Flink多流处理之coGroup(协同分组)
这篇文章主要介绍协同分组coGroup的使用,先讲解API代码模板,后面会结图解介绍coGroup是如何将流中数据进行分组的.
1 API介绍
- 数据源
# 左流数据 ➜ ~ nc -lk 6666 101,Tom 102,小明 103,小黑 104,张强 105,Ken 106,GG小日子 107,小花 108,赵宣艺 109,明亮# 右流数据 ➜ ~ nc -lk 7777 101,男,本科,程序员 102,男,本科,程序员 103,女,本科,会计 104,男,大专,安全工程师 105,男,硕士,律师 106,未知,小本,挖粪使者 108,女,本科,人事 110,男,本科,算法工程师 - 代码
import org.apache.flink.api.common.functions.CoGroupFunction; import org.apache.flink.api.common.typeinfo.TypeHint; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.api.java.tuple.Tuple4; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.util.Collector;/*** @Author: J* @Version: 1.0* @CreateTime: 2023/8/10* @Description: 协同分组**/ public class FlinkCoGroup {public static void main(String[] args) throws Exception {// 构建流环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 设置并行度env.setParallelism(2);// 数据源1(socket数据源),为了方便测试,根据实际情况自行选择DataStreamSource<String> sourceStream1 = env.socketTextStream("localhost", 6666);// 将数据进行切分返回Tuple2(id,name)SingleOutputStreamOperator<Tuple2<String, String>> mapStream1 = sourceStream1.map(value -> {String[] split = value.split(",");return Tuple2.of(split[0], split[1]);}).returns(new TypeHint<Tuple2<String, String>>() {});// 数据源2(socket数据源),为了方便测试,根据实际情况自行选择DataStreamSource<String> sourceStream2 = env.socketTextStream("localhost", 7777);// 将数据进行切分返回Tuple4(id,gender,education,job)SingleOutputStreamOperator<Tuple4<String, String, String, String>> mapStream2 = sourceStream2.map(value -> {String[] split = value.split(",");return Tuple4.of(split[0], split[1], split[2], split[3]);}).returns(new TypeHint<Tuple4<String, String, String, String>>() {});// 数据流协同DataStream<Tuple4<String, String, String, String>> coGrouped = mapStream1.coGroup(mapStream2).where(tup -> tup.f0) // 左流协同分组字段(mapStream1).equalTo(tup -> tup.f0) // 右流协同分组字段(mapStream2).window(TumblingProcessingTimeWindows.of(Time.seconds(20))) // 开窗口,以处理时间划分(每20秒一个窗口).apply(new CoGroupFunction<Tuple2<String, String>, Tuple4<String, String, String, String>, Tuple4<String, String, String, String>>() {@Overridepublic void coGroup(Iterable<Tuple2<String, String>> first, Iterable<Tuple4<String, String, String, String>> second, Collector<Tuple4<String, String, String, String>> out) throws Exception {/***first 代表左流的迭代器* second 代表右流的迭代器* out 则是返回的数据形式* 具体方法中两个迭代器存数据的原理后续会通过图结合进行解析**/// 这里的逻辑模拟sql中left join// 遍历左流数据(first)for (Tuple2<String, String> left : first) {// 定义右流是否为NULL判断标识boolean flag = false;// 遍历右流数据(second)for (Tuple4<String, String, String, String> right : second) {// 返回left(id, name) + right(gender, education)Tuple4<String, String, String, String> tup4 = Tuple4.of(left.f0, left.f1, right.f1, right.f2);// 输出out.collect(tup4);// 修改判断标识flag = true;}// 如果右流为NULL,则输出左流的数据if (!flag) {// 这里用字符串"NULL"代替null值,方便观察Tuple4<String, String, String, String> tup4 = Tuple4.of(left.f0, left.f1, "NULL", "NULL");// 输出out.collect(tup4);}}}});// 打印结果coGrouped.print();env.execute("Flink CoGroup");} } - 结果
从数据源和结果数据可以看到和代码逻辑是完全吻合的.2> (102,小明,男,本科) 1> (106,GG小日子,未知,小本) 2> (109,明亮,NULL,NULL) 1> (107,小花,NULL,NULL) 2> (105,Ken,男,硕士) 2> (103,小黑,女,本科) 2> (101,Tom,男,本科) 2> (108,赵宣艺,女,本科) 2> (104,张强,男,大专)
2 原理解析
我这我们先看一下图解,如下
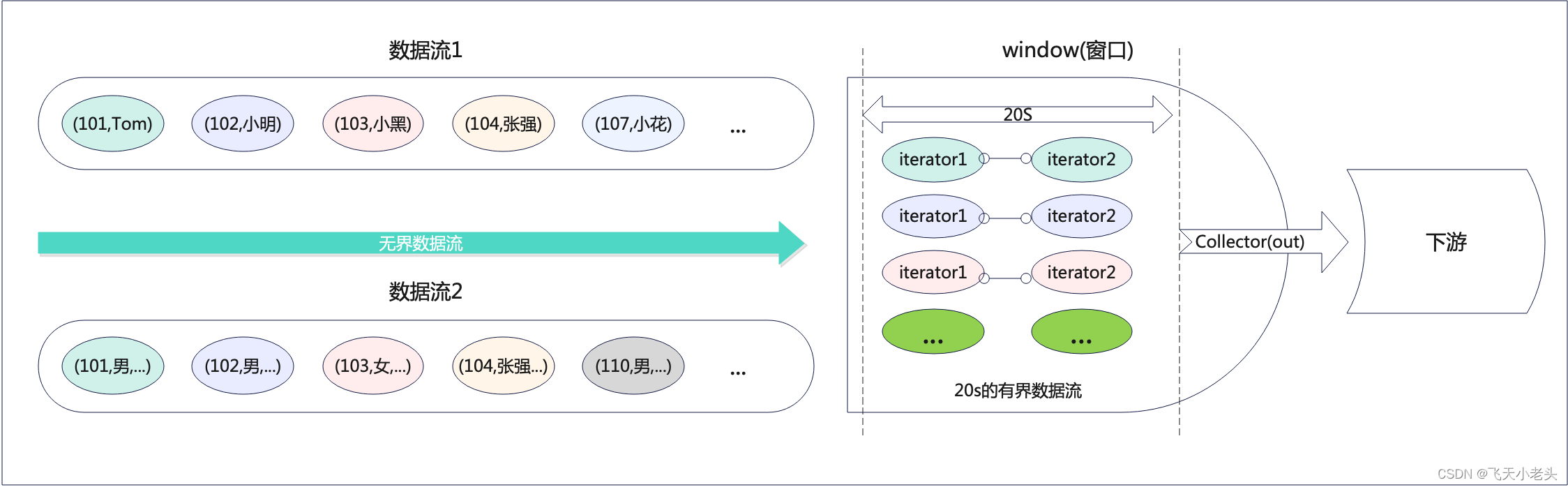
- 无界转有界
在代码中我们开启window,这也是使用coGroup的必要条件,开启window后实际上就是将我们原本的无界数据流转变成一个以20S为界限的有界数据流. - 迭代器分组
将数据进入到窗口内后,就会根据经我们前面设定的条件也就是.where和.equalTo中的内容将mapStream1和mapStream2中的数据根据key进行分组存储到不同的iterator中. - 逻辑计算
上面已经将数据根据key都存储到iterator中了,这里就会根据我们在new CoGroupFunction<...>(){...}中的写的逻辑将mapStream1和mapStream2中具有相同key的iterator进行计算. - 输出
当一个window结束后,就会将数据按照计算后的结果(在代码中就是Tuple4<String, String, String, String>)输出到下游.
相关文章:
Flink多流处理之coGroup(协同分组)
这篇文章主要介绍协同分组coGroup的使用,先讲解API代码模板,后面会结图解介绍coGroup是如何将流中数据进行分组的. 1 API介绍 数据源# 左流数据 ➜ ~ nc -lk 6666 101,Tom 102,小明 103,小黑 104,张强 105,Ken 106,GG小日子 107,小花 108,赵宣艺 109,明亮# 右流数据 ➜ ~ n…...
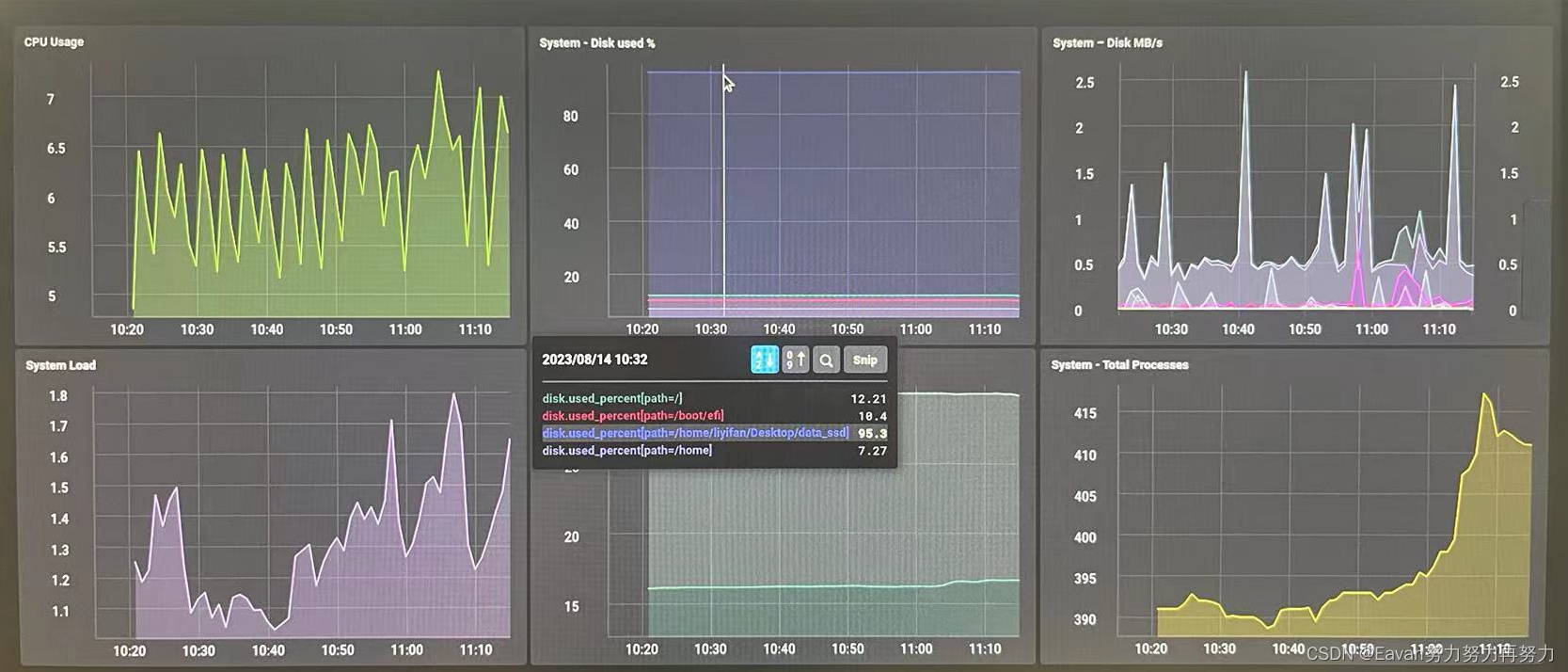
基于TICK的DevOps监控实战(Ubuntu20.04系统,Telegraf+InfluDB+Chronograf+Kapacitor)
1、TICK简介 TICK是InfluxData开发的开源高性能时序中台,集成了采集、存储、分析、可视化等能力,由Telegraf, InfluDB, Chronograf, Kapacitor等4个组件以一种灵活松散、但又紧密配合,互为补充的方式构成。TICK专注于DevOps监控、IoT监控、实…...
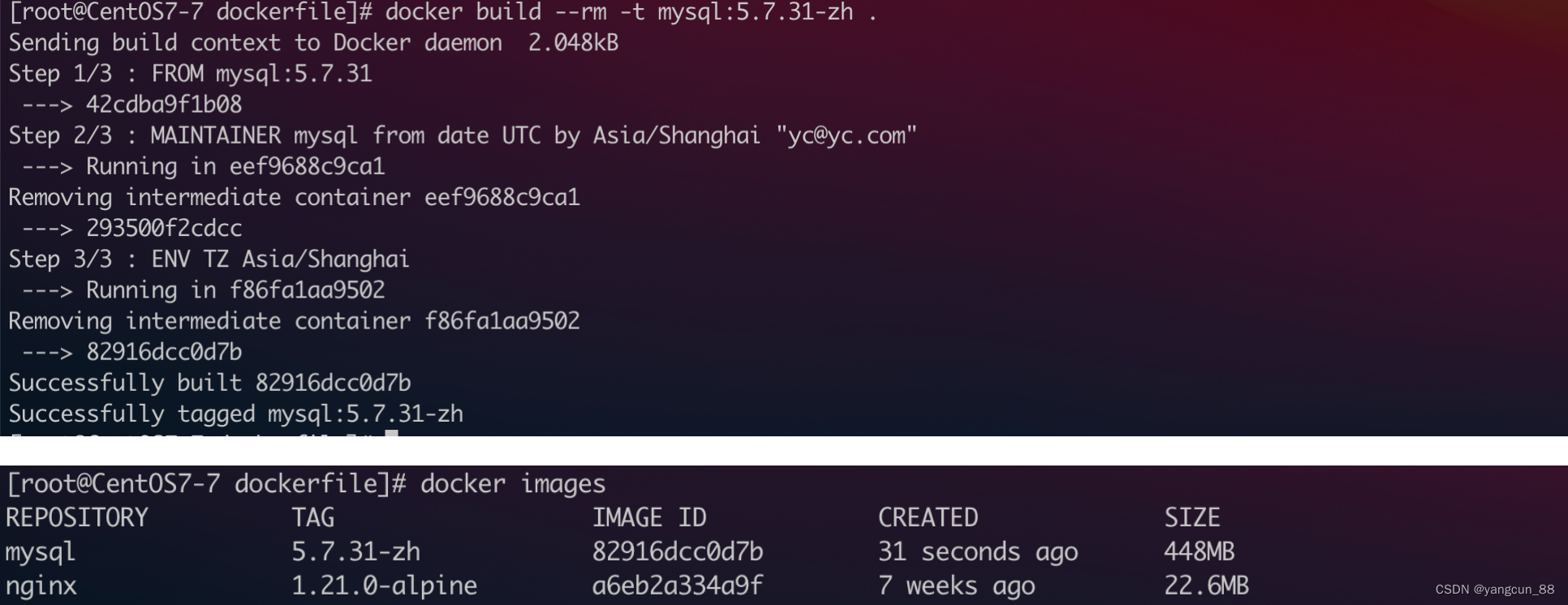
十九、docker学习-Dockerfile
Dockerfile 官网地址 https://docs.docker.com/engine/reference/builder/Dockerfile其实就是我们用来构建Docker镜像的源码,当然这不是所谓的编程源码,而是一些命令的集合,只要理解它的逻辑和语法格式,就可以很容易的编写Docke…...
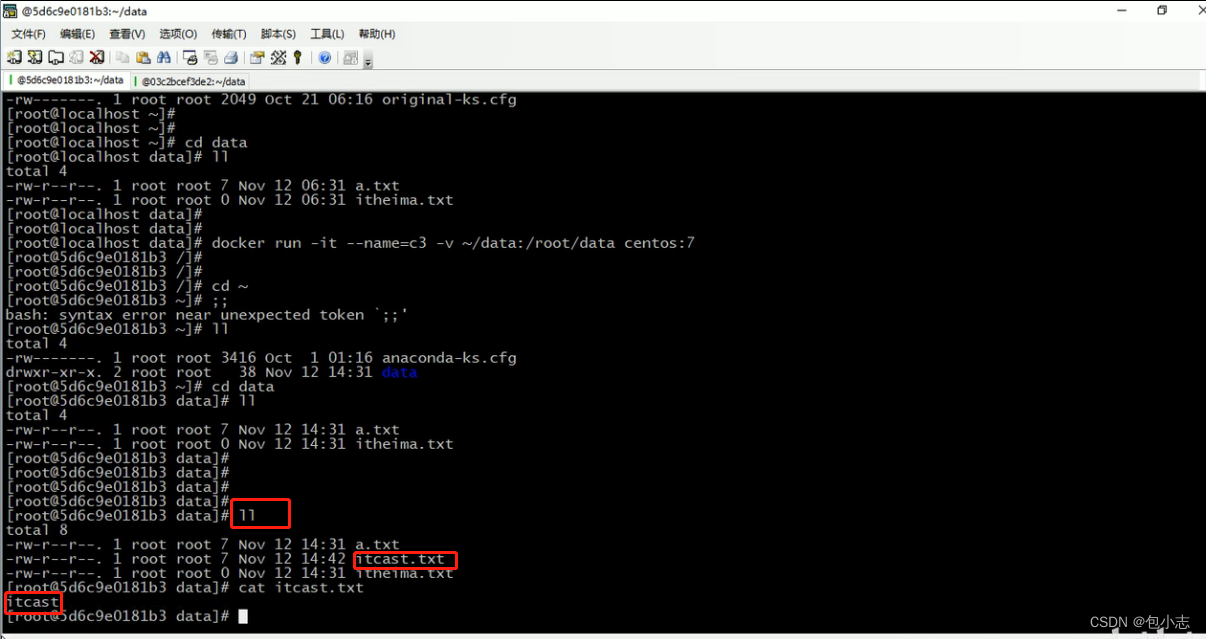
Docker容器的数据卷
1.数据卷的概念及作用 2.数据卷的配置 创建容器并挂载数据卷: docker run -it --namec1 -v /root/data:/root/data_container centos:7 /bin/bash按照容器挂载数据卷的原理,data_contianer这个目录下也会同步下来数据的更改。 3.一个容器挂载多个数据…...
推荐工具!使终端便于 DevOps 和 Kubernetes 使用
如果你熟悉 DevOps 和 Kubernetes 的使用,就会知道命令行界面(CLI)对于管理任务有多么重要。好在现在市面上有一些工具可以让终端在这些环境中更容易使用。在本文中,我们将探讨可以让工作流程简化的优秀工具,帮助你在 …...
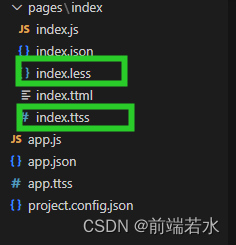
抖音小程序实现less语言编译样式
1.在抖音开发工具中搜索扩展less 2. 然后点击小齿轮选择扩展设置 3. 然后在扩展设置中选择在settings.json中编辑# 4. 在settings.json中加入以下这段代码即可 // Easy LESS配置"less.compile": {"compress": false,//是否压缩"sourceMap": fal…...

介绍 TensorFlow 的基本概念和使用场景
TensorFlow 是一种开源的机器学习框架,由 Google 开发。它是用来构建和训练机器学习模型的强大工具,支持很多种不同类型的机器学习算法,并使用数据流图来表示计算过程。 TensorFlow 的核心是张量 (Tensor) 和计算图 (Graph)。 张量 (Tensor)…...
抖音关键词搜索小程序排名怎么做
抖音关键词搜索小程序排名怎么做 1 分钟教你制作一个抖音小程序。 抖音小程序就是我的视频,左下方这个蓝色的链接,点进去就是抖音小程序。 如果你有了这个小程序,发布视频的时候可以挂载这个小程序,直播的时候也可以挂载这个小…...
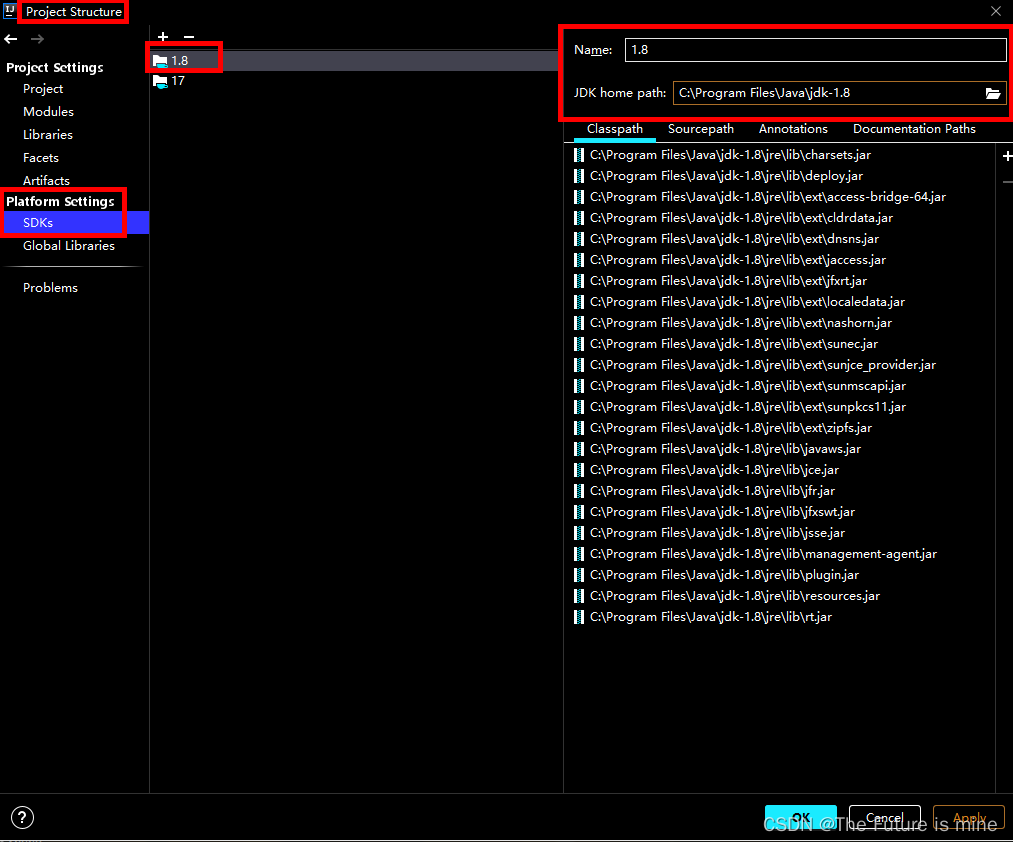
Windows下升级jdk1.8小版本
1.首先下载要升级jdk最新版本,下载地址:Java Downloads | Oracle 中国 2.下载完毕之后,直接双击下载完毕后的文件,进行安装。 3.安装完毕后,调整环境变量至新安装的jdk位置 4.此时,idea启动项目有可能会出…...
[保研/考研机试] KY235 进制转换2 清华大学复试上机题 C++实现
题目链接: KY235 进制转换2 https://www.nowcoder.com/questionTerminal/ae4b3c4a968745618d65b866002bbd32 描述 将M进制的数X转换为N进制的数输出。 输入描述: 输入的第一行包括两个整数:M和N(2<M,N<36)。 下面的一行输入一个数…...
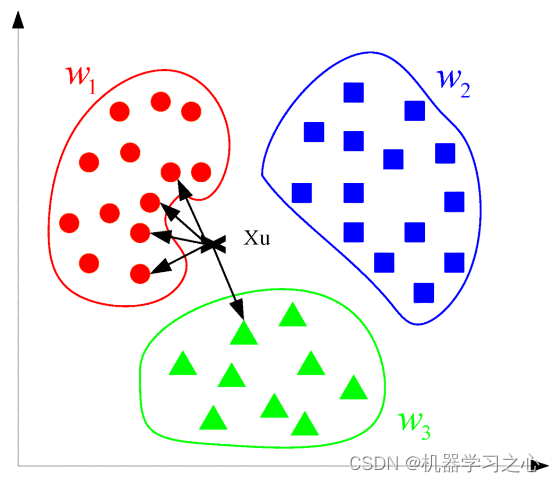
机器学习 | Python实现KNN(K近邻)模型实践
机器学习 | Python实现KNN(K近邻)模型实践 目录 机器学习 | Python实现KNN(K近邻)模型实践基本介绍模型原理源码设计学习小结参考资料基本介绍 一句话就可以概括出KNN(K最近邻算法)的算法原理:综合k个“邻居”的标签值作为新样本的预测值。更具体来讲KNN分类过程,给定一个训…...
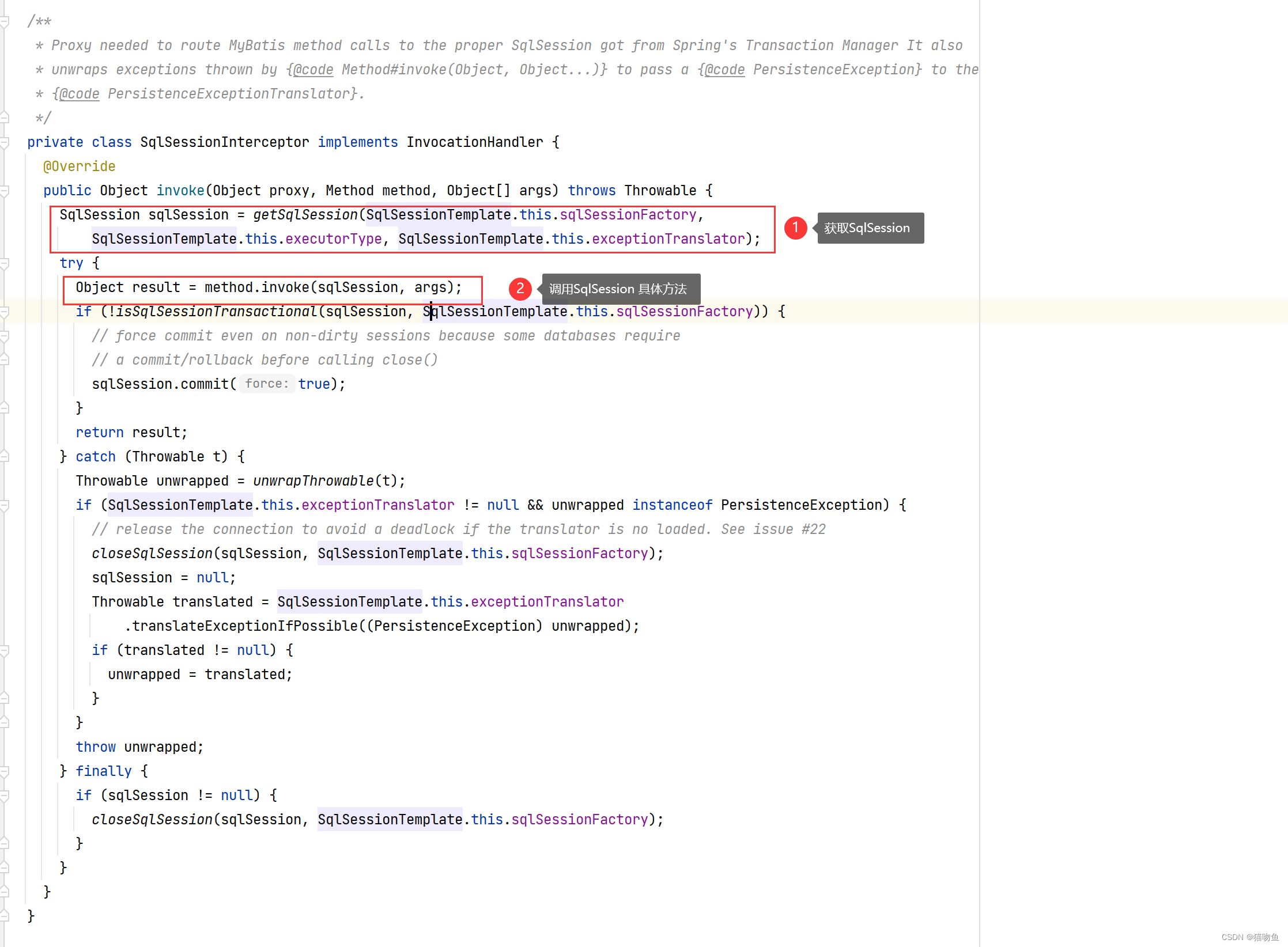
Mybatis 源码 ③ :SqlSession
一、前言 Mybatis 官网 以及 本系列文章地址: Mybatis 源码 ① :开篇Mybatis 源码 ② :流程分析Mybatis 源码 ③ :SqlSessionMybatis 源码 ④ :TypeHandlerMybatis 源码 ∞ :杂七杂八 在 Mybatis 源码 ②…...

Python 潮流周刊#15:如何分析异步任务的性能?
△点击上方“Python猫”关注 ,回复“1”领取电子书 你好,我是猫哥。这里每周分享优质的 Python、AI 及通用技术内容,大部分为英文。标题取自其中一则分享,不代表全部内容都是该主题,特此声明。 本周刊精心筛选国内外的…...
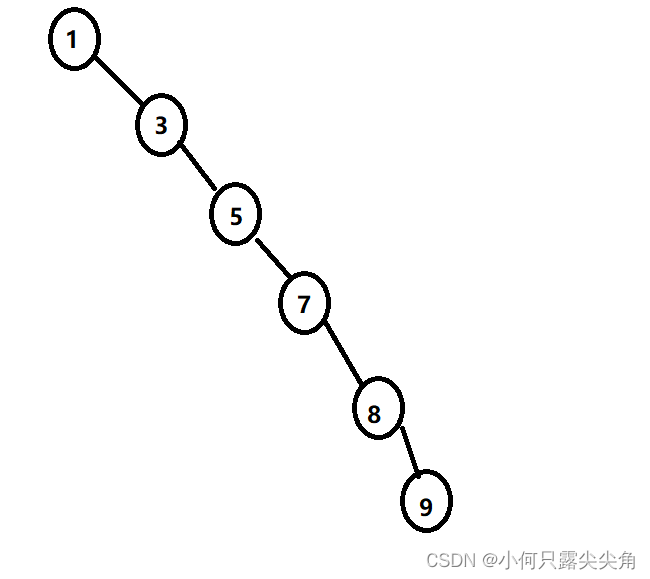
二叉搜索树K和KV结构模拟
一 什么是二叉搜索树 这个的结构特性非常重要,是后面函数实现的结构基础,二叉搜索树的特性是每个根节点都比自己的左树任一节点大,比自己的右树任一节点小。 例如这个图, 41是根节点,要比左树大,比右树小&…...

nlohmann json:检查object是否存在某个键
1.通过find进行检查 #include <iostream> #include <nlohmann/json.hpp> using namespace std; using json = nlohmann::json;int main() {json data = R"({"name": "xiaoming","age": 10, "parent": [{"fat…...
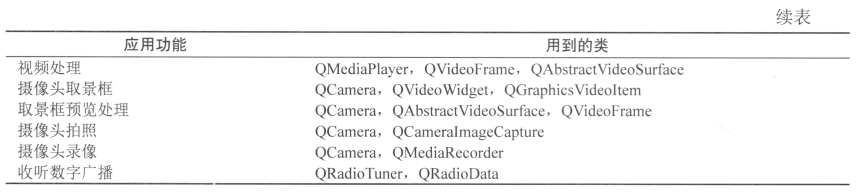
15-1_Qt 5.9 C++开发指南_Qt多媒体模块概述
多媒体功能指的主要是计算机的音频和视频的输入、输出、显示和播放等功能,Qt 的多媒体模块为音频和视频播放、录音、摄像头拍照和录像等提供支持,甚至还提供数字收音机的支持。本章将介绍 Qt 多媒体模块的功能和使用。 文章目录 1. Qt 多媒体模块概述2. …...

分页查询中起始位置的计算
在分页查询中,page 和 pageSize 其实就是表示页数和每页的条数。这两个参数通常用于在数据库查询时进行分页。 如果你想根据 page 和 pageSize 计算数据的起始位置(例如,MySQL数据库的LIMIT查询),可以使用以下公式&am…...

Failed to execute goal org.apache.maven.plugins
原因: 这个文件D:\java\maven\com\ruoyi\pg-student\maven-metadata-local.xml出了问题 解决: 最简单的直接删除D:\java\maven\com\ruoyi\pg-student\maven-metadata-local.xml重新打包 或者把D:\java\maven\com\ruoyi\pg-student这个目录下所有文件…...

50吨收费站生活一体化污水处理设备厂家价格低
50吨收费站生活一体化污水处理设备厂家价格低 设备工艺说明 污水处理设备主要用于生活污水和与之类似的工业有机废水的处理,其主要处理方法是采用目前较为成熟的生化处理技术—生物接触氧化,水质设计按一般生活污水水质设计计算,按BOD5平均20…...
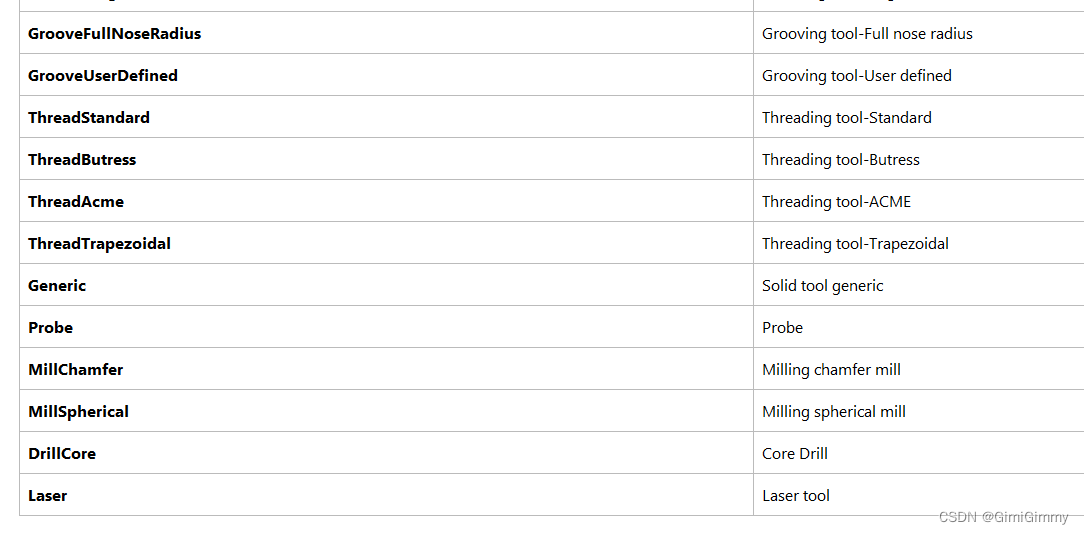
UG NX二次开发(C#)-CAM-获取刀具类型
文章目录 1、前言2、UG NX中的刀具类型3、获取刀具类型3.1 刀具类型帮助文档1、前言 在UG NX的加工模块,加工刀具是一个必要的因素,其包括了多种类型的类型,有铣刀、钻刀、车刀、磨刀、成型刀等等,而且每种刀具所包含的信息也各不相同。想获取刀具的信息,那就要知道刀具的…...

基于LM22678的树莓派硬盘专用电源设计:解决供电不稳与电流冲击
1. 项目概述:为什么我们需要一个“专用”电源?如果你正在用树莓派搭配一块机械硬盘搭建一个家庭服务器或者个人云存储,可能已经遇到了一个不大不小的麻烦:供电不稳。树莓派官方推荐的5V/3A电源,单独带树莓派4B跑满负载…...

GitLab External Wiki代理权限绕过漏洞深度解析
1. 这个漏洞不是“修个补丁”就能完事的——它暴露的是 GitLab 权限模型里一个被长期忽视的逻辑断层GitLab 安全漏洞 CVE-2025-2614,光看编号容易误以为是又一个常规的越权或 XSS 类型漏洞。但我在实际复现和审计过程中发现,它根本不是配置疏漏或代码拼写…...

Burp Suite深度解析:从流量抓包到业务逻辑漏洞挖掘
1. 这不是“学个插件”——Burp Suite 是渗透测试的呼吸系统 很多人第一次听说 Burp Suite,是在某篇“三步拿下登录框”的速成教程里:装好Java、拖进浏览器代理、点几下Repeater就弹出密码明文。结果真去测一个中型SaaS后台,不到十分钟就卡在…...

DragonBones与Godot集成:骨骼动画的可编程化实践
1. 为什么在Godot里用DragonBones不是“锦上添花”,而是“绕不开的刚需” 去年上线一个横版动作手游Demo时,美术团队交来一套20个角色、每个角色含8套动画(待机/跑动/跳跃/攻击/受击/死亡/闪避/必杀)的Spine资源。我兴冲冲导入God…...
)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)当你的UE5 RPG项目发展到中期,技能数量从十几个膨胀到几十个时,最痛苦的莫过于发现InputAction绑定已经变成一团乱麻。每次新增技能都要修改输入绑定逻辑&a…...

【与我学 ClaudeCode】协作篇 之 Worktree + Task Isolation :目录隔离的并行执行通道
作者:逆境不可逃 技术永无止境 希望我的内容可以帮助到你!!!! 大家吼 ! 我是 逆境不可逃 今天给大家带来文章《【与我学 ClaudeCode】协作篇 之 Worktree Task Isolation :目录隔离的并行执行通道》. Le…...

基于MAX78000的离线鸟类声音识别:边缘AI从数据到部署全流程解析
1. 项目概述:当边缘AI“听懂”鸟鸣在野外生态监测或自家后院观鸟时,你是否有过这样的经历:听到一阵清脆或婉转的鸟鸣,却完全不知道是哪位“歌唱家”在表演?传统的鸟类识别依赖专家经验和图鉴比对,不仅门槛高…...
原理与ScalableHD架构优化实践)
超维计算(HDC)原理与ScalableHD架构优化实践
1. 超维计算(HDC)基础解析超维计算(Hyperdimensional Computing, HDC)是一种受大脑信息处理机制启发的计算范式,其核心思想是用高维随机向量(通常称为超向量或HV)来表示和处理信息。与传统神经网…...

TorchDynamo与TorchInductor:PyTorch编译器生态的完整解析
TorchDynamo与TorchInductor:PyTorch编译器生态的完整解析 【免费下载链接】torchdynamo A Python-level JIT compiler designed to make unmodified PyTorch programs faster. 项目地址: https://gitcode.com/gh_mirrors/to/torchdynamo TorchDynamo 是一个…...
)
在线文档协作工具选型必看:14款产品对比(2026版)
一、在线文档协作工具的概念解析及其核心功能 在线文档协作工具是基于云端的文档创建、编辑、共享与协同沟通平台,核心目标是让团队在同一份资料上“实时共同工作”,减少反复传文件、版本混乱与沟通成本。 企业常见的核心能力包括: 多人实…...