Android Jetpack Compose 中的分页与缓存展示

Android Jetpack Compose 中的分页与缓存展示
在几乎任何类型的移动项目中,移动开发人员在某个时候都会处理分页数据。如果数据列表太大,无法一次从服务器检索完毕,这就是必需的。因此,我们的后端同事为我们提供了一个端点,返回分页数据列表,并期望我们知道如何在客户端处理它。
在本文中,我们将重点介绍如何使用 Android 在 2023 年 6 月推荐的最新方法来获取、缓存和显示分页数据。我们将经过以下步骤:
- 从公共 GraphQL API 中按页获取 Pokemon 数据列表
- 使用 Room 将获取的数据缓存到本地数据库
- 使用最新的 Paging 库组件来处理分页
- 使用 LazyColumn 智能地显示页面项(只渲染可见内容)
对于示例项目,我将在文章末尾分享 GitHub 存储库链接,我们将使用 Hilt 作为我们的依赖注入库,并使用干净架构(表示层 → 领域层 ← 数据层)。因此,我将从数据层开始解释事物,然后转向领域层,最后结束在表示层。
数据层
这一层是关于分页和缓存的大部分内容。因此,如果您能够通过这一部分,您将基本完成了它。
远程数据源
作为远程数据源,我们将使用一个公共的 GraphQL Pokemon API。与我们用于与 REST API 交互的 Retrofit 不同,我们使用 Apollo 的 Kotlin 客户端来处理 GraphQL API。它允许我们执行 GraphQL 查询,并根据请求和响应自动生成 Kotlin 模型。
首先,我们需要将以下行添加到我们的模块级别的 build.gradle 文件中:
plugins {// ...id "com.apollographql.apollo3" version "$apollo_version"
}apollo {service("pokemon") {packageName.set("dev.thunderbolt.pokemonpager.data")}
}dependencies {// ...implementation "com.apollographql.apollo3:apollo-runtime:$apollo_version"
}
在这里,我们在 apollo 块中设置了 Apollo 库的配置。它提供了许多设置,您可以通过其文档查看所有设置。目前,我们只需要将包名设置为 dev.thunderbolt.pokemonpager.data,这样生成的 Kotlin 文件将位于正确的包中,也就是数据层。
然后,我们需要下载服务器的模式,以便库能够生成模型,并且我们可以使用自动完成来编写查询。为了下载模式,我们使用 Apollo 提供的以下命令:
./gradlew :app:downloadApolloSchema --endpoint='https://graphql-pokeapi.graphcdn.app/graphql' --schema=app/src/main/graphql/schema.graphqls
这将在 app/src/main/graphql/schema.graphqls 目录中下载服务器的模式。
现在,是时候在一个名为 pokemon.graphql 的文件中编写我们的查询,该文件与模式文件位于同一文件夹中。
query PokemonList($offset: Int!$limit: Int!
) {pokemons(offset: $offset,limit: $limit) {nextOffsetresults {idnameimage}}
}
当我们构建项目时,Apollo Kotlin 将通过自动运行名为 generateApolloSources 的 Gradle 任务为此查询生成模型。
回到 Kotlin 的世界,我们将定义我们的 PokemonApi 类,以封装与 GraphQL 的所有交互,如下所示:
class PokemonApi {private val BASE_URL = "https://graphql-pokeapi.graphcdn.app/graphql"private val apolloClient = ApolloClient.Builder().serverUrl(BASE_URL).addHttpInterceptor(LoggingInterceptor()).build()suspend fun getPokemonList(offset: Int, limit: Int): PokemonListQuery.Pokemons? {val response = apolloClient.query(PokemonListQuery(offset = offset,limit = limit,)).execute()// IF RESPONSE HAS ERRORS OR DATA IS NULL, THROW EXCEPTIONif (response.hasErrors() || response.data == null) {throw ApolloException(response.errors.toString())}return response.data!!.pokemons}
}
在这里,我们使用所需的配置初始化 Apollo Client 实例,并实现了我们执行在 pokemon.graphql 文件中编写的生成的 Kotlin 版本查询的函数。该函数基本上会获取 offset 和 limit 参数,执行查询,如果一切顺利,就会返回查询的响应,这也是由 Apollo 自动生成的。
本地数据源/存储
为了在本地存储关系型数据并创建一个离线优先的应用程序,我们将依赖于 Room,这是一个在 SQLite 之上编写的 Android 持久性库。
首先,我们需要将 Room 依赖项添加到我们的 build.gradle 文件中:
dependencies {// ...implementation "androidx.room:room-ktx:$room_version"kapt "androidx.room:room-compiler:$room_version"implementation "androidx.room:room-paging:$room_version"
}
然后,我们将定义两个实体类,一个用于在我们的数据库中存储 Pokemon 数据,另一个用于跟踪要获取的下一页的页数。
@Entity("pokemon")
data class PokemonEntity(@PrimaryKey val id: Int,val name: String,val imageUrl: String,
)@Entity("remote_key")
data class RemoteKeyEntity(@PrimaryKey val id: String,val nextOffset: Int,
)
在这方面,我们还需要两个 DAO(数据访问对象)类来定义其中的所有数据库交互。
@Dao
interface PokemonDao {@Insert(onConflict = OnConflictStrategy.REPLACE)suspend fun insertAll(items: List<PokemonEntity>)@Query("SELECT * FROM pokemon")fun pagingSource(): PagingSource<Int, PokemonEntity>@Query("DELETE FROM pokemon")suspend fun clearAll()
}@Dao
interface RemoteKeyDao {@Insert(onConflict = OnConflictStrategy.REPLACE)suspend fun insert(item: RemoteKeyEntity)@Query("SELECT * FROM remote_key WHERE id = :id")suspend fun getById(id: String): RemoteKeyEntity?@Query("DELETE FROM remote_key WHERE id = :id")suspend fun deleteById(id: String)
}
在这里,我们需要特别关注的关键函数是 pagingSource()。Room 可以返回数据列表作为 PagingSource,以便我们稍后将创建的 Pager 对象将其用作生成 PagingData 流的单一源。
最后,我们需要一个 RoomDatabase 类,在本地数据库中为这些实体创建表,并提供 DAO 以与这些表进行交互。
@Database(entities = [PokemonEntity::class, RemoteKeyEntity::class],version = 1,
)
abstract class PokemonDatabase : RoomDatabase() {abstract val pokemonDao: PokemonDaoabstract val remoteKeyDao: RemoteKeyDao
}这两个类,即 PokemonDatabase 和之前定义的 PokemonApi 类,都由我们数据层的 Hilt 模块实例化并提供为单例对象。
@Module
@InstallIn(SingletonComponent::class)
class DataModule {@Provides@Singletonfun providePokemonDatabase(@ApplicationContext context: Context): PokemonDatabase {return Room.databaseBuilder(context,PokemonDatabase::class.java,"pokemon.db",).fallbackToDestructiveMigration().build()}@Provides@Singletonfun providePokemonApi(): PokemonApi {return PokemonApi()}// ...
}
远程中介器(Remote Mediator)
现在,我们要实现我们的远程中介器类(RemoteMediator),它将负责在需要时从远程 API 加载分页数据到本地数据库中。需要注意的是,远程中介器并不直接向用户界面提供数据。如果分页数据用尽,分页库会触发远程中介器的 load(…) 方法,以从远程获取并存储更多的数据到本地。因此,我们的本地数据库始终可以保持作为唯一的真实数据源。
在 load(…) 函数中,我们首先需要检查我们正在处理哪种类型的加载。如果 LoadType 是:
- REFRESH,这意味着我们要么处于初始加载状态,要么数据已经无效,我们需要从头开始获取数据。因此,如果是这种情况,我们将偏移值设置为 “0”,以获取第一页的数据。
- PREPEND,我们需要获取当前页面之前的页面数据。在这个示例的范围内,不需要在向上滚动时获取任何内容。因此,我们只需返回
MediatorResult.Success(endOfPaginationReached = true),以指示不应再进行数据加载。 - APPEND,我们需要获取当前页面之后的页面数据。在这种情况下,我们会获取已经由前一个数据加载存储在本地数据库中的远程键(remote key)对象。如果没有或者其
nextOffset值为 “0”,则表示没有更多数据可加载和追加。顺便说一下,这就是该 API 的工作方式。你的 API 可能以不同方式指示数据的结束,因此需要相应地编写你的 APPEND 逻辑。
在确定了正确的偏移值之后,现在是时候使用此偏移值和配置中提供的 pageSize 进行 API 调用了。我们将在下一步创建 Pager 对象时设置页面大小。
如果 API 调用成功返回新的页面数据,我们将使用相应的 DAO 函数将项目和下一个偏移值存储在我们的数据库中。在这里,我们需要在事务块中执行所有数据库交互,以便如果任何交互失败,数据库不会发生任何更改。
最后,如果在数据库调用之后一切顺利,我们将返回 MediatorResult.Success,通过将最新加载返回的项目数与我们将在配置中定义的页面大小进行比较,来检查是否已达到分页的末尾。
Pager 对象
现在,我们要再次回到我们数据层的 Hilt 模块,并创建我们的 Pager 对象。这个对象将把我们到目前为止所定义的所有内容整合在一起,作为 PagingData 流的构造函数工作。
@Module
@InstallIn(SingletonComponent::class)
class DataModule {// ...@Provides@Singletonfun providePokemonPager(pokemonDatabase: PokemonDatabase,pokemonApi: PokemonApi,): Pager<Int, PokemonEntity> {return Pager(config = PagingConfig(pageSize = 20),remoteMediator = PokemonRemoteMediator(pokemonDatabase = pokemonDatabase,pokemonApi = pokemonApi,),pagingSourceFactory = {pokemonDatabase.pokemonDao.pagingSource()},)}
}
在这里,我们向 Pager 的构造函数提供了三个要素。首先,我们设置了所需的页面大小的 PagingConfig,正如我之前提到的。其次,我们提供了我们的远程中介器实例。第三,我们将由 Room 提供的分页源设置为 Pager 的唯一数据源。
仓库(Repository)
由于我们在远程中介器中完成了大部分工作,所以我们的仓库实现将相当简单。
class PokemonRepositoryImpl @Inject constructor(private val pokemonPager: Pager<Int, PokemonEntity>
) : PokemonRepository {override fun getPokemonList(): Flow<PagingData<Pokemon>> {return pokemonPager.flow.map { pagingData ->pagingData.map { it.toPokemon() }}}
}
使用我们的 Pager 实例,我们只需将其 PagingData 流返回给使用者。但在这之前,我们还需要将 PokemonEntity 映射到领域的 Pokemon 模型。这是因为根据 Clean Architecture 的基础,我们的领域层不了解数据或表示层,因此不应将数据模型传递到领域层。
领域层(Domain Layer)
在这个纯 Kotlin 层中,实际上没有太多事情发生。在这里,我们有我们的 Pokemon 模型、仓库接口以及与该仓库交互的简单用例类。
// REPOSITORY INTERFACE
interface PokemonRepository {fun getPokemonList(): Flow<PagingData<Pokemon>>
}// USE CASE
class GetPokemonList @Inject constructor(private val pokemonRepository: PokemonRepository
) {operator fun invoke(): Flow<PagingData<Pokemon>> {return pokemonRepository.getPokemonList().flowOn(Dispatchers.IO)}
}// MODEL
data class Pokemon(val id: Int,val name: String,val imageUrl: String,
)
在这里,你可能会有一个问题,即如何在纯 Kotlin 层中使用PagingData,而在这里我们没有依赖于任何 Android 组件。实际上很简单:分页库为非 Android 模块提供了特定的依赖项,因此我们可以访问所有简单的 Paging 组件,如 PagingSource、PagingData、Pager,甚至是 RemoteMediator。
dependencies {// ...implementation "androidx.paging:paging-common:$paging_version"
}
表示层(Presentation Layer)
在快速涵盖了领域层之后,让我们直接跳入表示层,其中的关键内容都在这里。但首先,我们需要将以下 Paging 依赖项添加到我们的 build.gradle 文件中:
dependencies {// ...implementation "androidx.paging:paging-runtime-ktx:$paging_version"implementation "androidx.paging:paging-compose:$paging_version"
}
除了 runtime-ktx 依赖项之外,这里还需要 compose 依赖项,因为它在我们的分页数据流和 UI 之间提供了一些中间件。
ViewModel
这又是本文中的一个简单类,在这里我们只需获取由用例提供的流(该流已由仓库提供),并将其存储在一个值中。
@HiltViewModel
class PokemonListViewModel @Inject constructor(private val getPokemonList: GetPokemonList
) : ViewModel() {val pokemonPagingDataFlow: Flow<PagingData<Pokemon>> = getPokemonList().cachedIn(viewModelScope)
}
我们通过调用cachedIn(viewModelScope)来存储该流,以便在 ViewModel 的生命周期内保持其活动状态。此外,它还可以在屏幕旋转等配置更改时保持存活,这样你就可以获取相同的现有数据,而不必从头开始获取。
这种方法还可以保持我们的冷流状态不变,并且不会像 stateIn(…) 方法一样将其转换为热流(StateFlow)。这意味着如果流未被收集,就不会执行不必要的代码。
屏幕(UI)
现在,我们来到了分页的最后一步,在这一步中,我们将在LazyColumn中显示我们的分页项。在 Jetpack Compose 中,不再有 RecyclerView 或适配器。所有这些都在下面进行处理,而且我们大量的项目仍然可以智能布局,而不会引起任何性能问题。
@Composable
fun PokemonListScreen(snackbarHostState: SnackbarHostState
) {val viewModel = hiltViewModel<PokemonListViewModel>()val pokemonPagingItems = viewModel.pokemonPagingDataFlow.collectAsLazyPagingItems()if (pokemonPagingItems.loadState.refresh is LoadState.Error) {LaunchedEffect(key1 = snackbarHostState) {snackbarHostState.showSnackbar((pokemonPagingItems.loadState.refresh as LoadState.Error).error.message ?: "")}}Box(modifier = Modifier.fillMaxSize()) {if (pokemonPagingItems.loadState.refresh is LoadState.Loading) {CircularProgressIndicator(modifier = Modifier.align(Alignment.Center))} else {LazyColumn(modifier = Modifier.fillMaxSize(),horizontalAlignment = Alignment.CenterHorizontally,) {items(count = pokemonPagingItems.itemCount,key = pokemonPagingItems.itemKey { it.id },) { index ->val pokemon = pokemonPagingItems[index]if (pokemon != null) {PokemonItem(pokemon,modifier = Modifier.fillMaxWidth(),)}}item {if (pokemonPagingItems.loadState.append is LoadState.Loading) {CircularProgressIndicator(modifier = Modifier.padding(16.dp))}}}}}
}
在我们的组合屏幕中,首先要做的是创建我们的 ViewModel 实例,并使用辅助函数 collectAsLazyPagingItems() 收集其中存储的分页数据流。这将冷流转换为 LazyPagingItems 实例。通过这个实例,我们可以访问已加载的项目,以及不同的加载状态,以相应地改变 UI。除此之外,我们甚至可以使用此实例触发数据刷新或重新尝试以前失败的加载。
在 Box 布局中,如果 LazyPagingItems 的“refresh”加载状态为 Loading,则我们知道我们正在初始加载,并且尚无项目可显示。因此,我们显示一个进度指示器。否则,我们会显示一个 LazyColumn,以及使用我们的 LazyPagingItems 实例设置的项目列表的数量和键参数。在每个项目中,我们只需使用给定的索引访问相应的 Pokemon 对象,并呈现 PokemonItem 组合,出于简单起见,这里不给出实现细节。
我们还有一种特殊情况,即需要在这些项目下方显示加载指示器。这发生在我们正在获取更多数据的过程中,可以通过 LazyPagingItems 的“append”加载状态来检测到。因此,如果是这种情况,我们将一个进度指示器追加到列表的末尾。
最后,请不要认为我们在开始部分忽略了LaunchedEffect部分。LaunchedEffect 组合用于在组合内部安全地调用挂起函数。在 Jetpack Compose 中,我们需要协程范围来显示 Snackbar,因为 SnackbarHostState.showSnackbar(…) 是一个挂起函数。在这里,我们显示一个 Snackbar 消息,以防刷新错误,基本上对应于我们的情况下的“初始加载”错误。然而,正如我之前提到的,我们在这里构建了一个离线优先的应用,因此如果我们在 Room 中已经缓存了数据,用户将看到该数据,以及错误消息。
希望您在 Android Jetpack Compose 中的分页和缓存的这段具有挑战性的旅程中能够与我同行。我尽力坚持最新和推荐的操作方式。请随时指出错误或可以做得更好的地方。整个项目已经作为 GitHub 存储库共享,以便您可以下载并进行测试。
GitHub
https://github.com/thunderbolt-codes/Pokemon-Pager
相关文章:
Android Jetpack Compose 中的分页与缓存展示
Android Jetpack Compose 中的分页与缓存展示 在几乎任何类型的移动项目中,移动开发人员在某个时候都会处理分页数据。如果数据列表太大,无法一次从服务器检索完毕,这就是必需的。因此,我们的后端同事为我们提供了一个端点&#…...
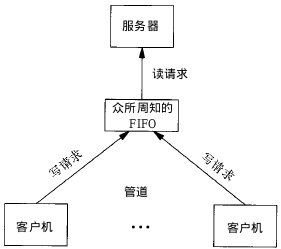
无名管道 / 有名管道(FIFO)
根据上节所讲就可以了解到:管道其实就是实现进程间通讯IPC中的一种类型方法 基本概念(无名管道) 管道是一种最基本的IPC机制,通常指无名管道,也是UNIX系统IPC最古老的形式。管道只能作用于有血缘关系的进程之间&…...

Three.js纹理贴图
目录 Three.js入门 Three.js光源 Three.js阴影 Three.js纹理贴图 纹理是一种图像或图像数据,用于为物体的材质提供颜色、纹理、法线、位移等信息,从而实现更加逼真的渲染结果。 纹理可以应用于Three.js中的材质类型,如MeshBasicMaterial…...

1+X Web前端开发职业技能等级证书建设方案
一 、系统概述 1X Web前端开发技术是计算机类专业重要的核心课程,课程所包含的教学内容多,实践性强,并且相关技术更新快。传统的课堂讲授模式以教师为中心,学生被动式接收,难以调动学生学习的积极性和主动性。混合式教…...

Rx.NET in Action 第二章学习笔记
2 Hello, Rx 本章节涵盖的内容: 不使用Rx的工作方式向项目中添加Rx创建你的第一个Rx应用程序 Rx 的目标是协调和统筹来自社交网络、传感器、用户界面事件等不同来源的基于事件的异步计算。例如,建筑物周围的监控摄像头和移动传感器会在有人靠近建筑物时触发…...

【软件工程 | 模块耦合】什么是模块耦合及分类
概念 耦合(coupling)是对两个模块之间联接程度的一种度量。模块间的依赖程度越大,则其耦合程度也就越大; 反之,模块间的依赖程度越小,则其耦合程度也就越小。 很显然,为了使软件具有较好的可维护性和可修改性…...

OCT介绍和分类
前言:研究方向和OCT有关,为了方便以后回顾,所以整理了OCT相关的一些内容。 OCT介绍和分类 OCT介绍分类时域OCT频域OCT扫频OCT谱域OCT OCT介绍 名称:OCT、光学相干层析成像术、Optical Coherence Tomography。 概念:O…...
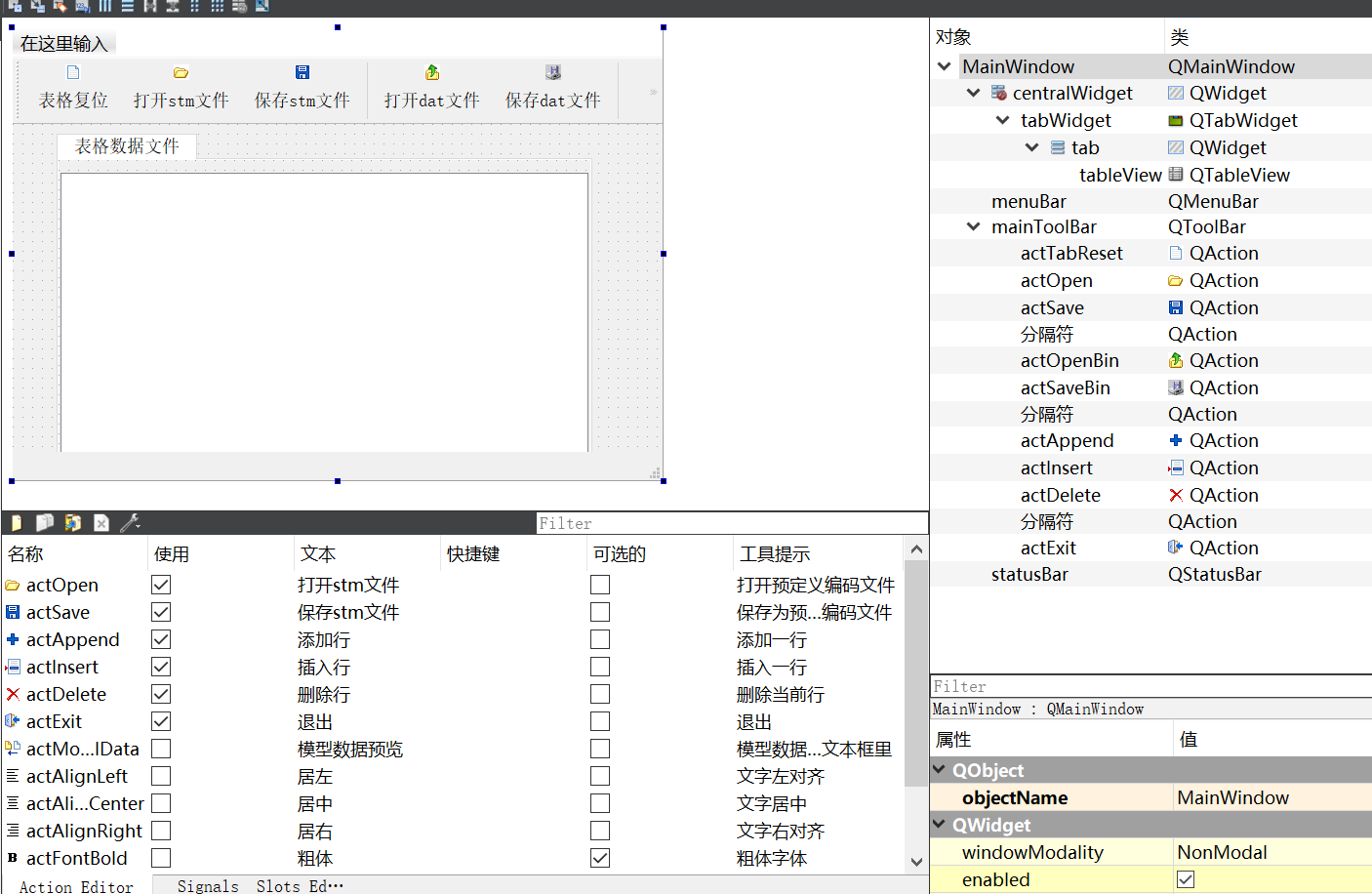
07-2_Qt 5.9 C++开发指南_二进制文件读写(stm和dat格式)
文章目录 1. 实例功能概述2. Qt预定义编码文件的读写2.1 保存为stm文件2.2 stm文件格式2.3 读取stm文件 3. 标准编码文件的读写3.1 保存为dat文件3.2 dat文件格式3.3 读取dat文件 4. 框架及源码4.1 可视化UI设计4.2 mainwindow.cpp 1. 实例功能概述 除了文本文件之外ÿ…...
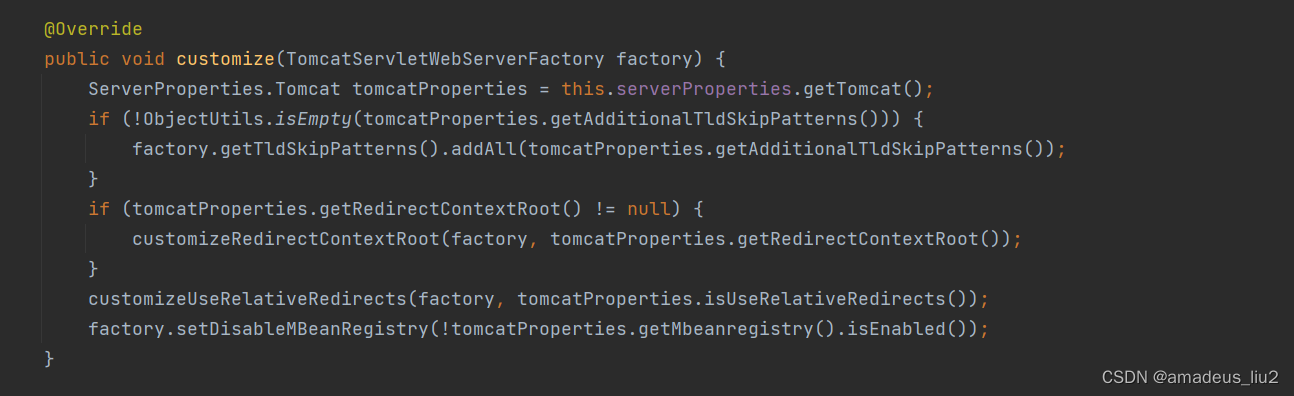
SpringBoot复习:(41)配置文件中配置的server开头的属性是怎么配置到Servlet容器中起作用的?
ServletWebServerFactoryAutoConfiguration类: 可以看到其中使用了EnableConfigurationProperties导入了ServerProperties 而ServerProperties通过使用ConfigurationProperties注解导入了配置文件中已server开头的那些配置项。 可以看到ServletWebServerFactory定…...

深入解读网络协议:原理与重要概念
目录 TCP/IP协议 IP地址 子网掩码 DNS 网关 网络端口 TCP/IP协议 TCP/IP是互联网通信的基础协议。它由两个部分组成:TCP负责数据的可靠传输,确保数据按序到达目标;IP负责寻址和路由,确保数据在网络中正确传递。TCP/IP协议簇…...

O型圈不同类型的应用指南
O型圈因其优异的密封性能而广泛应用于各个行业和应用。它们简单、经济高效且密封可靠,下面我们了解一下适合每种应用的特定类型的O型圈。 1、汽车行业 在汽车行业中,O型圈在密封发动机部件和防止机油或冷却剂泄漏方面发挥着至关重要的作用。常见应用包…...

Mysql 搭建MHA高可用架构,实现自动failover,完成主从切换
目录 自动failover MHA: MHA 服务 项目:搭建Mysql主从复制、MHA高可用架构 实验项目IP地址配置: MHA下载地址 项目步骤: 一、修改主机名 二、编写一键安装mha node脚本和一键安装mha mangaer脚本,并执行安装…...

Python:列表、元组、集合、字典,数据类型之间的 5 个差异
Python:列表、元组、集合、字典,数据类型之间的 5 个差异 1. 相同点2. 不同点2.1 排序2.2 索引2.3 可变性2.5 允许的类型2.4 允许重复 源码 这篇博客将介绍列表、元组、集合、字典(lists, tuples, sets, and dictionaries)数据类型…...
)
redis学习笔记(四)
文章目录 list(数组)(1)添加子成员(2)基于索引获取列表成员(3)获取列表的切片(4)获取列表的长度(5)按索引设置值(6&#x…...

-L和-rpath-link和-rpath
知识点 现代连接器在处理动态库时将链接时路径(Link-time path)和运行时路径(Run-time path)分开,用户可以通过-L指定连接时库的路径,通过-R(或-rpath)指定程序运行时库的路径,大大提…...
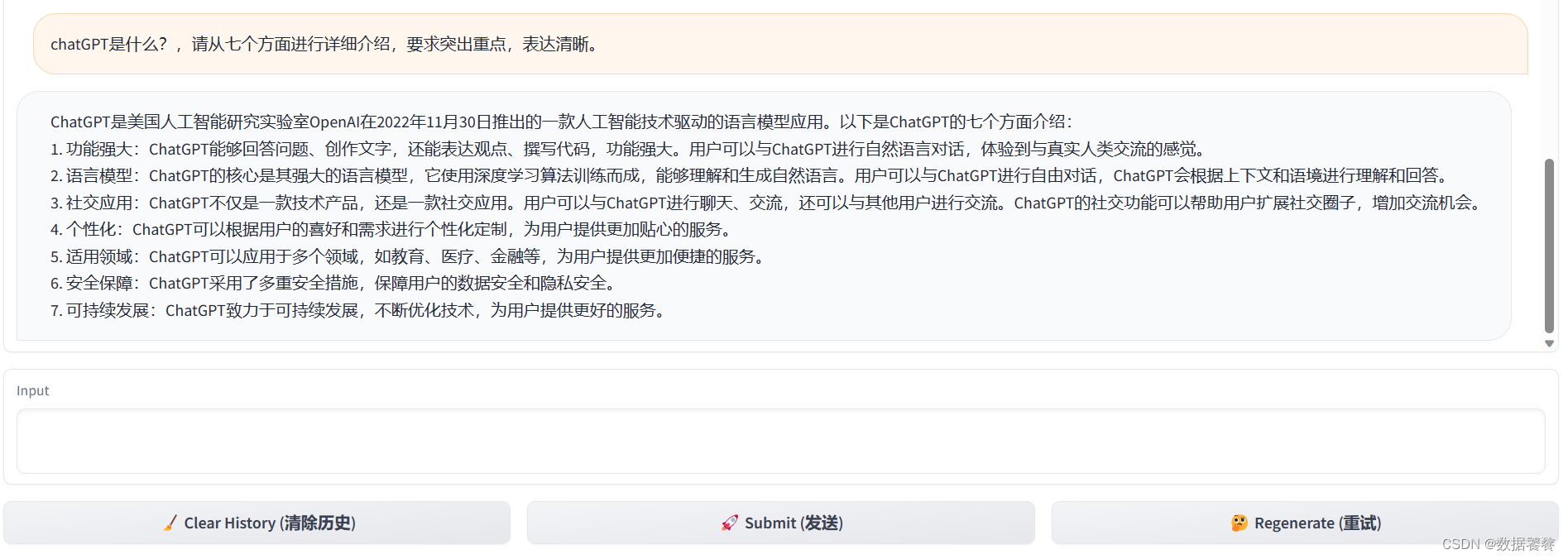
chatGPT小白快速入门培训课程-001
一、前言 本文是《chatGPT小白快速入门培训课程》的第001篇文章,全部内容采用chatGPT和chatGPT开源平替软件生成。完整内容大纲详见:《chatGPT小白快速入门课程大纲》。 本系列文章,参与: AIGC征文活动 #AIGC技术创作内容征文# …...

【Linux操作系统】深入理解Linux系统编程中的传入参数、传出参数和传入传出参数
在Linux系统编程中,函数的参数扮演着至关重要的角色。参数的传递方式可以分为传入参数、传出参数和传入传出参数。本文将详细解释这三种参数的概念、特点以及如何使用它们来实现灵活和高效的函数调用和数据传递。 文章目录 1. 解释和举例1.1 传入参数(i…...
结构型模式:3、过滤器模式(Filter、Criteria Pattern)(C++示例)设计模式)
(二)结构型模式:3、过滤器模式(Filter、Criteria Pattern)(C++示例)设计模式
目录 1、过滤器模式(Filter、Criteria Pattern)含义 2、过滤器模式应用场景 3、过滤器模式主要几个关键角色 4、C实现过滤器模式的示例 1、过滤器模式(Filter、Criteria Pattern)含义 (1)过滤器模式是…...
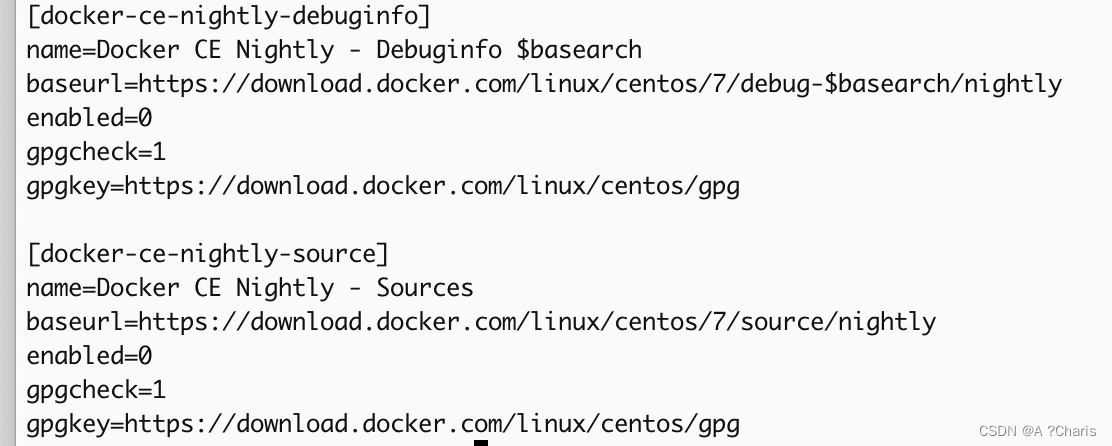
欧拉OS 使用 CentOS 7 yum repo
一、下载CentOS的repo的yum文件 任何基于CentOS的yum的repo 的url是这样的: 但欧拉OS输出这个变量为:openEuler 20.03 (LTS-SP3) 那明显欧拉想要使用这个yum的url找不到这个版本, 所以直接讲这个变量替换为 7, Centos 7的7 然后执行&…...

C进阶(1/7)——数据在内存中的存储
目录 前言: 一.数据类型介绍 类型基本归类: 整型家族: 浮点数家族: 构造类型: 指针类型: 空类型: 二.整型在内存中的存储 1.原码,反码,补码 2.大小端介绍 3.练…...

番茄小说下载器终极指南:三步构建你的离线阅读自由王国
番茄小说下载器终极指南:三步构建你的离线阅读自由王国 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾在地铁里读到精彩章节时突然断网?是否在…...

3步深度解锁:网络设备权限管理工具的实战手册
3步深度解锁:网络设备权限管理工具的实战手册 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否曾面对功能受限的网络设备感到束手无策?当默认配置锁死了硬…...

Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南
Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout…...

3分钟快速安装BetterNCM插件管理器,让你的网易云音乐功能翻倍
3分钟快速安装BetterNCM插件管理器,让你的网易云音乐功能翻倍 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 还在为网易云音乐功能单一而烦恼吗?想要解锁更多个…...

基于Atmega 1284P的16位复古计算器:硬件设计与软件实现全解析
1. 项目概述与核心思路最近在整理工作室时,翻出了一堆老旧的7段数码管和矩阵键盘,看着这些充满复古气息的元件,一个想法冒了出来:为什么不自己动手做一台复古风格的计算器呢?不是那种用液晶屏显示的现代计算器…...

【C++】零基础入门 · 第 6 节:数组
上一节我们学习了函数,知道了如何把代码封装起来方便复用。但在实际编程中,你很快就会遇到一个问题:如果要存储 100 个学生的成绩,难道要定义 100 个变量吗?这显然不现实。数组就是 C++ 给出的答案——它让我们能用一个变量名管理一组相同类型的数据。 1. 为什么需要数组…...

ThingLinks-IoT:一站式物联网平台解决方案
ThingLinks-IoT 物联网平台 | 多协议接入物模型告警联动视频接入AI 助手 一体化方案 一个面向项目交付与企业生产场景的国产物联网中台——把"设备接入 → 数据处理 → 告警联动 → 业务集成"这条链路上的通用能力一次性做完做稳,让你只关心自己的业务。 …...

无声输入革命:如何用Chaplin在5分钟内构建本地唇语识别系统
无声输入革命:如何用Chaplin在5分钟内构建本地唇语识别系统 【免费下载链接】chaplin A real-time silent speech recognition tool. 项目地址: https://gitcode.com/gh_mirrors/chapl/chaplin 在嘈杂的办公室、安静的图书馆,或是需要绝对隐私的医…...

QKeyMapper完整指南:Windows上最强大的免费按键映射解决方案
QKeyMapper完整指南:Windows上最强大的免费按键映射解决方案 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支持游戏手柄映射到键鼠&…...

MFCC与可解释机器学习:构建可解释的L2发音AI诊断系统
1. 项目概述:当语音技术遇见二语教学 作为一名在语音技术和教育技术交叉领域摸爬滚打了十多年的从业者,我常常思考一个问题:我们能用算法“听”出一个人说外语时,他的母语口音吗?更进一步,我们能否不仅“听…...