数据结构篇七:排序
文章目录
- 前言
- 1.插入排序
- 1.1 基本思想
- 1.2 代码实现
- 1.3 特性总结
- 2.希尔排序
- 2.1 基本思想
- 2.2 代码实现
- 2.3 特性总结
- 3. 选择排序
- 3.1 基本思想
- 3.2 代码实现
- 3.3 特性总结
- 4. 堆排序
- 4.1 基本思想
- 4.2 代码实现
- 4.3 特性总结
- 5. 冒泡排序
- 5.1 基本思想
- 5.2 代码实现
- 5.3 特性总结
- 6. 快速排序
- 6.1 基本思想
- 6.1.1 思想一
- 6.1.2 思想二
- 6.1.3 思想三
- 6.2 代码实现
- 6.2.1 递归版本
- 6.2.2 非递归版本
- 6.3 优化
- 6.4 特性总结
- 7.归并排序
- 7.1 基本思想
- 7.2 代码实现
- 7.2.1 递归版本
- 7.2.2 非递归版本
- 7.3 特性总结
- 8. 计数排序
- 8.1 基本思想
- 8.2 代码实现
- 8.3 特性总结
- 9. 总结
前言
所谓排序,就是使一串记录按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。不同的排序算法各有优劣,本章内容讲介绍插入排序、希尔排序、选择排序、冒泡排序、堆排序、快速排序、归并排序以及计数排序八大排序算法。
1.插入排序
1.1 基本思想
插入排序是一种比较简单的排序算法,它的基本思想是:以待排序数据的第一个数据为标准,将这一个数据看为一个已排好的数据(此时只看这一个数据,先记为a),然后将它后一个数据(记为b)将 b 与 a 进行比较,如果 a 比 b 大,就将 a 向后覆盖(升序),直到遇到比 b 小的或者到数据结束停止。
如图:
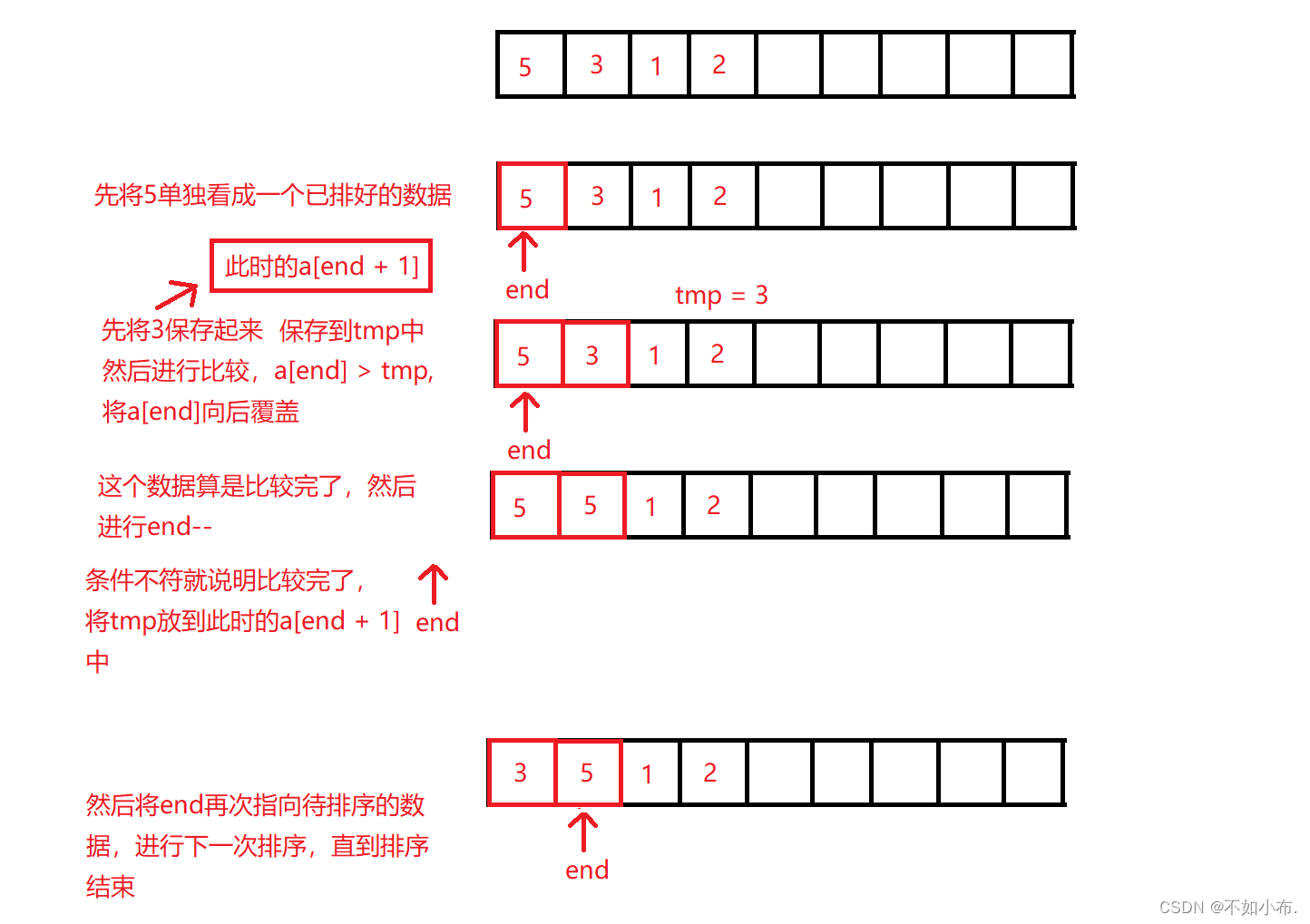
图和代码一起看更容易理解一些。
1.2 代码实现
void InsertSort(int* a, int n)
{assert(a);int i = 0;for (i = 0; i < n - 1; i++){int end = i;int tmp = a[end + 1];while (end >= 0){if (a[end] > tmp){a[end + 1] = a[end];end--;}else{break;}}a[end + 1] = tmp;}
}
1.3 特性总结
- 元素集合越接近有序,直接插入排序算法的时间效率越高。
- 时间复杂度:O(N^2)
- 空间复杂度:O(1),它是一种稳定的排序算法
- 稳定性:稳定
2.希尔排序
2.1 基本思想
先选定一个整数,把待排序数据分成个组,所有距离为 gap 的数据分在同一组内,并对每一组内的记录进行排序。然后取上述重复分组和排序的工作。当到达 gap = 1 时,所有记录在统一组内排好序。
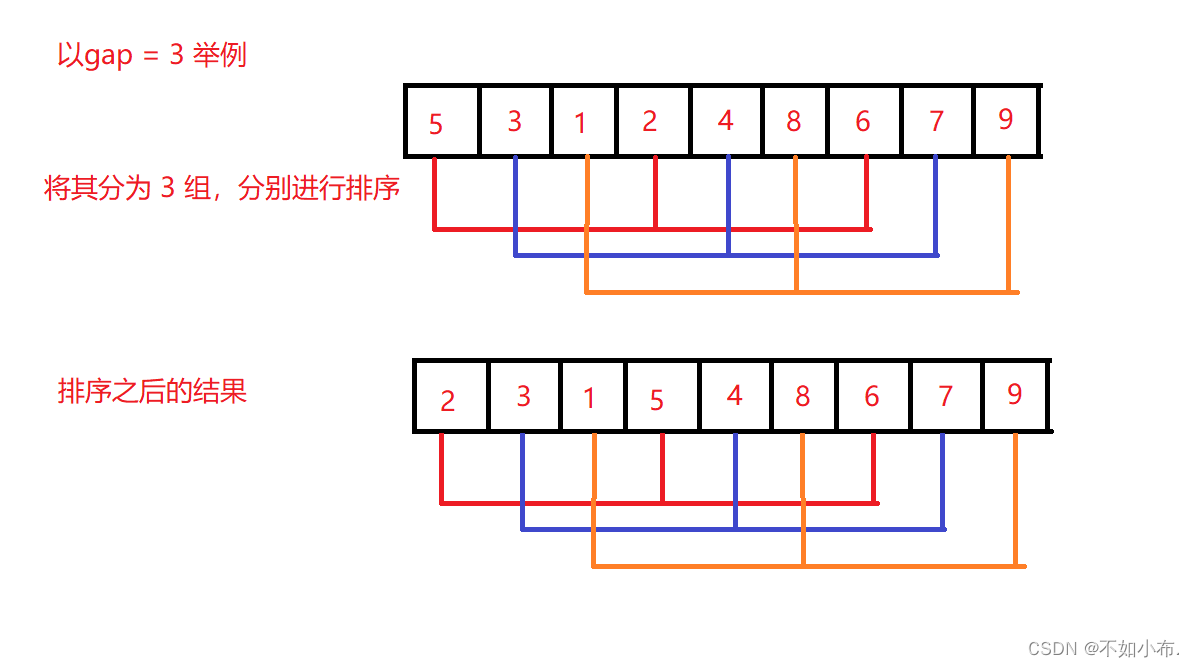
实际是先将数据分为许多组,分别进行排序,每一次排序都会使较小数移到前面,使数据逐渐接近有序。希尔排序的过程就是先进行多次预排序(分组排序的过程),一直到数据间隔 gap = 1 时完成所有排序。在实际中 gap 的初始值可给数据个数的一半,每排完一次 gap 就除 2 ,直到 gap = 1 时结束排序。
2.2 代码实现
void ShellSort(int* a, int n)
{int gap = 3;int i = 0;int j = 0;//while (gap > 1)//{// gap /= 2; //当gap为1时就直接插入排序// for (j = 0; j < gap; j++) //通过j变量控制i变量,依次排序每个元素// {// for (i = j; i < n - gap; i += gap) // 排一组// {// int end = i;// int tmp = a[end + gap];// while (end >= 0) // 排一个// {// if (a[end] > tmp)// {// a[end + gap] = a[end];// end -= gap;// }// else// {// break;// }// }// a[end + gap] = tmp;// }// }//}while (gap > 1){gap /= 2; //当gap为1时就直接插入排序for (i = 0; i < n - gap; i++) // 一个接一个排{int end = i;int tmp = a[end + gap];while (end >= 0) // 排一个{if (a[end] > tmp){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}
}
每组的数据排序采用了直接插入排序,希尔排序的主要思想是需要进行多次预排序,使数据逐渐有序。
2.3 特性总结
- 希尔排序是对直接插入排序的优化。
- 当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样就
会很快。这样整体而言,可以达到优化的效果。我们实现后可以进行性能测试的对比。 - 希尔排序的时间复杂度不好计算,因为gap的取值方法很多,导致很难去计算,因此在许多教材中给出的希尔排序的时间复杂度都不固定。
- 稳定性:不稳定
3. 选择排序
3.1 基本思想
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完
3.2 代码实现
这里进行了一点点小小的优化,同时找到最大和最小值,分别放到起始位置和末位置。
void Swap(int* x, int* y)
{int tmp = *x;*x = *y;*y = tmp;
}//O(n*2)
void SelectSort(int* a, int n)
{int end = n - 1;int begin = 0;while (begin < end){int mini = begin, maxi = end;int i = 0;for (i = begin; i <= end; i++){if (a[i] < a[mini])mini = i;if (a[i] > a[maxi])maxi = i;}Swap(&a[mini], &a[begin]);if (begin == maxi)maxi = mini;Swap(&a[maxi], &a[end]);begin++;end--;}
}
值得注意的是当 begin 与 maxi 重合的情况,因为我们是先交换最小值与首位置,交换完后就会导致 maxi 指向的值不再是最大值,而是跑到了交换后的 mini 所指向的地方,因此当 begin 与 maxi 重合时,在交换完后我们就需要修改 maxi 的位置,使其指向正确的位置。具体如图:
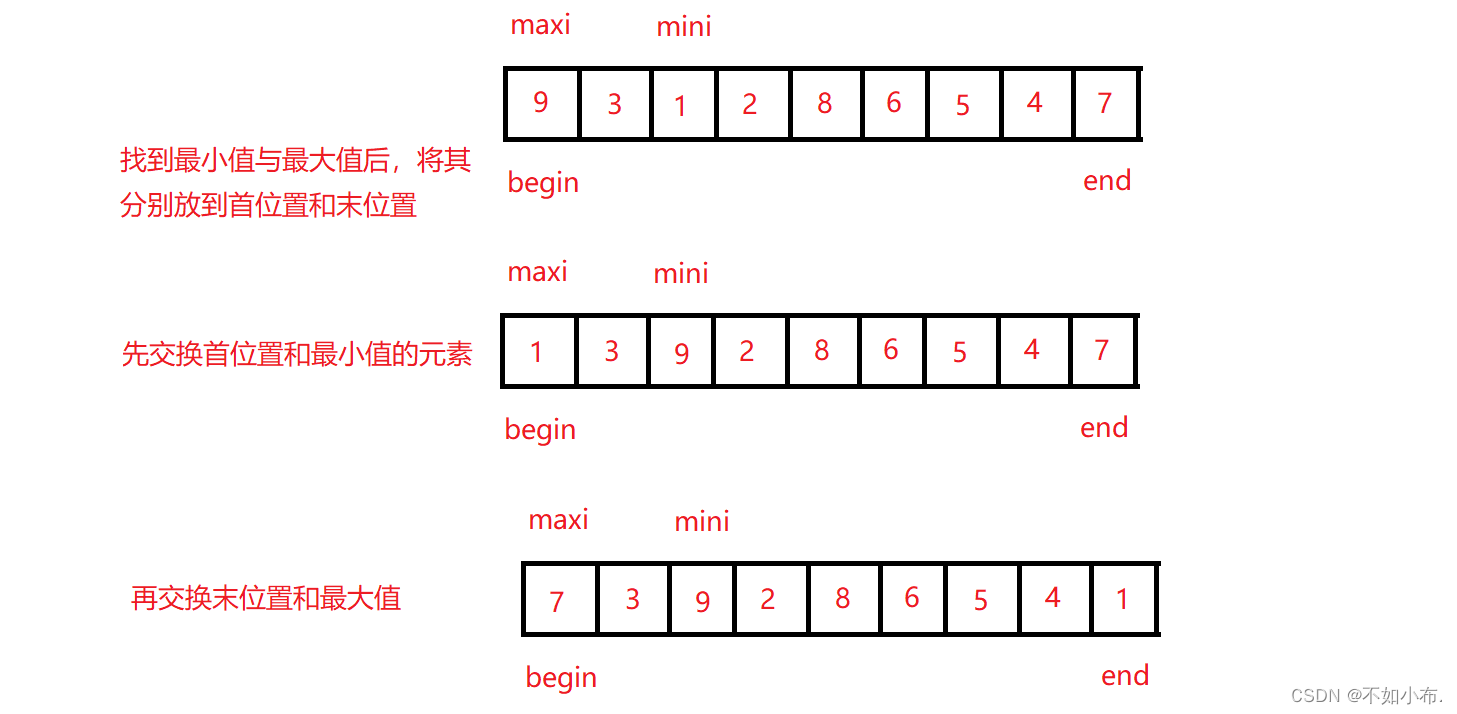
3.3 特性总结
- 直接选择排序思考非常好理解,但是效率不是很好,实际中很少使用。
- 时间复杂度:O(N^2)
- 空间复杂度:O(1)
- 稳定性:不稳定
4. 堆排序
4.1 基本思想
堆排序是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是通过堆来进行选择数据。需要注意的是排升序要建大堆,排降序建小堆。具体思路在我的另一篇文章数据结构篇六:二叉树中有所讲解,想了解的可以点击这里进行跳转,这里我就只贴上代码了。
4.2 代码实现
//向上调整
void AdjustUp(int* data, int child)
{int parent = (child - 1) / 2;while (child > 0){if (data[child] < data[parent]) // "<" 小堆{Swap(&data[child], &data[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}
}//向下调整
void AdjustDown(int* data, int size, int parent)
{int child = (parent * 2) + 1;while (child < size){if (child + 1 < size && data[child] > data[child + 1]) // "<" 大堆{child++;}if (data[child] < data[parent]) // ">"大堆{Swap(&data[child], &data[parent]);parent = child;child = (parent * 2) + 1;}else{break;}}
}//堆排序
//升序 -- 大堆
//降序 -- 小堆
void HeapSort(int* a, int n)
{1.建堆 O(N*logn)int i = 0;//for (i = 1; i < n; i++)//{// AdjustUp(a, i);//}//2.建堆 O(N)for (i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(a, n, i);}int end = n - 1;while (end >= 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);end--;}
}
4.3 特性总结
- 堆排序使用堆来选数,效率就高了很多。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(1)
- 稳定性:不稳定
5. 冒泡排序
5.1 基本思想
根据序列中两个数据的大小来对换这两个数据在序列中的位置。这个很简单,将每个数与其他数依次进行比较排序就完成了。
5.2 代码实现
void BubbleSort(int* a, int n)
{int i = 0;for (i = 0; i < n - 1; i++) //趟数{int j = 0;for (j = 0; j < n - 1 - i; j++) //每个元素比较次数{if (a[j] > a[j + 1]){Swap(&a[j], &a[j + 1]);}}}
}
5.3 特性总结
- 冒泡排序是一种非常容易理解的排序。
- 时间复杂度:O(N^2)
- 空间复杂度:O(1)
- 稳定性:稳定
6. 快速排序
6.1 基本思想
取待排序元素序列中的某元素作为基准值,按照该基准值将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
6.1.1 思想一
这里我将介绍三种快速排序的思路,先看第一种。左子序列中需要所有元素均小于基准值,右子序列中需要所有元素均大于基准值,因此我们要在右边找小于基准值的移到左边,左边找大于基准值的移到右边。
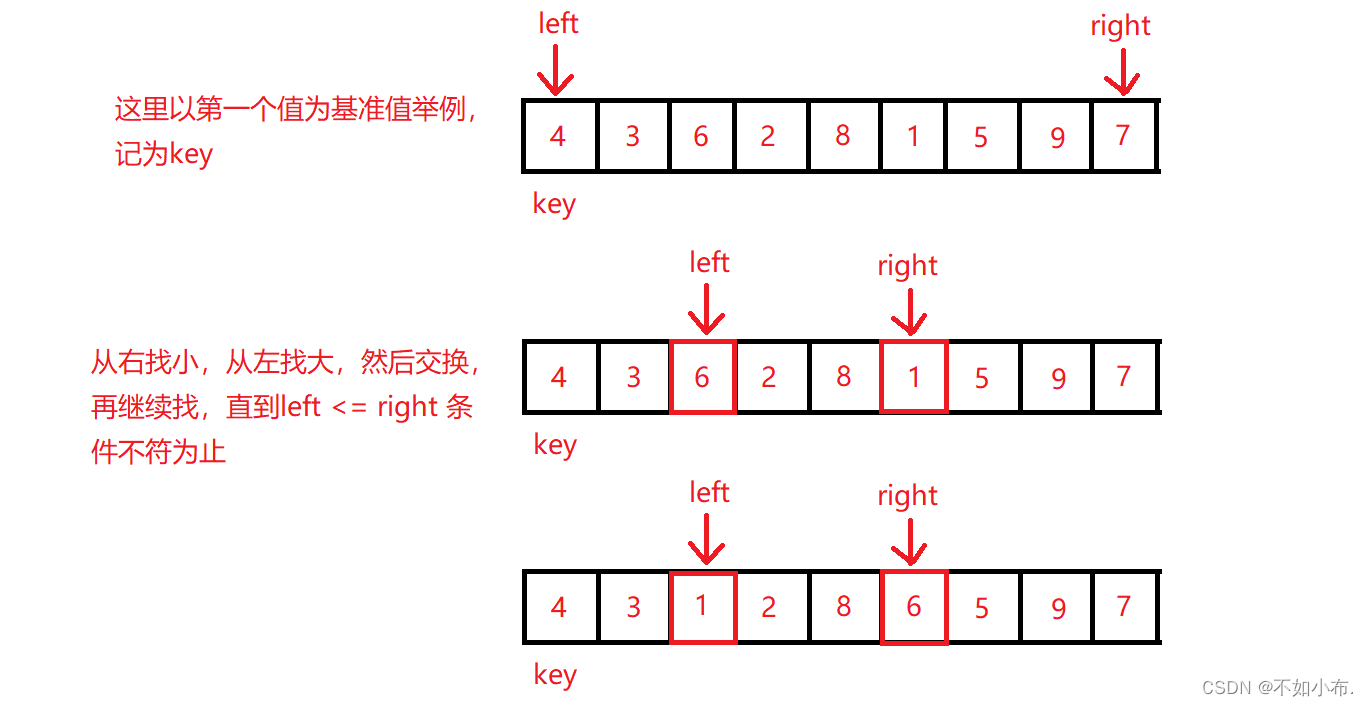
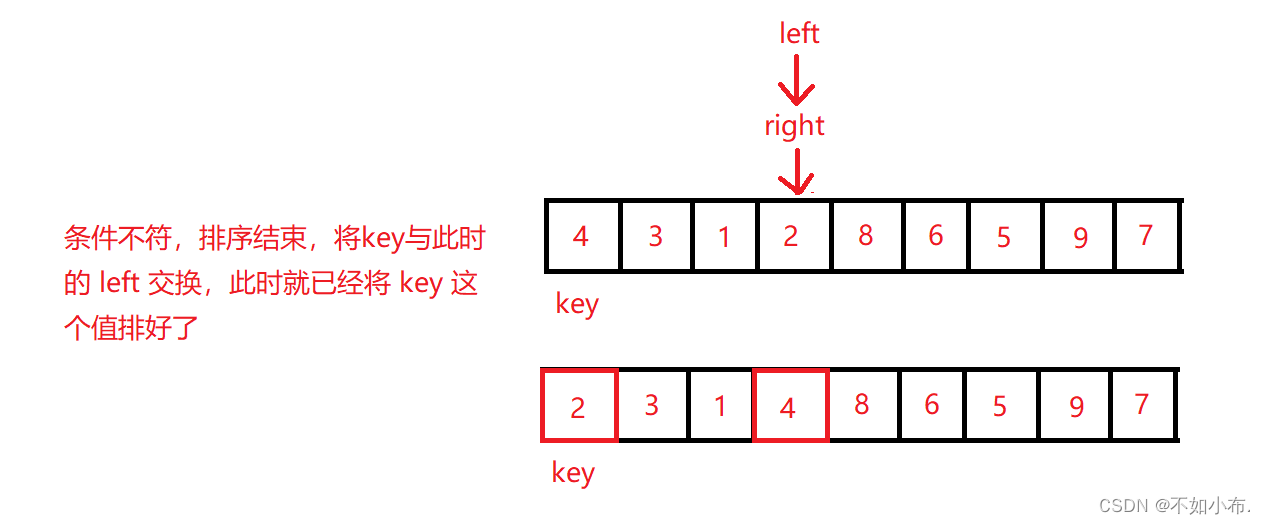
这里注意的是必须从右开始往左找,这样 left 最终停止的位置才能将 key 放到正确的位置上。
这只是进行的一次排序,之后就是以它为分界点,对左右序列继续排序,是一个不断分割 + 排序的过程,因此我们可以考虑用递归来解决。
6.1.2 思想二
是一个挖坑的思路,大体上与第一种相似,略有不同。

6.1.3 思想三
用 prev 指向数据开头,cur 指向 prev 的下一个,再用 key 记录第一个数据当作基准值。 用 cur 从头开始找比 key 小的,找到了就与 prev 的下一位置进行交换,因为当前的 prev 指向的是基准值,我们是从基准值的下一个位置开始排序的,所以是与基准值的下一位置进行交换。本质上可以看作为 prev 前的数据包括 prev 指向的数据,都是比基准值小的,而完成这一效果的做法就是通过 cur 来找到比基准值小的数据,然后与prev 的下一个数据进行交换再进行 prev++,直到cur 遍历完数据为止。
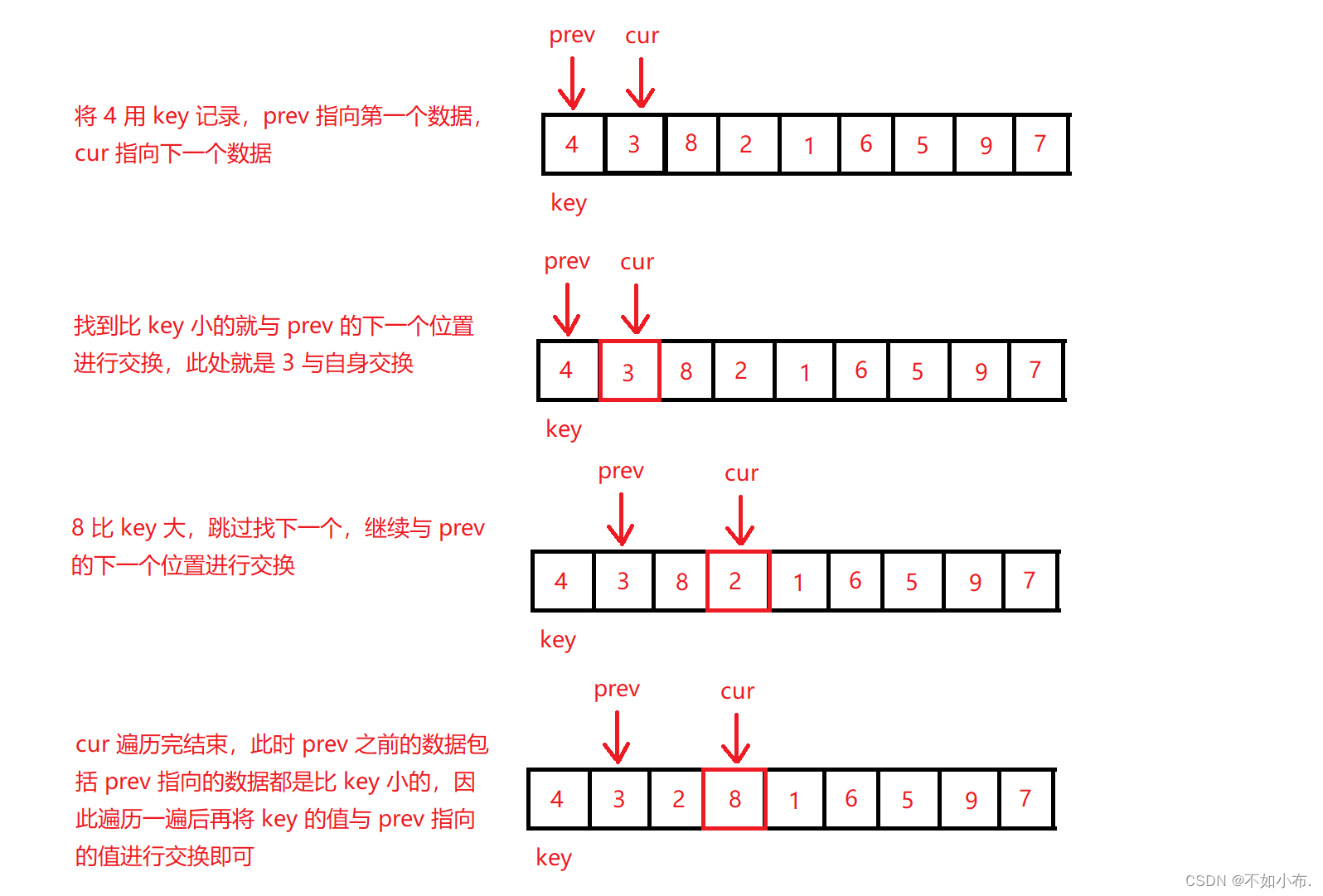
prev 之前的数据不包括 key 的位置,也就是从第二个数据开始到 prev 之间都是比 key 小的,而将此时的 prev 与 key 进行交换,就产生了从第一个数据开始到此时 prev 之前的数据都是比 key 小的了,说明这个数就排序完成了。
6.2 代码实现
int Partion1(int* a, int left, int right)
{int min = GetMidIndex(a, left, right);Swap(&a[left], &a[min]);int key = left;while (left < right){//从右往左,找小的while (left < right && a[right] >= a[key]){right--;}//从左往右,找大的while (left < right && a[left] <= a[key]){left++;}Swap(&a[left], &a[right]);}Swap(&a[left], &a[key]);return left;
}//挖坑法
int Partion2(int* a, int left, int right)
{int min = GetMidIndex(a, left, right);Swap(&a[left], &a[min]);int pivot = left;int key = a[left];while (left < right){//从右往左,找小的,放到左边的坑里while (left < right && a[right] >= key){right--;}//Swap(&a[pivot], &a[right]);a[pivot] = a[right];pivot = right;//从左往右,找大的,放到右边的坑里while (left < right && a[left] <= key){left++;}//Swap(&a[pivot], &a[left]);a[pivot] = a[left];pivot = left;}a[pivot] = key;return pivot;
}//前后指针
int Partion3(int* a, int left, int right)
{int key = left;int prev = left , cur = left + 1;while (cur <= right){if (a[key] > a[cur]){Swap(&a[cur], &a[++prev]);cur++;}else{cur++;}}Swap(&a[key], &a[prev]);return prev;
}
6.2.1 递归版本
三个思想每次返回的都是基准值的排序好之后的下标,也就是分成了左右两个子区间,用递归不断对子区间进行排序就可以了,如果不太理解递归过程,可以去跳转到数据结构篇六:二叉树这篇文章去看一看二叉树前序遍历递归。
void QuickSort(int* a, int left, int right)
{if (left >= right)return;int key = Partion3(a, left, right);QuickSort(a, left, key - 1);QuickSort(a, key + 1, right);
}
6.2.2 非递归版本
非递归的实现就需要借助栈的辅助了,我们将每一次需要进行排序的区间存入栈中,在每排序完一个子区间都会将这个子区间分成的更小的子区间进行压栈。每开始排序一个区间都会将该区间进行出栈,同时入栈这个区间的子区间,直到栈为空时说明所以区间都排序完成了。
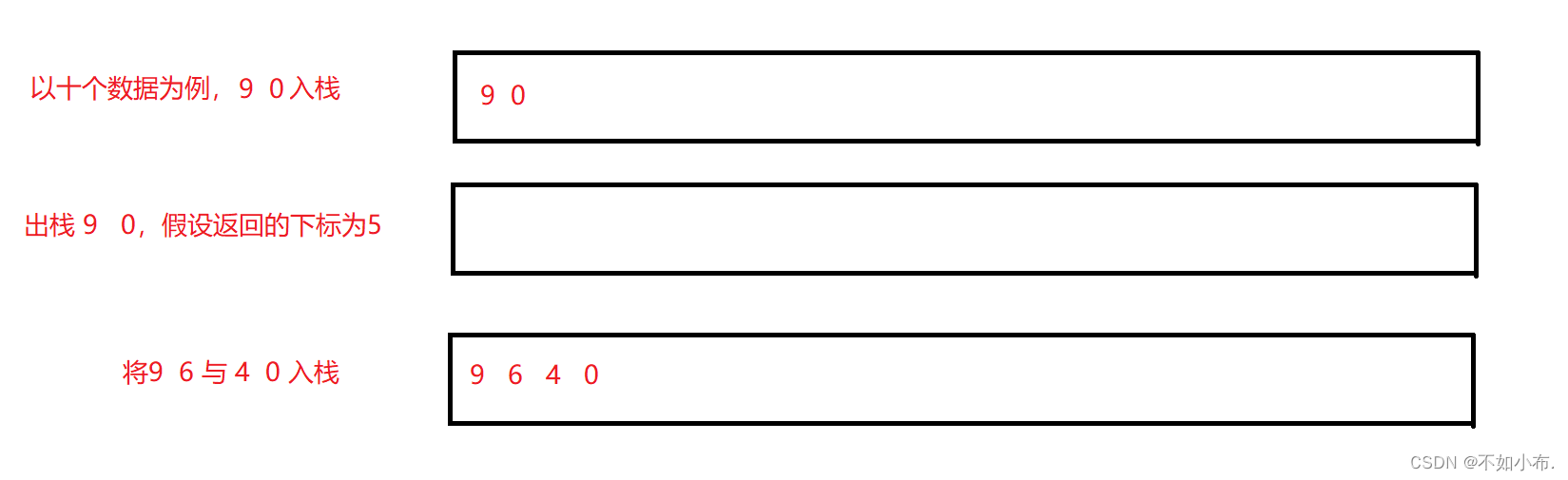
这样不断重复就相当于模拟了递归的过程。非递归的好处在于不需要消耗太多的空间,如果数据太多的话,递归深度过高容易造成栈溢出,非递归就很好的解决了这个问题。
void QuickSortNonR(int* a, int left, int right)
{Stack st;StackInit(&st);StackPush(&st, left); //入栈StackPush(&st, right);while (!StackEmpty(&st)){int end = StackTop(&st);//取栈顶元素StackPop(&st); //出栈int begin = StackTop(&st);StackPop(&st);int key = Partion3(a, begin, end);//[begin,key - 1] key [key + 1,end]if (begin < key - 1){StackPush(&st, begin); //入栈StackPush(&st, key - 1);}if (key + 1 < end){StackPush(&st, key + 1);StackPush(&st, end);}}StackDestroy(&st);
}
6.3 优化
大家看代码可以会看到一个GetMidIndex();这个函数,这是一个对与基准值选取的优化,假设第一个数据就是所有数据的最大值或者最小值,那么排序会出现什么情况?会出现第一次排序一直遍历完才找到,相较于两边同时找会慢上很多,因此才有了这个对 key 值选取的优化。
int GetMidIndex(int* a, int left, int right)
{int mid = (left + right) / 2;if (a[left] > a[mid]){if (a[mid] > a[right]){return mid;}else if(a[left] < a[right]){return left;}else{return right;}}else //a[left] < a[mid]{if (a[right] < a[left]){return left;}else if (a[right] > a[mid]){return mid;}else{return right;}}
}
6.4 特性总结
- 快速排序整体的综合性能和使用场景都是比较好的一个排序,但是对于已经比较有序的数据排序比较慢,是属于一个数据越乱排序效果越好的一个算法。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(logN)
- 稳定性:不稳定
7.归并排序
7.1 基本思想
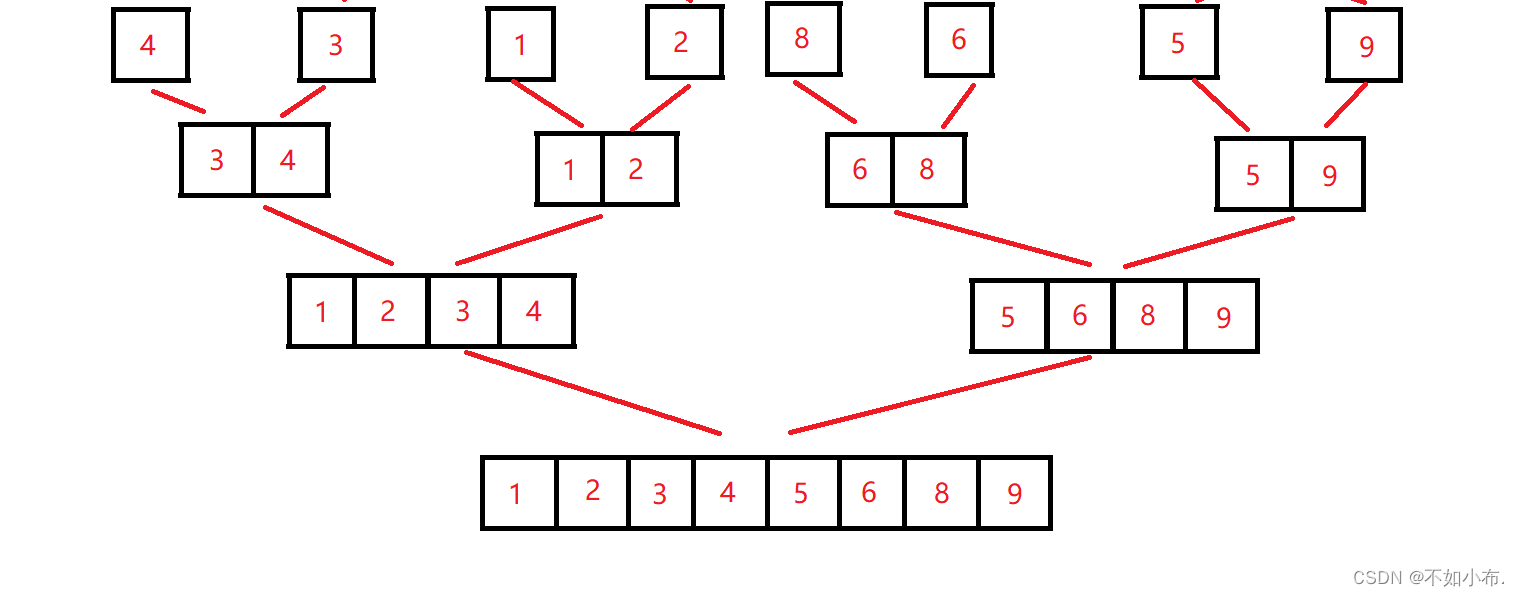
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个非常典型的应用。将已经有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
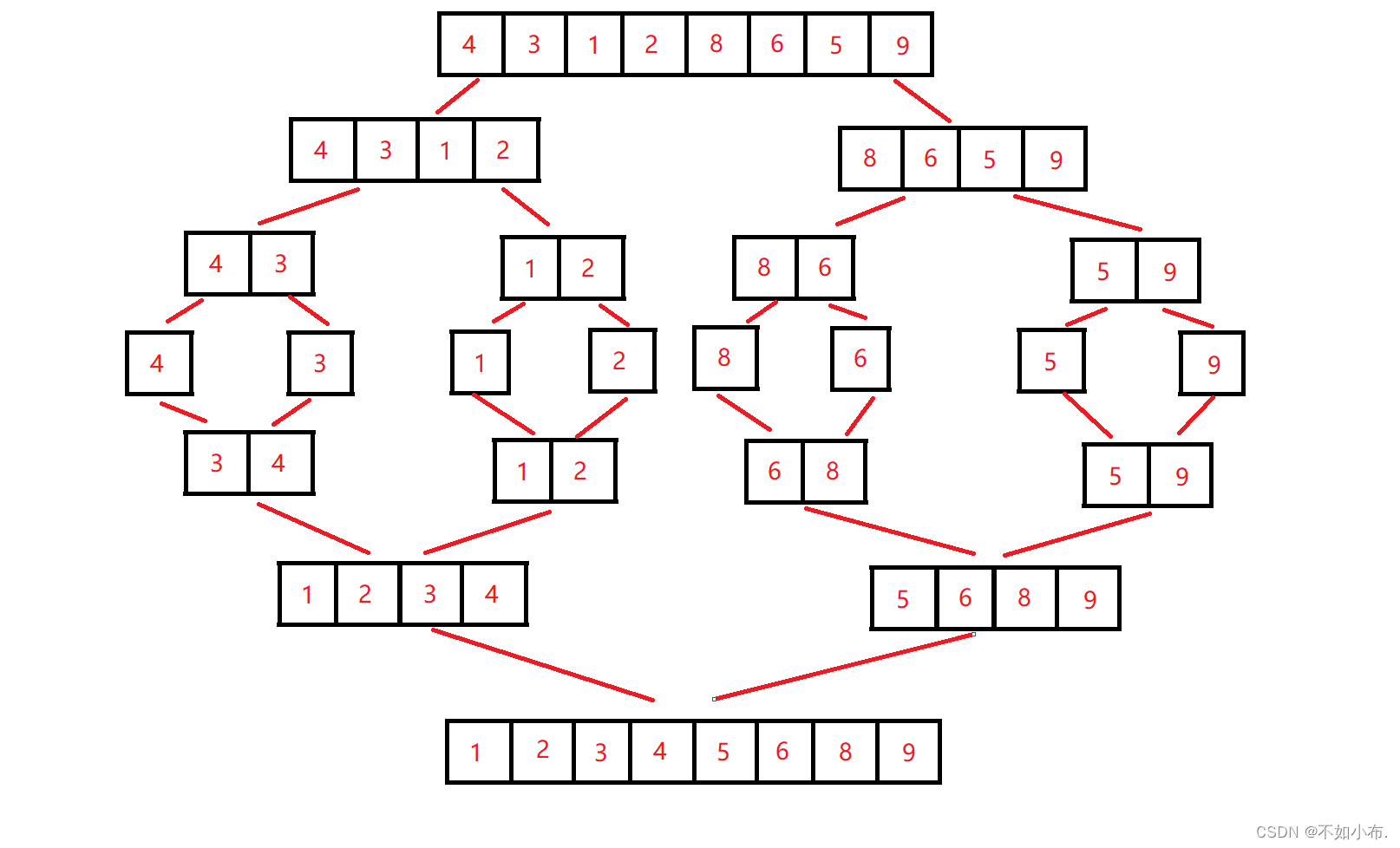
本质上为两两排序,四四排序……,不断增加数据进行排序的过程。我们要做的就是不断分割区别,再对相邻的两个区间进行排序。由于本身的数据需要进行比较,因此还需要一个临时数组来保存每次排序好的数据,在结束排序后再拷贝回原数组就可以了。递归过程可参考数据结构篇六:二叉树这篇文章来理解。
7.2 代码实现
7.2.1 递归版本
void _MergeSort(int* a, int left, int right, int* tmp)
{if (left >= right)return;//进行递归分割区间int mid = (left + right) / 2;_MergeSort(a, left, mid, tmp);_MergeSort(a, mid + 1, right, tmp);//进行排序int begin1 = left, end1 = mid; //左区间int begin2 = mid + 1, end2 = right;//右区间int i = left;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}while (begin1 <= end1){tmp[i++] = a[begin1++];}while (begin2 <= end2){tmp[i++] = a[begin2++];}}void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){printf("MergeSort:");exit(-1);}_MergeSort(a, 0, n - 1, tmp);free(tmp);tmp = NULL;
}
7.2.2 非递归版本
非递归第一时间时间是结束栈或者队列来完成,但是这里却不行,因为我们需要将区间先不断分割到最小才开始排序,而在用栈和队列模拟递归时存储的是区间的边界,到栈或者队列为空时就结束了。但是在这里,我们在分割到最小的区间时,在排序完出队列就结束了。

也就是这一步完成之后栈或者队列就为空了,就结束了,无法完成排序,所以不能用栈或者队列来辅助完成。
因此就要换一个思路,这里是通过 gap 来控制区间,不需要进行递归分割,直接用循环进行控制区间,通过 gap 来更改每次区间的大小。
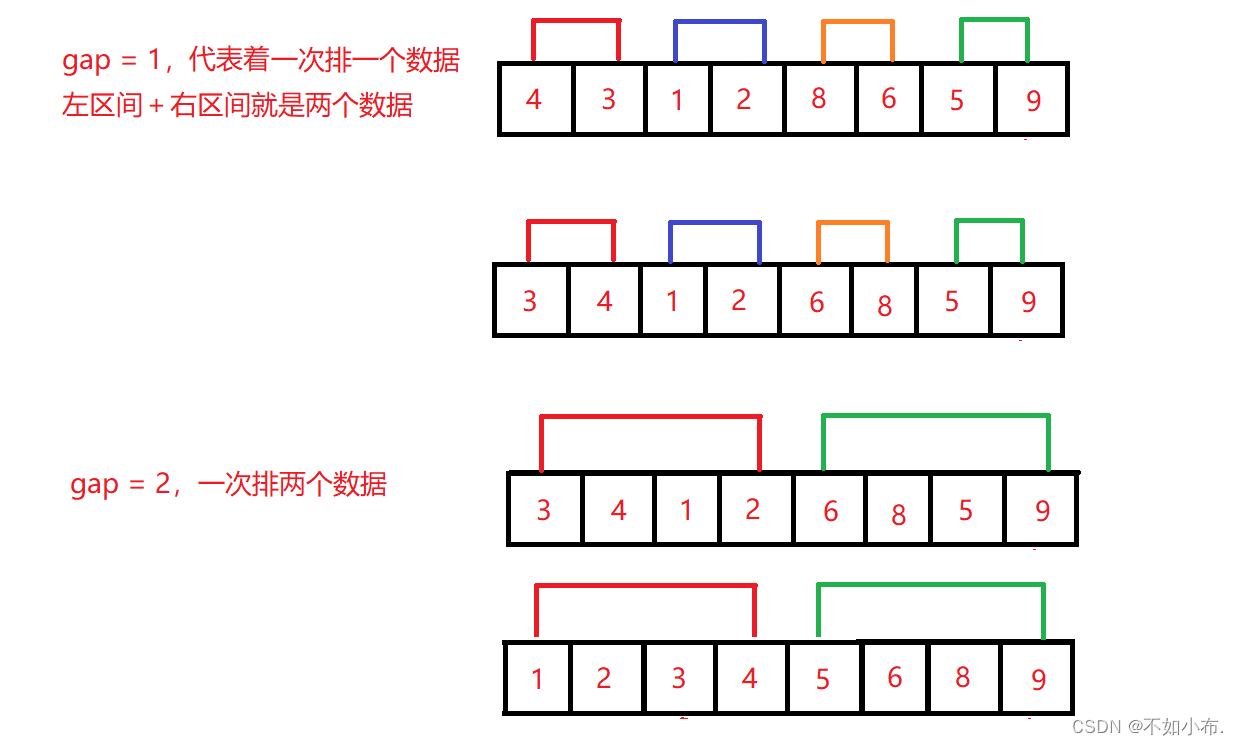
与这个对照看更容易理解。
但是这样就会出现一个大问题,gap 每次都是之前的二倍,也就是每次排序的数据个数都是之前的二倍,2,4,8,16……,那么如果是10个数据呢?就会出现越界情况,明明只有10个数据,你却访问到了10个数据后面的空间。因此还需要对这种情况进行调整,防止出现访问不该访问的地址空间的情况。
通过观看代码知道,会出现越界情况的只有end1,begin2,end2这三个,因为一个区间没有数据的话循环根本就不会进来的,而有数据的话 begin1 就不会越界。end2 越界的话只需要将 end2 的值改为 n - 1 就可以了,让它重新指向最后一个数据的位置就不会出现越界了,begin2 越界的话将 begin2 改为 n,end2 改为 n - 1,这样 begin2 > end2 就说明该区间不存在了,就不会访问这个区间了。end1 越界的情况与 end2 越界的处理方法一致。这样就完美解决了会发生越界的问题了。
void MergeSortNonR1(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){printf("MergeSort:");exit(-1);}int gap = 1, i = 0; //类似层序while (gap < n){for (i = 0; i < n; i = i + 2 * gap){//[i,i+gap-1] [i+gap, i+gap*2-1]int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + gap * 2 - 1;int j = i;//end2 越界if (end2 >= n){end2 = n - 1;}//begin2 越界 [begin2,end2]不存在,讲这个区间设置为不存在if (begin2 >= n){begin2 = n;end2 = n - 1;}//end1 越界,[begin2,end2]不存在if (end1 >= n){end1 = n - 1;}while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];}}while (begin1 <= end1){tmp[j++] = a[begin1++];}while (begin2 <= end2){tmp[j++] = a[begin2++];}}int j = 0;for (j = 0; j < n; j++){a[j] = tmp[j];}gap *= 2;}free(tmp);tmp = NULL;
}
7.3 特性总结
- 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(N)
- 稳定性:稳定
8. 计数排序
8.1 基本思想
统计相同元素出现次数,根据统计的结果将结果放回到原来的序列中。
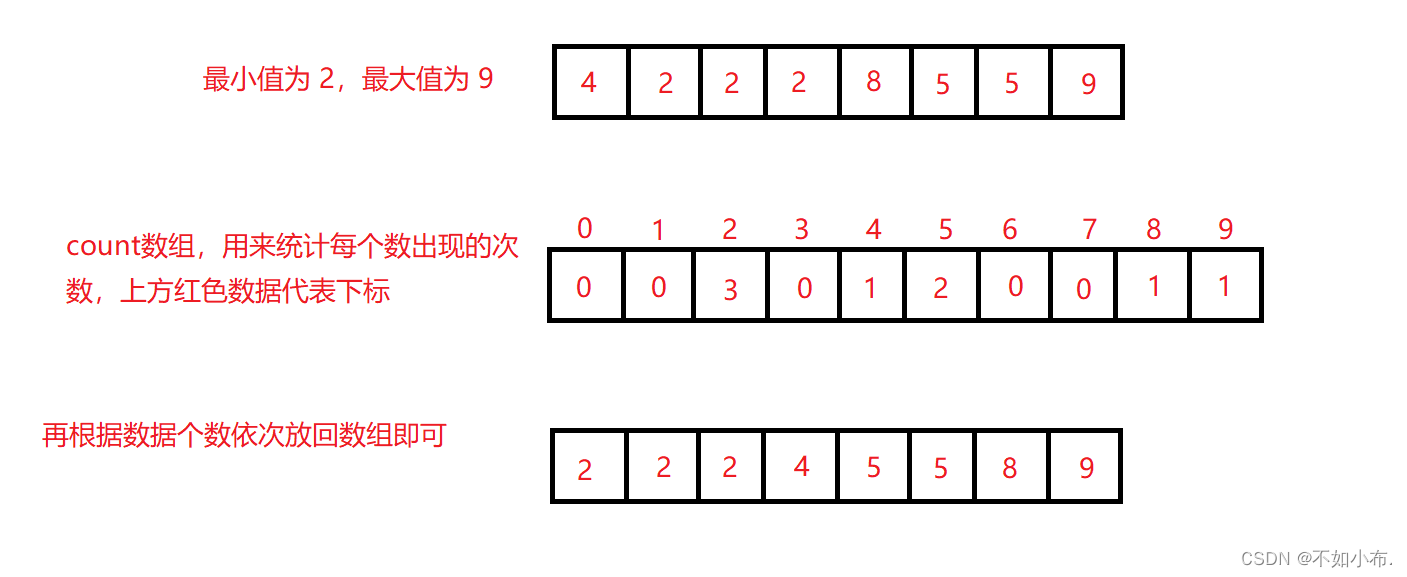
可以理解为用新开辟出来的 count 数组来记录每个数据出现的次数,count 数组的下标代表原数组的数据,count 数组中存储的,就是所对应下标出现的次数。
从上图看,0 和 1 是没有使用到的空间,有用的空间只有 2 到 9,因此我们可以用最大值减去最小值加一,来开辟count 数组的空间,减小空间损耗。但同时下标对应的原数组数据也会发生改变,比如上面的 2,在存放时就需要减去最小值 2 来存放到 0 这个位置,在最后放回原数组时再加上这个最小值就可以了。
不好理解的话大家可以通过画图带入数据来更加细致的理解这个过程。这也是学习数据结构内容的重要方法。
8.2 代码实现
void CountSort(int* a, int n)
{int max = a[0], min = a[0];int i = 0;for (i = 0; i < n; i++){if (a[i] < min){min = a[i];}if (a[i] > max){max = a[i];}}int range = max - min + 1;int* count = (int*)malloc(sizeof(int) * range);if (count == NULL){printf("MergeSort:");exit(-1);}memset(count, 0, sizeof(int) * range);//计数for (i = 0; i < n; i++){count[a[i] - min]++;}//排序int j = 0;for (i = 0; i < range; i++){while (count[i]--){a[j++] = i + min;}}free(count);count = NULL;
}
8.3 特性总结
- 计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。
- 时间复杂度:O(MAX(N,范围))
- 空间复杂度:O(范围 range )
- 稳定性:稳定
9. 总结
此篇内容也是比较多,跟二叉树一样也是花费了几天时间来整理(叹气),不过还是比二叉树好多了(哎嘿)。如果大家发现有什么错误的地方,可以私信或者评论区指出喔(官话)。那么数据结构就先告一段落了,接下来就要进行C++和Linux的学习了,希望能与大家共同进步,那么本期就到此结束,让我们下期再见!!觉得不错可以点个赞以示鼓励喔!!
相关文章:
数据结构篇七:排序
文章目录 前言1.插入排序1.1 基本思想1.2 代码实现1.3 特性总结 2.希尔排序2.1 基本思想2.2 代码实现2.3 特性总结 3. 选择排序3.1 基本思想3.2 代码实现3.3 特性总结 4. 堆排序4.1 基本思想4.2 代码实现4.3 特性总结 5. 冒泡排序5.1 基本思想5.2 代码实现5.3 特性总结 6. 快速…...

Vue组件的边界情况
01.$root; 访问组件的根实例;用的不多,基本上在vuex上进行数据操作; 02.$parent/$children; 可以获得父组件或者子组件上边的数据;一般不建议使用$parent,因为如果获取这个值进行修改的话,也会更改父组件上…...

less、sass的使用及其区别
CSS预处理器 CSS 预处理器是一种扩展了原生 CSS 的工具,它们添加了一些编程语言的特性,以便更有效地编写、组织和维护样式代码。预处理器允许开发者使用变量、嵌套、函数、混合等功能,从而使 CSS 更具可读性、可维护性和重用性,特…...
[保研/考研机试] 猫狗收容所 C++实现
题目描述: 输入: 第一个是n,它代表操作序列的次数。接下来是n行,每行有两个值m和t,分别代表题目中操作的两个元素。 输出: 按顺序输出收养动物的序列,编号之间以空格间隔。 源代码ÿ…...

Kotlin 基础教程一
Kotlin 基本数据类型 Java | Kotlin byte Byte short Short int Int long Long float Float double Double boolean Boolean c…...

数据结构笔记--前缀树的实现
1--前缀树的实现 前缀树的每一个节点拥有三个成员变量,pass表示有多少个字符串经过该节点,end表示有多少个字符串以该节点结尾,nexts表示该字符串可以走向哪些节点; #include <iostream> #include <unordered_map>str…...

C/C++时间获取函数
time.h包含C/C中用于获取时间,和时间转换方面的函数。 1、time() 函数 time_t time(time_t *seconds) 返回自(1970-01-01 00:00:00 UTC)起经过的时间,以秒为单位。如果 seconds 不为空,则返回值也存储在变量 seconds …...

sql中判断日期是否是同一天
sql中判断日期是否是同一天的sql sql: select id,product_id,seckill_price,stock_count,time,intergral,start_date from t_seckill_product where to_days(start_date) to_days(now()) to_days函数: 使用to_days(start_date) to_days(now())的方式是一种常见的…...
NAS搭建指南一——服务器的选择与搭建
一、服务器的选择 有自己的本地的公网 IP 的请跳过此篇文章按需求选择一个云服务器,目的就是为了进行 frp 的搭建,完成内网穿透我选择的是腾讯云服务器,我的配置如下,仅供参考: 4. 腾讯云服务器官网地址 二、服务器…...
豪越HYDO智能运维助力智慧医院信息化建设
随着国家政策的推动与支持,医疗行业信息化应用不断普及,大数据、AI、医疗物联网等技术的应用,快速推动了电子病历、智慧服务、智慧管理的智慧医院建设和医院信息标准化建设,通过不断探索创新“智慧医院”服务模式,实现…...

Week1题目重刷
今天把week1的题目都重新刷了一遍,明天开始week2的内容~ 704.二分查找 class Solution {public int search(int[] nums, int target) {int l 0, r nums.length - 1, m;while (l < r) {m (l r) >>> 1;if (nums[m] < target) {l m 1;} else if…...
考研数据结构:第七章 查找
文章目录 一、查找的基本概念二、顺序查找和折半查找2.1顺序查找2.3折半查找2.3.1算法思想2.3.2代码实现2.3.3查找效率分析2.3.4折半查找判定树的构造2.3.5折半查找效率2.3.6小结 2.4分块查找 三、树形查找3.1二叉排序树3.1.1二叉排序树定义3.1.2查找操作3.1.3插入操作3.1.4二叉…...

【Linux进程篇】环境变量
【Linux进程篇】环境变量 目录 【Linux进程篇】环境变量基本概念常见环境变量查看环境变量方法测试PATH测试HOME测试SHELL和环境变量相关的命令环境变量的组织方式通过代码如何获取环境变量命令行参数命令行第三个参数通过第三方变量environ获取 本地变量通过系统调用获取或设置…...
【软件测试】Linux环境下Docker搭建+Docker搭建MySQL服务(详细)
目录:导读 前言 一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 Linux之docker搭…...

去了字节跳动,才知道年薪40W的测试有这么多?
今年大环境不好,内卷的厉害,薪资待遇好的工作机会更是难得。最近脉脉职言区有一条讨论火了: 哪家互联网公司薪资最‘厉害’? 下面的评论多为字节跳动,还炸出了很多年薪40W的测试工程师 我只想问一句,现在的…...
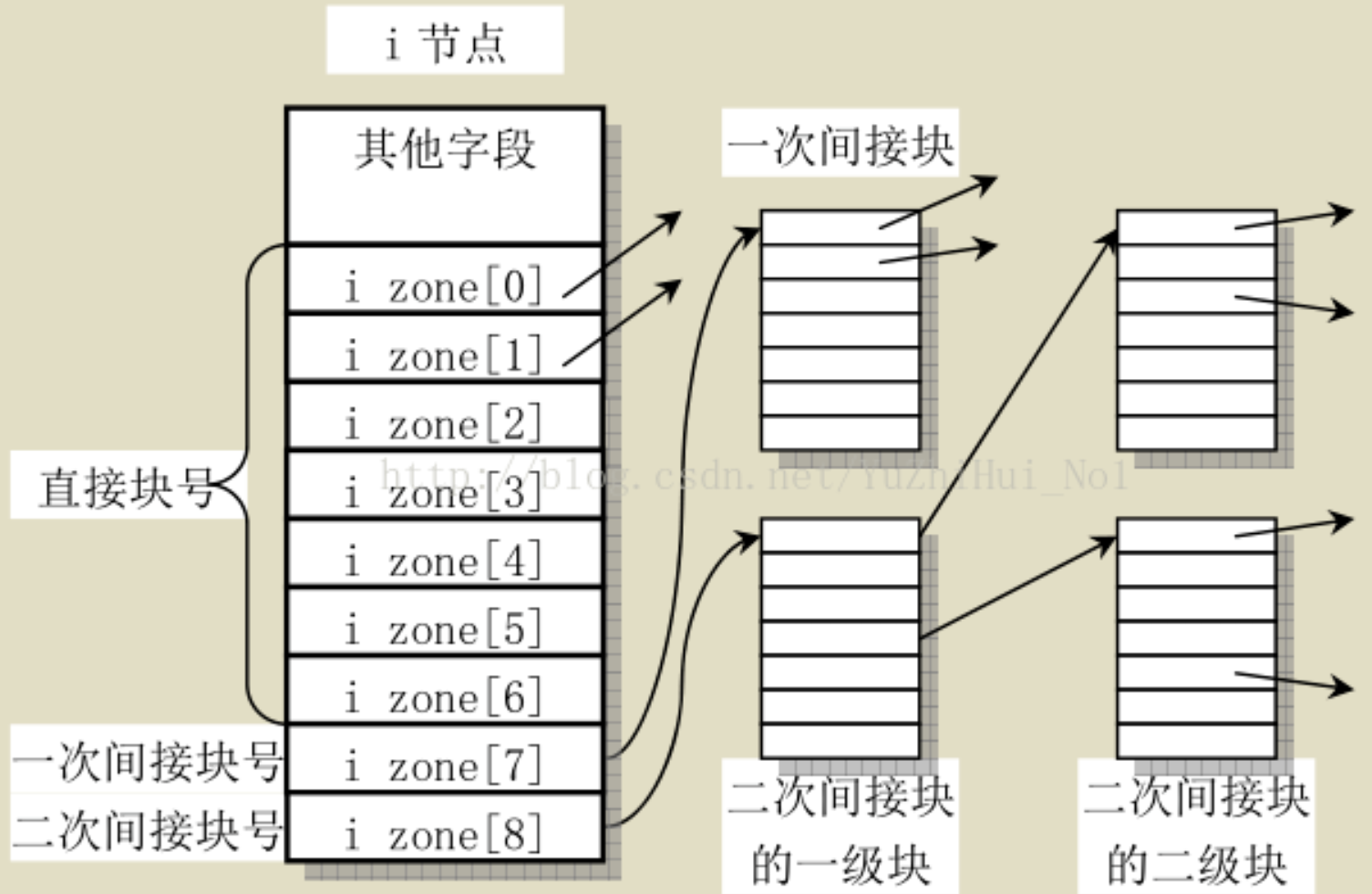
linux0.95(VFS重点)源码通俗解读(施工中)
文件系统在磁盘中的体现 下面是磁盘的内容,其中i节点就是一个inode数组,逻辑块就是数据块可用于存放数据 操作系统通过将磁盘数据读入到内存中指定的缓冲区块来与磁盘交互,对内存中的缓冲区块修改后写回磁盘。 进程(task_struct * task[N…...
mac ssh连接另一台window虚拟机vm
vmware配置端口映射 编辑(E) > 虚拟网络编辑器(N)... > NAT设置(S)... window防火墙,入站规则添加5555端口 控制面板 > 系统和安全 > Windows 防火墙>高级设置>入站规则>新建规则... tips windows查看端口命令:netstat -ano | f…...
使用Python解析通达信本地lday数据结构
通达信软件中的vipdoc是一个存储股票行情数据的文件夹。在通达信软件的安装目录下,可以找到一个名为vipdoc的文件夹,里面存放着各个股票的分时、日线、周线、月线等行情数据文件。这些数据文件可以用于自定义分析和回测股票的走势和交易策略,…...

【Mysql】修改definer
修改definer 本文介绍如何修改MySQL中的function、procedure、event、view和trigger的definer 修改function、procedure的definer 首先,我们需要登录MySQL命令行界面,然后执行以下命令: select definer from mysql.proc;这个命令会列出所…...

图片预览插件vue-photo-preview的使用
移动端项目中需要图片预览的功能,但本身使用mintui,vantui中虽然也有,但是为了一个组件安装这个有点儿多余,就选用了vue-photo-preview插件实现(其实偷懒也不想自己写)。 1、安装 npm i vue-photo-preview…...

③ AI副业第一步:如何找到适合自己的AI赚钱赛道
③ AI副业第一步:如何找到适合自己的AI赚钱赛道选对赛道,努力才有意义。选错赛道,越努力离钱越远。前言:为什么大多数人AI副业做不起来? 我观察了100想做AI副业的人,失败的原因高度一致: 失败路…...

Veo 2胶片质感生成器失效?——深度解析Color Science v2.3内核中被屏蔽的Cinematic Grain Injection层
更多请点击: https://kaifayun.com 第一章:Veo 2胶片质感生成器失效现象全景透视 近期大量用户反馈,Veo 2 胶片质感生成器在调用 generate_film_effect() 接口后返回空纹理、纯灰帧或 HTTP 503 Service Unavailable 错误,且该问题…...

Owl-Alpha 新手快速上手指南
在处理大规模数据或构建高性能应用时,我们常常会遇到一个棘手的问题:如何在不阻塞主线程的情况下,高效地执行耗时任务?无论是处理图像、解析大型文件,还是进行复杂的数学运算,传统的单线程模式往往会让界面…...

孤舟笔记 互联网常用框架篇二 Dubbo服务请求失败怎么处理?集群容错策略你用过几种
文章目录先说结论Failover:换家店试试Failfast:不行就算了Failsafe:忘了这事Failback:回头再说Forking:同时点几家Broadcast:通知所有人怎么选择回答技巧与点评加分回答面试官点评个人网站分布式系统中&…...
)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)第一次戴上Meta Quest 3时,那种虚拟与现实交织的震撼感至今难忘。但作为开发者,更让我着迷的是如何让虚拟物体在真实空间中"记住"…...

航空发动机叶片三维扫描-诺斯顿
航空发动机叶片作为发动机的核心动力部件,其精度与性能直接决定发动机的推力、燃油效率及运行安全性,三维扫描技术作为航空制造领域的核心数字化手段,已广泛应用于叶片全生命周期的多个关键环节。其应用涵盖叶片研发设计阶段的逆向工程&#…...

BiliBiliCCSubtitle终极指南:5个实战技巧高效下载B站字幕
BiliBiliCCSubtitle终极指南:5个实战技巧高效下载B站字幕 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 还在为无法保存B站视频字幕而烦恼࿱…...

从无线破解到PDF解密:盘点那些容易被忽略的‘非主流’密码审计场景与工具
密码安全审计的隐秘战场:从无线网络到加密文档的实战指南 当大多数人谈论密码安全时,脑海中浮现的往往是服务器登录、数据库访问这些企业级场景。然而在数字生活的每个角落,从家庭Wi-Fi到工作文档,密码保护的脆弱性同样可能成为安…...

CentOS 8/Stream 8系统DNF换源后,安装软件还是慢?试试这几个排查命令和优化技巧
CentOS 8/Stream 8系统DNF换源后安装缓慢的深度排查与优化指南当你已经按照教程将CentOS 8/Stream 8的DNF源切换为国内镜像,却发现软件安装速度依然不尽如人意时,这种体验确实令人沮丧。作为长期使用CentOS系统的技术专家,我完全理解这种&quo…...

Taotoken的Token Plan套餐如何帮助项目更可控地预估成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的Token Plan套餐如何帮助项目更可控地预估成本 对于项目管理者或独立开发者而言,在集成大模型能力时…...