JVM——分代收集理论和垃圾回收算法
一、分代收集理论
1、三个假说
弱分代假说:绝大多数对象都是朝生夕灭的。
强分代假说:熬过越多次垃圾收集过程的对象越难以消亡。
这两个分代假说共同奠定了多款常用的垃圾收集器的一致的设计原则:收集器应该将Java堆划分出不同的区域,然后将回收对象依据其年龄(年龄即对象熬过垃圾收集过程的次数)分配到不同的区域之中存储。
把分代收集理论具体放到现在的商用Java虚拟机中里,设计者一般至少会把Java堆划分成新生代和老年代两个区域。
新生代和老年代:每次垃圾收集时都发现有大批对象死去,而每次回收后存活的少量对象,将会逐步晋升到老年代中存放。
每次回收进行后,没有被回收的对象年龄加1,加到一定次数(一般是13),就会进入老年代。
如果一个区域中大多数对象都是朝生夕灭,难以熬过垃圾收集过程的话,那么把它们集中放在一起,每次回收时只关注如何保留少量存活而不是去标记那些大量将要被回收的对象,就能以较低代价回收到大量的空间;如果剩下的都是难以消亡的对象,那把它们集中放在一块,虚拟机便可以使用较低的频率来回收这个区域,这就同时兼顾了垃圾收集的时间开销和内存的空间有效利用。
跨代引用问题:新生代引用了老年代的对象,老年代不消亡,新生代就不消亡,但是每次回收还需要扫描,看老年代有没有被回收,需要遍历老年代所有对象,增加内存压力,让新生代年龄加1,当老年代消亡时,新生代也消亡了。
依据这条假说,我们就不应再为了少量的跨代引用去扫描整个老年代,也不必浪费空间专门记录 每一个对象是否存在及存在哪些跨代引用, 只需在新生代上建立一个全局的数据结构 (该结构被称为“记忆集”, Remembered Set ), 这个结构把老年代划分成若干小块,标识出老年代的哪一块内存会存在跨代引用 。此后当发生Minor GC 时,只有 包含了跨代引用的小块内存里的对象才会被加入到GC Roots进行扫描 。虽然这种方法需要在对象改变引用关系(如将自己或者某个属性赋值)时维护记录数据的正确性,会增加一些运行时的开销,但比起收集时扫描整个老年代来说仍然是划算的。
2、部分收集和整堆收集
- 新生代收集(Minor GC/Young GC):指目标只是新生代的垃圾收集。
- 老年代收集(Major GC/Old GC):指目标只是老年代的垃圾收集。目前只有CMS收集器会有单独收集老年代的行为。
- 混合收集(Mixed GC):指目标是收集整个新生代以及部分老年代的垃圾收集。目前只有G1收集器会有这种行为。
整堆收集(Full GC):收集整个Java堆和方法区的垃圾收集。
二、垃圾回收算法
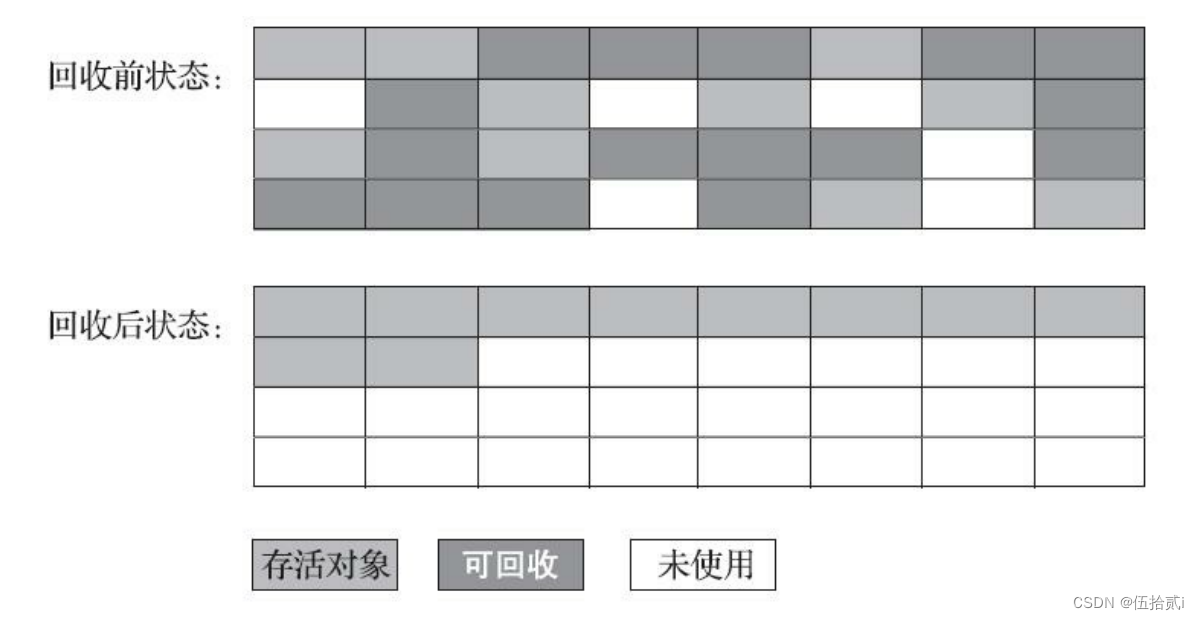
1、标记-清除算法
分为标记和清除两个阶段。后续大部分算法也是以它为基础。
标记所有需要回收的对象,然后统一回收。
反过来也可以。
标记所有存活的对象,回收没有标记的。
缺点:
1.程序效率不稳定:当Java堆中包含大量对象,而其中大部分是需要被回收的,这时必须进行大量标记和清除动作,导致标记和清除两个过程的执行效率都随对象数量的增长而降低。
2.内存碎片化:标记、清除之后会产生大 量不连续的内存碎片,空间碎片太多可能会导致当以后在程序运行过程中需要分配较大对象时无法找 到足够的连续内存而不得不提前触发另一次垃圾收集动作。
2、标记-复制算法
优点:解决碎片化问题,实现简单,运行高效。
缺点:可用内存缩小为原来的一半。

3、标记-整理算法
针对老年代,其中的标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向内存空间一端移动,然后直接清理掉边界以外的内存。
优点:1.移动完会使内存更加规整
2.如果老年代多,基本上都不移动
缺点:1.如果不应用于老年代,需要移动的对象过多就会消耗大量资源
2.移动时必须暂停所有程序
相关文章:
JVM——分代收集理论和垃圾回收算法
一、分代收集理论 1、三个假说 弱分代假说:绝大多数对象都是朝生夕灭的。 强分代假说:熬过越多次垃圾收集过程的对象越难以消亡。 这两个分代假说共同奠定了多款常用的垃圾收集器的一致的设计原则:收集器应该将Java堆划分出不同的区域&…...

jar包独立运行的几种方式
linux启动jar包的方式,直接运行与守护进程运行 通常我们开发好的程序需要打成war/jar包,在linux运行,war包好说直接丢在tomcat中即可,如果开发好的程序为jar包的话,方式比较多 直接启动(java-jar xxx.jar) java -jar shareniu.jar 特点:当前ssh窗口被锁定&#x…...

[python] 安装numpy+scipy+matlotlib+scikit-learn及问题解决
这篇文章主要讲述Python如何安装Numpy、Scipy、Matlotlib、Scikit-learn等库的过程及遇到的问题解决方法。最近安装这个真是一把泪啊,各种不兼容问题和报错,希望文章对你有所帮助吧!你可能遇到的问题包括: ImportError: N…...

uniapp使用命令创建页面
package.js下创建命令 "scripts": {"add": "node ./auto/addPage.ts" } package.js同级目录创建auto/addPage.ts addPage.ts代码如下 const fs require(fs) const path require(path) const targetPath process.argv[2];// 要创建的目录地…...

Linux(进程控制)
进程控制 进程创建fork函数初识fork函数返回值写时拷贝fork常规用法fork调用失败的原因 进程终止进程退出码进程常见退出方法 进程等待进程等待必要性获取子进程status进程等待的方法 阻塞等待与非阻塞等待阻塞等待非阻塞等待 进程替换替换原理替换函数函数解释命名理解 做一个…...
进制介绍)
Java学习笔记——(18)进制介绍
对于整数,有四种表示方式: 二进制:0,1 ,满 2 进 1.以 0b 或 0B 开头。(注:书写二进制时需要按四位数字一组的方式书写,缺的前面补0)十进制:0-9 ,满 10 进 1。…...
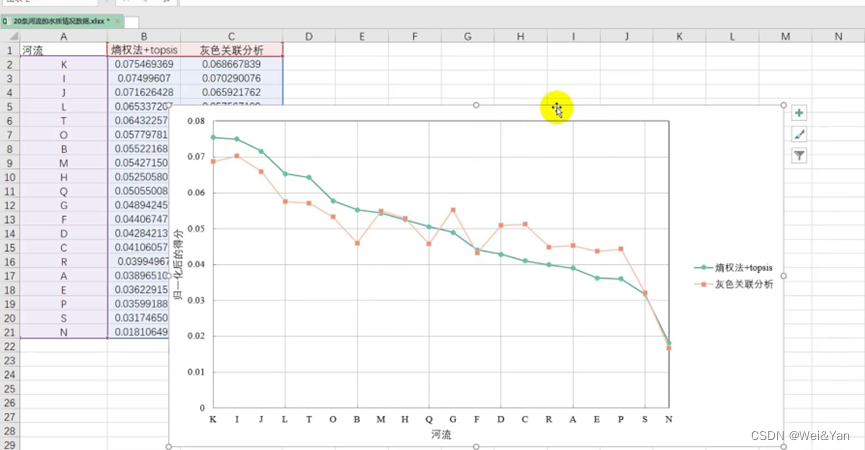
【数学建模】--灰色关联分析
系统分析: 一般的抽象系统,如社会系统,经济系统,农业系统,生态系统,教育系统等都包含有许多种因素,多种因素共同作用的结果决定了该系统的发展态势。人们常常希望知道在众多的因素中,哪些是主要…...

图像像素梯度
梯度 在高数中,梯度是一个向量,是有方向有大小。假设一二元函数f(x,y),在某点的梯度有: 结果为: 即方向导数。梯度的方向是函数变化最快的方向,沿着梯度的方向容易找到最大值。 图像梯度 在一幅模糊图…...

[论文笔记]Batch Normalization
引言 本文是论文神作Batch Normalization的阅读笔记,这篇论文引用量现在快50K了。 由于上一层参数的变化,导致每层输入的分布会在训练期间发生变化,让训练深层神经网络很复杂。这会拖慢训练速度,因为需要更低的学习率并小心地进行参数初始化,使得很难训练这种具有非线性…...

SpringCloud教程(中)
目录 八、Hystrix(服务降级) 8.1、Hystrix基本概念 8.1.1、分布式系统面临的问题 8.1.2、Hystrix是什么? 8.1.3、服务降级 概念 哪些情况会触发降级 8.1.4、服务熔断 8.1.5、服务限流 8.2、Hystrix案例 8.2.1、Hystrix支付微服务构…...

蓝帽杯2022
计算机取证 1 内存取证获取开机密码 现对一个windows计算机进行取证,请您对以下问题进行分析解答。 从内存镜像中获得taqi7的开机密码是多少?(答案参考格式:abcABC123) 首先我们直接对 1.dmp 使用 vol查看 py -2 v…...

vue + el-table 表格数据导出为excel表格
下载依赖 npm install --save xlsx file-saver引入插件 import * as XLSX from xlsx; import FileSaver from "file-saver";完整代码 <template><div class"administrativeCase-container"><div class"content-box"><di…...

ClickHouse(二十):Clickhouse SQL DDL操作-2-分区表DDL操作
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 &…...
Springboot 在 redis 中使用 Guava 布隆过滤器机制
一、导入SpringBoot依赖 在pom.xml文件中,引入Spring Boot和Redis相关依赖 <!-- Google Guava 使用google的guava布隆过滤器实现--><dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><vers…...
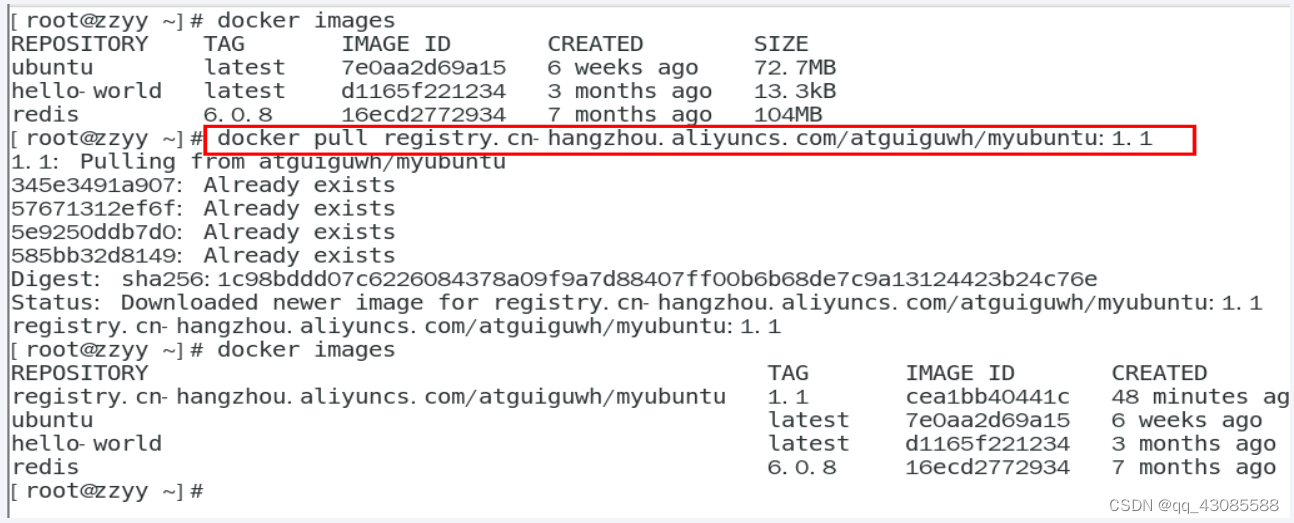
Docker本地镜像发布到阿里云
1. 本地镜像发布到阿里云 2. 镜像的生成方法 OPTIONS说明: -a :提交的镜像作者; -m :提交时的说明文字; 本次案例centosubuntu两个,当堂讲解一个,家庭作业一个,请大家务必动手,亲自实操。 docke…...
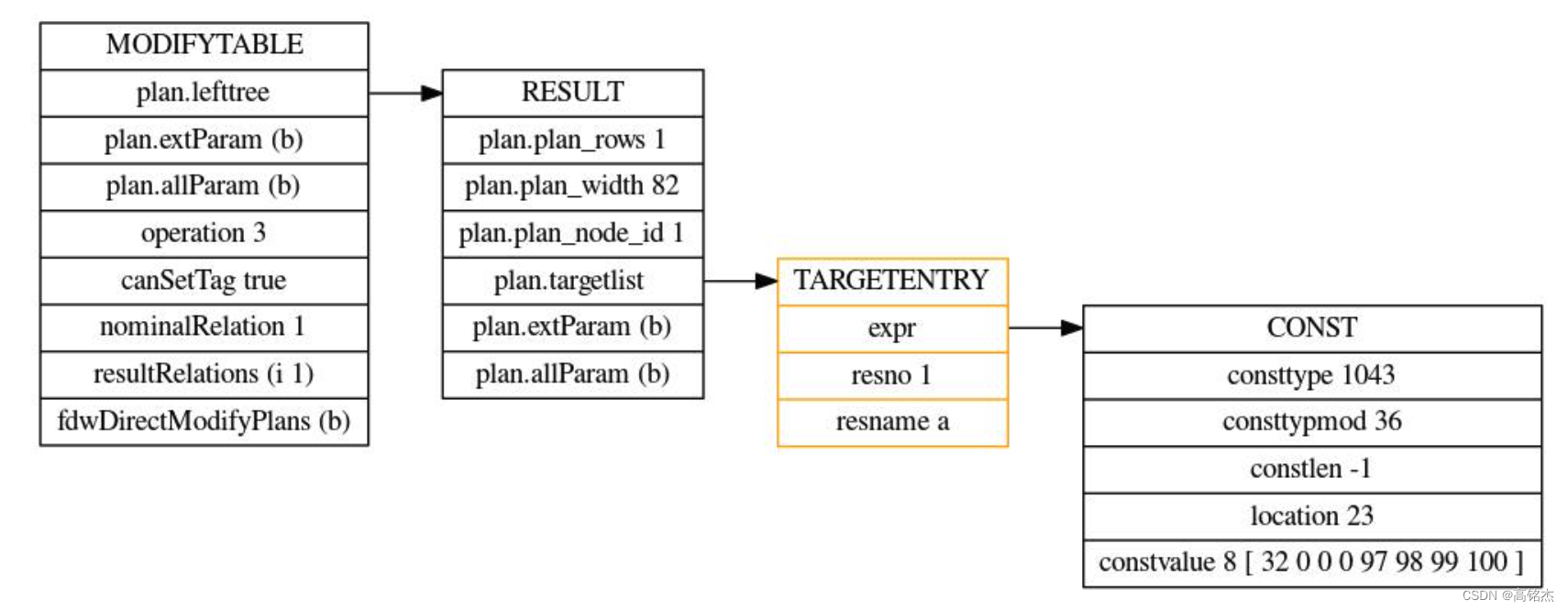
Postgresql源码(112)plpgsql执行sql时变量何时替换为值
相关 《Postgresql源码(41)plpgsql函数编译执行流程分析》 《Postgresql源码(46)plpgsql中的变量类型及对应关系》 《Postgresql源码(49)plpgsql函数编译执行流程分析总结》 《Postgresql源码(5…...

OhemCrossEntropyLoss
1. Ohem Cross Entropy Loss 的定义 OhemCrossEntropyLoss 是一种用于深度学习中目标检测任务的损失函数,它是针对不平衡数据分布和困难样本训练的一种改进版本的交叉熵损失函数。Ohem 表示 “Online Hard Example Mining”,意为在线困难样本挖掘。在目…...

prometheusalert区分告警到不同钉钉群
方法一 修改告警规则 - alert: cpu使用率大于88%expr: instance:node_cpu_utilization:ratio * 100 > 88for: 5mlabels:severity: criticallevel: 3kind: CpuUsageannotations:summary: "cpu使用率大于85%"description: "主机 {{ $labels.hostname }} 的cp…...
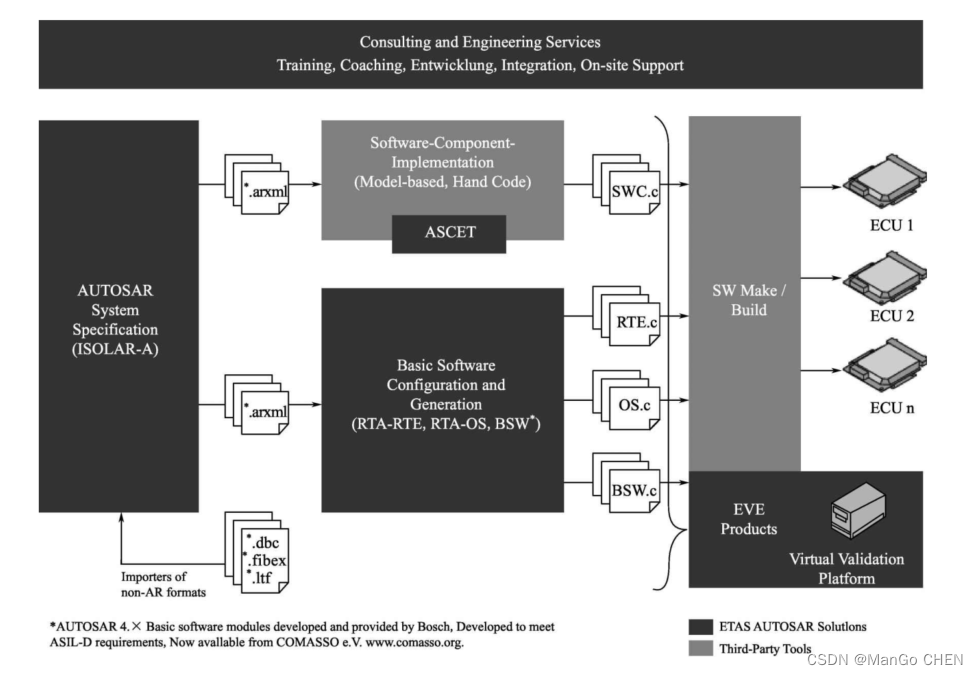
AUTOSAR规范与ECU软件开发(实践篇)3.2 ETAS AUTOSAR系统解决方案介绍(上)
1、ETAS AUTOSAR系统解决方案介绍 博世集团ETAS公司基于其强大的研发实力为用户提供了一套高效、 可靠的AUTOSAR系统解决方案, 该方案覆盖了软件架构设计、 应用层模型设计、 基础软件开发、 软件虚拟验证等各个方面, 如图3.5所示, 其中深色…...

【leetcode】第三章 哈希表part02
454.四数相加II public int fourSumCount(int[] nums1, int[] nums2, int[] nums3, int[] nums4) {HashMap<Integer,Integer> map new HashMap<>();// 统计频率for (int i 0; i < nums1.length; i) {for (int j 0; j < nums2.length; j) {int num nums1…...

AI Newsletter的本质:一种高信噪比的信息过滤与认知校准方法论
1. 项目概述:一份“AI Newsletter”背后的真实工作流与信息筛选逻辑你点开邮箱,看到标题为This AI newsletter is all you need #41的邮件——它没用夸张的“爆炸性突破”“颠覆认知”这类词,也没塞满emoji和感叹号,但你还是点了开…...

Onekey Steam清单下载工具:3步搞定游戏清单管理的终极指南
Onekey Steam清单下载工具:3步搞定游戏清单管理的终极指南 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 在Steam游戏生态中,清单文件是连接游戏客户端与服务器资源的关…...
)
ElevenLabs荷兰文语音生成速度对比实测:从4.2s→0.8s的WebSocket流式优化路径(附可复用代码片段)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs荷兰文语音生成速度对比实测:从4.2s→0.8s的WebSocket流式优化路径(附可复用代码片段) ElevenLabs 的 Dutch(nl-NL)语音合成在默认…...
)
Postgresql基础实践教程(二)
十三、查询会员的预订开始时间 题目 如何列出名为"David Farrell"的会员的所有预订开始时间? 预期结果 starttime 2012-09-18 09:00:00 2012-09-18 17:30:00 2012-09-18 13:30:00 2012-09-18 20:00:00 2012-09-19 09:30:00 2012-09-19 15:00:00 2012-09-19 12:00:…...
OpenAvatarChat终极指南:5分钟打造你的专属AI数字人
OpenAvatarChat终极指南:5分钟打造你的专属AI数字人 【免费下载链接】OpenAvatarChat 项目地址: https://gitcode.com/gh_mirrors/op/OpenAvatarChat 想象一下,你正在开发一个智能客服系统,需要让数字人能够自然流畅地与用户对话。传…...

如何快速清理Windows驱动垃圾:DriverStore Explorer终极使用指南
如何快速清理Windows驱动垃圾:DriverStore Explorer终极使用指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你的C盘空间是不是总在不知不觉中变小?系统运行…...

【BUUCTF】【WEB】Unicorn shop
考点:Unicode数字字符,python的int()函数打开题目,发现这个页面很像买东西的网站,一共有四个商品,每个商品的价格不一样,但是第4个的商品最贵,而且超出了其他商品特别多,由此合理猜测…...

企业微信 Webhook 回调详解
Webhook 回调,是企业微信自动化开发中最核心的能力之一。很多开发者在做企业微信自动化时,都会先关注“消息发送”。 但真正影响系统自动化能力的,其实是“消息回调”。因为只有实时接收到客户消息、群消息与事件通知,系统才能真正…...

从一次任务到一次进化:完整拆解 Skill 创建、复用、修补链路
点击上方 前端Q,关注公众号回复加群,加入前端Q技术交流群写到这一篇,第二章的拼图终于齐了。 前面四篇我把 Hermes 的自学习系统拆成了 4 个零件:Memory(记知识)、Skill(记做法)、Nu…...

华为认证“以学代考”续证政策——伙伴篇
华为认证面向伙伴正式推出“以学代考”续证机制,支持华为中国区政企伙伴通过在线学习和在线考试后,即可获取续认证。当前,“以学代考”产品已上架伙伴TF基金产品兑换清单,伙伴可通过TF基金兑换相应课程,完成续认证。完…...