pytorch入门-TensorBoard和Transforms
TensorBoard
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms# python的用法 -》 tensor数据类型
# 通过transforms.ToTensor 去解决两个问题
# 1. transforms该如何使用(python)
# 2. 为什么需要Tensor的数据类型# 就对路径 = D:\PyCharm\learn_torch\dataset\train\ants_image\0013035.jpg
# 相对路径 = dataset\train\ants_image\0013035.jpg
img_path = r"dataset\train\ants_image\0013035.jpg"
img_path_abs = r"D:\PyCharm\learn_torch\dataset\train\ants_image\0013035.jpg"img = Image.open(img_path)
writer = SummaryWriter("logs")
# print(img)# 1. transforms该如何使用(python)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
# print(tensor_img)writer.add_image("Tensor_img", tensor_img)writer.close()Transform
from PIL import Image#from PIL import Image 是正确导入PIL(Python Imaging Library)包中的 Image 模块的方式。通过这个导入语句,你可以使用 Image 模块进行各种图像操作,如打开、操作和保存图像。
from torch.utils.tensorboard import SummaryWriter#torch.utils.tensorboard 模块提供了在 PyTorch 中使用 TensorBoard 的功能。在这个模块中,SummaryWriter 类是用于创建和管理 TensorBoard 日志的关键类。
from torchvision import transforms #torchvision.transforms 模块是 PyTorch 提供的图像预处理工具集,它提供了各种常用的图像预处理操作和转换器。通过导入 transforms 模块,你可以使用其中的转换器来对图像进行常见的预处理操作,如缩放、裁剪、旋转、翻转、标准化等。writer = SummaryWriter("logs") #SummaryWriter("logs") 是一个用于创建 TensorBoard 的 SummaryWriter 对象的函数。它接受一个可选的参数,表示 TensorBoard 日志文件的保存路径。
img = Image.open(r"练手数据集\val\bees\6a00d8341c630a53ef00e553d0beb18834-800wi.jpg")#代码中的 Image.open 是 PIL 库中的一个函数,用于打开图像文件。它接受一个参数,表示要打开的图像文件路径。
print(img)# ToTensor ToTensor 是一个常用的数据转换操作,用于将 PIL 图像或 NumPy 数组转换为 PyTorch 的张量(tensor)。
trans_totensor = transforms.ToTensor()# 定义 ToTensor 转换
img_tensor = trans_totensor(img)# 将图像转换为张量
writer.add_image("ToTensor", img_tensor)#writer.add_image 是一个用于将图像添加到 TensorBoard 可视化的函数。通过传递一个图像张量给这个函数,你可以在 TensorBoard 中观察、比较和分析图像数据。# Normalize Normalize 是一个常用的数据转换操作,用于将张量中的数值进行标准化。标准化可以使数据在一定范围内进行缩放,并且具有零均值和单位方差。
print(img_tensor[0][0][0])#显示标准化后的图像张量中的某个像素的值
trans_norm = transforms.Normalize([0.5, 0.5, 0.5],[0.5, 0.5, 0.5])#创建了一个 Normalize 类型的转换器 trans_norm。这个转换器可以将图像张量进行标准化,使其均值为 0.5,标准差为 0.5。 # 定义标准化转换
img_norm = trans_norm(img_tensor)# 进行标准化
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm)# Resize 是一个常用的图像预处理操作,它用于调整图像的尺寸。通过 Resize 操作,你可以将图像调整为特定的宽度和高度,或者按比例缩放。
print(img.size)
trans_resize = transforms.Resize((512,512)) #通过 transforms.Resize() 创建了一个名为 trans_resize 的转换器,将图像的尺寸调整为 (512, 512)。
# img PIL -> resize -> img_resize PIL
img_resize = trans_resize(img) # 将转换器应用到图像上
# img_resize PIL -> totensor -> img_resize totensor
img_resize = trans_totensor(img_resize)#将经过 transforms.Resize() 转换器调整大小后的图像 img_resize 转换为张量。
writer.add_image("Resize",img_resize,0)print(img_resize)# compose - resize - 2 #transforms.Compose 是 torchvision.transforms 模块中的一个函数,用于将多个图像预处理操作串联在一起形成一个组合转换器。
trans_resize_2 = transforms.Resize(512)
# PIL -> PIL -> tensor
trans_compose = transforms.Compose([trans_resize_2, trans_totensor])#是一个 PyTorch 中的图像转换函数,用于将多个图像转换操作组合在一起,以便同时应用于图像数据
img_resize_2 = trans_compose(img)
writer.add_image("Resize",img_resize_2,1)# RandomCrop transforms.RandomCrop 是 torchvision.transforms 模块中的一个转换器,用于随机裁剪图像。
trans_random = transforms.RandomCrop(512)# 定义随机裁剪转换器
trans_compose_2 = transforms.Compose([trans_random, trans_totensor])#创建一个组合转换器 trans_compose_2,其中包含两个转换器 trans_random 和 trans_totensor。
for i in range(10):img_crop = trans_compose_2(img)## 应用组合转换器writer.add_image("RandomCrop", img_crop,i)writer.close()torchvision数据集的使用
import torchvision
from torch.utils.tensorboard import SummaryWriterdataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()
])train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform, download=True)# print(test_set[0])
# print(test_set.classes)
#
# img,target = test_set[0]
# print(img)
# print(target)
# print(test_set.classes[target])
# img.show()
# print(test_set[0])writer = SummaryWriter("p10")
for i in range(10):img, target = test_set[i]writer.add_image("test_set", img, i)writer.close()dataloader的使用
import torchvision#准备测试数据集
from torch.utils.data import DataLoader#通过使用DataLoader,您可以自动将数据集分成小的批次,这对于训练深度学习模型非常重要。DataLoader还提供了多线程数据加载和预取功能,以提高数据加载的效率。
from torch.utils.tensorboard import SummaryWritertest_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())#这行代码使用torchvision.datasets.CIFAR10函数创建了一个test_data对象,表示CIFAR-10数据集的测试集。该数据集包含图像和相应的标签,用于评估模型的性能。
# 代码中的参数如下所示:
# "./dataset":指定数据集文件存储的路径。可以根据自己的需要进行更改。
# train=False:表示加载的是测试集,而不是训练集。
# transform=torchvision.transforms.ToTensor():指定了数据集的转换操作,将图像转换为Tensor类型。test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False)#这行代码创建了一个名为test_loader的数据加载器,用于加载测试数据集。
# 参数解释如下:
# dataset=test_data:指定要加载的数据集对象,这里是test_data,即CIFAR-10的测试集数据。
# batch_size=64:指定每个批次的大小为64,即每次加载64个样本。
# shuffle=True:表示在每个epoch开始时是否打乱数据集的顺序。这里将数据打乱以增加随机性。
# num_workers=0:指定用于数据加载的子进程数量。默认为0,表示只使用主进程进行数据加载。
# drop_last=False:指定是否丢弃最后一个不完整的批次。这里设置为False,表示即使最后一个批次样本数量不足64个,也要加载。# 测试数据集中第一张图片及target
img, target = test_data[0]#返回的img变量将包含图像数据,而target变量将包含该图像对应的标签。
print(img.shape)
print(target)#遍历test_loader数据加载器中的所有批次,并将批次中的图像数据添加到SummaryWriter对象中,以便在TensorBoard中可视化。# 在每个epoch中的每个批次中,它执行以下操作:
#
# 从test_loader加载器中获取一个批次的数据,包括图像和相应的标签,通过for data in test_loader: img, targets = data这行代码实现。
#
# 利用writer.add_images方法,将当前批次的图像添加到TensorBoard中。这行代码使用了"Epoch:{}"作为标题,其中的epoch变量表示当前的epoch数。img是当前批次的图像数据,step用于标识每个批次的索引。
#
# 更新step的值,以进行下一个批次的计数。
writer = SummaryWriter("dataloader")
for epoch in range(2):step = 0for data in test_loader:img,targets = data# print(img.shape)# print(targets)writer.add_images("Epoch:{}".format(epoch),img,step)step = step +1writer.close()相关文章:
pytorch入门-TensorBoard和Transforms
TensorBoard from PIL import Image from torch.utils.tensorboard import SummaryWriter from torchvision import transforms# python的用法 -》 tensor数据类型 # 通过transforms.ToTensor 去解决两个问题 # 1. transforms该如何使用(python) # 2. …...

【java】Java基础——接口和实现
当一个类实现一个接口时,必须提供接口中定义的所有方法的具体实现,除非这个类是抽象类。默认方法:default修饰接口中的方法,可实现方法体,在实现接口的类中可以不重写该方法 // 定义一个接口,接口不关心方…...

JetPack Compose 学习笔记(持续整理中...)
1.为什么要学? 1.命令式和声明式 UI大战,个人认为命令式UI自定义程度较高,能更深入到性能,内存优化方面,而申明式UI 是现在主流的设计,比如React,React Native,Flutter,Swift UI等等,现在性能也逐渐在变得更好 2.还有一个原因compose 是KMM 是完整跨平台的UI基础 3.…...

遍历集合List的五种方法以及如何在遍历集合过程中安全移除元素
一、遍历集合List的五种方法 测试数据 List<String> list new ArrayList<>(); list.add("A");list.add("B");list.add("C");1. 普通for循环 普通for循环,通过索引遍历 for (int i 0; i < list.size(); i) {Syst…...

【SQL应知应会】索引(二)• MySQL版
欢迎来到爱书不爱输的程序猿的博客, 本博客致力于知识分享,与更多的人进行学习交流 本文收录于SQL应知应会专栏,本专栏主要用于记录对于数据库的一些学习,有基础也有进阶,有MySQL也有Oracle 索引 • MySQL版 前言一、索引1.简介2.创建2.1 索引…...

Android 简单的视频、图片压缩工具
首页需要压缩的工具包 1.Gradle implementation com.iceteck.silicompressorr:silicompressor:2.2.3 2.添加相关权限(手机得动态申请权限) <uses-permission android:name"android.permission.READ_EXTERNAL_STORAGE"/> <uses-p…...

信息论、推理和机器学习算法之间交叉的经典例子
信息论、推理和机器学习算法之间交叉的经典例子: 熵和信息增益在决策树学习中的应用。信息增益利用熵的概念来评估特征的分类能力,从而指导决策树的增长。 交叉熵在神经网络训练中的广泛使用。它结合信息论与最大似然推断,用于度量预测分布与真实分布之间的距离。 变分推断常被…...
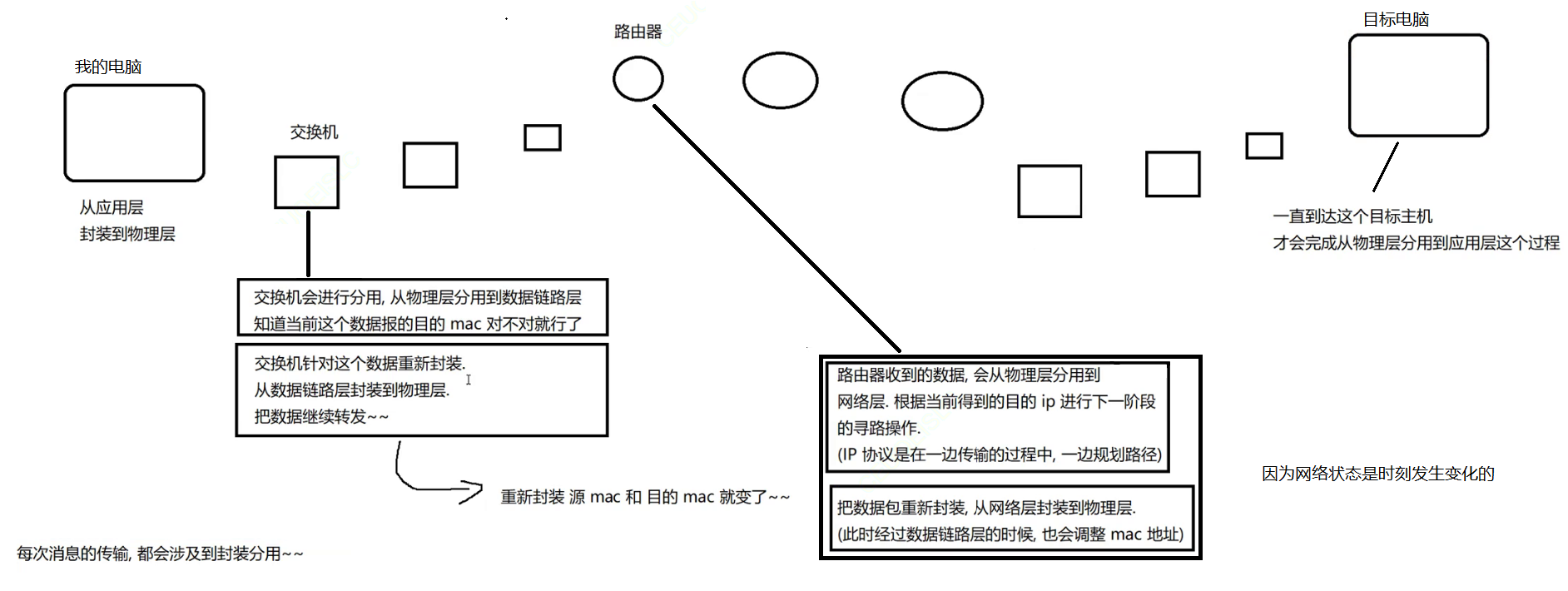
【多线程】网络原理初识
网络原理初识 1. 网络发展史1.2 独立模式1.3 网络互联1.3 局域网1.4 广域网 2. 网络通信基础2.1 IP地址2.2 端口号2.3 认识协议2.4 五元组2.5 协议分层2.5.1 什么是协议分层2.5.2 协议分层的好处2.5.2 OSI七层模型2.5.3 TCP/IP五层模型 2.6 封装和分用2.6.1 封装2.6.1.1 应用层…...

Android之ADB常用命令
15、查看ipv6 是否使能 sysctl -a | grep ipv6 | grep disable 13、以太网获取Ip、网关、子网掩码、域名等 adb shell 网卡信息:ifconfig eth0 dns1:getprop net.dns1 dns2:getprop net.dns2 12、屏幕分辨率:wm size 11、…...
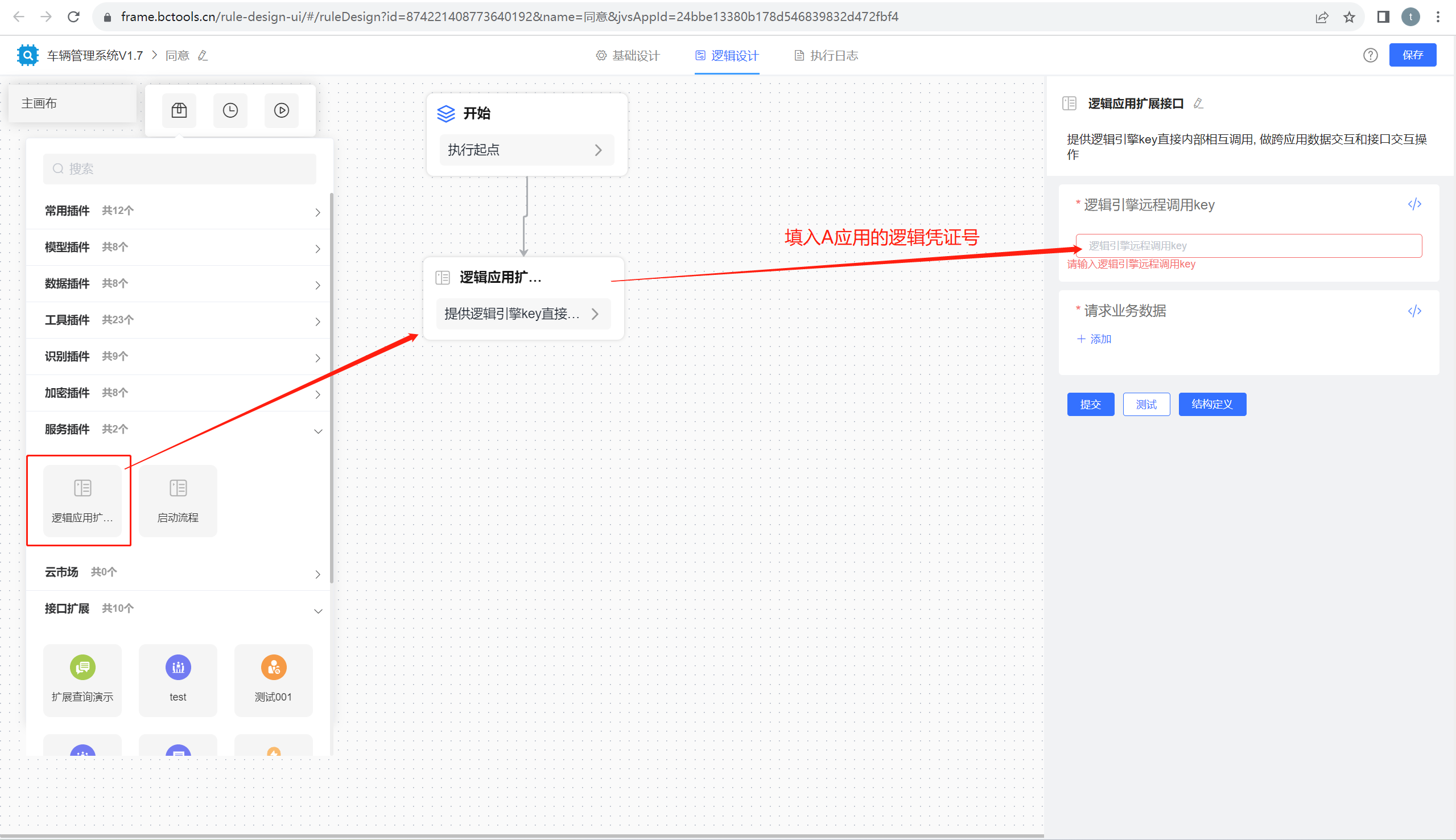
低代码开发工具:JVS轻应用之间如何实现数据的调用?
在低代码开发平台中,如何实现应用之间的数据共享呢?最标准的方式是通过接口,本文介绍JVS轻应用如何实现将数据通过API输出、轻应用如何实现体内API数据的获取?实现方式如下图所示,不管是数据提供方,还是数据…...
在Java中对XML的简单应用
XML 数据传输格式1 XML 概述1.1 什么是 XML1.2 XML 与 HTML 的主要差异1.3 XML 不是对 HTML 的替代 2 XML 语法2.1 基本语法2.2 快速入门2.3 组成部分2.3.1 文档声明格式属性 2.3.2 指令(了解):结合CSS2.3.3 元素2.3.4 属性**XML 元素 vs. 属…...

Linu学习笔记——常用命令
Linux 常用命令全拼: Linux 常用命令全拼 | 菜鸟教程 一、切换root用户 1.给root用户设置密码 sudo passwd root 2.输入密码,并确认密码 3.切换到root用户 su:Swith user(切换用户) su root 二、切换目录 目录结构:Linux 系…...
PLUS操作流程、应用与实践,多源不同分辨率数据的处理、ArcGIS的应用、PLUS模型的应用、InVEST模型的应用
PLUS模型是由中国地质大学(武汉)地理与信息工程学院高性能空间计算智能实验室开发,是一个基于栅格数据的可用于斑块尺度土地利用/土地覆盖(LULC)变化模拟的元胞自动机(CA)模型。PLUS模型集成了基于土地扩张分析的规则挖掘方法和基于多类型随机…...
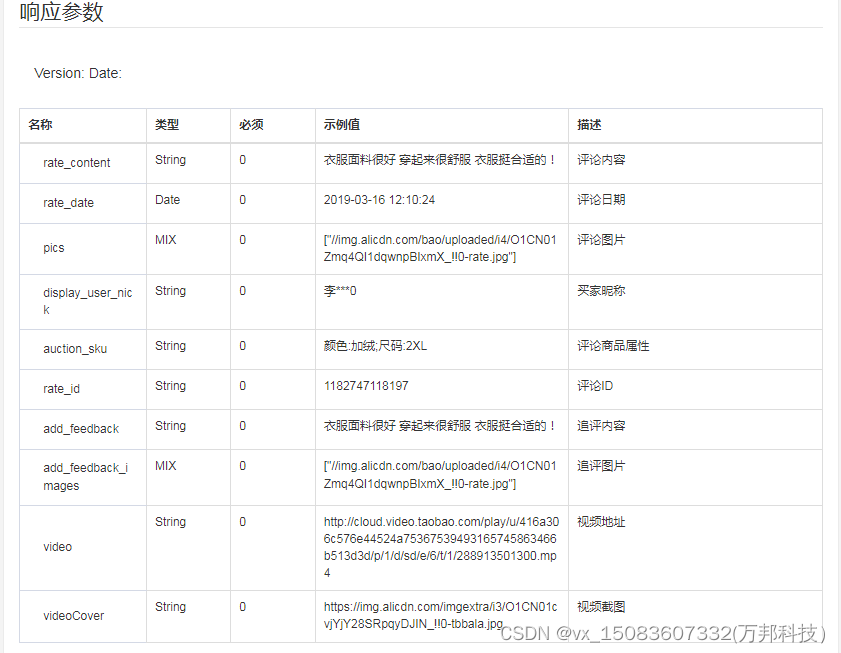
item_review-获得淘宝商品评论
一、接口参数说明: item_review-获得淘宝商品评论,点击更多API调试,请移步注册API账号点击获取测试key和secret 公共参数 请求地址: https://api-gw.onebound.cn/taobao/item_review 名称类型必须描述keyString是调用key(点击获…...
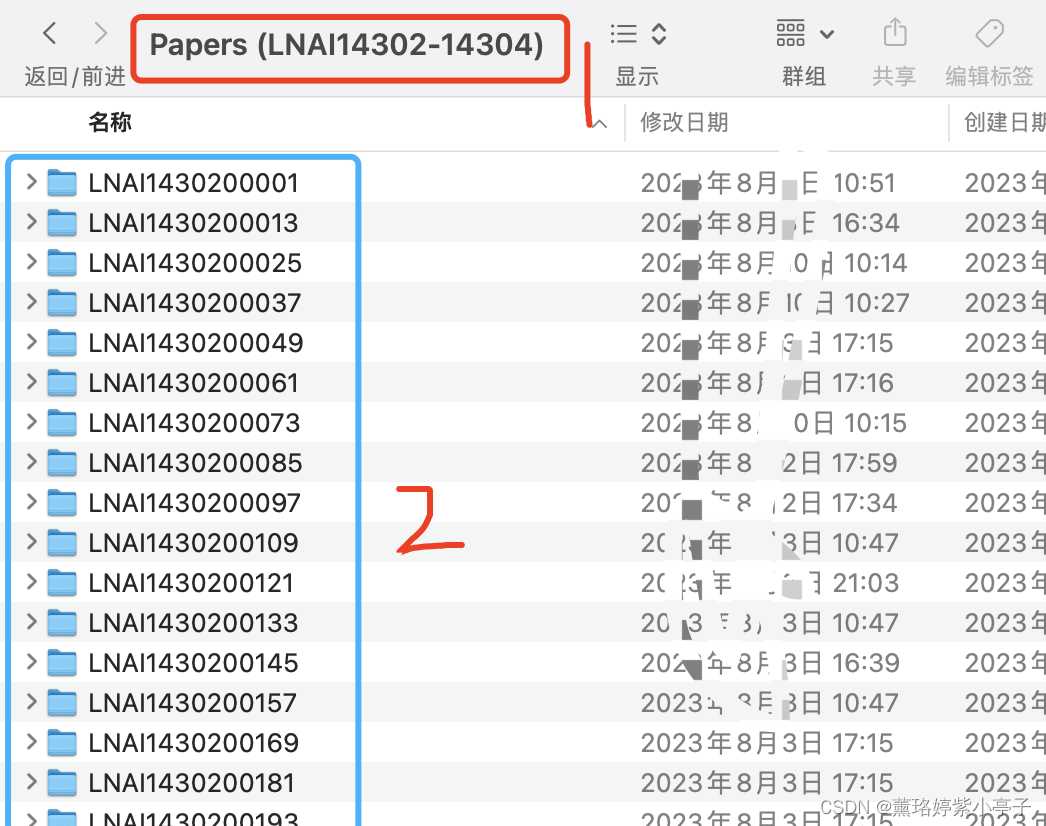
如何读取文件夹内的诸多文件,并选择性的保留部分文件
目录 问题描述: 问题解决: 问题描述: 当前有一个二级文件夹,第一层是文件夹名称是“Papers(LNAI14302-14304)",第二级文件夹目录名称如下图蓝色部分所示。第三层为存放的文件,如下下图所示,每一个文件中,均存放三个文件,分别为copyright.pdf, submission.pdf, s…...
每天一道leetcode:1129. 颜色交替的最短路径(图论中等广度优先遍历)
今日份题目: 给定一个整数 n,即有向图中的节点数,其中节点标记为 0 到 n - 1。图中的每条边为红色或者蓝色,并且可能存在自环或平行边。 给定两个数组 redEdges 和 blueEdges,其中: redEdges[i] [ai, bi…...
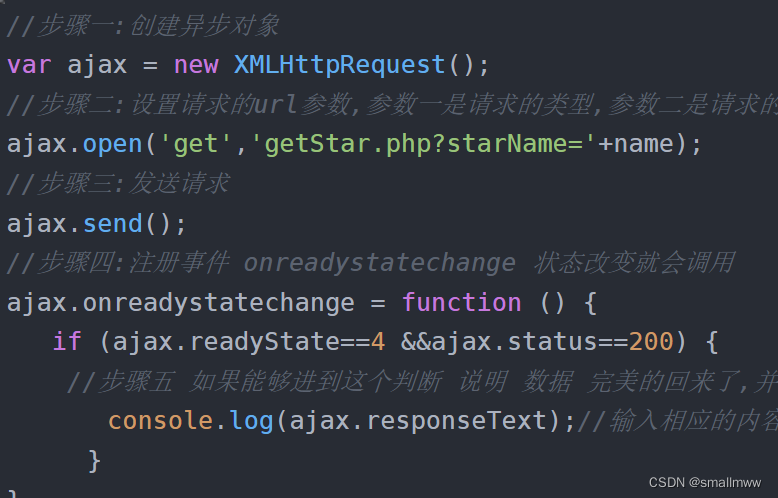
原生js发送ajax请求---ajax请求篇(一)
在原生js中我们使用的是XMLHttpRequest对象来发送ajax请求 主要步骤就是: 1.创建XMLHTTPRequest对象 2.使用open方法设置和服务器的交互信息 3.设置发送的数据,开始和服务器端交互 4.注册事件 5.更新界面 (1) get方式 //步骤一…...

【ARM 嵌入式 编译系列 2.1 -- GCC 编译参数学习】
文章目录 1.1 GCC 编译参数1.1.1 GCC arm-noe-eabi- 介绍1.1.1.1 ARM 和 Thumb 指令集区别1.1.2 GCC CFLAGS 介绍1.1.3 GCC LDFLAGS 介绍1.1.4 CXXFLAGS 介绍上篇文章:ARM 嵌入式 编译系列 2 – GCC 编译过程介绍 下篇文章:ARM 嵌入式 C 入门及渐进 3 – GCC attribute((weak…...

C++教程 - How to C++系列专栏第3篇
关于专栏 这个专栏是优质的C教程专栏,如果你还没看过第0篇,点击C教程 - How to C系列专栏第0篇去第0篇 本专栏一致使用操作系统:macOS Ventura,代码编辑器:CLion,C编译器:Clang 感谢一路相伴…...
使用Edge和chrom扩展工具(GoFullPage)实现整页面截图或生成PDF文件
插件GoFullPage下载:点击免费下载 如果在浏览网页时,有需要整个页面截图或导出PDF文件的需求,这里分享一个Edge浏览器的扩展插件:GoFullPage。 这个工具可以一键实现页面从上到下滚动并截取。 一、打开“管理扩展”(…...

Python strip 与 rstrip 函数区别
Python strip 与 rstrip 函数区别 文章目录Python strip 与 rstrip 函数区别一、核心作用二、基础语法三、基础使用示例四、指定删除特定字符五、常用业务场景一、核心作用 函数作用范围strip()移除字符串首尾空白字符rstrip()仅移除字符串右侧末尾字符,左侧保持不…...

终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接
终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在数字化制造和工程设计领域,STL到STEP转换已成为连接3D…...

3大技术突破:重新定义Switch游戏安装性能极限
3大技术突破:重新定义Switch游戏安装性能极限 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer Awoo Installer是一款专为破解版Nintendo…...

自然语言处理的实战项目:从0到1搭建属于自己的文本分类系统
对于软件测试从业者而言,日常工作中我们每天都会接触大量的文本数据:缺陷管理系统中的bug描述、测试用例的步骤说明、用户反馈的问题报告、需求文档的规格描述,甚至是接口返回的异常信息文本。这些非结构化文本往往隐含着关键业务信息&#x…...

XZ9971,60V,5A,NMOS 封装:SOT223
封装:SOT223类型:NVDS:60V VGS: 20V ID:5ARDS(ON):10V <50mΩRDS(ON):4.5V <60mΩ型号: XZ9971 封装:SOT223类型&…...

从自然语言到可视化洞察:ChartGPT如何用AI重构数据图表生成范式
从自然语言到可视化洞察:ChartGPT如何用AI重构数据图表生成范式 【免费下载链接】chart-gpt AI tool to build charts based on text input 项目地址: https://gitcode.com/gh_mirrors/ch/chart-gpt 在数据驱动的决策时代,业务人员与技术团队之间…...
)
不止是移动:用UE5.1蓝图优化你的MetaHuman性能(头发渲染、LOD设置避坑指南)
不止是移动:用UE5.1蓝图优化你的MetaHuman性能(头发渲染、LOD设置避坑指南)在虚幻引擎5.1中,MetaHuman已经成为了数字人创作的重要工具。然而,许多开发者在实现了基础移动控制后,往往会忽视对MetaHuman资产…...
)
DeepSeek熔断决策延迟超23ms?,基于eBPF实时观测的熔断器内核态性能瓶颈诊断指南(限内部技术圈流通)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek熔断降级方案 DeepSeek大模型服务在高并发、低质量请求或底层依赖异常时,需具备快速响应的熔断与降级能力,以保障系统整体可用性与资源稳定性。该方案基于响应延迟、错误…...

Beyond Compare 5密钥生成技术深度解密:从RSA加密到完整激活解决方案
Beyond Compare 5密钥生成技术深度解密:从RSA加密到完整激活解决方案 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 在软件开发与系统维护领域,Beyond Compare 5作为文件…...

Mapbox Studio Classic快速上手:10分钟创建你的第一个地图项目
Mapbox Studio Classic快速上手:10分钟创建你的第一个地图项目 【免费下载链接】mapbox-studio-classic 项目地址: https://gitcode.com/gh_mirrors/ma/mapbox-studio-classic Mapbox Studio Classic是一款强大的地图设计工具,通过直观的界面和简…...