件的格式3. properties 配置文件说明3.1 properties 基本语法3.2 读取配置文件3.3 properties 优缺点分析 4. yml配置文件说明4.1 yml 基本语法4.2 yml 配置读取 5. properties和yml的对比 SpringBoot配置文件 1. 配置文…...

ResNet创新点总结
ResNet(Residual Networks)是深度学习中的一个重要架构,其创新点主要体现在解决了深层神经网络训练中的梯度消失和梯度爆炸问题,从而使得可以构建更深的神经网络。以下是 ResNet 的创新点总结: 1. 残差连接&#x…...
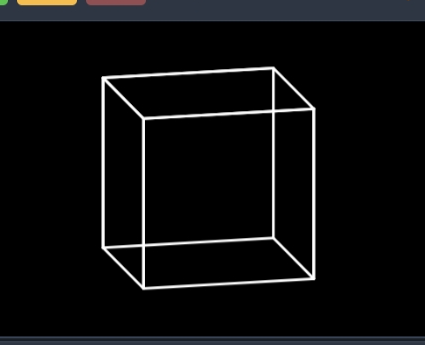
Scratch 之 3D 介绍及教程
第一章 为什么 3D 很难? 1.1 3D 难在何处? 3D 之所以会使我们觉得困难,是因为 Scratch 软件只有两个坐标轴,既:X轴、Y轴。 2维坐标系 而 3D 却拥有三个坐标轴: 3维坐标系 怎么办?很简单&…...

最强自动化测试框架Playwright(19)- 事件
Playwright允许收听网页上发生的各种类型的事件,例如网络请求,创建子页面,专用工作人员等。有几种方法可以订阅此类事件,例如等待事件或添加或删除事件侦听器。 等待事件 大多数情况下,脚本需要等待特定事件的发生。…...

静态网页和动态网页区别
1,静态网页和动态网页有何区别 1) 更新和维护 静态网页内容一经发布到网站服务器上,无论是否有用户访问,这些网页内容都是保存在网站服务器上的。如果要修改网页的内容,就必须修改其源文件,然后重新上传到服务器上。…...

美国服务器有哪些类型?
美国服务器有哪些类型?常见的服务器可分为虚拟主机、云服务器、物理服务器以及高防服务器,在海外服务器之中,使 用较多的属于美国服务器,下面我们就一起看看美国服务器有哪些及常见的美国服务器。 美国服务器有哪些? 与服务器一样&am…...

【基因检测人工智能】如何使用JAVASCRIPT在HTML文档内部增加一个段落
【基因检测人工智能】如何使用JAVASCRIPT在HTML文档内部增加一个段落 目的:采用JAVASCRIPT在一个HTML网页中增加一个段落。 下面是原来的HTML代码部分: <!DOCTYPE html> <html lang"zh-Hans"><head><meta charset&quo…...

unittest单元测试
当你在编写测试用例时,可以使用Python内置的unittest模块来进行单元测试。下面是一个逐步指南,帮助你理解如何编写和运行基本的单元测试。 导入必要的模块: 首先,你需要导入unittest模块和需要测试的模块(例如…...
每天一道leetcode:72. 编辑距离(动态规划困难)
今日份题目: 给你两个单词 word1 和 word2, 请返回将 word1 转换成 word2 所使用的最少操作数 。 你可以对一个单词进行如下三种操作: 插入一个字符 删除一个字符 替换一个字符 示例1 输入:word1 "horse", word…...

详细介绍如何使用 OpenCV 对图像进行锐化
将了解锐化图像的过程,我们将使用内核来突出显示每个特定像素并增强其发出的颜色。它与模糊过程非常相似,只不过现在我们不是创建一个内核来平均每个像素强度,而是创建一个内核,该内核将使像素强度更高,因此对人眼来说更加突出。 了解流程的后端。 很高兴知道内核用于模糊…...
Java代理模式——静态代理与动态代理
代理模式 代理模式允许你为其他对象提供一个代理,以控制对这个对象的访问。代理模式在不改变实际对象的情况下,可以在访问对象时添加额外的功能。 可以理解为代理模式为被代理对象创造了一个替身,调用者可以通过这个替身去实现这个被代理对…...

Vue day02 Computed和Watch
1.事件绑定 可以用 v-on 指令监听DOM 事件,并在触发时运行一些 JavaScript 代码。v-on 还可以接收一个需要调用的方法名称。 <button v-on:click"handler">good</button> methods: { handler: function (event) { if (event) { alert(event.t…...
【Java】一只小菜坤的编程题之旅【3】
文章目录 1丶判定是否互为字符重排2、杨辉三角3丶某公司的1个面试题(字符串包含问题) 1丶判定是否互为字符重排 这个题我们用一个非常简单的思想就能实现,我们先将字符串转换为字符数组,然后对字符数组进行排序,然后再…...
)
全面掌握 Jaeger 分布式调用链路跟踪理论和实战,Go 为所有使用 go-resty 库发起 HTTP 请求集成链路跟踪 jaeger(附源码)
全面掌握 Jaeger 分布式调用链路跟踪理论和实战,Go 为所有使用 go-resty 库发起 HTTP 请求集成链路跟踪 jaeger(附源码)。 介绍一个开源的分布式跟踪系统 Jaeger,首先从理论基础知识开始学习,将学习如何在 HTTP 请求中集成链路跟踪,以及如何在 GORM 框架实现,最后学习 …...

vue键盘和鼠标事件
1、键盘事件 **按Enter键** keyup.enter**按PageDown键** keyup.page-down **按Tab键** keyup.tab **按Delete键** keyup.delete **按ESC键** keyup.esc**按Space键** keyup.space **按↑(Up)键** keyup.up**按↓(Down)键** keyup…...

Chrome 手动代理设置 HTTP/Socks5
1、安装代理插件:SwitchyOmega 在线安装 从 Chrome 应用商店 安装,如果您无法从该链接安装,请使用下面的离线安装。 离线安装 ①、去 Github 下载 最新版安装包 ,或者直接 本地下载 文件进行安装。 ②、下载安装文件后…...
SpringBoot第35讲:SpringBoot集成连接池 - 默认连接池HikariCP
SpringBoot第35讲:SpringBoot集成连接池 - 默认连接池HikariCP 本文是SpringBoot第35讲,主要介绍数据库连接池,以及SpringBoot集成默认的HikariCP的实践。 文章目录 SpringBoot第35讲:SpringBoot集成连接池 - 默认连接池HikariCP1…...

龙芯k - 走马观碑组ST驱动移植该
正文 异步/等待解决了什么问题? 在传统同步I/O操作中(如文件读取或Web API调用),调用线程会被阻塞直到操作完成。这在UI应用中会导致界面冻结,在服务器应用中则造成线程资源的浪费。async/await通过非阻塞的异步操作解…...

MATLAB+CPLEX仿真平台下的微网虚拟电厂日前优化调度模型:融合电动汽车出行及充放电规律...
MATLAB代码:含多种需求响应及电动汽车的微网/虚拟电厂日前优化调度 关键词:需求响应 空调负荷 电动汽车 微网优化调度 虚拟电厂调度 仿真平台:MATLABCPLEX 主要内容:代码主要做的是一个微网/虚拟电厂的日前优化调度模型&#…...
)
保姆级教程:在Jetson Orin上从零搭建PyTorch+TensorFlow环境(含torchvision源码编译避坑)
保姆级教程:在Jetson Orin上从零搭建PyTorchTensorFlow环境(含torchvision源码编译避坑) NVIDIA Jetson Orin作为当前边缘计算领域的旗舰平台,其ARM架构下的深度学习环境配置一直是开发者的痛点。本文将手把手带你完成从系统准备到…...

保姆级 uPyPi 教程|从 到 :MicroPython 驱动包一键安装 + 分享全攻略诮
这个代码的核心功能是:基于输入词的长度动态选择反义词示例,并调用大模型生成反义词,体现了 “动态少样本提示(Dynamic Few-Shot Prompting)” 与 “上下文长度感知的示例选择” 的能力。 from langchain.prompts impo…...

# 上海第一次带宠物去洗护,怎么避免被坑和乱剪毛?
在上海养宠,洗护是绕不开的刚需。尤其是第一次带毛孩子去店里,很多铲屎官心里都打鼓:怕价格不透明,怕美容师手重,更怕“一言不合就剃光”。这里整理了几个大家最关心的问题,帮你理清思路,少踩坑…...

别再死记命令了!通过一个Packet Tracer静态路由实验,彻底搞懂‘下一跳’和‘出接口’的区别
别再死记命令了!通过Packet Tracer实验彻底搞懂静态路由的“下一跳”与“出接口” 刚接触网络配置时,很多人会陷入一个误区:把静态路由的配置命令当作魔法咒语来记忆。直到某天,当网络拓扑发生变化,或者需要在不同场景…...

Orion Framework:嵌入式轻量级REST客户端实现
1. Orion Framework 框架深度解析:面向嵌入式系统的轻量级 REST API 客户端实现1.1 定位与工程价值辨析Orion Framework 并非通用 Web 框架,而是一个专为资源受限嵌入式环境设计的精简型 REST API 客户端通信中间件。其核心工程目标明确:在无…...

C语言实战:时间戳转换与边界处理的全面解析
1. 时间戳基础概念与C语言处理场景 时间戳本质上就是个数字计数器,记录从某个固定时间点(比如1970年1月1日)到现在经过的秒数或毫秒数。我第一次接触这个概念是在处理物联网设备数据时,传感器传回来的全是像"1654321000"…...
---命令解析和工具映射寡)
【GUI-Agent】阶跃星辰 GUI-MCP 解读---()---命令解析和工具映射寡
先回顾:三次握手(建立连接)核心流程(实际版) 为了让挥手流程衔接更顺畅,咱们先快速回顾三次握手的实际核心,避免上下文脱节: 第一步(客户端→服务器)…...

GB/T28181设备接入WVP平台保姆级教程:从海康到大华的配置避坑指南
GB/T28181设备接入WVP平台实战指南:海康/大华/宇视全品牌配置解析 第一次接触GB/T28181协议时,我盯着设备ID和SIP服务器配置页面发呆了半小时——这些看似简单的字段背后藏着太多细节陷阱。本文将用真实项目经验,带你拆解不同品牌设备在WVP平…...