当速度很重要时:使用 Hazelcast 和 Redpanda 进行实时流处理
在本教程中,了解如何构建安全、可扩展、高性能的应用程序,以释放实时数据的全部潜力。
在本教程中,我们将探索 Hazelcast 和 Redpanda 的强大组合,以构建对实时数据做出反应的高性能、可扩展和容错的应用程序。
Redpanda 是一个流数据平台,旨在处理高吞吐量、实时数据流。Redpanda 与 Kafka API 兼容,为 Apache Kafka 提供了高性能且可扩展的替代方案。Redpanda 独特的架构使其能够每秒处理数百万条消息,同时确保低延迟、容错和无缝可扩展性。
Hazelcast 是一个统一的实时流数据平台,通过独特地将流处理和快速数据存储相结合,实现对事件流和传统数据源的低延迟查询、聚合和状态计算,从而对动态数据进行即时操作。它允许您快速构建资源高效的实时应用程序。您可以以任何规模部署它,从小型边缘设备到大型云实例集群。
在这篇文章中,我们将指导您设置和集成这两种技术,以实现实时数据摄取、处理和分析,从而实现强大的流分析。最后,您将深入了解如何利用 Hazelcast 和 Redpanda 的组合功能来释放应用程序的流分析和即时操作的潜力。
那么,让我们开始吧!
Pizza in Motion:披萨外卖服务的解决方案架构
首先,让我们了解我们要构建什么。我们大多数人都喜欢披萨,所以让我们以披萨送货服务为例。我们的披萨外卖服务实时接收来自多个用户的订单。这些订单包含时间戳、user_id、pizza_type 和数量。我们将使用 Python 生成订单,将它们引入 Redpanda,然后使用 Hazelcast 处理它们。
但是,如果您想通过上下文数据丰富披萨订单怎么办?例如,为特定类型的披萨推荐特定的开胃菜。如何实时做到这一点?
实际上有多种选择,但在这篇博文中,我们将向您展示如何使用 Hazelcast 通过存储在 Hazelcast 的 iMap 中的开胃菜丰富来自 Redpanda 的披萨订单。
下面是该解决方案的简要示意图。
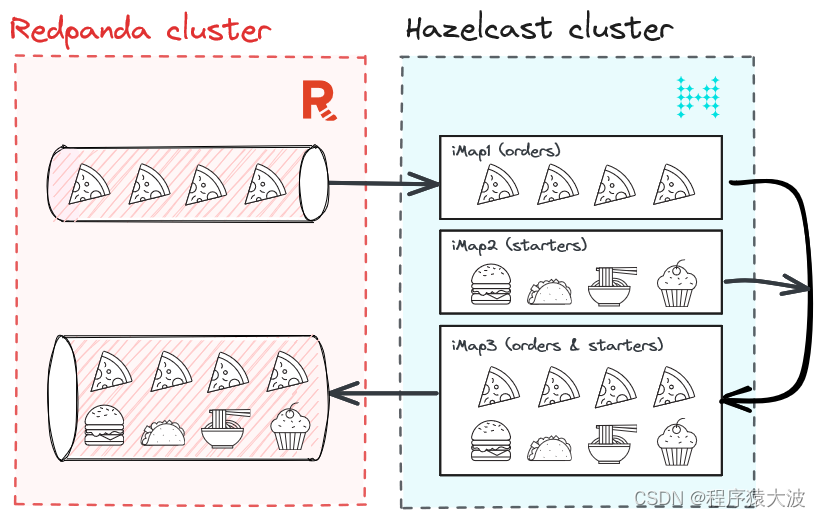
教程:使用 Redpanda 和 Hazelcast 进行实时流处理
设置 Redpanda
在本教程的范围内,我们将使用 Docker Compose 设置 Redpanda 集群。因此,请确保本地安装了 Docker Compose。
docker-compose.yml在您选择的位置创建文件并向其中添加以下内容。
version: "3.7"
name: redpanda-quickstart
networks:
redpanda_network:
driver: bridge
volumes:
redpanda-0: null
services:
redpanda-0:
command:
- redpanda
- start
- --kafka-addr internal://0.0.0.0:9092,external://0.0.0.0:19092
# Address the broker advertises to clients that connect to the Kafka API.
# Use the internal addresses to connect to the Redpanda brokers'
# from inside the same Docker network.
# Use the external addresses to connect to the Redpanda brokers'
# from outside the Docker network.
- --advertise-kafka-addr internal://redpanda-0:9092,external://localhost:19092
- --pandaproxy-addr internal://0.0.0.0:8082,external://0.0.0.0:18082
# Address the broker advertises to clients that connect to the HTTP Proxy.
- --advertise-pandaproxy-addr internal://redpanda-0:8082,external://localhost:18082
- --schema-registry-addr internal://0.0.0.0:8081,external://0.0.0.0:18081
# Redpanda brokers use the RPC API to communicate with eachother internally.
- --rpc-addr redpanda-0:33145
- --advertise-rpc-addr redpanda-0:33145
# Tells Seastar (the framework Redpanda uses under the hood) to use 1 core on the system.
- --smp 1
# The amount of memory to make available to Redpanda.
- --memory 1G
# Mode dev-container uses well-known configuration properties for development in containers.
- --mode dev-container
# enable logs for debugging.
- --default-log-level=debug
image: docker.redpanda.com/redpandadata/redpanda:v23.1.11
container_name: redpanda-0
volumes:
- redpanda-0:/var/lib/redpanda/data
networks:
- redpanda_network
ports:
- 18081:18081
- 18082:18082
- 19092:19092
- 19644:9644
console:
container_name: redpanda-console
image: docker.redpanda.com/redpandadata/console:v2.2.4
networks:
- redpanda_network
entrypoint: /bin/sh
command: -c 'echo "$$CONSOLE_CONFIG_FILE" > /tmp/config.yml; /app/console'
environment:
CONFIG_FILEPATH: /tmp/config.yml
CONSOLE_CONFIG_FILE: |
kafka:
brokers: ["redpanda-0:9092"]
schemaRegistry:
enabled: true
urls: ["http://redpanda-0:8081"]
redpanda:
adminApi:
enabled: true
urls: ["http://redpanda-0:9644"]
ports:
- 8080:8080
depends_on:- redpanda-0上面的文件包含使用单个代理启动 Redpanda 集群所需的配置。如果需要,您可以使用三代理集群。但是,对于我们的用例来说,单个经纪人就足够了。
请注意,仅建议在 Docker 上使用 Redpanda 进行开发和测试。对于其他部署选项,请考虑Linux或Kubernetes。
为了生成数据,我们使用 Python 脚本:
import asyncio
import json
import os
import random
from datetime import datetimefrom kafka import KafkaProducer
from kafka.admin import KafkaAdminClient, NewTopicBOOTSTRAP_SERVERS = ("localhost:19092"if os.getenv("RUNTIME_ENVIRONMENT") == "DOCKER"else "localhost:19092"
)PIZZASTREAM_TOPIC = "pizzastream"
PIZZASTREAM_TYPES = ["Margherita","Hawaiian","Veggie","Meat","Pepperoni", "Buffalo","Supreme","Chicken",
]async def generate_pizza(user_id):producer = KafkaProducer(bootstrap_servers=BOOTSTRAP_SERVERS)while True:data = {"timestamp_": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),"pizza": random.choice(PIZZASTREAM_TYPES),"user_id": user_id,"quantity": random.randint(1, 10),}producer.send(PIZZASTREAM_TOPIC,key=user_id.encode("utf-8"),value=json.dumps(data).encode("utf-8"),)print(f"Sent a pizza stream event data to Redpanda: {data}")await asyncio.sleep(random.randint(1, 5))async def main():tasks = [generate_pizza(user_id)for user_id in [f"user_{i}" for i in range(10)]]await asyncio.gather(*tasks)if __name__ == "__main__":# Create kafka topics if running in Docker.if os.getenv("RUNTIME_ENVIRONMENT") == "DOCKER":admin_client = KafkaAdminClient(bootstrap_servers=BOOTSTRAP_SERVERS, client_id="pizzastream-producer")# Check if topics already exist firstexisting_topics = admin_client.list_topics()for topic in [PIZZASTREAM_TOPIC]:if topic not in existing_topics:admin_client.create_topics([NewTopic(topic, num_partitions=1, replication_factor=1)])asyncio.run(main())设置 Hazelcast
启动 Hazelcast 本地集群。这将以客户端/服务器模式运行 Hazelcast 集群以及在本地网络上运行的管理中心实例。
brew tap hazelcast/hz
brew install hazelcast@5.3.1
hz -V现在我们了解了要构建的内容并设置了先决条件,让我们直接进入解决方案。
步骤1:启动Redpanda集群
让我们通过在终端中运行以下命令来启动Redpanda 集群。确保您位于保存文件的同一位置docker-compose.yml。
docker compose up -d类似于以下内容的输出确认 Redpanda 集群已启动并正在运行。
[+] Running 4/4
⠿ Network redpanda_network Created 0.0s
⠿ Volume "redpanda-quickstart_redpanda-0" Created 0.0s
⠿ Container redpanda-0 Started 0.3s
⠿ Container redpanda-console Started 0.6s第 2 步:运行 Hazelcast
您可以运行以下命令来启动具有一个节点的 Hazelcast 集群。
hz start要将更多成员添加到集群,请打开另一个终端窗口并重新运行启动命令。
第 3 步:在 Hazelcast 上运行 SQL
我们将使用 SQL shell——在集群上运行 SQL 查询的最简单方法。您可以使用SQL查询地图和Kafka主题中的数据。结果可以直接发送到客户端或插入到地图或 Kafka 主题中。您还可以使用 Kafka Connector,它允许您在 Hazelcast 集群和 Kafka 之间流式传输、过滤和转换事件。您可以通过运行以下命令来执行此操作:
bin/hz-cli sql第 4 步:摄取 Hazelcast iMap (pizzastream)
使用 SQL 命令,我们创建pizzastreamMap:
CREATE OR REPLACE MAPPING pizzastream(
timestamp_ TIMESTAMP,
pizza VARCHAR,
user_id VARCHAR,
quantity DOUBLE
)
TYPE Kafka
OPTIONS (
'keyFormat' = 'varchar',
'valueFormat' = 'json-flat',
'auto.offset.reset' = 'earliest',
'bootstrap.servers' = 'localhost:19092');步骤 5:用推荐数据丰富流(推荐器)
对于这一步,我们创建另一个地图:
CREATE or REPLACE MAPPING recommender (
__key BIGINT,
user_id VARCHAR,
extra1 VARCHAR,
extra2 VARCHAR,
extra3 VARCHAR )
TYPE IMap
OPTIONS (
'keyFormat'='bigint',
'valueFormat'='json-flat');我们在 Map 中添加一些值:
INSERT INTO recommender VALUES
(1, 'user_1', 'Soup','Onion_rings','Coleslaw'),
(2, 'user_2', 'Salad', 'Coleslaw', 'Soup'),
(3, 'user_3', 'Zucchini_fries','Salad', 'Coleslaw'),
(4, 'user_4', 'Onion_rings','Soup', 'Jalapeno_poppers'),
(5, 'user_5', 'Zucchini_fries', 'Salad', 'Coleslaw'),
(6, 'user_6', 'Soup', 'Zucchini_fries', 'Coleslaw'),
(7, 'user_7', 'Onion_rings', 'Soup', 'Jalapeno_poppers'),
(8, 'user_8', 'Jalapeno_poppers', 'Coleslaw', 'Zucchini_fries'),
(9, 'user_9', 'Onion_rings','Jalapeno_poppers','Soup');第 6 步:使用 SQL 合并两个映射
基于上面两个Map,我们发送以下SQL查询:
SELECTpizzastream.user_id AS user_id,recommender.extra1 as extra1,recommender.extra2 as extra2,recommender.extra3 as extra3,pizzastream.pizza AS pizza
FROM pizzastream
JOIN recommender
ON recommender.user_id = recommender.user_id
AND recommender.extra2 = 'Soup';第7步:将组合数据流发送到Redpanda
为了将结果发送回 Redpanda,我们在 Hazelcast 中创建一个 Jet 作业,将 SQL 查询结果存储到一个新的 Map 中,然后存储到 Redpanda 中:
CREATE OR REPLACE MAPPING recommender_pizzastream(
timestamp_ TIMESTAMP,
user_id VARCHAR,
extra1 VARCHAR,
extra2 VARCHAR,
extra3 VARCHAR,
pizza VARCHAR
)
TYPE Kafka
OPTIONS (
'keyFormat' = 'int',
'valueFormat' = 'json-flat',
'auto.offset.rest' = 'earliest',
'bootstrap.servers' = 'localhost:19092'
);CREATE JOB recommender_job AS SINK INTO recommender_pizzastream SELECTpizzastream.timestamp_ as timestamp_,pizzastream.user_id AS user_id,recommender.extra1 as extra1,recommender.extra2 as extra2,recommender.extra3 as extra3,pizzastream.pizza AS pizza
FROM pizzastream
JOIN recommender
ON recommender.user_id = recommender.user_id
AND recommender.extra2 = 'Soup';结论
在这篇文章中,我们解释了如何使用 Redpanda 和 Hazelcast 构建披萨外卖服务。
Redpanda 通过将披萨订单作为高吞吐量流摄取、可靠地存储它们并允许 Hazelcast 以可扩展的方式使用它们来增加价值。一旦食用,Hazelcast 就会利用上下文数据丰富披萨订单(立即向用户推荐开胃菜),并将丰富的数据发送回 Redpanda。
Hazelcast 允许您快速构建资源高效的实时应用程序。您可以以任何规模部署它,从小型边缘设备到大型云实例集群。Hazelcast 节点集群共享数据存储和计算负载,可以动态扩展和缩减。
相关文章:
当速度很重要时:使用 Hazelcast 和 Redpanda 进行实时流处理
在本教程中,了解如何构建安全、可扩展、高性能的应用程序,以释放实时数据的全部潜力。 在本教程中,我们将探索 Hazelcast 和 Redpanda 的强大组合,以构建对实时数据做出反应的高性能、可扩展和容错的应用程序。 Redpanda 是一个流…...

筛法求欧拉函数
思路: (1)若要分别求1~n每个数的欧拉函数值,则复杂度O(n*n^0.5),超时; (2)于是考虑用欧拉筛进行求取; (3)欧拉筛:基于线…...

consul限制注册的ip
假设当前服务器的ip是:192.168.56.130 1、允许 所有ip 注册(验证可行) consul agent -server -ui -bootstrap-expect1 -data-dir/usr/local/consul -nodedevmaster -advertise192.168.56.130 -bind0.0.0.0 -client0.0.0.0 2、只允许 当前ip 注册 consul agent -…...
用AI攻克“智能文字识别创新赛题”,这场大学生竞赛掀起了什么风潮?
文章目录 一、前言1.1 大赛介绍1.2 项目背景 二、基于智能文字场景个人财务管理创新应用2.1 作品方向2.2 票据识别模型2.2.1 文本卷积神经网络TextCNN2.2.2 Bert 预训练微调2.2.3 模型对比2.2.4 效果展示 2.3 票据文字识别接口 三、未来展望 一、前言 1.1 大赛介绍 中国大学生…...

EJB基本概念和使用
一、EJB是什么? EJB是sun的JavaEE服务器端组件模型,是一种规范,设计目标与核心应用是部署分布式应用程序。EJB2.0过于复杂,EJB3.0的推出减轻了开发人员进行底层开发的工作量,它取消或最小化了很多(以前这些是必须实现)…...

神经网络基础-神经网络补充概念-09-m个样本的梯度下降
概念 当应用梯度下降算法到具有 m 个训练样本的逻辑回归问题时,我们需要对每个样本计算梯度并进行平均,从而更新模型参数。这个过程通常称为批量梯度下降(Batch Gradient Descent)。 代码实现 import numpy as npdef sigmoid(z…...

分布式 - 消息队列Kafka:Kafka消费者分区再均衡(Rebalance)
文章目录 01. Kafka 消费者分区再均衡是什么?02. Kafka 消费者分区再均衡的触发条件?03. Kafka 消费者分区再均衡的过程?04. Kafka 如何判定消费者已经死亡?05. Kafka 如何避免消费者的分区再均衡?06. Kafka 消费者分区再均衡有什…...
BIO、NIO和AIO
一.引言 何为IO 涉及计算机核心(CPU和内存)与其他设备间数据迁移的过程,就是I/O。数据输入到计算机内存的过程即输入,反之输出到外部存储(比如数据库,文件,远程主机)的过程即输出。 I/O 描述了计算机系统…...
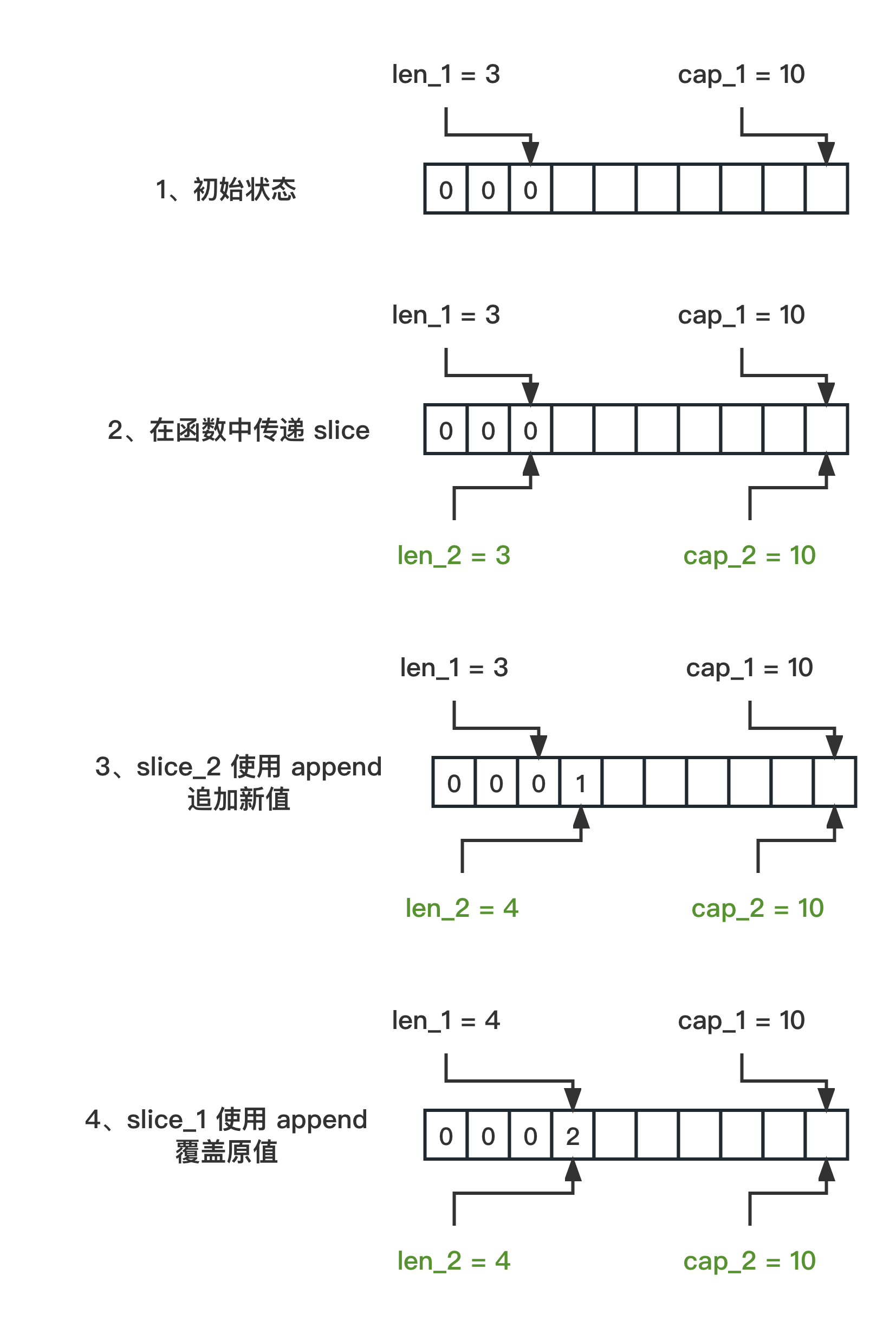
理解 Go 中的切片:append 操作的深入分析(篇1)
理解 Go 语言中 slice 的性质对于编程非常有益。下面,我将通过两个代码示例来解释切片在不同函数之间传递并执行 append 操作时的具体表现。 本篇为第 1 篇,当切片的容量 cap 充足时 第一份代码 slice1 的初始长度为 3,容量为 10 func main()…...
由于找不到mfc140u.dll,无法继续执行代码怎么修复?
当我在使用某个应用程序时遇到了mfc140u.dll缺失的错误提示时,我意识到这是由于该动态链接库文件丢失或损坏所引起的。mfc140u.dll是MFC的一部分,它包含了许多与用户界面、窗口管理、控件等相关的函数和类。这个文件通常用于支持使用MFC开发的应用程序的…...

【0.1】lubancat鲁班猫4刷入debian网络ping 域名不通问题
目录 1. 环境2. 操作步骤 1. 环境 lubancat4鲁班猫4 (4G0)不带emmc系统镜像lubancat-rk3588-debian11-gnome-20230807_update.img官方资料地址https://doc.embedfire.com/products/link/zh/latest/linux/ebf_lubancat.html 2. 操作步骤 从官网给的百度网盘下载linux系统全部…...
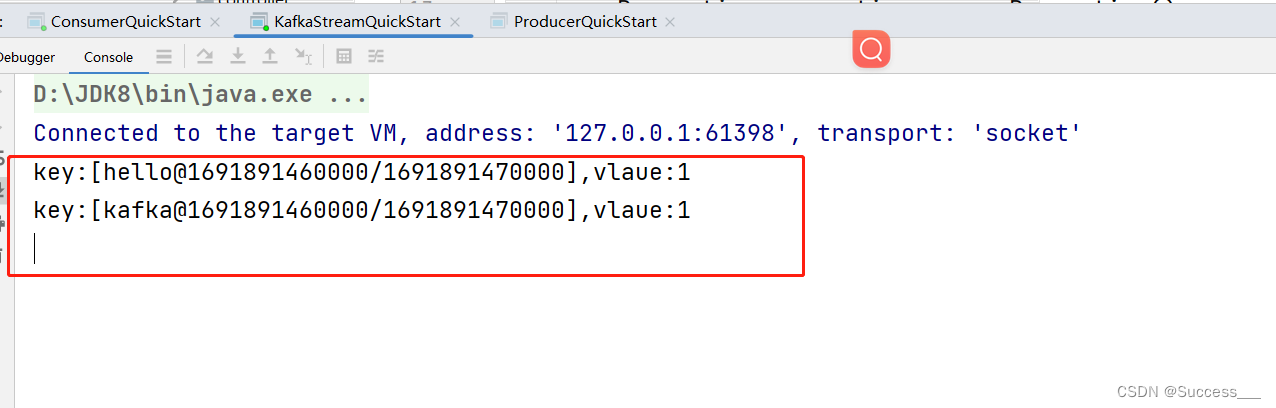
KafkaStream:基本使用
简介: kafkaStream:提供了对存储在kafka中的数据进行流式处理和分析的功能 特点: KafkasSream提供了一个非常简单轻量的Library,它可以非常方便的嵌入到java程序中,也可以任何方式打包部署 入门案例: 1、…...
【数据结构】二叉树
完全二叉树 是指所有结点度数小于等于2的树 所以这种情况也是: 几条性质 一个具有n个结点的完全二叉树的深度为: log 2 ( n 1 ) 的结果向上取整。 \\\log_{2}(n1) \ \ 的结果向上取整。 log2(n1) 的结果向上取整。设度为0的结点个数是n0&#…...
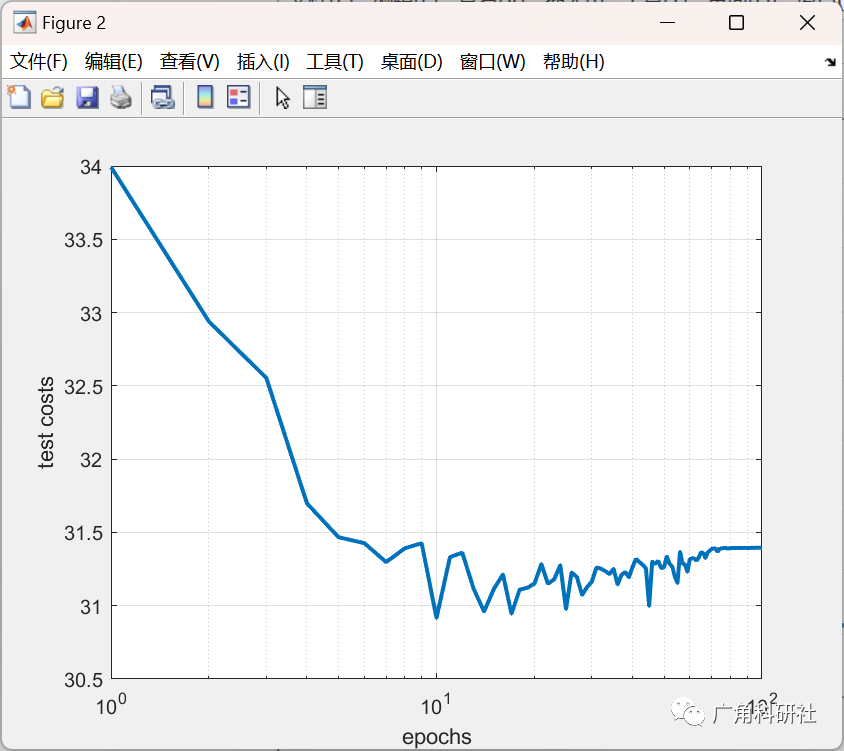
基于灰狼优化(GWO)、帝国竞争算法(ICA)和粒子群优化(PSO)对梯度下降法训练的神经网络的权值进行了改进(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
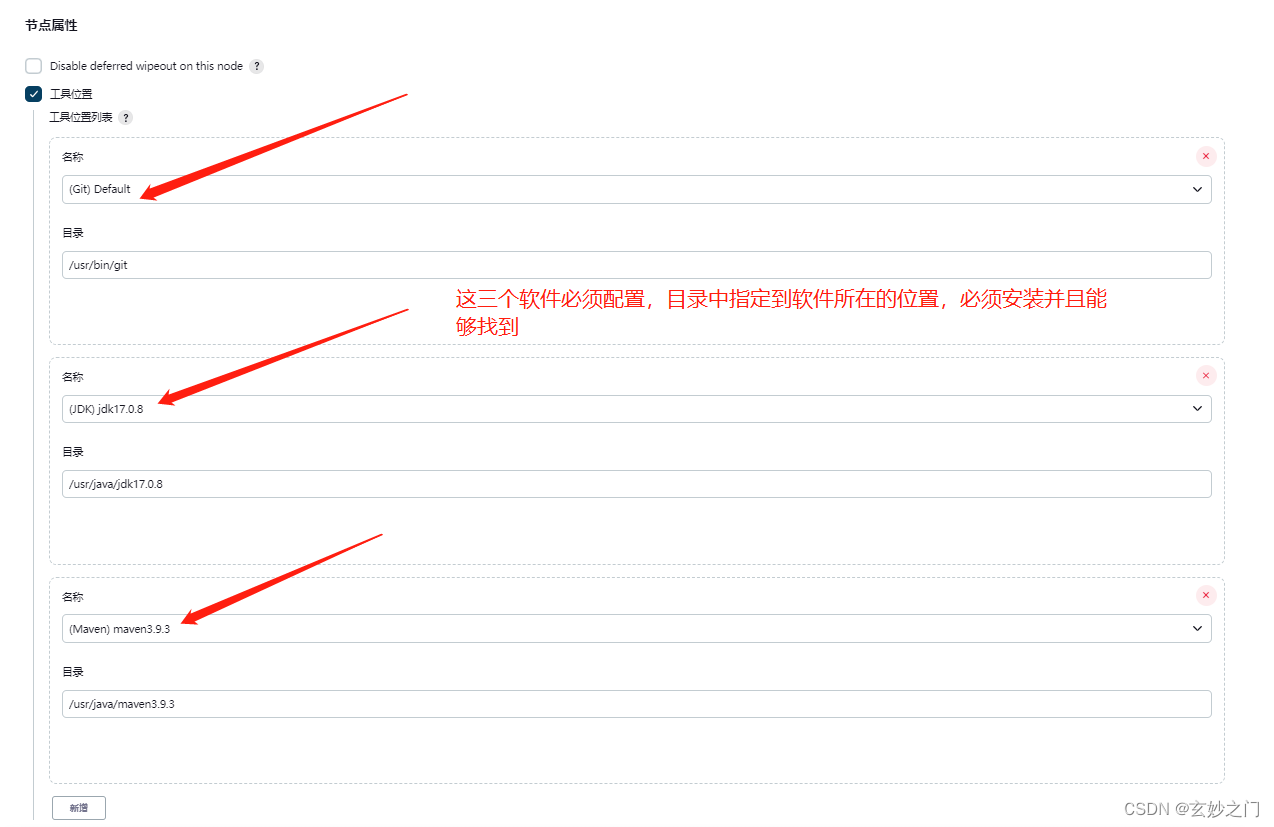
jenkins自动化构建保姆级教程(持续更新中)
1.安装 1.1版本说明 访问jenkins官网 https://www.jenkins.io/,进入到首页 点击【Download】按钮进入到jenkins下载界面 左侧显示的是最新的长期支持版本,右侧显示的是最新的可测试版本(可能不稳定),建议使用最新的…...

HTTPS 的加密流程
目录 一、HTTPS是什么? 二、为什么要加密 三、"加密" 是什么 四、HTTPS 的工作过程 1.对称加密 2.非对称加密 3.中间人攻击 4.证书 总结 一、HTTPS是什么? HTTPS (Hyper Text Transfer Protocol Secure) 是基于 HTTP 协议之上的安全协议&…...
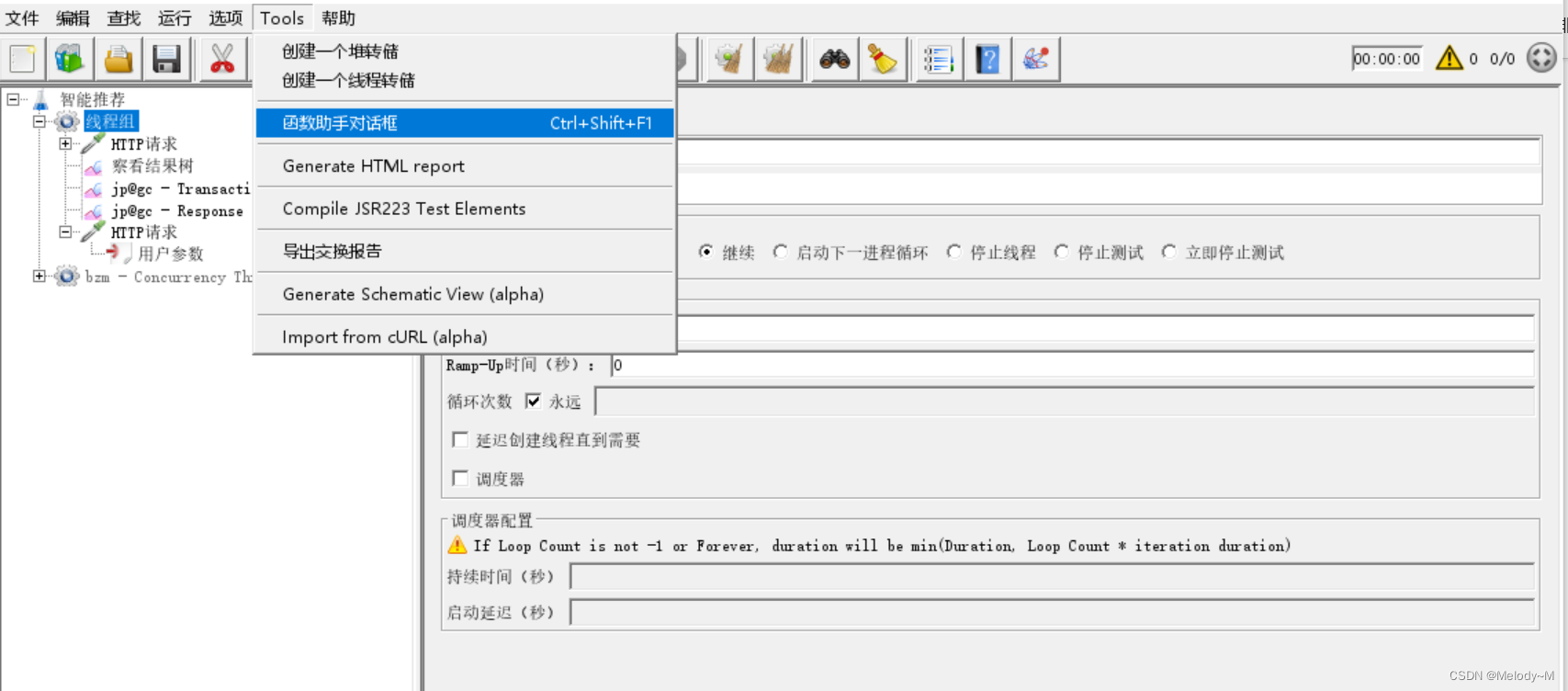
Jmeter 参数化的几种方法
目录 配置元件-用户自定义变量 前置处理器-用户参数 配置元件-CSV Data Set Config Tools-函数助手 配置元件-用户自定义变量 可在测试计划、线程组、HTTP请求下创建用户定义的变量 全局变量,可以跨线程组调用 jmeter执行的时候,只获取一次࿰…...

剑指Offer45.把数组排成最小的数 C++
1、题目描述 输入一个非负整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个。 示例 1: 输入: [10,2] 输出: “102” 示例 2: 输入: [3,30,34,5,9] 输出: “3033459” 2、VS2019上运行 先转换成字符串再组合起来 #in…...
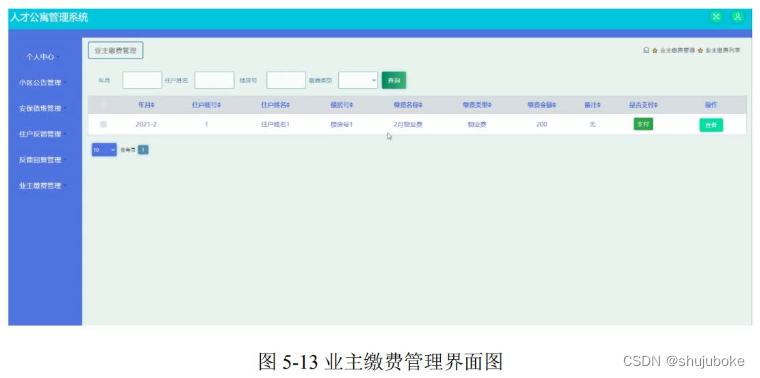
【java毕业设计】基于SSM+MySql的人才公寓管理系统设计与实现(程序源码)--人才公寓管理系统
基于SSMMySql的人才公寓管理系统设计与实现(程序源码毕业论文) 大家好,今天给大家介绍基于SSMMySql的人才公寓管理系统设计与实现,本论文只截取部分文章重点,文章末尾附有本毕业设计完整源码及论文的获取方式。更多毕业…...
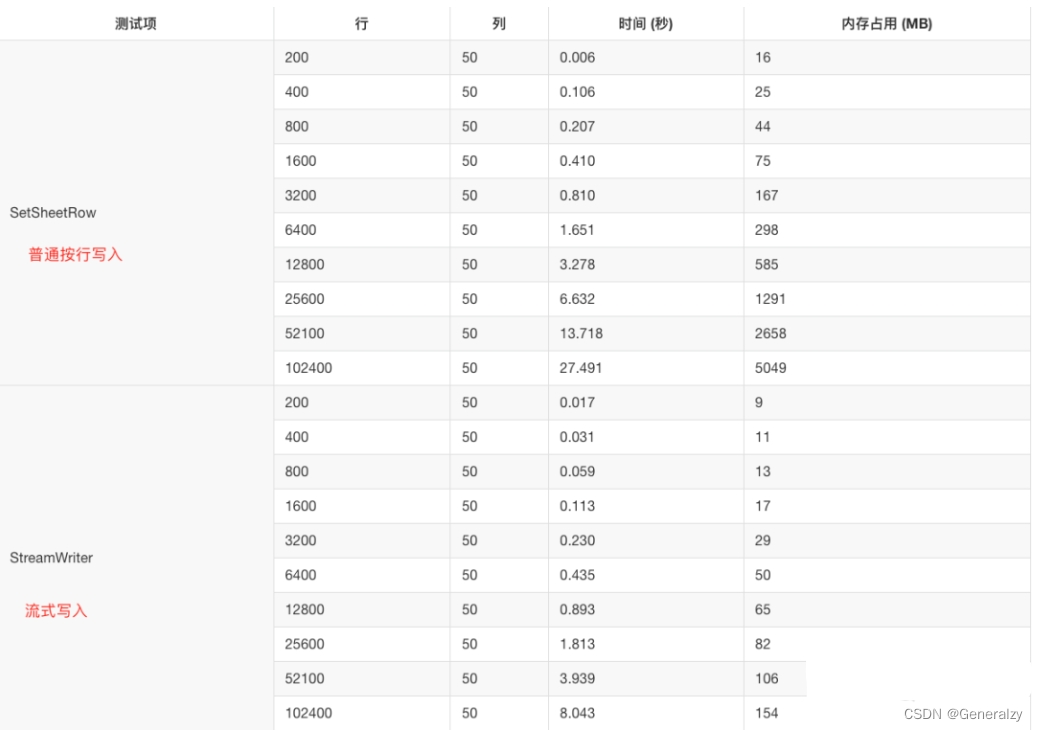
golang操作excel的高性能库——excelize/v2
目录 介绍文档与源码安装快速开始创建 Excel 文档读取 Excel 文档打开数据流流式写入 [相关 Excel 开源类库性能对比](https://xuri.me/excelize/zh-hans/performance.html) 介绍 Excelize是一个纯Go编写的库,提供了一组功能,允许你向XLAM / XLSM / XLS…...

不只是连线:深入理解模拟版图中电阻的‘Segment’与‘M’参数对实际阻值的影响
不只是连线:深入理解模拟版图中电阻的‘Segment’与‘M’参数对实际阻值的影响 在模拟集成电路设计中,电阻作为最基本的无源元件之一,其版图实现往往被初学者视为简单的金属连线问题。然而,当设计从原理图转向物理实现时ÿ…...

影刀RPA跨境店群运营架构:Python协同Chromium底层调度与高并发容器化架构
定了。在这场旷日持久的跨境电商反爬风控拉锯战中,我们终于用一套基于 Python 深度协同的分布式微服务调度架构,重塑了跨境千店矩阵的自动化底座。 这几天,科技圈被“DeepSeek V4 首发华为昇腾芯片,国产 AI 开始打破英伟达 CUDA …...

钉钉知识库日志迁移至Cursor的实践方法和具体操作步骤
一、钉钉知识库导出方法 方法1:手动导出(适合文档数量较少) 操作步骤: 电脑端钉钉 → 左下角【更多】→【文档】→【知识库】 进入目标知识库,打开需要迁移的文档 点击页面左上角 【文档】→【下载为】 选择导出格式:Word (.docx)、PDF 或 长图 文件默认以当前文档…...
)
DeepSeek SSO性能压测实录:单集群支撑5000+并发登录的4大调优阈值(含Prometheus监控指标基线)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek SSO单点登录性能压测全景概览 DeepSeek SSO 作为企业级统一身份认证中枢,其在高并发场景下的响应延迟、会话稳定性与令牌签发吞吐能力直接决定下游所有业务系统的可用性边界。本章…...

开发智能客服系统时利用 Taotoken 实现模型降级与容灾路由的策略
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发智能客服系统时利用 Taotoken 实现模型降级与容灾路由的策略 在构建面向真实用户的智能客服系统时,服务的连续性与…...

联想拯救者工具箱终极指南:完全替代Vantage的轻量级硬件管理方案
联想拯救者工具箱终极指南:完全替代Vantage的轻量级硬件管理方案 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/LenovoLegionToolkit …...

CXPatcher:让Mac上的CrossOver性能飞升的终极指南
CXPatcher:让Mac上的CrossOver性能飞升的终极指南 【免费下载链接】CXPatcher A patcher to upgrade Crossover dependencies and improve compatibility 项目地址: https://gitcode.com/gh_mirrors/cx/CXPatcher 你是否曾经在Mac上尝试运行Windows游戏时感到…...

Bilibili神奇弹幕机器人:打造智能直播间的完整免费解决方案
Bilibili神奇弹幕机器人:打造智能直播间的完整免费解决方案 【免费下载链接】MagicalDanmaku 本仓库及所有相关项目已永久停止开发、维护和任何形式的分发。 项目地址: https://gitcode.com/gh_mirrors/bi/MagicalDanmaku 想要让你的B站直播间实现自动化运营…...

怎么远程操作另一台手机 手机能远程控制别的手机吗
想远程操作另一台手机应急?不管是忘带工作机需回复客户消息,还是手游玩家用备用机远程控制主力机挂机领福利,都需要好用的工具。市面上能远程操作另一台手机的软件不少,但是却多有短板,难以适配需求。推荐无界趣连2.0&…...

构建企业级智能设计转换桥梁:Unity Figma Bridge高性能自动化集成方案深度解析
构建企业级智能设计转换桥梁:Unity Figma Bridge高性能自动化集成方案深度解析 【免费下载链接】UnityFigmaBridge Easily bring your Figma Documents, Components, Assets and Prototypes to Unity 项目地址: https://gitcode.com/gh_mirrors/un/UnityFigmaBrid…...