【 BERTopic应用 02/3】 分析卡塔尔世界杯推特数据

摄影:Fauzan Saari on Unsplash
一、说明
这是我们对世界杯推特数据分析的第3部分,我们放弃了。我们将对我们的数据进行情绪分析,以了解人们对卡塔尔世界杯的感受。我将在这里介绍的一个功能强大的工具包是Hugging Face,您可以在其中找到各种模型,任务,数据集,它还为刚开始学习机器学习的人提供课程。在这篇文章中,我们将使用一个情绪分析模型和拥抱面孔令牌来完成我们的任务。
二、情绪分析
情感分析是使用自然语言处理(NLP)来识别,提取和研究情感状态和主观信息。我们可以将这种技术应用于客户评论和调查响应,以对我对产品或服务的意见。
让我们看几个例子:
- 我喜欢今天的天气!标记: 正面
- 天气预报说明天会多云。标签: 中性
- 雨不会停。野餐计划被推迟了。无赖。。。标签: 负面
上面的例子清楚地显示了推文的极性,因为文本的结构很简单。以下是一些难以轻易发现情绪的挑战性案例。
- 我不喜欢下雨天。(否定)
- 我喜欢在刮风的时候跑步,但不会推荐给我的朋友。(有条件的积极情绪,难以分类)
- 一杯好咖啡真的需要时间,因为它让我等了30分钟才喝一口。(讽刺)
现在我们已经介绍了什么是情绪分析以及如何应用这种技术,让我们学习如何在我们的 Twitter 数据上实现这种方法。
遇见“推特-罗伯塔-基地-情绪-最新"
用于情绪分析的 Twitter-roBERTa-base 是一个 RoBERTa-base 模型,从 124 年 2018 月到 2021 年 <> 月在 ~<>M 条推文上训练,并使用 TweetEval 基准对情绪分析进行了微调。我不会深入探讨 RoBERTa-base 模型的细节,但简单地说,RoBERTa 从预训练过程中删除了下一句预测 (NSP) 任务,并引入了动态掩码,因此掩码标记在训练期间会发生变化。对于更详细的评论,我建议阅读Suleiman Khan的文章和Chandan Durgia的文章。
要启动此模型,我们可以使用由Hugging Face团队创建的推理API。推理 API 允许您对 NLP、音频和计算机视觉中的任务进行文本文本和评估 80, 000 多个机器学习模型。查看此处以获取详细文档。它很容易使用推理API,您只需这样做即可获得您的拥抱脸令牌(它是免费的)。首先,您应该创建一个拥抱脸帐户并注册。然后,单击您的个人资料并转到设置。
- 读取:如果您只需要从拥抱人脸中心读取内容(例如,在下载私有模型或进行推理时),请使用此角色。
- 写入:如果需要创建内容或将内容推送到存储库(例如,在训练模型或修改模型卡时),请使用此令牌。
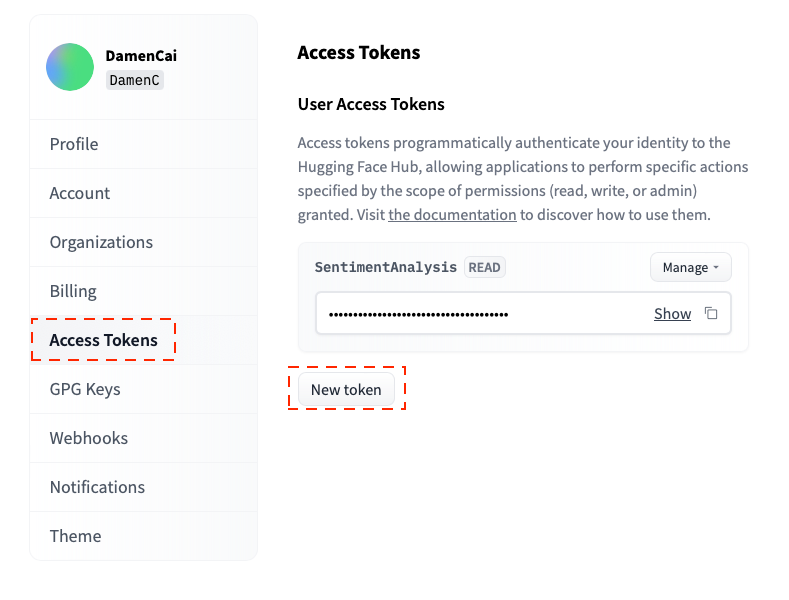
由作者创建

User access tokens
现在我们有了我们需要的一切,让我们做一些分析!
三、准备我们的数据
首先,我们需要导入一些依赖项并加载数据。对我们拥有的 10, 000 条推文运行情绪分析需要一些时间。出于演示目的,我们将从池中随机抽取 300 条推文。
import pandas as pd
import pickle
import requests
import randomwith open('world_cup_tweets.pkl', 'rb') as f:data = pickle.load(f)tweets = data.Tweet_processed.to_list()
tweets = random.sample(tweets, 300)四、运行分析
然后我们将语言模型和我们的拥抱脸令牌分别传递给变量。
model = "cardiffnlp/twitter-roberta-base-sentiment-latest"
hf_token = "YOUR OWN TOKEN"我们定义了一个采用单个参数的分析函数:数据。此函数将我们的 Twitter 数据转换为 JSON 格式,其中包含对传递给函数的输入数据的模型推理结果。
API_URL = "https://api-inference.huggingface.co/models/" + model
headers = {"Authorization": "Bearer %s" % (hf_token)}def analysis(data):payload = dict(inputs=data, options=dict(wait_for_model=True))response = requests.post(API_URL, headers=headers, json=payload)return response.json()我们初始化一个空列表,以存储每条推文的情绪分析结果。我们对列表中的每条推文使用循环。然后我们使用 try-except 块技术:
- 对于可以分析的推文,我们调用我们定义的函数分析,将当前推文作为输入,并从返回的列表中检索第一个结果。此结果应为字典列表,每个词典都包含情绪标签和分数。我们使用内置的 max 函数在情绪结果中查找得分最高的字典。我们将一个新词典附加到tweets_analysis列表中,其中包含推文及其相应的标签,其中包含得分最高的情绪。
- 对于无法分析的推文,我们使用 except 块,该块捕获 try 块中发生的任何异常并打印错误消息。情绪分析功能可能无法分析某些推文,因此包含此块以处理这些情况。
tweets_analysis = []
for tweet in tweets:try:sentiment_result = analysis(tweet)[0]top_sentiment = max(sentiment_result, key=lambda x: x['score']) # Get the sentiment with the higher scoretweets_analysis.append({'tweet': tweet, 'sentiment': top_sentiment['label']})except Exception as e:print(e)然后我们可以将数据加载到数据框中并查看一些初步结果。
# Load the data in a dataframe
df = pd.DataFrame(tweets_analysis)# Show a tweet for each sentiment
print("Positive tweet:")
print(df[df['sentiment'] == 'positive']['tweet'].iloc[0])
print("\nNeutral tweet:")
print(df[df['sentiment'] == 'neutral']['tweet'].iloc[0])
print("\nNegative tweet:")
print(df[df['sentiment'] == 'negative']['tweet'].iloc[0])# Outputs: (edited by author to remove vulgarity)Positive tweet:
Messi, you finally get this World Cup trophy. Happy ending and you are officially called球王 Neutral tweet:
Nicholas the Dolphin picks 2022 World Cup Final winner Negative tweet:
Yall XXXX and this XXXX world cup omg who XXXX CARESSS我们还应该使用 groupby 函数来查看样本中有多少推文是正数或负数。
sentiment_counts = df.groupby(['sentiment']).size()
print(sentiment_counts)# Outputs:
sentiment
negative 46
neutral 63
positive 166
dtype: int64既然我们在这里,为什么不使用饼图来可视化结果:
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(6,6), dpi=100)
ax = plt.subplot(111)
sentiment_counts.plot.pie(ax=ax, autopct='%1.1f%%', startangle=270, fontsize=12, label="")由作者创建
似乎大多数人对卡塔尔世界杯感到满意。伟大!
人们在正面和负面推文中谈论什么?我们可以使用词云来显示这些组中的关键字。
# pip install first if you have not installed wordcloud in your environment from wordcloud import WordCloud
from wordcloud import STOPWORDS# Wordcloud with positive tweets
positive_tweets = df[df['sentiment'] == 'positive']['tweet']
stop_words = ["https", "co", "RT"] + list(STOPWORDS)
positive_wordcloud = WordCloud(max_font_size=50, max_words=50, background_color="white", stopwords = stop_words).generate(str(positive_tweets))
plt.figure()
plt.title("Positive Tweets - Wordcloud")
plt.imshow(positive_wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()# Wordcloud with negative tweets
negative_tweets = df[df['sentiment'] == 'negative']['tweet']
stop_words = ["https", "co", "RT"] + list(STOPWORDS)
negative_wordcloud = WordCloud(max_font_size=50, max_words=50, background_color="white", stopwords = stop_words).generate(str(negative_tweets))
plt.figure()
plt.title("Negative Tweets - Wordcloud")
plt.imshow(negative_wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
由作者创建

五、总结
现在我希望你已经学会了如何在拥抱脸中使用推理 API 对推文进行情感分析。这是一个功能强大的工具,高度适用于各个领域。关注我以获取更多想法和技术。
相关文章:
【 BERTopic应用 02/3】 分析卡塔尔世界杯推特数据
摄影:Fauzan Saari on Unsplash 一、说明 这是我们对世界杯推特数据分析的第3部分,我们放弃了。我们将对我们的数据进行情绪分析,以了解人们对卡塔尔世界杯的感受。我将在这里介绍的一个功能强大的工具包是Hugging Face,您可以在…...
变量声明)
TypeScript教程(三)变量声明
一、变量声明 变量是一种使用方便的占位符,用于引用计算机内存地址,可以将变量看做存储数据的容器 命名规则: 1.变量名称可以包含数字和字母 2.除了下划线_和美元$符号外,不能包含其他特殊字符,包括空格 3.变量名…...

【数据结构】堆的实现,堆排序以及TOP-K问题
目录 1.堆的概念及结构 2.堆的实现 2.1初始化堆 2.2销毁堆 2.3取堆顶元素 2.4返回堆的大小 2.5判断是否为空 2.6打印堆 2.7插入元素 2.8堆的向上调整 2.9弹出元素 2.10堆的向下调整 3. 建堆时间复杂度 4. 堆的应用 4.1 堆排序 4.2 TOP-K问题 1.堆的概念及结构 …...
释放马氏距离的力量:用 Python 探索多元数据分析
一、说明 马哈拉诺比斯距离(Mahalanobis Distance)是一种测量两个概率分布之间距离的方法。它是基于样本协方差矩阵的函数,用于评估两个向量之间的相似程度。Mahalanobis Distance考虑了数据集中各个特征之间的协方差,因此比欧氏距…...
【不限于联想Y9000P电脑关盖再打开时黑屏的解决办法】
不限于联想Y9000P电脑关盖再打开时黑屏的解决办法 问题的前言问题的出现问题拟解决 问题的前言 事情发生在昨天,更新了Win11系统后: 最惹人注目的三处地方就是: 1.可以查看时间的秒数了; 2.右键展示的内容变窄了; 3.按…...
策略模式实战应用
场景 假设做了个卖课网站,会员等级分为月vip、年vip、终生vip,每个等级买课的优惠力度不一样,传统的写法肯定是一堆的 if-else,现在使用策略模式写出代码实现 代码实现 策略模式的核心思想就是对扩展开放,对修改关闭…...

JAVA集合-Map
// 【Map】:双列集合,键值对形式存储,映射关系(kay,value) // 实现:HashMap // 子接口:SortedMap Map的子接口 // 实现类:TreeMap // HashMap // 1。可以插入null // …...

利用Simulink Test进行模型单元测试 - 1
1.搭建用于测试的简单模型 随手搭建了一个demo模型MilTestModel,模型中不带参数 2.创建测试框架 1.模型空白处右击 测试框架 > 为‘MilTestModel’创建 菜单 2.在创建测试框架对话框中,点击OK,对应的测试框架MilTestMode_Harness1就自动…...

深入探讨代理技术:保障网络安全与高效爬虫
1. Socks5代理与IP代理的区别与应用 Socks5代理和IP代理是代理技术中的两个重要方面,它们有着不同的特点和应用场景。Socks5代理是一种协议,支持TCP和UDP流量传输,适用于需要实时数据传输的场景,例如在线游戏或实时通信应用。而I…...
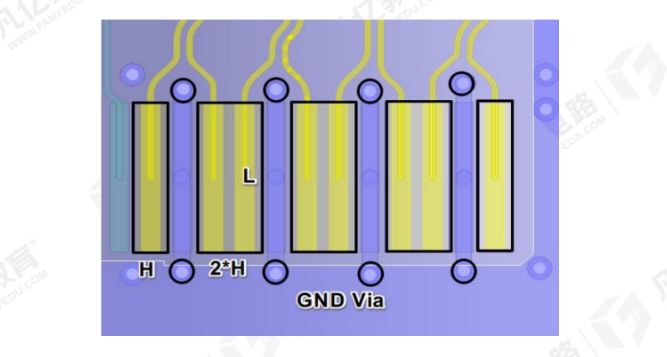
HDMI接口的PCB布局布线要求
高清多媒体接口(High Definition Multimedia Interface),简称:HDMI,是一种全数字化视频和声音发送接口,可以发送未压缩的音频及视频信号。随着技术的不断提升,HDMI的传输速率也不断的提升&#…...
)
Linux tar包安装 Prometheus 和 Grafana(知识点:systemd Unit/重定向)
0. 介绍 用tar包的方式安装 Prometheus 和 Grafana Prometheus:开源的监控方案Grafana:将Prometheus的数据可视化平台 Prometheus已经有了查询功能为什么还需要grafana呢?Prometheus基于promQL这一SQL方言,有一定门槛!Grafana基于浏览器的操作与可视化图表大大降低了理解难…...
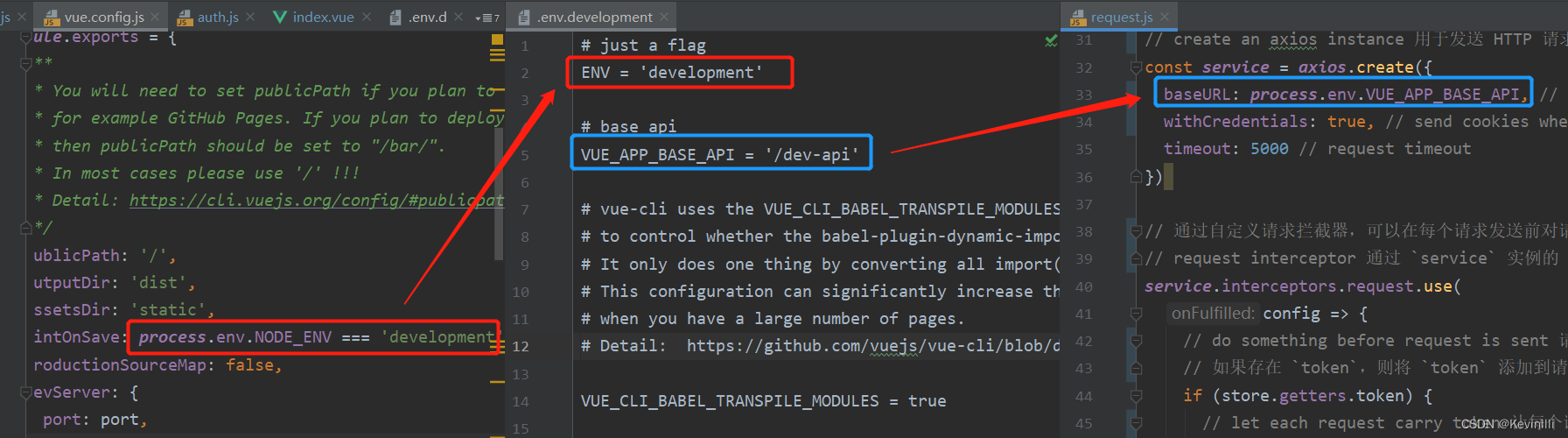
【Vue框架】用户和请求
前言 在上一篇 【Vue框架】Vuex状态管理 针对Vuex状态管理以getters.js进行说明,没有对其中state引入的对象进行详细介绍,因为整体都比较简单,也就不对全部做详细介绍了;但其中的user.js涉及到获取用户的信息、前后端请求的token…...
NGINX组件(rewrite)
一、location匹配的规则和优先级(*) URI:统一资源标识符,是一种字符串标识,用于标识抽象的或者是物理资源;如:文件、图片、视频等 nginx中的URI匹配的是:网址”/“后的路径 如&…...
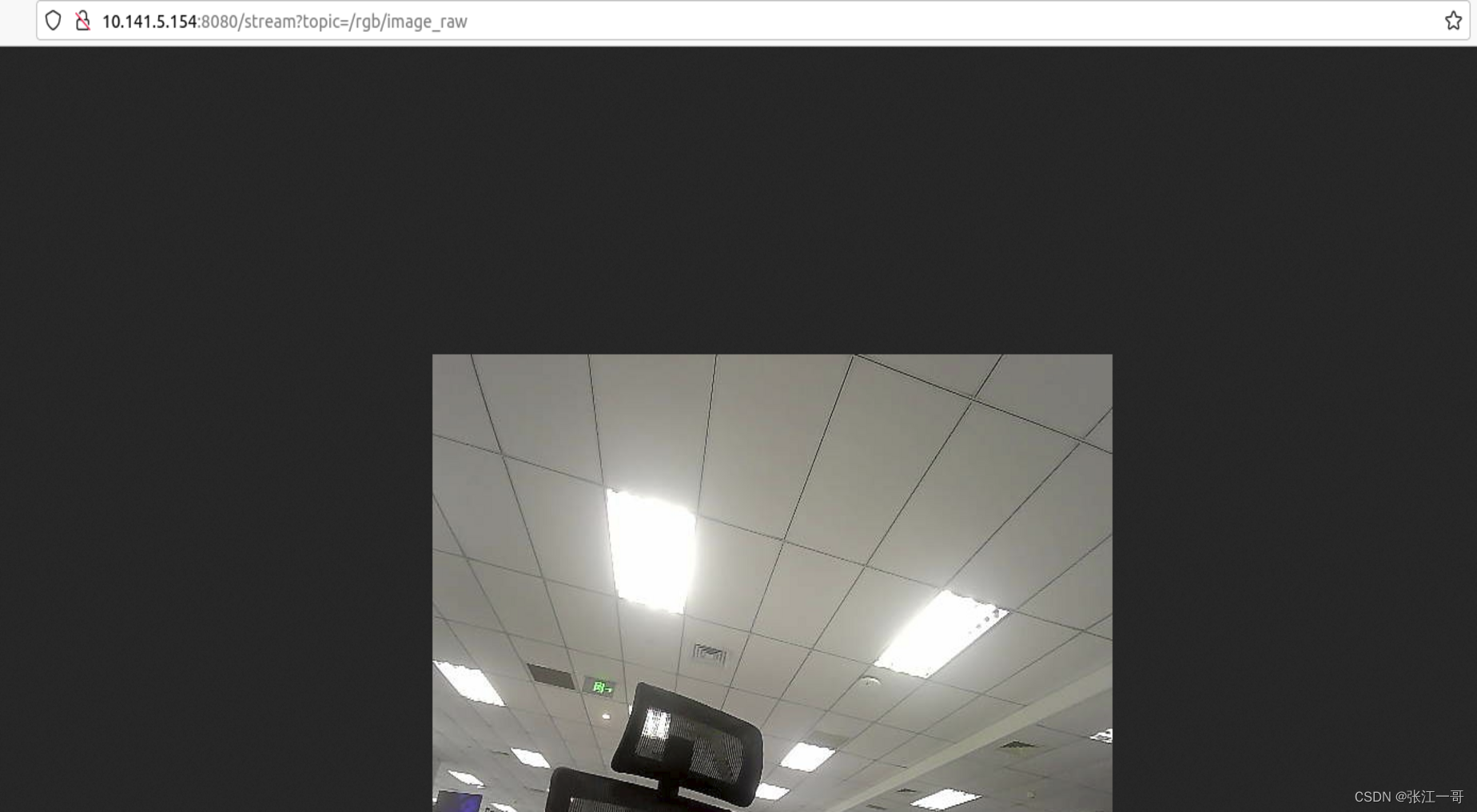
网页显示摄像头数据的方法---基于web video server
1. 背景: 在ros系统中有发布摄像头的相关驱动rgb数据,需求端需要将rgb数据可以直接在网页上去显示。 问题解决: web_video_server功能包,相关链接: web_video_server - ROS Wiki 2. 下载,安装和编译&a…...

SIFT 算法 | 如何在 Python 中使用 SIFT 进行图像匹配
介绍 人类通过记忆和理解来识别物体、人和图像。你看到某件事的次数越多,你就越容易记住它。此外,每当一个图像在你的脑海中弹出时,它就会将该项目或图像与一堆相关的图像或事物联系起来。如果我告诉你我们可以使用一种称为 SIFT 算法的技术来教机器做同样的事情呢? 尽管…...
K8S系列四:服务管理
写在前面 本文是K8S系列第四篇,主要面向对k8s新手同学。阅读本文需要读者对k8s的基本概念,比如Pod、Deployment、Service、Namespace等基础概念有所了解,尚且不了解的同学推荐先阅读本系列的第一篇文章《K8S系列一:概念入门》[1]…...

冠达管理:融券卖出交易规则?
融券卖出买卖是指投资者在没有实际持有某只股票的情况下,经过借入该股票并卖出来取得赢利的一种股票买卖方式。融券卖出买卖规矩针对不同市场、不同证券公司之间可能会存在一些差异,但基本的规矩包含如下几个方面。 一、融资融券的资历要求 在进行融券卖…...
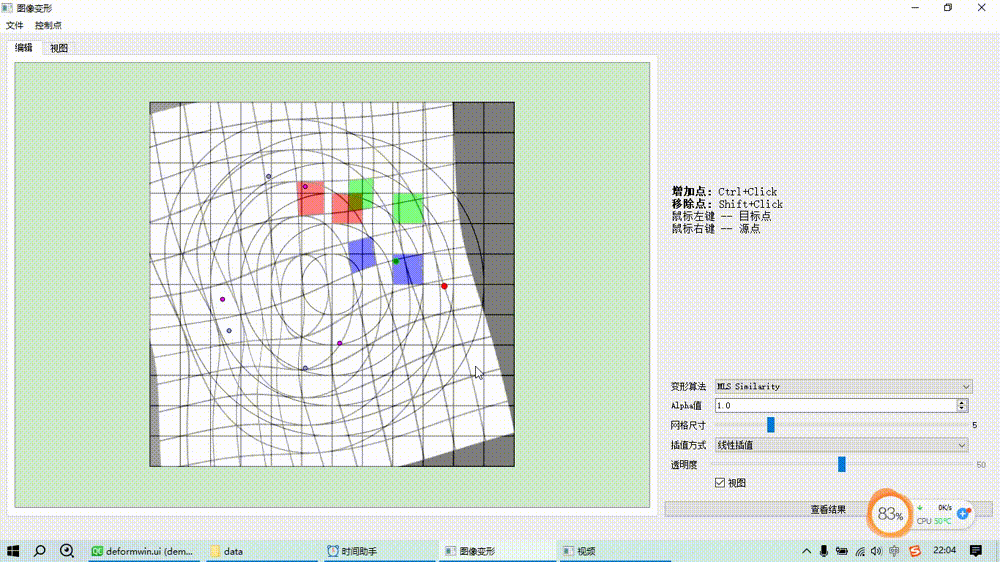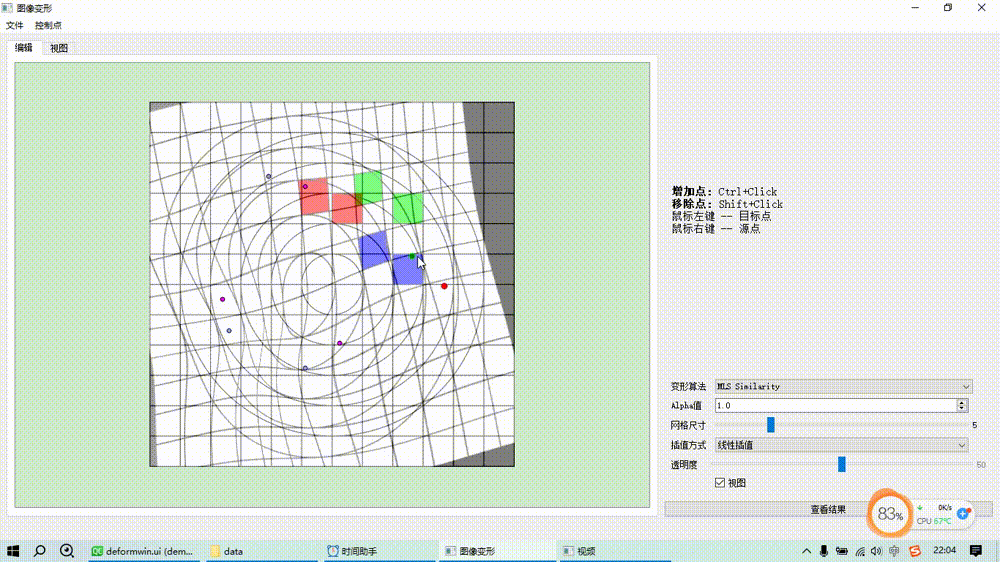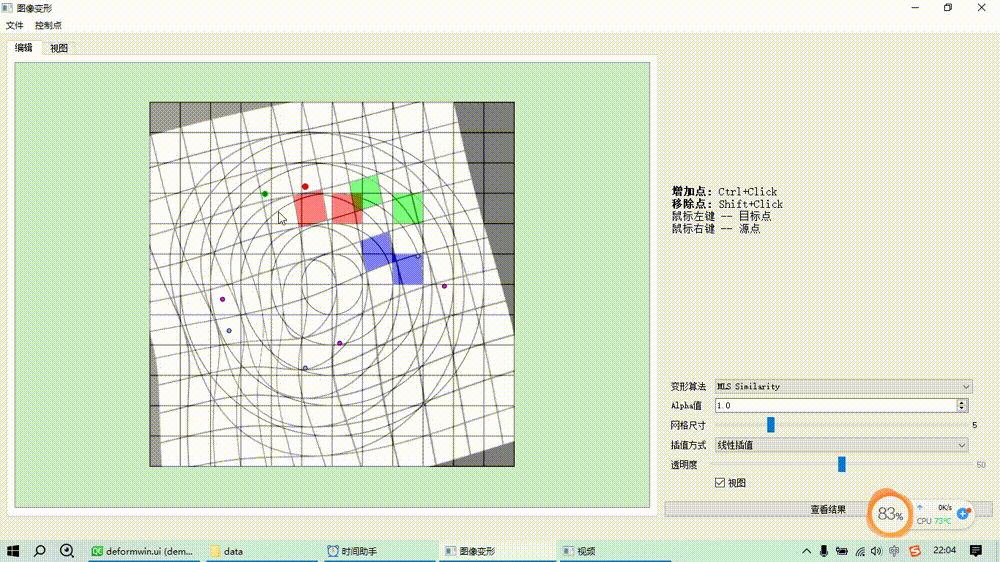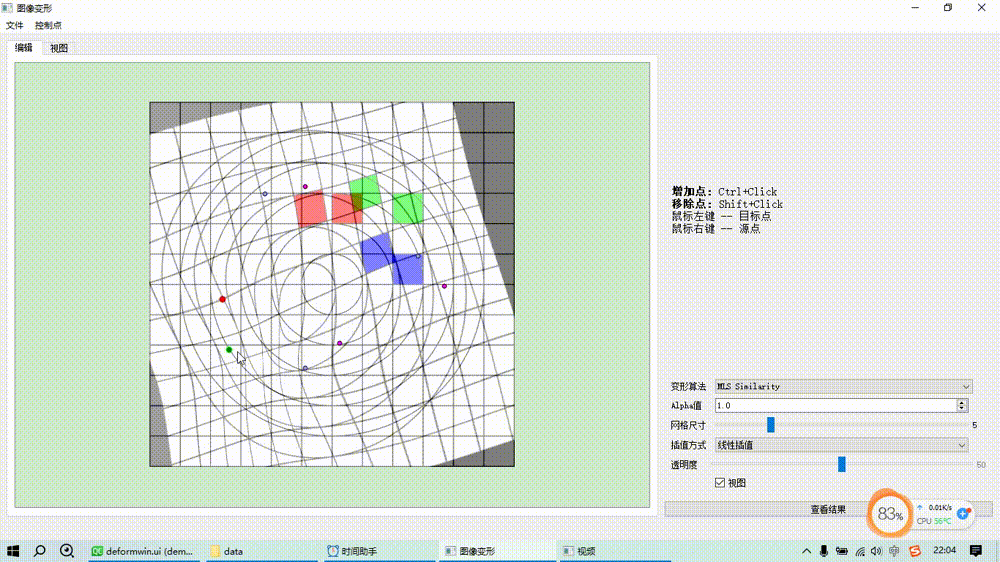
图像变形之移动最小二乘算法(MLS)
基本原理 基于移动最小二乘的图像变形是通过一组源控制点和目标控制点来控制变形,对于每一个待求变形后位置的点而言,根据预设的形变类型(如仿射变换、相似变换、刚性变换)求解一个最小二乘优化目标函数估计一个局部的坐标变换矩阵…...

搭建一个功能齐全的网站
搭建一个功能齐全的网站,需要准备和掌握的一些关键技术和功能可概括如下: 前端技术: HTML/CSS - 网页内容结构和样式JavaScript - 实现网页交互功能前端框架(Vue、React等) - 更高效开发交互页面响应式设计 - 网站适配移动端 后端技术: 服务器(Linux、Nginx等) - 提供网站访…...

Java-jar和war包的区别
jar包和war包的区别: 1、war是一个web模块,其中需要包括WEB-INF,是可以直接运行的WEB模块;jar一般只是包括一些class文件,在声明了Main_class之后是可以用java命令运行的。 2、war包是做好一个web应用后,通…...

3分钟搞定GitHub中文界面:终极汉化插件使用指南
3分钟搞定GitHub中文界面:终极汉化插件使用指南 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese 你是否曾经因为GitHub的英…...

【限时解析】DeepSeek 2024 Q3计费规则更新:2项重大变更将影响92%高频用户
更多请点击: https://kaifayun.com 第一章:DeepSeek计费模式分析 DeepSeek 提供的 API 服务采用按量计费(Pay-as-you-go)模式,核心计费维度为模型调用所消耗的 Token 总数,包含输入(prompt&…...

解密AliceSoft游戏文件处理:3种高效提取与编辑方法深度解析
解密AliceSoft游戏文件处理:3种高效提取与编辑方法深度解析 【免费下载链接】alice-tools Tools for extracting/editing files from AliceSoft games. 项目地址: https://gitcode.com/gh_mirrors/al/alice-tools alice-tools是一款专为AliceSoft游戏设计的开…...

信念网络与LSTM在工业物联网实时控制中的应用
1. 信念网络在实时控制系统中的应用原理在工业物联网环境中,无线网络控制系统(WNCS)面临着独特的挑战。不同于有线网络的稳定传输特性,无线信道会受到多径衰落、同频干扰和设备移动性等因素影响,导致控制更新的传输具有显著的不确定性。传统的…...

LayerDivider:3分钟让单张插画变可编辑图层的AI魔法
LayerDivider:3分钟让单张插画变可编辑图层的AI魔法 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 你知道吗?现在有超过85%的数字…...

WarcraftHelper终极指南:3大模块彻底解决魔兽争霸3兼容性问题
WarcraftHelper终极指南:3大模块彻底解决魔兽争霸3兼容性问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为魔兽争霸3在Win…...

利用大语言模型生成可解释特征:从黑盒预测到白盒决策的工程实践
1. 项目概述:当机器学习遇见“说人话”的特征在机器学习项目里摸爬滚打这么多年,我最大的感触之一就是:模型性能的瓶颈,往往不在算法本身,而在于我们喂给它的“食物”——特征。尤其是在处理文本数据时,这个…...

低查重AI写教材秘诀大揭秘!高效工具助你快速生成专业教材
一、AI教材写作的现状与需求 在编写教材之前,选择合适的工具常常让人感到无比纠结!如果用普通的办公软件,功能显得太过于简单,想要搭建框架或者规范格式,都只能依靠手工操作;而如果选择了专业的教材编写工…...

对比直接使用厂商API体验Taotoken聚合服务的稳定性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商API体验Taotoken聚合服务的稳定性 在集成大模型能力到实际业务的过程中,开发者除了关注模型效果和成本…...

KLayout 0.29.12版图编辑工具:DRC验证引擎性能提升20%与多工艺节点设计支持
KLayout 0.29.12版图编辑工具:DRC验证引擎性能提升20%与多工艺节点设计支持 【免费下载链接】klayout KLayout Main Sources 项目地址: https://gitcode.com/gh_mirrors/kl/klayout KLayout是一款开源的集成电路版图编辑与验证工具,专注于GDSII/O…...