【数据结构】八大排序详解
🚀 作者简介:一名在后端领域学习,并渴望能够学有所成的追梦人。
🐌 个人主页:蜗牛牛啊
🔥 系列专栏:🛹数据结构、🛴C++
📕 学习格言:博观而约取,厚积而薄发
🌹 欢迎进来的小伙伴,如果小伙伴们在学习的过程中,发现有需要纠正的地方,烦请指正,希望能够与诸君一同成长! 🌹
文章目录
- 插入排序
- 直接插入排序
- 希尔排序
- 选择排序
- 直接选择排序
- 堆排序
- 交换排序
- 冒泡排序
- 快速排序
- 递归实现快排
- hoare版本
- 挖坑法
- 前后指针法
- 非递归实现快排
- 归并排序
- 递归实现
- 非递归实现
- 计数排序
- 排序算法复杂度及稳定性分析
排序的相关概念
排序就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。
稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前(相同的数据,保证排序前后它们的相对位置不变),则称这种排序算法是稳定的;否则称为不稳定的。
内部排序:数据元素全部放在内存中的排序。
外部排序:数据元素太多不能同时放在内存中,根据排序过程的要求不能在内外存之间移动数据的排序。
插入排序
直接插入排序
直接插入排序是一种简单的插入排序法,其基本思想是:把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列。
如当我们向一个有序序列中插入元素时,可能有下面几种情况:

单次插入数据的代码如下:
int end = n - 1;//n - 1为插入数据的前一个位置的下标
int tmp = a[end + 1];//tmp就是插入数据
//循环找到比tmp小的数据
while (end >= 0)
{if (a[end] > tmp){a[end + 1] = a[end];--end;}else{break;}
}
//将end + 1位置值覆盖为tmp
a[end + 1] = tmp;
对数组中元素进行排序,我们可以理解为end是从数组下标为0的位置开始的,tmp = a[end + 1]便是插入的数据:
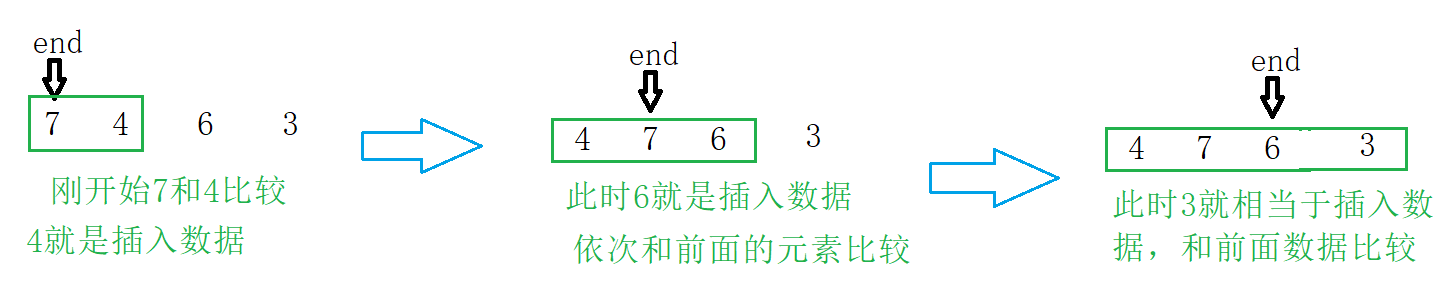
在单次插入数据的外面加上一层for循环来控制即可:
代码(排升序):
//直接插入排序
void InsertSort(int* a, int n)
{//将数组从第一个位置开始排序//注意这里的循环条件是for (int i = 0; i < n - 1; i++){int end = i;int tmp = a[end + 1];//记录下一个位置的元素while (end >= 0)//循环条件{if (a[end] > tmp){a[end + 1] = a[end];--end;}else{break;}}//将tmp的值放到合适位置a[end + 1] = tmp;}
}
注意:for循环中的判断条件为i < n - 1,因为如果判断条件为i < n时,访问下标end所在的位置时,虽然没有问题,但是tmp = a[end + 1],访问end+ 1下标时将会发生越界访问问题。

直接插入排序特性总结:
-
时间复杂度:最坏情况是逆序,每次都要遍历到while循环结束,将数据插入到下标为0的位置,此时每个单趟排序的时间复杂度为end,一共要挪动的次数为1 + 2 + 3 + 4 + ……+ (n - 1) ,所以最坏情况下时间复杂度为O(N2);最好情况就是每次插入的数据都能保证数组有序,时间复杂度为O(N)。
-
空间复杂度:不需要开辟额外的空间,所以空间复杂度为O(1)。
-
通过上面时间复杂度可以知道:元素集合越接近有序,直接插入排序算法的时间效率越高
当数据完全有序时,直接插入排序就是O(N),只需比较N次,不需要交换
- 直接插入排序是一种具有稳定性的排序算法(当有两个相同的数据时,可以保证它们之间的相对顺序不变)。
希尔排序
希尔排序也可以叫做缩小增量排序,我们通过上面对直接插入排序的特性总结可以知道元素集合越接近有序,直接插入排序算法的时间效率越高,希尔排序就是对直接插入排序的优化。
希尔排序的算法思想:
1、先对初始数据进行预排序;
2、对预排序之后的数据再进行直接插入排序
通过上述两步进行排序就会比直接对原始数据进行直接插入排序的效率高,从而达到优化的效果。
预排序就是选定一个gap作为间距,将要排序的数据分为gap组,先分别对每组数据进行直接插入排序,再缩小gap值并再次对每组数据进行排序。然后当gap == 1时对预排序之后的数据再进行直接插入排序就完成整体数据的排序了。

我们先对上面的数据进行一次预排序,代码实现:
void ShellSort(int* a, int n)
{//假设gap为3int gap = 3;//将gap组数据都排好序for (int i = 0; i < gap; i++){//将本组数据排好序for (int j = i; j < n - gap; j = j + gap){int end = j;int tmp = a[end + gap];while (end >= 0){if (a[end] > tmp){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}
}
代码运行结果:

实现过程:
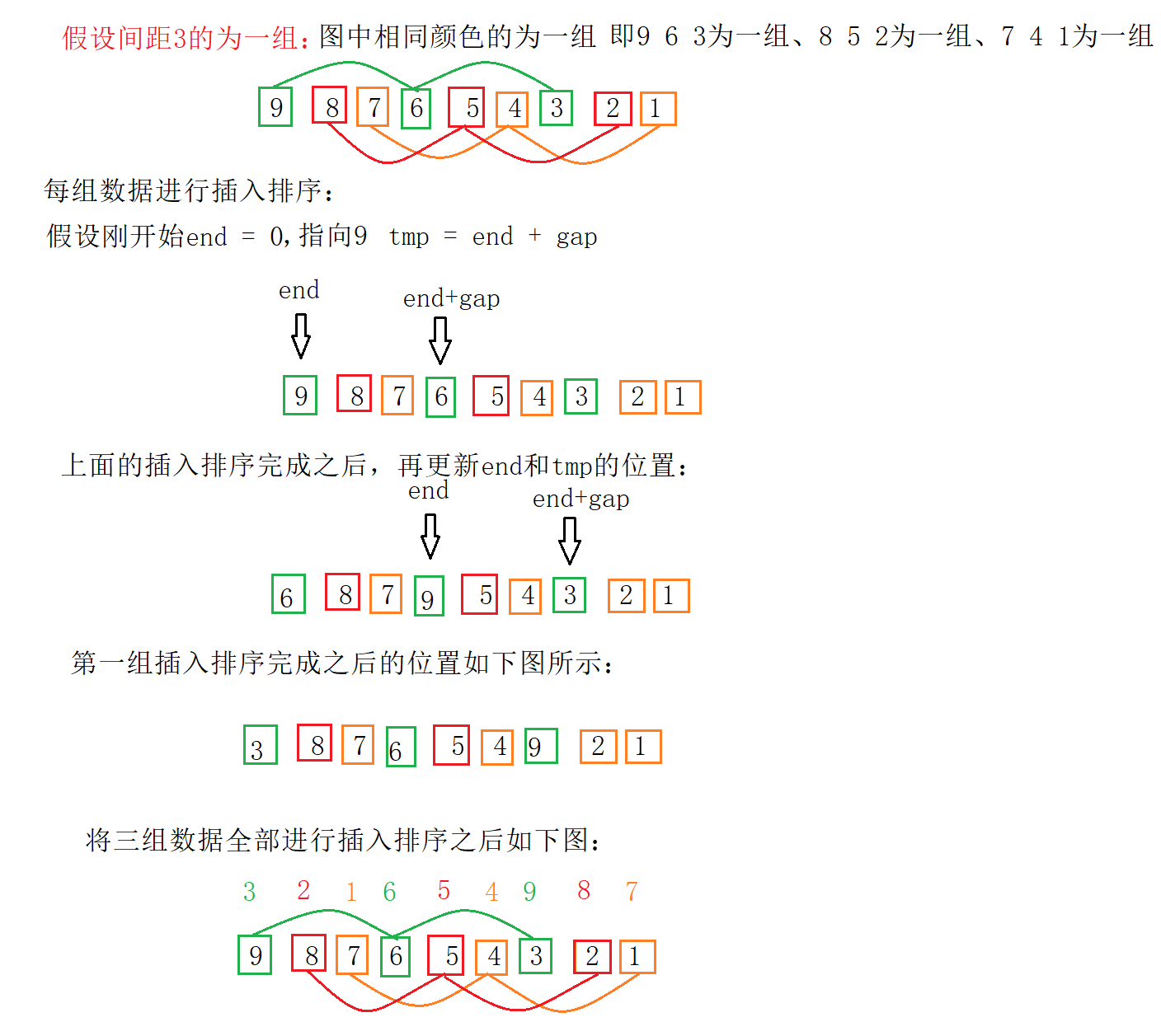
所以此次预排序的起始和最后结果为:
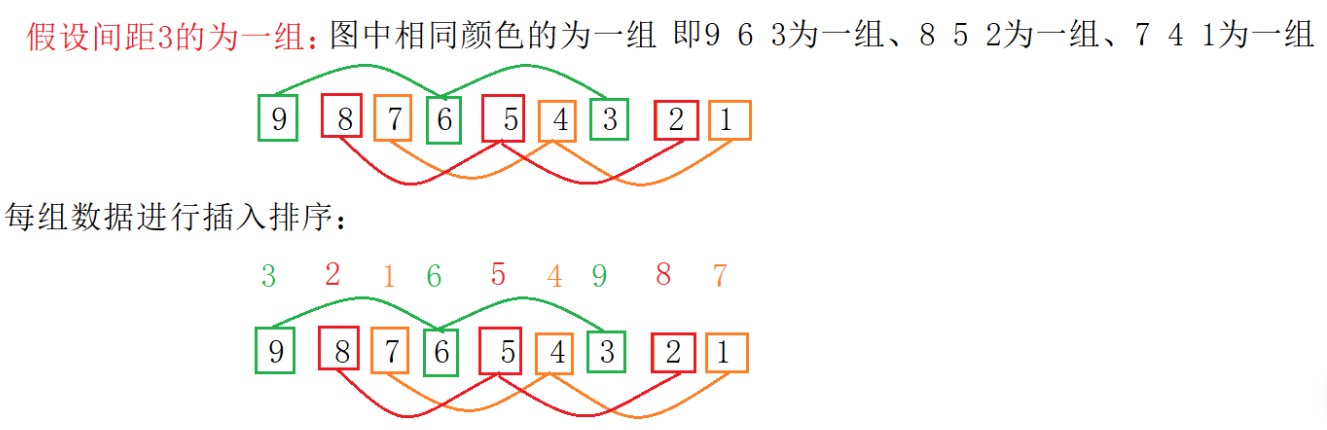
上面的单次预排序和直接插入排序很像,如果gap等于1就是直接插入排序了。直接插入排序在for循环中的条件为i < n- 1; i++,而这次预排序在循环中的条件是i = n - gap; i += gap。
上面的程序中,假设数据个数为N,有gap组,每组有N/gap个数据,每组最坏情况下挪动次数:1+2+3+……+gap/n(和直接插入有点类似),所以时间复杂度最坏的情况:(1 + 2+ 3 + …… +gap/n) gap(乘以gap因为有gap组)。*
对于上面的代码我们可以简化使其具有相同的效果:
void ShellSort(int* a, int n)
{//假设gap为3int gap = 3;for (int j = 0; j < n - gap; ++j){int end = j;int tmp = a[end + gap];while (end >= 0){if (a[end] > tmp){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}
}

当gap大于1的时候是预排序,但是当gap等于1的时候就是直接插入排序。
思考:当数据个数N = 100000时,如果gap还是等于3是否合适?肯定是不合适的,所以我们可以改变gap的值,因为预排序可以走很多次,只要最后一次gap == 1便能实现数据有序,所以我们可以改变gap的值,有多种写法:
void ShellSort(int* a, int n)
{int gap = n;while (gap > 1){//保证最后一次gap等于1,进行预排序之后的插入排序//gap = gap / 2;//假设gap为3gap = gap / 3 + 1;//一定要加1保证最后结果为1,除2一定能保证gap大于1时结果为1,但是除3//不能,gap = 2 时除3等于0,所以要加1//int gap = 3;for (int j = 0; j < n - gap; ++j){int end = j;int tmp = a[end + gap];while (end >= 0){if (a[end] > tmp){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}
}

预排序(以升序为例):
1、gap越大,大的数可以更快到后面,小的可以更快到前面;但是gap越大越不接近有序。
2、gap越小,数据跳动越慢,但是越接近有序。
希尔排序的时间复杂度:
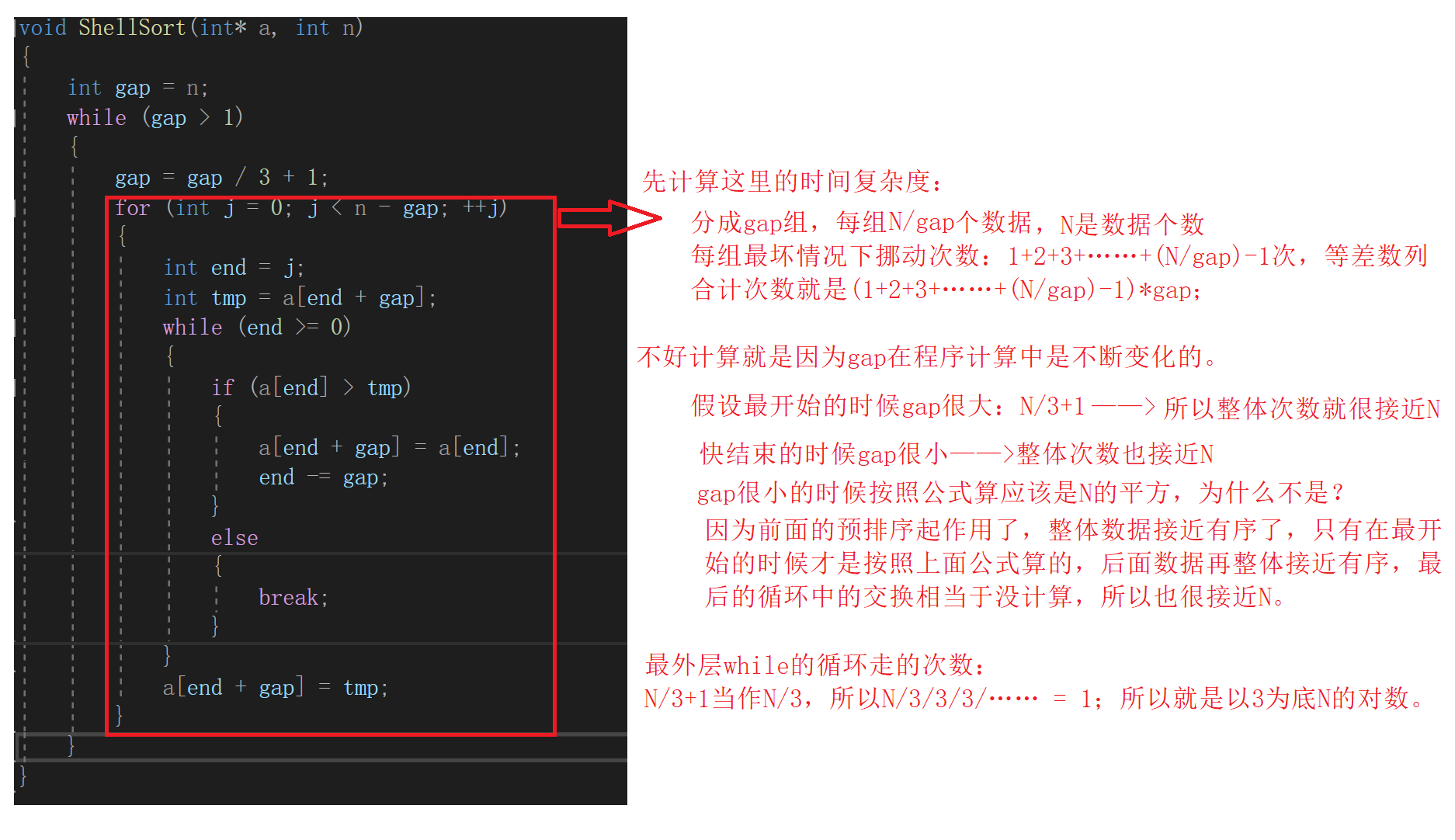
希尔排序的时间复杂度并不好计算,我们可以记一个结论:希尔排序的时间复杂度为O(N1.3)。
对比直接插入排序和希尔排序的性能:
clock()函数获取的是毫秒。
void TestOp()
{srand(time(0));const int N = 10000;int* a1 = (int*)malloc(sizeof(int) * N);int* a2 = (int*)malloc(sizeof(int) * N);for (int i = 0; i < N; i++){a1[i] = rand();a2[i] = a1[i];}//直接插入排序int begin1 = clock();InsertSort(a1, N);int end1 = clock();//希尔排序int begin2 = clock();ShellSort(a2, N);int end2 = clock();printf("InsertSort:%d\n", end1 - begin1);printf("ShellSort:%d\n", end2 - begin2);
}
运行结果:
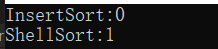
要注意C语言的rand()函数有一定的局限性,随机数最多只能产生3万多个,我们可以通过+i的方式让随机数不那么重复。
希尔排序特性总结:
-
希尔排序是对直接插入排序的优化。
-
当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序。这样整体而言,可以达到优化的效果。
-
希尔排序的时间复杂度不好计算,我们可以记一个结论:希尔排序的时间复杂度为O(N1.3)。
-
**稳定性:不稳定。**因为可能将相同的数据分到不同组中,可能导致排完之后相对顺序就发生改变。
选择排序
选择排序的基本思想:每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完 。
直接选择排序
直接选择排序就是在一组数据中通过遍历找到最小的数据,然后放到数组的前边(未更新数据的位置),并且重复遍历查找交换,直到全部数据排完。

(升序为例)代码实现:
//直接选择排序
void OptionSort(int* a, int n)
{int begin = 0;//确保遍历完全部数据while (begin < n){int min = begin;//记录最小元素的下标//找到最小的元素for (int i = begin; i < n; i++){if (a[min] > a[i]){min = i;//更新min下标,使其是较小元素的下标}}Swap(&a[min], &a[begin]);//交换begin++;//从下一个位置开始遍历}
}
上述代码在最坏情况下,第一次要比较N-1次,第二次要比较N-2次……最后一次比较一次,所以最坏情况下的时间复杂度为O(N2),空间复杂度为O(1)。
上述思路可以优化:每趟遍历的时候找到最大值和最小值的位置,然后把最大值放在该序列的尾部,最小值放在该序列的头部。这样可以使排序的效率提升一倍。
//直接选择排序
void OptionSort(int* a, int n)
{int left = 0;//第一个元素的下标int right = n - 1;//最后一个元素的下标while (left < right){int min = left;//记录最小元素的下标int max = right;//记录最大元素的下标//找到最小的元素和最大的元素for (int i = left; i <= right; i++){if (a[min] > a[i]){min = i;//更新min下标,使其是较小元素的下标}if (a[max] < a[i]){max = i;//更新max下标,使其是较大元素的下标}}Swap(&a[min], &a[left]);//交换Swap(&a[max], &a[right]);left++;//从下一个位置开始遍历right--;}
}
我们拿数组{ 9,8,7,6,5,4,3,2,1}测试之后打印结果为:

这组测试和我们想要的目标序列不一样,这是因为存在一种特殊情况:当我们找到最大的元素和最小的元素之后,我们先把最小值交换到下标为begin的位置,如果当max下标的位置刚好是begin位置,最小值交换之后max指向的就是最小值,这时才进行交换结果肯定不正确,所以我们要加一个判断,如果刚好max下标是begin位置,交换之后最大值就到min下标的位置了,所以要让max = min。
//当left和max下标相同,防止最大值被最小值交换,让max下标等于min
if (left == max)
{max = min;
}
经过修改后的完整代码为:
//直接选择排序
void OptionSort(int* a, int n)
{int left = 0;//第一个元素的下标int right = n - 1;//最后一个元素的下标while (left < right){int min = left;//记录最小元素的下标int max = right;//记录最大元素的下标//找到最小的元素和最大的元素for (int i = left; i <= right; i++){if (a[min] > a[i]){min = i;//更新min下标,使其是较小元素的下标}if (a[max] < a[i]){max = i;//更新max下标,使其是较大元素的下标}}Swap(&a[min], &a[left]);//交换//当left和max下标相同,防止最大值被最小值交换,让max下标等于minif (left == max){max = min;}Swap(&a[max], &a[right]);left++;//从下一个位置开始遍历right--;}
}
测试结果:

直接选择排序特性总结:
- 直接选择排序容易理解,但是效率不是很好,在实际中很少使用。
- 时间复杂度:O(N2)
- 空间复杂度:O(1)
- 稳定性:不稳定
堆排序
对于堆排序,我们要先熟悉向下调整算法和建堆。向下调整算法有一个前提:左右子树必须是一个堆,才能调整。(若想将其调整为小堆,那么根结点的左右子树必须都为小堆;若想将其调整为大堆,那么根结点的左右子树必须都为大堆。)
向下调整法的基本思想(以小堆为例):
从根结点处开始,选出左右孩子中值较小的孩子,让值较小的孩子与其父亲进行比较:
如果孩子比父亲节点值小,则该孩子与父亲节点进行交换,并将原来孩子节点的位置当作父结点继续向下进行调整,直到调整完成;
如果孩子比父亲节点值大,就不需要处理了,说明此时调整完成,该树已经是小堆了。
以小堆为例:
int array[] = {27,15,19,18,28,34,65,49,25,37};
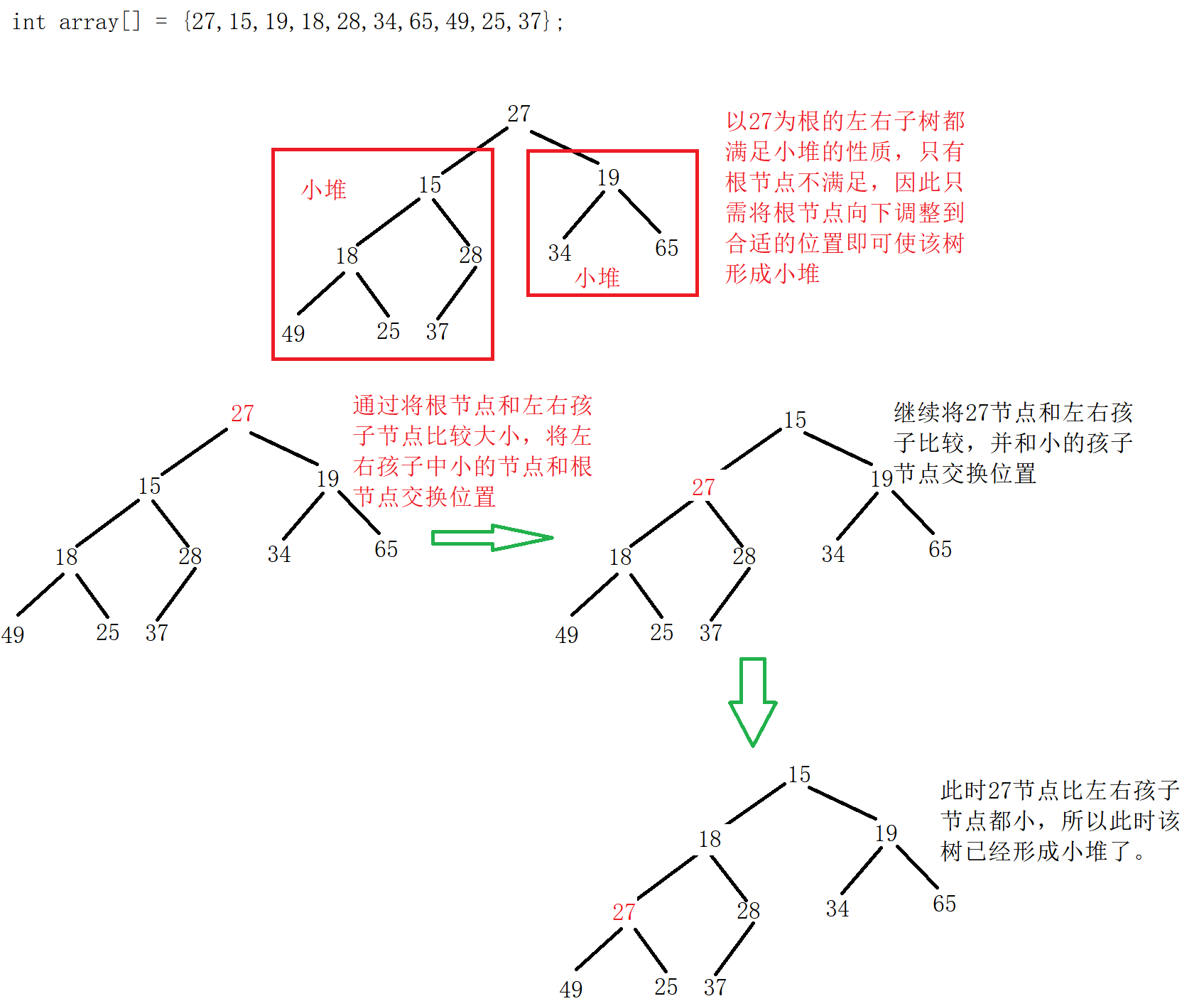
向下调整法的代码如下(以小堆为例):
//交换函数
void Swap(HPDataType* x, HPDataType* y)
{HPDataType tmp = *x;*x = *y;*y = tmp;
}
//堆的向下调整(小堆)
void AdjustDown(HPDataType* a, int n, int parent)
{int child = (parent * 2) + 1;//求出左孩子节点while (child < n){if (child + 1 < n && a[child] > a[child + 1])//找出孩子节点中较小的{child++;}//当父结点大小孩子节点时,交换位置并更新父结点和子节点if (a[parent] > a[child]){Swap(&a[parent], &a[child]);//交换parent = child;child = (parent * 2) + 1;}//堆已经形成else{break;}}
}
使用堆向下调整算法,最坏情况下(一直需要交换节点),假设树的高度为h,那么需要交换的次数为h - 1;假设该树的节点个数为N,那么h = log2(N+1)(按照满二叉树计算),所以可以得出堆的向下调整算法的时间复杂度为:O(log2N)。
使用堆的向下调整算法需要满足其根结点的左右子树均为大堆或是小堆,那么如何将一个树调整为堆呢?
可以从倒数第一个非叶子节点开始进行向下调整,并且从该节点开始向前依次进行向下调整:第一个非叶子节点也就是最后一个叶子节点的父结点,假设节点个数为n,则最后一个叶子节点下标为n-1,由child = (parent * 2) + 1,可得其父结点的下标为(n-1 -1)/2;

代码(以小堆为例):
//建堆
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{AdjustDown(php->a, php->size, i);
}
建堆的时间复杂度:
因为堆是完全二叉树,而满二叉树也是完全二叉树,此处为了简化使用满二叉树来证明(时间复杂度本来看的就是近似值,多几个节点不影响最终结果) :

由上图计算建堆过程中总的调整次数:T(n) = 1 * (h - 1) + 2 * (h - 2) + ……+2h-2 * 1;再通过错位相减法最后求得:T(n) = 1- h + 21 + 22 +
…… + 2h-1,等比数列求和得:T(n) = 2h - h - 1,设N是满二叉树的节点个数,由 N = 2h - 1和h = log2(N + 1)可以求出T(n) = N - log2(N+1),则建堆的时间复杂度为O(N)。
总结:
堆的向下调整法的时间复杂度:O(logN)
建堆的时间复杂度:O(N)。
在进行堆排序之前,需要满足给定数据的数据结构必须是堆,建堆有两种方式,分别为向上调整建堆和向下调整建堆。
向下调整建堆的时间复杂度为O(N),再次分析我们会发现向上调整建堆的时间复杂度为O(N * logN),所以向下调整建堆更好。
如果我们想利用堆排序做到升序,选择建大堆还是小堆呢?
如果建小堆,最小的数即堆顶,每次都要将堆顶的数据固定,再处理其他的数据时还要重新建堆,这样太麻烦;要么就是将堆顶数据放入新开辟的空间中,然后再找次小的,依次向后,但是这样要开辟新的空间。
如果建大堆,堆顶的数据是最大的,每次将堆顶的数据和最后一个数据交换,这样最大的数就放到了最后,然后只处理前N-1个数据,把堆顶数据向下调整,调整之后堆顶数据就是次大的数据,将其和第N-1个数交换,再去处理前N-2个数据这样依次处理,最终就可以实现升序。
堆排序即利用堆的思想来进行排序,总共分为两个步骤:
1、建堆
- 升序:建大堆
- 降序:建小堆
2、利用堆删除思想来进行排序
建堆和堆删除中都用到了向下调整,因此掌握了向下调整,就可以完成堆排序:
//交换函数
void Swap(int* x, int* y)
{int tmp = *x;*x = *y;*y = tmp;
}
//向下调整法建大堆
void AdjustDown(int* a, int n, int parent)
{int child = (parent * 2) + 1;//求出左孩子节点while (child < n){if (child + 1 < n && a[child] < a[child + 1])//找出孩子节点中较大的{child++;}//当父结点小于孩子节点时,交换位置并更新父结点和子节点if (a[parent] < a[child]){Swap(&a[parent], &a[child]);parent = child;child = (parent * 2) + 1;}else{break;}}
}
//堆排序--升序---向下调整法建大堆
void HeapSort(int* a, int n)
{//向下调整法建大堆for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(a, n, i);}//建好大堆开始调整int end = n - 1;while (end){//将堆顶数据放到最后Swap(&a[0], &a[end]);AdjustDown(a, end, 0);end--;}
}
堆排序的时间复杂度为:O(N * logN)。
堆排序特性总结:
- 堆排序使用堆来选数,效率变高
- 时间复杂度:O(N * logN)
- 空间复杂度:O(1)
- 稳定性:不稳定
交换排序
交换,就是根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位置,交换排序的特点是:将键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动(升序),降序则相反。
冒泡排序
冒泡排序的单趟排序中,每次比较两个相邻数据,将较大的那个放在后面,单趟排序完成后,最大的数就会在最后面,然后继续排序,直到所有的数据全部有序。

代码实现:
//交换函数
void Swap(int* x, int* y)
{int tmp = *x;*x = *y;*y = tmp;
}
//冒泡排序
void BubbleSort(int* a, int n)
{//外面的for循环是需要走的排序趟数for (int i = 0; i < n - 1; i++){//这里的for循环是为了每趟中比较相邻两个元素for (int j = 0; j < n - i - 1; j++){//当前一个数据大于后一个数据时两者交换if (a[j] > a[j + 1]){Swap(&a[j], &a[j + 1]);}}}
}

我们还可以通过一个标记位将代码再优化一下:
每趟排序执行完可以判断一下是否执行了交换操作,如果没有执行交换操作说明数组已经有序了,如果执行了则说明数组无序。
代码如下:
//交换函数
void Swap(int* x, int* y)
{int tmp = *x;*x = *y;*y = tmp;
}
//冒泡排序
void BubbleSort(int* a, int n)
{int flag = 0;//外面的for循环是需要走的排序趟数for (int i = 0; i < n - 1; i++){//这里的for循环是为了每趟中比较相邻两个元素for (int j = 0; j < n - i - 1; j++){//当前一个数据大于后一个数据时两者交换if (a[j] > a[j + 1]){Swap(&a[j], &a[j + 1]);flag = 1;}}//如果flag没有改变,说明数组有序if (flag == 0)break;}
}
冒泡排序的特性总结:
时间复杂度:O(N^2)
空间复杂度:O(1)
稳定性:稳定
快速排序
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法。快速排序的基本思想:任取待排序元素序列中的某元素作为基准值,按照该基准值将待排序列分为两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后左右序列重复该过程,直到所有元素都排列在相应位置上为止(下面的默认都是升序)。
递归实现快排
hoare版本
hoare版本思路:
选择最左边的元素(即第一个元素,也可以选择最右边的元素即最后一个)作为基准值,下标为key,两个指针left和right分别指向数组的最左边和最右边,如果选择最左边的元素就让right先出发向左找比key小的值,找到就停下;再让left开始向右找大于key的值,找到也停下,然后交换left和right位置的元素,交换之后重复上述操作……直到当left和right相遇时再将key对应的元素和相遇位置的元素交换,这时key的左边都是比它小的值,key的右边都是比它大的值。
示例:

上面示例中是一趟排序完成得到的结果。

上面的单趟排序中left和right相遇的位置刚好是3的位置,恰好比key对应的元素小,如果相遇位置的元素比key大,key对应位置的元素和相遇位置交换之后就无法保证key左边的都比key小,key右边的都比key大了。应该如何保证呢?
如果最左边元素作为基准值key,那么就要让right先走;如果最右边元素作为基准值key,就要让left先走,这样做就能保证。
当最左边元素为基准值key时,让right先走,相遇情况有以下两种:
1、left停止,right在向左找小的过程中相遇
right在移动,left停止,说明此时是left和right刚交换完元素然后right开始移动,如果是刚交换完那么此时left位置元素就是比key小的元素,left和right此时相遇和key位置交换元素,仍旧能够保证key左边是小元素,右边是大元素。
2、right停止,left在向右找大的过程中相遇
right停止,说明此时已经找到比key小的元素了,left和right相遇和key交换也能满足要求。
当最右边元素作为基准值key,让left先走,也能保证满足要求。
我们可以实现一下单趟排序:
//单趟排序,left指的是最左边元素的下标,right指的是最右边元素的下标
void SingleSort(int* a,int left ,int right)
{int key = left;while (left < right){//保证要让right先走,a[right] >= a[key]要加=while (left < right && a[right] >= a[key]){--right;}//a[left] <= a[key]加上等号是为了能够让left向后查找比while (left < right && a[left] <= a[key]){++left;}if (left < right)Swap(&a[left], &a[right]);}Swap(&a[left], &a[key]);
}

**这样一趟排序过后使key位置元素处在了最后排序完成应该在的位置,此时左边都是比它小的元素,右边都是比它大的元素;同时可以以key元素位置为分割线,分割出两个子区间,再使用key排序的方法将两个子区间排序。**这种把问题分解解决的方法我们可以使用递归来解决。
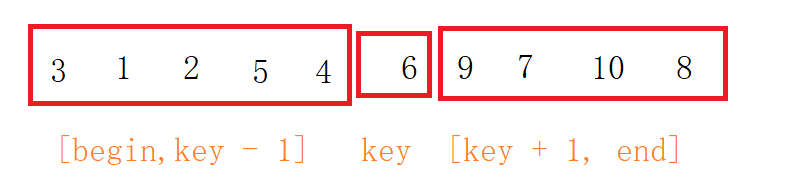
代码实现:
//单趟排序
int SingleSort(int* a,int left ,int right)
{int key = left;while (left < right){//保证要让right先走while (left < right && a[right] >= a[key]){--right;}while (left < right && a[left] <= a[key]){++left;}if (left < right)Swap(&a[left], &a[right]);}Swap(&a[left], &a[key]);return left;
}
//begin是元素的起始位置,end指的是数组最后一个元素的下标
void QuickSort(int* a, int begin, int end)
{if (begin >= end){return;}int key = SingleSort(a, begin, end);QuickSort(a, begin, key - 1);QuickSort(a, key+1,end);
}
测试:

时间复杂度:
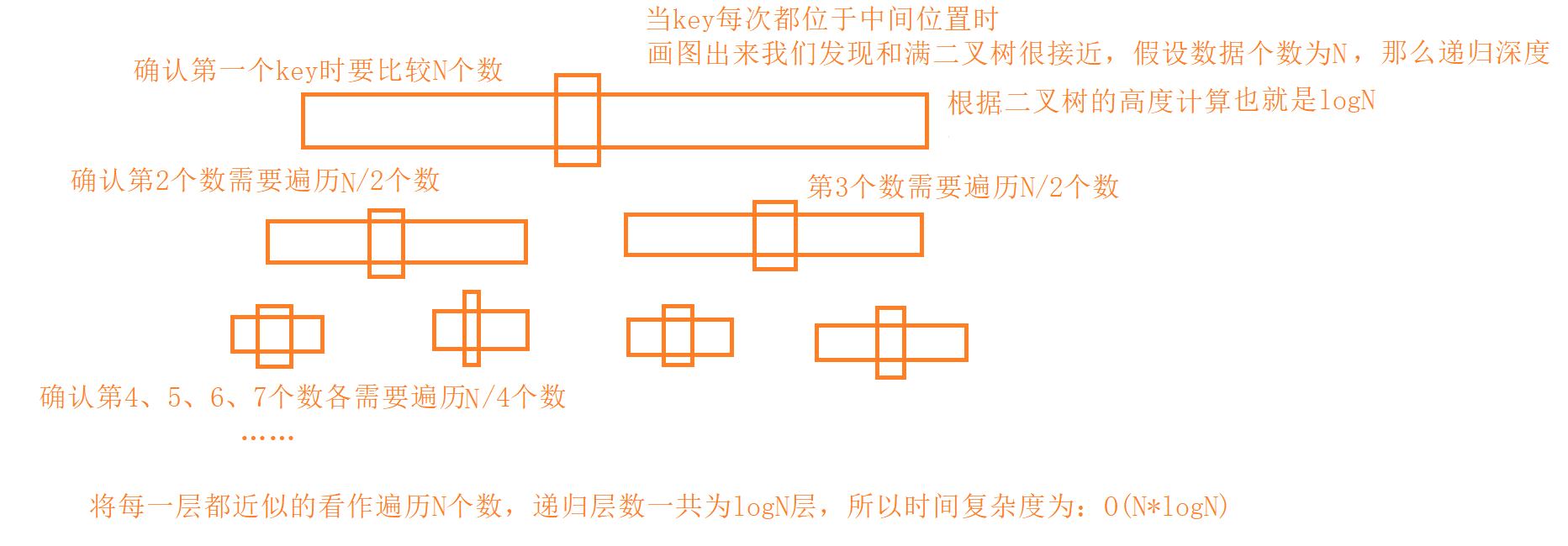
但是当我们使用上面的方法去排已经有序或者接近有序的数据时,效率反而会降低,因为会出现下面这种情况:

此时第一层要遍历N个数,第二层要遍历N-1个数……等差求和最后得出遍历个数为N * (1+N)/2,时间复杂度为O(N2)。
而且这种情况不仅效率会变慢,还有可能因为递归层数过多而出现栈溢出。
我们可以通过三数取中法和小区间优化的方法对程序进行优化。
三数取中法:
通过改变选key的方法:对一组待排序的数据,我们从第一个数,中间位置的数和最后一个数中选取中间值。
代码实现三数取中:
//三数取中函数
int GetMid(int* a, int left, int right)
{//防止left和right太大溢出int mid = left + (right - left) / 2;if (a[mid] > a[left]){if (a[right] > a[mid])return mid;else if (a[left] > a[right])return left;elsereturn right;}//a[mid] < a[left]else{if (a[right] < a[mid])return mid;else if (a[left] > a[right])return right;elsereturn left;}
}
同时我们也要对单趟排序的代码进行修改:

更改后的代码:
//三数取中函数
int GetMid(int* a, int left, int right)
{//防止left和right太大溢出int mid = left + (right - left) / 2;if (a[mid] > a[left]){if (a[right] > a[mid])return mid;else if (a[left] > a[right])return left;elsereturn right;}//a[mid] < a[left]else{if (a[right] < a[mid])return mid;else if (a[left] > a[right])return right;elsereturn left;}
}
//单趟排序
int SingleSort(int* a,int left ,int right)
{int mid = GetMid(a, left,right);Swap(&a[mid], &a[left]);int key = left;while (left < right){//保证要让right先走while (left < right && a[right] >= a[key]){--right;}while (left < right && a[left] <= a[key]){++left;}if (left < right)Swap(&a[left], &a[right]);}Swap(&a[left], &a[key]);return left;
}
//begin是元素的起始位置,end指的是数组最后一个元素的下标
void QuickSort(int* a, int begin, int end)
{if (begin >= end){return;}int key = SingleSort(a, begin, end);QuickSort(a, begin, key - 1);QuickSort(a, key+1,end);
}
优化之后不管待排序数据是有序是接近有序,不会导致递归层数较深从而导致栈溢出,也在一定程度上提高了效率。
小区间优化:
在待排区间较小时,我们可以直接用一个直接插入排序去单独进行排序,从而达到一个优化的效果。
//begin是元素的起始位置,end指的是数组最后一个元素的下标
void QuickSort(int* a, int begin, int end)
{if (begin >= end){return;}//小区间用直接插入排序//当区间数据为8个时采用直接排序if (end - begin + 1 < 8){//a+begin是区间首元素下标InsertSort(a + begin, end - begin + 1);}else{int key = SingleSort(a, begin, end);//左区间QuickSort(a, begin, key - 1);//右区间QuickSort(a, key + 1, end);}
}
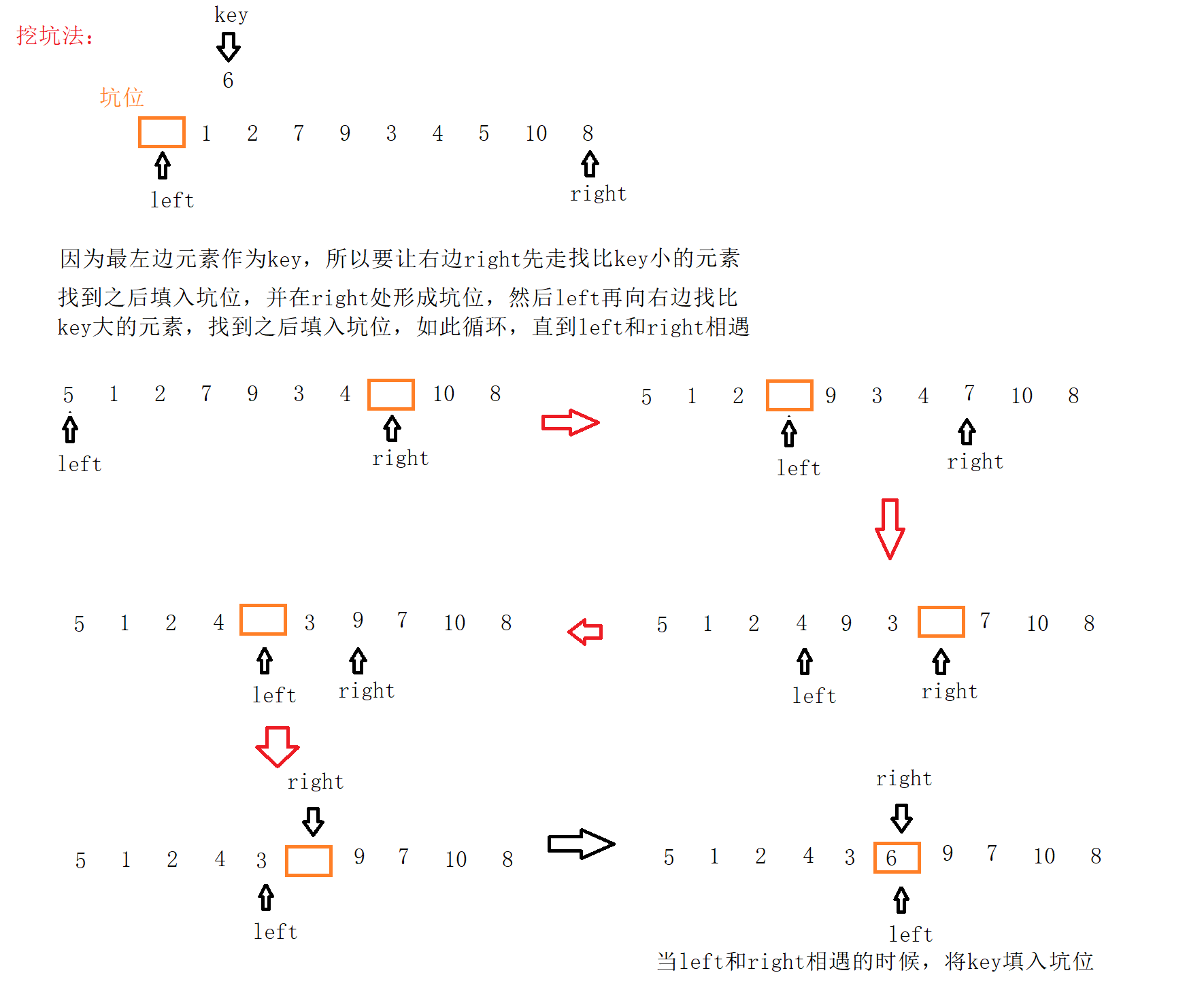
挖坑法
挖坑法基本思路:
1、定义一个变量key用来保存选出的数据(一般是第一个或者是最后一个),并在选取数据的位置形成一个坑位;
2、和上面思路一样也定义两个指针left和right(如果选的是最左边元素,则让right先走,如果是最右边元素作为key,则让left先走,这里和上面一样,选的是最左边元素作为坑位);
3、在走的过程中如果right遇到比key小的元素就填入坑位,并在right指向的位置形成一个坑位,left走的过程中如果找到比key大的元素就将该位置的元素填入坑位,并在left指向的位置形成一个坑位,循环走下去,直到最终left和right相遇,相遇之后将key抛入坑位即可。
经过上面思路完成一次单趟排序,使得key值左边的数据小于key,key值右边的数据大于key。和上面思路差不多也是通过不断的划分为小区间,然后通过递归完成。
单趟代码实现:
//挖坑法单趟排序
int Single2Sort(int* a, int left, int right)
{int mid = GetMid(a, left, right);Swap(&a[mid], &a[left]);int key = a[left];//记录基准值int hole = left;//从最左边开始挖坑while (left < right){//保证先走right再走leftwhile (left < right && a[right] >= key){--right;}//填坑a[hole] = a[right];hole = right;while (left < right && a[left] <= key){++left;}a[hole] = a[left];hole = left;}//最后将key填入坑中a[hole] = key;return hole;
}
整体代码实现:
//挖坑法单趟排序
int Single2Sort(int* a, int left, int right)
{int mid = GetMid(a, left, right);Swap(&a[mid], &a[left]);int key = a[left];//记录基准值int hole = left;//从最左边开始挖坑while (left < right){//保证先走right再走leftwhile (left < right && a[right] >= key){--right;}//填坑a[hole] = a[right];hole = right;while (left < right && a[left] <= key){++left;}a[hole] = a[left];hole = left;}//最后将key填入坑中a[hole] = key;return hole;
}
void Quick2Sort(int* a, int begin, int end)
{if (begin >= end)return;//记录下标位置int keyi = Single2Sort(a, begin, end);//递归Quick2Sort(a, begin, keyi - 1);Quick2Sort(a, keyi + 1, end);
}
前后指针法
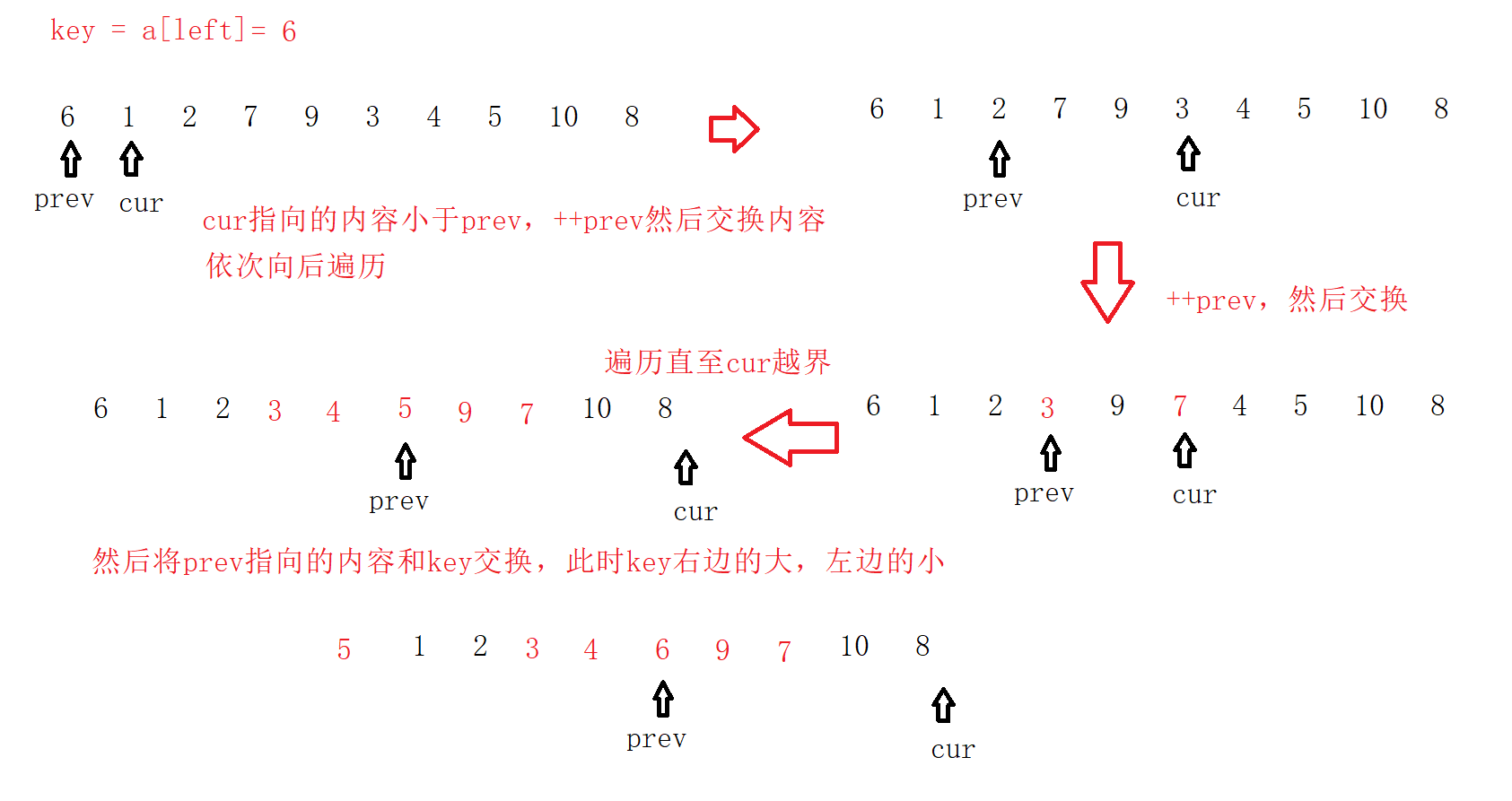
前后指针法单趟排序的基本步骤是:
1、选出一个key,一般都是最左边元素或者最右边元素;
2、设有两个指针,一个指针prev,指向数组序列的首个元素,另外一个指针cur指向数组首个元素的下一个位置;
3、若cur指向的内容小于key,则++prev之后,将cur指向的内容和prev指向的内容进行交换,然后再cur++;如果cur指向的内容大于key,则继续++cur,循环指向第三步,直到cur指针遍历完整个数组,最后再将key的值和prev指向的内容进行交换即可。
经过一次单趟排序,使得key左边的数据全部都小于key,key右边的数据全部都大于key。同样使用递归的思路进行分区间排序。
单趟排序代码:
//前后指针法单趟排序
int Single3Sort(int* a,int left,int right)
{int key = a[left];int prev = left;int cur = prev + 1;//right是最后一个元素的下标while (cur <= right){if (a[cur] < key){++prev;Swap(&a[prev], &a[cur]);}++cur;}Swap(&a[prev], &a[left]);return prev;
}
整体代码实现:
//前后指针法单趟排序
int Single3Sort(int* a,int left,int right)
{int key = a[left];int prev = left;int cur = prev + 1;//right是最后一个元素的下标while (cur <= right){if (a[cur] < key){++prev;Swap(&a[prev], &a[cur]);}++cur;}Swap(&a[prev], &a[left]);return prev;
}
void Quick3Sort(int* a, int begin, int end)
{if (begin >= end){return;}int keyi = Single3Sort(a, begin, end);//[begin,keyi - 1] keyi [keyi + 1,end]Quick3Sort(a, begin, keyi - 1);Quick3Sort(a, keyi + 1,end);
}
时间复杂度:O(N * logN)。
非递归实现快排
当我们需要将一个用递归实现的算法改为非递归时,一般需要借用一个数据结构,快排的非递归需要我们借助数据结构中的栈来实现,栈使用的空间是在堆上开辟的,与栈区相比,堆区的空间比较大。

在上面的实现过程中对数组进行递归排序,每次递归不同之处就是传递的区间不一样,我们都是先对整体进行划分然后再分别处理他的左右两个子区间,我们这里借助栈就是为了帮助我们去控制这个区间的。
非递归实现快排基本思路:
1、首先初始化一个栈,将我们要排序的数组的首个元素下标和最后一个元素的下标插入栈中(最开始区间)
2、再通过StackTop和StackPop操作取出左边元素和右边元素,注意栈的结构是先进后出(取出顺序);
3、然后通过单趟排序找到keyi,keyi将区间分为两个子区间,再根据区间[left,keyi - 1] keyi [keyi + 1,right]将区间的左右下标插入栈中,要注意插入栈中的顺序,同时还要注意当区间中只有一个元素时不需要再插入。
只要栈中不为空就一直循环进行下去,所以循环条件就是判断栈为不为空。
//非递归快排
void QuickSortNonR(int* a, int begin, int end)
{ST st;//初始化栈StackInit(&st);//刚开始区间[begin,end]StackPush(&st, begin);StackPush(&st, end);while (!StackEmpty(&st)){//先进后出,先接收右边int right = StackTop(&st);StackPop(&st);//再接收左边int left = StackTop(&st);StackPop(&st);int keyi = Single1Sort(a, left, right);//再按照区间压入[left,keyi - 1] keyi [keyi + 1, right]//判断区间是否只剩下一个数if (right > keyi - 1){StackPush(&st, keyi + 1);StackPush(&st, right);}if (keyi - 1 > left){StackPush(&st, left);StackPush(&st, keyi - 1);}}//最后销毁栈StackDestroy(&st);
}
快速排序特性总结:
- 快速排序整体的综合性能和使用场景都比较好。
- 时间复杂度:O(N * logN)。
- 空间复杂度:O(logN)
- 稳定性:不稳定
归并排序
归并排序是建立在归并操作上的一种有效,稳定的排序算法,该算法是采用分治法的一个非常典型的应用。是将已有序的子序列合并,得到完全有序的序列。

但是当给我们一组数据让我们使用归并排序,我们并不能保证将这组数据从中间分开两边数据就是有序的,但是我们可以将它们变为有序从而进行归并排序。

递归实现
我们可以利用递归的思路,首先将其从中间分成两组,只要让两组变得有序就可以对其进行归并,但是分成的两组也无法保证有序,所以可以继续将这两组进行拆分变得有序……所以如果我们要想让数据有序,就要进行多次划分,不断分割成子问题,当被划分出来的区间只有一个数时,就可以认为它是一个有序区间了,我们就可以开始一层一层的向前合并,当将所有的区间合并完,排序也就完成了。
时间复杂度分析:
从下图我们可以看出当分解完成的时候,看起来很像满二叉树:

那它的递归层数我们可以认为是logN。而分解完成后每一层我们都要进行合并,合并其实就是遍历找小的进行尾插,这里的尾插指的是我们要将数据放到一个新数组中,因为直接在原数组中比较尾插有时候会覆盖有些有效数据。所以我们需要开辟一个新的大小为N(原数组中的)的数组,即归并排序的空间复杂度是O(N)。
那我们对每一层进行合并,要对每个数据进行遍历比较也就是每层都要比较N次;排完序之后还要将数据放到原始的数组中,所以还要将尾插到新数组的数据拷贝回原数组,也需要遍历一趟,所以时间复杂度为O(N * logN)。
我们分析实现代码:
因为要递归实现,所以我们可以再定义一个函数,避免在原函数中递归多次开辟空间,子函数的命名可以在函数名前面加一个_。
开辟一个数组并且定义一个子函数,在子函数中找到中间值,将数组分成两个区间,当两个子区间有序就可以进行归并;分解的时候递归的结束条件就是当区间中只剩下一个数的时候,说明已经分解到底了,此时就可以进行合并了。
如何进行合并呢?遍历两个区间的数据,找到小的插入到tmp数组中,当全部合并完成之后将tmp数组中的数组拷贝到原数组中并且将tmp数组销毁:
//子函数专门递归用来排序
void _merger(int* a, int begin, int end, int* tmp)
{if (begin >= end)return;//分解//取中间值//int mid = (begin + end) / 2;int mid = begin + (end - begin)/ 2;//将两个区间分别进行处理_merger(a, begin, mid, tmp);_merger(a, mid + 1, end, tmp);//归并int begin1 = begin;int end1 = mid;int begin2 = mid + 1;int end2 = end;int i = begin;//用来记录新数组中插入数据下标的位置while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}//将其中未遍历完的数据插入到新数组中while (begin1 <= end1){tmp[i++] = a[begin1++];}while (begin2 <= end2){tmp[i++] = a[begin2++];}//最后再将新数组拷贝回原数组memcpy(a + begin, tmp + begin, (end - begin + 1) * sizeof(int));
}
//n是数据个数
void merger(int* a, int n)
{//开辟一个空间用来存储排完序的数据int* tmp = (int*)malloc(sizeof(int)* n);if (tmp == NULL){perror("malloc fail");return;}_merger(a, 0, n - 1, tmp);free(tmp);tmp = NULL;
}
非递归实现
归并排序的非递归算法并不需要借助栈来完成,我们只需要控制每次参与合并的元素个数即可,最终便能使序列变为有序。
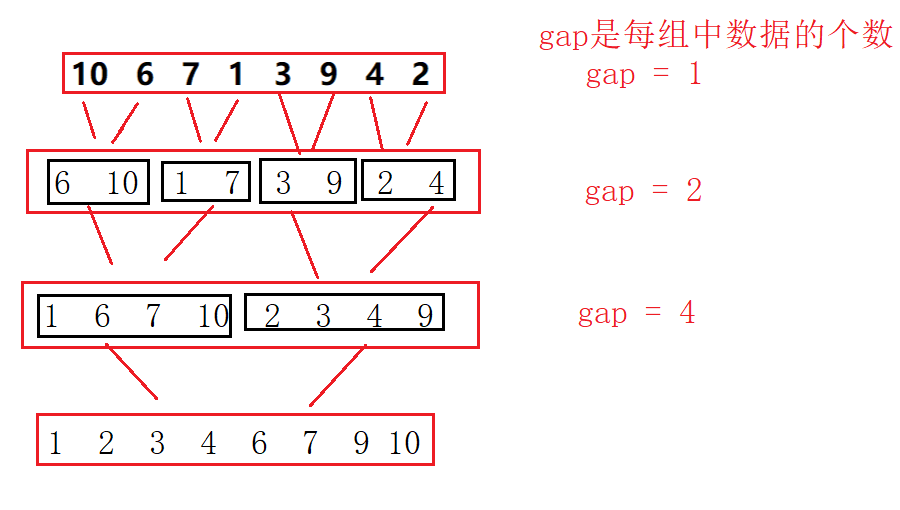
我们可以先把原始数组中的数据当作一个数据为一组,每组只有一个数据,那每组中的数据都可以认为是有序的,然后从前到后两两进行合并:

这样一趟之后我们可以把每两个数看作一组,每组数据也都是有序的,然后相邻的两组再进行合并,依次循环最后可以得到有序的数组,所以我们可以定义一个变量gap,来定义每组中数据的个数:
代码实现的时候要控制好区间边界:
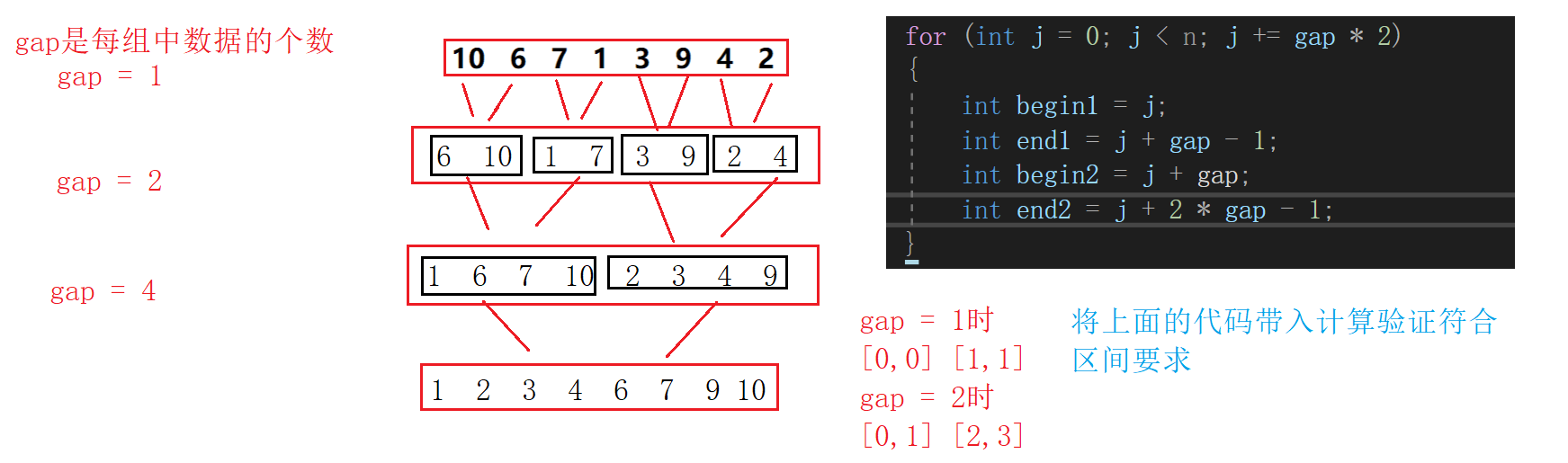 区间边界变化也要注意拷贝到原数组的时候将拷贝区间也跟着改变一下:
区间边界变化也要注意拷贝到原数组的时候将拷贝区间也跟着改变一下:
void MergerSortNonR(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");return;}int gap = 1;while (gap < n){for (int j = 0; j < n; j += gap * 2){int begin1 = j;int end1 = j + gap - 1;int begin2 = j + gap;int end2 = j + 2 * gap - 1;int i = j;//用来记录新数组中插入数据下标的位置while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}//将其中未遍历完的数据插入到新数组中while (begin1 <= end1){tmp[i++] = a[begin1++];}while (begin2 <= end2){tmp[i++] = a[begin2++];}//最后再将新数组拷贝回原数组(只拷贝已经归并的区间)memcpy(a + j, tmp + j, (end2 - j + 1) * sizeof(int));}gap *= 2;}free(tmp);tmp = NULL;
}
但是当我们使用测试用例{ 6,1,2,7,9,3,4,5,10,8 }去测试的时候会报错,出现越界问题。当gap = 2 时,j = 8时,end2 = j + 2 * gap - 1 = 11;数组下标只到9,所以数组越界了。
所以我们要分析一下几种特殊情况:
归并的区间是[begin1,end1]和[begin2,end2],begin1是不会越界的,因为begin1 = j是我们判断过的j < n;
所以越界只会出现下面几种情况:
1、左区间越界,即end1越界;
如果end1越界的话,说明第二组是不存在的,也就是说这一次合并只有一组,这种情况直接break。
2、右区间全部越界,即begin2越界;
这种情况第二组不存在,直接break。
3、左区间没有越界,右区间部分越界,即begin2没有越界但end2越界;
这种情况调整end2的取值,n是数据个数,n-1就是最后一个元素下标,直接让end2等于最后一个元素下标n-1。
修改之后代码如下:
//非递归归并排序
void MergerSortNonR(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");return;}int gap = 1;while (gap < n){for (int j = 0; j < n; j += gap * 2){int begin1 = j;int end1 = j + gap - 1;int begin2 = j + gap;int end2 = j + 2 * gap - 1;//判断是否越界并对其进行处理//判断左区间是否越界if (end1 >= n)break;//直接直接跳出//判断右区间是否越界if (begin2 >= n)break;//直接直接跳出if (end2 >= n)end2 = n - 1;//让其等于数组最后一个元素下标int i = j;//用来记录新数组中插入数据下标的位置while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}//将其中未遍历完的数据插入到新数组中while (begin1 <= end1){tmp[i++] = a[begin1++];}while (begin2 <= end2){tmp[i++] = a[begin2++];}//最后再将新数组拷贝回原数组(只拷贝已经归并的区间)memcpy(a + j, tmp + j, (end2 - j + 1) * sizeof(int));}gap *= 2;}free(tmp);tmp = NULL;
}
归并排序的特性总结:
1、时间复杂度:O(N*logN)
2、空间复杂度:O(N)
3、稳定性:稳定
计数排序
计数排序,又叫非比较排序,是一个非基于比较的排序算法,基本思路是开辟一定范围的空间,然后通过遍历数组,将所有数据出现的次数映射在对应数组下标的空间内,遍历完数组之后,我们开辟的新数组内部,对应的下标内存放的就是该下标元素出现的次数,那么我们就可以对这些数据进行处理,把数据依次覆盖到原数组内部。
计数排序又称为鸽巢原理,是对哈希直接定址法的变形应用。

当我们将原数组遍历一次之后,完成了元素出现次数的统计,我们再从头去遍历新数组(从下标为0的位置开始),就以上图中新数组为例,下标0位置出现次数为0,下标1位置出现1次,就拿去覆盖原数组中首个元素,然后依次向后遍历,完成之后就是将数组中元素排序完成。
但是当待排序数据的大小差别非常大的时候,比如数组{1,2,3,4,200,3000,10000},最大数为10000,最小的数据为1,如果按照上面创建数组的方式并不合适,因此计数排序的局限性就是一般适用于范围相对集中的数据。
那么当范围集中且数据比较大时,如{101,104,102,98},我们可以使用相对映射来记录,而上面的那种直接记录的方式被称为绝对映射(即待排的数据是几,它的出现次数就保存在了另一个数组下标为几的位置上)。
使用相对映射方法:先找到数组中的最大值max和最小值min,开一个空间大小为(max - min + 1)的数组,上面例子中最大值104,最小值98,拿开一个大小为7的数组,数组的下标范围就是[0,6];然后最小的元素映射到数组下标为0的位置上,即对于待排数组中的数组a[i],就映射到下标为a[i]-min的位置上。
而且使用绝对映射时,当数组中出现负数的时候就不能用来记录了,毕竟数组下标不会出现负数,但是使用相对映射就不用担心数组过大和出现负数的问题了。
代码实现:
//计数排序
void CountSort(int* a, int n)
{assert(a);int max = a[0];//记录最大值int min = a[0];//记录最小值for (int i = 0; i < n; i++){//找最大值if (max < a[i]){max = a[i];}//找最小值if (min > a[i]){min = a[i];}//根据最大值和最小值确定开辟数组的大小}int range = max - min + 1;//创建用来计数的数组//当我们不想手动进行初始化为0的时候可以使用calloc函数,calloc会自动初始化为0//int* tmp = (int*)calloc(range,sizeof(int));int* tmp = (int*)malloc(sizeof(int) * range);if (tmp == NULL){perror("malloc fail");return;}//将新数组的全部元素都设置为0memset(tmp, 0, sizeof(int) * range);//统计个数放到tmp数组中for (int i = 0; i < n; i++){tmp[a[i] - min]++;}int j = 0;//排序for (int i = 0; i < range; i++){//tmp[i]里存的是数据出现个数while (tmp[i]--){a[j] = i + min;j++;}}//freefree(tmp);tmp = NULL;
}
计数排序特性总结
1、计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。
2、时间复杂度:O(N + range)
3、空间复杂度:O(range)
4、稳定性:稳定
排序算法复杂度及稳定性分析
| 排序方法 | 平均情况 | 最好情况 | 最坏情况 | 辅助空间 | 稳定性 |
|---|---|---|---|---|---|
| 直接插入排序 | O(N2) | O(N) | O(N2) | O(1) | 稳定 |
| 希尔排序 | O(NlogN)~O(N2) | O(N1.3) | O(N2) | O(1) | 不稳定 |
| 直接选择排序 | O(N2) | O(N2) | O(N2) | O(1) | 不稳定 |
| 堆排序 | O(NlogN) | O(NlogN) | O(NlogN) | O(1) | 不稳定 |
| 冒泡排序 | O(N2) | O(N) | O(N2) | O(1) | 稳定 |
| 快速排序 | O(NlogN) | O(NlogN) | O(N2) | O(logN)~O(N) | 不稳定 |
| 归并排序 | O(NlogN) | O(NlogN) | O(NlogN) | O(N) | 稳定 |
相关文章:
【数据结构】八大排序详解
🚀 作者简介:一名在后端领域学习,并渴望能够学有所成的追梦人。 🐌 个人主页:蜗牛牛啊 🔥 系列专栏:🛹数据结构、🛴C 📕 学习格言:博观而约取&…...
VSCode如何设置高亮
一、概述 本文主要介绍在 VSCode 看代码时,怎样使某个单词高亮显示,主要通过以下三步实现: 安装 highlight-words 插件 配置 highlight-words 插件 设置高亮快捷键F8 工作是嵌入式开发的,代码主要是C/C的,之前一直用…...

密钥大全ubuntu
VMware Workstation Tech Preview 20H2 GG1JR-APD1P-0857Q-DQQN9-PU2CA VMware Workstation v16 Pro for Windows(反馈失效) ZF3R0-FHED2-M80TY-8QYGC-NPKYF YF390-0HF8P-M81RQ-2DXQE-M2UT6 ZF71R-DMX85-08DQY-8YMNC-PPHV8 VMware Workstation v15 f…...

Spring Task入门案例
Spring Task 是Spring框架提供的任务调度工具,可以按照约定的时间自动执行某个代码逻辑。 定位:定时任务框架 作用:定时自动执行某段Java代码 强调:只要是需要定时处理的场景都可以使用Spring Task 1. cron表达式 cron表达式…...
针对Android项目蓝牙如何学习
一、概述(Overview) 蓝牙是一种专有的开放式无线技术标准,用于在固定和移动设备之间进行短距离数据交换(使用2400–2480 MHz ISM波段的短波长无线电传输),从而创建具有高度安全性的个人局域网(PANs)。由电信供应商爱立信(telecoms vendor Ericsson)于1994年创建,[1…...

C++学习笔记总结练习:内存分配器编程实现
内存分配器练习 C内存分配器是用于管理程序运行时内存的工具。它负责分配和释放内存,以满足程序在运行过程中的动态内存需求。在C中,有几种内存分配器可供选择,包括操作系统提供的默认分配器、自定义分配器和第三方库提供的分配器。 默认分配…...
【uniapp】使用Vs Code开发uniapp:
文章目录 一、使用命令行创建uniapp项目:二、安装插件与配置:三、编译和运行:四、修改pinia: 一、使用命令行创建uniapp项目: 二、安装插件与配置: 三、编译和运行: 该项目下的dist》dev》mp-weixin文件导入微信开发者…...
【STM32】高效开发工具CubeMonitor快速上手
工欲善其事必先利其器。拥有一个辅助测试工具,能极大提高开发项目的效率。STM32CubeMonitor系列工具能够实时读取和呈现其变量,从而在运行时帮助微调和诊断STM32应用,类似于一个简单的示波器。它是一款基于流程的图形化编程工具,类…...

React 使用 i18n 翻译换行解决方法
当前问题: json 配置文件 "detail": {"10001": "Top 10 \nBIGGEST WINS" } 按以上方式文本在渲染的时候并不能识别我们加入 \n 要实现换行的意图,通过拆分成两个多语来实现又太低级。 解决方法: 在该多语…...

QEMU源码全解析37 —— Machine(7)
接前一篇文章:QEMU源码全解析36 —— Machine(6) 本文内容参考: 《趣谈Linux操作系统》 —— 刘超,极客时间 《QEMU/KVM》源码解析与应用 —— 李强,机械工业出版社 特此致谢! 上回书讲完了q…...
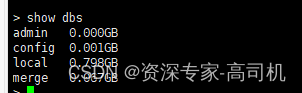
如何将阿里云WiredTiger引擎的MongoDB物理备份文件恢复至自建数据库
数据库操作一直是一个比较敏感的话题,动不动“删库跑路”,可见数据库操作对于一个项目而言是非常重要的,我们有时候会因为一个游戏的严重bug或者运营故障要回档数据库,而你们刚好使用的是阿里云的Mongodb,那么这篇文章…...

SAP FIORI Launchpad 403 forbidden error
问题: 在前台输入/N/UI2/FLP 浏览器显示 403 forbidden 查阅资料得知 相关sicf 的服务未激活 note:3011106 检查以下所有服务是否已在事务代码 SICF 中激活: /default_host/sap/bc/ui2/nwbc/ /default_host/sap/bc/ui2/start_up /default_host/sap…...

【MongoDB】高性能非关系型数据库
文章目录 基本介绍MongoDB和redis做比较MongoDB 在Java中的使用MongoDB的应用场景 基本介绍 MongoDB是一个开源的、面向文档的NoSQL数据库管理系统。它采用了类似JSON的BSON(二进制JSON)数据模型,具有高度灵活性和可扩展性,被广泛…...
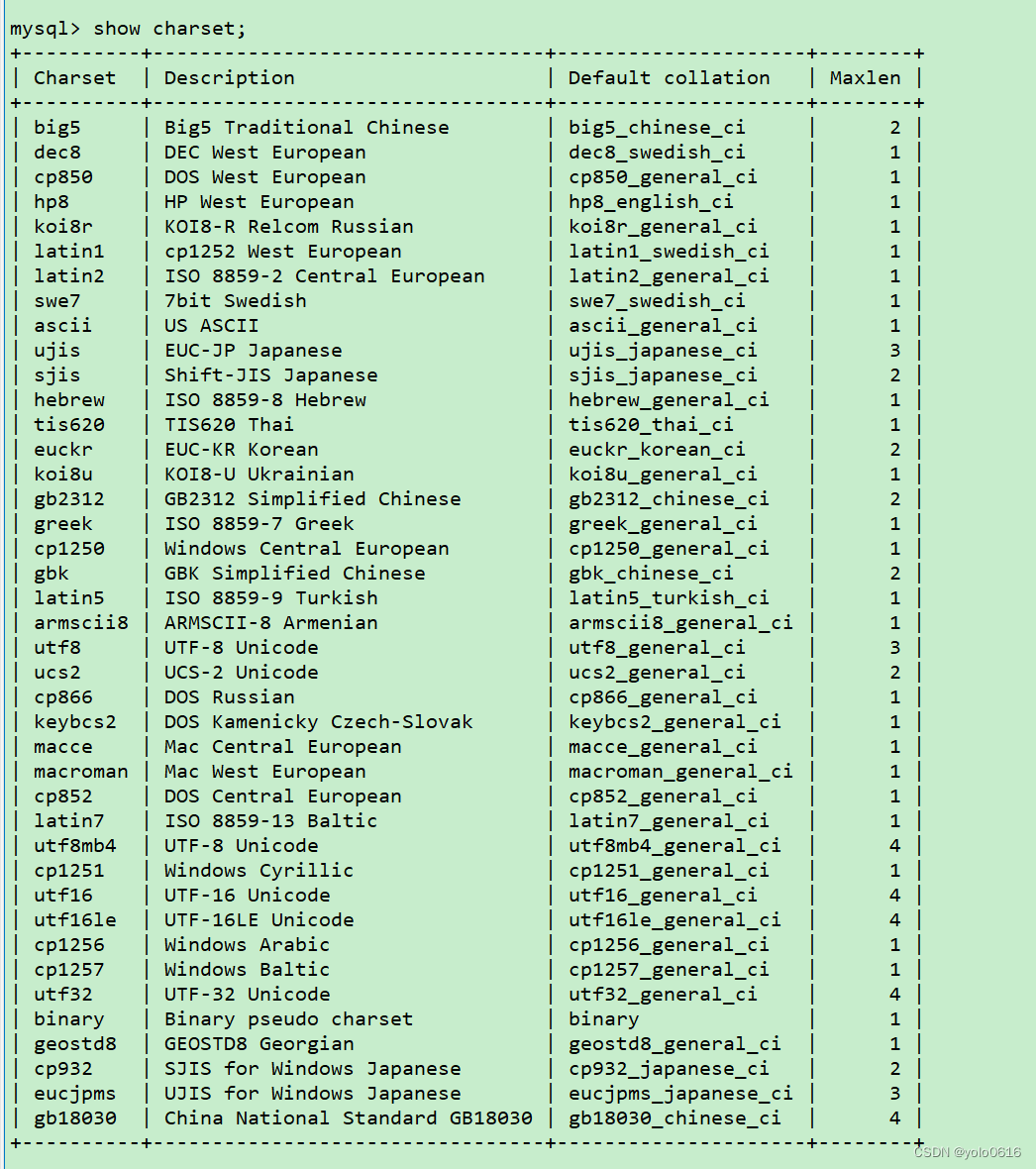
二、MySql库的操作
文章目录 一、库的操作(一)创建数据库(二)创建数据库案例(三)字符集和校验规则1、 查看系统默认字符集以及校验规则2、查看数据库支持的字符集3、查看数据库支持的字符集校验规则4、校验规则对数据库的影响…...

【ARM 嵌入式 编译系列 10 -- GCC 编译缩减可执行文件 elf 文件大小】
文章目录 GCC 如何缩减可执行文件size测试代码 上篇文章:ARM 嵌入式 编译系列 9-- GCC 编译符号表(Symbol Table)的详细介绍 下篇文章:ARM 嵌入式 编译系列 10.1 – GCC 编译缩减可执行文件 elf 文件大小 GCC 如何缩减可执行文件s…...

IDEA启动报错java.nio.charset.MalformedInputException: Input length=2
IDEA启动报错java.nio.charset.MalformedInputException: Input length2 问题解决后记 问题 原本系统运行好好得,一段时间没打开,再次打开重启 IDEA启动报错java.nio.charset.MalformedInputException: Input length2。 解决 百度了 https://blog.csd…...

【Vue-Router】路由传参
1. query 传参 list.json {"data": [{"name": "面","price":300,"id": 1},{"name": "水","price":400,"id": 2},{"name": "菜","price":500,"…...

平板选择什么电容笔比较好?ipad手写笔推荐品牌
在现在的生活上,有了iPad平板,一切都变得简单了许多,也让我们的学习以及工作都更加的便利。这其中,电容笔就起到了很大的作用,很多人都不知道,到底要买什么牌子的电容笔?哪些电容笔的性价比比较…...

什么是数字化车间
一、数字化车间概述 数字化车间是以现代化信息、网络、数据库、自动识别等技术为基础,通过智能化、数字化、MES系统信息化等手段融合建设的数字化生产车间,精细地管理生产资源、生产设备和生产过程。随着工业4.0概念的提出,未来的工业和制造…...
创新零售,京东重新答题?
继新一轮组织架构调整后,京东从低价到下沉动作不断。 新成立的创新零售部在京东老将闫小兵的带领下悄然完成了整合。近日,京喜拼拼已改名为京东拼拼,与七鲜、前置仓等业务共同承载起京东线上线下加速融合的梦想。 同时,拼拼的更…...

3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题
3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题 【免费下载链接】tool the USBToolBox tool 项目地址: https://gitcode.com/gh_mirrors/too/tool 在Hackintosh和跨平台开发领域,USB端口映射一直是个令人头疼的技术难题。US…...

自制BLE112串口编程器:基于Bootloader的免调试器烧录方案
1. 项目概述:为BLE112模块打造一款免调试器的RS232编程器在嵌入式开发,特别是早期的蓝牙低功耗(BLE)模块应用中,我们常常会遇到一个棘手的问题:官方开发工具链的依赖和限制。以Silicon Labs(当时…...

一次搞懂内存取证:用Volatility3和Cobalt Strike分析工具复现VNCTF‘来一把紧张刺激的CS’
实战内存取证:从Volatility3到Cobalt Strike信标分析全解析 在网络安全事件响应中,内存取证往往是发现高级威胁的最后一道防线。当攻击者使用文件无落地的技术时,传统的磁盘取证可能一无所获,而内存中却保留着攻击行为的完整痕迹。…...

智能体所有权与版权:AI Agent Harness Engineering 创造的作品归谁所有?
1. 标题选项 《AI Agent创作版权迷局破解:从Harness工程原理到所有权划分的完整指南》 《智能体作品归谁?AI Agent Harness Engineering场景下的版权规则深度拆解》 《告别权属纠纷:一文搞懂AI Agent生成内容的所有权、版权与收益分配规则》 《Harness工程视角下的AI创作权:…...
:执行计划教我做事)
开发转兼职DBA(二):执行计划教我做事
开发转兼职DBA(二):执行计划教我做事 查询慢了不知道为什么,加了索引还是慢,复合索引怎么建,执行计划怎么看——这些不是DBA的专利,是每个写SQL的开发者迟早要面对的事。 文章目录 开发转兼职DB…...

WebSocket实时通信架构进阶:Room、命名空间与集群部署
WebSocket实时通信架构进阶:Room、命名空间与集群部署 作者:Crown_22 | AI Agent & Hermes Agent 桌面程序开发者 前言 WebSocket已经成为实时应用的标准技术,但大多数教程只停留在"建立连接、发送消息"的基础阶段。在生产环境中,你需要处理Room管理、命名空…...

3分钟告别英文恐惧:Android Studio中文界面轻松切换指南
3分钟告别英文恐惧:Android Studio中文界面轻松切换指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 你是否曾经因…...
)
微信聊天图片丢了别慌!保姆级教程:找回并解密DAT文件(支持新旧版微信路径)
微信DAT图片恢复实战:从文件定位到批量解密的完整指南 微信聊天记录中的图片突然消失?别急着放弃!那些看似无法打开的DAT文件里,可能藏着您的重要回忆或工作资料。本文将带您深入微信存储机制,手把手完成从文件定位到…...

2026数据治理平台选型:五款产品如何赋能数据中台建设?
一、引言:数据中台的成败,关键在治理在数字化浪潮的席卷下,“数据中台”已成为当代企业信息化架构中的核心战略组件。然而,一个悖论正困扰着大量企业:数据中台的基础设施搭建日趋完善,但真正将数据转化为业…...

【2026实测】怎么提高论文原创度?盘点8款主流降AI工具,附结构级优化指南
写文章最怕碰到什么,是辛辛苦苦自己码出来的字,却被标了极高的AI值。目前很多文本审核机制对内容的原创度要求极高,纯手写的初稿也可能因为句式太工整被判定为机器生成的。 为了帮几个快被这事折腾疯了的学弟学妹找条出路,我花了…...