大数据分析案例-基于KMeans和DBSCAN算法对汽车行业客户进行聚类分群

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
喜欢大数据分析项目的小伙伴,希望可以多多支持该系列的其他文章
| 大数据分析案例-基于随机森林算法预测人类预期寿命 |
| 大数据分析案例-基于随机森林算法的商品评价情感分析 |
| 大数据分析案例-用RFM模型对客户价值分析(聚类) |
| 大数据分析案例-对电信客户流失分析预警预测 |
| 大数据分析案例-基于随机森林模型对北京房价进行预测 |
| 大数据分析案例-基于RFM模型对电商客户价值分析 |
| 大数据分析案例-基于逻辑回归算法构建垃圾邮件分类器模型 |
| 大数据分析案例-基于决策树算法构建员工离职预测模型 |
| 大数据分析案例-基于KNN算法对茅台股票进行预测 |
| 大数据分析案例-基于多元线性回归算法构建广告投放收益模型 |
| 大数据分析案例-基于随机森林算法构建返乡人群预测模型 |
| 大数据分析案例-基于决策树算法构建金融反欺诈分类模型 |
目录
1.项目背景
2.项目简介
2.1项目说明
2.2数据说明
2.3技术工具
3.算法原理
4.项目实施步骤
4.1理解数据
4.2数据预处理
4.3探索性数据分析
4.3.1不同组别的性别分布
4.3.2不同组别的年龄分布
4.3.3不同组别的工作经验vs消费得分
4.3.4不同组别的客户分布
4.3.5不同组别的家庭规模
4.3.6客户年龄分布
4.3.7工作经验分布
4.3.8家庭规模分布
4.4特征工程
4.5模型构建
4.5.1KMeans
4.5.2DBSCAN
5.实验总结
源代码
1.项目背景
随着汽车行业的快速发展和竞争日益激烈,汽车制造商和销售商需要更好地了解其客户群体,以提供个性化的产品和服务,提高客户满意度,并在市场中取得竞争优势。对于汽车行业来说,客户群体是非常多样化的,包括不同地区、不同年龄、不同收入水平、不同购车动机等的消费者。
在这种背景下,使用聚类分析算法,如KMeans和DBSCAN,可以帮助汽车行业进行客户细分,即将客户划分为具有相似特征的群体。通过这样的细分,汽车企业可以更好地了解不同客户群体的需求和行为,根据客户的特点量身定制产品和服务,提高客户满意度和忠诚度。
KMeans算法是一种常用的聚类分析方法,它将数据点分为预先定义的K个簇,使得每个数据点与所属簇的质心之间的距离最小化。通过KMeans算法,汽车企业可以将客户群体划分为K个不同的类别,每个类别具有相似的购车特征和行为习惯,从而为市场营销和产品推广提供有针对性的策略。
DBSCAN算法是另一种常用的聚类算法,它基于数据点的密度来发现不同形状和大小的簇。DBSCAN算法适用于发现具有不同密度和形状的簇,这对于汽车行业来说尤为重要,因为不同地区的客户群体可能具有不同的密度和规模。
综上所述,基于KMeans和DBSCAN算法对汽车行业客户进行聚类分群的实验具有重要意义,它可以帮助汽车企业深入了解不同客户群体的特征,制定精准的营销策略,提高客户满意度,增加销售额,并在激烈的市场竞争中取得优势。
2.项目简介
2.1项目说明
本实验旨在通过对汽车行业客户数据进行分析,找出不同客户类型的属性和行为特征,最后使用KMeans聚类算法进行聚类分群,根据客户的特点量身定制产品和服务,提高客户满意度和忠诚度,增加销售额,并在激烈的市场竞争中取得优势。
2.2数据说明
本数据集来源于kaggle,原始数据集共有8068条,11个特征变量,各变量含义解释如下:
ID:客户ID
Gender:客户性别
Ever_Married:客户婚姻状况
Age:客户年龄
Graduated:客户是毕业生吗?
Profession:客户的职业
Work_Experience:多年工作经验
Spending_Score:客户的消费评分
Family_Size:客户家庭成员人数(含客户)
Var_1:客户的匿名类别
Segmentation:(目标)客户的客户群
2.3技术工具
Python版本:3.9
代码编辑器:jupyter notebook
3.算法原理
4.项目实施步骤
4.1理解数据
首先导入本次实验用到的第三方库,然后加载数据集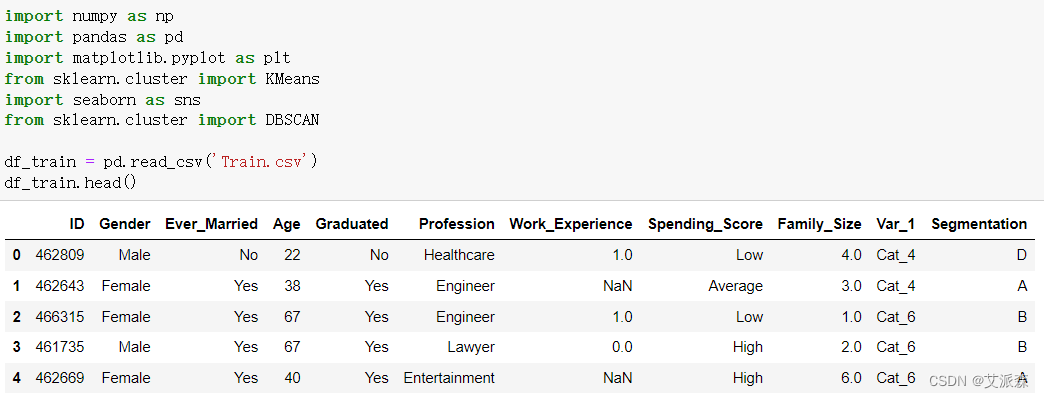
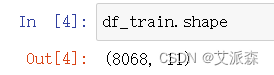
查看数据大小
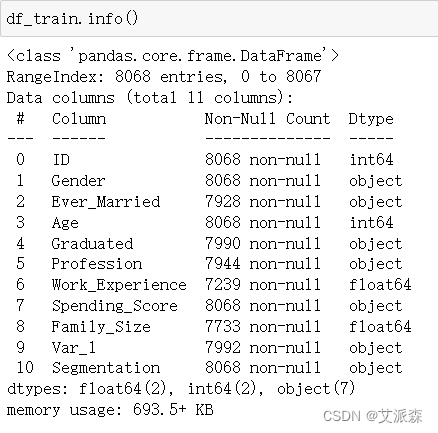
查看数据基本信息
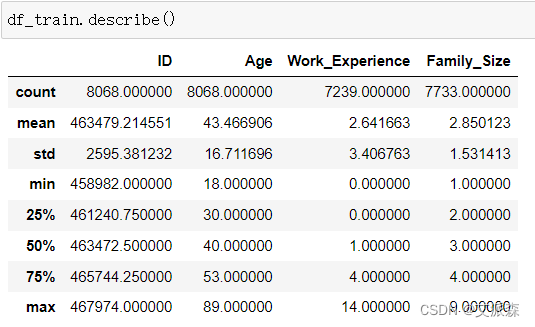
数值型变量描述性统计
非数值型变量描述性统计

4.2数据预处理
统计缺失值情况

删除缺失值
检测数据集是否存在重复值,结果为False说明没有

4.3探索性数据分析
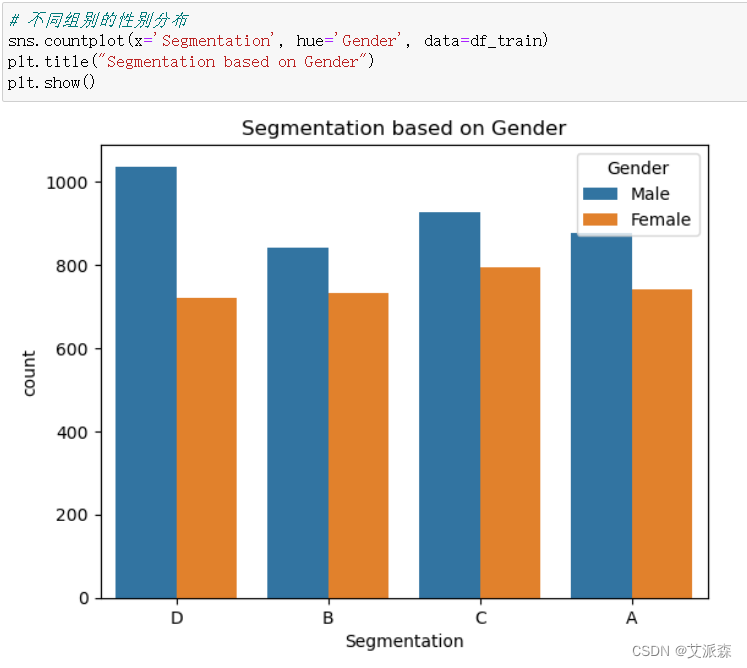
4.3.1不同组别的性别分布
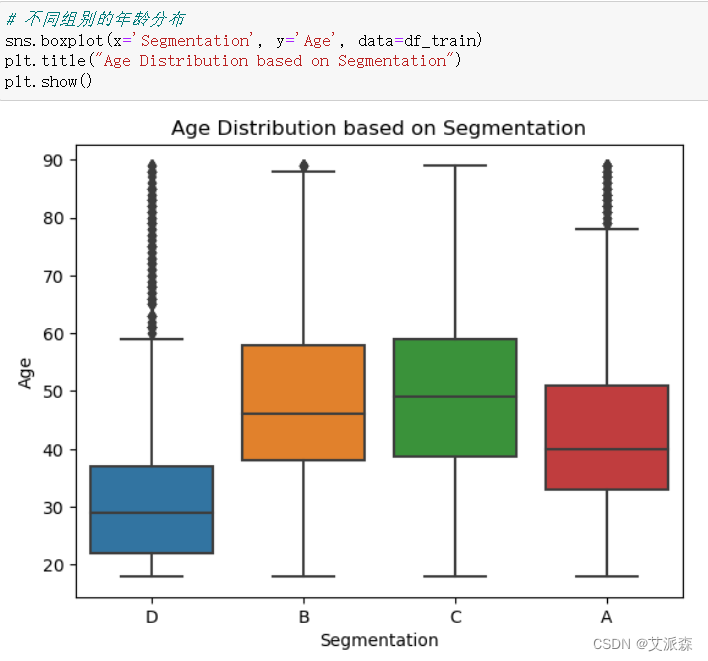
4.3.2不同组别的年龄分布
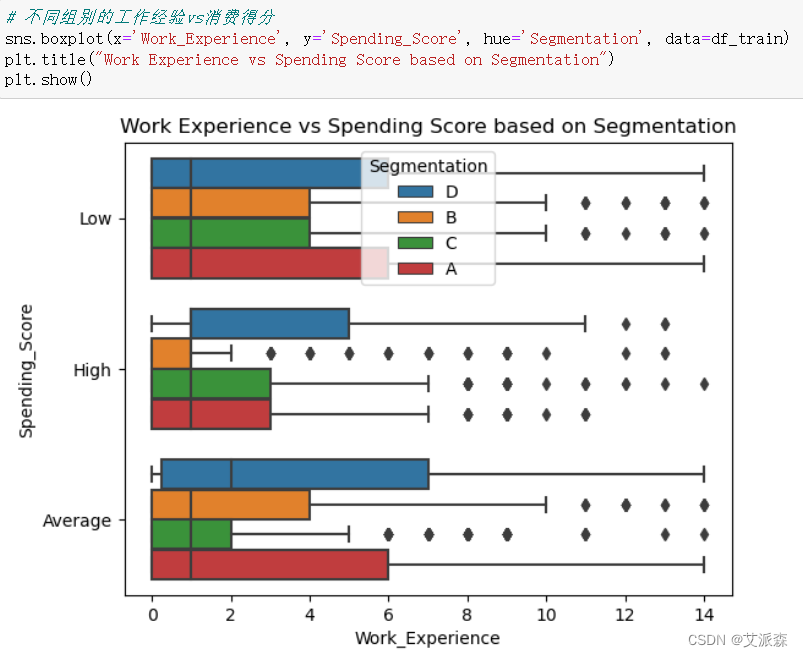
4.3.3不同组别的工作经验vs消费得分
4.3.4不同组别的客户分布
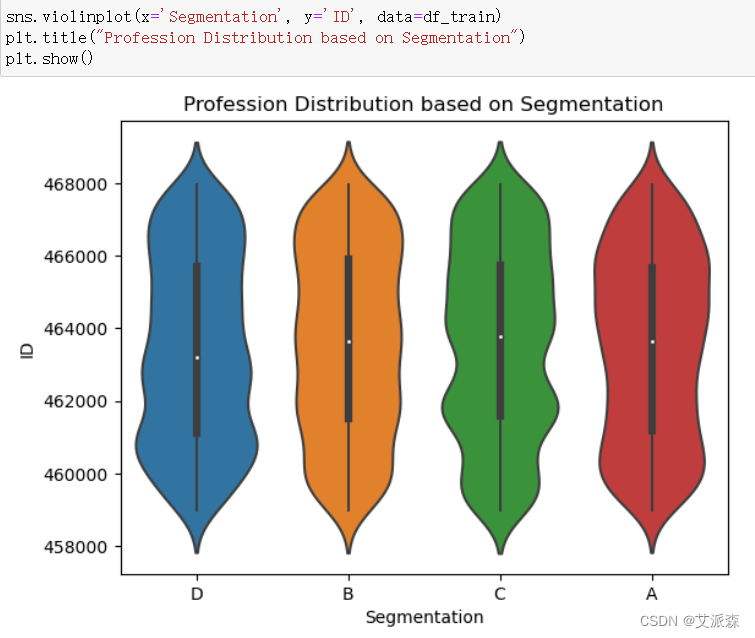
4.3.5不同组别的家庭规模
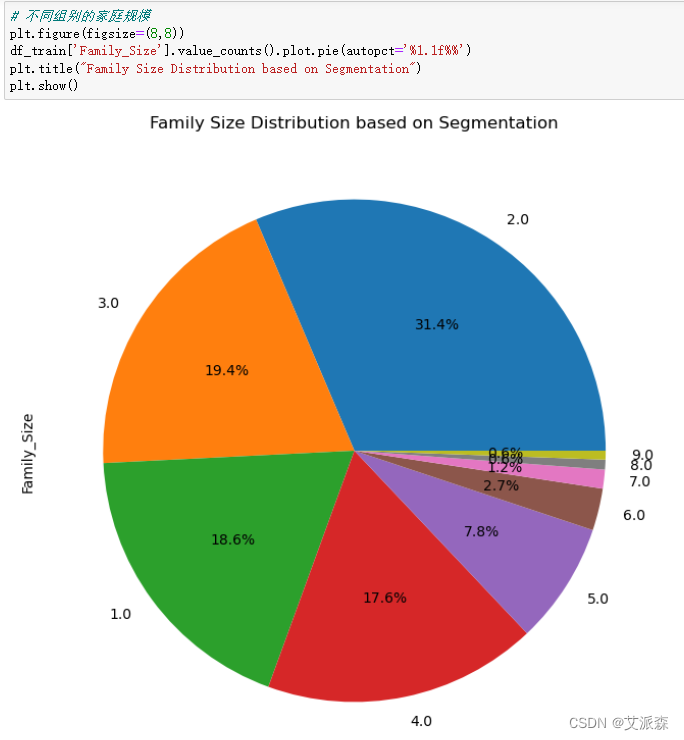
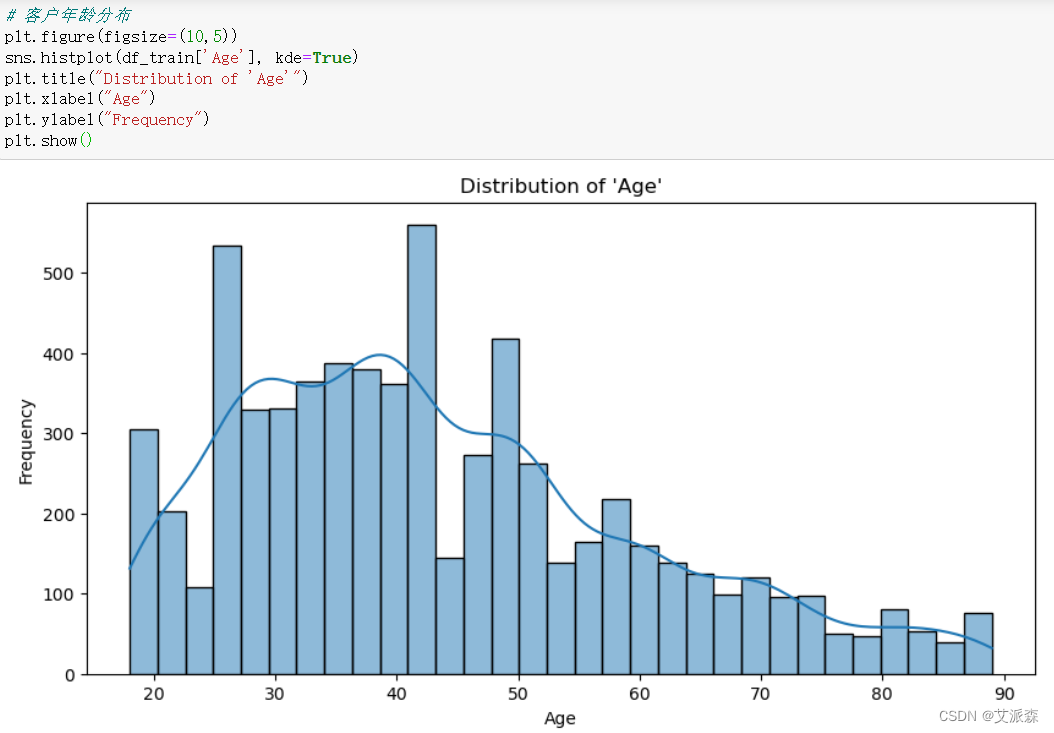
4.3.6客户年龄分布
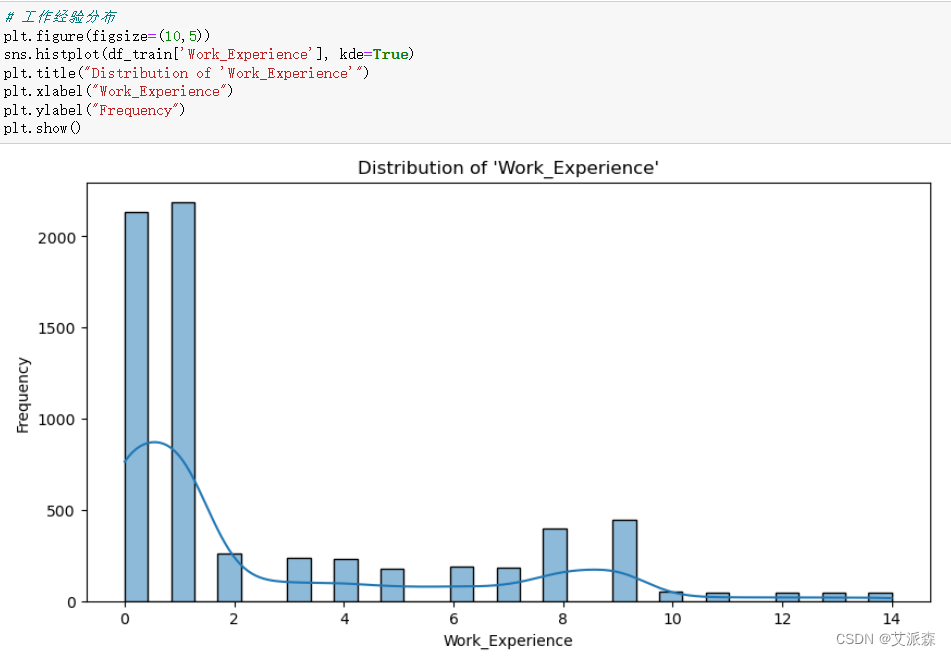
4.3.7工作经验分布
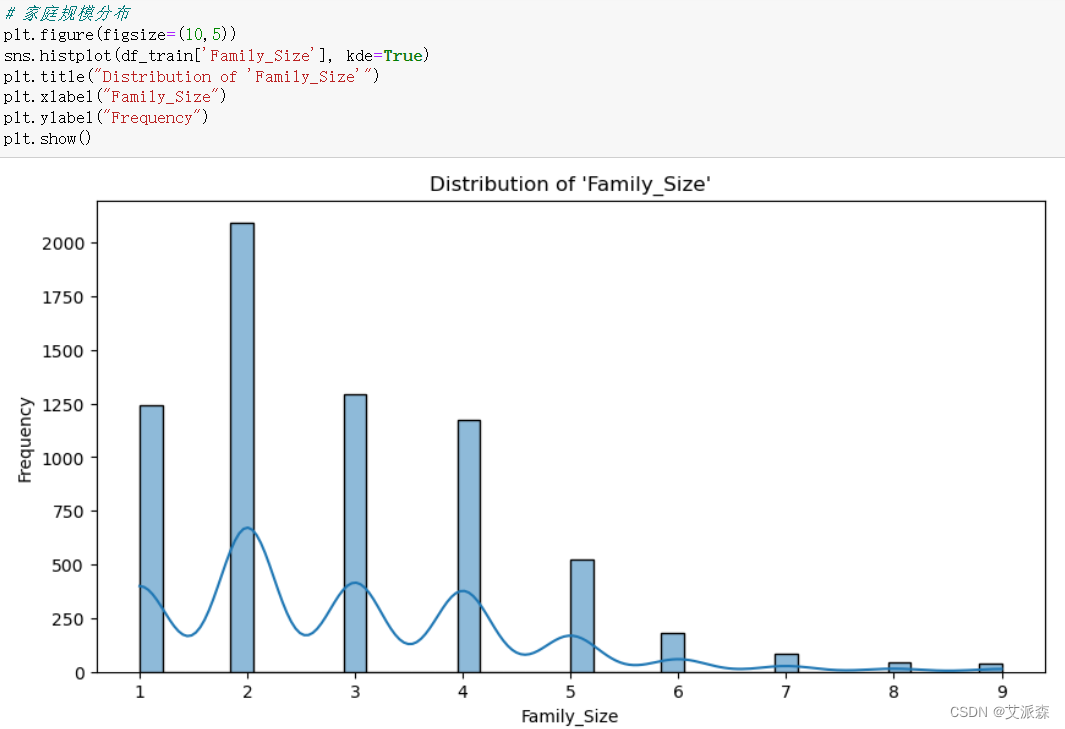
4.3.8家庭规模分布
4.4特征工程
先删除无关变量ID和目标变量

对非数值变量进行编码

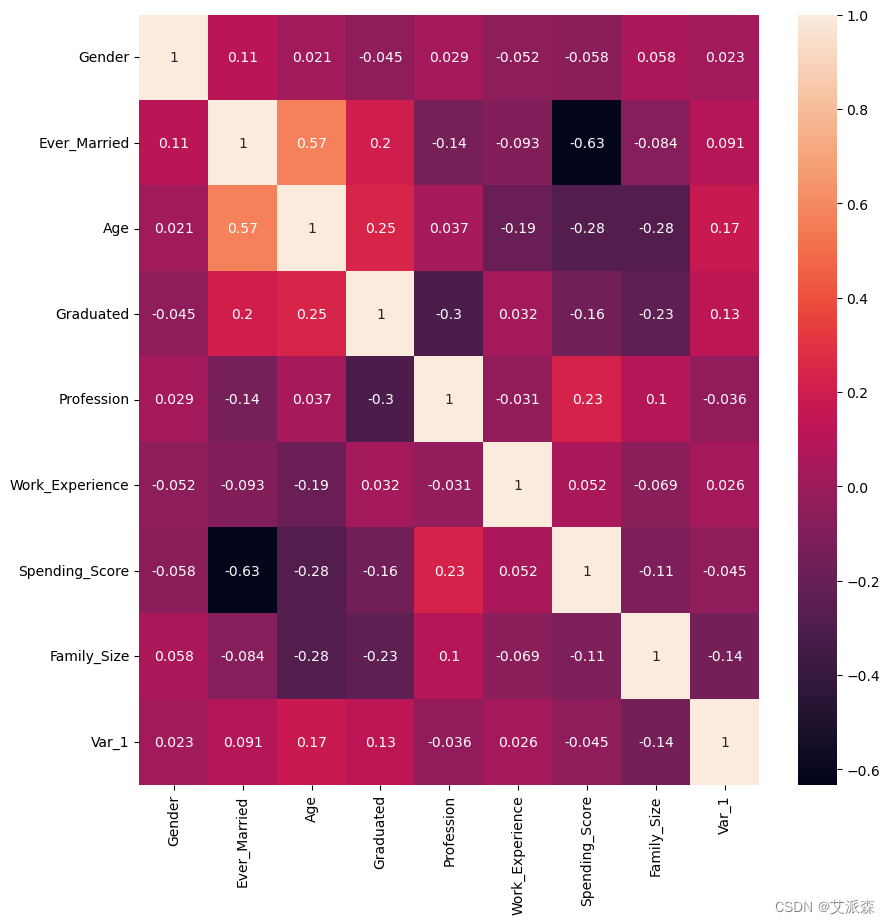
做出相关性热力图

数据标准化处理

4.5模型构建
4.5.1KMeans

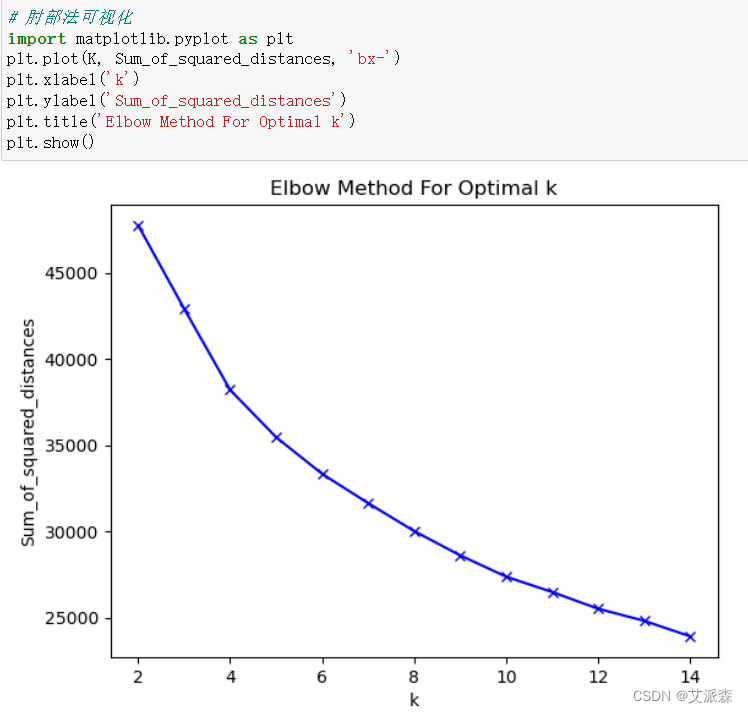
肘部法可视化
训练模型

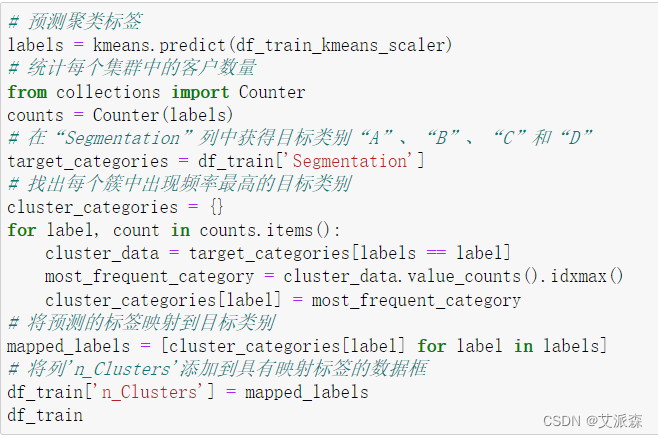
获取聚类标签
模型结果评估
4.5.2DBSCAN
训练模型

模型评估
5.实验总结
针对以上四个细分类别的汽车行业客户,可以制定相应的精准营销策略,以满足不同客户群体的需求和偏好,提高市场营销效果。
1. 细分D:年龄在35岁以下的未婚人士,消费得分低,主要在医疗保健行业工作。
- 营销策略:针对这一群体的客户,可以推出经济实惠的汽车型号,注重车辆的安全性和燃油经济性。强调汽车的安全性和便捷性,例如配备先进的安全技术和智能连接功能,以吸引年轻消费者。同时,可利用社交媒体和互联网广告来宣传,以吸引这一年龄段的年轻人。
2. 细分A:年龄在25岁到53岁之间,结婚率约为55%,消费得分低。职业包括市场营销、娱乐、工程等。主要的家庭规模是1人和2人。
- 营销策略:针对这一群体,可以推出多样化的车型,注重个性化定制服务。考虑到主要是小家庭,可以强调车辆的空间利用和舒适性,以满足家庭出行的需求。另外,可以提供更多的金融方案和促销活动,吸引这一群体的购车兴趣。
3. 细分B:约75%的结婚率,通常在33岁到55岁之间。混合支出得分分布(低:平均:高的比例为4:3:2)。通常在市场营销部门工作。这部分的家庭通常由2个成员组成。
- 营销策略:针对这一群体,可以推出豪华、高品质的汽车型号,注重车辆的品牌价值和科技配置。强调汽车的豪华感和驾驶体验,吸引这一群体对高品质车型的购买。同时,可提供个性化的购车方案和定制服务,满足这一群体的个性化需求。
4. 细分C:80%左右的结婚率,年龄在32 - 70岁之间。各个细分市场的消费得分各不相同(低:平均:高的比例为3:4:2)。主要从事市场营销工作。这部分的家庭规模通常在2到4人之间。
- 营销策略:针对这一群体,可以推出具有较高性价比的汽车型号,注重车辆的耐用性和性能表现。强调汽车的经济实惠和可靠性,满足这一群体对性价比的追求。此外,可以开展与企业合作的促销活动,吸引这一群体的购车兴趣。
心得与体会:
通过这次Python项目实战,我学到了许多新的知识,这是一个让我把书本上的理论知识运用于实践中的好机会。原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。
在这次实战中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等
在此次实战中,我还学会了下面几点工作学习心态:
1)继续学习,不断提升理论涵养。在信息时代,学习是不断地汲取新信息,获得事业进步的动力。作为一名青年学子更就应把学习作为持续工作用心性的重要途径。走上工作岗位后,我会用心响应单位号召,结合工作实际,不断学习理论、业务知识和社会知识,用先进的理论武装头脑,用精良的业务知识提升潜力,以广博的社会知识拓展视野。
2)努力实践,自觉进行主角转化。只有将理论付诸于实践才能实现理论自身的价值,也只有将理论付诸于实践才能使理论得以检验。同样,一个人的价值也是透过实践活动来实现的,也只有透过实践才能锻炼人的品质,彰显人的意志。
3)提高工作用心性和主动性。实习,是开端也是结束。展此刻自我面前的是一片任自我驰骋的沃土,也分明感受到了沉甸甸的职责。在今后的工作和生活中,我将继续学习,深入实践,不断提升自我,努力创造业绩,继续创造更多的价值。
这次Python实战不仅仅使我学到了知识,丰富了经验。也帮忙我缩小了实践和理论的差距。在未来的工作中我会把学到的理论知识和实践经验不断的应用到实际工作中,为实现理想而努力。
源代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import seaborn as sns
from sklearn.cluster import DBSCANdf_train = pd.read_csv('Train.csv')
df_train.head()
df_train.shape
df_train.info()
df_train.describe()
df_train.describe(include='O')
df_train.isnull().sum() # 统计缺失值
df_train.dropna(inplace=True) # 删除缺失值
df_train.shape
any(df_train.duplicated()) # 检测数据集是否存在重复值
# 不同组别的性别分布
sns.countplot(x='Segmentation', hue='Gender', data=df_train)
plt.title("Segmentation based on Gender")
plt.show()
# 不同组别的年龄分布
sns.boxplot(x='Segmentation', y='Age', data=df_train)
plt.title("Age Distribution based on Segmentation")
plt.show()
# 不同组别的工作经验vs消费得分
sns.boxplot(x='Work_Experience', y='Spending_Score', hue='Segmentation', data=df_train)
plt.title("Work Experience vs Spending Score based on Segmentation")
plt.show()
sns.violinplot(x='Segmentation', y='ID', data=df_train)
plt.title("Profession Distribution based on Segmentation")
plt.show()
# 不同组别的家庭规模
plt.figure(figsize=(8,8))
df_train['Family_Size'].value_counts().plot.pie(autopct='%1.1f%%')
plt.title("Family Size Distribution based on Segmentation")
plt.show()
# 客户年龄分布
plt.figure(figsize=(10,5))
sns.histplot(df_train['Age'], kde=True)
plt.title("Distribution of 'Age'")
plt.xlabel("Age")
plt.ylabel("Frequency")
plt.show()
# 工作经验分布
plt.figure(figsize=(10,5))
sns.histplot(df_train['Work_Experience'], kde=True)
plt.title("Distribution of 'Work_Experience'")
plt.xlabel("Work_Experience")
plt.ylabel("Frequency")
plt.show()
# 家庭规模分布
plt.figure(figsize=(10,5))
sns.histplot(df_train['Family_Size'], kde=True)
plt.title("Distribution of 'Family_Size'")
plt.xlabel("Family_Size")
plt.ylabel("Frequency")
plt.show()
# 删除目标变量
df_train_kmeans = df_train.drop(['Segmentation', 'ID'], axis=1)
df_train_kmeans
# 将分类列转换为标签编码列
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
df_train_kmeans['Gender'] = encoder.fit_transform(df_train_kmeans['Gender'])
df_train_kmeans['Ever_Married'] = encoder.fit_transform(df_train_kmeans['Ever_Married'])
df_train_kmeans['Graduated'] = encoder.fit_transform(df_train_kmeans['Graduated'])
df_train_kmeans['Profession'] = encoder.fit_transform(df_train_kmeans['Profession'])
df_train_kmeans['Spending_Score'] = encoder.fit_transform(df_train_kmeans['Spending_Score'])
df_train_kmeans['Var_1'] = encoder.fit_transform(df_train_kmeans['Var_1'])
df_train_kmeans.head()
# 相关系数矩阵
corr = df_train_kmeans.corr()
# 绘制热力图
plt.figure(figsize=(10,10))
sns.heatmap(corr, annot=True)
plt.show()
# 数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df_train_kmeans_scaler = scaler.fit_transform(df_train_kmeans)
df_train_kmeans_scaler
KMeans
# 肘部法寻找最佳簇数
Sum_of_squared_distances = []
K = range(2,15)
for k in K:km = KMeans(n_clusters=k)km = km.fit(df_train_kmeans_scaler)Sum_of_squared_distances.append(km.inertia_)print("For k =", k, ", the inertia is", km.inertia_)
# 肘部法可视化
import matplotlib.pyplot as plt
plt.plot(K, Sum_of_squared_distances, 'bx-')
plt.xlabel('k')
plt.ylabel('Sum_of_squared_distances')
plt.title('Elbow Method For Optimal k')
plt.show()
# 根据肘部法确定最佳聚类数
best_k = 4
# 训练KMeans模型
kmeans = KMeans(n_clusters=best_k)
kmeans.fit(df_train_kmeans_scaler)
# 预测聚类标签
labels = kmeans.predict(df_train_kmeans_scaler)
# 统计每个集群中的客户数量
from collections import Counter
counts = Counter(labels)
# 在“Segmentation”列中获得目标类别“A”、“B”、“C”和“D”
target_categories = df_train['Segmentation']
# 找出每个簇中出现频率最高的目标类别
cluster_categories = {}
for label, count in counts.items():cluster_data = target_categories[labels == label]most_frequent_category = cluster_data.value_counts().idxmax()cluster_categories[label] = most_frequent_category
# 将预测的标签映射到目标类别
mapped_labels = [cluster_categories[label] for label in labels]
# 将列'n_Clusters'添加到具有映射标签的数据框
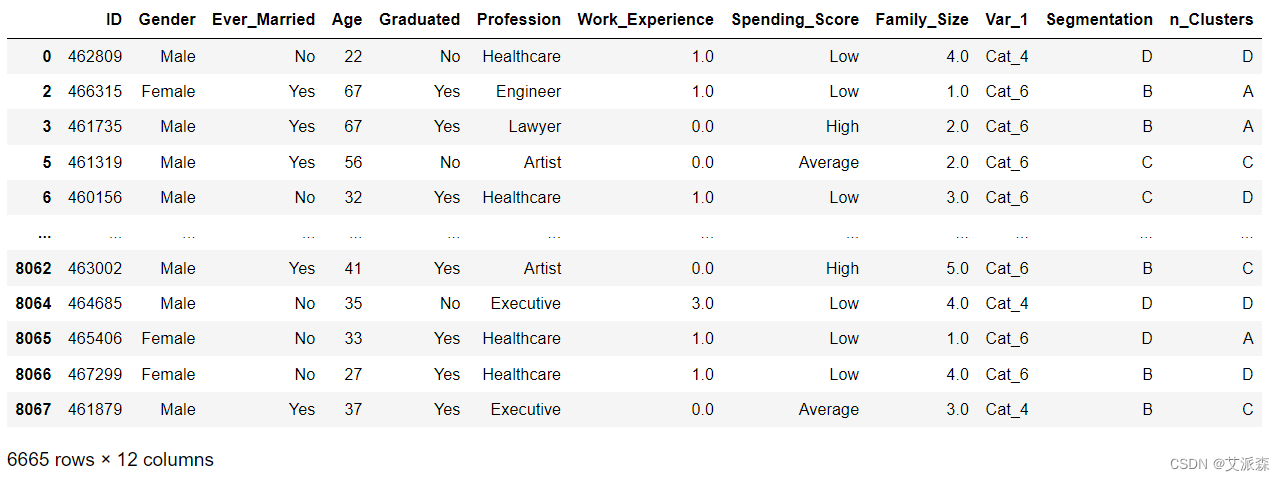
df_train['n_Clusters'] = mapped_labels
df_train
# 计算正确预测的次数
correct_predictions = sum(df_train['Segmentation'] == df_train['n_Clusters'])
# 计算预测的总数
total_predictions = df_train.shape[0]
# 以百分比计算准确度
accuracy = (correct_predictions / total_predictions) * 100
print("-- Accuracy for KMeans: {:.2f}%".format(accuracy))
DBSCAN
# 训练DBSCAN模型
dbscan = DBSCAN(eps=0.6, min_samples=5)
dbscan.fit(df_train_kmeans_scaler)
# 预测聚类标签
labels = dbscan.labels_
# 统计每个集群中的客户数量
from collections import Counter
counts = Counter(labels)
# 在` Segmentation `列中获得目标类别` A `, ` B `, ` C `和` D `
target_categories = df_train['Segmentation']
# 找出每个簇中出现频率最高的目标类别
cluster_categories = {}
for label, count in counts.items():cluster_data = target_categories[labels == label]most_frequent_category = cluster_data.value_counts().idxmax()cluster_categories[label] = most_frequent_category
# 将预测的标签映射到目标类别
mapped_labels = [cluster_categories[label] if label in cluster_categories else 'Noise' for label in labels]
# 将列'n_Clusters'添加到具有映射标签的数据框
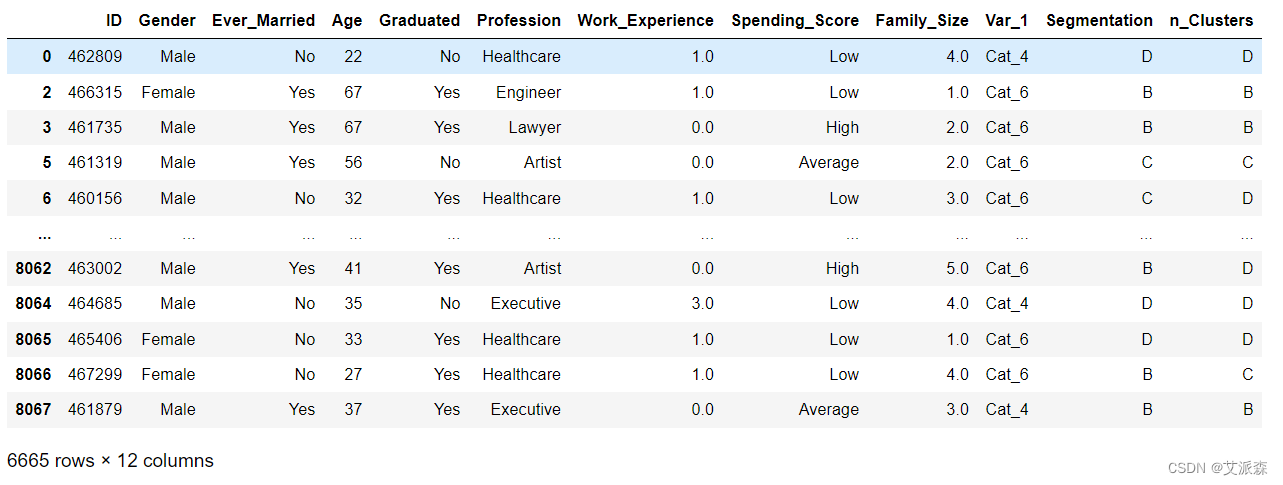
df_train['n_Clusters'] = mapped_labels
df_train
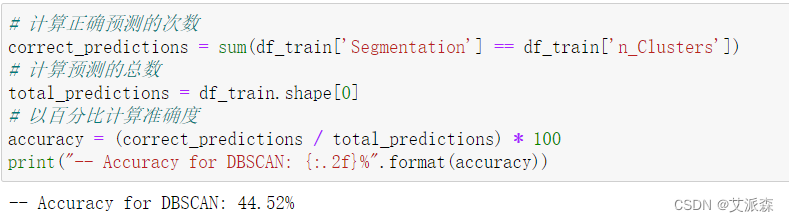
# 计算正确预测的次数
correct_predictions = sum(df_train['Segmentation'] == df_train['n_Clusters'])
# 计算预测的总数
total_predictions = df_train.shape[0]
# 以百分比计算准确度
accuracy = (correct_predictions / total_predictions) * 100
print("-- Accuracy for DBSCAN: {:.2f}%".format(accuracy))相关文章:
大数据分析案例-基于KMeans和DBSCAN算法对汽车行业客户进行聚类分群
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

Vue 3 中定义组件常用方法
在Vue 3 中有多种定义组件的方法。从选项到组合再到类 API,情况大不相同 1、方式一:Options API 这是在 Vue 中声明组件的最常见方式。从版本 1 开始可用,您很可能已经熟悉它。一切都在对象内声明,数据在幕后由 Vue 响应。它不是…...

Linux | curl命令调用接口时查看调用时长和详情
关注wx: CodingTechWork 引言 在服务器中通过curl命令调用接口时,我们经常需要分析一些时长。本文主要总结两种方式进行处理。 curl命令 使用time命令 time curl -k -u <username>:<password> https://127.0.0.1/xxxx -vvv 使用文本 编…...
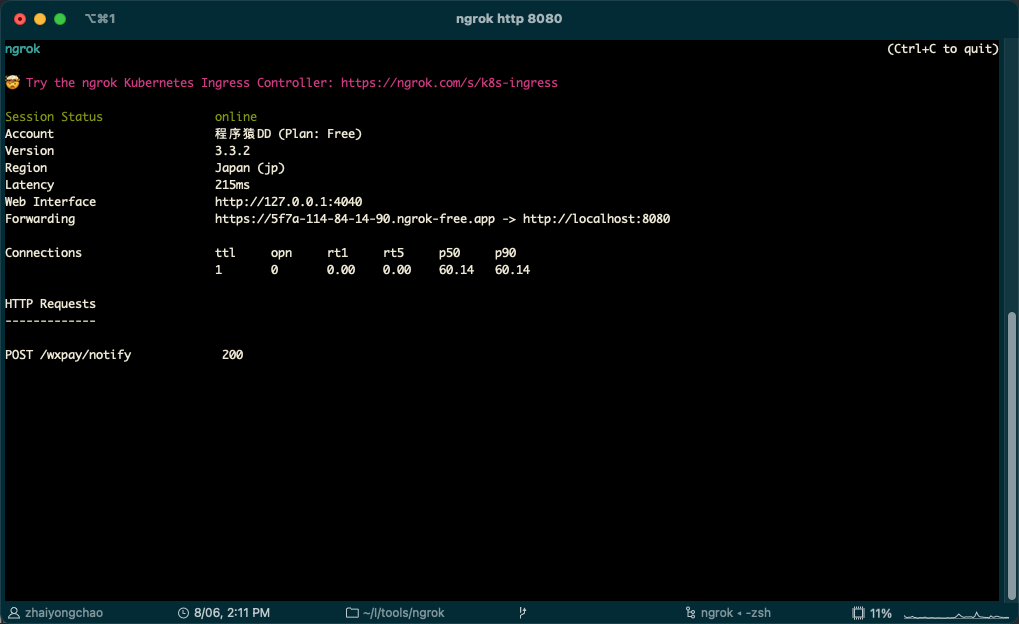
用ngrok实现内网穿透,一行命令就搞定!
最近在写支付的东西,调试时候需要让支付平台能够回调本地接口来更新支付成功的状态。但由于开发机器没有公网IP,所以需要使用内网穿透来让支付平台能够成功访问到本地开发机器,这样才能更高效率的进行调试。 推荐内网穿透的文章已经很多很多…...
C++ 混合Python编程 及 Visual Studio配置
文章目录 需求配置环节明确安装的是64位Python安装目录 创建Console C ProjectCpp 调用 Python Demo 参考 需求 接手了一个C应用程序,解析csv和生成csv文件,但是如果要把多个csv文件合并成一个Excel,分布在不同的Sheet中,又想在一…...

斐波拉契数列+二进制--夏令营
1. f[40]{0,1} 数组赋值:只赋值前两个的话,剩余的自动为0 2.先要自己写出斐波拉契数列判断一下应该要多少个斐波拉契数样例,第39项已经超样例数500了,所以够用 3.就是把一个数字拆分成斐波拉契数列里的数的和嘛,但是…...
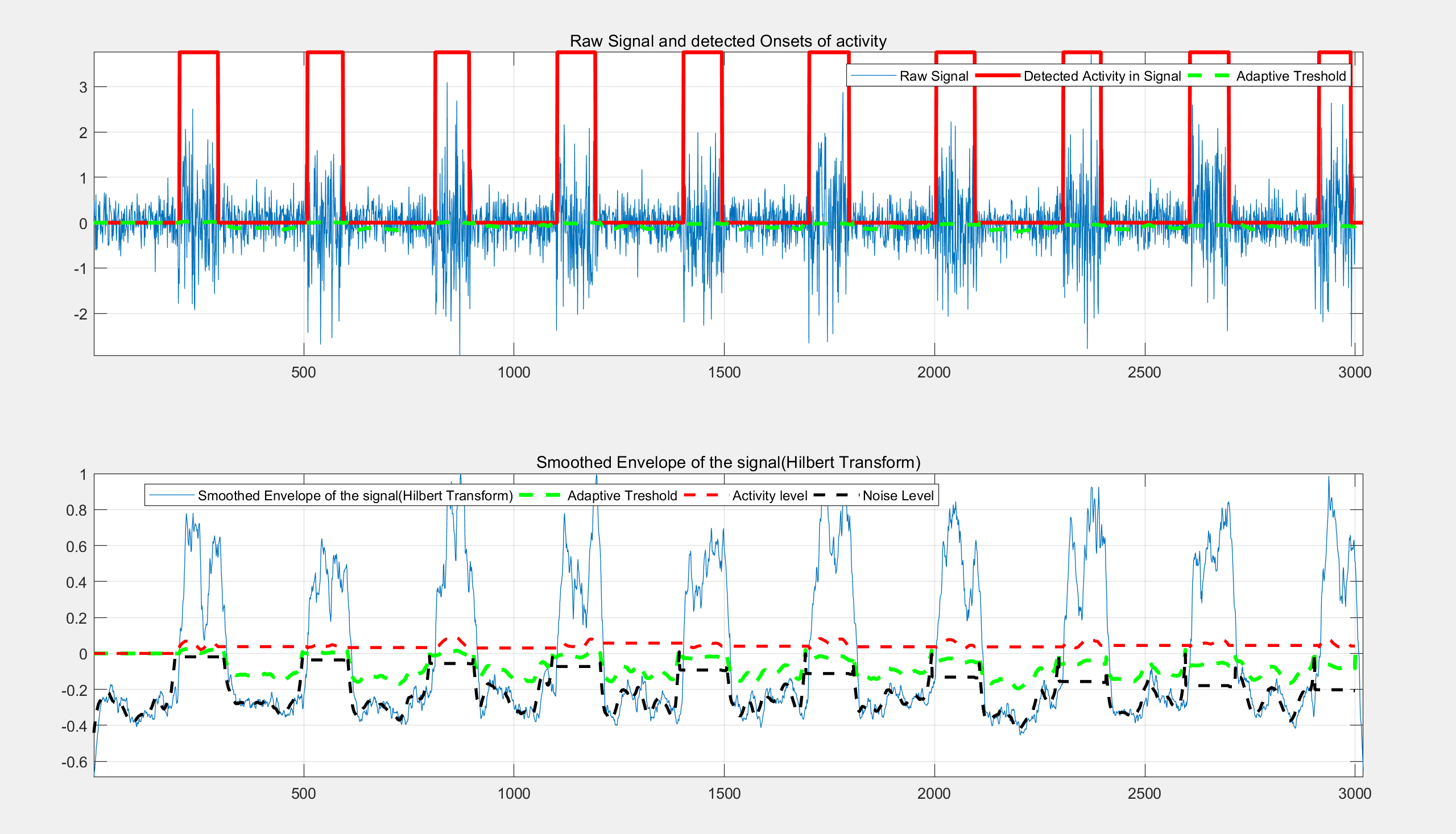
【使用Hilbert变换在噪声信号中进行自动活动检测】基于Hilbert变换和平滑技术进行自动信号分割和活动检测研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Android 13 Launcher——屏蔽上拉到应用列表
背景 Launcher定制需要将原先的应用列表去掉,可以从根源去掉,就是将上拉出现应用列表的上拉手势直接屏蔽,让其不能上拉出现应用列表界面,在研究的过程中顺便将下拉出现负一屏的逻辑也研究了下,如下就是具体实现。 目录 背景 一.如何屏蔽上拉出现应用列表 一.如何屏蔽上拉…...

Java 基础知识点
Object 类相关方法 getClass 获取当前运行时对象的 Class 对象。 hashCode 返回对象的 hash 码。 clone 拷贝当前对象, 必须实现 Cloneable 接口。浅拷贝对基本类型进行值拷贝,对引用类型拷贝引用;深拷贝对基本类型进行值拷贝,对…...

jenkins容器内CI/CD 项目失败问题
问题: 在jenkins 的docker容器内CI/CD制作vue项目镜像失败 1、docker权限问题 permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Post "http://%2Fvar%2Frun%2Fdocker.sock/v1.24/build?buildargs%…...

CRC 校验码
CRC 校验码 题目解答发送端接收端 题目 假设生成多项式为 G(X)X4X31,要求出二进制序列10110011的CRC校验码 解答 发送端 首先 生成多项式为:G(X)X4X31,改写为二进制比特串为11001(有X的几次方,对应的2的几次方的位就是1) 因为…...

代码随想录二刷day01
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、704. 二分查找二、35. 搜索插入位置三、34. 在排序数组中查找元素的第一个和最后一个位置四、69. x 的平方根五、367. 有效的完全平方数六、27. 移除元素七…...
【C++奇遇记】智能的函数探幽
🎬 博客主页:博主链接 🎥 本文由 M malloc 原创,首发于 CSDN🙉 🎄 学习专栏推荐:LeetCode刷题集 数据库专栏 初阶数据结构 🏅 欢迎点赞 👍 收藏 ⭐留言 📝 如…...
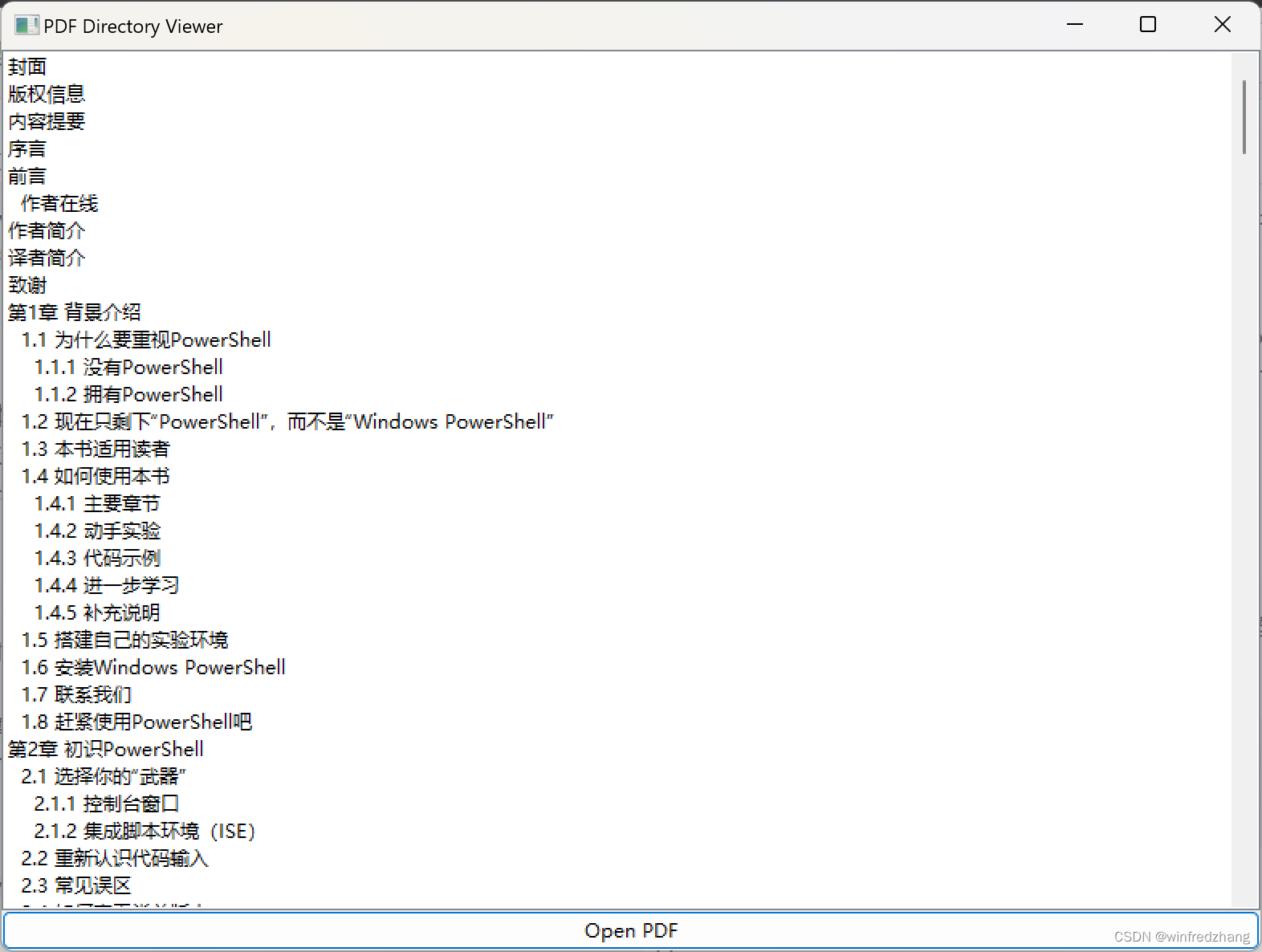
使用wxPython和PyMuPDF在Python中显示PDF目录的实现
展示如何使用wxPython和PyMuPDF库在Python中选择PDF文件并将目录显示在列表框中。 简介: 在本篇教程中,我们将学习如何使用wxPython和PyMuPDF库在Python中选择PDF文件,并将其目录显示在一个列表框中。这将使用户能够方便地浏览PDF文档的目录…...

综述:计算机视觉中的图像分割
一、说明 这篇文章是关于图像分割的探索,这是解决计算机视觉问题(如对象检测、对象识别、图像编辑、医学图像分析、自动驾驶汽车等)的重要步骤之一。让我们从介绍开始。 二、图像分割介绍 图像分割是计算机视觉中的一项基本任务,涉…...

【动态规划基础】数字三角形(IOI1994)
题目描述 数字三角形 输入输出样例 输入样例#1: 5 7 3 8 8 1 0 2 7 4 4 4 5 2 6 5输出样例#1: 30思路: 这题可能看到的第一眼——直接贪心然后一层一层判断呀!!!不过很快又会发现,额___好…...

yolo源码注释2——数据集配置文件
代码基于yolov5 v6.0 目录: yolo源码注释1——文件结构yolo源码注释2——数据集配置文件yolo源码注释3——模型配置文件yolo源码注释4——yolo-py 数据集配置文件一般放在 data 文件夹下的 XXX.yaml 文件中,格式如下: path: # 数据集存放路…...
)
Java实现根据姓名生成头像(钉钉样式)
头像生成器代码如下: package com.hua.util;import org.apache.commons.lang3.StringUtils;import javax.imageio.ImageIO; import java.awt.*; import java.awt.geom.RoundRectangle2D; import java.awt.image.BufferedImage; import java.io.File; import java.i…...

微信小程序备案流程
微信小程序备案流程 📔 千寻简笔记介绍 千寻简笔记已开源,Gitee与GitHub搜索chihiro-notes,包含笔记源文件.md,以及PDF版本方便阅读,且是用了精美主题,阅读体验更佳,如果文章对你有帮助请帮我…...
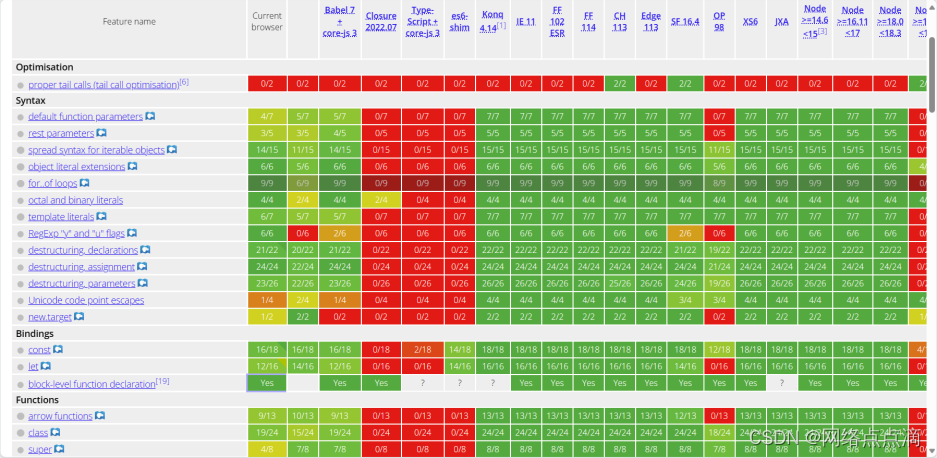
JavaScript版本ES5/ES6及后续版本
JavaScript简史 1995: Brendan Eich在短短10天内创建了JavaScript的第一个版本。它被称为摩卡,但已经具备了现代JavaScript的许多基本特性! 1996: 为了吸引Java开发人员,Mocha先是更改为LiveScript,然后又更改为Ja…...

WebSocket实时通信架构进阶:Room、命名空间与集群部署
WebSocket实时通信架构进阶:Room、命名空间与集群部署 作者:Crown_22 | AI Agent & Hermes Agent 桌面程序开发者 前言 WebSocket已经成为实时应用的标准技术,但大多数教程只停留在"建立连接、发送消息"的基础阶段。在生产环境中,你需要处理Room管理、命名空…...

Hindsight测试策略:单元测试、集成测试和端到端测试
Hindsight测试策略:单元测试、集成测试和端到端测试 【免费下载链接】hindsight Hindsight: Agent Memory That Learns 项目地址: https://gitcode.com/GitHub_Trending/hindsight2/hindsight Hindsight作为一款专注于Agent Memory的开源项目,其可…...

HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器
HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III地图编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hiv…...

通过Taotoken实现Hermes Agent自定义模型供应商接入
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken实现Hermes Agent自定义模型供应商接入 Hermes Agent是一个流行的AI智能体开发框架,它支持通过配置自定义…...

render_async嵌套渲染:构建复杂异步界面的完整解决方案
render_async嵌套渲染:构建复杂异步界面的完整解决方案 【免费下载链接】render_async render_async lets you include pages asynchronously with AJAX 项目地址: https://gitcode.com/gh_mirrors/re/render_async 在现代Web开发中,页面加载速度…...

Burp抓包失败的五大隐形墙与HTTPS解密断裂点排查指南
1. 这不是Burp用得不对,是环境链路断在了你没看见的地方“Burp抓不到包”——这句话我过去三年里听开发、测试、刚转安全的新人说了不下两百遍。但真正打开Burp一看,Proxy标签页里空空如也,连个localhost:8080的请求都没有,十有八…...

别再盲调temperature=0.2!DeepSeek补全效果突变的4个隐藏参数,资深架构师压箱底调参清单
更多请点击: https://intelliparadigm.com 第一章:别再盲调temperature0.2!DeepSeek补全效果突变的4个隐藏参数,资深架构师压箱底调参清单 DeepSeek-R1/VL 等开源大模型在实际部署中,仅靠调节 temperature 往往收效甚…...

Facebook登录协议逆向解析:appsecret_proof与e2e加密机制
1. 这不是“爬虫教程”,而是一次对现代Web身份协议的解剖实验你有没有试过,在调试一个Facebook登录集成时,浏览器Network面板里突然冒出一串带sig、access_token、e2e、c_user的请求,参数长度动辄上千字符,加密方式五花…...

使用Taotoken CLI工具一键配置多开发环境下的统一模型接入点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置多开发环境下的统一模型接入点 在团队协作或管理多个AI应用项目时,一个常见的痛点是每个…...

终极指南:用AlwaysOnTop免费开源工具彻底改变你的Windows工作方式
终极指南:用AlwaysOnTop免费开源工具彻底改变你的Windows工作方式 【免费下载链接】AlwaysOnTop Make a Windows application always run on top 项目地址: https://gitcode.com/gh_mirrors/al/AlwaysOnTop 你是否经常在多个窗口间来回切换,浪费宝…...