初识Redis
目录
- 认识Redis
- 分布式系统
- Redis的特性
- Redis的应用场景
- Redis客户端
- Redis命令
认识Redis

上面一段话是官网给出的对Redis的介绍,in-memory data store表明Redis是在内存中存储数据的,这和我们接触的其他数据库就有很大的不同,比如MySQL,它是将数据存储在磁盘中的,但由于MySQL需要与磁盘交互,访问速度就比较慢,而很多互联网产品,又对性能要求比较高,这时,Redis就可以发挥出它的作用了,因为是在内存中存储数据,就意味着访问速度远比在磁盘中快,极大地提高了程序的性能。
Redis也不是各方面领先于MySQL,比如在存储空间上,是远小于MySQL的,毕竟磁盘的空间要远大于内存!
要想存储的数据多,访问速度也快,就可以考虑将MySQL和Redis结合起来使用,因为20%的热点数据能满足80%的访问需求,但带来的问题是:系统的复杂程度大大提升了,而且数据发生修改时,还涉及到Redis和MySQL之间的数据同步问题,此时,Redis被作为cache
Redis的初心,就是用来作为一个"消息中间件"的(消息队列),然而,当前很少会直接使用Redis作为消息中间件,因为业界有更多更专业的消息中间件使用
为什么要有Redis,直接用变量存储不行?
在单机程序,Redis相对于变量存储数据,没有优势可言,但在分布式系统中,才能发挥威力,基于网络,可以把自己内存中的变量给别的进程,甚至别的主机的进程进行使用
分布式系统
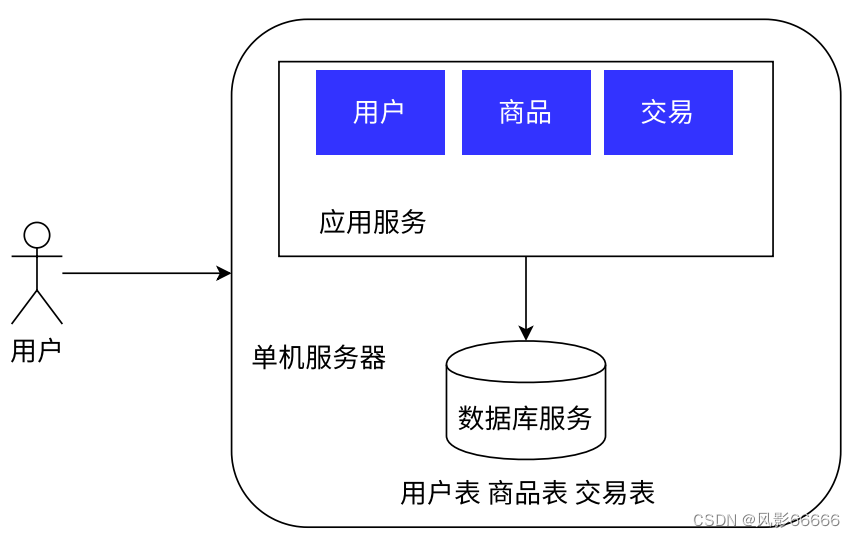
单机架构
如下图,是一个单机架构,只有一台服务器,它负责所有的工作,虽然只有一台服务器,但现在的硬件非常nice,也就意味着一台服务器的性能也很高,可以支持非常高的并发和非常大的数据存储,所以,绝大部分的公司的产品,就是这种单机架构!
分布式系统的引入
业务进一步增长,用户量和数据量都水涨船高,一台服务器难以应付,如果同一时刻处理的请求多了,可能会导致某个硬件资源不够用了,即导致服务器处理请求的时间变长,甚至于处理出错!
而要想解决这个问题,无非两种方式,第一个是节流,在软件上优化,但对程序员的水平要求就比较高;另一种方式就是引入更多的主机、更多的硬件资源,但一台主机的硬件资源是有限的,比如就4个内存插槽,你也就只能插4条内存条,所以就需要引入多台主机,此时的系统就可以称为是"分布式系统"
分布式系统的引入,会使得系统的复杂程度会大大提高,出现bug的概率也越高,则使用的人力成本上也就会越高,所以,引入分布式,是一种无奈之举!
应用服务和数据库服务分离
如下图, 将应用服务和数据库服务部署在不同的服务器,就可以给他们搭配不同的服务器,比如应用服务器,里面可能会包含很多的业务逻辑,可能会吃CPU和内存,就采用CPU和内存好的主机;而数据服务器,需要更大的硬盘空间,更快的访问速度,就可以配置更大硬盘的主机,甚至是SSD硬盘,这样就能达到更高的性价比!!!

引入更多的应用服务器节点
如下图,应用服务器可能会比较吃CPU和内存,如果把CPU和内存吃没了,此时应用服务器就顶不住了,就需要引入更多的应用服务器,来解决上述问题,同时也需要引入负载均衡器,用户的请求会先到达负载均衡器/网关服务器,然后根据负载情况,将请求分配给负载相对小的应用服务器,尽可能保证每台应用服务器处理的用户请求是均衡的,当然,这里就会用到负载均衡的相关算法
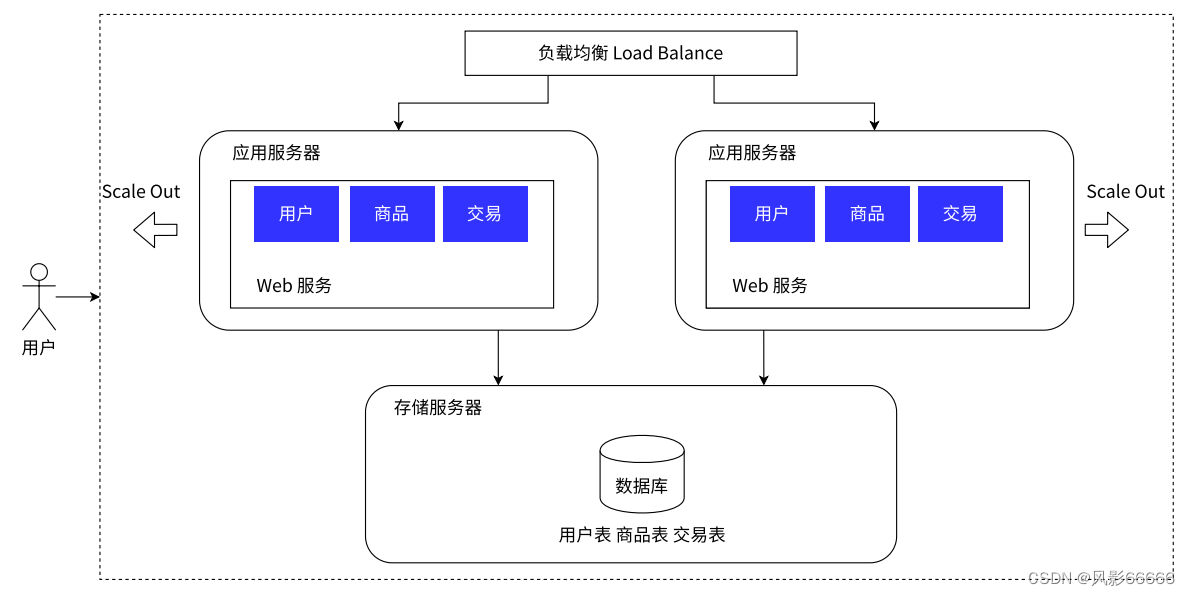
负载均衡器,对于请求量的承担能力,是远超过应用服务器的,因为负载均衡器就相当于领导,负责派发任务,而应用服务器则相当于职员,负责执行任务。如果出现请求量大到负载均衡器也扛不住了的时候,就可以引入更多的负载均衡器,即引入多个机房
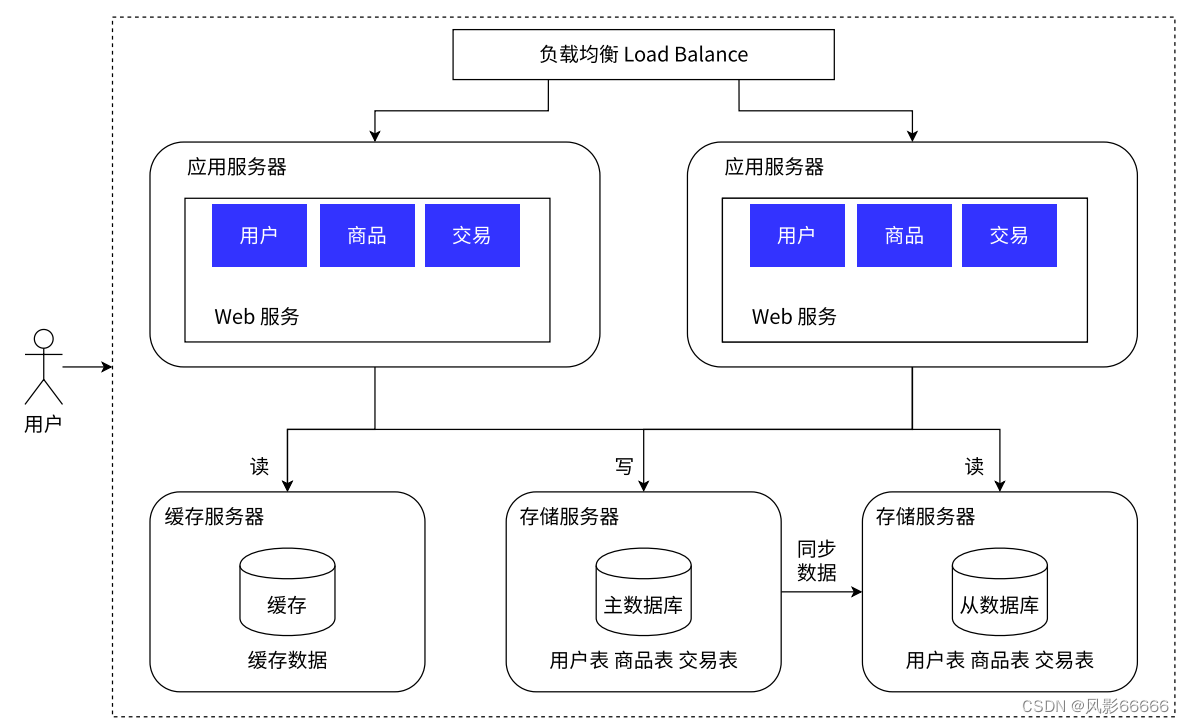
引入更多的数据库服务器(读写分离)
如下图,当数据量太多,一台数据库服务器难以支撑时,就需要引入更多的服务器来存储数据,而实际的应用场景中,读的频率是比写要高的,所以一般是一台主服务器,多台从服务器,主服务器负责写,读服务器负责读,同时从服务器通过负载均衡的方式,让应用服务器进行访问

引入缓存
数据库天然有个问题,那就是响应速度是更慢的!所以就需要把数据区分“冷热”,热点数据存放到缓存中,而缓存的访问速度往往比数据要快很多!如下图所示
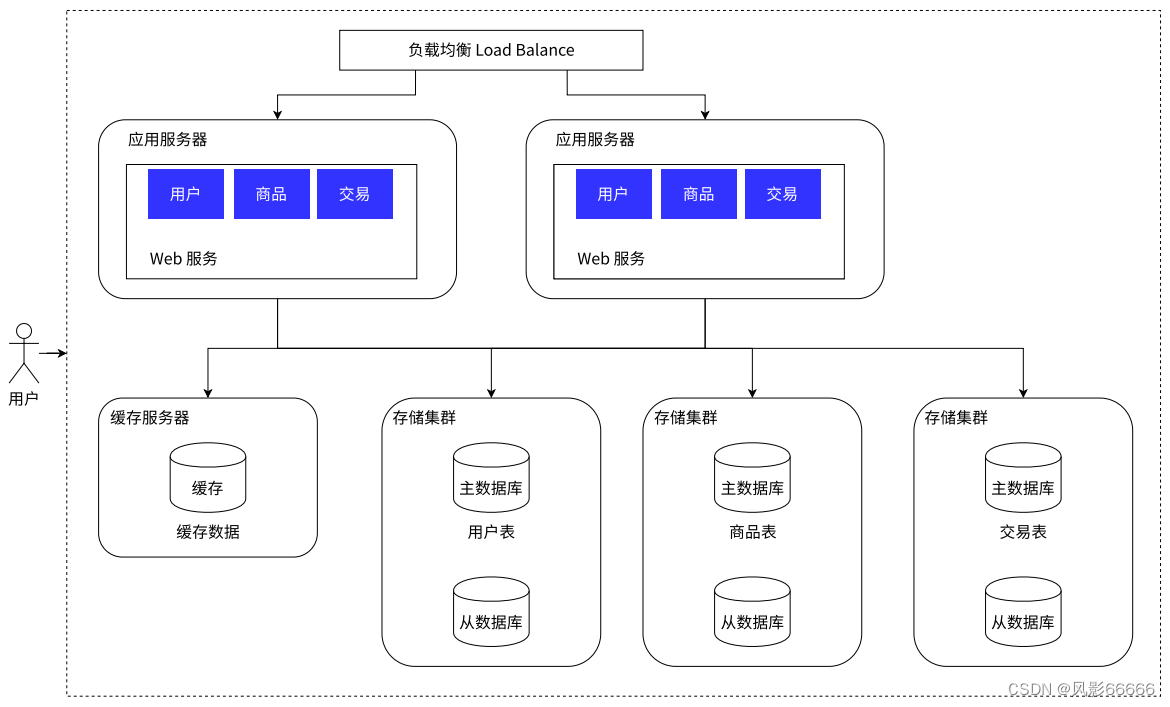
分库分表
当数据量更大时,一台服务器已经存不下了,就需要多台主机存储,同时能对数据库进行进一步的拆分,即分库分表。本来一台数据库服务器上有多个数据库(create database),现在引入多台数据库服务器,就能每个数据库服务器存储一个或者一部分数据库,甚至如果某个表特别大,一台主机存不下,也可以针对表进行拆分!具体分库分表如何实现,还要结合实际的业务场景来展开,因为业务决定技术。如下图所示
微服务架构
前面的应用服务器,里面可能做了很多的业务,这就可能导致这个服务器的代码变得非常复杂,而为了更方便代码的维护,就可以把这样的复杂的服务器,拆分成更多的,功能更单一的,但是更小的服务器,同时服务器的种类和数量就增加了!如下图所示
注意:微服务本质上是在解决"人"的问题
当应用服务器复杂了,就势必需要更多的人来维护,当人多了,就需要配套的管理,把这些人组织好,可以划分组织结构,分成多个组,每个组分别配备领导进行管理,分成多个组,就需要进行分工,而拆分成多组微服务,就利于人员的组织结构的分配了
微服务的优势
解决了人的问题;
使用微服务,可以更方便于功能的复用;
可以给不同的服务进行不同的部署
引入微服务,付出的代价?
系统性能的下降,而要想保证性能不下降太多,就需要引入更多、更好的硬件资源,而拆分出来更多的服务,多个功能之间要更依赖网络里通信,而如果用的网卡不是很好的那种,那网络通信的速度比硬盘还慢!
系统复杂程度提高,可用性受到影响,服务器更多了,出现问题的概念就更大了,这就需要一系列的手段,来保证系统的可用性,比如更丰富的监控报警,以及配套的运维人员
分布式系统的概念
应用/系统
一个应用,就是一个/组服务器程序
模块/组件
一个应用,里面有很多个功能,每个独立的功能,就可以称为是一个模块/组件
分布式
引入多个主机/服务器,协调配合完成一系列的工作(物理上的多台主机)
集群
引入多个主机/服务器,协调配合完成一系列的工作(逻辑上的多台主机)
主/从
分布式系统中一种比较典型的结构,多个服务器节点,其中一个是主,另外的则是从,从节点的数据要从主节点这里同步过来
中间件
和业务无关的服务(功能更通用的服务),比如数据库,缓存,消息队列
可用性
系统整体可用的时间/总的时间,也是一个系统的第一要务
响应时长
衡量服务器的性能,越小越好
吞吐 vs 并发
衡量系统的处理请求的能力,衡量性能的一种方式
Redis的特性

如上图,可以看出Redis是在内存中存储数据的,Redis主要是通过"键值对"的方式来存储组织数据,是一种"非关系型数据库",key都是string,value则可以是字符串、哈希表、列表、集合等等

如上图,针对Redis的操作,可用通过简单的交互式命令进行操作,也可以通过一些脚本的方式,批量执行一些操作(可以带有一些逻辑)
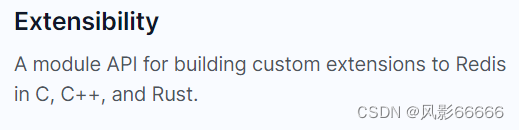
如上图,Redis提供了一组API,可以用C、C++和Rust语言在Redis原有的功能基础上再进行扩展,即编写动态链接库

如上图,为了使Redis存储的数据持久化,Redis会把数据存储再硬盘上,即内存为主,硬盘为辅

如上图,Redis作为一个分布式系统的中间件,能够支持集群是很关键的,这个水平扩展,类似于"分库分表"。
一个Redis能存储的数据是有限的,因为内存空间有限,就可以引入多台主机,部署多个Redis节点,每个Redis节点存储数据的一部分

如上图,Redis具有高可用特性,数据存在冗余/备份,Redis自身也是支持"主从"结构的,从节点就相当于主节点的备份了
为什么Redis快?
1、Redis数据存在内存中,就比访问硬盘的数据库,要快很多
2、Redis核心功能都是比较简单的逻辑,如比较简单的操作内存的数据结构
3、从网络角度,Redis使用了IO多路复用的方式
4、Redis使用的是单线程模型,减少了不必要的线程之间的竞争开销,因为Redis的核心任务主要是操作内存的数据结构,不会吃很多CPU
Redis的应用场景

如上图,Redis可以被当作数据库使用,虽然在大多数情况下,考虑到数据存储,优先考虑的是"大",但是仍然有一些场景,考虑的是"快",比如搜索引擎

如上图,Redis存的是部分数据,比如热点数据,全量数据都是以MySQL为主的,哪怕Redis的数据没了,还可以从MySQL那里加载回来
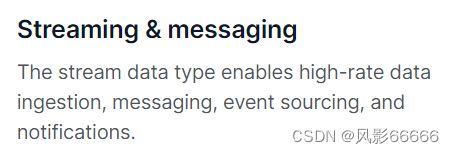
如上图,Redis可以作为消息队列,基于这个可以实现一个网络版本的生产者-消费者模型
如下图,在用户浏览某个网站时,访问不同的网页,负载均衡器有很大的可能将请求打到不同的应用服务器,而保存的session的只有一台服务器上有,这就会给用户带来不好的体验,毕竟要多次重新登录,此时有两种方式解决这个问题
1、想办法让负载均衡器,把同一个用户的请求始终打到同一台机器上,但就不能通过轮询的方式来选择应用服务器,而要用userld之类的方式来分配机器
2、把会话单独拎出来,放到一台独立的机器上存储(Redis)

Redis客户端
和MySQL一样,Redis也是一个客户端-服务器结构的程序,它的客户端和服务器可以在同一台主机上,也可以在不同主机上
Redis客户端的形态
命令行客户端redis-cli
图形化界面的客户端(桌面程序、web程序)
基于redis的API自行开发客户端(工作中最主要的形态),非常类似于MySQL的C语言API和JDBC
Redis命令
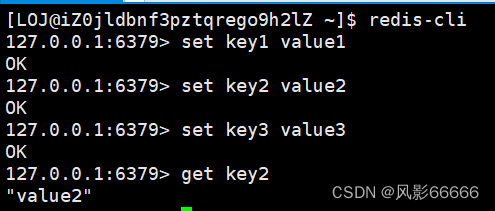
get和set命令
set:把key和value存储进去
get:根据key来获取value
set和get也是Redis最核心的两个命令
如下图,key和value都是字符串,即使没有加"“,当然,加”"或’'都是可以的
注意:Redis中的命令是不区分大小写的!!!
key不存在时,会直接返回空
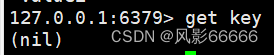
Redis全局命令:能够搭配任意一个数据结构来使用的命令
keys命令
keys:用来查询当前服务器上匹配的key,后面接pattern,pattern方便查找我们想要的,keys类似于Linux中的grep命令
如下图,设置下面键值对,方便下面的演示
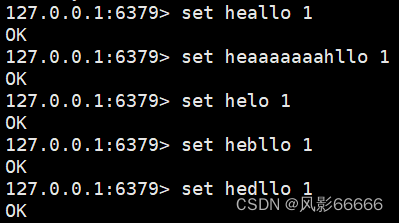
?:匹配任意一个字符
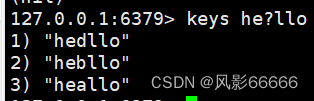
*:匹配0个或多个任意字符
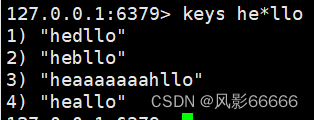
[abcde]:只能匹配到a b c d e,别的不行,相当于给出固定的选项了

[^a]:排除a,只有a匹配不了,其他的都能匹配
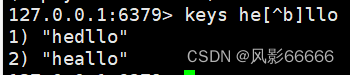
[a-b]:匹配a-b这个范围内的字符,包含两侧边界

注意:keys命令的时间复杂度是O(N),所以在生产环境上,一般都会禁止使用keys命令,尤其是大杀器keys *,它会查询出Redis中所有的key。生产环境上的key可能会非常多,而Redis是一个单线程的服务器,执行keys *的可能性非常长,使得Redis服务器被阻塞了,就无法给其他客户端提供服务了,这样的后果是灾难性的!
工作中会涉及到的几种环境
办公环境、开发环境、测试环境、线上环境/生产环境,操作线上环境的任何一个设备/程序都要怀着12分的谨慎!
exists命令
判断一个或多个key是否存在,时间复杂度O(1),返回值:key存在的个数,redis是按照哈希表的方式来组织的
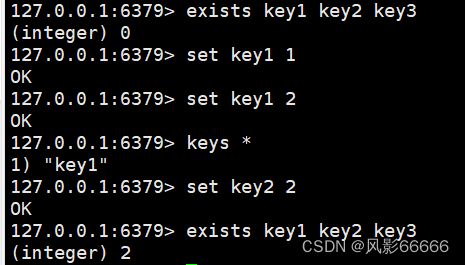
如上图,一次判断多个key,比起一次判断一个,效率会更高,因为redis是一个客户端—服务器结构的程序,而客户端与服务端是通过网络进行通信的,相对内存而言,网络通信很慢,所以走一次网络和走多次网络区别很大
del命令
删除指定的key,一次可以删除多个,时间复杂度O(1),返回值:删除掉的key的个数
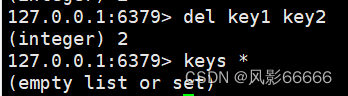
redis作为缓存时,误删了几个数据,相对于MySQL而言,影响不是很大,但如果把所有的数据或者一大半数据一下子干没了,影响就大了去了,本来redis是帮MySQL负重前行的,而redis数据被删了,就只能去MySQL中获取数据了,很容易把MySQL搞崩
redis作为数据库时,哪怕误删一个数据,影响都会很大
redis作为消息队列时,误删数据影响大不大,就需要具体问题具体分析了
expire命令
给指定的key设置过期时间,单位是秒,时间复杂度O(1),返回值:1表示设置成功,0表示设置失败
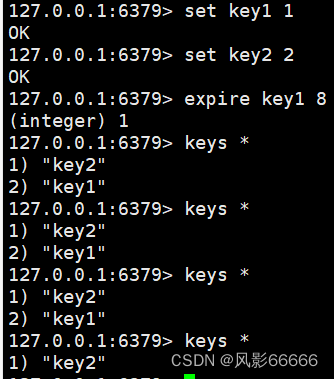
应用场景:手机验证码、外卖优惠券
注意:必须针对已经存在的key设置过期时间
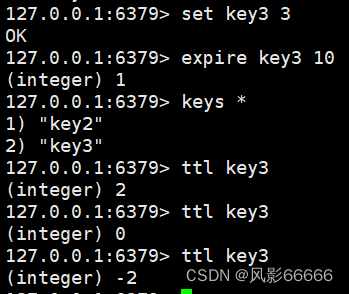
ttl命令(time to live)
查看当前key的过期时间还剩多少,时间复杂度O(1),-1表示没有关联过期时间,-2表示key不存在
redis中key的过期策略
如果直接遍历所有的key,显然是行不通的,效率太低了
redis整体的策略是定期删除和惰性删除
定性删除:每次抽取一部分,进行验证过期时间,保证这个抽取检查的过程足够快
为什么要对定性删除的时间,有明确的要求?
因为redis是单线程的程序,主要的任务执行命令,如果扫描过期key消耗的时间太多了,就可能导致正常处理请求命令就被阻塞了,类似于keys *
惰性删除:当某个key已经到过期时间了,但是暂时还没删它,key还存在,后面又一次访问,正好用到了这个key,于是这次访问就会让redis服务器触发删除key的操作,同时再返回一个nil
过期策略也可以通过定时器来实现!!!
定时器
概念:在某个时间达到之后,执行指定的任务
基于优先级队列实现定时器
假定现在又很多key都设置了过期时间,就可以把这些key加入到一个优先级队列中,指定优先级规则:过期时间早的,先出队列,队首元素,就是最早要过期的key,然后只需要给定时器分配一个线程,让这个线程取检查队首元素,看看是否过期即可,此时,扫描线程不需要遍历所有key,只需要盯住队首元素即可
在扫描线程检查队首元素过期时间的时候,也不能检查太频繁,可以根据当前时刻和队首元素的过期时间,设置一个等待,当时间差不多到了,系统再去唤醒这个线程,来新任务时,唤醒线程,重新设置阻塞时间即可!
基于时间轮实现定时器
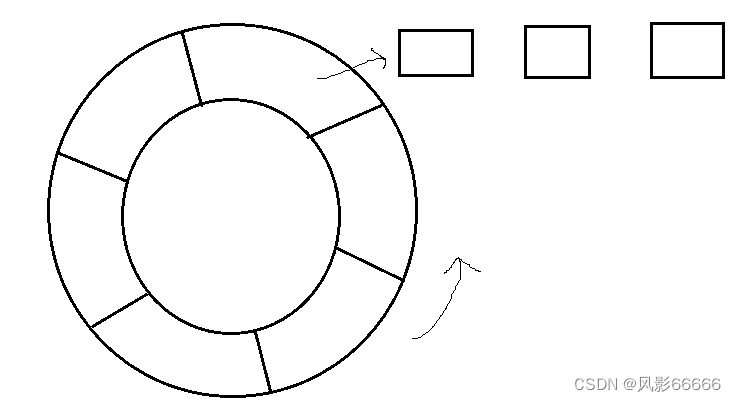
如上图,把时间划分成很多小段—划分的粒度,看实际需求
每个小段上都挂着一个链表,每个链表都代表一个要执行的任务(相当于一个函数指针,以及对应的参数啥的)
给定一个指针,指向时间轮中的一个格子,让它绕着这个时间轮旋转,每走到一个格子,就会尝试把这个格子上链表的任务尝试执行一下
注意:每个格子是多少时间,一共多少格子,都是需要根据实际场景,灵活调配的
type命令
查看这个key对应value的类型,有string、list、set、hash等等,时间复杂度O(1)
相关文章:
初识Redis
目录 认识Redis分布式系统Redis的特性Redis的应用场景Redis客户端Redis命令 认识Redis 上面一段话是官网给出的对Redis的介绍,in-memory data store表明Redis是在内存中存储数据的,这和我们接触的其他数据库就有很大的不同,比如MySQL…...
每天一道leetcode:115. 不同的子序列(动态规划困难)
今日份题目: 给你两个字符串 s 和 t ,统计并返回在 s 的 子序列 中 t 出现的个数。 题目数据保证答案符合 32 位带符号整数范围。 示例1 输入:s "rabbbit", t "rabbit" 输出:3 解释: 如下所…...

服务器数据恢复-RAID5多块磁盘离线导致崩溃的数据恢复案例
服务器数据恢复环境: DELL POWEREDGE某型号服务器中有一组由6块SCSI硬盘组建的RAID5阵列,LINUX REDHAT操作系统,EXT3文件系统,存放图片文件。 服务器故障&分析: 服务器raid5阵列中有一块硬盘离线,管理员…...

NO.2 MyBatis框架:创建Mapper接口和映射文件,实现基本增删改查
目录 1、Mapper接口和映射文件关系 2、Mapper接口和映射文件的命名规则 2.1 Mapper接口的命名规则 2.2 映射文件的命名规则 3、Mapper接口和映射文件的创建及增删改查的实现 3.1 Mapper接口和映射文件的创建 3.2 增删改查的实现 3.2.1表结构 3.2.2 创建表User对应的实…...

【JS】怎么提取object类的内容
需求:在网页端中通过getElementsByClassName获取到一个元素,想提取其中的数字内容做个if判断,奈何一直提取不了 开始获取元素时,以为默认就是字符类型;但使用操作字符的函数就失败,然后就考虑数据类型是不是…...
分布式系统的 38 个知识点
天天说分布式分布式,那么我们是否知道什么是分布式,分布式会遇到什么问题,有哪些理论支撑,有哪些经典的应对方案,业界是如何设计并保证分布式系统的高可用呢? 1. 架构设计 这一节将从一些经典的开源系统架…...
)
机器学习基础(二)
线性回归 误差是独立并且具有相同的分布通常认为服从均值为0方差为的高斯分布。 损失函数(loss Function)/代价函数(Cost Function) 其实两种叫法都可以,损失函数(loss function)或代价函数(cost function)是将随机事件或其有关随机变量的取值映射为非负实数以表示该随…...

Java 实现Rtsp 转rtmp,hls,flv
服务支撑:FFmpeg srs(流媒体服务器) 整个流程是 FFmpeg 收流转码 推 rtmp 到流媒体服务 流媒体服务再 分发流到公网 搭建流媒体服务: 1. SRS (Simple Realtime Server) | SRS (本例子使用的是SrS 安装使用docker ) 2.GitHub - ZLMedi…...
)
机器学习基础(三)
逻辑回归 场景 垃圾邮件分类 预测肿瘤是良性还是恶性 预测某人的信用是否良好 正确率与召回率 正确率与召回率(Precision & Recall)是广泛应用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量。 一般来说,正确率就是检索出来的条目有多少是正确的,召回率就…...
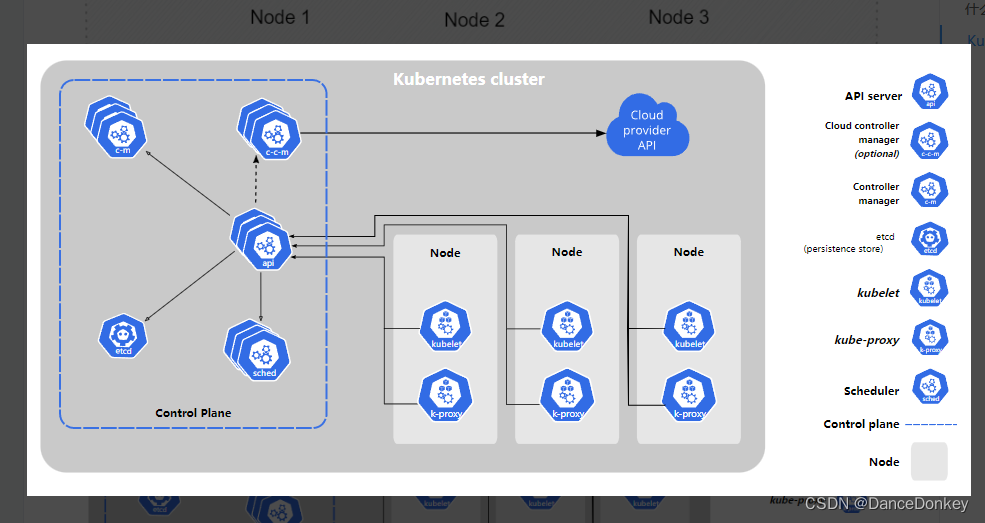
Kubeadm安装K8s集群
一、硬件环境 准备3台Linux服务器,此处用Vmware虚拟机。 主机名CPU内存k8smaster2核4Gk8snode12核4Gk8snode22核4G 二、系统前置准备 配置三台主机的hosts文件 cat << EOF > /etc/hosts 192.168.240.130 k8smaster 192.168.240.132 k8snode1 192.168.…...

【C++】开源:spdlog跨平台日志库配置使用
😏★,:.☆( ̄▽ ̄)/$:.★ 😏 这篇文章主要介绍spdlog日志库配置使用。 无专精则不能成,无涉猎则不能通。——梁启超 欢迎来到我的博客,一起学习,共同进步。 喜欢的朋友可以关注一下,下…...

[Azkaban] No active executors found
没有找到活动的executors,需在MySQL数据库里设置端口为12321的executors表的active为1: select * from executors;如果显示active0 则需要进行处理: update azkaban.executors set active1;当active0,更新为1时,用 n…...

无涯教程-Perl - recv函数
描述 This function receives a message on SOCKET attempting to read LENGTH bytes, placing the data read into variable SCALAR.The FLAGS argument takes the same values as the recvfrom( ) system function, on which the function is based. When communicating wit…...

算法练习-搜索 相关
文章目录 迷宫问题 迷宫问题 定义一个二维数组 m行 * n列 ,如 4 5 数组下所示: int arr[5][5] { 0, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, }; 它表示一个迷宫,1表示墙壁,0表示可以走的路,只…...

PyQt5控件布局管理
Qt Designer提供了四种窗口布局:Vertical Layout(垂直布局) ,Horizontal Layout(水平布局),Grid Layout(栅格布局),Form Layout(表单布局),以及一种隐藏的布局—绝对布局 一般进行布局有两种方式: 一是通…...

TypeScript 一分钟让你理解泛型是什么
TypeScript 一分钟让你理解 泛型是什么 TS的泛型是指在定义函数、接口或类型时,不预先指定具体的类型,而是在使用时指定类型限制的一种特性。 泛型和函数中的参数比较类似,我们定义一个函数的时候有时会给它留一个参数名,在使用这…...
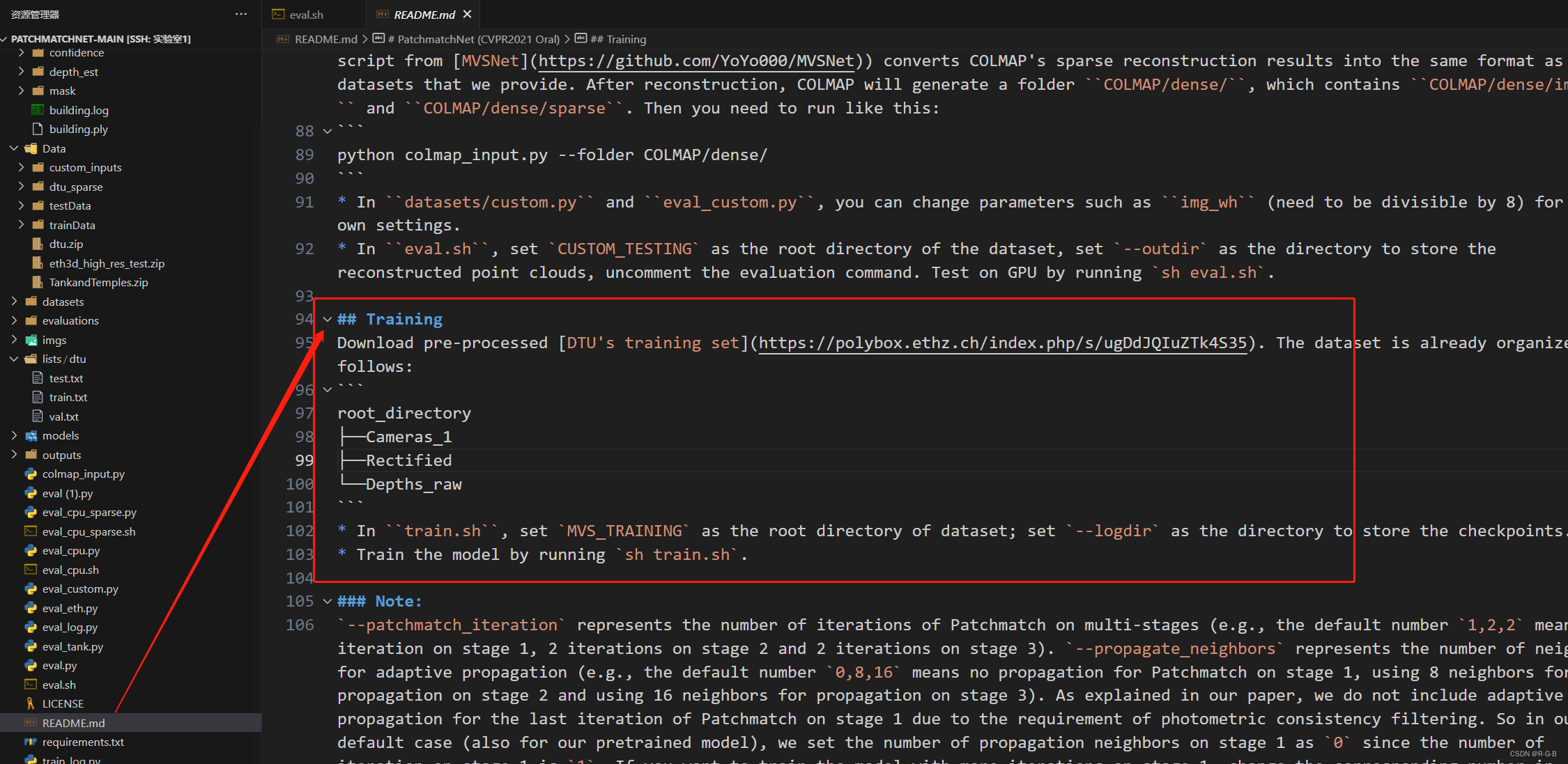
PatchMatchNet 训练dtu数据集、训练曲线查看、实操教程图图文详解、
文章目录 1 查看要求 下载数据集2 训练2.1 路径配置2.2 训练2.3 模型输出 与 训练曲线查看2.4 输出训练 log文件1 查看要求 下载数据集 在代码文件加下打开 README.md文件找到训练说明,查看那要求、下载训练集、训练方法 ## Training Download pre-processed [DTUs trainin…...

怎样制定测试计划和设计测试用例?
测试工作贯穿于整个软件开发生命周期,是一项庞大而复杂的工作,需要制订一个完整且详细的测试计划作为指导。测试计划是整个测试工作的导航图,但它并不是一成不变的,随着项目推进或需求变更,测试计划也会不断发生改变&a…...
教你如何为博客网站申请阿里云的免费域名HTTPS证书
如何为博客网站申请阿里云的免费域名HTTPS证书 文章目录 如何为博客网站申请阿里云的免费域名HTTPS证书前置条件:步骤1 例如阿里云控制台,选择SSL证书步骤2 申请购买免费证书步骤3 创建证书步骤3.1 证书申请步骤3.2 DNS域名验证 步骤4 等待证书审核成功&…...
在线Word怎么转换成PDF?Word无法转换成PDF文档原因分析
不同的文件格式使用方法是不一样的,而且也需要使用不同的工具才可以打开编辑内容,针对不同的场合用户们难免会用到各种各样的文件格式,要想在不修改内容的前提下提高工作效率,那就需要用到文件格式转换,那么在线Word怎…...

CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测
CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测无人机技术的普及带来了新的安全挑战,从隐私侵犯到关键设施威胁,反无人机技术正成为计算机视觉领域的热点。CVPR 2023反无人机竞赛提供的开源数据集和基线模型…...

物理引导的机器学习工作流:气候建模的融合创新与实践
1. 项目概述:当气候建模遇见机器学习如果你像我一样,在气候模拟这个领域摸爬滚打超过十年,就会深刻体会到一种“甜蜜的负担”:我们构建的地球系统模型(ESM)越来越精细,物理过程越来越复杂&#…...

Agent开发面试通关攻略:吃透稳拿offer
阅读前置:2026年当下最卷也最缺人的AI岗位,一定是AI Agent开发。最近刷遍CSDN、牛客、力扣最新面经,发现一个非常明显的招聘趋势:普通大模型微调岗位饱和内卷,而AI Agent开发岗位人才严重缺口,薪资更高、竞…...

警惕!AI正在悄悄重构全球攻防格局
警惕!AI 正在悄悄重构全球攻防格局 热点聚焦 AI重构网络安全:全球巨头加速布局 2026年5月,全球网络安全领域迎来重大变革,AI技术正在重塑攻防格局。OpenAI发布专为网络安全防御打造的集成化AI平台Daybreak,将安全防…...

嵌入式快速原型开发:基于Sceptre平台与LPC2148的实战指南
1. 项目概述:Sceptre,一个被低估的嵌入式快速原型利器 在嵌入式开发的世界里,我们总是在寻找那个“刚刚好”的平台:它要足够强大,能跑复杂的算法;要足够小巧,能塞进各种外壳;要足够便…...

Owl-Alpha 新手快速上手指南
在处理大规模数据或构建高性能应用时,我们常常会遇到一个棘手的问题:如何在不阻塞主线程的情况下,高效地执行耗时任务?无论是处理图像、解析大型文件,还是进行复杂的数学运算,传统的单线程模式往往会让界面…...
)
Claude端到端测试设计:从零搭建可审计、可回放、可量化的AI服务测试流水线(含开源Schema校验工具)
更多请点击: https://codechina.net 第一章:Claude端到端测试设计 端到端测试是验证Claude模型在真实用户交互链路中行为一致性的关键手段。它覆盖从原始提示输入、上下文管理、流式响应生成,到输出解析与业务校验的全路径,确保模…...

InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制
InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制 【免费下载链接】InVideo 基于UE4实现的rtsp的视频播放插件 项目地址: https://gitcode.com/gh_mirrors/in/InVideo InVideo是一个基于Unreal Engine 5开发的RTSP视频播放插件࿰…...

如何优化 MySQL 千万级数据分页查询的性能?
它的本质是:**传统 LIMIT offset, size 在大数据量下性能急剧下降,是因为 MySQL 必须 扫描并丢弃 前 offset 行数据。当 offset 很大时(如 LIMIT 1000000, 10),MySQL 需要读取 1,000,010 行记录,执行 1,000…...

3大突破性功能:用HiveWE革新你的魔兽争霸III地图创作体验
3大突破性功能:用HiveWE革新你的魔兽争霸III地图创作体验 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hive…...