此文详解,数据仓库管理建设的经验
目前由于数据分散在不同的存储环境或数据库中,对于新业务需求的开发需要人工先从不同的数据库中同步、集中、合并等处理,造成资源和人力的浪费。同时,目前的系统架构,无法为未来数据驱动业务创新的理念提供友好的支撑。需要建设新一代数据管理平台来解决数据利用率效率跟不上,以及不能支撑业务发展的问题。以此建设背景,建设新一代数据管理平台需要能够支持数据汇集、数据分析、数据应用、数据计算、数据管理、数据资源管理。
建设目标
一、提高业务产品的研发效率 解决不同的业务部门之间的项目、组件、数据很难复用,同时带来繁重的运维成本的环境对业务团队的同事来讲不友好(除了要熟悉业务以外还需要对底层框架有比较深入的了解)重复的开发工作(例如导表、调度等本来可以复用的模块,却需要在多个项目中重复实现)频繁的跨部门需求沟通和讨论,平台将会统一数据、数据共享、服务组件来提高业务产品研发的效率。

二、提升业务需求的响应能力经常遇到业务需求变更和新的需求,传统的开发模式从“找数据”、“对接数据”、“编码开发”等过程,开发周期较长,影响业务需求的快速服务。数据平台提供可视化的API开发接口、组件服务库,能够快速响应业务需求的开发。比如开发一个新的业务需要用户的完整信息,则需要在平台上可视化调用各数据拼装新的数据单元,形成数据服务接口,快速支撑开发人员,从而减少业务上线的时间,提升业务的响应速度。
三、让数据具备赋能业务创新的能力深度挖掘数据价值,面向数据分析场景构建数据模型,支撑业务决策和产品智能。平台数据需按照规范的建模方法论将数据形成主题域模型、形成标签模型或者指标模型。这些数据模型是数据平台的核心资产,数据平台的各业务系统通过大数据计算平台这座数据加工厂统一加工后产生数据模型,再将这些数据资产通过可视化的界面管理起来,并使用标准化的数据服务接口对数据应用端提供数据应用服务,如快速建立新业务指标模型。
应用平台“四化”建设
1、数据汇集可视化以往数据同步需要对不同的数据源单独编写数据同步工具,耗时耗力,但是所有的行为抽象是同类,可以建设可视化管理系统来对数据汇集管理、调度。
2、数据建模自助化打通不同业务口子的数据融合,快速形成新的数据服务单元,将传统的、手动的方式改为线上可视化任务方式,比如要查询会员的信息,可能分布在不同的数据源中,在线可以实现打通宽表,实现会员信息的再次编排,形成用户完整的数据单元。群策群力,构建模型应用市场。
(1)数据模型市场
建立模型市场,类似于应用市场,对数据管理人员、分析人员或者其他授权人员提供数据模型共享。模型市场有系统预置以及有其他创建模型的组织来提供,市场包含多种风控模型、预测模型、营销模型等。数据模型市场不仅仅支持模型在线分析,同时数据模型可以作为能力对业务过程助力,如一个用户来需要办理一个新业务需要对其购买意愿做评估,则可以用模型市场中营销模型对其做出分析。
(2)简单分析模型建模
在线选择数据源,将数据源通到控制面板中,然后建立数据源直接的关系后,提交计算,形成一个新的数据单元。
(3)复杂分析模型建模
数据工程师登录平台,创建新的项目,申请数据资源。
数据工程师通过元数据查找选出表,选择数据集或者数据接口,填写相关信息
申请这些需要用到的表。比如需要用到100 张表,其中70 张是通过 T+1 的方式使用,30 张是通过实时方式使用。

默认会做标准化脱敏加密策略,收到这些申请之后,数据管理员会按策略依次进行审批。
审批通过后,会自动准备和输出所申请的数据资源,数据工程师可以运用拿到的数据资源进行自助查询、开发、配置、SQL 编排生成等。
最后将自助报表或仪表板提交给用户使用。
3、数据服务接口化数据平台具备“只要能够获取到数据表/视图的权限,便支持封装为API接口发布”的能力。而标准的API接口能够充分实现各业务单位按需申请使用,现有成果的可复用性大大减少了重复建设的成本,也极大降低了信息中心的工作压力,实现易上手、低成本、稳定的数据开放共享服务,帮助前台业务快速接入,创建数据服务API的两种方式:
(1)构建简单数据服务接口
以【向导模式】新建API,填入接口的基本信息,含API名称、API路径、协议等。
选择数据源,库名称、表名称后,系统会自动展示表结构的Schema信息。
基于表结构勾选出需要的入参及出参字段,并设置好查询条件、是否分页及使用过滤器等选项。
对新API进行验证,结果符合预期后点击发布,新API就正式上线提供服务了。
(2)构建复杂数据服务接口
以【脚本模式】新建API,该操作与简单数据查询服务操作一致。
先选择数据源,含库类型、库名称后,再编写一条完整的SQL语句,支持同一数据源下多张表的关联查询、支持字段别名、SQL函数等。
编写好SQL语句后,系统会自动分析出API的入参和出参,请对参数信息进行设置如是否分页、使用过滤器等选项,方便API调用者。
新API进行验证,结果符合预期后点击发布,新API就正式上线提供服务了。
4、业务服务组件化对目前各个系统中重合度高的业务形成组件化,构建一个领域服务层组件或微服务模块,来提供整合后的领域服务能力,这个组件如果需要提供一个关联多个业务对象的数据集合,那么就需要调用API接口返回多个独立数据集合,然后在组件业务逻辑实现中来完成多个数据集的整合工作,开放给前台使用,方便前台业务场景和功能的实现。
基础平台建设
1、数据集成要提高数据使用效率,打破数据库之间的物理隔阂,需要先将数据汇聚到数据仓库中,数据同步分为实时和非实时,采用的技术也不同。目前先从ODS中同步到hive。数据同步策略的类型包括:全量表、增量表、新增及变化表、拉链表:Ø 全量表:存储完整的数据。Ø 增量表:存储新增加的数据。Ø 新增及变化表:存储新增加的数据和变化的数据。Ø 拉链表:对新增及变化表做定期合并。
2、实体表同步策略
实体表:比如用户,理财产品等,实体表数据量比较小,通常可以做每日全量,是每天存一份完整数据。即每日全量。
(1)维度表同步策略
维度表:比如订单状态,审批状态,产品分类,维度表数据量比较小,通常可以做每日全量,是每天存一份完整数据。即每日全量。说明:
针对可能会有变化的状态数据可以存储每日全量。
没变化的客观世界的维度(比如性别,地区,民族)可以只存一份固定值。
(2)事务型事实表同步策略
事务型事实表:比如,交易流水,操作日志,出库入库记录等。因为数据不会变化,而且数据量巨大,所以每天只同步新增数据即可,所以可以做成每日增量表,即每日创建一个分区存储。
(3)周期型事实表同步策略
周期型事实表:比如订单申请等2、数据存储存储的数据包含业务数据和元数据。存储的数据分为四层,每一层采用的存储方式和数据不同,如下:
ODS层:原始数据层,存放原始数据,直接加载原始日志、数据,数据保持原貌不做处理,目前系统中已经存在。
DWD层:结构和粒度与原始表保持一致,对ODS层数据进行清洗(去除空值,脏数据,超过极限范围的数据),DWD数据采用hive的方式管理,将从ODS中的数据同步到hive。
DWS层:以DWD为基础,进行轻度汇总,如将用户的基本信息从各个业务系统中合并为一张宽表,此层的数据仍然存储在hive中。
ADS层:数据应用也即数据应用开发层,通过数据计算层的计算后,根据数据类型的不同可以存储到不同的存储器中,如文本型查询的数据可以存储的ES中,对计算结果的查询可以存储在SqlServer中。

3、元数据管理通过Atlas来管理Hive中的元数据,形成元数据目录,以此设计出元模型,然后将数据仓库系统之中的元数据按元模型集中汇总并关联到一起,达到企业对数据统一管理与应用的目的。业务元数据相对复杂,来源较广泛且不统一,需要对业务系统进行深入理解,按业务主题进行整理,梳理出业务范围、业务名称 、业务定义、业务描述、业务关系等,并添加到元数据管理系统中,主要作用实现如下:
元数据权限管理:对数据管理需要有权限的管理员管理,是关乎到数据质量的关键。
元数据质量:包含元数据一致性检查,对异常或者不符合规则的数据告警。
数据血缘分析:数据产生的链路或者路径,例如通过数据 A 数据 B 产生了数据 C,那么 C 的父血缘就是 A 和 B,反之亦然。在大数据套件中描述数据“父子”关系,以思维导图形式展现了数据变化影响和数据生产溯源,清晰刻画表与表之间、任务与任务之间的关系。如图,是红楼梦的数据血缘关系。
- 数据计算数据计算由数据管理员来实现,解决的问题根据业务需要对数据融合得出的数据结果。计算层分为离线计算和实时计算。
- 业务流程数据管理人员可以在平台上可视化的对数据处理,先创建数据应用集合以及对应的数据表,然后在可视化界面上编写数据处理脚本,需要提交后台任务管理系统执行,执行完成后根据数据要求存储到不同的数据器中。
- 离线计算针对数据量大、逻辑复杂的计算交由后台任务系统,调用Hive计算。将计算的结果可以存储到SqlServer或者ES中,根据数据需求场景不同而定。
- 实时查询针对业务频繁查询的场景,并且数据量大的数据计算完成后可以存储到ES,针对统计分析类同时数据量较大可以使用Presto来查询。

- 任务调度本系统的任务主要对数据同步任务、离线计算等任务管理。数据管理员将数据处理任务可以在线或者离线编辑完成后,上传到Azkaban平台执行,执行完成后自动同步发布到相关的数据器中并且通知相关人员。
- 数据应用开发
- 业务流程用户(开发人员或者数据分析人员)在平台上申请数据资源,并且在平台上可视化选择需要的数据源以及数据字段,数据分为业务开发支撑的数据和数据分析。数据管理人员接收到数据集资源申请后,处理数据完成后,通知用户。
- 数据提供方式数据两种提供方式,在线阅览和数据接口。
- 数据建模分析同上业务开发人员需求,需要数据仍然向数据管理员申请数据,指定需要的数据。数据管理人员在平台上,制作数据主题。同时,在线的数据分析平台会预置一些数据图表、计算公式等。
- 数据安全在实际业务中,尤其是 涉及机密和敏感数据时,仅限授权用户访问就至关重要。同时访问是否合理等信息也 需要系统记录下来,让管理员可以回溯,进一步保证数据安全。平台通过认证 (Authentication)、授权(Authorization)、审计(Audit)三个方面来保证数据安全。
- 认证认证是用户进入系统的第一道屏障。建议采用了 Kerberos 做用户级别的认证。Kerberos 的设计主要针对 client-server 模型,基于加密方法建立用户(和系统)识别自己的方法,对个人通信以安全的手段进行身份认证,用户和服务器都能验证对方的身份。
- 授权平台提供基于角色和个人的访问控制。对 HDFS、Hive 等实现了统一的,细粒度的数据访问控制。从数据角度,可以查看当前何种角色/何人有何种权限。从角色/个人角度,可以查看对哪些数据有何种权限。
(3)审计 平台为项目安全提供较直观的整体评估和事件跟踪,包括实时监测对系统敏感信 息的访问和操作行为,根据规则设定报警并及时阻断违规操作,收集并记录行为,可 检索所有记录,提供统计信息五个方面。 监控处理的信息包括用户动作,管理员动作两大类。用户动作,所有用户的登录 信息,对数据、对资源、对服务的访问和操作等;管理员动作,管理员对项目、成员等做出的配置等。
管理规范建设
将数据平台的作用和价值最大化,靠的是软件和制度规范,比如在创建数据表时,没有规范的情况下,可能会带来数据血缘的杂乱等情况。数据平台管理的规范是一个体系化,以下为举例一些规范。
1、数据仓库层次结构规范可分为基本分层结构规范、各层物理表命名规范、数据库对象命名规范等。
2、数据库安全管理规范为了规范管理,做好经营分析数据仓库的安全管理工作,实现不同的责任人不同的层次,将用户权限尽可能的管理起来同时又不影响正常工作,需要对数据库进行安全管理,如:(1)数据库管理人员由项目经理和数据经理来掌控,一般情况下不得使用DBA角色登录数据库。(2)数据人员使用数据库开发人员角色登录,每个数据人员一个用户,归属数据库开发人员组。(3)前台程序开发人员,由界面开发人员使用,可以查看所有的表,但是无法进行DDL操作。
建设经验分享
数据管理平台体系涵盖既包含数据技术平台,也包含数据开发、数据模型、数据应用产品。通过建设数据平台建立数据管理和数据应用提现,规模化服务业务,保证数据质量,更大限度的发挥数据价值,主要有以下三个方面来保障建设:
1、数据同步一致性数据同步过程中的一致性问题主要包含如下几大分类,增量一致性、状态变更一致性、数据丢失。
增量一致性:一般情况下,可以用时间维度或者id来做增量标识。
状态变更一致性:如用户更新了个人信息或者订单状态变更,最好的办法是同步日志,要不然就是根据时间范围批量更新。
数据丢失:在传输过程中由于程序错误等情况的发送,目前的解决办法分为两种:
(1)发送端以批的形式,同时配合事务。(2)接收端根据不同数据采用不同的规避策略来实现,如目的有自增长ID,一般是容错后报错提醒。
2、数据实时同步源数据变化捕获是数据集成的起点,获取数据源变化主要有三种方式:基于日志的解析模式、基于增量条件查询模式、数据源主动Push模式。通常来说,采用数据库的日志进行增量捕获应当被优先考虑。能够完整获取数据变化的操作类型,尤其是Delete操作,这是增量条件查询模式很难做到的;不依赖特别的数据字段语义,例如更新时间;多数情况下具备较强的实时性。
3、数据质量管理不论是数据同步还是数据的使用,数据治理至关重要。比如在数据同步过程中,出现了不合法的数据格式,在源库中存储没有问题,同步就会出现一些问题。另外在数据分析时,特别是数值分析,出现的数值是字符型就无法分析了。数据治理的工作展开,主要考虑三个维度:模型架构、平台技术和流程规范。
(1)在模型架构层面,依据传统数据仓库的理论是对数据进行分层管理,每一层进行相应的业务主题梳理,提炼出业务实体、实体之间的关系、实体的业务行为以及这些由业务行为所沉淀出的度量指标。
(2)在平台技术层面,首先要有元数据管理系统,其次要有数据血缘追溯系统、数据质量监测系统等,这些平台技术可以帮助我们部分实现自动化管理。作为互联网企业,业务迭代、表以及字段的增加速度都非常快,如果没有好的平台技术支撑,消耗的人力成本会非常高。
免责声明:本公众号所发布的文章为本公众号原创,或者是在网络搜索到的优秀文章进行的编辑整理,文章版权归原作者所有,仅供读者朋友们学习、参考。对于分享的非原创文章,有些因为无法找到真正来源,如果标错来源或者对于文章中所使用的图片、链接等所包含但不限于软件、资料等,如有侵权,请直接联系后台,说明具体的文章,后台会尽快删除。给您带来的不便,深表歉意。
相关文章:
此文详解,数据仓库管理建设的经验
目前由于数据分散在不同的存储环境或数据库中,对于新业务需求的开发需要人工先从不同的数据库中同步、集中、合并等处理,造成资源和人力的浪费。同时,目前的系统架构,无法为未来数据驱动业务创新的理念提供友好的支撑。需要建设新…...
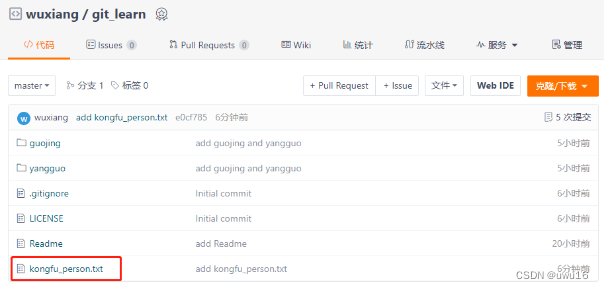
01 - 工作区、暂存区、版本库、远程仓库 - 以一次连贯的提交操作为例
查看所有文章链接:(更新中)GIT常用场景- 目录 文章目录 1. 工作区、暂存区、版本库、远程仓库1.1 工作区1.2 工作区 > 暂存区:git add1.3 暂存区 > 版本库:git commit1.4 push到远程仓库 1. 工作区、暂存区、版本…...

cesium学习记录06-视图、场景与相机
一、视图(Viewer) viewer是cesium的核心类,是一切的开端。通过new Cesium.Viewer(container, options)来创建一个Viewer对象,而通过这个 Viewer对象,可以添加图层、实体、相机控制等,以及设置一些全局属性…...

flutter开发实战-MethodChannel实现flutter与原生Android双向通信
flutter开发实战-MethodChannel实现flutter与原生Android双向通信 最近开发中需要原生Android与flutter实现通信,这里使用的MethodChannel 一、MethodChannel MethodChannel:用于传递方法调用(method invocation)。 通道的客户端和宿主端通过传递给通…...
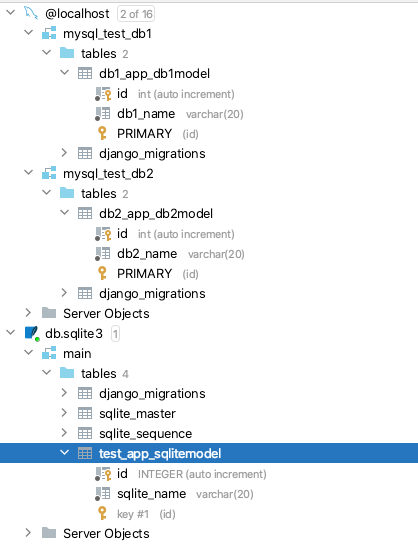
django使用多个数据库实现
一、说明: 在开发 Django 项目的时候,很多时候都是使用一个数据库,即 settings 中只有 default 数据库,但是有一些项目确实也需要使用多个数据库,这样的项目,在数据库配置和使用的时候,就比较麻…...

Linux常见面试题,应对面试分享
操作系统基础 1.cpu占⽤率太⾼了怎么办? 排查思路是什么,怎么定位这个问题,处理流程 其他程序: 1.通过top命令按照CPU使⽤率排序找出占⽤资源最⾼的进程 2.lsof查看这个进程在使⽤什么⽂件或者有哪些线程 3.询问开发或者⽼⼤,是什么业务在使⽤这个进程…...
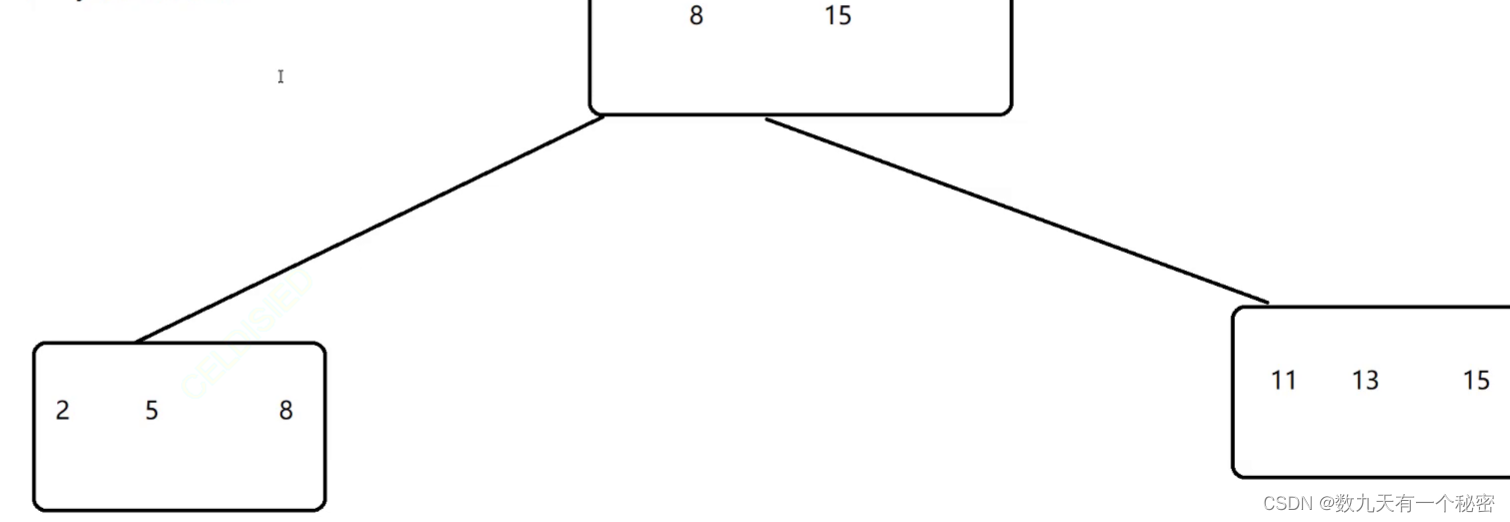
mysql索引的数据结构(Innodb)
首选要注意,这里的数据结构是存储在硬盘上的数据结构,不是内存中的数据结构,要重点考虑io次数. 一.不适合的数据结构: 1.Hash:不适合进行范围查询和模糊匹配查询.(有些数据库索引会使用Hash,但是只能精准匹配) 2.红黑树:可以范围查询和模糊匹配,但是和硬盘io次数比较多. 二…...

【MySQL】Java实现JDBC编程
文章目录 1. JDBC2. 添加驱动包3. 编程3.1 创建数据源3.2 与数据库建立连接3.3 构造SQL语句3.4 执行SQL语句3.5 释放资源,关闭连接 1. JDBC 数据库编程必须掌握至少一门编程语言,一种数据库,会导入数据库驱动包。 操作和连接不同数据库都需要…...
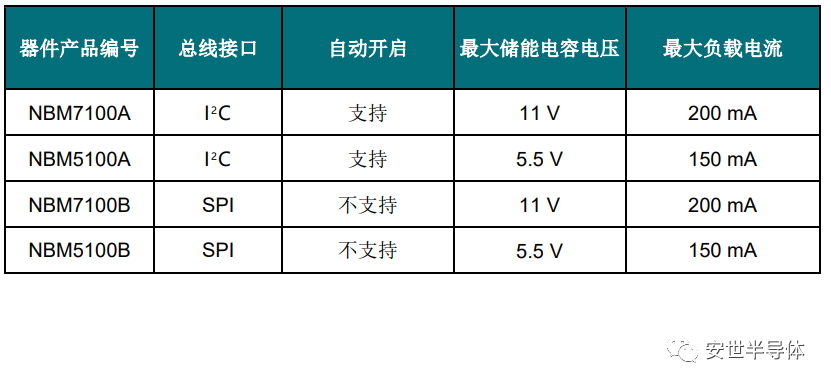
纽扣电池寿命和功率增强器
近日,基础半导体器件领域的高产能生产专家Nexperia(安世半导体)宣布推出NBM7100和NBM5100。这两款IC采用了具有突破意义的创新技术,是专为延长不可充电的典型纽扣锂电池寿命而设计的新型电池寿命增强器,相比于同类解决…...
bilibili倍数脚本,油猴脚本
一. 内容简介 bilibili倍数脚本,油猴脚本 二. 软件环境 2.1 Tampermonkey 三.主要流程 3.1 创建javascript脚本 点击添加新脚本 就是在 (function() {use strict;// 在这编写自己的脚本 })();倍数脚本,含解析 // UserScript // name bi…...
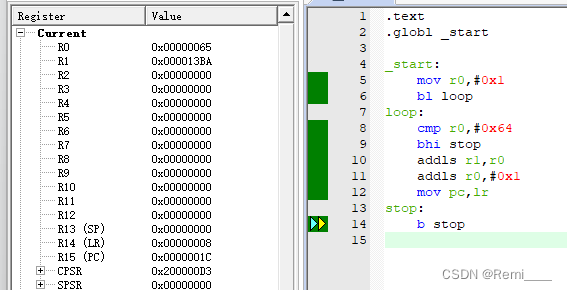
8.14 作业
1. .text .globl _start_start:mov r0,#0x9mov r1,#0xfbl loop loop:cmp r0,r1beq stopsubhi r0,r1subls r1,r0mov pc,lr stop:b stop 2.实现1-100的和 .text .globl _start_start:mov r0,#0x1bl loop loop:cmp r0,#0x64bhi stopaddls r1,r0addls r0,#0x1mov pc,lr stop:b sto…...

Debian安装和使用Elasticsearch 8.9
命令行通过 .deb 包安装 Elasticsearch 创建一个新用户 adduser elastic --> rust # 添加sudo权限 # https://phoenixnap.com/kb/how-to-create-sudo-user-on-ubuntu usermod -aG sudo elastic groups elastic下载Elasticsearch v8.9.0 Debian 包 https://www.elastic.co/…...

三 、CTR预估数据准备
三 CTR预估数据准备 3.1 分析并预处理raw_sample数据集 # 从HDFS中加载样本数据信息 df spark.read.csv("hdfs://localhost:9000/datasets/raw_sample.csv", headerTrue) df.show() # 展示数据,默认前20条 df.printSchema()显示结果: ------------…...
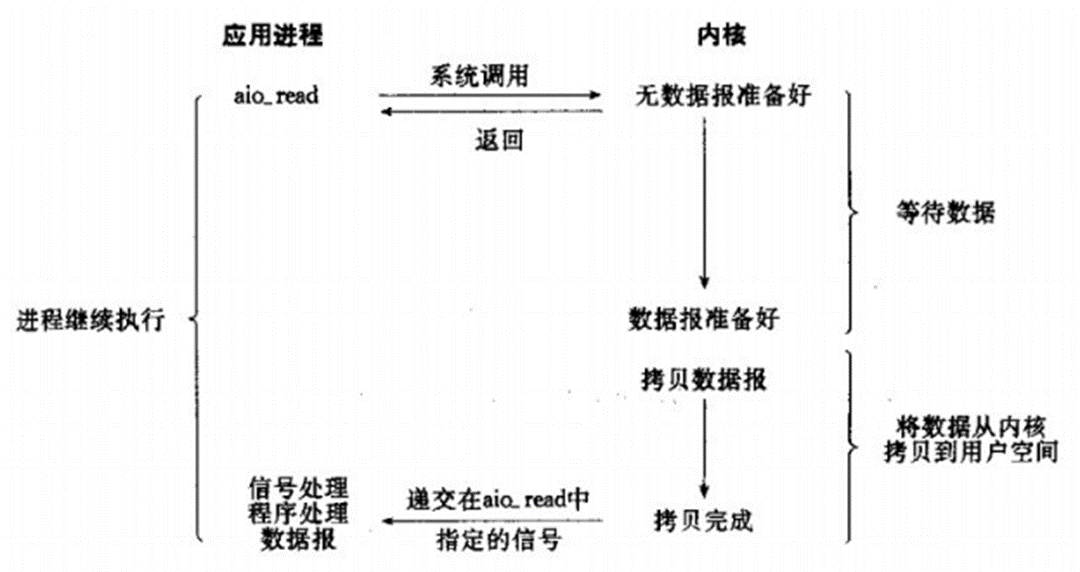
netty学习分享 二
操作系统IO模型与实现原理 阻塞IO 模型 应用程序调用一个IO函数,导致应用程序阻塞,等待数据准备好。如果数据没有准备好,一直等待….数据准备好了,从内核拷贝到用户空间,IO函数返回成功指示。 当调用recv()函数时,系…...

聊聊web服务器NGINX
文章目录 聊聊web服务器NGINXNGINX的起源NGINX早期阶段首次发布快速扩展模块化架构逐步增加功能商业收购 NGINX能做什么NGINX的优势NGINX为何能兴起 聊聊web服务器NGINX NGINX的起源 NGINX是一个 HTTP 和反向代理服务器,一个邮件代理服务器,以及一个通…...

【hello C++】特殊类设计
目录 一、设计一个类,不能被拷贝 二、设计一个类,只能在堆上创建对象 三、设计一个类,只能在栈上创建对象 四、请设计一个类,不能被继承 五、请设计一个类,只能创建一个对象(单例模式) C🌷 一、设计一个类&…...
js实现按创建时间戳1609459200000 开始往后开始显示运行时长-demo
运行时长 00日 00时 17分 59秒 代码 function calculateRuntime(timestamp) {const startTime Date.now(); // 获取当前时间戳//const runtimeElement document.getElementById(runtime); // 获取显示运行时长的元素function updateRuntime() {const currentTimestamp Date…...
latex三线表按页面大小填充
latex三线表按页面大小填充 使用Latex表格时会出现下图情况,表格没有填充整个页面,导致不美观。 解决方法: 在\begin{tabular}前加上\resizebox{\linewidth}{!}{ , 在\end{tabular} 后加 ‘}’ 如下:\resizebox{…...
佛祖保佑,永不宕机,永无bug
当我们的程序编译通过,能预防的bug也都预防了,其它的就只能交给天意了。当然请求佛祖的保佑也是必不可少的。 下面是一些常用的保佑图: 佛祖保佑图 ——————————————————————————————————————————…...

redis分布式集群-redis+keepalived+ haproxy
redis分布式集群架构(RedisKeepalivedHaproxy)至少需要3台服务器、6个节点,一台服务器2个节点。 redis分布式集群架构中的每台服务器都使用六个端口来实现多路复用,最终实现主从热备、负载均衡、秒级切换的目标。 redis分布式集…...
 显卡排行榜 天梯图)
top50 BF16算力(TFLOPS) 显卡排行榜 天梯图
排名显卡型号BF16算力(TFLOPS)售价(元)单TFLOPS价格(元)1B200(SXM)45002200000488.892H200(SXM)19801200000606.063MI300X1307750000573.834H100 SXM519501100000564.105RTX PRO 6000 Blackwell1150780000678.266H100 PCIe 80GB1560850000544.877RTX 50906803400050.008A100 80…...

从多路复用到三维光阵:Arduino驱动8x8x8 LED立方体全解析
1. 项目概述:用Arduino点亮一个三维世界几年前,我第一次在创客展上看到一个8x8x8的LED立方体,那种由数百个光点构成的、在三维空间中流动的动画效果,瞬间就把我吸引住了。它不像普通的平面LED屏,而是真正有“深度”的光…...

终极艾尔登法环帧率解锁指南:轻松突破60FPS限制
终极艾尔登法环帧率解锁指南:轻松突破60FPS限制 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenRing…...

告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF
告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF 【免费下载链接】caj2pdf Convert CAJ (China Academic Journals) files to PDF. 转换中国知网 CAJ 格式文献为 PDF。佛系转换,成功与否,皆是玄学。 项目地址: https://gitcode.com/…...

Hindsight API参考:REST接口完整文档
Hindsight API参考:REST接口完整文档 【免费下载链接】hindsight Hindsight: Agent Memory That Learns 项目地址: https://gitcode.com/GitHub_Trending/hindsight2/hindsight Hindsight是一个强大的Agent Memory系统,提供了全面的REST API接口&…...

TV Bro电视浏览器:为智能电视打造的最佳遥控器上网解决方案
TV Bro电视浏览器:为智能电视打造的最佳遥控器上网解决方案 【免费下载链接】tv-bro Simple web browser for android optimized to use with TV remote 项目地址: https://gitcode.com/gh_mirrors/tv/tv-bro 还在为智能电视上网操作不便而烦恼吗?…...

ShrinkBox后门攻击:如何让自动驾驶模型“看错”距离,威胁ML-ADAS安全
1. 项目概述在自动驾驶和高级驾驶辅助系统(ADAS)领域,基于机器学习的目标检测模型,如YOLO系列,已成为感知环境、实现碰撞预警的核心组件。这些模型通过实时识别和定位道路上的车辆、行人等目标,为后续的距离…...

JWT弱密钥爆破实战:从HS256签名原理到CTF权限提升
1. 这不是密码学考试,而是一场“密钥猜谜”实战JWT(JSON Web Token)在现代Web系统中早已不是可选项,而是默认配置。登录成功后返回一串形如eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyX2lkIjoxMjMsIm5hbWUiOiLnlKjliYkiLCJpYX…...

claude code用户如何迁移到taotoken解决封号与token不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code 用户如何迁移到 Taotoken 解决封号与 Token 不足问题 应用场景类,针对 Claude Code 用户常遇封号与 Token…...

MeloTTS实战指南:解决多语言TTS部署中的核心挑战
MeloTTS实战指南:解决多语言TTS部署中的核心挑战 【免费下载链接】MeloTTS High-quality multi-lingual text-to-speech library by MyShell.ai. Support English, Spanish, French, Chinese, Japanese and Korean. 项目地址: https://gitcode.com/GitHub_Trendin…...