数据分析-python学习 (1)numpy相关
内容为:https://juejin.cn/book/7240731597035864121的学习笔记
导包
import numpy as np
numpy数组创建
- 创建全0数组,正态分布、随机数组等就不说了,提供了相应的方法
- 通过已有数据创建有两种 arr1=np.array([1,2,3,4,5]) 或者data=np.loadtxt(‘C:/Users/000001_all.csv’,dtype=‘float’,delimiter=‘,’,skiprows=1) (data=np.genfromtxt(‘C:/Users/000001_all.csv’,dtype=‘float32’,delimiter=‘,’,skip_header=1) )
- 注意浅拷贝与深拷贝
arraycopy是深,asarray是浅
import numpy as np
arr1=np.array([1,2,3,4,5])
arr2=np.array(arr1)
arr3=np.asarray(arr1)
arr4=np.copy(arr1)
arr1[0]=100
print('更改后arr2为:',arr2)
print('更改后arr3为:',arr3)
print('更改后arr4为:',arr4)更改后arr2为: [1 2 3 4 5]
更改后arr3为: [100 2 3 4 5]
更改后arr4为: [1 2 3 4 5]
- 数组的切片也是浅拷贝
Score=np.array([69,80,90,40,60,20,90,94,90,99])#学生的成绩Score[:3]=0print('修改切片对象成绩后的Score为',Score)Score1=[69,80,90,40,60,20,90,94,90,99]Score1_list=Score1[:3]Score1_list=0print('修改Score1_list后的Score1为',Score1)修改切片对象成绩后的Score为 [ 0 0 0 40 60 20 90 94 90 99]
修改Score1_list后的Score1为 [69, 80, 90, 40, 60, 20, 90, 94, 90, 99]索引的访问
访问某个下标(一个元素)得到的也是一个数值;如果访问的是多个下标,得到的是一个数组
一维
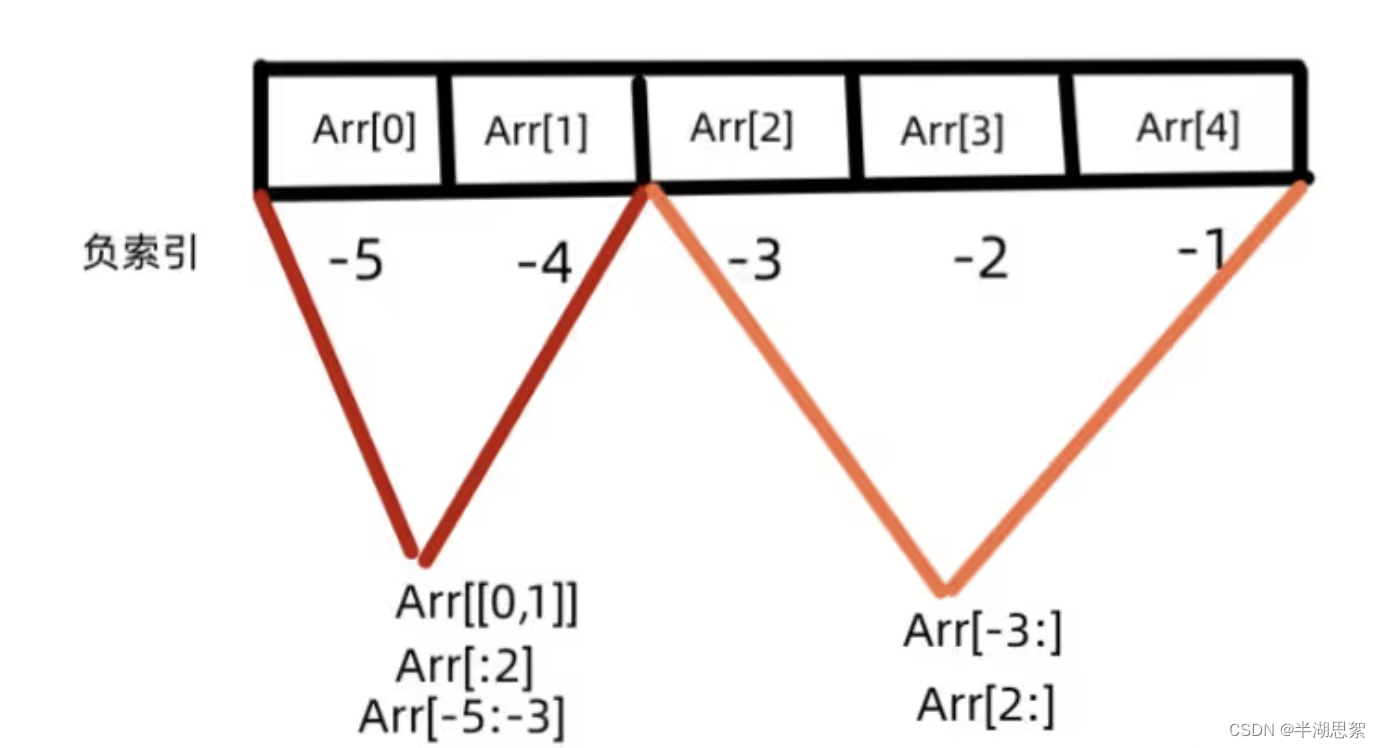
二维
Score2=np.array([[69,40,30],[80,90,40],[90,100,50],[40,20,99],[60,60,66],[20,66,44],[90,88,56],[94,99,67],[90,20,70],[99,50,86]])print('学号为1的同学的语文和英语成绩为',Score2[[0,0],[0,2]])
学号为 1 的同学的语文和英语成绩为 [69 30]
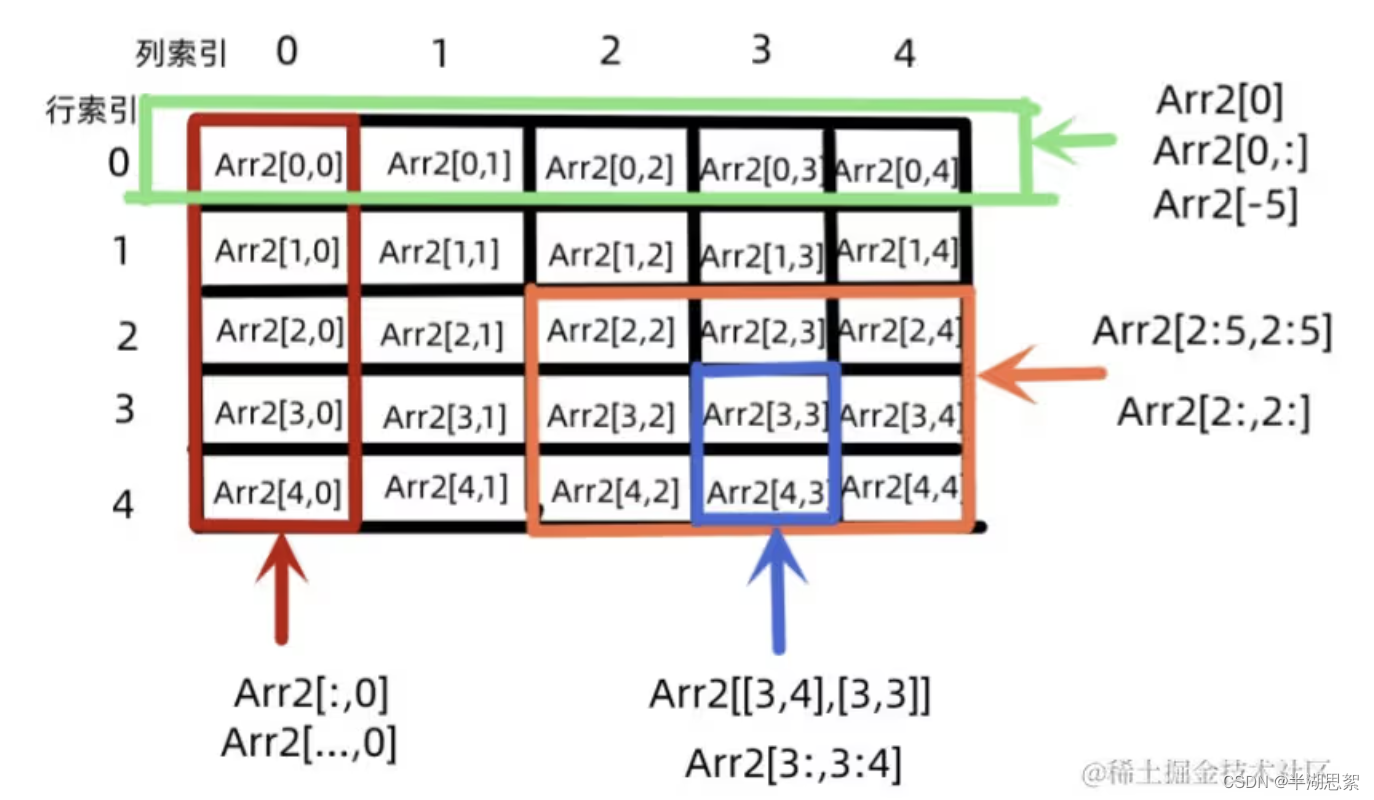
三维
Space=np.array([[[5,4,8],[5,9,2],[4,5,3]],[[4,9,6],[2,2,5],[4,3,4]],[[4,2,1],[7,6,3],[4,6,5]]])print(Space[[0,0,1],[0,1,2],[0,0,2]])[5 5 4]

数组的运算
广播
3种
广播机制的原则是如果两个数组的从后数第一个维度轴长度相符或其中一个数组的轴长为 1,则认为它们能够广播
- 一
Arr1=np.array([1,2,3])
print(Arr1)
print(Arr1*3)[1 2 3]
[3 6 9]
- 二
Arr2=np.array([[1,2,3],[4,5,6]])
Arr1=np.array([1,2,3])
print(Arr1)
print(Arr2)
print(Arr1+Arr2)[1 2 3]
**********
[[1 2 3][4 5 6]]
**********
[[2 4 6][5 7 9]]- 三
Arr2=np.array([[1,2,3],[4,5,6]])
Arr=np.array([[1],[2]])
print(Arr2)
print(Arr)
print(Arr2+Arr)[[1 2 3][4 5 6]]
**********
[[1][2]]
**********
[[2 3 4][6 7 8]]数值与数组的标量运算,就用到了广播机制,会把数据扩充到跟待运算一样的大小,按位相加/减/乘/除
计算函数
除了可以arr1与arr2直接相运算,如arr1*arr2,也有相应的方法
方法:add() 加法函数,subtract() 减法函数,multiply() 乘法函数,divide() 除法函数,mod() 取余函数。
Score_F=np.array([69,80,90,40,60,20,90,94,90,99])#第一次成绩
Score_S=np.array([70,92,63,20,50,96,33,44,55,30])#第二次成绩
Score_chaju=np.subtract(Score_F,Score_S)
print('求两次成绩的和',np.add(Score_F,Score_S))
print('第一次成绩的0.6加第二次成绩的0.4',np.add(np.multiply(Score_F,0.6),np.multiply(Score_S,0.4)))
print('查看两次成绩的差距,差距以正数显示',np.abs(Score_chaju))统计函数
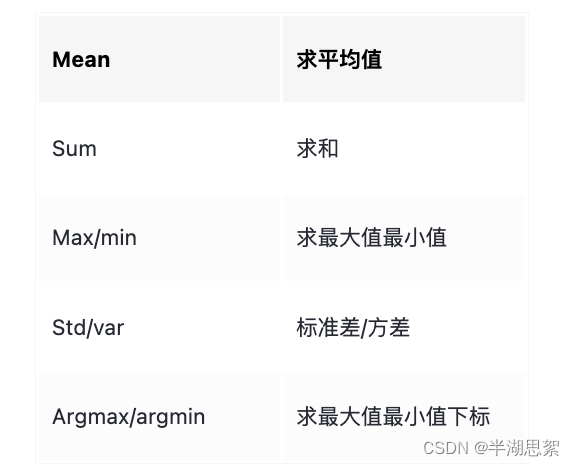
axis有两个值,为0求的是纵向的聚合值,为1求的是横向的聚合值,
常用的聚合函数如下:mean,sum,max,min,std,var
标准差是方差的算数平方根(标准差和原数据单位相同,方差多个平方),所以方差>标准差,说明偏差大;方差<标准差,说明偏差小

逻辑运算
提供了all、any 和 where 这三个方法
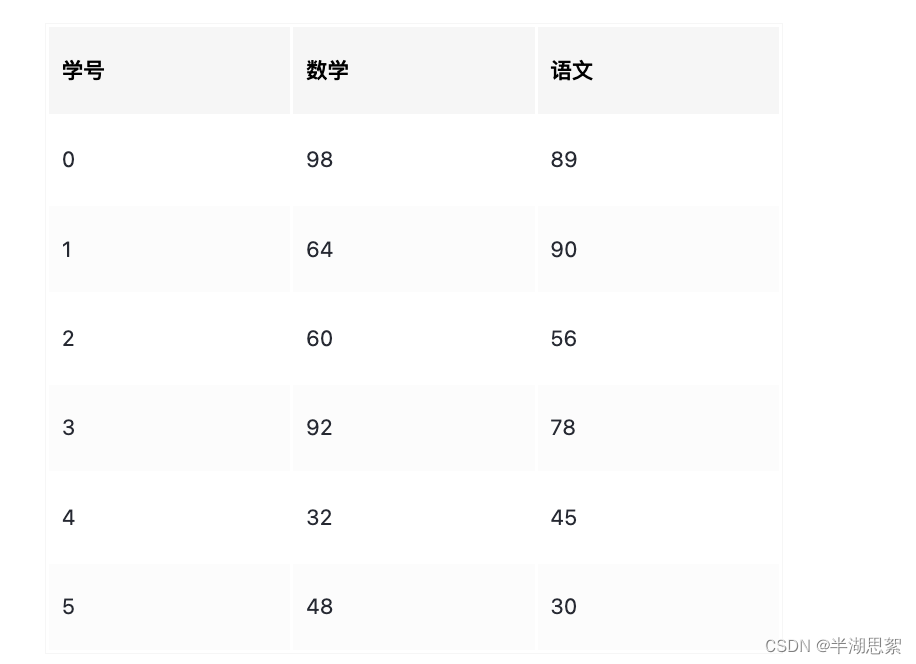
# 得到两门成绩都及格的同学的成绩
import numpy as np
Score=np.array([[98,89],[64,90],[60,56],[92,78],[32,45],[48,30]])
Score60=Score>60
Score_bool=np.all(Score60,axis=1)
print(Score_bool)
print(Score[Score_bool])[ True True False True False False]
[[98 89][64 90][92 78]]#查看数学或者语文超过 90 分同学的成绩
Score90=Score>90
Score_bool=np.any(Score90,axis=1)
print(Score_bool)
print(Score[Score_bool])[ True False False True False False]
[[98 89][92 78]]# 成绩大于60的分数有哪些
import numpy as np
Score_math=np.array([98,64,60,92,32,48])
score60_index = np.where(Score_math>60)
score60 = Score_math[score60_index]
print(score60_index)
print(score60)(array([0, 1, 3]),)
[98 64 92]
矩阵运算
可以用@或dot来实现,它俩是等价的
注意是(3, 2)*(2, 4)=(3, 4) 只有
fruit_price=np.array([[5,4,3]]) # 1*3
jinshu=np.array([[2],[3],[1]]) # 3*1
print('水果的总价格为:\n',fruit_price@jinshu) #得到的是1*1的矩阵
print('水果的总价格为:\n',np.dot(fruit_price,jinshu))水果的总价格为:[[25]]
水果的总价格为:[[25]]
数组的拆分与合并
合并
水平可以用concatenate 方法、hstack 方法和 column_stack 方法
垂直可以用concatenate 方法、vstack 方法和 row_stack 方法
- 水平
import numpy as np
Stock1=np.array([[14.322,14.552],[14.472,14.532],[14.592,15.022],[14.852,14.802]])
Stock2=np.array([[14.652,14.192],[14.832,14.422],[15.022,14.592],[15.152,14.722]])
# 方式1
Stock=np.concatenate((Stock1,Stock2),axis=1)
# 方式2
Stock=np.hstack((Stock1,Stock2))
# 方式3
Stock=np.column_stack((Stock1,Stock2)) print(Stock)#上面3种得到的结果一样,写一块了[[14.322 14.552 14.652 14.192][14.472 14.532 14.832 14.422][14.592 15.022 15.022 14.592][14.852 14.802 15.152 14.722]]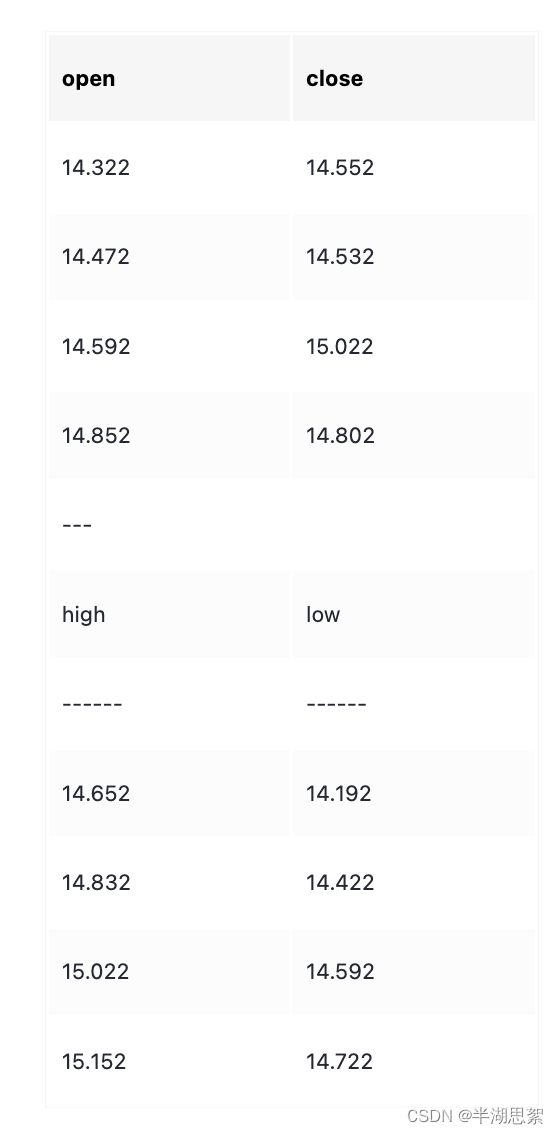
- 垂直
import numpy as np
Stock1=np.array([[14.322,14.552],[14.472,14.532],[14.592,15.022],[14.852,14.802]])
Stock2=np.array([[14.912,14.932],[14.772,14.602]])
Stock=np.concatenate((Stock1,Stock2),axis=0)
Stock=np.vstack((Stock1,Stock2))
Stock=np.row_stack((Stock1,Stock2))
print(Stock)[[14.322 14.552][14.472 14.532][14.592 15.022][14.852 14.802][14.912 14.932][14.772 14.602]]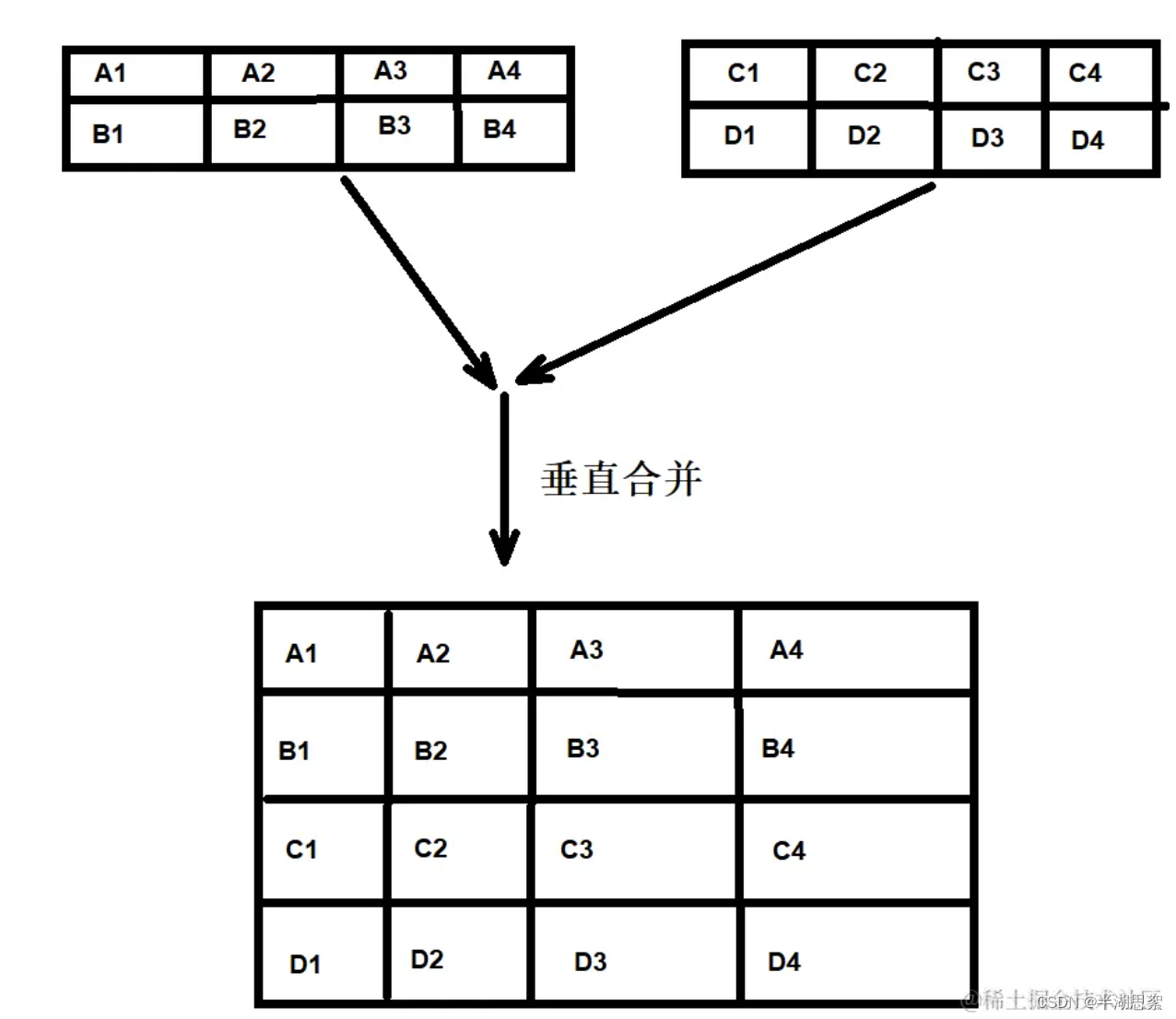
分割
# 水平
import numpy as np
Stock=np.array([[14.322,14.552],[14.472,14.532],[14.592,15.022],[14.852,14.802],[14.912,14.932],[14.772,14.602]])
open,close=np.split(Stock,2,axis=1)
print('open为{},close为{}'.format(open,close))open为[[14.322][14.472][14.592][14.852][14.912][14.772]],close为[[14.552][14.532][15.022][14.802][14.932][14.602]]# 垂直
# 这里面对行下标做切分,包含头不包含尾如按[1,3,4]: 0, 1,2, 3, 4,5
import numpy as np
Stock=np.array([[14.322,14.552],[14.472,14.532],[14.592,15.022],[14.852,14.802],[14.912,14.932],[14.772,14.602]])
arr1,arr2,arr3,arr4=np.split(Stock,[1,3,4],axis=0)
print('arr1为{},arr2为{},arr3为{},arr4为{}'.format(arr1,arr2,arr3,arr4))arr1为[[14.322 14.552]],arr2为[[14.472 14.532][14.592 15.022]],arr3为[[14.852 14.802]],arr4为[[14.912 14.932][14.772 14.602]]综合案例:
https://juejin.cn/book/7240731597035864121/section/7255506664244117559
相关文章:
数据分析-python学习 (1)numpy相关
内容为:https://juejin.cn/book/7240731597035864121的学习笔记 导包 import numpy as np numpy数组创建 创建全0数组,正态分布、随机数组等就不说了,提供了相应的方法通过已有数据创建有两种 arr1np.array([1,2,3,4,5]) 或者datanp.loadt…...

数据库的游标
数据库的游标(Cursor)是用于在数据库中进行数据操作的一个控制结构。它类似于在编程语言中使用的指针或迭代器,用于遍历数据库结果集并在结果集上执行各种操作。 游标允许我们在数据库查询的结果集中逐行移动,并对每一行执行特定…...
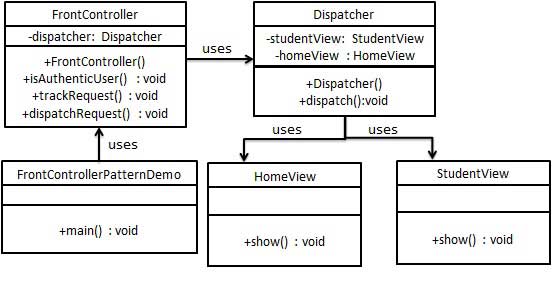
【设计模式】前端控制器模式
前端控制器模式(Front Controller Pattern)是用来提供一个集中的请求处理机制,所有的请求都将由一个单一的处理程序处理。该处理程序可以做认证/授权/记录日志,或者跟踪请求,然后把请求传给相应的处理程序。以下是这种…...

SQL | 过滤数据
4-过滤数据 4.1-使用WHERE子句 数据根据 WHERE 子句中指定的搜索条件进行过滤。WHERE 子句在表名( FROM 子句)之后给出。 select prod_name,prod_price from products where prod_price 3.49; 上述语句查询价格为3.49的行,然后输出名字和…...
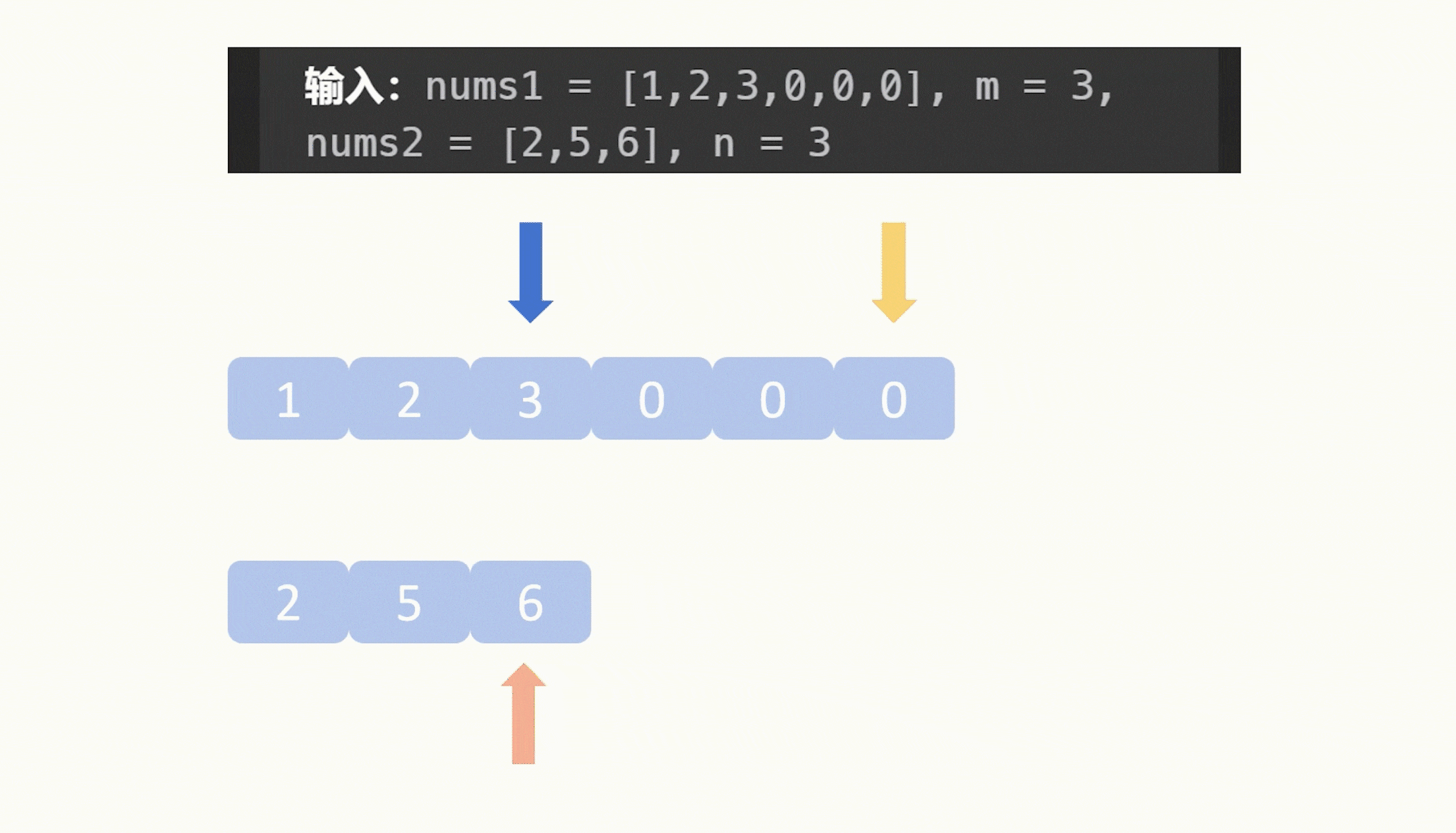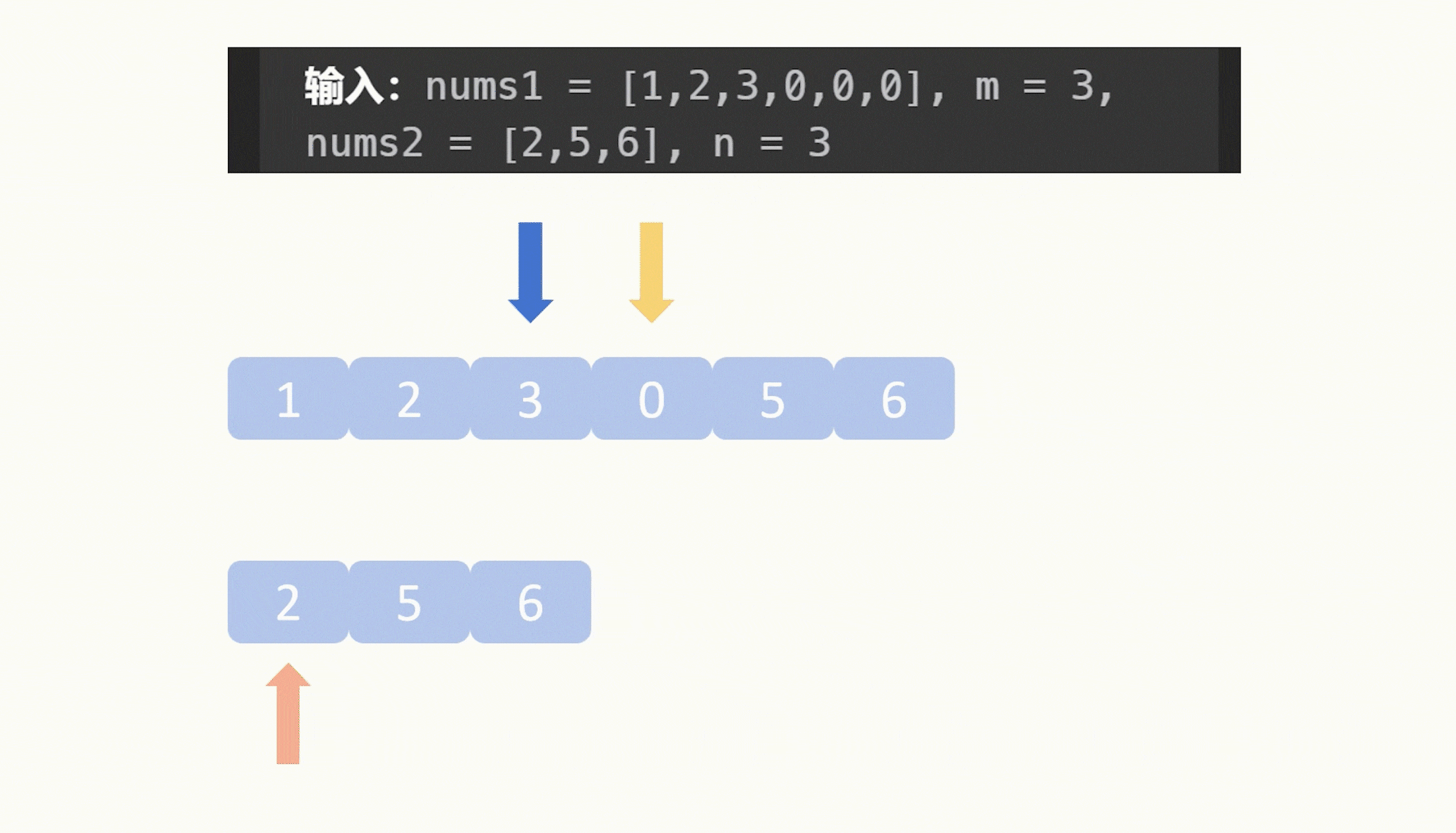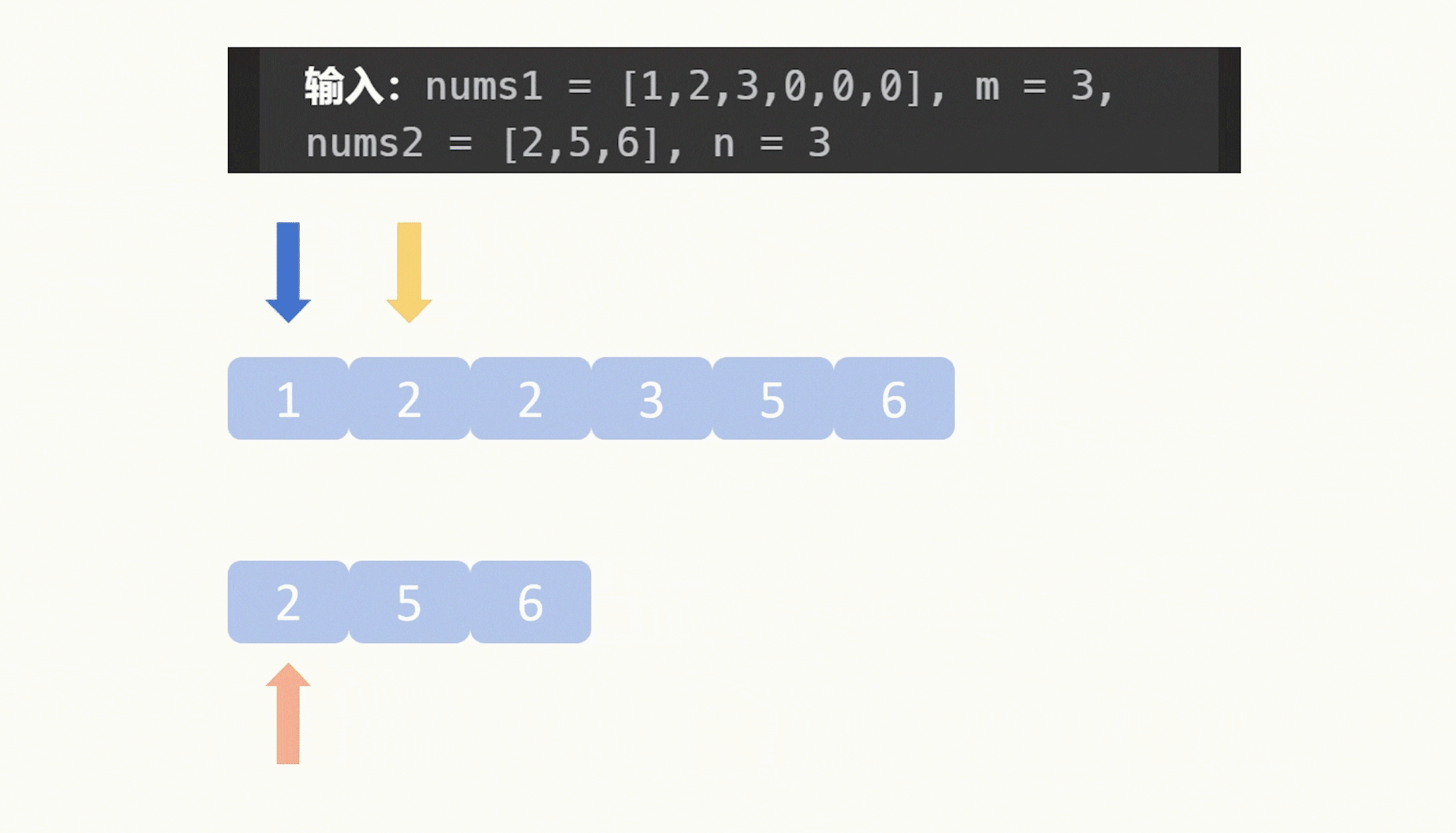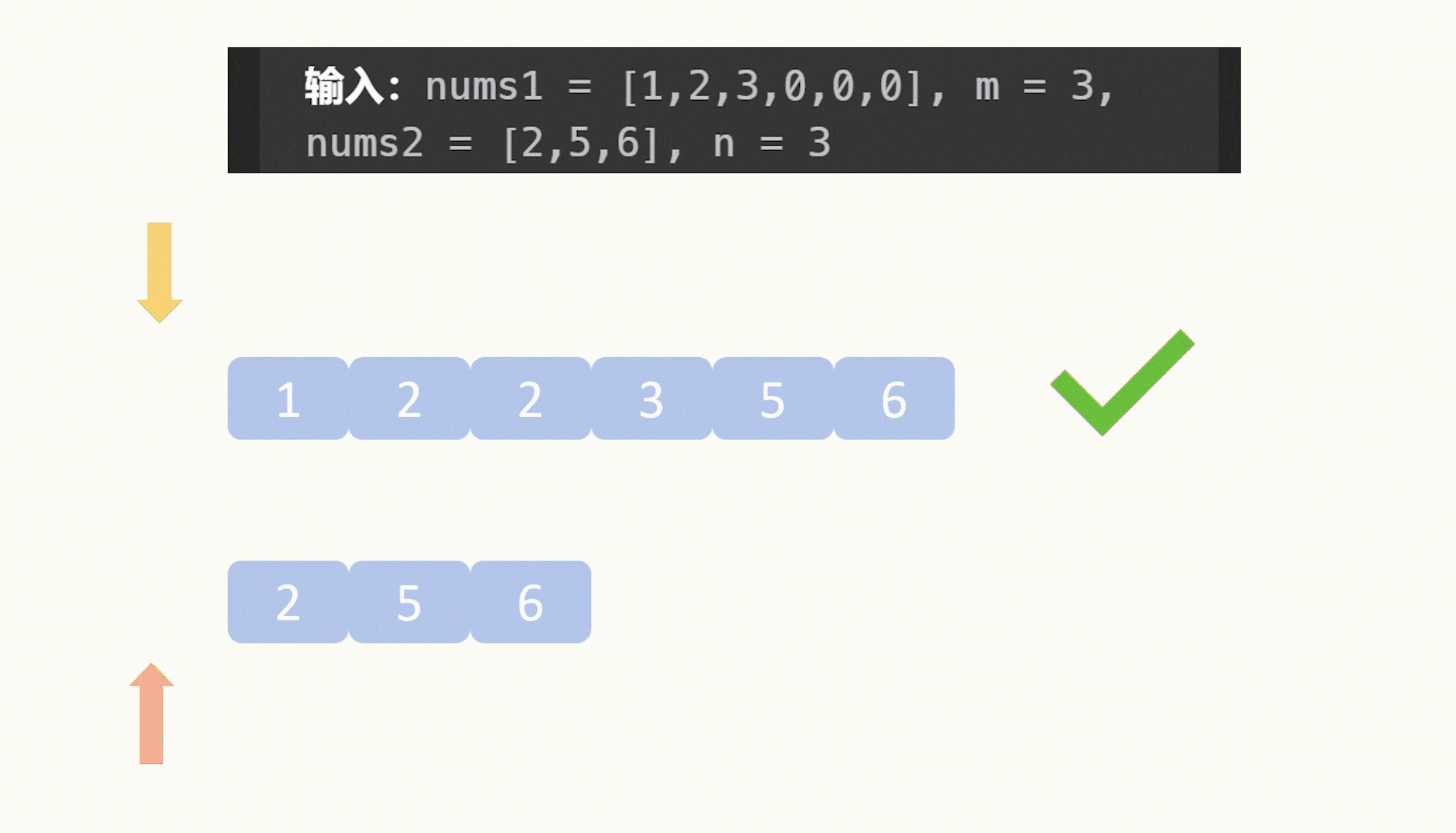
【力扣每日一题】2023.8.13 合并两个有序数组
目录 题目: 示例: 分析: 代码: 题目: 示例: 分析: 题目给我们两个升序数组,让我们合并它们,要求合并之后仍然是升序,并且这个合并操作是在数组1原地修改…...
数据结构篇七:排序
文章目录 前言1.插入排序1.1 基本思想1.2 代码实现1.3 特性总结 2.希尔排序2.1 基本思想2.2 代码实现2.3 特性总结 3. 选择排序3.1 基本思想3.2 代码实现3.3 特性总结 4. 堆排序4.1 基本思想4.2 代码实现4.3 特性总结 5. 冒泡排序5.1 基本思想5.2 代码实现5.3 特性总结 6. 快速…...

Vue组件的边界情况
01.$root; 访问组件的根实例;用的不多,基本上在vuex上进行数据操作; 02.$parent/$children; 可以获得父组件或者子组件上边的数据;一般不建议使用$parent,因为如果获取这个值进行修改的话,也会更改父组件上…...

less、sass的使用及其区别
CSS预处理器 CSS 预处理器是一种扩展了原生 CSS 的工具,它们添加了一些编程语言的特性,以便更有效地编写、组织和维护样式代码。预处理器允许开发者使用变量、嵌套、函数、混合等功能,从而使 CSS 更具可读性、可维护性和重用性,特…...
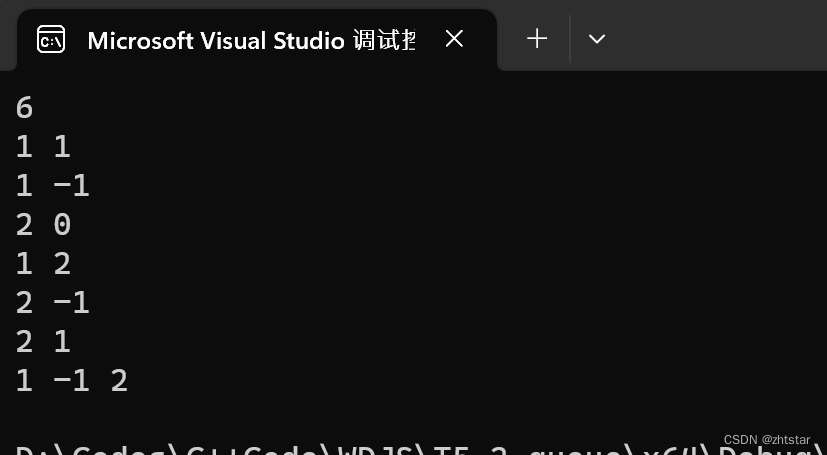
[保研/考研机试] 猫狗收容所 C++实现
题目描述: 输入: 第一个是n,它代表操作序列的次数。接下来是n行,每行有两个值m和t,分别代表题目中操作的两个元素。 输出: 按顺序输出收养动物的序列,编号之间以空格间隔。 源代码ÿ…...

Kotlin 基础教程一
Kotlin 基本数据类型 Java | Kotlin byte Byte short Short int Int long Long float Float double Double boolean Boolean c…...

数据结构笔记--前缀树的实现
1--前缀树的实现 前缀树的每一个节点拥有三个成员变量,pass表示有多少个字符串经过该节点,end表示有多少个字符串以该节点结尾,nexts表示该字符串可以走向哪些节点; #include <iostream> #include <unordered_map>str…...

C/C++时间获取函数
time.h包含C/C中用于获取时间,和时间转换方面的函数。 1、time() 函数 time_t time(time_t *seconds) 返回自(1970-01-01 00:00:00 UTC)起经过的时间,以秒为单位。如果 seconds 不为空,则返回值也存储在变量 seconds …...

sql中判断日期是否是同一天
sql中判断日期是否是同一天的sql sql: select id,product_id,seckill_price,stock_count,time,intergral,start_date from t_seckill_product where to_days(start_date) to_days(now()) to_days函数: 使用to_days(start_date) to_days(now())的方式是一种常见的…...
NAS搭建指南一——服务器的选择与搭建
一、服务器的选择 有自己的本地的公网 IP 的请跳过此篇文章按需求选择一个云服务器,目的就是为了进行 frp 的搭建,完成内网穿透我选择的是腾讯云服务器,我的配置如下,仅供参考: 4. 腾讯云服务器官网地址 二、服务器…...
豪越HYDO智能运维助力智慧医院信息化建设
随着国家政策的推动与支持,医疗行业信息化应用不断普及,大数据、AI、医疗物联网等技术的应用,快速推动了电子病历、智慧服务、智慧管理的智慧医院建设和医院信息标准化建设,通过不断探索创新“智慧医院”服务模式,实现…...

Week1题目重刷
今天把week1的题目都重新刷了一遍,明天开始week2的内容~ 704.二分查找 class Solution {public int search(int[] nums, int target) {int l 0, r nums.length - 1, m;while (l < r) {m (l r) >>> 1;if (nums[m] < target) {l m 1;} else if…...
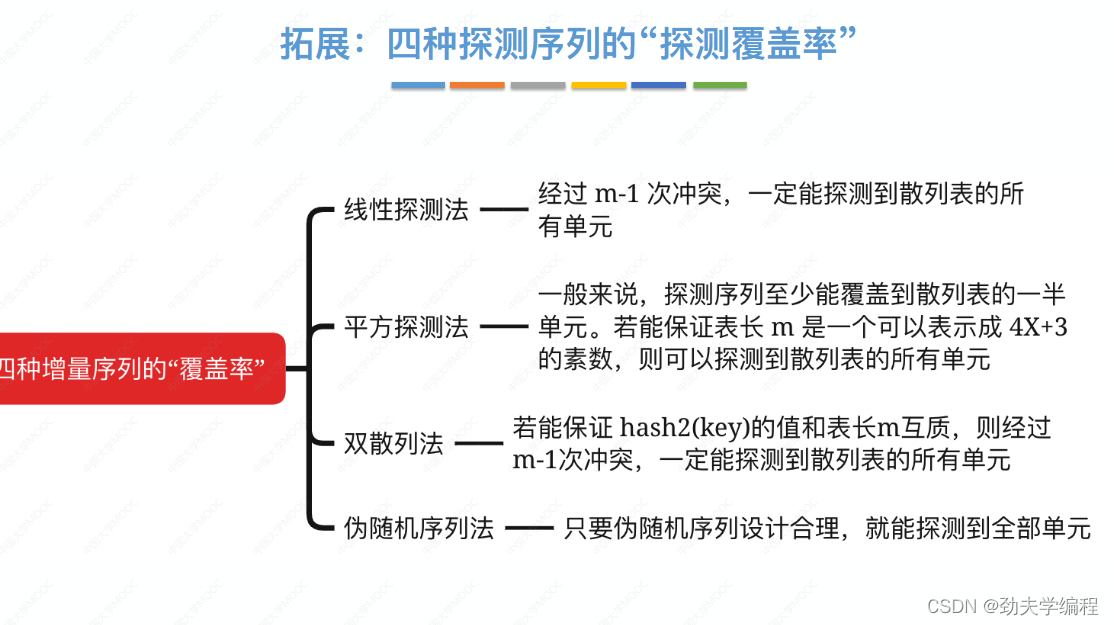
考研数据结构:第七章 查找
文章目录 一、查找的基本概念二、顺序查找和折半查找2.1顺序查找2.3折半查找2.3.1算法思想2.3.2代码实现2.3.3查找效率分析2.3.4折半查找判定树的构造2.3.5折半查找效率2.3.6小结 2.4分块查找 三、树形查找3.1二叉排序树3.1.1二叉排序树定义3.1.2查找操作3.1.3插入操作3.1.4二叉…...

【Linux进程篇】环境变量
【Linux进程篇】环境变量 目录 【Linux进程篇】环境变量基本概念常见环境变量查看环境变量方法测试PATH测试HOME测试SHELL和环境变量相关的命令环境变量的组织方式通过代码如何获取环境变量命令行参数命令行第三个参数通过第三方变量environ获取 本地变量通过系统调用获取或设置…...
【软件测试】Linux环境下Docker搭建+Docker搭建MySQL服务(详细)
目录:导读 前言 一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 Linux之docker搭…...

去了字节跳动,才知道年薪40W的测试有这么多?
今年大环境不好,内卷的厉害,薪资待遇好的工作机会更是难得。最近脉脉职言区有一条讨论火了: 哪家互联网公司薪资最‘厉害’? 下面的评论多为字节跳动,还炸出了很多年薪40W的测试工程师 我只想问一句,现在的…...

四旋翼变形控制:RL与MPC在混合动力学中的对比
1. 四旋翼变形控制的技术挑战与解决方案四旋翼变形控制(Quadrotor Morpho-Transition)是当前机器人领域最具挑战性的前沿技术之一。这项技术使机器人能够在空中完成形态变换,实现从飞行模式到地面模式的平滑切换。想象一下,一架四…...

Obsidian PDF++:如何在Obsidian中实现PDF与笔记的无缝双向链接?
Obsidian PDF:如何在Obsidian中实现PDF与笔记的无缝双向链接? 【免费下载链接】obsidian-pdf-plus PDF: the most Obsidian-native PDF annotation & viewing tool ever. Comes with optional Vim keybindings. 项目地址: https://gitcode.com/gh_…...

告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件
告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件当面对数百GB的设计素材、日志文件或数据库备份需要迁移时,传统的FTP传输往往会成为效率瓶颈。我曾在一个视频处理项目中,需要将230GB的4K原始素材从移动硬盘导入服务器ÿ…...
:这份内部测试SOP已被3家头部科技公司紧急采购)
DeepSeek-R1补全能力封测倒计时(仅剩72小时开放API灰度权限):这份内部测试SOP已被3家头部科技公司紧急采购
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-R1代码补全能力封测全景概览 DeepSeek-R1 是深度求索(DeepSeek)推出的高性能开源推理模型,在代码补全场景中展现出显著的上下文理解力与多语言泛化能力。本…...

解密高校教师必会的Gemini 3.1 Pro五大科研隐藏技能:从论文评估到创新点锁定
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 科研路上,有人发完顶刊顺利晋升,有人还在为创新点抓耳挠腮。 大多数教…...

Spring Security OAuth2 /oauth/token 401原因与Content-Type规范
1. 问题现场还原:一个看似简单却让开发停摆两小时的/oauth/token请求刚接手一个老项目做安全加固,第一件事就是验证OAuth2密码模式的token获取流程。我照着文档写了一条curl命令:curl -X POST http://localhost:8080/oauth/token回车执行&…...

别再只比参数了!从插件生态到中文优化,聊聊ChatGPT和文心一言的“隐形”差异
超越参数之争:ChatGPT与文心一言的生态与本土化实战解析 当技术评测文章还在反复比较模型参数量与发布时间时,真正影响日常工作效率的往往是那些未被量化的"软实力"。本文将从插件生态构建与中文场景优化两个维度,带您重新认识这两…...

模拟电路实现自主循线机器人:无MCU的硬件逻辑设计
1. 项目概述:用最纯粹的模拟电路,造一台会“思考”的机器人每次看到那些在赛道上灵巧穿梭的循线小车,你是不是也手痒,想自己动手做一个?但一听到“单片机”、“编程”、“Arduino”这些词,又觉得门槛太高&a…...

JS中forEach与普通for
for就不用说了,最普通的循环函数forEach1. 只写 1 个参数只接收当前遍历元素let arr [10,20,30] arr.forEach(item > {console.log(item) // 依次 10、20、30 })2. 写 2 个参数依次接收元素值、下标索引let arr [10,20,30] arr.forEach((item, index) > {co…...

Linux 负载均衡的 cache_nice_tries:缓存友好的迁移尝试
简介现如今服务器、嵌入式设备、工控主板普遍采用多核、NUMA 架构 CPU,多进程多线程并发运行模式成为常态。Linux 内核依靠调度域分层负载均衡机制,分散 CPU 运行压力,避免单核心负载过高、其余核心空闲浪费硬件算力。但任务跨核心迁移是一把…...