4.3、Flink任务怎样读取Kafka中的数据
目录
1、添加pom依赖
2、API使用说明
3、这是一个完整的入门案例
4、Kafka消息应该如何解析
4.1、只获取Kafka消息的value部分
4.2、获取完整Kafka消息(key、value、Metadata)
4.3、自定义Kafka消息解析器
5、起始消费位点应该如何设置
5.1、earliest()
5.2、latest()
5.3、timestamp()
6、Kafka分区扩容了,该怎么办 —— 动态分区检查
7、在加载KafkaSource时提取事件时间&添加水位线
7.1、使用内置的单调递增的水位线生成器 + kafka timestamp 为事件时间
7.2、使用内置的单调递增的水位线生成器 + kafka 消息中的 ID字段 为事件时间
1、添加pom依赖
我们可以使用Flink官方提供连接Kafka的工具flink-connector-kafka
该工具实现了一个消费者FlinkKafkaConsumer,可以用它来读取kafka的数据
如果想使用这个通用的Kafka连接工具,需要引入jar依赖
<!-- 引入 kafka连接器依赖-->
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>1.17.0</version>
</dependency>2、API使用说明
官网链接:Apache Kafka 连接器
语法说明:
// 1.初始化 KafkaSource 实例
KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers(brokers) // 必填:指定broker连接信息 (为保证高可用,建议多指定几个节点) .setTopics("input-topic") // 必填:指定要消费的topic.setGroupId("my-group") // 必填:指定消费者的groupid(不存在时会自动创建).setValueOnlyDeserializer(new SimpleStringSchema()) // 必填:指定反序列化器(用来解析kafka消息数据,转换为flink数据类型).setStartingOffsets(OffsetsInitializer.earliest()) // 可选:指定启动任务时的消费位点(不指定时,将默认使用 OffsetsInitializer.earliest()).build(); // 2.通过 fromSource + KafkaSource 获取 DataStreamSource
env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");3、这是一个完整的入门案例
开发语言:java1.8
flink版本:flink1.17.0
public class ReadKafka {public static void main(String[] args) throws Exception {newAPI();}public static void newAPI() throws Exception {// 1.获取执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2.读取kafka数据KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("worker01:9092") // 必填:指定broker连接信息 (为保证高可用,建议多指定几个节点).setTopics("20230810") // 必填:指定要消费的topic.setGroupId("FlinkConsumer") // 必填:指定消费者的groupid(不存在时会自动创建).setValueOnlyDeserializer(new SimpleStringSchema()) // 必填:指定反序列化器(用来解析kafka消息数据).setStartingOffsets(OffsetsInitializer.earliest()) // 可选:指定启动任务时的消费位点(不指定时,将默认使用 OffsetsInitializer.earliest()).build();env.fromSource(source,WatermarkStrategy.noWatermarks(),"Kafka Source").print();// 3.触发程序执行env.execute();}
}
4、Kafka消息应该如何解析
代码中需要提供一个反序列化器(Deserializer)来对 Kafka 的消息进行解析
反序列化器的功能:
将Kafka ConsumerRecords转换为Flink处理的数据类型(Java/Scala对象)
反序列化器通过 setDeserializer(KafkaRecordDeserializationSchema.of(反序列化器类型)) 指定
下面介绍两种常用Kafka消息解析器:
KafkaRecordDeserializationSchema.of(new JSONKeyValueDeserializationSchema(true)) :
1、返回完整的Kafka消息,将JSON字符串反序列化为ObjectNode对象
2、可以选择是否返回Kafak消息的Metadata信息,true-返回,false-不返回
KafkaRecordDeserializationSchema.valueOnly(StringDeserializer.class) :
1、只返回Kafka消息中的value部分
4.1、只获取Kafka消息的value部分
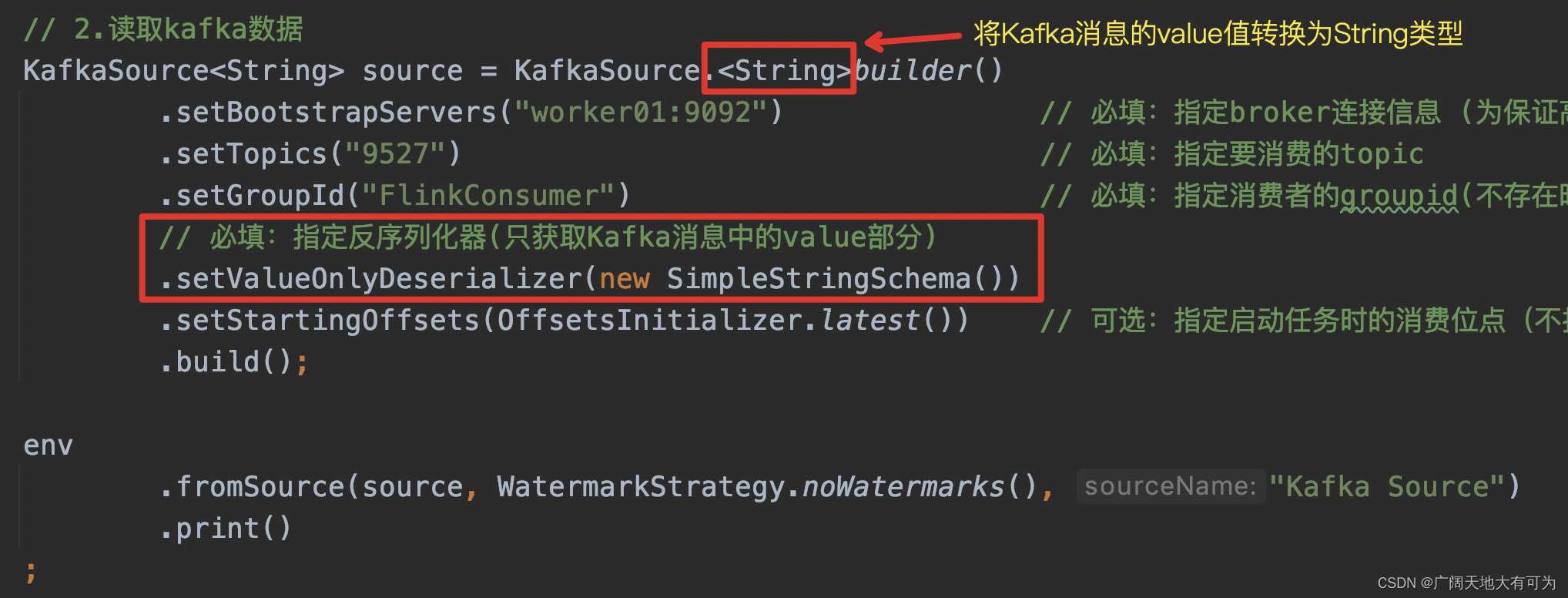 4.2、获取完整Kafka消息(key、value、Metadata)
4.2、获取完整Kafka消息(key、value、Metadata)
kafak消息格式:
key = {"nation":"蜀国"}
value = {"ID":整数}
public static void ParseMessageJSONKeyValue() throws Exception {// 1.获取执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2.读取kafka数据KafkaSource<ObjectNode> source = KafkaSource.<ObjectNode>builder().setBootstrapServers("worker01:9092") // 必填:指定broker连接信息 (为保证高可用,建议多指定几个节点).setTopics("9527") // 必填:指定要消费的topic.setGroupId("FlinkConsumer") // 必填:指定消费者的groupid(不存在时会自动创建)// 必填:指定反序列化器(将kafak消息解析为ObjectNode,json对象).setDeserializer(KafkaRecordDeserializationSchema.of(// includeMetadata = (true:返回Kafak元数据信息 false:不返回)new JSONKeyValueDeserializationSchema(true))).setStartingOffsets(OffsetsInitializer.latest()) // 可选:指定启动任务时的消费位点(不指定时,将默认使用 OffsetsInitializer.earliest()).build();env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source").print();// 3.触发程序执行env.execute();}
运行结果: 
常见报错:
Caused by: java.io.IOException: Failed to deserialize consumer record ConsumerRecord(topic = 9527, partition = 0, leaderEpoch = 0, offset = 1064, CreateTime = 1691668775938, serialized key size = 4, serialized value size = 9, headers = RecordHeaders(headers = [], isReadOnly = false), key = [B@5e9eaab8, value = [B@67390400).at org.apache.flink.connector.kafka.source.reader.deserializer.KafkaDeserializationSchemaWrapper.deserialize(KafkaDeserializationSchemaWrapper.java:57)at org.apache.flink.connector.kafka.source.reader.KafkaRecordEmitter.emitRecord(KafkaRecordEmitter.java:53)... 14 more
Caused by: org.apache.flink.shaded.jackson2.com.fasterxml.jackson.core.JsonParseException: Unrecognized token 'xxxx': was expecting (JSON String, Number, Array, Object or token 'null', 'true' or 'false')at [Source: (byte[])"xxxx"; line: 1, column: 5]报错原因:
出现这个报错,一般是使用flink读取fafka时,使用JSONKeyValueDeserializationSchema
来解析消息时,kafka消息中的key 或者 value 内容不符合json格式而造成的解析错误
例如下面这个格式,就会造成解析错误 key=1000,value=你好
那应该怎么解决呢?
1、如果有权限修改Kafka消息格式,可以将Kafka消息key&value内容修改为Json格式
2、如果没有权限修改Kafka消息格式(比如线上环境,修改比较困难),可以重新实现
JSONKeyValueDeserializationSchema类,根据所需格式来解析Kafka消息(可以参考源码)
4.3、自定义Kafka消息解析器
生产中对Kafka消息及解析的格式总是各种各样的,当flink预定义的解析器满足不了业务需求时,可以通过自定义kafka消息解析器来完成业务的支持
例如,当使用 MyJSONKeyValueDeserializationSchema 获取Kafka元数据时,只返回了 offset、topic、partition 三个字段信息,现在需要`kafka生产者写入数据时的timestamp`,就可以通过自定义kafka消息解析器来完成
代码示例:
// TODO 自定义Kafka消息解析器,在 metadata 中增加 timestamp字段
public class MyJSONKeyValueDeserializationSchema implements KafkaDeserializationSchema<ObjectNode>{private static final long serialVersionUID = 1509391548173891955L;private final boolean includeMetadata;private ObjectMapper mapper;public MyJSONKeyValueDeserializationSchema(boolean includeMetadata) {this.includeMetadata = includeMetadata;}@Overridepublic void open(DeserializationSchema.InitializationContext context) throws Exception {mapper = JacksonMapperFactory.createObjectMapper();}@Overridepublic ObjectNode deserialize(ConsumerRecord<byte[], byte[]> record) throws Exception {ObjectNode node = mapper.createObjectNode();if (record.key() != null) {node.set("key", mapper.readValue(record.key(), JsonNode.class));}if (record.value() != null) {node.set("value", mapper.readValue(record.value(), JsonNode.class));}if (includeMetadata) {node.putObject("metadata").put("offset", record.offset()).put("topic", record.topic()).put("partition", record.partition())// 添加 timestamp 字段.put("timestamp",record.timestamp());}return node;}@Overridepublic boolean isEndOfStream(ObjectNode nextElement) {return false;}@Overridepublic TypeInformation<ObjectNode> getProducedType() {return getForClass(ObjectNode.class);}}
运行结果:

5、起始消费位点应该如何设置
起始消费位点说明:
起始消费位点是指 启动flink任务时,应该从哪个位置开始读取Kafka的消息
下面介绍下常用的三个设置:
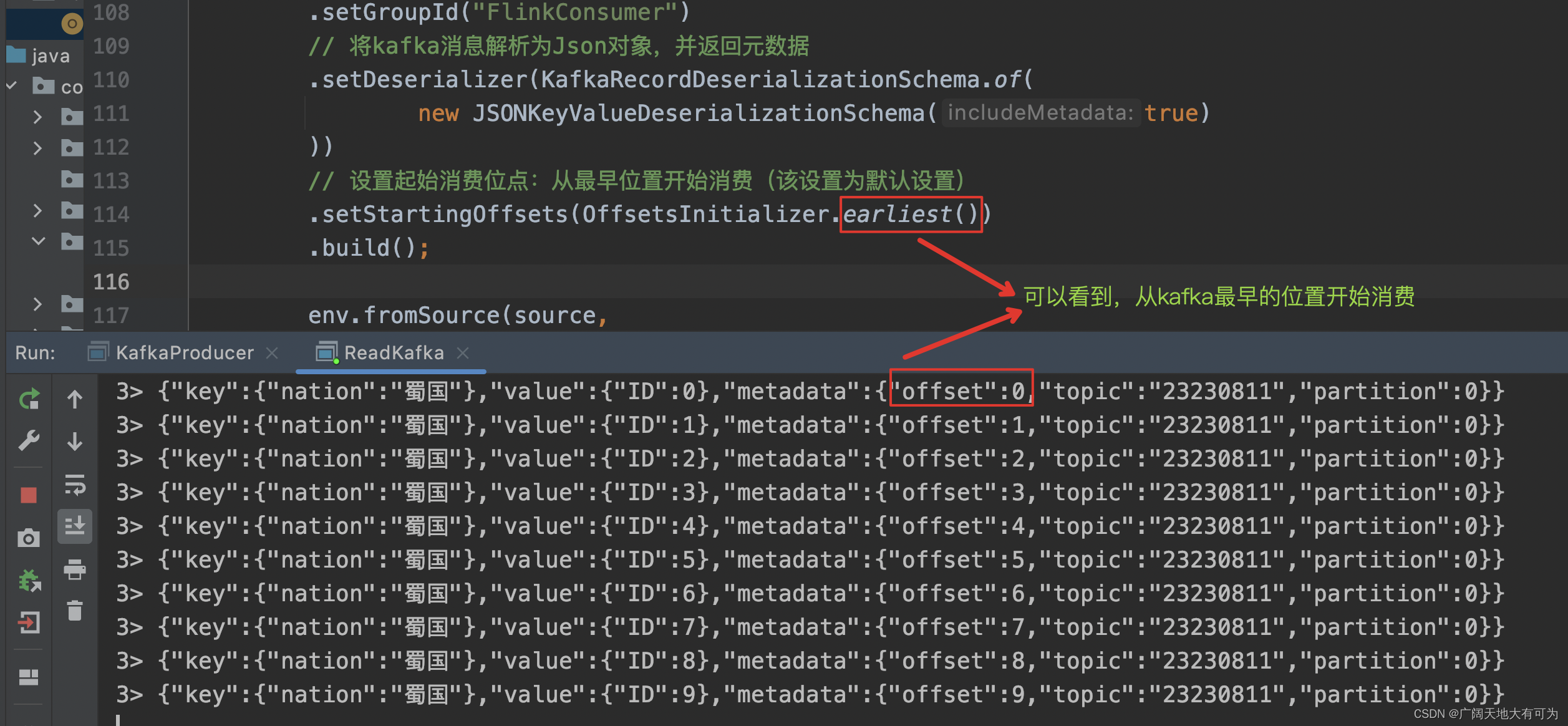
OffsetsInitializer.earliest() :
从最早位点开始消
这里的最早指的是Kafka消息保存的时长(默认为7天,生成环境各公司略有不同)
该这设置为默认设置,当不指定OffsetsInitializer.xxx时,默认为earliest()
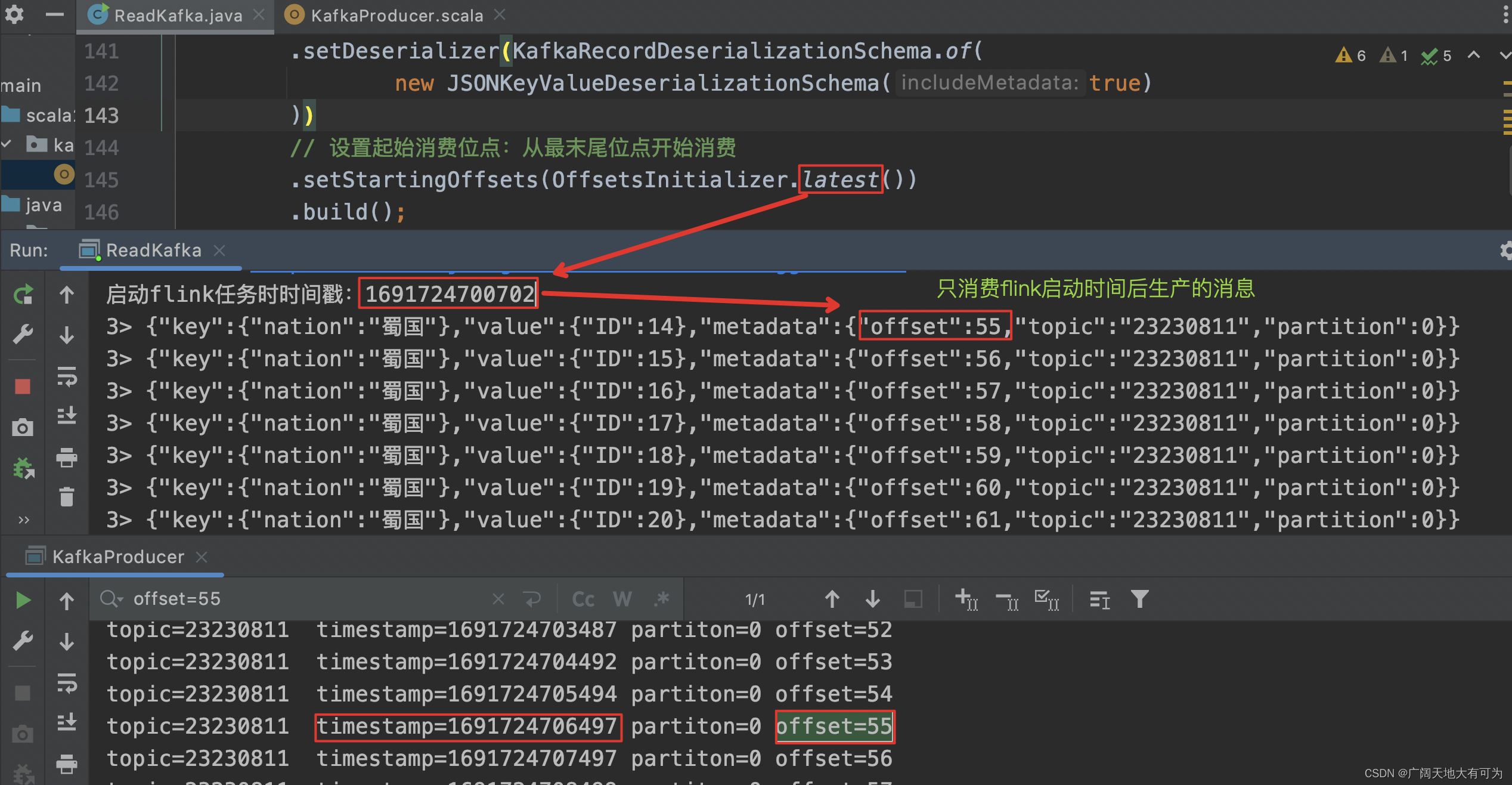
OffsetsInitializer.latest() :
从最末尾位点开始消费
这里的最末尾指的是flink任务启动时间点之后生产的消息
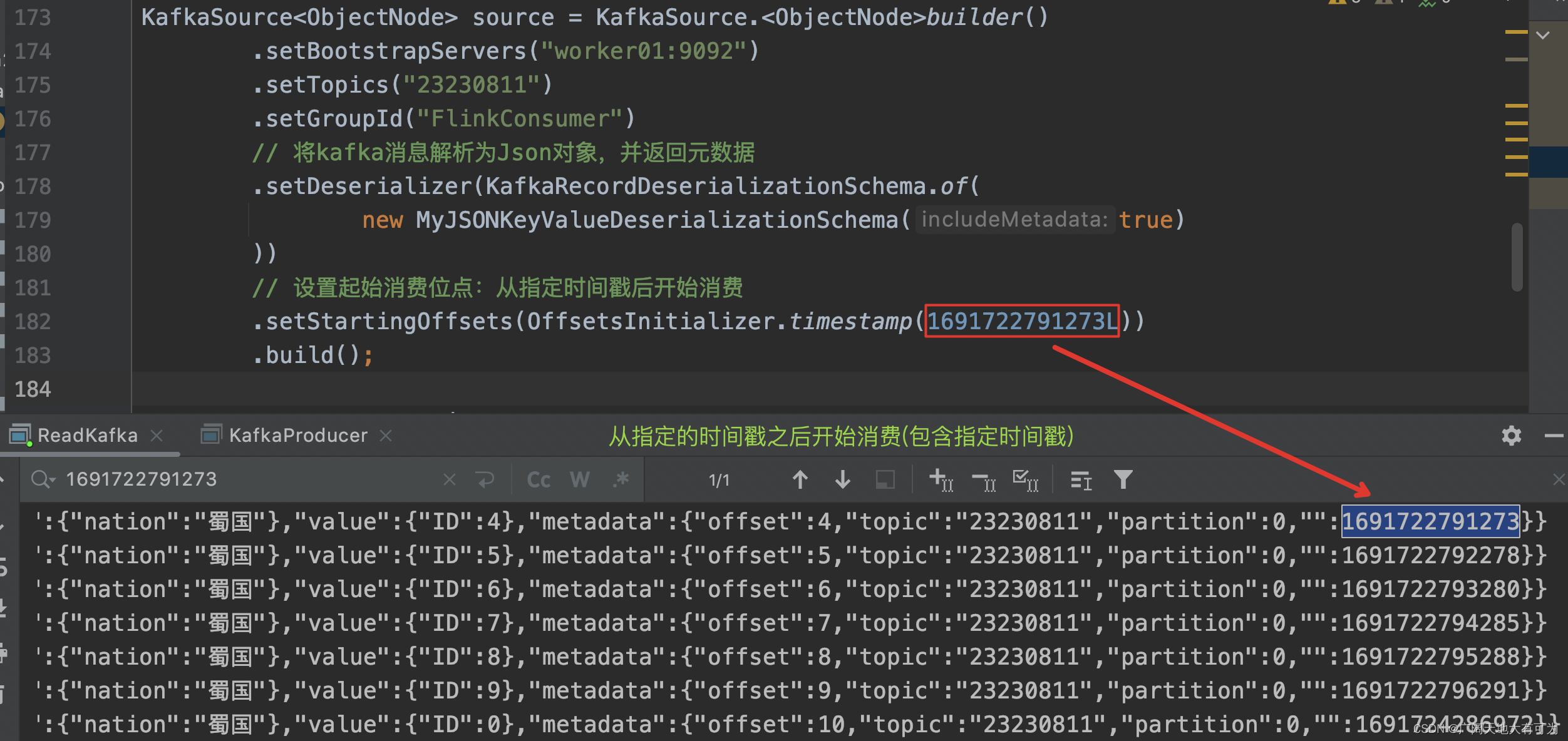
OffsetsInitializer.timestamp(时间戳) :
从时间戳大于等于指定时间戳(毫秒)的数据开始消费
下面用案例说明下,三种设置的效果,kafak生成10条数据,如下:
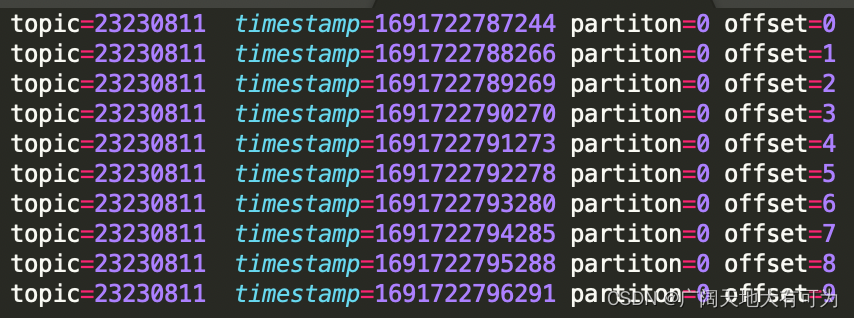 5.1、earliest()
5.1、earliest()
代码示例:
KafkaSource<ObjectNode> source = KafkaSource.<ObjectNode>builder().setBootstrapServers("worker01:9092").setTopics("23230811").setGroupId("FlinkConsumer")// 将kafka消息解析为Json对象,并返回元数据.setDeserializer(KafkaRecordDeserializationSchema.of(new JSONKeyValueDeserializationSchema(true)))// 设置起始消费位点:从最早位置开始消费(该设置为默认设置).setStartingOffsets(OffsetsInitializer.earliest()).build();运行结果:
5.2、latest()
代码示例:
KafkaSource<ObjectNode> source = KafkaSource.<ObjectNode>builder().setBootstrapServers("worker01:9092").setTopics("23230811").setGroupId("FlinkConsumer")// 将kafka消息解析为Json对象,并返回元数据.setDeserializer(KafkaRecordDeserializationSchema.of(new JSONKeyValueDeserializationSchema(true)))// 设置起始消费位点:从最末尾位点开始消费.setStartingOffsets(OffsetsInitializer.latest()).build();运行结果:
5.3、timestamp()
代码示例:
KafkaSource<ObjectNode> source = KafkaSource.<ObjectNode>builder().setBootstrapServers("worker01:9092").setTopics("23230811").setGroupId("FlinkConsumer")// 将kafka消息解析为Json对象,并返回元数据.setDeserializer(KafkaRecordDeserializationSchema.of(new MyJSONKeyValueDeserializationSchema(true)))// 设置起始消费位点:从指定时间戳后开始消费.setStartingOffsets(OffsetsInitializer.timestamp(1691722791273L)).build();运行结果:
6、Kafka分区扩容了,该怎么办 —— 动态分区检查
在flink1.13的时候,如果Kafka分区扩容了,只有通过重启flink任务,才能消费到新增分区的数据,小编就曾遇到过上游业务部门的kafka分区扩容了,并没有通知下游使用方,导致实时指标异常,甚至丢失了数据。
在flink1.17的时候,可以通过`开启动态分区检查`,来实现不用重启flink任务,就能消费到新增分区的数据
开启分区检查:(默认不开启)
KafkaSource.builder().setProperty("partition.discovery.interval.ms", "10000"); // 每 10 秒检查一次新分区代码示例:
KafkaSource<ObjectNode> source = KafkaSource.<ObjectNode>builder().setBootstrapServers("worker01:9092").setTopics("9527").setGroupId("FlinkConsumer")// 将kafka消息解析为Json对象,并返回元数据.setDeserializer(KafkaRecordDeserializationSchema.of(new JSONKeyValueDeserializationSchema(true)))// 设置起始消费位点:从最末尾位点开始消费.setStartingOffsets(OffsetsInitializer.latest())// 开启动态分区检查(默认不开启).setProperty("partition.discovery.interval.ms", "10000") // 每 10 秒检查一次新分区.build();7、在加载KafkaSource时提取事件时间&添加水位线
可以在 fromSource(source,WatermarkStrategy,sourceName) 时,提取事件时间和制定水位线生成策略
注意:当不指定事件时间提取器时,Kafka Source 使用 Kafka 消息中的时间戳作为事件时间
7.1、使用内置的单调递增的水位线生成器 + kafka timestamp 为事件时间
代码示例:
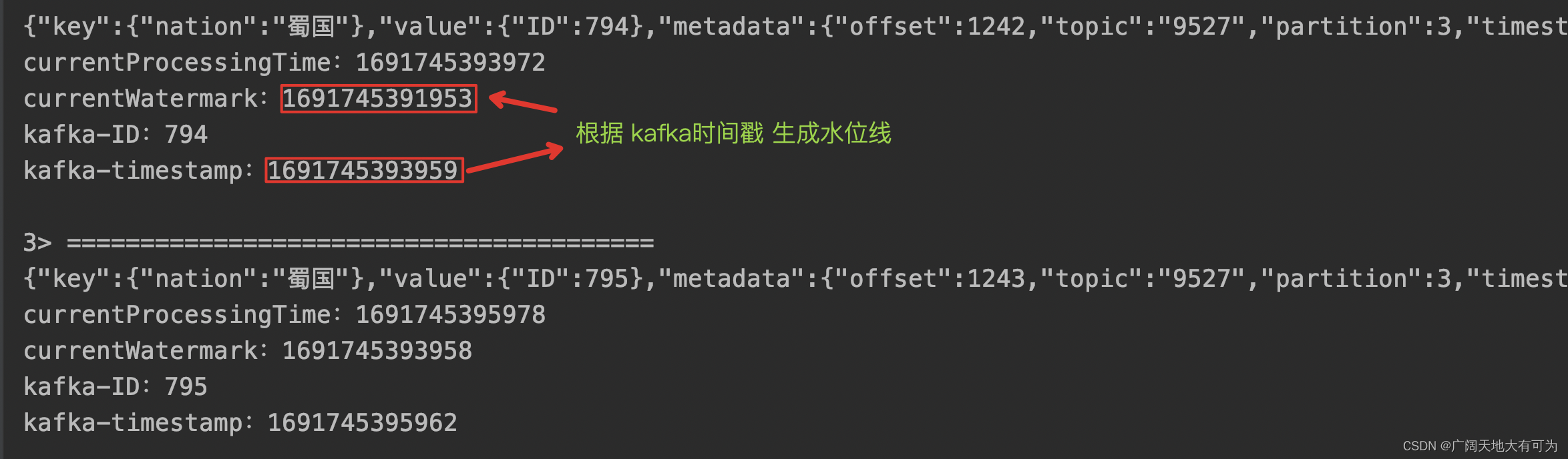
// 在读取Kafka消息时,提取事件时间&插入水位线public static void KafkaSourceExtractEventtimeAndWatermark() throws Exception {// 1.获取执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2.读取kafka数据KafkaSource<ObjectNode> source = KafkaSource.<ObjectNode>builder().setBootstrapServers("worker01:9092").setTopics("9527").setGroupId("FlinkConsumer")// 将kafka消息解析为Json对象,并返回元数据.setDeserializer(KafkaRecordDeserializationSchema.of(new MyJSONKeyValueDeserializationSchema(true)))// 设置起始消费位点:从最末尾位点开始消费.setStartingOffsets(OffsetsInitializer.latest()).build();env.fromSource(source,// 使用内置的单调递增的水位线生成器(默认使用 kafka的timestamp作为事件时间)WatermarkStrategy.forMonotonousTimestamps(),"Kafka Source")// 通过 ProcessFunction 查看提取的事件时间和水位线信息.process(new ProcessFunction<ObjectNode, String>() {@Overridepublic void processElement(ObjectNode kafkaJson, ProcessFunction<ObjectNode, String>.Context ctx, Collector<String> out) throws Exception {// 当前处理时间long currentProcessingTime = ctx.timerService().currentProcessingTime();// 当前水位线long currentWatermark = ctx.timerService().currentWatermark();StringBuffer record = new StringBuffer();record.append("========================================\n");record.append(kafkaJson + "\n");record.append("currentProcessingTime:" + currentProcessingTime + "\n");record.append("currentWatermark:" + currentWatermark + "\n");record.append("kafka-ID:" + Long.parseLong(kafkaJson.get("value").get("ID").toString()) + "\n");record.append("kafka-timestamp:" + Long.parseLong(kafkaJson.get("metadata").get("timestamp").toString()) + "\n");out.collect(record.toString());}}).print();// 3.触发程序执行env.execute();}
运行结果:
7.2、使用内置的单调递增的水位线生成器 + kafka 消息中的 ID字段 为事件时间
代码示例:
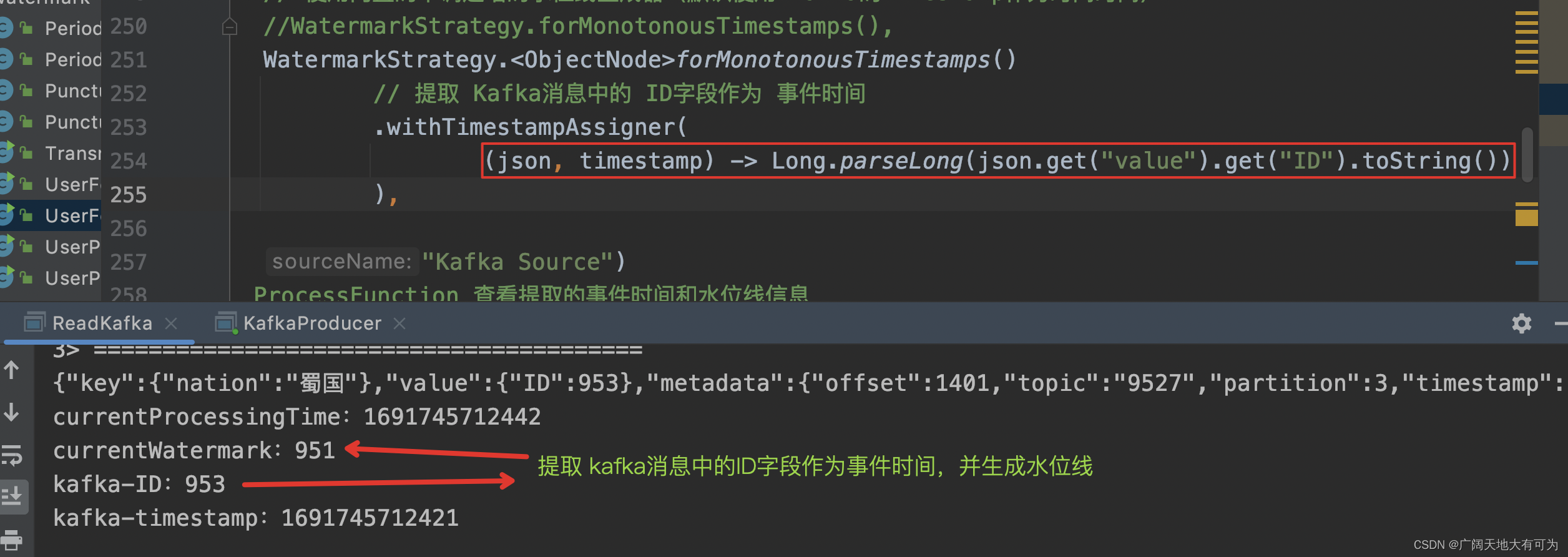
// 在读取Kafka消息时,提取事件时间&插入水位线public static void KafkaSourceExtractEventtimeAndWatermark() throws Exception {// 1.获取执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2.读取kafka数据KafkaSource<ObjectNode> source = KafkaSource.<ObjectNode>builder().setBootstrapServers("worker01:9092").setTopics("9527").setGroupId("FlinkConsumer")// 将kafka消息解析为Json对象,并返回元数据.setDeserializer(KafkaRecordDeserializationSchema.of(new MyJSONKeyValueDeserializationSchema(true)))// 设置起始消费位点:从最末尾位点开始消费.setStartingOffsets(OffsetsInitializer.latest()).build();env.fromSource(source,// 使用内置的单调递增的水位线生成器(使用 kafka消息中的ID字段作为事件时间)WatermarkStrategy.<ObjectNode>forMonotonousTimestamps()// 提取 Kafka消息中的 ID字段作为 事件时间.withTimestampAssigner((json, timestamp) -> Long.parseLong(json.get("value").get("ID").toString())),"Kafka Source")// 通过 ProcessFunction 查看提取的事件时间和水位线信息.process(new ProcessFunction<ObjectNode, String>() {@Overridepublic void processElement(ObjectNode kafkaJson, ProcessFunction<ObjectNode, String>.Context ctx, Collector<String> out) throws Exception {// 当前处理时间long currentProcessingTime = ctx.timerService().currentProcessingTime();// 当前水位线long currentWatermark = ctx.timerService().currentWatermark();StringBuffer record = new StringBuffer();record.append("========================================\n");record.append(kafkaJson + "\n");record.append("currentProcessingTime:" + currentProcessingTime + "\n");record.append("currentWatermark:" + currentWatermark + "\n");record.append("kafka-ID:" + Long.parseLong(kafkaJson.get("value").get("ID").toString()) + "\n");record.append("kafka-timestamp:" + Long.parseLong(kafkaJson.get("metadata").get("timestamp").toString()) + "\n");out.collect(record.toString());}}).print();// 3.触发程序执行env.execute();}
运行结果:
相关文章:
4.3、Flink任务怎样读取Kafka中的数据
目录 1、添加pom依赖 2、API使用说明 3、这是一个完整的入门案例 4、Kafka消息应该如何解析 4.1、只获取Kafka消息的value部分 4.2、获取完整Kafka消息(key、value、Metadata) 4.3、自定义Kafka消息解析器 5、起始消费位点应该如何设置 5.1、earliest() 5.2、lat…...

C语言实例_和校验算法
一、算法介绍 和校验(Checksum)是一种简单的纠错算法,用于检测或验证数据传输或存储过程中的错误。它通过对数据进行计算并生成校验和,然后将校验和附加到数据中,在接收端再次计算校验和并进行比较,以确定…...
安全加密框架图——Oracle安全开发者
Oracle安全开发者 ACLs 设计 ACLs(访问控制列表)时,可以根据以下思路进行设计: 所有者文件权限:确定文件的所有者能够对文件执行哪些操作,如读取、写入、执行等。这可以根据文件的性质和拥有者的职责来决…...

Android databinding 被多次定义
一、报错: AndroidStudio运行代码时,编译器报 Type androidx.databinding.Bindable is defined multiple times...... 二、解决: 点击 Build -> Clean Project,关闭编译器再打开即可。 三、解决过程: 在使用Andro…...

云原生周刊:Kubernetes v1.28 新特性一览 | 2023.8.14
推荐一个 GitHub 仓库:Fast-Kubernetes。 Fast-Kubernetes 是一个涵盖了 Kubernetes 的实验室(LABs)的仓库。它提供了关于 Kubernetes 的各种主题和组件的详细内容,包括 Kubectl、Pod、Deployment、Service、ConfigMap、Volume、…...

机器学习之分类模型
机器学习之分类模型 概述分类模型逻辑回归最近邻分类朴素贝叶斯支持向量机决策树随机森林多层感知机基于集成学习的分类模型VotingBaggingStackingBlendingBoosting 概述 机器学习分类模型通过训练集进行学习,建立一个从输入空间 X X X到输出空间 Y Y Y(…...

学习Vue:创建第一个Vue实例
当您开始探索 Vue.js,第一步就是创建一个 Vue 实例。Vue 实例是 Vue.js 应用程序的核心构建块,它使您能够将数据与用户界面连接起来,实现动态交互。在本文中,我们将详细介绍如何创建您的第一个 Vue 实例。 步骤1:引入 …...
JavaFx基础学习【二】:Stage
一、介绍 窗口Stage为图中标绿部分: 实际为如下部分: 不同的操作系统表现的样式不同,以下都是以Windows操作系统为例,为了使大家更清楚Stage是那部分,直接看以下图,可能更清楚: 有点潦草&…...

C语言——动态内存函数(malloc、calloc、realloc、free)
了解动态内存函数 前言:一、malloc函数二、calloc函数三、realloc函数四、free函数 前言: 在C语言中,动态内存函数是块重要的知识点。以往,我们开辟空间都是固定得,数组编译结束后就不能继续给它开辟空间了࿰…...

Redis数据结构——Redis简单动态字符串SDS
定义 众所周知,Redis是由C语言写的。 对于字符串类型的数据存储,Redis并没有直接使用C语言中的字符串。 而是自己构建了一个结构体,叫做“简单动态字符串”,简称SDS,比C语言中的字符串更加灵活。 SDS的结构体是这样的…...

【计算机网络】TCP协议超详细讲解
文章目录 1. TCP简介2. TCP和UDP的区别3. TCP的报文格式4. 确认应答机制5. 超时重传6. 三次握手7. 为什么两次握手不行?8. 四次挥手9. 滑动窗口10. 流量控制11. 拥塞控制12. 延时应答13. 捎带应答14. 面向字节流15. TCP的连接异常处理 1. TCP简介 TCP协议广泛应用于可靠性要求…...

Salesforce特别元数据部署技巧
标准的picklist字段部署 <?xml version"1.0" encoding"UTF-8" standalone"yes"?> <Package xmlns"http://soap.sforce.com/2006/04/metadata"><types><members>Opportunity.StageName</members><…...

[前端系列第2弹]CSS入门教程:从零开始学习Web页面的样式和布局
在这篇文章中,我将介绍CSS的基本概念、语法、选择器、属性和值,以及如何使用它们来定义Web页面的外观和布局。还将给一些简单而实用的例子,可以跟着我一步一步地编写自己的CSS样式表。 目录 一、什么是CSS 二、CSS的语法 三、CSS的选择器 …...

非计算机科班如何丝滑转码?
转码,也就转行为程序员,已成为当今数字化时代的一种重要技能。随着科技的发展,越来越多的人开始意识到掌握编程技能的重要性,而非计算机科班出身的朋友们,想要丝滑转码,也许可以从以下几个方面入手。 一、明…...

亿发创新中医药信息化解决方案,自动化煎煮+调剂,打造智能中药房
传统中医药行业逐步复兴,同时互联网科技和人工智能等信息科技助力中医药行业逐步实现数字化转型。利用互联网、物联网、大数据等科技,实现现代科学与传统中医药的结合,提供智能配方颗粒调配系统、中药自动化调剂系统、中药煎配智能管理系统、…...
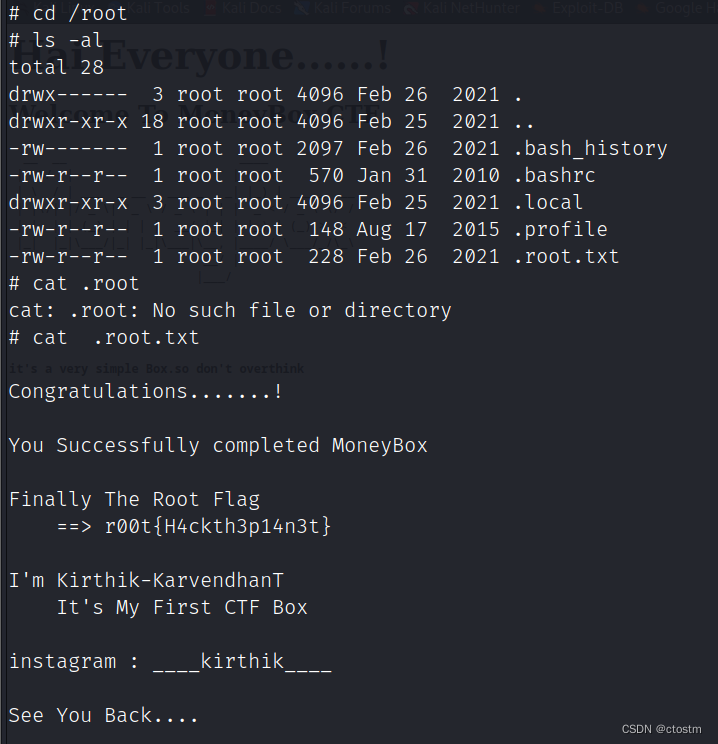
Vulnhub: MoneyBox: 1靶机
kali:192.168.111.111 靶机:192.168.111.194 信息收集 端口扫描 nmap -A -sC -v -sV -T5 -p- --scripthttp-enum 192.168.111.194 ftp匿名登录发现trytofind.jpg 目录爆破发现blogs目录 gobuster dir -u http://192.168.111.194 -w /usr/share/word…...

[国产MCU]-BL602开发实例-LCD1602 I2C驱动
LCD1602 I2C驱动 文章目录 LCD1602 I2C驱动1、LCD1602/LCD2004介绍2、硬件准备3、驱动实现本文将详细介绍如何在K210中驱动LCD1602/LCD2004 I2C显示屏。 1、LCD1602/LCD2004介绍 LCD1602液晶显示器是广泛使用的一种字符型液晶显示模块。它是由字符型液晶显示屏(LCD)、控制驱…...
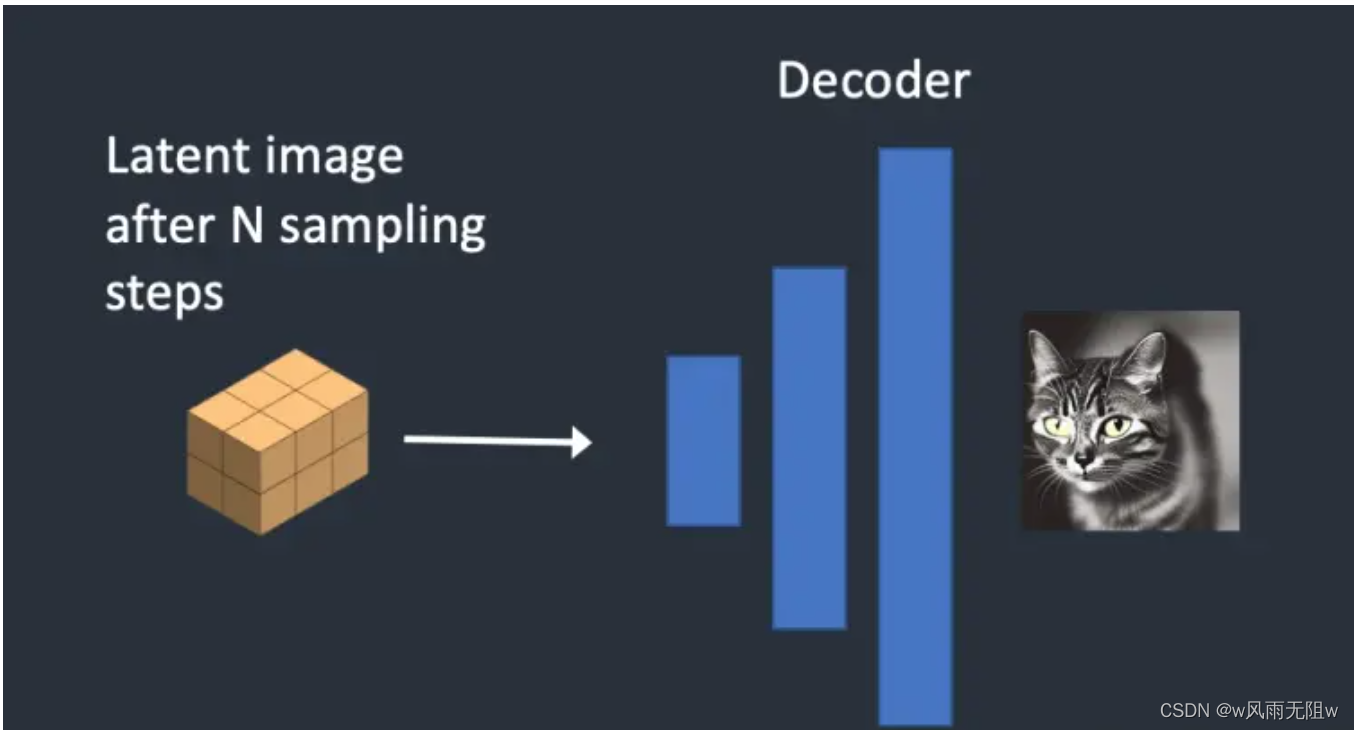
AI 绘画Stable Diffusion 研究(七) 一文读懂 Stable Diffusion 工作原理
大家好,我是风雨无阻。 本文适合人群: 想要了解AI绘图基本原理的朋友。 对Stable Diffusion AI绘图感兴趣的朋友。 本期内容: Stable Diffusion 能做什么 什么是扩散模型 扩散模型实现原理 Stable Diffusion 潜扩散模型 Stable Diffu…...

URLSearchParams:JavaScript中的URL查询参数处理工具
文章目录 导言:一、URLSearchParams的来历二、URLSearchParams的作用三、URLSearchParams的方法和属性四、使用示例五、注意事项六、结论参考资料 导言: 在Web开发中,处理URL查询参数是一项常见的任务。为了简化这一过程,JavaScr…...

1.4 数据库管理与优化
数据库管理与优化 文章目录 数据库管理与优化1. 数据库概述1.1 数据库的定义和作用1.2 数据库管理系统(DBMS) 2. 数据库模型2.1 关系型数据库**2.2 非关系型数据库 3. 数据库设计3.1 数据库设计原则3.2 数据库设计步骤 4. 数据库优化4.1 数据库性能优化4…...

Godot PCK解包原理与专业逆向实践指南
1. 这不是“解压软件”,而是Godot游戏逆向工程的第一把手术刀你刚下载了一款用Godot引擎开发的独立游戏,想研究它的UI动效逻辑,或者复刻一段粒子特效,又或者只是单纯好奇——那个让你反复通关三次的像素风过场动画,图层…...

AMLP框架实战:基于MACE构建高精度机器学习势函数
1. 项目概述:当机器学习势函数遇上自动化管道在计算化学和材料科学领域,我们长久以来面临着一个核心矛盾:精度与效率的权衡。密度泛函理论(DFT)能提供接近实验的精度,但计算成本高昂,通常只能处…...

Yokogawa AAI835-H50/K4A00模拟输入/输出模块
Yokogawa AAI835-H50/K4A00 模拟输入/输出模块产品特点:通道配置:共8个通道,含4路模拟输入和4路模拟输出。信号类型:所有通道均支持4-20mA标准电流信号。HART通信:支持HART协议,可与智能现场设备双向数字通…...

Unity iOS构建报错SDK version is 0的根因与精准修复
1. 这个报错不是Unity在“发脾气”,而是工程配置在“装死”刚接手一个老项目,打开Unity编辑器,点Build Settings准备打包iOS,结果弹出一行红字:“SDK version is 0, cannot build”。我第一反应是——这什么鬼…...

SpeakingURL版本升级指南:从旧版本迁移到最新版本的完整教程
SpeakingURL版本升级指南:从旧版本迁移到最新版本的完整教程 【免费下载链接】speakingurl Generate a slug – transliteration with a lot of options 项目地址: https://gitcode.com/gh_mirrors/sp/speakingurl SpeakingURL是一款强大的URL友好化工具&…...

Linux平台终极Jellyfin客户端:如何用Tsukimi打造专业级媒体中心体验?
Linux平台终极Jellyfin客户端:如何用Tsukimi打造专业级媒体中心体验? 【免费下载链接】tsukimi A simple third-party Jellyfin client for Linux 项目地址: https://gitcode.com/gh_mirrors/ts/tsukimi 你是否厌倦了网页版Jellyfin的笨重体验&am…...

终极Windows风扇控制指南:FanControl让你的电脑安静又高效
终极Windows风扇控制指南:FanControl让你的电脑安静又高效 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...

5分钟掌握m4s-converter:将B站缓存视频无损转换为MP4的终极指南
5分钟掌握m4s-converter:将B站缓存视频无损转换为MP4的终极指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾在B站缓存了…...

Win11Debloat:如何用自动化配置工具实现Windows系统的智能优化
Win11Debloat:如何用自动化配置工具实现Windows系统的智能优化 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutte…...

3步掌握B站缓存视频转换:m4s-converter完整指南
3步掌握B站缓存视频转换:m4s-converter完整指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否在B站缓存了大量珍贵的学习资料…...