yolov5、YOLOv7、YOLOv8改进:注意力机制CA
目录
1.背景介绍
论文题目:《Coordinate Attention for Efficient Mobile NetWork Design》论文地址: https://arxiv.org/pdf/2103.02907.pdf
2.原理介绍
3.YOLOv5改进:
3.1common中加入下面代码
3.2在yolo.py中注册
3.3添加配置文件
4.yolov7改进
4.1 在common中加入以下代码
4.2在yolo.py中注册
4.3添加配置文件
1.背景介绍
论文题目:《Coordinate Attention for Efficient Mobile NetWork Design》
论文地址: https://arxiv.org/pdf/2103.02907.pdf

2.原理介绍
本文中,作者通过将位置信息嵌入到通道注意力中提出了一种新颖的移动网络注意力机制,将其称为“Coordinate Attention”。与通过2维全局池化将特征张量转换为单个特征向量的通道注意力不同,Coordinate注意力将通道注意力分解为两个1维特征编码过程,分别沿2个空间方向聚合特征。这样,可以沿一个空间方向捕获远程依赖关系,同时可以沿另一空间方向保留精确的位置信息。然后将生成的特征图分别编码为一对方向感知和位置敏感的attention map,可以将其互补地应用于输入特征图,以增强关注对象的表示。
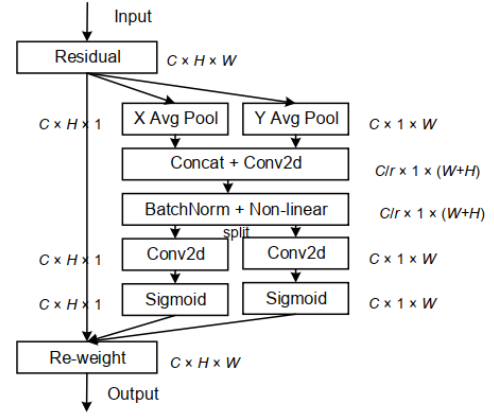
step1: 为了避免空间信息全部压缩到通道中,这里没有使用全局平均池化。为了能够捕获具有精准位置信息的远程空间交互,对全局平均池化进行的分解,具体如下:
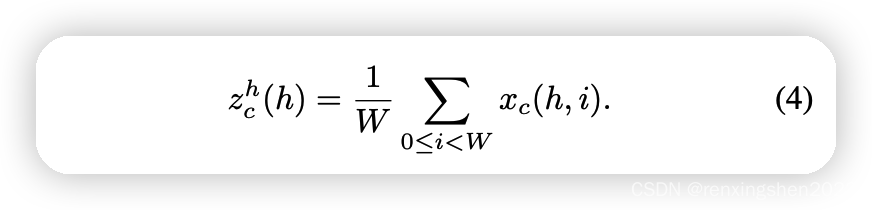

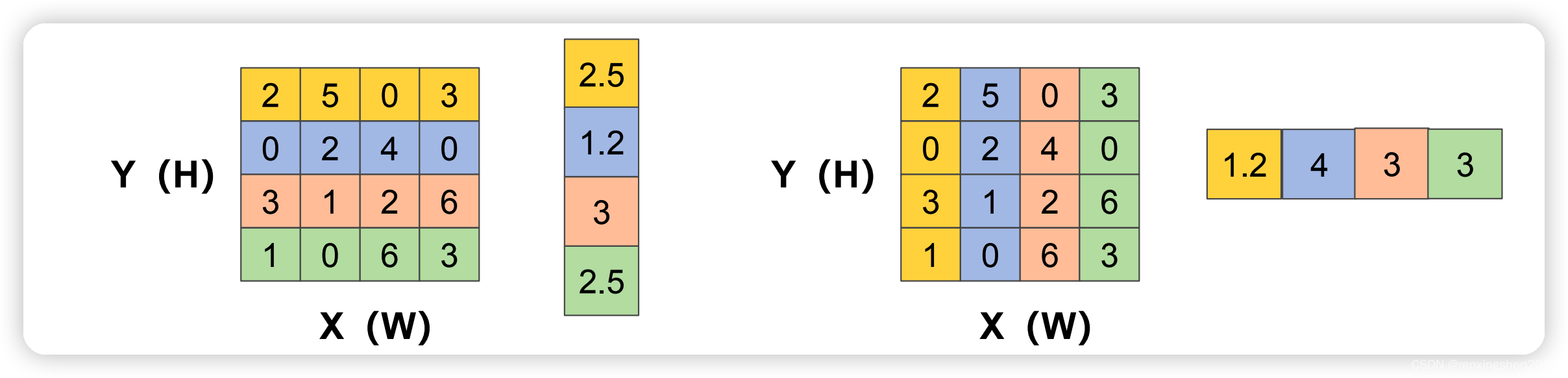
对尺寸为C ∗ H ∗ W C*H*WC∗H∗W输入特征图I n p u t InputInput分别按照X XX方向和Y YY方向进行池化,分别生成尺寸为C ∗ H ∗ 1 C*H*1C∗H∗1和C ∗ 1 ∗ W C*1*WC∗1∗W的特征图。如下图所示(图片粘贴自B站大佬渣渣的熊猫潘)。
step2:将生成的C ∗ 1 ∗ W C*1*WC∗1∗W的特征图进行变换,然后进行concat操作。公式如下:
..................
最后:Coordinate Attention 的输出公式可以写成:

不同于通道注意力将输入通过2D全局池化转化为单个特征向量,CoordAttention将通道注意力分解为两个沿着不同方向聚合特征的1D特征编码过程。这样的好处是可以沿着一个空间方向捕获长程依赖,沿着另一个空间方向保留精确的位置信息。然后,将生成的特征图分别编码,形成一对方向感知和位置敏感的特征图,它们可以互补地应用到输入特征图来增强感兴趣的目标的表示
3.YOLOv5改进:
3.1 common中加入下面代码
class h_sigmoid(nn.Module):def __init__(self, inplace=True):super(h_sigmoid, self).__init__()self.relu = nn.ReLU6(inplace=inplace)def forward(self, x):return self.relu(x + 3) / 6class h_swish(nn.Module):def __init__(self, inplace=True):super(h_swish, self).__init__()self.sigmoid = h_sigmoid(inplace=inplace)def forward(self, x):return x * self.sigmoid(x)
class CA(nn.Module):# Coordinate Attention for Efficient Mobile Network Design'''Recent studies on mobile network design have demonstrated the remarkable effectiveness of channel attention (e.g., the Squeeze-and-Excitation attention) for liftingmodel performance, but they generally neglect the positional information, which is important for generating spatially selective attention maps. In this paper, we propose anovel attention mechanism for mobile iscyy networks by embedding positional information into channel attention, whichwe call “coordinate attention”. Unlike channel attentionthat transforms a feature tensor to a single feature vector iscyy via 2D global pooling, the coordinate attention factorizes channel attention into two 1D feature encoding processes that aggregate features along the two spatial directions, respectively'''def __init__(self, inp, oup, reduction=32):super(CA, self).__init__()mip = max(8, inp // reduction)self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)self.bn1 = nn.BatchNorm2d(mip)self.act = h_swish()self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)def forward(self, x):identity = xn,c,h,w = x.size()pool_h = nn.AdaptiveAvgPool2d((h, 1))pool_w = nn.AdaptiveAvgPool2d((1, w))x_h = pool_h(x)x_w = pool_w(x).permute(0, 1, 3, 2)y = torch.cat([x_h, x_w], dim=2)y = self.conv1(y)y = self.bn1(y)y = self.act(y) x_h, x_w = torch.split(y, [h, w], dim=2)x_w = x_w.permute(0, 1, 3, 2)a_h = self.conv_h(x_h).sigmoid()a_w = self.conv_w(x_w).sigmoid()out = identity * a_w * a_hreturn out
3.2在yolo.py中注册
找到parse.model模块 加入下列代码
elif m in [CA]:c1, c2 = ch[f], args[0]if c2 != no: # if not outputssc2 = make_divisible(c2 * gw, 8)args = [c1, c2, *args[1:]]
3.3添加配置文件
# YOLOv5 🚀, GPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth iscyy multiple
width_multiple: 0.50 # layer channel iscyy multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[-1, 1, CA, [1024]],[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
到此YOLOv5就改好了
4.yolov7改进
4.1 在common中加入以下代码
class h_sigmoid(nn.Module):def __init__(self, inplace=True):super(h_sigmoid, self).__init__()self.relu = nn.ReLU6(inplace=inplace)def forward(self, x):return self.relu(x + 3) / 6class h_swish(nn.Module):def __init__(self, inplace=True):super(h_swish, self).__init__()self.sigmoid = h_sigmoid(inplace=inplace)def forward(self, x):return x * self.sigmoid(x)
class CA(nn.Module):# Coordinate Attention for Efficient Mobile Network Design'''Recent studies on mobile network design have demonstrated the remarkable effectiveness of channel attention (e.g., the Squeeze-and-Excitation attention) for liftingmodel performance, but they generally neglect the positional information, which is important for generating spatially selective attention maps. In this paper, we propose anovel attention mechanism for mobile iscyy networks by embedding positional information into channel attention, whichwe call “coordinate attention”. Unlike channel attentionthat transforms a feature tensor to a single feature vector iscyy via 2D global pooling, the coordinate attention factorizes channel attention into two 1D feature encoding processes that aggregate features along the two spatial directions, respectively'''def __init__(self, inp, oup, reduction=32):super(CA, self).__init__()mip = max(8, inp // reduction)self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)self.bn1 = nn.BatchNorm2d(mip)self.act = h_swish()self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)def forward(self, x):identity = xn,c,h,w = x.size()pool_h = nn.AdaptiveAvgPool2d((h, 1))pool_w = nn.AdaptiveAvgPool2d((1, w))x_h = pool_h(x)x_w = pool_w(x).permute(0, 1, 3, 2)y = torch.cat([x_h, x_w], dim=2)y = self.conv1(y)y = self.bn1(y)y = self.act(y) x_h, x_w = torch.split(y, [h, w], dim=2)x_w = x_w.permute(0, 1, 3, 2)a_h = self.conv_h(x_h).sigmoid()a_w = self.conv_w(x_w).sigmoid()out = identity * a_w * a_hreturn out
4.2在yolo.py中注册
找到parse.model模块 加入下列代码
elif m in [CA]:c1, c2 = ch[f], args[0]if c2 != no: # if not outputssc2 = make_divisible(c2 * gw, 8)args = [c1, c2, *args[1:]]
4.3添加配置文件
# YOLOv7 🚀, GPL-3.0 license
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel iscyy multiple# anchors
anchors:- [12,16, 19,36, 40,28] # P3/8- [36,75, 76,55, 72,146] # P4/16- [142,110, 192,243, 459,401] # P5/32# yolov7 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [32, 3, 1]], # 0[-1, 1, Conv, [64, 3, 2]], # 1-P1/2[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [128, 3, 2]], # 3-P2/4 [-1, 1, C3, [128]], [-1, 1, Conv, [256, 3, 2]], [-1, 1, MP, []],[-1, 1, Conv, [128, 1, 1]],[-3, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [128, 3, 2]],[[-1, -3], 1, Concat, [1]], # 16-P3/8[-1, 1, Conv, [128, 1, 1]],[-2, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [512, 1, 1]],[-1, 1, MP, []],[-1, 1, Conv, [256, 1, 1]],[-3, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 2]],[[-1, -3], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [1024, 1, 1]], [-1, 1, MP, []],[-1, 1, Conv, [512, 1, 1]],[-3, 1, Conv, [512, 1, 1]],[-1, 1, Conv, [512, 3, 2]],[[-1, -3], 1, Concat, [1]],[-1, 1, C3, [1024]],[-1, 1, Conv, [256, 3, 1]],]# yolov7 head by iscyy
head:[[-1, 1, SPPCSPC, [512]],[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[31, 1, Conv, [256, 1, 1]],[[-1, -2], 1, Concat, [1]],[-1, 1, C3, [128]],[-1, 1, Conv, [128, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[18, 1, Conv, [128, 1, 1]],[[-1, -2], 1, Concat, [1]],[-1, 1, C3, [128]],[-1, 1, MP, []],[-1, 1, Conv, [128, 1, 1]],[-3, 1, CA, [128]],[-1, 1, Conv, [128, 3, 2]],[[-1, -3, 44], 1, Concat, [1]],[-1, 1, C3, [256]], [-1, 1, MP, []],[-1, 1, Conv, [256, 1, 1]],[-3, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 2]], [[-1, -3, 39], 1, Concat, [1]],[-1, 3, C3, [512]],# 检测头 -----------------------------[49, 1, RepConv, [256, 3, 1]],[55, 1, RepConv, [512, 3, 1]],[61, 1, RepConv, [1024, 3, 1]],[[62,63,64], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)]
至此v7就配置完成了
v8的配置同v5是一样的。
CA不仅考虑到空间和通道之间的关系,还考虑到长程依赖问题。通过实验发现,CA不仅可以实现精度提升,且参数量、计算量较少。
如果修改的过程中,有遇到其他问题,欢迎评论区留言,大家一起学习进步。
相关文章:
yolov5、YOLOv7、YOLOv8改进:注意力机制CA
目录 1.背景介绍 论文题目:《Coordinate Attention for Efficient Mobile NetWork Design》论文地址: https://arxiv.org/pdf/2103.02907.pdf 2.原理介绍 3.YOLOv5改进: 3.1common中加入下面代码 3.2在yolo.py中注册 3.3添加配置文件 …...

LeetCode解法汇总617. 合并二叉树
目录链接: 力扣编程题-解法汇总_分享记录-CSDN博客 GitHub同步刷题项目: https://github.com/September26/java-algorithms 原题链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 描述: 给你两棵二…...

记vite打包vue项目内存溢出问题解决
出现问题 FATAL ERROR: Ineffective mark-compacts near heap limit Allocation failed - JavaScript heap out of memory解决方法一: 1.根据网上的资料是通过全局下载npm包increase-memory-limit: npm install -g increase-memory-limit2.在项目目录执…...
技术、传感器网络的结合研究)
【SCI征稿】2区SCI,大数据与遥感技术、图像处理技术、物联网(IoT)技术、传感器网络的结合研究
期刊简介: 【出版社】Elsevier 【影响因子】IF(2022):3.0-4.0 【期刊分区】JCR2区,中科院4区 【检索情况】SCIE 在检,正刊 【参考周期】期刊部系统内提交,预计3个月左右录用,走…...

java_基础语法及用法
文章目录 一、java基础1.1 JAVAEE的13个规范 二、java基础语法2.1 final2.2 static2.3 异常 三、java基础用法3.1 时间格式化3.2 java计时 一、java基础 1.1 JAVAEE的13个规范 JAVA EE的十三种规范 二、java基础语法 2.1 final 1.被final修饰的类不可以被继承 2.被final修…...
C# WPF 开源主题 HandyControl 的使用(一)
HandyControl是一套WPF控件库,它几乎重写了所有原生样式,同时包含80余款自定义控件(正逐步增加),下面我们开始使用。 1、准备 1.1 创建项目 C# WPF应用(.NET Framework)创建项目 1.2 添加包 1.3 在App.xaml中引用…...
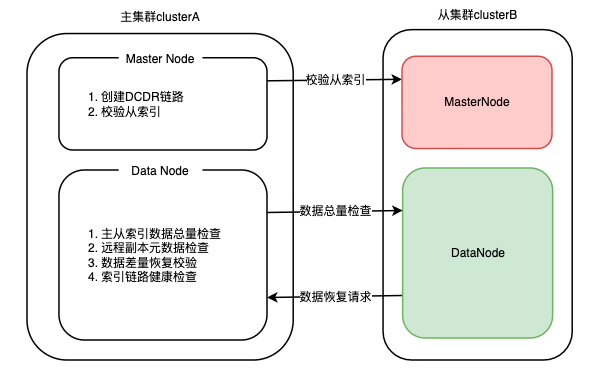
探索ES高可用:滴滴自研跨数据中心复制技术详解
Elasticsearch 是一个基于Lucene构建的开源、分布式、RESTful接口的全文搜索引擎,其每个字段均可被索引,且能够横向扩展至数以百计的服务器存储以及处理TB级的数据,其可以在极短的时间内存储、搜索和分析大量的数据。 滴滴ES发展至今…...

指针---进阶篇(二)
指针---进阶篇(二) 前言一、函数指针1.抛砖引玉2.如何判断函数指针?(方法总结) 二、函数指针数组1.什么是函数指针数组?2.讲解函数指针数组3.模拟计算器:讲解函数指针数组 三、指向函数指针数组…...
Python实现SSA智能麻雀搜索算法优化循环神经网络分类模型(LSTM分类算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 麻雀搜索算法(Sparrow Search Algorithm, SSA)是一种新型的群智能优化算法,在2020年提出&a…...

【go语言基础】结构体struct
主要是敲代码,敲的过程中会慢慢体会。 1.概念 结构体是用户定义的类型,表示若干字段的集合,目的是将数据整合在一起。 简单的说,类似Java中的实体类。存储某个实体属性的集合。 2.结构体声明 注意:结构体名字&…...

显卡服务器适用于哪些场景
显卡(GPU)服务器,简单来说,GPU服务器是基于GPU的应用于视频编解码、深度学习、科学计算等多种场景的快速、 稳定、弹性的计算服务。那么壹基比小鑫告诉你显卡服务器主要的用途有哪一些。 一、运行手机模拟器 显卡服务器可支持…...

MySQL DML 数据操作
文章目录 1.插入记录INSERTREPLACE 2.删除记录3.修改记录4.备份还原数据参考文献 1.插入记录 INSERT 使用 INSERT INTO 语句可以向数据表中插入数据。INSET INTO 有三种形式。 INSET INTO tablename SELECT...INSET INTO tablename SET column1value1,column2value2...INSET…...

服务端与网络相关知识
1. http/https 协议 1.0 协议缺陷: ⽆法复⽤链接,完成即断开,重新慢启动和 TCP 3 次握⼿head of line blocking : 线头阻塞,导致请求之间互相影响 1.1 改进: ⻓连接(默认 keep-alive ),复⽤host 字段指定对应的虚拟站点新增功…...

一分钟上手Vue VueI18n Internationalization(i18n)多国语言系统开发、国际化、中英文语言切换!
这里以Vue2为例子 第一步:安装vue-i18n npm install vue-i18n8.26.5 第二步:在src下创建js文件夹,继续创建language文件夹 在language文件夹里面创建zh.js、en.js、index.js这仨文件 这仨文件代码分别如下: zh.js export de…...
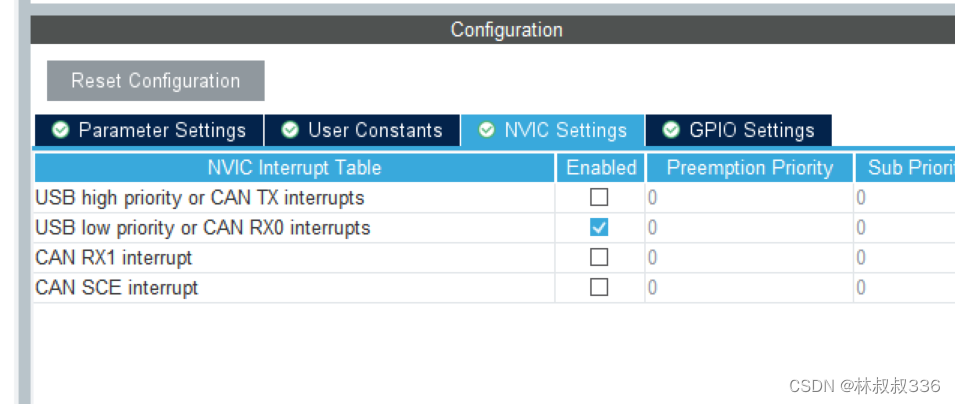
stm32 cubemx can通讯(1)回环模式
文章目录 前言一、cubemx配置二、代码1.过滤器的配置(后续会介绍)2.main.c3.主循环 总结 前言 介绍使用stm32cubemx来配置can,本节讲解一个简答,不需要stm32的can和外部连接,直接可以用于验证的回环模式。 所谓回环模…...
Python基础小项目
今天给大家写一期特别基础的Python小项目,欢迎大家支持,并给出自己的完善修改 (因为我写的都是很基础的,运行速率不是很好的 目录 1. 地铁票价题目程序源码运行截图 2. 购物车题目程序源码运行截图 3. 名片管理器题目程序源码运行…...

Python Opencv实践 - 在图像上绘制图形
import cv2 as cv import numpy as np import matplotlib.pyplot as pltimg cv.imread("../SampleImages/pomeranian.png") print(img.shape)plt.imshow(img[:,:,::-1])#画直线 #cv.line(img,start,end,color,thickness) #参考资料:https://blog.csdn.ne…...

管理者应该编码,但不是在工作时
管理者应该编码吗?这个问题似乎没有一个明确的答案。这场辩论有支持者也有反对者,每一方都有自己的论点。我最近在工作中编写了一个副业项目,这让我重新评估了我在这个问题上的立场。经历了这些之后,我可以说,我的立场已经从管理…...

深度学习常用的python库学习笔记
文章目录 数据分析四剑客Numpyndarray数组和标量之间的运算基本的索引和切片数学和统计方法线性代数 PandasMatplotlibPIL 数据分析四剑客 Numpy Numpy中文网 ndarray 数组和标量之间的运算 基本的索引和切片 数学和统计方法 线性代数 Pandas Pandas中文网 Matplotlib Mat…...

C语言属刷题训练【第八天】
文章目录 🪗1、如下程序的运行结果是( )💻2、若有定义: int a[2][3]; ,以下选项中对 a 数组元素正确引用的是( )🧿3、在下面的字符数组定义中,哪一个有语法错…...

ARM指令追踪技术及TRCVICTLR寄存器详解
1. ARM指令追踪技术概述在嵌入式系统开发和调试过程中,指令追踪(Instruction Trace)是一项至关重要的技术。它通过硬件机制记录处理器的执行流程,为开发者提供程序运行的完整轨迹。ARM架构从v7开始引入嵌入式跟踪宏单元࿰…...

C语言双端队列完整实现:一行代码吃透头尾操作,算法效率拉满
一、为什么C语言实现双端队列,是数据结构的必学天花板?在C语言数据结构里,队列、栈都是基础中的基础,但真正能把灵活度、效率、内存管理三者揉到一起的,还得是双端队列(deque)。普通队列只能一头…...
)
ThinkPad开机报错0183/0253?别慌,手把手教你搞定EFI变量错误(附BIOS重置教程)
ThinkPad开机报错0183/0253?EFI变量错误全面解决方案当你按下ThinkPad的电源键,期待熟悉的开机画面时,屏幕上却突然跳出一串神秘代码——"0183: Bad CRC of Security Settings in EFI Variable"或"0253: EFI Variable Block D…...

6款高效降AI率工具 改写实力出众
写论文时反复检测出的AI痕迹总让你提心吊胆?别担心,这里整理了6款真正好用的论文降AI率工具,堪称应对AI生成特征的“得力助手”。它们能有效识别并消除AI生成的痕迹,改写能力出众,帮你快速降低查重率,顺利通…...

基于双T振荡器的正弦波LED调光电路设计与实践
1. 项目概述:用双T振荡器实现正弦波LED调光最近在捣鼓一些氛围灯项目,总感觉用单片机PWM做的呼吸灯效果有点“硬”,那种线性的明暗变化看久了难免审美疲劳。于是翻出以前模拟电路的老本行,琢磨着能不能用纯硬件的方式,…...

Jupyter Notebook里跑argparse脚本总报错?一个空列表参数搞定ipykernel_launcher.py error
Jupyter Notebook中argparse报错的终极解决方案:空列表参数实战解析在数据科学和机器学习的工作流中,Jupyter Notebook因其交互式特性成为众多研究者的首选工具。然而,当我们尝试在Notebook中运行那些原本为命令行设计的Python脚本时…...

uWSGI目录穿越漏洞CVE-2018-7490深度利用与防御实战
1. 这不是“读文件”那么简单:uWSGI目录穿越在真实攻防链中的定位与误判代价你刚在Vulfocus靶场里跑通了CVE-2018-7490的PoC,用curl "http://target:8080/?p../../../../etc/passwd"成功读出了root:x:0:0:root:/root:/bin/bash,截…...

风控系统如何全维度识别爬虫:IP、账号与行为的协同决策机制
1. 这不是“反爬失败”,而是风控系统在对你做全维度画像你写完一段 requests BeautifulSoup 的代码,本地跑通了,开开心心部署到服务器,结果第二天早上发现:所有请求返回 403,日志里全是空响应;…...
)
【Veo 2提示词SOP白皮书】:从模糊意图到像素级输出的8步标准化工作流(附NASA级测试用例库)
更多请点击: https://intelliparadigm.com 第一章:Veo 2提示词工程的本质与范式跃迁 Veo 2并非单纯升级的视频生成模型,而是一次提示词工程范式的根本性重构——它将传统“指令式提示”(prompt-as-command)转向“意图…...

Python strip 与 rstrip 函数区别
Python strip 与 rstrip 函数区别 文章目录Python strip 与 rstrip 函数区别一、核心作用二、基础语法三、基础使用示例四、指定删除特定字符五、常用业务场景一、核心作用 函数作用范围strip()移除字符串首尾空白字符rstrip()仅移除字符串右侧末尾字符,左侧保持不…...