[python] 安装numpy+scipy+matlotlib+scikit-learn及问题解决
这篇文章主要讲述Python如何安装Numpy、Scipy、Matlotlib、Scikit-learn等库的过程及遇到的问题解决方法。最近安装这个真是一把泪啊,各种不兼容问题和报错,希望文章对你有所帮助吧!你可能遇到的问题包括:
ImportError: No module named sklearn 未安装sklearn包
ImportError: DLL load failed: 找不到指定的模块
ImportError: DLL load failed: The specified module could not be found
Microsoft Visual C++ 9.0 is required Unable to find vcvarsall.bat
Numpy Install RuntimeError: Broken toolchain: cannot link a simple C program
ImportError: numpy.core.multiarray failed to import
ImportError: cannot import name __check_build
ImportError: No module named matplotlib.pyplot
一. 安装过程
最早我是使用"pip install scikit-learn"命令安装的Scikit-Learn程序,并没有注意需要安装Numpy、Scipy、Matlotlib,然后在报错"No module named Numpy"后,我接着使用PIP或者下载exe程序安装相应的包,同时也不理解安装顺序和版本的重要性。其中最终都会报错" ImportError: DLL load failed: 找不到指定的模块",此时我的解决方法是:
错误:sklearn ImportError: DLL load failed: 找不到指定的模块
重点:安装python第三方库时总会出现各种兼容问题,应该是版本问题,版本需要一致。
下载:http://download.csdn.net/detail/eastmount/9366117
第一步:卸载原始版本,包括Numpy、Scipy、Matlotlib、Scikit-Learn
pip uninstall scikit-learn
pip uninstall numpy
pip uninstall scipy
pip uninstall matplotlib
第二步:不使用"pip install package"或"easy_install package"安装,或者去百度\CSDN下载exe文件,而是去到官网下载相应版本。
http://www.lfd.uci.edu/~gohlke/pythonlibs/#scipy
http://www.lfd.uci.edu/~gohlke/pythonlibs/#numpy
http://www.lfd.uci.edu/~gohlke/pythonlibs/#matplotlib
http://www.lfd.uci.edu/~gohlke/pythonlibs/#scikit-learn
安装过程中最重要的地方就是版本需要兼容。其中操作系统为64位,Python为2.7.8 64位,下载的四个whl文件如下,其中cp27表示CPython 2.7版本,cp34表示CPython 3.4,win_arm64指的是64位版本。
numpy-1.10.2-cp27-none-win_amd64.whl
scipy-0.16.1-cp27-none-win_amd64.whl
matplotlib-1.5.0-cp27-none-win_amd64.whl
scikit_learn-0.17-cp27-none-win_amd64.whl
PS:不推荐使用"pip install numpy"安装或下载如"numpy-MKL-1.8.0.win-amd64-py2.7.exe"类似文件,地址如:
Numerical Python - Browse /NumPy at SourceForge.net
SciPy: Scientific Library for Python - Browse Files at SourceForge.net
第三步:去到Python安装Scripts目录下,再使用pip install xxx.whl安装,先装Numpy\Scipy\Matlotlib包,再安装Scikit-Learn。
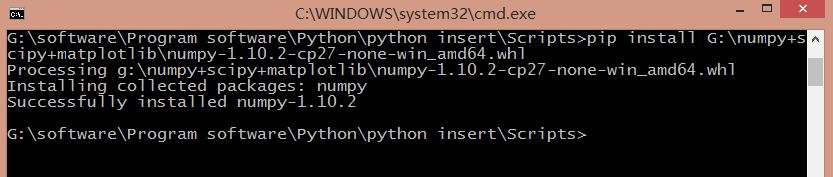
其中我的python安装路径"G:\software\Program software\Python\python insert\Scripts",同时四个whl文件安装核心代码:
pip install G:\numpy+scipy+matplotlib\numpy-1.10.2-cp27-none-win_amd64.whl
pip install G:\numpy+scipy+matplotlib\scikit_learn-0.17-cp27-none-win_amd64.whl
C:\>G:
G:\>cd G:\software\Program software\Python\python insert\Scripts
G:\software\Program software\Python\python insert\Scripts>pip install G:\numpy+s
cipy+matplotlib\numpy-1.10.2-cp27-none-win_amd64.whl
Processing g:\numpy+scipy+matplotlib\numpy-1.10.2-cp27-none-win_amd64.whl
Installing collected packages: numpy
Successfully installed numpy-1.10.2
G:\software\Program software\Python\python insert\Scripts>pip install G:\numpy+s
cipy+matplotlib\matplotlib-1.5.0-cp27-none-win_amd64.whl
Installing collected packages: matplotlib
Successfully installed matplotlib-1.5.0
G:\software\Program software\Python\python insert\Scripts>pip install G:\numpy+s
cipy+matplotlib\scipy-0.16.1-cp27-none-win_amd64.whl
Processing g:\numpy+scipy+matplotlib\scipy-0.16.1-cp27-none-win_amd64.whl
Installing collected packages: scipy
Successfully installed scipy-0.16.1
G:\software\Program software\Python\python insert\Scripts>pip install G:\numpy+s
cipy+matplotlib\scikit_learn-0.17-cp27-none-win_amd64.whl
Processing g:\numpy+scipy+matplotlib\scikit_learn-0.17-cp27-none-win_amd64.whl
Installing collected packages: scikit-learn
Successfully installed scikit-learn-0.17
第四步:此时配置完成,关键是Python64位版本兼容问题和Scripts目录。最后用北邮论坛一个神人的回复结束这个安装过程:“傻孩子,用套件啊,给你介绍一个Anaconda或winpython。只能帮你到这里了! ”
二. 测试运行环境
搞了这么半天,为什么要装这些呢?给几个用例验证它的正确安装和强大吧!
Scikit-Learn是基于python的机器学习模块,基于BSD开源许可。Scikit-learn的基本功能主要被分为六个部分,分类,回归,聚类,数据降维,模型选择,数据预处理,具体可以参考官方网站上的文档。
NumPy(Numeric Python)系统是Python的一种开源的数值计算扩展,一个用python实现的科学计算包。它提供了许多高级的数值编程工具,如:矩阵数据类型、矢量处理,以及精密的运算库。专为进行严格的数字处理而产生。
内容包括:1、一个强大的N维数组对象Array;2、比较成熟的(广播)函数库;3、用于整合C/C++和Fortran代码的工具包;4、实用的线性代数、傅里叶变换和随机数生成函数。numpy和稀疏矩阵运算包scipy配合使用更加方便。
SciPy (pronounced "Sigh Pie") 是一个开源的数学、科学和工程计算包。它是一款方便、易于使用、专为科学和工程设计的Python工具包,包括统计、优化、整合、线性代数模块、傅里叶变换、信号和图像处理、常微分方程求解器等等。
Matplotlib是一个Python的图形框架,类似于MATLAB和R语言。它是python最著名的绘图库,它提供了一整套和matlab相似的命令API,十分适合交互式地进行制图。而且也可以方便地将它作为绘图控件,嵌入GUI应用程序中。
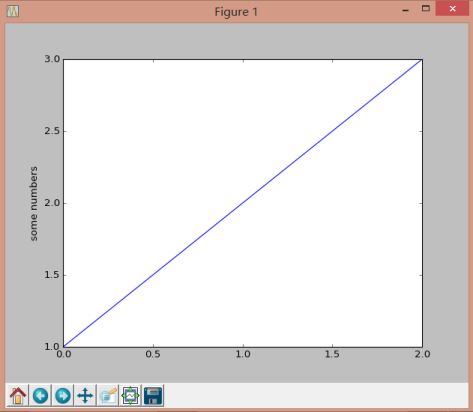
第一个代码:斜线坐标,测试matplotlib
import matplotlib
import numpy
import scipy
import matplotlib.pyplot as plt
plt.plot([1,2,3])
plt.ylabel('some numbers')
plt.show()
运行结果:
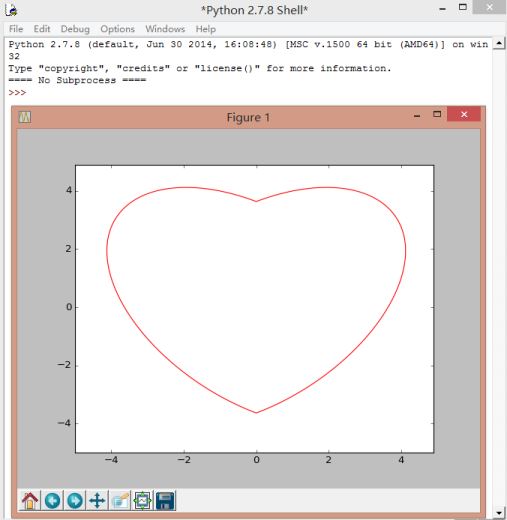
第二个代码:桃心程序,测试numpy和matplotlib
代码参考:Windows 下 Python easy_install 的安装 - KingsLanding
import numpy as np
import matplotlib.pyplot as plt
X = np.arange(-5.0, 5.0, 0.1)
Y = np.arange(-5.0, 5.0, 0.1)
x, y = np.meshgrid(X, Y)
f = 17 * x ** 2 - 16 * np.abs(x) * y + 17 * y ** 2 - 225
fig = plt.figure()
cs = plt.contour(x, y, f, 0, colors = 'r')
plt.show()
运行结果:
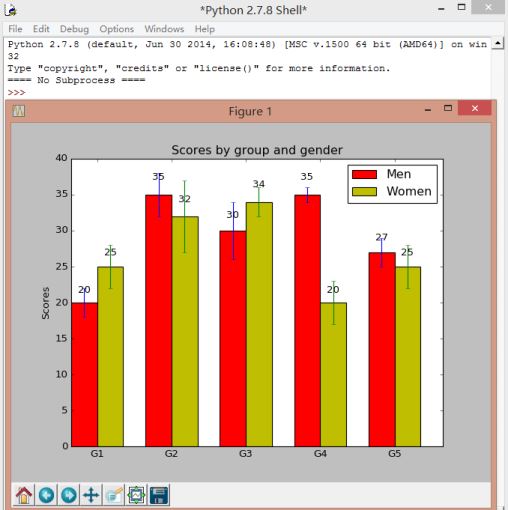
第三个程序:显示Matplotlib强大绘图交互功能
代码参考:Python-Matplotlib安装及简单使用 - bery
import numpy as np
import matplotlib.pyplot as plt
N = 5
menMeans = (20, 35, 30, 35, 27)
menStd = (2, 3, 4, 1, 2)
ind = np.arange(N) # the x locations for the groups
width = 0.35 # the width of the bars
fig, ax = plt.subplots()
rects1 = ax.bar(ind, menMeans, width, color='r', yerr=menStd)
womenMeans = (25, 32, 34, 20, 25)
womenStd = (3, 5, 2, 3, 3)
rects2 = ax.bar(ind+width, womenMeans, width, color='y', yerr=womenStd)
# add some
ax.set_ylabel('Scores')
ax.set_title('Scores by group and gender')
ax.set_xticks(ind+width)
ax.set_xticklabels( ('G1', 'G2', 'G3', 'G4', 'G5') )
ax.legend( (rects1[0], rects2[0]), ('Men', 'Women') )
def autolabel(rects):
# attach some text labels
for rect in rects:
height = rect.get_height()
ax.text(rect.get_x()+rect.get_width()/2., 1.05*height, '%d'%int(height),
ha='center', va='bottom')
autolabel(rects1)
autolabel(rects2)
plt.show()
运行结果:
PS:如果设置legend没有显示比例图标,则参考下面代码:
[python] view plain copy
- # coding=utf-8
- import numpy as np
- import matplotlib
- import scipy
- import matplotlib.pyplot as plt
- #设置legend: http://bbs.byr.cn/#!article/Python/7705
- #mark样式: http://www.360doc.com/content/14/1026/02/9482_419859060.shtml
- #国家 融合特征值
- x1 = [10, 20, 50, 100, 150, 200, 300]
- y1 = [0.615, 0.635, 0.67, 0.745, 0.87, 0.975, 0.49]
- #动物
- x2 = [10, 20, 50, 70, 90, 100, 120, 150]
- y2 = [0.77, 0.62, 0.77, 0.86, 0.87, 0.97, 0.77, 0.47]
- #人物
- x3 = [10, 20, 50, 70, 90, 100, 120, 150]
- y3 = [0.86, 0.86, 0.92, 0.94, 0.97, 0.97, 0.76, 0.46]
- #国家
- x4 = [10, 20, 50, 70, 90, 100, 120, 150]
- y4 = [0.86, 0.85, 0.87, 0.88, 0.95, 1.0, 0.8, 0.49]
- plt.title('Entity alignment result')
- plt.xlabel('The number of class clusters')
- plt.ylabel('Similar entity proportion')
- plot1, = plt.plot(x1, y1, '-p', linewidth=2)
- plot2, = plt.plot(x2, y2, '-*', linewidth=2)
- plot3, = plt.plot(x3, y3, '-h', linewidth=2)
- plot4, = plt.plot(x4, y4, '-d', linewidth=2)
- plt.xlim(0, 300)
- plt.ylim(0.4, 1.0)
- #plot返回的不是matplotlib对象本身,而是一个列表,加个逗号之后就把matplotlib对象从列表里面提取出来
- plt.legend( (plot1,plot2,plot3,plot4), ('Spot', 'Animal', 'People', 'Country'), fontsize=10)
- plt.show()
输出如下图所示:
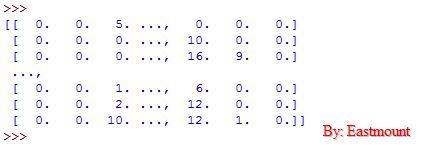
第四个代码:矩阵数据集,测试sklearn
from sklearn import datasets
iris = datasets.load_iris()
digits = datasets.load_digits()
print digits.data
运行结果:
第五个代码:计算TF-IDF词语权重,测试scikit-learn数据分析
参考代码:python scikit-learn计算tf-idf词语权重_python 分词权重_liuxuejiang158的博客-CSDN博客
# coding:utf-8
__author__ = "liuxuejiang"
import jieba
import jieba.posseg as pseg
import os
import sys
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
if __name__ == "__main__":
corpus=["我 来到 北京 清华大学", #第一类文本切词后的结果 词之间以空格隔开
"他 来到 了 网易 杭研 大厦", #第二类文本的切词结果
"小明 硕士 毕业 与 中国 科学院", #第三类文本的切词结果
"我 爱 北京 天安门"] #第四类文本的切词结果
#该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
vectorizer=CountVectorizer()
#该类会统计每个词语的tf-idf权值
transformer=TfidfTransformer()
#第一个fit_transform是计算tf-idf,第二个fit_transform是将文本转为词频矩阵
tfidf=transformer.fit_transform(vectorizer.fit_transform(corpus))
#获取词袋模型中的所有词语
word=vectorizer.get_feature_names()
#将tf-idf矩阵抽取出来,元素a[i][j]表示j词在i类文本中的tf-idf权重
weight=tfidf.toarray()
#打印每类文本的tf-idf词语权重,第一个for遍历所有文本,第二个for便利某一类文本下的词语权重
for i in range(len(weight)):
print u"-------这里输出第",i,u"类文本的词语tf-idf权重------"
for j in range(len(word)):
print word[j],weight[i][j]
运行结果:

三. 其他错误解决方法
这里虽然讲解几个安装时遇到的其他错误及解决方法,但作者更推荐上面的安装步骤。
在这之前,我反复的安装、卸载、升级包,其中遇到了各种错误,改了又改,百度了又谷歌。常见PIP用法如下:
* pip install numpy --安装包numpy
* pip uninstall numpy --卸载包numpy
* pip show --files PackageName --查看已安装包
* pip list outdated --查看待更新包信息
* pip install --upgrade numpy --升级包
* pip install -U PackageName --升级包
* pip search PackageName --搜索包
* pip help --显示帮助信息
ImportError: numpy.core.multiarray failed to import
python安装numpy时出现的错误,这个通过stackoverflow和百度也是需要python版本与numpy版本一致,解决的方法包括"pip install -U numpy"升级或下载指定版本"pip install numpy==1.8"。但这显然还涉及到更多的包,没有前面的卸载下载安装统一版本的whl靠谱。
Microsoft Visual C++ 9.0 is required(unable to find vcvarsall.bat)
因为Numpy内部矩阵运算是用C语言实现的,所以需要安装编译工具,这和电脑安装的VC++或VS2012有关,解决方法:如果已安装Visual Studio则添加环境变量VS90COMNTOOLS即可,不同的VS版本对应不同的环境变量值:
Visual Studio 2010 (VS10)设置 VS90COMNTOOLS=%VS100COMNTOOLS%
Visual Studio 2012 (VS11)设置 VS90COMNTOOLS=%VS110COMNTOOLS%
Visual Studio 2013 (VS12)设置 VS90COMNTOOLS=%VS120COMNTOOLS%
但是这并没有解决,另一种方法是下载Micorsoft Visual C++ Compiler for Python 2.7的包。
下载地址:http://www.microsoft.com/en-us/download/details.aspx?id=44266
参考文章:安装pandas出现错误“error: Microsoft Visual C++ 10.0 is required (Unable to find vcvarsall.bat).”的解决办法 - OSCHINA - 中文开源技术交流社区
PS:这些问题基本解决方法使用pip升级、版本一致、重新下载相关版本exe文件再安装。
总之,最后希望文章对你有所帮助!尤其是刚学习Python和机器学习的同学。
相关文章:
[python] 安装numpy+scipy+matlotlib+scikit-learn及问题解决
这篇文章主要讲述Python如何安装Numpy、Scipy、Matlotlib、Scikit-learn等库的过程及遇到的问题解决方法。最近安装这个真是一把泪啊,各种不兼容问题和报错,希望文章对你有所帮助吧!你可能遇到的问题包括: ImportError: N…...

uniapp使用命令创建页面
package.js下创建命令 "scripts": {"add": "node ./auto/addPage.ts" } package.js同级目录创建auto/addPage.ts addPage.ts代码如下 const fs require(fs) const path require(path) const targetPath process.argv[2];// 要创建的目录地…...

Linux(进程控制)
进程控制 进程创建fork函数初识fork函数返回值写时拷贝fork常规用法fork调用失败的原因 进程终止进程退出码进程常见退出方法 进程等待进程等待必要性获取子进程status进程等待的方法 阻塞等待与非阻塞等待阻塞等待非阻塞等待 进程替换替换原理替换函数函数解释命名理解 做一个…...
进制介绍)
Java学习笔记——(18)进制介绍
对于整数,有四种表示方式: 二进制:0,1 ,满 2 进 1.以 0b 或 0B 开头。(注:书写二进制时需要按四位数字一组的方式书写,缺的前面补0)十进制:0-9 ,满 10 进 1。…...
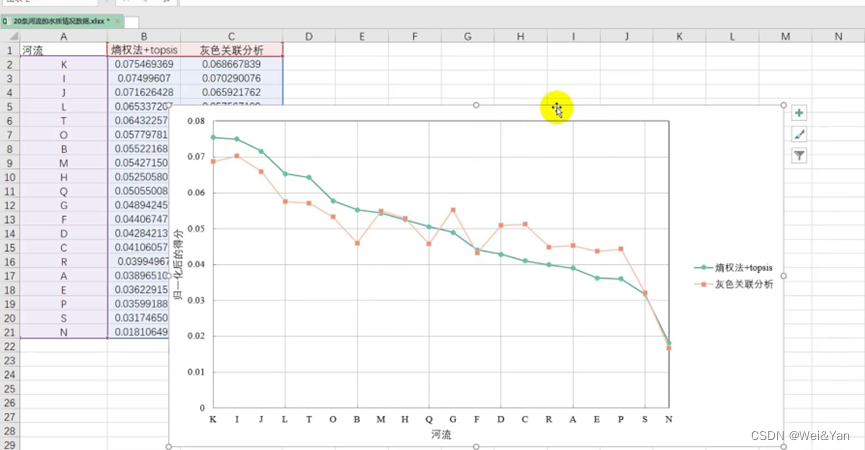
【数学建模】--灰色关联分析
系统分析: 一般的抽象系统,如社会系统,经济系统,农业系统,生态系统,教育系统等都包含有许多种因素,多种因素共同作用的结果决定了该系统的发展态势。人们常常希望知道在众多的因素中,哪些是主要…...

图像像素梯度
梯度 在高数中,梯度是一个向量,是有方向有大小。假设一二元函数f(x,y),在某点的梯度有: 结果为: 即方向导数。梯度的方向是函数变化最快的方向,沿着梯度的方向容易找到最大值。 图像梯度 在一幅模糊图…...

[论文笔记]Batch Normalization
引言 本文是论文神作Batch Normalization的阅读笔记,这篇论文引用量现在快50K了。 由于上一层参数的变化,导致每层输入的分布会在训练期间发生变化,让训练深层神经网络很复杂。这会拖慢训练速度,因为需要更低的学习率并小心地进行参数初始化,使得很难训练这种具有非线性…...

SpringCloud教程(中)
目录 八、Hystrix(服务降级) 8.1、Hystrix基本概念 8.1.1、分布式系统面临的问题 8.1.2、Hystrix是什么? 8.1.3、服务降级 概念 哪些情况会触发降级 8.1.4、服务熔断 8.1.5、服务限流 8.2、Hystrix案例 8.2.1、Hystrix支付微服务构…...

蓝帽杯2022
计算机取证 1 内存取证获取开机密码 现对一个windows计算机进行取证,请您对以下问题进行分析解答。 从内存镜像中获得taqi7的开机密码是多少?(答案参考格式:abcABC123) 首先我们直接对 1.dmp 使用 vol查看 py -2 v…...

vue + el-table 表格数据导出为excel表格
下载依赖 npm install --save xlsx file-saver引入插件 import * as XLSX from xlsx; import FileSaver from "file-saver";完整代码 <template><div class"administrativeCase-container"><div class"content-box"><di…...

ClickHouse(二十):Clickhouse SQL DDL操作-2-分区表DDL操作
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 &…...
Springboot 在 redis 中使用 Guava 布隆过滤器机制
一、导入SpringBoot依赖 在pom.xml文件中,引入Spring Boot和Redis相关依赖 <!-- Google Guava 使用google的guava布隆过滤器实现--><dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><vers…...
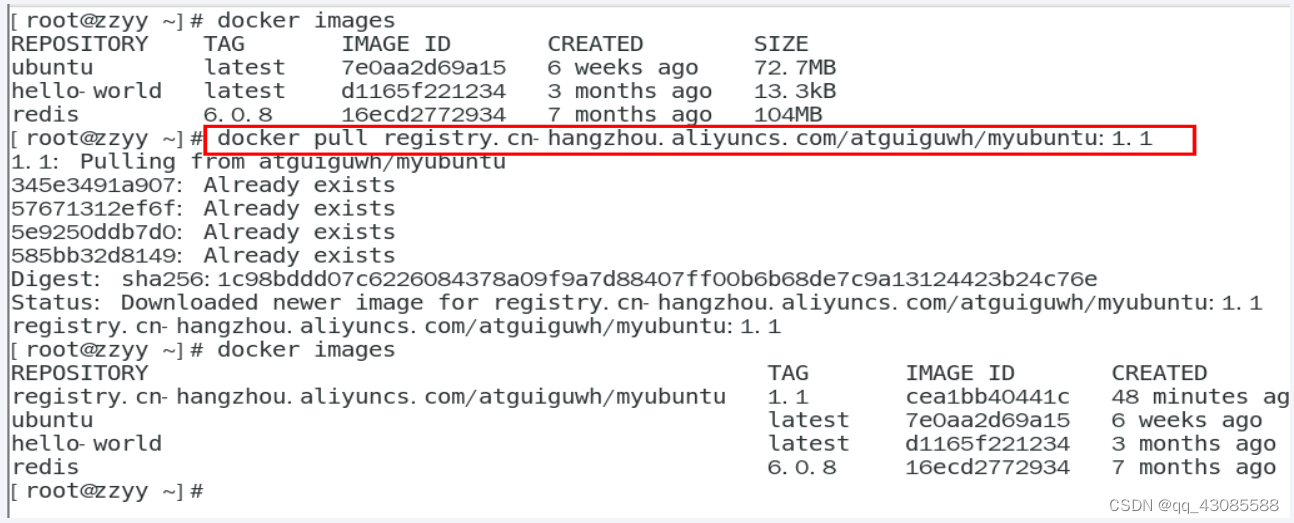
Docker本地镜像发布到阿里云
1. 本地镜像发布到阿里云 2. 镜像的生成方法 OPTIONS说明: -a :提交的镜像作者; -m :提交时的说明文字; 本次案例centosubuntu两个,当堂讲解一个,家庭作业一个,请大家务必动手,亲自实操。 docke…...
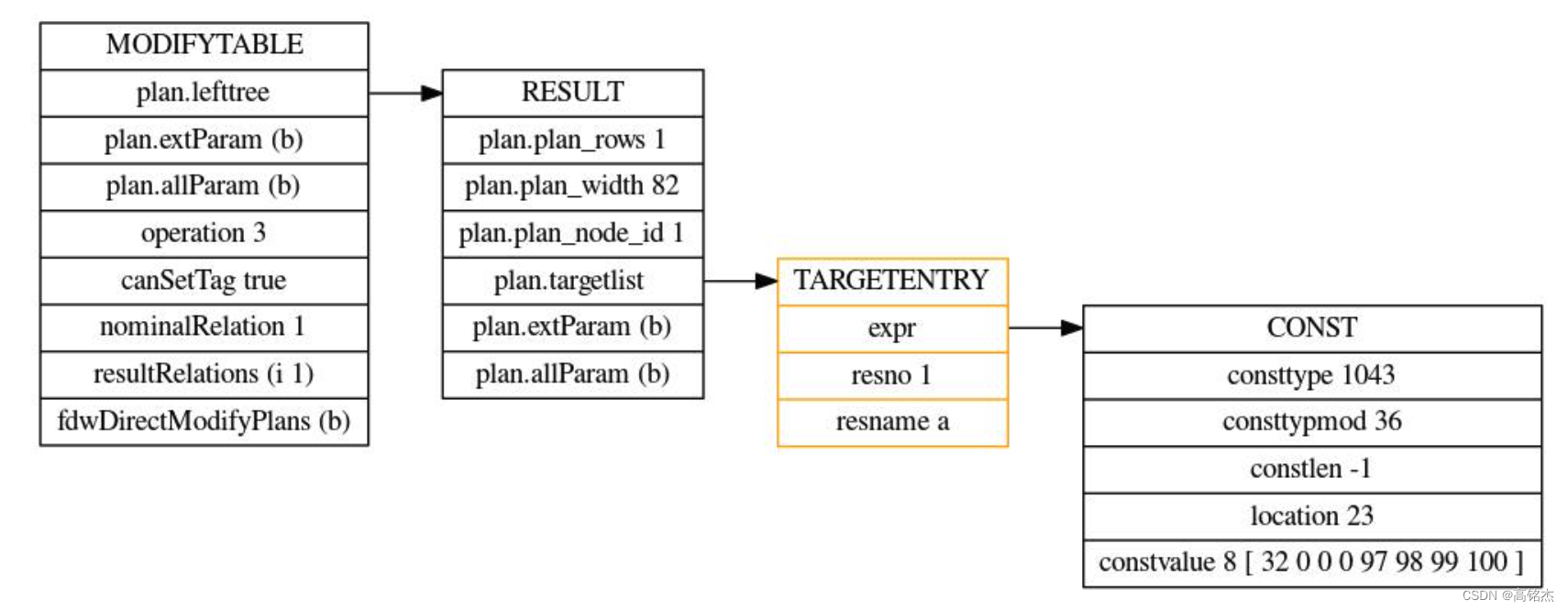
Postgresql源码(112)plpgsql执行sql时变量何时替换为值
相关 《Postgresql源码(41)plpgsql函数编译执行流程分析》 《Postgresql源码(46)plpgsql中的变量类型及对应关系》 《Postgresql源码(49)plpgsql函数编译执行流程分析总结》 《Postgresql源码(5…...

OhemCrossEntropyLoss
1. Ohem Cross Entropy Loss 的定义 OhemCrossEntropyLoss 是一种用于深度学习中目标检测任务的损失函数,它是针对不平衡数据分布和困难样本训练的一种改进版本的交叉熵损失函数。Ohem 表示 “Online Hard Example Mining”,意为在线困难样本挖掘。在目…...

prometheusalert区分告警到不同钉钉群
方法一 修改告警规则 - alert: cpu使用率大于88%expr: instance:node_cpu_utilization:ratio * 100 > 88for: 5mlabels:severity: criticallevel: 3kind: CpuUsageannotations:summary: "cpu使用率大于85%"description: "主机 {{ $labels.hostname }} 的cp…...
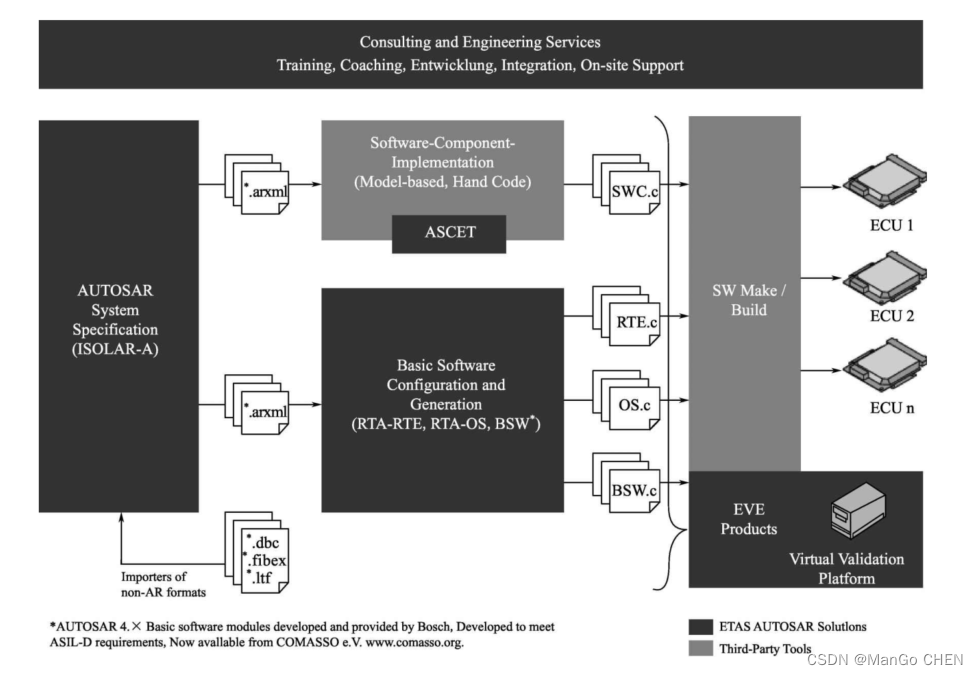
AUTOSAR规范与ECU软件开发(实践篇)3.2 ETAS AUTOSAR系统解决方案介绍(上)
1、ETAS AUTOSAR系统解决方案介绍 博世集团ETAS公司基于其强大的研发实力为用户提供了一套高效、 可靠的AUTOSAR系统解决方案, 该方案覆盖了软件架构设计、 应用层模型设计、 基础软件开发、 软件虚拟验证等各个方面, 如图3.5所示, 其中深色…...

【leetcode】第三章 哈希表part02
454.四数相加II public int fourSumCount(int[] nums1, int[] nums2, int[] nums3, int[] nums4) {HashMap<Integer,Integer> map new HashMap<>();// 统计频率for (int i 0; i < nums1.length; i) {for (int j 0; j < nums2.length; j) {int num nums1…...
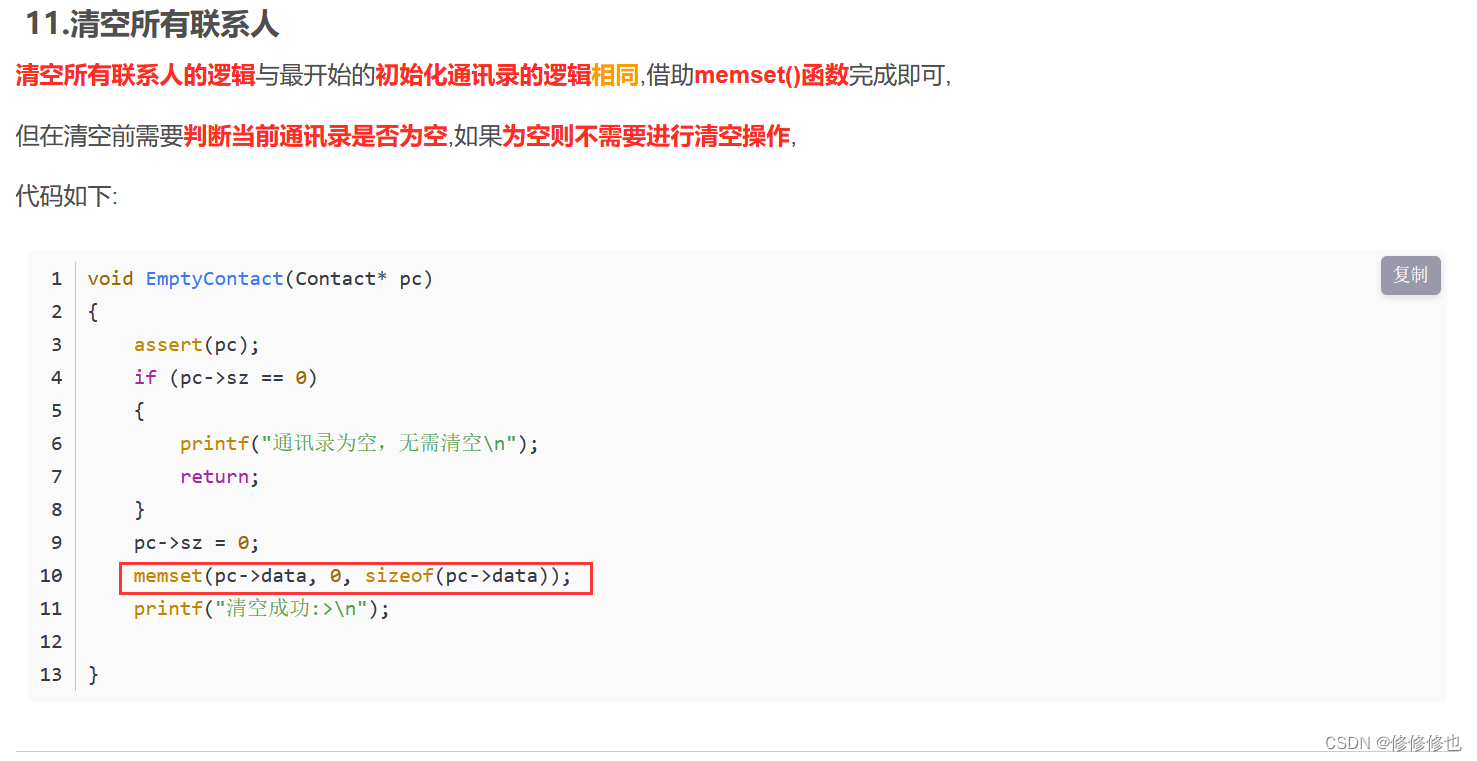
【C语言】memset()函数
一.memset()函数简介 我们先来看一下cplusplus.com - The C Resources Network网站上memset()函数的基本信息: 1.函数功能 memset()函数的功能是:将一块内存空间的每个字节都设置为指定的值。 这个函数通常用于初始化一个内存空间,或者清空一个内存空间…...
、重写(override,也叫做“覆盖”)和重定义(redefine,也叫作“隐藏”)的区别?)
C++中重载(overload)、重写(override,也叫做“覆盖”)和重定义(redefine,也叫作“隐藏”)的区别?
在C中,允许在同一作用域中的某个函数和运算符指定多个定义,分别称为函数重载和运算符重载。 重载声明是指一个与之前已经在该作用域内声明过的函数或方法具有相同名称的声明,但是它们的参数列表和定义(实现)不相同。 …...

Onekey Steam清单下载工具:3步搞定游戏清单管理的终极指南
Onekey Steam清单下载工具:3步搞定游戏清单管理的终极指南 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 在Steam游戏生态中,清单文件是连接游戏客户端与服务器资源的关…...

免费图片去水印工具有哪些?2026年在线网站、APP软件完整盘点与推荐
处理图片水印已经成为很多工作和生活场景的常见需求。无论是自媒体运营者整理素材、设计师进行后期处理,还是普通用户保存喜欢的图片,找到一个好用的去水印工具都能显著提高效率。在2026年,市场上涌现出许多免费的图片去水印工具,…...

深夜连上服务器,我再也不想敲命令行
前言 那是晚上十一点,我第五次输错IPtables规则,服务器直接失联了。赶紧给机房打电话,求助工程师帮忙重启。电话里听着对方说"下次小心点",我只能苦笑——命令行这东西,真不是熬夜能hold住的。 就在这时&a…...

淘金币自动化脚本:每天节省20分钟,解放双手的终极指南
淘金币自动化脚本:每天节省20分钟,解放双手的终极指南 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinb…...

mpv.net:Windows平台最强大的开源媒体播放器解决方案
mpv.net:Windows平台最强大的开源媒体播放器解决方案 【免费下载链接】mpv.net 🎞 mpv.net is a media player for Windows with a modern GUI. 项目地址: https://gitcode.com/gh_mirrors/mp/mpv.net 在Windows平台上寻找一款既强大又简洁的媒体…...

JetBrains IDE试用期重置终极指南:轻松解决IDE过期问题
JetBrains IDE试用期重置终极指南:轻松解决IDE过期问题 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾经遇到过这样的困扰:正在专注编码时,突然弹出的"试用期已结…...

巨亏47亿,市值5000亿:拆解智谱AI的定价逻辑
2026年1月8日,智谱以每股116.2港元登陆港交所。截至5月中旬,其股价一度冲上1160港元,市值突破5000亿港元,较发行价累涨近10倍。而同期披露的2025年财报显示,公司全年营收7.24亿元,经调整净亏损31.82亿元。来…...
全线工程塑料产品与技术服务)
宏裕塑胶代理沙伯基础创新SABIC(原GE塑料)全线工程塑料产品与技术服务
宏裕塑胶依托源头直采模式,整合沙伯基础创新 SABIC(原 GE 塑料)等国际一线品牌工程塑料原料,为制造业企业提供高性价比、稳定可控的供应链解决方案,助力客户降本增效,适用于汽车零配件、精密电子、注塑生产…...

Taotoken官方折扣活动如何切实降低模型调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken官方折扣活动如何切实降低模型调用成本 1. 成本感知:从按需付费到计划性支出 对于个人开发者或中小型团队而言…...

3步掌握Jellyfin智能字幕插件:新手快速上手指南
3步掌握Jellyfin智能字幕插件:新手快速上手指南 【免费下载链接】jellyfin-plugin-maxsubtitle 一个 Jellyfin 中文字幕插件(未来可以不局限中文) 项目地址: https://gitcode.com/gh_mirrors/je/jellyfin-plugin-maxsubtitle MaxSubti…...