Flink CDC系列之:TiDB CDC 导入 Elasticsearch
Flink CDC系列之:TiDB CDC 导入 Elasticsearch
- 一、通过docker 来启动 TiDB 集群
- 二、下载 Flink 和所需要的依赖包
- 三、在TiDB数据库中创建表和准备数据
- 四、启动Flink 集群,再启动 SQL CLI
- 五、在 Flink SQL CLI 中使用 Flink DDL 创建表
- 六、Kibana查看ElasticSearch数据
- 七、在 TiDB增删改数据,观察 ElasticSearch 中的结果
一、通过docker 来启动 TiDB 集群
git clone https://github.com/pingcap/tidb-docker-compose.git
替换目录 tidb-docker-compose 里面的 docker-compose.yml 文件,内容如下所示:
version: "2.1"services:pd:image: pingcap/pd:v5.3.1ports:- "2379:2379"volumes:- ./config/pd.toml:/pd.toml- ./logs:/logscommand:- --client-urls=http://0.0.0.0:2379- --peer-urls=http://0.0.0.0:2380- --advertise-client-urls=http://pd:2379- --advertise-peer-urls=http://pd:2380- --initial-cluster=pd=http://pd:2380- --data-dir=/data/pd- --config=/pd.toml- --log-file=/logs/pd.logrestart: on-failuretikv:image: pingcap/tikv:v5.3.1ports:- "20160:20160"volumes:- ./config/tikv.toml:/tikv.toml - ./logs:/logs command:- --addr=0.0.0.0:20160- --advertise-addr=tikv:20160- --data-dir=/data/tikv- --pd=pd:2379- --config=/tikv.toml- --log-file=/logs/tikv.logdepends_on:- "pd"restart: on-failuretidb:image: pingcap/tidb:v5.3.1ports:- "4000:4000"volumes:- ./config/tidb.toml:/tidb.toml- ./logs:/logscommand:- --store=tikv- --path=pd:2379- --config=/tidb.toml- --log-file=/logs/tidb.log- --advertise-address=tidbdepends_on:- "tikv"restart: on-failureelasticsearch:image: elastic/elasticsearch:7.6.0container_name: elasticsearchenvironment:- cluster.name=docker-cluster- bootstrap.memory_lock=true- "ES_JAVA_OPTS=-Xms512m -Xmx512m"- discovery.type=single-nodeports:- "9200:9200"- "9300:9300"ulimits:memlock:soft: -1hard: -1nofile:soft: 65536hard: 65536kibana:image: elastic/kibana:7.6.0container_name: kibanaports:- "5601:5601"volumes:- /var/run/docker.sock:/var/run/docker.sock
该 Docker Compose 中包含的容器有:
- TiDB 集群: tikv、pd、tidb。
- Elasticsearch:orders 表将和 products 表进行 join,join 的结果写入 Elasticsearch 中。
- Kibana:可视化 Elasticsearch 中的数据。
本机添加 host 映射 pd 和 tikv 映射 127.0.0.1。 在 docker-compose.yml 所在目录下运行如下命令以启动所有容器:
docker-compose up -d
mysql -h 127.0.0.1 -P 4000 -u root # Just test tidb cluster is ready,if you have install mysql local.
该命令会以 detached 模式自动启动 Docker Compose 配置中定义的所有容器。 你可以通过 docker ps 来观察上述的容器是否正常启动了。 也可以访问 http://localhost:5601/ 来查看 Kibana 是否运行正常。
另外可以通过如下命令停止并删除所有的容器:
docker-compose down
二、下载 Flink 和所需要的依赖包
下载 Flink 1.17.1 并将其解压至目录 flink-1.17.1
https://archive.apache.org/dist/flink/flink-1.17.1/flink-1.17.1-bin-scala_2.12.tgz
下载下面列出的依赖包,并将它们放到目录 flink-1.17.1/lib/ 下:
- flink-connector-tidb-cdc-2.4.1.jar
- flink-sql-connector-elasticsearch7-3.0.1-1.17.jar
三、在TiDB数据库中创建表和准备数据
创建数据库和表 products,orders,并插入数据:
-- TiDB
CREATE DATABASE mydb;
USE mydb;
CREATE TABLE products (id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,name VARCHAR(255) NOT NULL,description VARCHAR(512)
) AUTO_INCREMENT = 101;INSERT INTO products
VALUES (default,"scooter","Small 2-wheel scooter"),(default,"car battery","12V car battery"),(default,"12-pack drill bits","12-pack of drill bits with sizes ranging from #40 to #3"),(default,"hammer","12oz carpenter's hammer"),(default,"hammer","14oz carpenter's hammer"),(default,"hammer","16oz carpenter's hammer"),(default,"rocks","box of assorted rocks"),(default,"jacket","water resistent black wind breaker"),(default,"spare tire","24 inch spare tire");CREATE TABLE orders (order_id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,order_date DATETIME NOT NULL,customer_name VARCHAR(255) NOT NULL,price DECIMAL(10, 5) NOT NULL,product_id INTEGER NOT NULL,order_status BOOLEAN NOT NULL -- Whether order has been placed
) AUTO_INCREMENT = 10001;INSERT INTO orders
VALUES (default, '2020-07-30 10:08:22', 'Jark', 50.50, 102, false),(default, '2020-07-30 10:11:09', 'Sally', 15.00, 105, false),(default, '2020-07-30 12:00:30', 'Edward', 25.25, 106, false);四、启动Flink 集群,再启动 SQL CLI
使用下面的命令跳转至 Flink 目录下
cd flink-1.17.1
使用下面的命令启动 Flink 集群
./bin/start-cluster.sh
启动成功的话,可以在 http://localhost:8081/ 访问到 Flink Web UI,如下所示:
使用下面的命令启动 Flink SQL CLI
./bin/sql-client.sh
启动成功后,可以看到如下的页面:
五、在 Flink SQL CLI 中使用 Flink DDL 创建表
首先,开启 checkpoint,每隔3秒做一次 checkpoint
-- Flink SQL
Flink SQL> SET execution.checkpointing.interval = 3s;
使用 Flink SQL CLI 创建对应的表,用于同步这些底层数据库表的数据
Flink SQL> CREATE TABLE products (id INT,name STRING,description STRING,PRIMARY KEY (id) NOT ENFORCED) WITH ('connector' = 'tidb-cdc','tikv.grpc.timeout_in_ms' = '20000','pd-addresses' = '127.0.0.1:2379','database-name' = 'mydb','table-name' = 'products');Flink SQL> CREATE TABLE orders (order_id INT,order_date TIMESTAMP(3),customer_name STRING,price DECIMAL(10, 5),product_id INT,order_status BOOLEAN,PRIMARY KEY (order_id) NOT ENFORCED) WITH ('connector' = 'tidb-cdc','tikv.grpc.timeout_in_ms' = '20000','pd-addresses' = '127.0.0.1:2379','database-name' = 'mydb','table-name' = 'orders'
);Flink SQL> CREATE TABLE enriched_orders (order_id INT,order_date DATE,customer_name STRING,order_status BOOLEAN,product_name STRING,product_description STRING,PRIMARY KEY (order_id) NOT ENFORCED) WITH ('connector' = 'elasticsearch-7','hosts' = 'http://localhost:9200','index' = 'enriched_orders_1');
将关联后的数据插入到ElasticSearch
Flink SQL> INSERT INTO enriched_ordersSELECT o.order_id, o.order_date, o.customer_name, o.order_status, p.name, p.descriptionFROM orders AS oLEFT JOIN products AS p ON o.product_id = p.id;
六、Kibana查看ElasticSearch数据
检查最终的结果是否写入 ElasticSearch 中,可以在 Kibana 看到 ElasticSearch 中的数据。
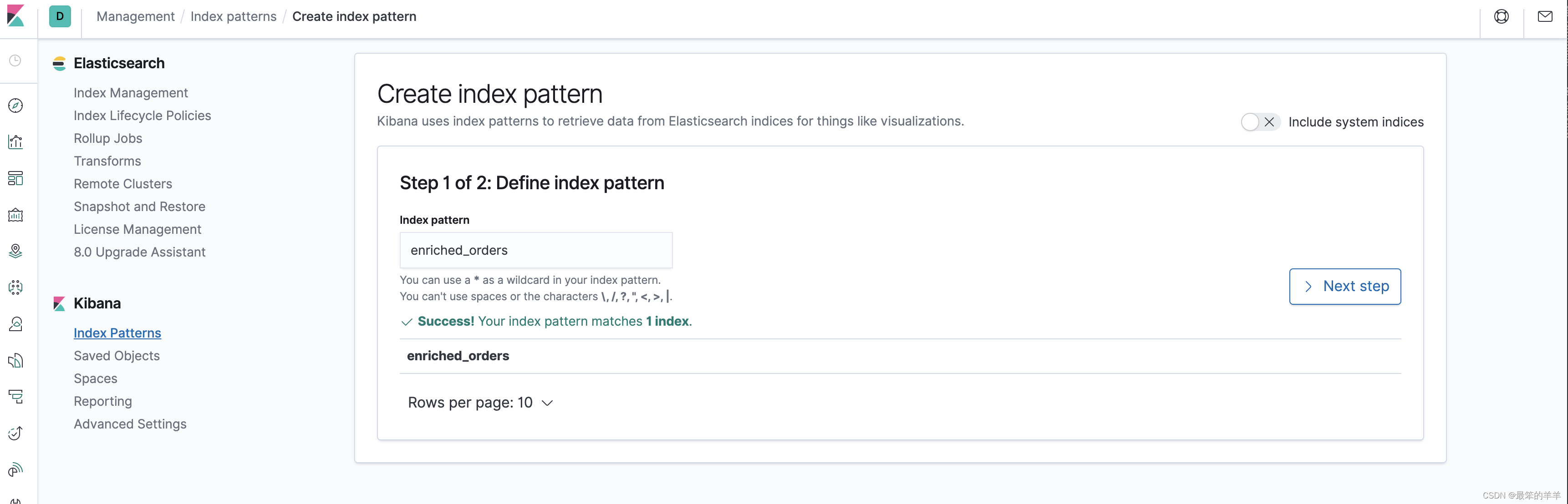
首先访问 http://localhost:5601/app/kibana#/management/kibana/index_pattern 创建 index pattern enriched_orders.
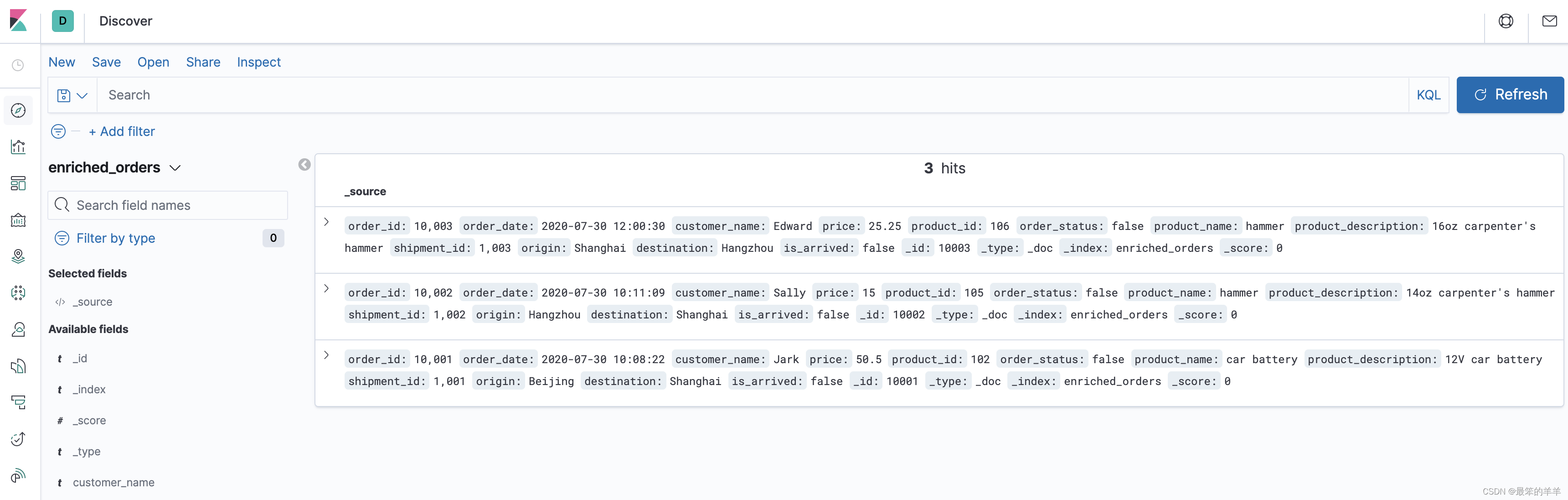
然后就可以在 http://localhost:5601/app/kibana#/discover 看到写入的数据了.
七、在 TiDB增删改数据,观察 ElasticSearch 中的结果
通过如下的 SQL 语句对 TiDB 数据库进行一些修改,然后就可以看到每执行一条 SQL 语句,Elasticsearch 中的数据都会实时更新。
INSERT INTO orders
VALUES (default, '2020-07-30 15:22:00', 'Jark', 29.71, 104, false);UPDATE orders SET order_status = true WHERE order_id = 10004;DELETE FROM orders WHERE order_id = 10004;
相关文章:
Flink CDC系列之:TiDB CDC 导入 Elasticsearch
Flink CDC系列之:TiDB CDC 导入 Elasticsearch 一、通过docker 来启动 TiDB 集群二、下载 Flink 和所需要的依赖包三、在TiDB数据库中创建表和准备数据四、启动Flink 集群,再启动 SQL CLI五、在 Flink SQL CLI 中使用 Flink DDL 创建表六、Kibana查看Ela…...

未来混合动力汽车的发展:技术探索与前景展望
随着环境保护意识的增强和对能源消耗的关注,混合动力汽车成为了汽车行业的研发热点。混合动力汽车融合了传统燃油动力和电力动力系统,通过优化能源利用效率,既降低了燃油消耗和排放,又提供了更长的续航里程。本文将探讨混合动力汽…...

C进阶(2/7)前篇——指针进阶
前言:本文章讲解部分指针进阶内容。后续继续更新。 文章重点: 1. 字符指针 2. 数组指针 3. 指针数组 4. 数组传参和指针传参 目录 前言:本文章讲解部分指针进阶内容。后续继续更新。 指针初阶了解: 1.字符指针 1.1一道有关于字…...
C 内存分配器 mimalloc
有论文 … … https://www.microsoft.com/en-us/research/publication/mimalloc-free-list-sharding-in-action/ 可以减少内存碎片,微软研究院2019 年开源出的内存分配器 代码,适配linux...

leetcode做题笔记74搜索二维矩阵
给你一个满足下述两条属性的 m x n 整数矩阵: 每行中的整数从左到右按非递减顺序排列。每行的第一个整数大于前一行的最后一个整数。 给你一个整数 target ,如果 target 在矩阵中,返回 true ;否则,返回 false 。 思…...

深信服数据中心管理系统 XXE漏洞复现
0x01 产品简介 深信服数据中心管理系统DC为AC的外置数据中心,主要用于海量日志数据的异地扩展备份管理,多条件组合的高效查询,统计和趋势报表生成,设备运行状态监控等功能。 0x02 漏洞概述 深信服数据中心管理系统DC存在XML外部实…...

【Kubernetes】Kubernetes的Pod进阶
Pod进阶 一、资源限制和重启策略1. 资源限制2. 资源单位2.1 CPU 资源单位2.2 内存 资源单位 3. 重启策略(restartPolicy) 二、健康检查的概念1. 健康检查1.1 探针的三种规则1.2 Probe 支持三种检查方法 2. 示例2.1 exec 方式2.2 httpGet 方式2.3 tcpSock…...

都错了!机械硬盘远比SSD更省电 最多领先94%
相信在绝大多数人的认知中,SSD固态硬盘因为没有HDD机械硬盘那样的移动部件,不但更稳定,还更省电。 但是,存储服务商Scality的研究表明,恰恰相反,HDD更省电。 他们以美光6500 ION 30.72TB QLC SSD、希捷银河…...
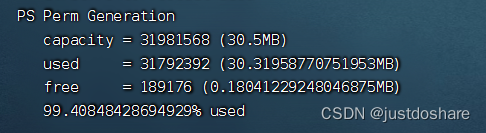
tomcat设置PermSize
最近tomcat老是报错,查看了日志出现PermGen 内存不够用,重启tomcat后查询使用情况 通过启动参数发现没有设置 PermGen,继续通过jmap查看 jmap -heap 21179 发现99%已使用,而且默认是30.5M,太小了,这里设置成256M 1. 创建setenv.sh文件 在/usr/local/tomcat/bin目录下创建一个…...
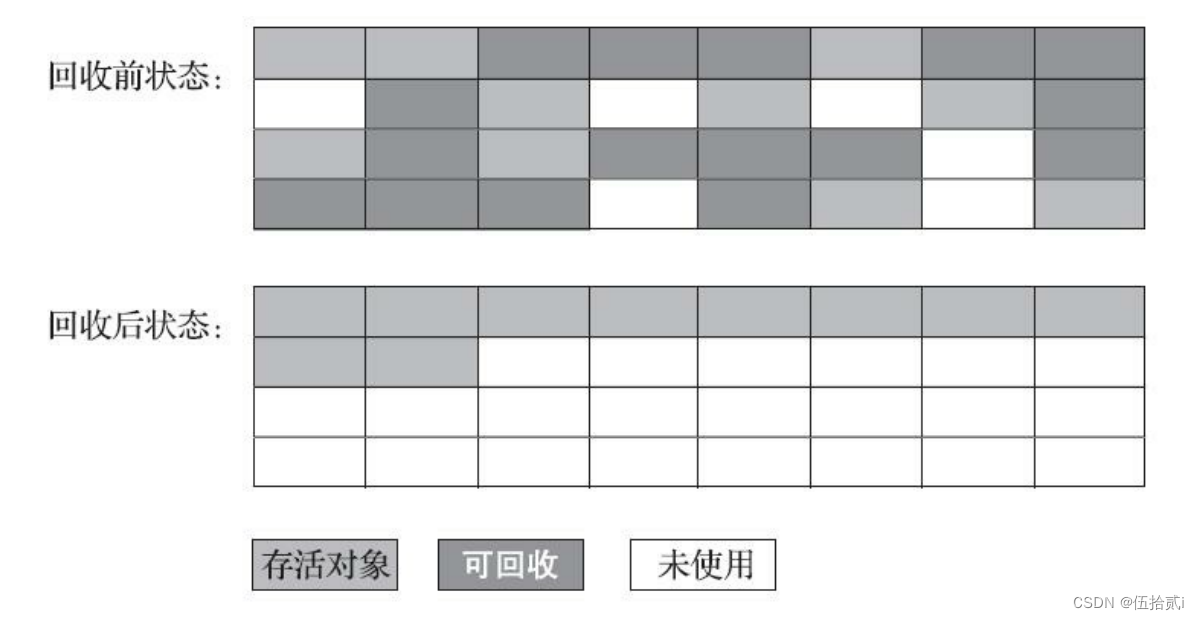
JVM——分代收集理论和垃圾回收算法
一、分代收集理论 1、三个假说 弱分代假说:绝大多数对象都是朝生夕灭的。 强分代假说:熬过越多次垃圾收集过程的对象越难以消亡。 这两个分代假说共同奠定了多款常用的垃圾收集器的一致的设计原则:收集器应该将Java堆划分出不同的区域&…...

jar包独立运行的几种方式
linux启动jar包的方式,直接运行与守护进程运行 通常我们开发好的程序需要打成war/jar包,在linux运行,war包好说直接丢在tomcat中即可,如果开发好的程序为jar包的话,方式比较多 直接启动(java-jar xxx.jar) java -jar shareniu.jar 特点:当前ssh窗口被锁定&#x…...

[python] 安装numpy+scipy+matlotlib+scikit-learn及问题解决
这篇文章主要讲述Python如何安装Numpy、Scipy、Matlotlib、Scikit-learn等库的过程及遇到的问题解决方法。最近安装这个真是一把泪啊,各种不兼容问题和报错,希望文章对你有所帮助吧!你可能遇到的问题包括: ImportError: N…...

uniapp使用命令创建页面
package.js下创建命令 "scripts": {"add": "node ./auto/addPage.ts" } package.js同级目录创建auto/addPage.ts addPage.ts代码如下 const fs require(fs) const path require(path) const targetPath process.argv[2];// 要创建的目录地…...

Linux(进程控制)
进程控制 进程创建fork函数初识fork函数返回值写时拷贝fork常规用法fork调用失败的原因 进程终止进程退出码进程常见退出方法 进程等待进程等待必要性获取子进程status进程等待的方法 阻塞等待与非阻塞等待阻塞等待非阻塞等待 进程替换替换原理替换函数函数解释命名理解 做一个…...
进制介绍)
Java学习笔记——(18)进制介绍
对于整数,有四种表示方式: 二进制:0,1 ,满 2 进 1.以 0b 或 0B 开头。(注:书写二进制时需要按四位数字一组的方式书写,缺的前面补0)十进制:0-9 ,满 10 进 1。…...
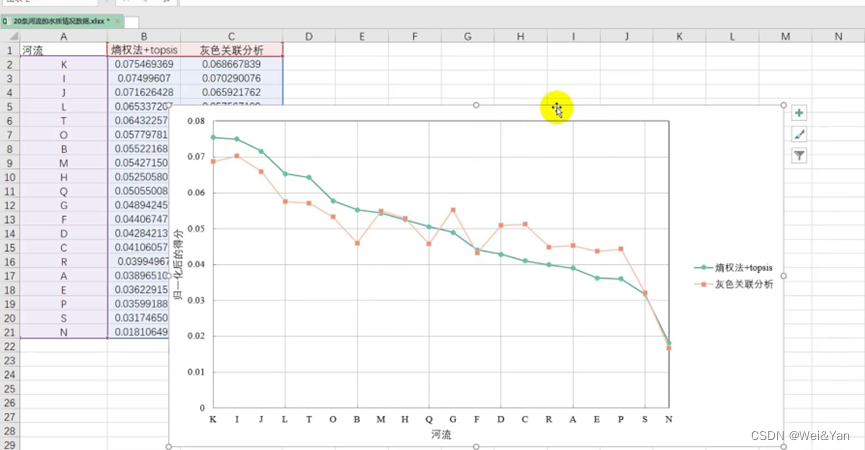
【数学建模】--灰色关联分析
系统分析: 一般的抽象系统,如社会系统,经济系统,农业系统,生态系统,教育系统等都包含有许多种因素,多种因素共同作用的结果决定了该系统的发展态势。人们常常希望知道在众多的因素中,哪些是主要…...

图像像素梯度
梯度 在高数中,梯度是一个向量,是有方向有大小。假设一二元函数f(x,y),在某点的梯度有: 结果为: 即方向导数。梯度的方向是函数变化最快的方向,沿着梯度的方向容易找到最大值。 图像梯度 在一幅模糊图…...

[论文笔记]Batch Normalization
引言 本文是论文神作Batch Normalization的阅读笔记,这篇论文引用量现在快50K了。 由于上一层参数的变化,导致每层输入的分布会在训练期间发生变化,让训练深层神经网络很复杂。这会拖慢训练速度,因为需要更低的学习率并小心地进行参数初始化,使得很难训练这种具有非线性…...

SpringCloud教程(中)
目录 八、Hystrix(服务降级) 8.1、Hystrix基本概念 8.1.1、分布式系统面临的问题 8.1.2、Hystrix是什么? 8.1.3、服务降级 概念 哪些情况会触发降级 8.1.4、服务熔断 8.1.5、服务限流 8.2、Hystrix案例 8.2.1、Hystrix支付微服务构…...

蓝帽杯2022
计算机取证 1 内存取证获取开机密码 现对一个windows计算机进行取证,请您对以下问题进行分析解答。 从内存镜像中获得taqi7的开机密码是多少?(答案参考格式:abcABC123) 首先我们直接对 1.dmp 使用 vol查看 py -2 v…...

瑞萨RZ系列核心板选型指南:从A55到RISC-V的嵌入式开发实战
1. 项目概述:当国产方案商遇上日系芯片巨头在嵌入式开发这个圈子里混久了,你会发现一个有趣的现象:很多项目在启动时,面临的第一个灵魂拷问往往不是“功能怎么实现”,而是“平台怎么选”。是追求极致的性能,…...

在Taotoken模型广场中根据任务需求挑选最合适的大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Taotoken模型广场中根据任务需求挑选最合适的大模型 1. 模型广场:统一查看与筛选的起点 当我们需要为特定的开发任务…...

1987年6月27日下午13-15点出生性格、运势和命运
1987年6月17日,下午15点到17点之间,正值盛夏时节,阳光炽烈而漫长。这一天出生的孩子,是中国改革开放后“黄金十年”中诞生的又一批弄潮儿。他们的成长轨迹,与全球化浪潮的涌入、市场经济的深化以及互联网的萌芽几乎同步…...

抖音批量下载解决方案:模块化架构与智能降级策略
抖音批量下载解决方案:模块化架构与智能降级策略 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖…...

vcs+verdi+vivado联合仿真
1.软件版本vivado和vcs的软件版本兼容Xilinx官方指导手册UG973本次使用的Vivado版本为2018.2图为Vivado2018.2支持的vcs版本,此时vcs有vcs和vcs-mx两种版本。VCS和VCS_MX的区别VCS_MX为mixed hdl 仿真器,支持vhdlverilogsv的混合仿真。vcs则是纯verilog的…...

终极歌词神器:5分钟学会用LDDC为你的音乐库添加完美歌词
终极歌词神器:5分钟学会用LDDC为你的音乐库添加完美歌词 【免费下载链接】LDDC 简单易用的精准歌词(逐字歌词/卡拉OK歌词)下载匹配工具|A simple and user-friendly tool for downloading and matching precise lyrics (word-by-word lyrics/Karaoke lyrics) 项目…...

【Linux】网络基础2---Socket编程预备
📌 相关专栏 【Linux专栏】【C语言专栏】【测试专栏】 上期回顾【Linux 】网络基础1 文章目录1. 理解源IP地址和目的IP地址2. 认识端口2.1端口号范围划分2.2 理解 "端⼝号" 和 "进程ID"2.3 源端口号与目的端口号2.4 理解Socket2. 传输层的典型代…...

3D格式转换神器:如何用stltostp轻松实现STL到STEP的无缝转换
3D格式转换神器:如何用stltostp轻松实现STL到STEP的无缝转换 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 你是否曾经遇到这样的困境?精心设计的3D打印模型在STL格式下…...

Aube:下一代 Node.js 包管理器,性能远超 pnpm
好的,我已经为您整理了关于新一代 Node.js 包管理器 Aube 的详细介绍文章。文章基于您提供的摘要和 GitHub 仓库的详细文档,扩充了功能介绍、使用场景和命令参考,以形成一个完整的详情页面。 Aube:下一代 Node.js 包管理器&#x…...

GEO优化避坑指南:告别关键词堆砌,用实体权威与结构化数据抢占AI推荐位
最近很多做技术的同行在后台问我:“为什么我写了那么多文章,AI搜索还是搜不到我的品牌?”这其实陷入了一个典型的误区:把GEO当成了换皮的SEO。在生成式AI时代,靠关键词堆砌和低质内容轰炸不仅无效,反而可能…...