【Pytroch】基于支持向量机算法的数据分类预测(Excel可直接替换数据)
【Pytroch】基于支持向量机算法的数据分类预测(Excel可直接替换数据)
- 1.模型原理
- 2.数学公式
- 3.文件结构
- 4.Excel数据
- 5.下载地址
- 6.完整代码
- 7.运行结果
1.模型原理
支持向量机(Support Vector Machine,SVM)是一种强大的监督学习算法,用于二分类和多分类问题。它的主要思想是找到一个最优的超平面,可以在特征空间中将不同类别的数据点分隔开。
下面是使用PyTorch实现支持向量机算法的基本步骤和原理:
-
数据准备: 首先,你需要准备你的训练数据。每个数据点应该具有特征(Feature)和对应的标签(Label)。特征是用于描述数据点的属性,标签是数据点所属的类别。
-
数据预处理: 根据SVM的原理,数据点需要线性可分。因此,你可能需要进行一些数据预处理,如特征缩放或标准化,以确保数据线性可分。
-
定义模型: 在PyTorch中,你可以定义一个支持向量机模型作为一个线性模型,例如使用
nn.Linear。 -
定义损失函数: SVM的目标是最大化支持向量到超平面的距离,即最大化间隔(Margin)。这可以通过最小化损失函数来实现,通常使用
hinge loss(合页损失)。PyTorch提供了nn.MultiMarginLoss损失函数,它可以用于SVM训练。 -
定义优化器: 选择一个优化器,如
torch.optim.SGD,来更新模型的参数以最小化损失函数。 -
训练模型: 使用训练数据对模型进行训练。在每个训练步骤中,计算损失并通过优化器更新模型参数。
-
预测: 训练完成后,你可以使用训练好的模型对新的数据点进行分类预测。对于二分类问题,可以使用模型的输出值来判断数据点所属的类别。
2.数学公式
当使用支持向量机(SVM)进行数据分类预测时,目标是找到一个超平面(或者在高维空间中是一个超曲面),可以将不同类别的数据点有效地分隔开。以下是SVM的数学原理:
-
超平面方程: 在二维情况下,超平面可以表示为
w 1 x 1 + w 2 x 2 + b = 0 w_1 x_1 + w_2 x_2 + b = 0 w1x1+w2x2+b=0
-
决策函数: 数据点 (x) 被分为两个类别的决策函数为
f ( x ) = w T x + b f(x) = w^T x + b f(x)=wTx+b
-
间隔(Margin): 对于一个给定的超平面,数据点到超平面的距离被称为间隔。支持向量机的目标是找到能最大化间隔的超平面。间隔可以用下面的公式计算:
间隔 = 2 ∥ w ∥ \text{间隔} = \frac{2}{\|w\|} 间隔=∥w∥2
-
支持向量: 支持向量是离超平面最近的那些数据点。这些点对于确定超平面的位置和间隔非常重要。支持向量到超平面的距离等于间隔。
-
最大化间隔: SVM 的目标是找到一个超平面,使得所有支持向量到该超平面的距离(即间隔)都最大化。这等价于最小化法向量的范数 (|w|),即:
最小化 1 2 ∥ w ∥ 2 \text{最小化} \quad \frac{1}{2}\|w\|^2 最小化21∥w∥2
-
对偶问题和核函数: 对偶问题的解决方法涉及到拉格朗日乘子,可以得到一个关于训练数据点的内积的表达式。这样,如果直接在高维空间中计算内积是非常昂贵的,可以使用核函数来避免高维空间的计算。核函数将数据映射到更高维的空间,并在计算内积时使用高维空间的投影,从而实现了在高维空间中的计算,但在计算上却更加高效。
总之,SVM利用线性超平面来分隔不同类别的数据点,通过最大化支持向量到超平面的距离来实现分类。对偶问题和核函数使SVM能够处理非线性问题,并在高维空间中进行计算。以上是SVM的基本数学原理。
3.文件结构

iris.xlsx % 可替换数据集
Main.py % 主函数
4.Excel数据

5.下载地址
- 资源下载地址
6.完整代码
import torch
import torch.nn as nn
import pandas as pd
import numpy as np # Don't forget to import numpy for the functions using it
import matplotlib.pyplot as plt # Import matplotlib for plotting
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import confusion_matrixclass SVM(nn.Module):def __init__(self, input_size, num_classes):super(SVM, self).__init__()self.linear = nn.Linear(input_size, num_classes)def forward(self, x):return self.linear(x)def train(model, X, y, num_epochs, learning_rate):criterion = nn.CrossEntropyLoss() # Use CrossEntropyLoss for multi-class classificationoptimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)for epoch in range(num_epochs):inputs = torch.tensor(X, dtype=torch.float32)labels = torch.tensor(y, dtype=torch.long) # Use long for class indicesoptimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()if (epoch + 1) % 100 == 0:print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')def test(model, X, y):inputs = torch.tensor(X, dtype=torch.float32)labels = torch.tensor(y, dtype=torch.long) # Use long for class indiceswith torch.no_grad():outputs = model(inputs)_, predicted = torch.max(outputs, 1)accuracy = (predicted == labels).float().mean()print(f'Accuracy on test set: {accuracy:.2f}')# Define the plot functions
def plot_confusion_matrix(conf_matrix, classes):plt.figure(figsize=(8, 6))plt.imshow(conf_matrix, cmap=plt.cm.Blues, interpolation='nearest')plt.title("Confusion Matrix")plt.colorbar()tick_marks = np.arange(len(classes))plt.xticks(tick_marks, classes)plt.yticks(tick_marks, classes)plt.xlabel("Predicted Label")plt.ylabel("True Label")plt.tight_layout()plt.show()def plot_predictions_vs_true(y_true, y_pred):plt.figure(figsize=(10, 6))plt.plot(y_true, 'go', label='True Labels')plt.plot(y_pred, 'rx', label='Predicted Labels')plt.title("True Labels vs Predicted Labels")plt.xlabel("Sample Index")plt.ylabel("Class Label")plt.legend()plt.show()def main():data = pd.read_excel('iris.xlsx')X = data.iloc[:, :-1].valuesy = data.iloc[:, -1].valueslabel_encoder = LabelEncoder()y = label_encoder.fit_transform(y)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)num_classes = len(label_encoder.classes_)model = SVM(X_train.shape[1], num_classes)num_epochs = 1000learning_rate = 0.001train(model, X_train, y_train, num_epochs, learning_rate)# Call the test function to get predictionsinputs = torch.tensor(X_test, dtype=torch.float32)labels = torch.tensor(y_test, dtype=torch.long)with torch.no_grad():outputs = model(inputs)_, predicted = torch.max(outputs, 1)# Convert torch tensors back to numpy arraysy_true = labels.numpy()y_pred = predicted.numpy()test(model, X_test, y_test)# Call the plot functionsconf_matrix = confusion_matrix(y_true, y_pred)plot_confusion_matrix(conf_matrix, label_encoder.classes_)plot_predictions_vs_true(y_true, y_pred)if __name__ == '__main__':main()7.运行结果



相关文章:
【Pytroch】基于支持向量机算法的数据分类预测(Excel可直接替换数据)
【Pytroch】基于支持向量机算法的数据分类预测(Excel可直接替换数据) 1.模型原理2.数学公式3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果 1.模型原理 支持向量机(Support Vector Machine,SVM)是一种强大的监…...

【Git】git初始化项目时 | git默认创建main分之 | 如何将git默认分支从main改为master
git 更改 branch 在 Git 中,如果你在第一次提交后想要将默认分支名从 main 修改为 master,你可以按照以下步骤进行操作: 创建 master 分支: 首先,你需要在当前的 main 分支基础上创建一个新的 master 分支。使用以下命…...

Vue3中配置environment
environment顾名思义就是环境,对于项目来说,无非就是: 开发环境:development生产环境:production 某些逻辑,配置等在两个不同的环境中要呈现出不同的状态,所以environment是一个必要的事情。 …...

前端基础积累_新技术_Vue_React_H5_奇怪的BUG_面试_招聘
前端之路 序 前几天在博客园收到了一封来自出版社的消息,说看到原来很久之前写的 < VueJS 源码分析的文章 > 希望能够联系他们出版社去写书。这样的事情虽然在博客园是会经常发生的,但是这也让我意识到了,多多写高质量的文章能够给 co…...

【密码学】维京密码
维京密码 瑞典罗特布鲁纳巨石上的图案看起来毫无意义,但是它确实是一种维京密码。如果我们注意到每组图案中长笔画和短笔画的数量,将得到一组数字2、4、2、3、3、5、2、3、3、6、3、5。组合配对得到24、23、35、23、36、35。现在考虑如图1.4所示的内容&a…...
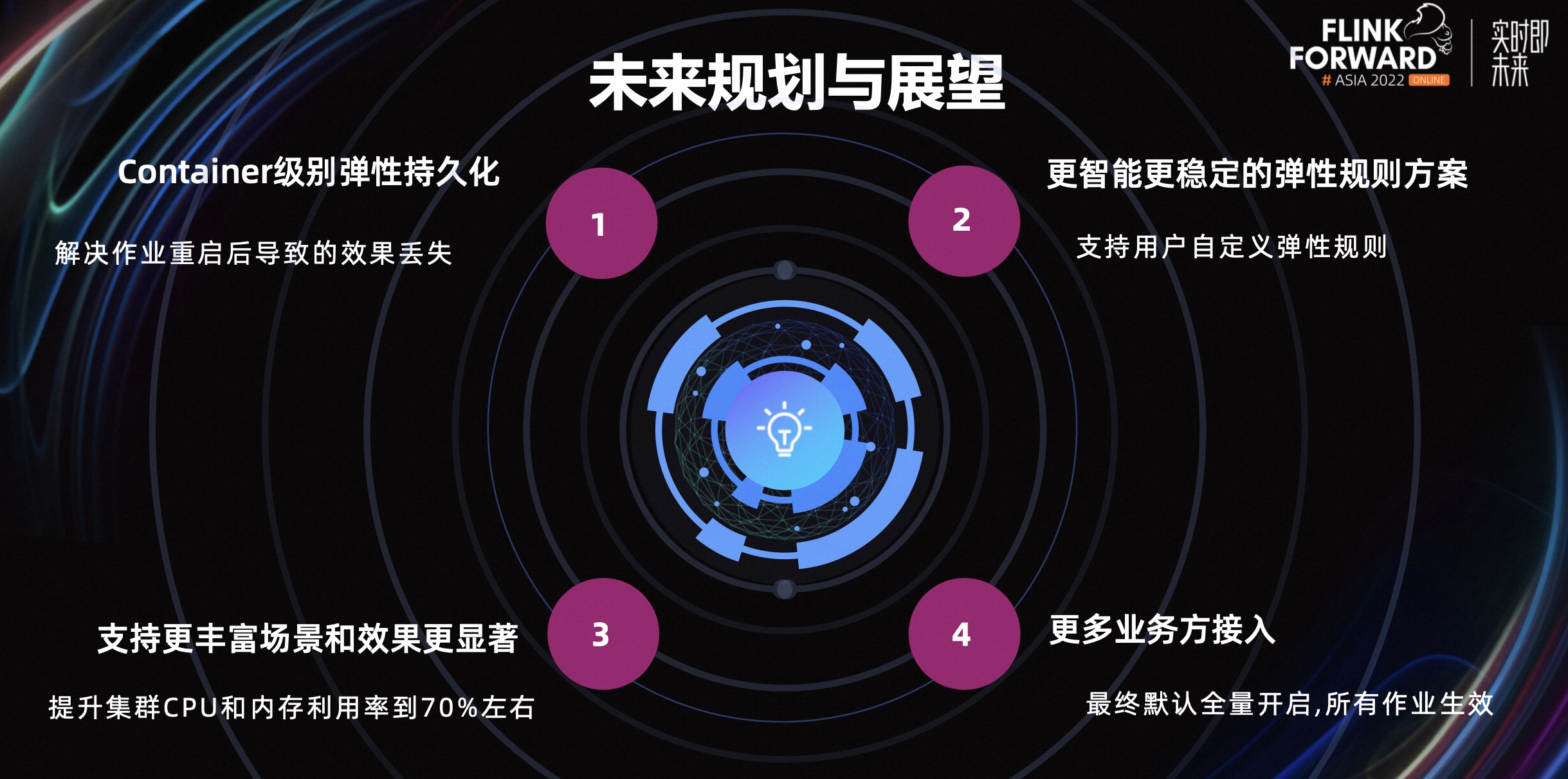
小米基于 Flink 的实时计算资源治理实践
摘要:本文整理自小米高级软件工程师张蛟,在 Flink Forward Asia 2022 生产实践专场的分享。本篇内容主要分为四个部分: 发展现状与规模框架层治理实践平台层治理实践未来规划与展望 点击查看原文视频 & 演讲PPT 一、发展现状与规模 如上图…...
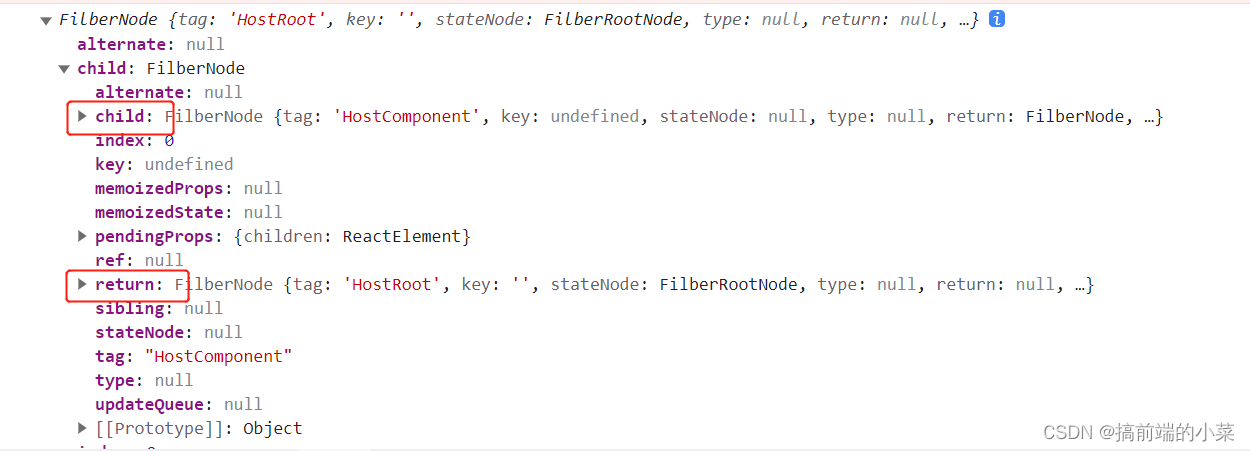
React源码解析18(3)------ beginWork的工作流程【mount】
摘要 OK,经过上一篇文章。我们调用了: const root document.querySelector(#root); ReactDOM.createRoot(root)生成了FilberRootNode和HostRootFilber。 并且二者之间的对应关系也已经确定。 而下一步我们就需要调用render方法来讲react元素挂载在ro…...

JAVA SpringBoot 项目 多线程、线程池的使用。
1.1 线程: 线程就是进程中的单个顺序控制流,也可以理解成是一条执行路径 单线程:一个进程中包含一个顺序控制流(一条执行路径) 多线程:一个进程中包含多个顺序控制流(多条执行路径࿰…...

【数据结构与算法】动态规划算法
动态规划算法 应用场景 - 背包问题 背包问题:有一个背包,容量为 4 磅,现有如下物品: 物品重量价格吉他(G)11500音响(S)43000电脑(L)32000 要求达到的目标…...

离线安装vscode插件,导出 Visual Studio Code 的扩展应用,并离线安装
在没有网络的情况下,如何安装vscode插件 1.使用之前电脑安装过的插件包 Visual Studio Code 的扩展应用安装位置在文件夹 .vscode/extensions 下。不同平台,它位于: Windows %USERPROFILE%\.vscode\extensions Mac ~/.vscode/extensions L…...

【ChatGPT 指令大全】怎么使用ChatGPT辅助程式开发
目录 写程式 解读程式码 重构程式码 解 bug 写测试 写 Regex 总结 在当今快节奏的数字化世界中,程式开发变得越来越重要和普遍。无论是开发应用程序、网站还是其他软件,程式开发的需求都在不断增长。然而,有时候我们可能会遇到各种问题…...

涂色
蜀山区2021年信息学竞赛试题 题目描述 Description 小李喜欢写日记,为了有效区分每题记录的内容,他循环使用七种不同颜色的笔在日记本上记录每天发生的事情,循环次序分别为Red,Orange,Yellow,Green,Blue,Cyan,Purple,由于近期工作繁忙&…...
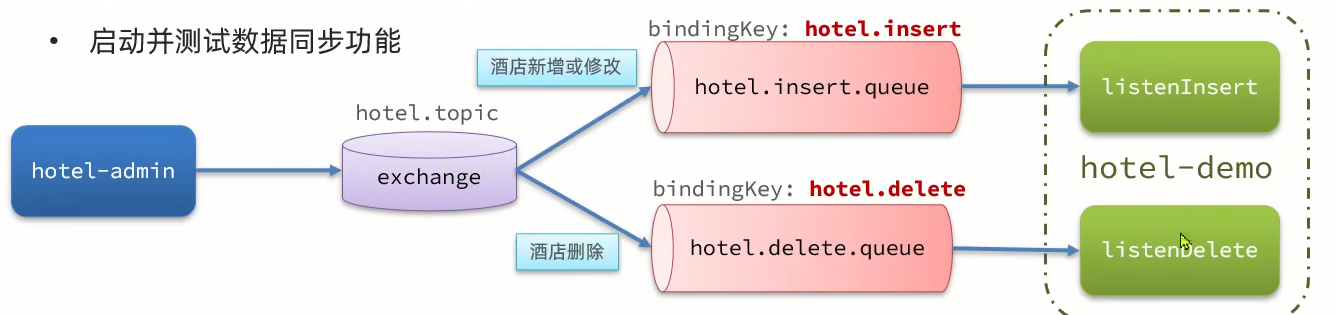
微服务——数据同步
问题分析 mysql和redis之间有数据同步问题,ES和mysql之间也有数据同步问题。 单体项目可以在crud时就直接去修改,但在微服务里面不同的服务不行。 方案一 方案二 方案三 总结 导入酒店管理项目 倒入完成功启动后可以看见数据成功获取到了 声明队列和…...
,SQL SERVER 手机选号(AABB、ABCD、DCBA、AAA),通过规则查询靓号)
MySQL 手机选号(AABB、ABCD、DCBA、AAA),SQL SERVER 手机选号(AABB、ABCD、DCBA、AAA),通过规则查询靓号
先上SQL SERVER: create table plat_uidlist(Uidd varchar(15) , Areaid int , State int)insert into plat_uidlist values(2335435 ,8 ,0 ) insert into plat_uidlist values(2335436 ,8 ,1 ) insert into plat_uidlist values(2335437 ,2 ,2 ) insert into plat…...
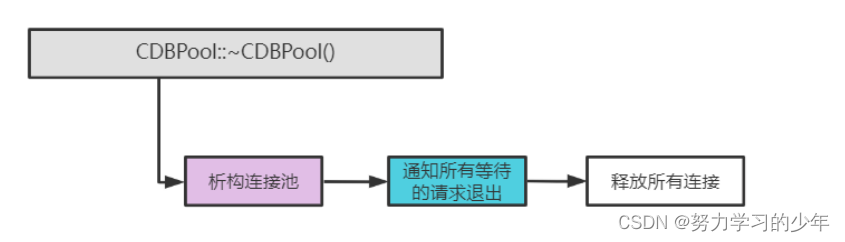
【server组件】——mysql连接池的实现原理
目录 1.池化技术 2.数据库连接池的定义 3.为什么要使用连接池 4. 数据库连接池的运行机制 5. 连接池与线程池的关系 6. CResultSet的设计 6.1构造函数 7. CDBConn的设计 6.1.构造函数 6.2.init——初始化连接 8.数据库连接池的设计要点 9.接口设计 9.1 构造函数 …...

DSP开发:串口sci的发送与接收实现
DSP开发:串口sci的发送与接收实现 文章目录 DSP开发:串口sci的发送与接收实现串口配置串口SCI初始化详细分析串口SCI使用 串口配置 /*--------------------------------------------scia----------------------------*/ /*----------------------------…...
实训一 :Linux的启动、关机及登录
实训一 :Linux的启动、关机及登录 2017 年 2 月 22 日 今日公布 实训目标 完成本次实训,将能够: 描述Linux的开机过程。在图形模式和文本模式下登录Linux。关闭和重启Linux 实训准备 一台已安装RHEL6的虚拟计算机,Linux虚拟…...

Redis分布式锁问题
1、业务单机情况下 问题:并发没有加锁导致线程安全问题。 解决方法:加锁处理,如lock、synchronized 仍有问题:业务分布式情况下,代码级别加锁已经无效。需要借助第三方组件,如redis、zookeeper。 2、业务分…...
windows安装apache-jmeter-5.6.2教程
目录 一、下载安装包(推荐第二种) 二、安装jmeter 三、启动jmeter 一、下载安装包(推荐第二种) 1.官网下载:Apache JMeter - Download Apache JMeter 2.百度云下载:链接:https://pan.baidu.…...

密码检查-C语言/Java
描述 小明同学最近开发了一个网站,在用户注册账户的时候,需要设置账户的密码,为了加强账户的安全性,小明对密码强度有一定要求: 1. 密码只能由大写字母,小写字母,数字构成; 2. 密码不…...

CompressO终极压缩神器:免费开源的一键瘦身工具,释放95%存储空间
CompressO终极压缩神器:免费开源的一键瘦身工具,释放95%存储空间 【免费下载链接】compressO Convert any video/image into a tiny size. 100% free & open-source. Available for Mac, Windows & Linux. 项目地址: https://gitcode.com/gh_m…...

ROS2手眼标定实战:从二维平面到三维空间的坐标对齐
1. 手眼标定基础概念与ROS2环境搭建 手眼标定是机器人视觉引导系统中的关键环节,简单来说就是让机器人"知道"眼睛看到的东西在哪里。想象一下你闭着眼睛摸桌上的水杯,如果不知道手和眼睛的相对位置关系,很容易把杯子打翻。在工业场…...

考虑需求响应和碳交易的柔性负荷综合能源系统优化调度模型
考虑需求响应和碳交易的综合能源系统日前优化调度模型 关键词:柔性负荷 需求响应 综合能源系统 参考:私我 仿真平台:MATLAB yalmipcplex 主要内容:在冷热电综合能源系统的基础上,创新性的对用户侧资源进行了细致的划…...

数字后端设计中的Floorplan实战:从基础到优化
1. 数字后端设计中的Floorplan基础概念 第一次接触数字后端设计时,听到"Floorplan"这个词我以为是建筑平面图。后来才发现,芯片设计和建筑设计还真有异曲同工之妙。Floorplan就是芯片设计的"平面布局图",它决定了芯片内部…...

PvZ Toolkit:植物大战僵尸PC版终极修改工具完全指南
PvZ Toolkit:植物大战僵尸PC版终极修改工具完全指南 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit PvZ Toolkit是一款专为植物大战僵尸一代PC版设计的开源综合修改工具,为玩…...
结合门控循环单元(GRU)进行交通流量预测的详细项目实例(含模型描述及部分示例代码)专栏近期有大量优惠 还请多多点一下关注 加油 谢谢 你的鼓)
项目介绍 MATLAB实现基于WT-GRU小波变换(WT)结合门控循环单元(GRU)进行交通流量预测的详细项目实例(含模型描述及部分示例代码)专栏近期有大量优惠 还请多多点一下关注 加油 谢谢 你的鼓
MATLAB实现基于WT-GRU小波变换(WT)结合门控循环单元(GRU)进行交通流量预测的详细项目实例 更多详细内容可直接联系博主本人 加v 我的昵称(nantangyuxi) 或者访问对应标题的完整博客或者文档下载页面&#…...

无需专业显卡!Qwen3-VL-4B Pro在普通电脑上的部署指南
无需专业显卡!Qwen3-VL-4B Pro在普通电脑上的部署指南 1. 从“看着眼馋”到“真正能用”:一个普通人的多模态AI体验 你有没有过这样的经历? 看到别人展示AI看图说话、识别表格、分析图表,觉得特别酷,自己也想试试。…...
详解)
千问3.5-2B快速上手:网页端四步操作(上传→提问→设置→获取)详解
千问3.5-2B快速上手:网页端四步操作(上传→提问→设置→获取)详解 1. 开篇:认识千问3.5-2B 千问3.5-2B是Qwen系列中的一款轻量级视觉语言模型,它能像人类一样"看"图片并回答相关问题。想象一下,…...

如何在5分钟内上手MobileNet-SSD:移动端实时目标检测终极指南
如何在5分钟内上手MobileNet-SSD:移动端实时目标检测终极指南 【免费下载链接】MobileNet-SSD Caffe implementation of Google MobileNet SSD detection network, with pretrained weights on VOC0712 and mAP0.727. 项目地址: https://gitcode.com/gh_mirrors/m…...

Jenkins 学习总结几
先唠两句:参数就像餐厅点单 把API想象成一家餐厅的“后厨系统”。 ? 路径参数/dishes/{dish_id} -> 好比你要点“宫保鸡丁”这道具体的菜,它是菜单(资源路径)的一部分。查询参数/dishes?spicytrue&typeSichuan -> 好比…...