Python学习笔记第五十七天(Pandas 数据清洗)
Python学习笔记第五十七天
- Pandas 数据清洗
- Pandas 清洗空值
- isnull()
- Pandas替换单元格
- mean()
- median()
- mode()
- Pandas 清洗格式错误数据
- Pandas 清洗错误数据
- Pandas 清洗重复数据
- duplicated()
- drop_duplicates()
- 后记
Pandas 数据清洗
数据清洗是对一些没有用的数据进行处理的过程。
很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要使数据分析更加准确,就需要对这些没有用的数据进行处理。
在这个教程中,我们将利用 Pandas包来进行数据清洗。
本文使用到的测试数据 property-data.csv 如下:
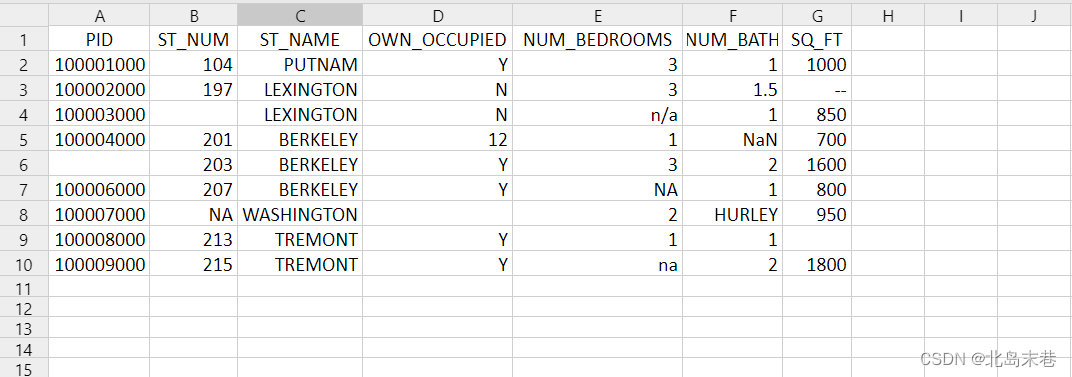
上表包含了四种空数据:
- n/a
- NA
- —
- na
Pandas 清洗空值
如果我们要删除包含空字段的行,可以使用 dropna() 方法,语法格式如下:
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数说明:
- axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。
- how:默认为 ‘any’ 如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置 how=‘all’ 一行(或列)都是 NA 才去掉这整行。
- thresh:设置需要多少非空值的数据才可以保留下来的。
- subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
- inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。
isnull()
我们可以通过 isnull() 判断各个单元格是否为空。
# 实例 1
import pandas as pd
df = pd.read_csv('property-data.csv')
print (df['NUM_BEDROOMS'])
print (df['NUM_BEDROOMS'].isnull())
以上例子中Pandas 把 n/a 和 NA 当作空数据,na 不是空数据,不符合我们要求,我们可以指定空数据类型:
# 实例 2
import pandas as pd
missing_values = ["n/a", "na", "--"]
df = pd.read_csv('property-data.csv', na_values = missing_values)
print (df['NUM_BEDROOMS'])
print (df['NUM_BEDROOMS'].isnull())
使用 pd.read_csv 函数读取了一个名为 ‘property-data.csv’ 的CSV文件,并将其存储在 df 变量中,df.dropna() 这行代码从原始DataFrame(在变量 df 中)中删除了包含空数据的行,将新的不含空数据行DataFrame转换为字符串并打印出来。
# 实例 3
import pandas as pd
df = pd.read_csv('property-data.csv')
new_df = df.dropna()
print(new_df.to_string())
注意:默认情况下,dropna() 方法返回一个新的 DataFrame,不会修改源数据。
如果你的 ‘property-data.csv’ 文件中有一些行包含空数据(例如,某个或多个列的值为空),那么这些行将会被删除,新的DataFrame(new_df)将不包含这些行。
需要注意的是,dropna() 默认会删除包含至少一个NaN值的行。如果你想删除所有NaN值并且只保留没有缺失值的行,你可以使用 dropna(how=‘all’)。
此外,你还可以通过设置 axis 参数来指定是行还是列应该被删除。例如,df.dropna(axis=1) 将删除包含空数据的列。
如果你要修改源数据 DataFrame, 可以使用 inplace = True 参数
# 实例 4
import pandas as pd
df = pd.read_csv('property-data.csv')
df.dropna(inplace = True)
print(df.to_string())
也可以移除指定列有空值的行
# 实例 5
import pandas as pd
df = pd.read_csv('property-data.csv')
# 移除 ST_NUM 列中字段值为空的行
df.dropna(subset=['ST_NUM'], inplace = True)
print(df.to_string())
也可以 fillna() 方法来替换一些空字段
# 实例 6
import pandas as pd
df = pd.read_csv('property-data.csv')
# 使用 12345 替换空字段
df.fillna(12345, inplace = True)
print(df.to_string())
也可以指定某一个列来替换数据:
# 实例 7
import pandas as pd
df = pd.read_csv('property-data.csv')
# 使用 12345 替换 PID 为空数据:
df['PID'].fillna(12345, inplace = True)
print(df.to_string())
Pandas替换单元格
替换空单元格的常用方法是计算列的均值、中位数值或众数。
Pandas使用 mean()、median() 和 mode() 方法计算列的均值(所有值加起来的平均值)、中位数值(排序后排在中间的数)和众数(出现频率最高的数)。
mean()
使用 mean() 方法计算列的均值并替换空单元格
# 实例 8
import pandas as pd
df = pd.read_csv('property-data.csv')
x = df["ST_NUM"].mean()
df["ST_NUM"].fillna(x, inplace = True)
print(df.to_string())
median()
使用 median() 方法计算列的中位数并替换空单元格
# 实例 9
import pandas as pd
df = pd.read_csv('property-data.csv')
x = df["ST_NUM"].median()
df["ST_NUM"].fillna(x, inplace = True)
print(df.to_string())
mode()
使用 mode() 方法计算列的众数并替换空单元格
# 实例 10
import pandas as pd
df = pd.read_csv('property-data.csv')
x = df["ST_NUM"].mode()
df["ST_NUM"].fillna(x, inplace = True)
print(df.to_string())
Pandas 清洗格式错误数据
数据格式错误的单元格会使数据分析变得困难,甚至不可能。
我们可以通过包含空单元格的行,或者将列中的所有单元格转换为相同格式的数据。
以下实例会格式化日期:
# 实例 11
import pandas as pd
# 第三个日期格式错误
data = {"Date": ['2020/12/01', '2020/12/02' , '20201226'],"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
df['Date'] = pd.to_datetime(df['Date'])
print(df.to_string())
Pandas 清洗错误数据
数据错误也是很常见的情况,我们可以对错误的数据进行替换或移除。
以下实例会替换错误年龄的数据:
# 实例 12
import pandas as pd
person = {"name": ['Google', 'Baidu' , 'Taobao'],"age": [50, 40, 12345] # 12345 年龄数据是错误的
}
df = pd.DataFrame(person)
df.loc[2, 'age'] = 30 # 修改数据
print(df.to_string())
也可以设置条件语句,将 age 大于 120 的设置为 120
# 实例 13
import pandas as pd
person = {"name": ['Google', 'Baidu' , 'Taobao'],"age": [50, 200, 12345]
}
df = pd.DataFrame(person)
for x in df.index:if df.loc[x, "age"] > 120:df.loc[x, "age"] = 120
print(df.to_string())
也可以将错误数据的行删除,将 age 大于 120 的删除
# 实例 14
import pandas as pd
person = {"name": ['Google', 'Baidu' , 'Taobao'],"age": [50, 40, 12345] # 12345 年龄数据是错误的
}
df = pd.DataFrame(person)
for x in df.index:if df.loc[x, "age"] > 120:df.drop(x, inplace = True)
print(df.to_string())
Pandas 清洗重复数据
如果我们要清洗重复数据,可以使用 duplicated() 和 drop_duplicates() 方法。
duplicated()
如果对应的数据是重复的,duplicated() 会返回 True,否则返回 False。
# 实例 15
import pandas as pd
person = {"name": ['Google', 'Baidu', 'Baidu', 'Taobao'],"age": [50, 40, 40, 23]
}
df = pd.DataFrame(person)
print(df.duplicated())
drop_duplicates()
删除重复数据,可以直接使用drop_duplicates() 方法。
# 实例 16
import pandas as pdpersons = {"name": ['Google', 'Runoob', 'Runoob', 'Taobao'],"age": [50, 40, 40, 23]
}df = pd.DataFrame(persons)df.drop_duplicates(inplace = True)
print(df)
后记
今天学习的是Python Pandas 数据清洗学会了吗。 今天学习内容总结一下:
- Pandas 数据清洗
- Pandas 清洗空值
- Pandas替换单元格
- Pandas 清洗格式错误数据
- Pandas 清洗错误数据
- Pandas 清洗重复数据
相关文章:
Python学习笔记第五十七天(Pandas 数据清洗)
Python学习笔记第五十七天 Pandas 数据清洗Pandas 清洗空值isnull() Pandas替换单元格mean()median()mode() Pandas 清洗格式错误数据Pandas 清洗错误数据Pandas 清洗重复数据duplicated()drop_duplicates() 后记 Pandas 数据清洗 数据清洗是对一些没有用的数据进行处理的过程…...
Elasticsearch的一些基本概念
文章目录 基本概念:文档和索引JSON文档元数据索引REST API 节点和集群节点Master eligible节点和Master节点Data Node 和 Coordinating Node其它节点 分片(Primary Shard & Replica Shard)分片的设定操作命令 基本概念:文档和索引 Elasticsearch是面…...

Guitar Pro8专业版吉他学习、绘谱、创作软件
Guitar Pro 8 专业版更强大!更优雅!更完美!Guitar Pro 8.0 五年磨一剑!多达30项功能优化!Guitar Pro8 版本一共更新近30项功能,令吉他打谱更出色!Guitar Pro8 是自2017年4月发布7.0之后发布的最…...
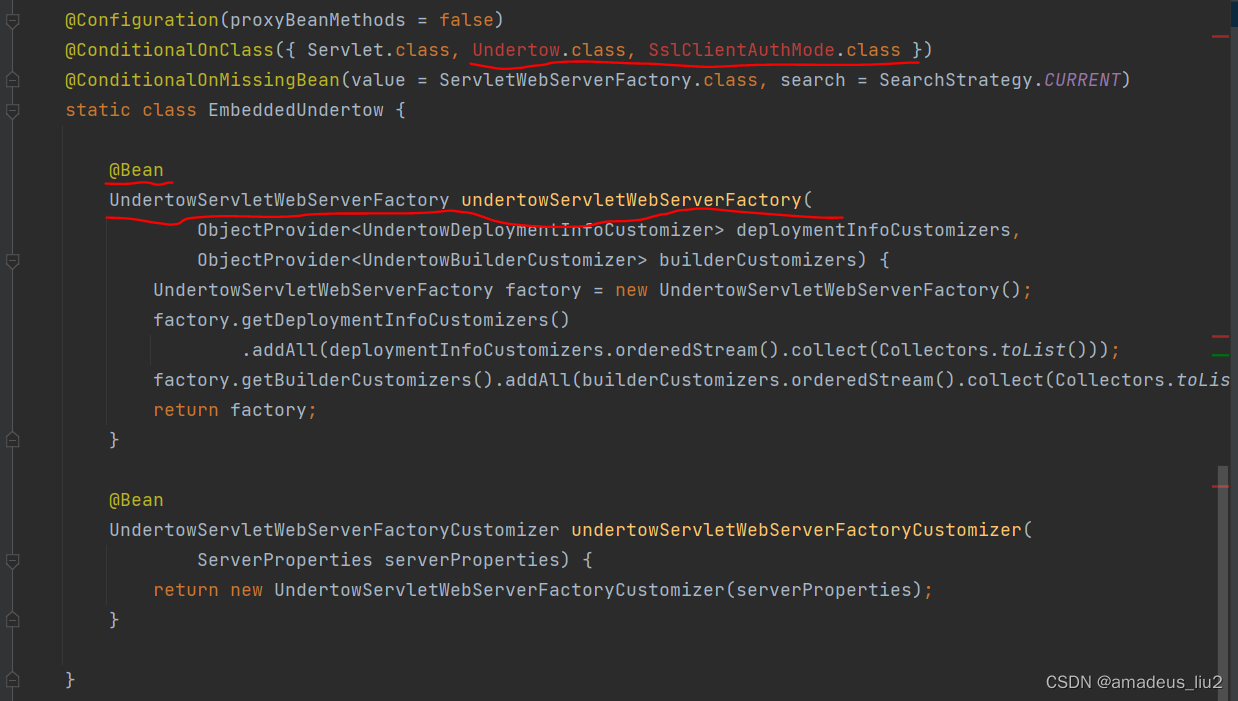
SpringBoot复习(39)Servlet容器的自动配置原理
Servlet容器自动配置类为ServletWebServerFactoryAutoConfiguration 可以看到通过Import注解导入了三个配置类: 通过这个这三个配置类可以看出,它们都使用了ConditionalOnClass注解,当类路径存在tomcat相关的类时,会配置一个T…...

【前端 | CSS】盒模型clientWidth、clientHeight、offsetWidht、offsetHeight
图 先看一个例子 html <div class"container"><div class"item">内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容内容</div> </…...

Django 高级指南:深入理解和使用类视图和中间件
Django 是一款强大的 Python Web 框架,它提供了一套完整的解决方案,让我们能够用 Python 语言快速开发和部署复杂的 Web 应用。在本文中,我们将会深入研究 Django 中的两个高级特性:类视图(Class-Based Viewsÿ…...

《C语言深度解剖》.pdf
🐇 🔥博客主页: 云曦 📋系列专栏:深入理解C语言 💨吾生也有涯,而知也无涯 💛 感谢大家👍点赞 😋关注📝评论 C语言深度解剖.pdf 提取码:yunx...
【小梦C嘎嘎——启航篇】string介绍以及日常使用的接口演示
【小梦C嘎嘎——启航篇】string 使用😎 前言🙌C语言中的字符串标准库中的string类string 比较常使用的接口对上述函数和其他函数的测试代码演示: 总结撒花💞 😎博客昵称:博客小梦 😊最喜欢的座右…...

多个 Github 账户访问 Github
文章目录 多个 Github 账户访问 Github背景步骤 参考 多个 Github 账户访问 Github 背景 如果我想在这台电脑上同时使用两个 Github 账号怎么办呢? 你主机上的 SSH 公钥只能标识出一个账号。如果需要使用另外一个git账号,访问仓库,你需要创…...

c#实现命令模式
下面是一个使用C#实现命令模式的示例代码: using System; using System.Collections.Generic;// 命令接口 public interface ICommand {void Execute();void Undo(); }// 具体命令:打开文件 public class OpenFileCommand : ICommand {private FileMana…...

Kubernetes的默认调度和自定义调度详解
默认调度和自定义调度详解 默认调度 默认调度是 Kubernetes 中的内置机制,它使用调度器组件来管理分配容器的节点。调度器依据以下原则选择合适的节点: 资源需求 :调度器会为每个 Pod 根据其 CPU 和内存需求选择一个具有足够资源的节点。亲…...

使用Spring-Security后,浏览器不能缓存的问题
Spring-Security在默认情况下是不允许客户端进行缓存的,在使用时可以通过禁用Spring-Security中的cacheControl配置项允许缓存。 protected void configure(HttpSecurity http) throws Exception {// 允许缓存配置http.headers().cacheControl().disable(); }...

中睿天下入选河南省网信系统2023年度网络安全技术支撑单位
近日,河南省委网信办发布了“河南省网信系统2023年度网络安全技术支撑单位名单”,中睿天下凭借出色的网络安全技术能力和优势成功入选。 本次遴选由河南省委网信办会同国家计算机网络与信息安全管理中心河南分中心(以下简称安全中心河南分中心…...

代码随想录day44 45 46
这部分的题目主要介绍了完全背包的内容; 主要考虑了两种情况,求组合数还是排列数 先遍历背包,再遍历物品,得到的就是组合数,也就是有顺序 for (int j 0; j < amount; j) { // 遍历背包容量for (int i 0; i <…...

一探Linux下的七大进程状态
文章目录 一、前言二、操作系统学科下的进程状态1、运行状态2、阻塞状态3、挂起状态 三、Linux下的7种进程状态1、运行状态R2、浅度睡眠状态S3、深度睡眠状态D一场有趣的官司 4、停止状态T5、进程跟踪状态t6、死亡状态X7、僵死状态Z —— 两个特殊进程① 僵尸进程② 孤儿进程 四…...

香港站群服务器为什么适合seo优化?
香港站群为什么适合seo优化?本文主要从以下四点出发进行原因阐述。 1.香港站群服务器的优势 2.香港站群服务器与国内服务器的对比 3.多IP站群服务器的优势 4.香港站群服务器在SEO优化中的注意事项 1.香港站群服务器的优势 香港站群服务器是为了满足企业SEO优化需求而提供…...

虚拟机内搭建CTFd平台搭建及CTF题库部署,局域网内机器可以访问
一、虚拟机环境搭建 1、安装docker、git、docker-compose ubuntu: sudo apt-get update #更新系统 sudo apt-get -y install docker.io #安装docker sudo apt-get -y install git #安装git sudo apt-get -y install python3-pip #安装pip3 sudo pip install dock…...
qq录屏怎么弄?手把手教会你!
“有没有人知道qq怎么录屏呀,听说qq可以录屏,刚好最近需要录制屏幕,就想用qq去录,但是找了很久,都没找到,有人知道吗,谢谢了。” 在如今数字化时代,屏幕录制已成为广泛使用的工具。…...

一文读懂c++语言
一文读懂C语言 C的发展C的设计目标C的特性C的挑战 C的发展 C是一种通用的、高级的编程语言,它是C语言的扩展。C由Bjarne Stroustrup于1983年首次引入,并在之后的几十年中不断发展壮大。C被广泛应用于各种领域,包括系统开发、游戏开发、嵌入式…...

BERT数据处理,模型,预训练
代码来自李沐老师《动手学pytorch》 在数据处理时,首先执行以下代码 def load_data_wiki(batch_size, max_len):"""加载WikiText-2数据集"""num_workers d2l.get_dataloader_workers()data_dir d2l.download_extract(wikitext-2, w…...
)
保姆级教程:在ArcGIS Pro插件中集成你的自定义工具箱(以‘消除重复要素’为例)
从脚本到按钮:ArcGIS Pro插件开发实战指南 在GIS日常工作中,我们常常会遇到一些重复性的数据处理任务。比如数据质检环节的"消除重复要素"操作,虽然可以通过Python脚本实现,但每次都需要打开IDE或Python窗口执行代码&am…...

物理引导的机器学习工作流:气候建模的融合创新与实践
1. 项目概述:当气候建模遇见机器学习如果你像我一样,在气候模拟这个领域摸爬滚打超过十年,就会深刻体会到一种“甜蜜的负担”:我们构建的地球系统模型(ESM)越来越精细,物理过程越来越复杂&#…...
)
用Python+OpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图)
用PythonOpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图) 边缘检测是计算机视觉中最基础也最关键的预处理步骤之一。想象一下,当你需要让计算机"看清"一张照片中的物体轮廓时,边缘检测算法就是它的"视觉…...

从Gamma函数到泊松分布:一个概率论中的含参量积分实用案例解析
Gamma函数与泊松分布:概率论中的数学之美 在数据科学和机器学习的实践中,概率分布构成了建模的基石。当我们深入探究这些分布背后的数学原理时,Gamma函数以其优雅的性质和广泛的应用脱颖而出。它不仅连接了离散与连续概率世界,更在…...

极致精简,功能强大的PDF编辑工具
这是一款功能全面的PDF编辑工具 你只需要导入一份PDF格式文件 就可以快速的对它进行插入 批注编辑保护转换等各种操作 而且无需登录 也可以直接使用 在插入选项中可以进行插入文字图片 页面页眉页脚页码文档背景水印视频音频等 在批注选项中可以管理批注隐藏批注 高亮显示 文本…...

2026 文章代码高亮方案选型
将基于 Prism.js 或 Highlight.js 的传统高亮方案与基于 Shiki 的现代化高亮方案进行对比,其核心区别在于底层解析原理的不同(正则表达式 vs. TextMate 语法树)。 以下是两种方案的底层原理、各自优缺点、核心对比矩阵以及适用场景的详细分析…...

yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案
yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上体验任天堂Switch游戏的魅力吗?yuzu模拟器正是你寻找的完美答案。作为…...

2026论文顶级降AI率工具大曝光:一键把AIGC率降至安全线!
步入2026年,学术圈的规则已经彻底变了味。过去那种只盯着查重率的“降重焦虑”早就被更可怕的“降AI焦虑”取代了。AI检测算法越来越聪明,高校审核标准也越来越严苛,光是把重复率压下去已经完全不够用了。现在摆在学生和科研人员面前的难题是…...

基于Cynthion逆向USB协议,为DP100电源开发Linux控制软件
1. 项目概述:用Cynthion嗅探USB,为DP100电源打造Linux软件作为一名长期在Linux环境下折腾硬件和嵌入式开发的爱好者,我经常遇到一个头疼的问题:很多不错的桌面小设备,比如电源、示波器、逻辑分析仪,它们的官…...

ubuntu环境下为python项目配置taotoken多模型api密钥与端点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Ubuntu环境下为Python项目配置Taotoken多模型API密钥与端点 1. 准备工作 在Ubuntu系统上为Python项目接入Taotoken,首…...