prometheus监控k8s服务并告警到钉钉
一、监控k8s集群
要监控k8s集群需要使用到以下服务用于收集监控的资源信息,node_exporter用于监控k8s集群节点的资源信息,kube-state-metrics用于监控k8s集群的deployment、statefulset、daemonset、pod等的状态,cadvisor用于监控k8s集群的pod资源信息
在k8s集群中创建monitoring的命名空间用于部署监控的容器
kubectl create namespace monitoring
在k8s集群中部署node_exporter容器服务
vi node-exporter.yaml
apiVersion: apps/v1
kind: DaemonSet #使用daemonset控制器,使得集群中的每个节点都能部署一个pod
metadata:name: node-exporternamespace: monitoring labels:k8s-app: node-exporter
spec:selector:matchLabels:k8s-app: node-exportertemplate:metadata:labels:k8s-app: node-exporterspec:tolerations: #配置容忍策略,使得pod能部署在master节点上- effect: NoSchedulekey: node-role.kubernetes.io/control-planecontainers:- image: prom/node-exporter #配置node-exporter的镜像imagePullPolicy: IfNotPresentname: prometheus-node-exporterports:- containerPort: 9100 #配置容器端口hostPort: 9100 #配置绑定k8s主机节点的端口,用于提供对外访问的接口protocol: TCPname: metricshostNetwork: true #使用hostNetwork: true是必要的,这样才能将Pod的网络栈绑定到宿主机上,以实现hostPort的功能执行yaml生成node-exporter容器
kubectl apply -y node-exporter.yaml
查看容器
kubectl get pod -n monitoring -l k8s-app=node-exporter -o wide

可以看到集群的每个节点都有一个node_exporter的pod服务
查看收集的数据
http://10.1.60.119:9100/metrics
在k8s集群中部署kube-state-metrics容器服务
部署kube-state-metrics服务需要去github上的项目拉取yaml
下载地址:https://github.com/kubernetes/kube-state-metrics/tree/v2.9.2
需要根据自己的k8s集群版本下载合适的kube-state-metrics版本,我的k8s版本是1.26.0所以我是下载了2.9.2版本的kube-state-metrics
mkdir /opt/kube-state-metrics && cd /opt/kube-state-metrics
将下载的安装包放到该目录下解压
tar -zxvf kube-state-metrics-2.9.2.tar.gz
将需要用到的yaml文件拷贝出来
mv kube-state-metrics-2.9.2/examples/standard/* /opt/kube-state-metrics
ls

更改一下yaml文件
vi deployment.yaml
apiVersion: apps/v1
kind: Deployment #使用deployment控制器,将pod部署在工作节点即可
metadata:labels:app.kubernetes.io/component: exporterapp.kubernetes.io/name: kube-state-metricsapp.kubernetes.io/version: 2.9.2name: kube-state-metricsnamespace: kube-system
spec:replicas: 1selector:matchLabels:app.kubernetes.io/name: kube-state-metricstemplate:metadata:labels:app.kubernetes.io/component: exporterapp.kubernetes.io/name: kube-state-metricsapp.kubernetes.io/version: 2.9.2spec:automountServiceAccountToken: truecontainers:- image: bitnami/kube-state-metrics:2.9.2 #更改镜像地址,原本的镜像在国外拉不下来livenessProbe:httpGet:path: /healthzport: 8080initialDelaySeconds: 5timeoutSeconds: 5name: kube-state-metricsports:- containerPort: 8080name: http-metrics- containerPort: 8081name: telemetryreadinessProbe:httpGet:path: /port: 8081initialDelaySeconds: 5timeoutSeconds: 5securityContext:allowPrivilegeEscalation: falsecapabilities:drop:- ALLreadOnlyRootFilesystem: truerunAsNonRoot: truerunAsUser: 65534seccompProfile:type: RuntimeDefaultnodeSelector:kubernetes.io/os: linuxserviceAccountName: kube-state-metrics关于镜像的问题可以使用docker命令查一下镜像
docker search kube-state-metrics
vi service.yaml
apiVersion: v1
kind: Service
metadata:labels:app.kubernetes.io/component: exporterapp.kubernetes.io/name: kube-state-metricsapp.kubernetes.io/version: 2.9.2name: kube-state-metricsnamespace: kube-system
spec:type: NodePortclusterIP:ports:- name: http-metricsport: 8080nodePort: 30080 #原本的端口值比较大,超过了nodeport的端口范围targetPort: http-metricsprotocol: TCP- name: telemetryport: 8081 nodePort: 30081 #原本的端口值比较大,超过了nodeport的端口范围targetPort: telemetryprotocol: TCPselector:app.kubernetes.io/name: kube-state-metrics其它的yaml保持默认即可
执行yaml创建kube-state-metrics服务
kubectl apply -f /opt/kube-state-metrics/
查看pod、svc服务
kubectl get pod,svc -n kube-system
查看收集的数据
http://10.1.60.119:30080/metrics

在k8s集群中部署cadvisor容器服务
vi cadvisor.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:name: cadvisornamespace: monitoring
spec:selector:matchLabels:k8s-app: cadvisortemplate:metadata:labels:k8s-app: cadvisorspec:tolerations:- effect: NoSchedulekey: node-role.kubernetes.io/control-planehostNetwork: truerestartPolicy: Alwayscontainers:- name: cadvisorimage: google/cadvisorimagePullPolicy: IfNotPresentports:- containerPort: 8080hostPort: 8080protocol: TCPname: metrics 执行yaml生成cadvisor容器
kubectl apply -y cadvisor.yaml
查看容器
kubectl get pod -n monitoring -l k8s-app=cadvisor -o wide

可以看到集群的每个节点都有一个cadvisor的pod服务
查看收集的数据
http://10.1.60.119:8080/metrics
二、Prometheus获取监控服务的数据并使用grafana展示
部署prometheus
参考:prometheus部署_Apex Predator的博客-CSDN博客
部署grafana
参考: grafana部署_Apex Predator的博客-CSDN博客
配置prometheus
编辑Prometheus配置文件
vi /opt/prometheus/prometheus/prometheus.yml
global:scrape_interval: 15s evaluation_interval: 15s
#alerting: #关于告警组件的配置先忽略# alertmanagers:# - static_configs:# - targets:# - 10.1.60.118:9093
#rule_files: #关于告警规则的配置先忽略
# - "/opt/prometheus/prometheus/rule/*.yml"
scrape_configs:- job_name: "prometheus"static_configs:- targets: ["localhost:9090"]- job_name: "k8s_node_exporter" #配置k8s集群node_exporter监控数据服务的接口static_configs:- targets: ["10.1.60.119:9100","10.1.60.120:9100","10.1.60.121:9100","10.1.60.122:9100","10.1.60.123:9100"]- job_name: "k8s_pod_cadvisor" #配置k8s集群cadvisor监控数据服务的接口static_configs:- targets: ["10.1.60.119:8080","10.1.60.120:8080","10.1.60.121:8080","10.1.60.122:8080","10.1.60.123:8080"]- job_name: "kube-state-metrics" #配置k8s集群kube-state-metrics监控数据服务的接口static_configs:- targets: ["10.1.60.119:30081"]- job_name: "kube-state-telemetry"static_configs:- targets: ["10.1.60.119:30080"]重启prometheus服务
systemctl restart prometheus
查看prometheus监控接口的情况
http://10.1.60.118:9090

配置grafana
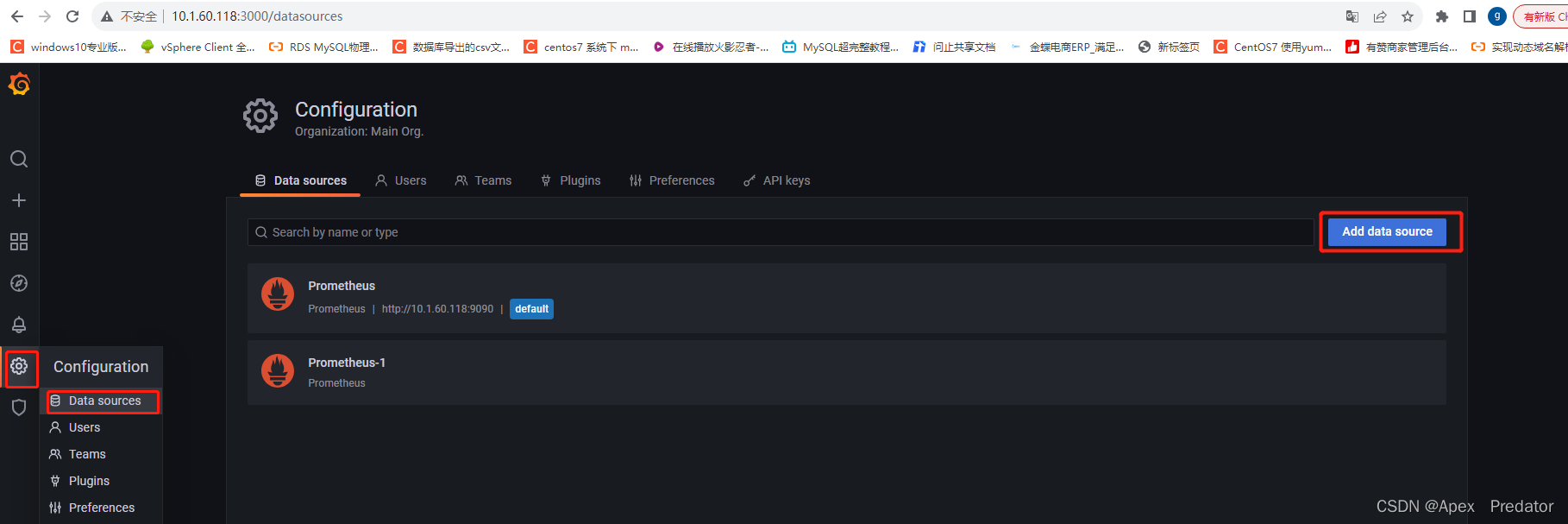
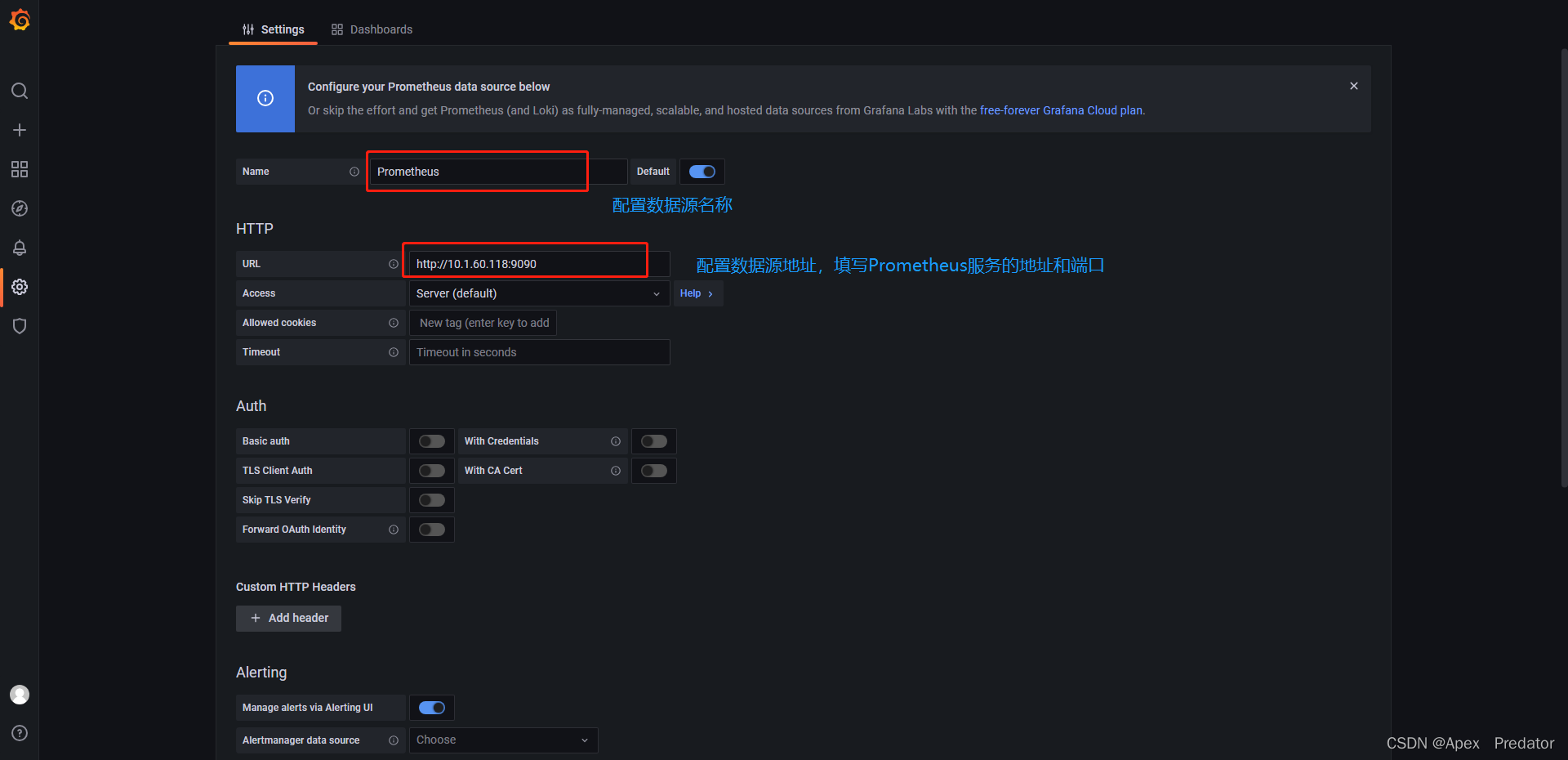
配置prometheus为数据源
配置数据展示的dashboard
在以下网页中找到需要的模板
地址:Dashboards | Grafana Labs
node_exporter服务的模板我们就使用id为1860的模板
kube-state-metrics服务的模板我们就使用id为13332的模板
cadvisor服务的模板我们就使用id为1860的模板
配置grafana应用模板

其余两个也是一样找到模板id后进行配置即可,这里就不再展示了
三、Prometheus配置告警规则和告警服务实现钉钉告警
要实现钉钉告警需要部署alertmanager和prometheus-webhook-dingtalk服务
部署参考:prometheus告警发送组件部署_Apex Predator的博客-CSDN博客
配置prometheus告警规则
关于prometheus的告警规则可以在以下网站中找,里面有很多的告警规则
参考:Awesome Prometheus alerts | Collection of alerting rules
我这里就配置k8s集群主机节点的告警规则和pod的一些告警规则
mkdir /opt/prometheus/prometheus/rule && cd /opt/prometheus/prometheus/rule
vi node_exporter.yml
groups:
- name: 服务器资源监控rules:- alert: 内存使用率过高expr: 100 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100 > 80for: 3mlabels:severity: 严重告警annotations:summary: "{{ $labels.instance }} 内存使用率过高, 请尽快处理!"description: "{{ $labels.instance }}内存使用率超过80%,当前使用率{{ $value }}%."- alert: 服务器宕机expr: up == 0for: 1slabels:severity: 严重告警annotations:summary: "{{$labels.instance}} 服务器宕机, 请尽快处理!"description: "{{$labels.instance}} 服务器延时超过3分钟,当前状态{{ $value }}. "- alert: CPU高负荷expr: 100 - (avg by (instance,job)(irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 90for: 5mlabels:severity: 严重告警annotations:summary: "{{$labels.instance}} CPU使用率过高,请尽快处理!"description: "{{$labels.instance}} CPU使用大于90%,当前使用率{{ $value }}%. "- alert: 磁盘IO性能expr: avg(irate(node_disk_io_time_seconds_total[1m])) by(instance,job)* 100 > 90for: 5mlabels:severity: 严重告警annotations:summary: "{{$labels.instance}} 流入磁盘IO使用率过高,请尽快处理!"description: "{{$labels.instance}} 流入磁盘IO大于90%,当前使用率{{ $value }}%."- alert: 网络流入expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance,job)) / 100) > 102400for: 5mlabels:severity: 严重告警annotations:summary: "{{$labels.instance}} 流入网络带宽过高,请尽快处理!"description: "{{$labels.instance}} 流入网络带宽持续5分钟高于100M. RX带宽使用量{{$value}}."- alert: 网络流出expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance,job)) / 100) > 102400for: 5mlabels:severity: 严重告警annotations:summary: "{{$labels.instance}} 流出网络带宽过高,请尽快处理!"description: "{{$labels.instance}} 流出网络带宽持续5分钟高于100M. RX带宽使用量{$value}}."- alert: TCP连接数expr: node_netstat_Tcp_CurrEstab > 10000for: 2mlabels:severity: 严重告警annotations:summary: " TCP_ESTABLISHED过高!"description: "{{$labels.instance}} TCP_ESTABLISHED大于100%,当前使用率{{ $value }}%."- alert: 磁盘容量expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 90for: 1mlabels:severity: 严重告警annotations:summary: "{{$labels.mountpoint}} 磁盘分区使用率过高,请尽快处理!"description: "{{$labels.instance}} 磁盘分区使用大于90%,当前使用率{{ $value }}%."vi kube-state-metrics.yml
groups: #用于定义一个或多个告警规则分组
- name: k8s容器服务监控 #告警规则分组的名称,用于标识一组相关的告警规则rules: #规则列表,每个规则定义了一个具体的告警条件和处理方式- alert: KubernetesNodeNotReady #告警规则的名称,用于标识告警规则expr: kube_node_status_condition{condition="Ready",status="true"} == 0 #定义告警的条件for: 10m #告警规则的持续时间配置,规定了节点状态满足告警条件的持续时间达到 10 分钟时触发告警labels:severity: 严重告警 #告警规则标签annotations:summary: "Kubernetes node not ready (instance {{ $labels.instance }})"description: "Node {{ $labels.node }} has been unready for a long time\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"- alert: KubernetesOutOfCapacityexpr: sum by (node) ((kube_pod_status_phase{phase="Running"} == 1) + on(uid) group_left(node) (0 * kube_pod_info{pod_template_hash=""})) / sum by (node) (kube_node_status_allocatable{resource="pods"}) * 100 > 90for: 2mlabels:severity: 严重告警annotations:summary: "Kubernetes out of capacity (instance {{ $labels.instance }})"description: "{{ $labels.node }} is out of capacity\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"- alert: KubernetesContainerOomKillerexpr: (kube_pod_container_status_restarts_total - kube_pod_container_status_restarts_total offset 10m >= 1) and ignoring (reason) min_over_time(kube_pod_container_status_last_terminated_reason{reason="OOMKilled"}[10m]) == 1for: 0mlabels:severity: 严重告警annotations:summary: "Kubernetes container oom killer (instance {{ $labels.instance }})"description: "Container {{ $labels.container }} in pod {{ $labels.namespace }}/{{ $labels.pod }} has been OOMKilled {{ $value }} times in the last 10 minutes.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"- alert: KubernetesVolumeOutOfDiskSpaceexpr: kubelet_volume_stats_available_bytes / kubelet_volume_stats_capacity_bytes * 100 < 10for: 2mlabels:severity: 严重告警annotations:summary: "Kubernetes Volume out of disk space (instance {{ $labels.instance }})"description: "Volume is almost full (< 10% left)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"- alert: KubernetesPersistentvolumeErrorexpr: kube_persistentvolume_status_phase{phase=~"Failed|Pending", job="kube-state-metrics"} > 0for: 0mlabels:severity: 严重告警annotations:summary: "Kubernetes PersistentVolume error (instance {{ $labels.instance }})"description: "Persistent volume is in bad state\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"- alert: pod不健康expr: sum by (namespace, pod) (kube_pod_status_phase{phase=~"Pending|Unknown|Failed"}) > 0for: 15mlabels:severity: 严重告警annotations:summary: "Kubernetes Pod not healthy (instance {{ $labels.instance }})"description: "Pod has been in a non-ready state for longer than 15 minutes.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"- alert: pod循环重启expr: increase(kube_pod_container_status_restarts_total[2m]) > 1for: 0mlabels:severity: 严重告警annotations:summary: "Kubernetes pod crash looping (instance {{ $labels.instance }})"description: "Pod {{ $labels.pod }} is crash looping\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"- alert: deployment部署失败未回滚expr: kube_deployment_status_observed_generation != kube_deployment_metadata_generationfor: 10mlabels:severity: 严重告警annotations:summary: "Kubernetes Deployment generation mismatch (instance {{ $labels.instance }})"description: "A Deployment has failed but has not been rolled back.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"- alert: k8s证书临期警告expr: apiserver_client_certificate_expiration_seconds_count{job="apiserver"} > 0 and histogram_quantile(0.01, sum by (job, le) (rate(apiserver_client_certificate_expiration_seconds_bucket{job="apiserver"}[5m]))) < 7*24*60*60for: 0mlabels:severity: 严重告警annotations:summary: "Kubernetes client certificate expires next week (instance {{ $labels.instance }})"description: "A client certificate used to authenticate to the apiserver is expiring next week.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"重启Prometheus服务
systemctl restart prometheus
访问prometheus查看规则是否生效
http://10.1.60.118:9090

告警测试,关闭node_exporter服务,看看是否会告警
kubectl delete -f node_exporter.yaml
通过prometheus我们可以看到告警规则首先是变成了pending状态

然后等了一会后转变为firing状态,这是因为配置了for,当触发条件满足一段时间后才会完全转化为触发告警
等待30s后将会收到钉钉告警,这是因为alertmanager配置了group_wait,当一组告警被触发后,在这个时间段内,其他属于同一组的告警也会被等待。这可以用于在一定时间内收集同一组告警,以便一次性发送通知
现在来将服务恢复一下,看多久会告警
kubectl apply -f node_exporter.yaml

可以看到是间隔时间几分钟后才告警恢复, 这是因为alertmanager配置了group_interval,一旦一个告警组的首个告警触发了通知,等待指定的间隔时间后,即使组内有其他告警,也会重新触发通知。这可以避免过于频繁地发送通知
其他的告警规则服务我就不一个一个测试了,都是没有问题的
相关文章:
prometheus监控k8s服务并告警到钉钉
一、监控k8s集群 要监控k8s集群需要使用到以下服务用于收集监控的资源信息,node_exporter用于监控k8s集群节点的资源信息,kube-state-metrics用于监控k8s集群的deployment、statefulset、daemonset、pod等的状态,cadvisor用于监控k8s集群的p…...

Go和Java实现解释器模式
Go和Java实现解释器模式 下面通过一个四则运算来说明解释器模式的使用。 1、解释器模式 解释器模式提供了评估语言的语法或表达式的方式,它属于行为型模式。这种模式实现了一个表达式接口,该接口 解释一个特定的上下文。这种模式被用在 SQL 解析、符…...
域名配置HTTPS
一、注册域名 这个可以在各大平台注册,具体看一下就会注册了,自己挑选一个自己喜欢的域名。 步骤一般也就是先实名,实名成功了才能注册域名。 二、办理SSL证书 这里使用的是阿里云的SSL免费证书 1、申请证书 二、填写申请 三、域名绑定生…...

机械设计cad,ug编程设计,ug模具设计,SolidWorks模具设计
模具设计培训课程: 【第一阶段:CAD识图制图】 [AutoCAD机械制图]:全面讲解AUTOCAD应用知识,常用命令讲解与运用,二维平面图绘制,三维成型零件的绘制与设计,制作工程图 【第二阶段:U…...

嵌入式开发的学习与未来展望:借助STM32 HAL库开创创新之路
引言: 嵌入式开发作为计算机科学领域的重要分支,为我们的日常生活和产业发展提供了无限的可能。STMicroelectronics的STM32系列芯片以其出色的性能和广泛的应用领域而备受关注。而STM32 HAL库作为嵌入式开发的高级库,为学习者提供了更高效、更…...
WPS-0DAY-20230809的分析和利用复现
WPS-0DAY-20230809的分析和初步复现 一、漏洞学习1、本地复现环境过程 2、代码解析1.htmlexp.py 3、通过修改shellcode拿shell曲折的学习msf生成sc 二、疑点1、问题2、我的测试测试方法测试结果 一、漏洞学习 强调:以下内容仅供学习和测试,一切行为均在…...
MongoDB(三十九)
目录 一、概述 (一)相关概念 (二)特性 二、应用场景 三、安装 (一)编译安装 (二)yum安装 1、首先制作repo源 2、软件包名:mongodb-org 3、启动服务:…...
InnoDB引擎
1 逻辑存储结构 InnoDB的逻辑存储结构如下图所示: 1). 表空间 表空间是InnoDB存储引擎逻辑结构的最高层, 如果用户启用了参数 innodb_file_per_table(在8.0版本中默认开启) ,则每张表都会有一个表空间(xxx.ibd),一个…...

CSS3中的var()函数
目录 定义: 语法: 用法: 定义: var()函数是一个 CSS 函数用于插入自定义属性(有时也被称为“CSS 变量”)的值 语法: var(custom-property-name, value) 函数的第一个参数是要替换的自定义属性…...
opencv图片换背景色
#include <iostream> #include<opencv2/opencv.hpp> //引入头文件using namespace cv; //命名空间 using namespace std;//opencv这个机器视觉库,它提供了很多功能,都是以函数的形式提供给我们 //我们只需要会调用函数即可in…...
JAVA语言:什么是懒加载机制?
JVM没有规定什么时候加载,一般是什么时候使用这个class才会什么时候加载,但是JVM规定了什么时候必须初始化(初始化是第三步、装载、连接、初始化),只要加载之后,那么肯定是要进行初始化的,所以我们就可以通过查看这个类有没有进行初始化,从而判断这个类有没有被加载。 …...
jupyter默认工作目录的更改
1、生成配置文件:打开Anaconda Prompt,输入如下命令 jupyter notebook --generate-config询问[y/N]时输入y 2、配置文件修改:根据打印路径打开配置文件jupyter_notebook_config.py,全文搜索找到notebook_dir所在位置。在单引号中…...
Flutter系列文章-Flutter UI进阶
在本篇文章中,我们将深入学习 Flutter UI 的进阶技巧,涵盖了布局原理、动画实现、自定义绘图和效果、以及 Material 和 Cupertino 组件库的使用。通过实例演示,你将更加了解如何创建复杂、令人印象深刻的用户界面。 第一部分:深入…...

Elasticsearch在部署时,对Linux的设置有哪些优化方法?
部署Elasticsearch时,可以通过优化Linux系统的设置来提升性能和稳定性。以下是一些常见的优化方法: 1.文件描述符限制 Elasticsearch需要大量的文件描述符来处理数据和连接,所以确保调整系统的文件描述符限制。可以通过修改 /etc/security/…...
【网络基础】应用层协议
【网络基础】应用层协议 文章目录 【网络基础】应用层协议1、协议作用1.1 应用层需求1.2 协议分类 2、HTTP & HTTPS2.1 HTTP/HTTPS 简介2.2 HTTP工作原理2.3 HTTPS工作原理2.4 区别 3、URL3.1 编码解码3.2 URI & URL 4、HTTP 消息结构4.1 HTTP请求方法4.2 HTTP请求头信…...

面试八股文Mysql:(1)事务实现的原理
1. 什么是事务 事务就是一组数据库操作,这些操作是一个atomic(原子性的操作) ,不可分割,要么都执行,要么回滚(rollback)都不执行。这样就避免了某个操作成功某个操作失败࿰…...

Linux学习之sed多行模式
N将下一行加入到模式空间 D删除模式空间中的第一个字符到第一个换行符 P打印模式空间中的第一个字符到第一个换行符 doubleSpace.txt里边的内容如下: goo d man使用下边的命令可以实现把上边对应的内容放到doubleSpace.txt。 echo goo >> doubleSpace.txt e…...
【刷题笔记8.15】【链表相关】LeetCode:合并两个有序链表、反转链表
LeetCode:【链表相关】合并两个有序链表 题目1:合并两个有序链表 题目描述 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 输入:l1 [1,2,4], l2 [1,3,4] 输出:[1,1,2,3…...

神经网络基础-神经网络补充概念-11-向量化逻辑回归
概念 通过使用 NumPy 数组来进行矩阵运算,将循环操作向量化。 向量化的好处在于它可以同时处理多个样本,从而加速计算过程。在实际应用中,尤其是处理大规模数据集时,向量化可以显著提高代码的效率。 代码实现-以逻辑回归为例 i…...

openGauss学习笔记-40 openGauss 高级数据管理-锁
文章目录 openGauss学习笔记-40 openGauss 高级数据管理-锁40.1 语法格式40.2 参数说明40.3 示例 openGauss学习笔记-40 openGauss 高级数据管理-锁 如果需要保持数据库数据的一致性,可以使用LOCK TABLE来阻止其他用户修改表。 例如,一个应用需要保证表…...

如何用开源工具轻松搞定热门演出门票:大麦抢票完全手册
如何用开源工具轻松搞定热门演出门票:大麦抢票完全手册 【免费下载链接】ticket-purchase 大麦自动抢票,支持人员、城市、日期场次、价格选择 项目地址: https://gitcode.com/GitHub_Trending/ti/ticket-purchase 你是否曾经为了一张心仪演出的门…...

如果夫妻双方也不愿意带孩子,家里也没有老人带孩子,还有必要生2胎吗?
这个问题没有绝对答案,需要结合你家的经济条件、精力储备和夫妻共识综合判断,没人带并不是一定不能生,但普通家庭确实要谨慎决策。结合你目前在南昌、夫妻二人都要兼顾工作的情况,帮你梳理核心决策维度: ✅ 满足以下条件,可以考虑生 经济条件足够支撑:你月收入2万以…...

跨平台B站视频下载终极指南:如何用BilibiliDown轻松搞定离线观看
跨平台B站视频下载终极指南:如何用BilibiliDown轻松搞定离线观看 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh…...

5个维度深度解析洛雪音乐音源:从技术实现到高效部署的完整指南
5个维度深度解析洛雪音乐音源:从技术实现到高效部署的完整指南 【免费下载链接】lxmusic- lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/gh_mirrors/lx/lxmusic- 洛雪音乐音源项目作为开源音乐资源聚合解决方案,通过JavaScr…...

3个步骤实现浏览器中魔兽争霸与星际争霸模型渲染的完整指南
3个步骤实现浏览器中魔兽争霸与星际争霸模型渲染的完整指南 【免费下载链接】mdx-m3-viewer A WebGL viewer for MDX and M3 files used by the games Warcraft 3 and Starcraft 2 respectively. 项目地址: https://gitcode.com/gh_mirrors/md/mdx-m3-viewer 你是否曾因…...

从零开始:如何用Fabric示例模组快速入门Minecraft模组开发
从零开始:如何用Fabric示例模组快速入门Minecraft模组开发 【免费下载链接】fabric-example-mod Example Fabric mod 项目地址: https://gitcode.com/gh_mirrors/fa/fabric-example-mod 你是否曾经想过为Minecraft添加自己的创意功能,却因为复杂的…...

3分钟彻底清理Windows右键菜单:ContextMenuManager让你的操作效率翻倍
3分钟彻底清理Windows右键菜单:ContextMenuManager让你的操作效率翻倍 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 还在为Windows右键菜单越来越臃…...

初始中断及实现中断
外部中断基础知识 中断概念:在运行主程序时,外部出现了满足中断触发条件的信号,转而去执行中断处理程序,执行完成后返回主程序stm外部中断框架复用功能与重映射 复用功能概念:引脚本身默认是一个GPIO,但它可…...
的标准化生成与检验计划集成)
[实战] 制造业质量控制中气泡图(Balloon Drawing)的标准化生成与检验计划集成
前言:2026 年质量管理的数字化底座在 2026 年的数字化工厂环境环境下,质量管理已从被动拦截转向主动预防。作为 FAI(首件检验)和 PPAP(生产件批准程序)流程中的核心环节,气泡图(Ball…...

构建全志Tina Linux Docker编译镜像:从环境配置到CI/CD实践
1. 项目概述:为什么我们需要一个专属的Docker编译镜像?如果你和我一样,长期在嵌入式Linux开发领域摸爬滚打,那么“环境搭建”这四个字,大概率是你开发周期里最耗时、也最令人头疼的环节之一。尤其是当我们面对像全志Ti…...