python爬虫6:lxml库
python爬虫6:lxml库
前言
python实现网络爬虫非常简单,只需要掌握一定的基础知识和一定的库使用技巧即可。本系列目标旨在梳理相关知识点,方便以后复习。
申明
本系列所涉及的代码仅用于个人研究与讨论,并不会对网站产生不好影响。
目录结构
文章目录
- python爬虫6:lxml库
- 1. 简介
- 2. 使用与语法
- 2.1 初始化
- 2.2 方法基础
- 2.3 寻找节点
- 2.4 筛选节点
- 2.5 获取属性值或文本内容
- 3. 总结
1. 简介
lxml库是python的第三方库,安装方式也是十分简单(pip安装),这里就不多赘述。而lxml库的特点就是简单和易上手,并且解析大型文档(特指xml或html文档)的速度也是比较快的,因此写爬虫解析网页的时候它也是我们的一个不错的选择。
这里大家需要明白一个事情:解析网页,其实就是去获取网页源码中的某些节点中的文本内容或属性值。举个例子,比如我们爬取的是小说网站,那么一般获取的是html代码中某些节点的文本值,再比如我们爬取图片网站,那么一般获取的是html代码中某些节点的属性值,这个属性值一般为url地址,但是这个地址指向的是图片内容而已。
2. 使用与语法
2.1 初始化
初始化:使用lxml库的第一个步骤永远是初始化,只有初始化之后我们才可以去使用它的语法。
初始化方法:
html = etree.HTML(text)
其中:
text : html内容的字符串
html : 一个lxml库的对象
例子:
from lxml import etree #我们主要使用的lxml库中的etree库
text = '''
<body><div class="key"><div class="iocnBox"><i class="iconfont icon-delete"></i></div><div class="empty">清空</div><textarea placeholder="在此述说新年寄语..." rows="1" class="van-field__control"></textarea><div class="buts">发送</div></div>
'''
#开始初始化
html = etree.HTML(text) #这里需要传入一个html形式的字符串
2.2 方法基础
lxml库的语法就是基于xpath语法来的,所以会了xpath语法,自然就会了lxml语法。而在lxml库中,加载xpath语法的方法为:html.xpath('xpath语法')。
而且观察返回的结果,发现大部分返回的都是以列表的形式返回的结果,这一点请注意。
2.3 寻找节点
| 语法 | 含义 |
|---|---|
| nodename(节点名字) | 直接根据写的节点名字查找节点,如:div |
| // | 在当前节点下的子孙节点中寻找,如://div |
| / | 在当前节点下的子节点中寻找,如:/div |
| . | 代表当前节点(可省略不写,就像我们有时候写的相对路径),如:./div |
| … | 当前节点的父节点,如:…/div |
下面来个例子:
from lxml import etreetext = '''
<body><div>这时测试的div</div><div><div>这是嵌套的div标签<p>这时嵌套的p标签</p></div></div><p>这时测试的p</p>
</body>
'''html = etree.HTML(text)
result = html.xpath('//div') #使用xpath语法,一是在子孙节点中寻找,二是寻找div的标签
print(result)
#结果:
#[<Element div at 0x1e4cadbf608>, <Element div at 0x1e4cae512c8>, <Element div at 0x1e4cae51348>]
2.4 筛选节点
上面只是找到节点,但是找到符合条件的结果非常多,因此我们需要进行筛选工作。
**重要说明:**当我们使用筛选时,筛选的方法都是包含在[](中括号)中的。
方法集合一:属性筛选:
| 方法名\符号 | 作用 |
|---|---|
| @ | 获取属性或者筛选属性,如:@class |
| contains | 判断属性中是否含有某个值(用于多值判断),如:contains(@class,‘hello’) |
属性筛选示例:
from lxml import etreetext = '''
<div class="hello"><p>Hello,this is used to tested</p>
</div>
<div class="hello test hi"><div><div>你好,这是用于测试的html代码</div></div>
</div><div class="button"><div class="menu"><input name="btn" type="button" value="按钮" /><div>
</div>
'''#初始化
html = etree.HTML(text)
#根据单一属性筛选#筛选出class="hello"的div标签
hello_tag = html.xpath('//div[@class="hello"]') #注意筛选的方法都是在中括号里面的
print(hello_tag) #结果为: [<Element div at 0x2ba41e6d088>],即找到了一个标签,符合条件#找出具有name="btn"的input标签
input_tag = html.xpath('//input[@name="btn"]')
print(input_tag) #结果为:[<Element input at 0x1751d29df08>],找到一个input标签,符合条件#筛选出具有class="hello"的div标签
hello_tags = html.xpath('//div[contains(@class,"hello")]')
print(hello_tags) #结果为:[<Element div at 0x1348272d248>, <Element div at 0x1348272d6c8>],即找到了两个div标签,符合条件
方法集合二:按序选择:
有时候我们会有这样的需求,我们爬取的内容是一个table标签(表格标签),或者一个ul(标签),了解过html的应该都知道这样的标签,内部还有很多标签,比如table标签里就有tr、td等,ul里面就有li标签等。对于这样的标签,我们有时候需要选择第一个或者最后一个或者前几个等。这样的方式我们也可以实现。
| 方法 | 作用 |
|---|---|
| last() | 获取最后一个标签 |
| 1 | 获取第一个标签 |
| position() < = > num | 筛选多个标签(具体见实例) |
注意:这里需要注意这里的序是从1开始而不是从0开始。
from lxml import etreetext = '''
<ul><li>1</li><li>2</li><li>3</li><li>4</li><li>5</li><li>6</li><li>7</li><li>8</li>
</ul>
'''#初始化
html = etree.HTML(text)#获取第一个li标签
first_tag = html.xpath('//li[1]') #令人吃惊,lxml并没有first()方法
print(first_tag)#获取最后一个li标签
last_tag = html.xpath('//li[last()]')
print(last_tag)#获取前五个标签
li_tags = html.xpath('//li[position() < 6]')
print(li_tags)
方法集合三:逻辑和计算:
其实在写筛选时是可以加入逻辑方法的,如:and、or、>、>=等。当然也是可以写入一些计算方法的,如:+、-等。
下面给出示例:
from lxml import etreetext = '''
<ul><li>1</li><li>2</li><li>3</li><li>4</li><li>5</li><li>6</li><li>7</li><li>8</li>
</ul>
'''#初始化
html = etree.HTML(text)#获取第二个li标签,使用=判断
second_tag = html.xpath('//li[position() = 2]')
print(second_tag)#获取第一个和第二个标签,使用or
tags = html.xpath('//li[position() = 1 or position() = 2]')
print(tags)#获取前三个标签,使用<
three_tags = html.xpath('//li[position()<4]')
print(three_tags)
2.5 获取属性值或文本内容
我们寻找标签、筛选标签的最终目的就是获取它的属性或者文本内容。下面讲解获取文本和属性的方法。
| 方法 | 作用 |
|---|---|
| @ | 获取属性或者筛选属性 |
| text() | 获取文本 |
举个例子:
from lxml import etreetext = '''
<div class="hello"><p>Hello,this is used to tested</p>
</div>
<div class="hello test hi"><div><div>你好,这是用于测试的html代码</div></div>
</div><div class="button"><div class="menu"><input name="btn" type="button" value="按钮" /><div>
</div>
'''#初始化
html = etree.HTML(text)#获取第一个div中的p标签中的文本
content = html.xpath('//div/p/text()') #注意使用text()的时机和位置
print(content) #结果为:['Hello,this is used to tested'],仍然是以列表形式返回结果#获取拥有第二个div中的文本,注意观察下面的不同之处
content_two = html.xpath('//div[position() = 2]/text()')
print(content_two) #结果为: ['\n ', '\n']content_three = html.xpath('//div[position() = 2]//text()')
print(content_three) #结果为: ['\n ', '\n ', '你好,这是用于测试的html代码', '\n ', '\n']
#两者不同之处在于:一个为//,一个为/。我们知道//获取其子孙节点中的内容,而/只获取其子节点的内容。
获取属性示例:
from lxml import etreetext = '''
<div class="hello" name="test"><p>Hello,this is used to tested</p>
</div>
<div class="hello test hi"><div><div>你好,这是用于测试的html代码</div></div>
</div><div class="button"><div class="menu"><input name="btn" type="button" value="按钮" /><div>
</div>
'''#初始化
html = etree.HTML(text)#获取第一个div的name属性
first_div_class = html.xpath('//div[@class="hello"]/@name')
print(first_div_class) #结果为:['test']#获取input标签的name值
input_tag_class = html.xpath('//input/@name')
print(input_tag_class) #结果为:['btn']
3. 总结
本篇内容为大家介绍了python爬虫解析库中最为常用的lxml库,其核心的内容在于获取节点、筛选节点、获取节点文本或属性值。
下一篇会以之前讲解的requests+lxml进行一个实战。
相关文章:

python爬虫6:lxml库
python爬虫6:lxml库 前言 python实现网络爬虫非常简单,只需要掌握一定的基础知识和一定的库使用技巧即可。本系列目标旨在梳理相关知识点,方便以后复习。 申明 本系列所涉及的代码仅用于个人研究与讨论,并不会对网站产生不好…...

Linux查找命令
find find /dir -name filename 按名字查找 find . -name “*.c” 将当前目录及其子目录下所有文件后缀为 .c 的文件列出来 find . -type f 将当前目录及其子目录中的所有文件列出 find . -ctime 20 将当前目录及其子目录下所有最近 20 天内更新过的文件列出 find / -type f -…...
在 IntelliJ IDEA 中使用 Docker 开发指南
目录 一、IDEA安装Docker插件 二、IDEA连接Docker 1、Docker for Windows 连接 2、SSH 连接 3、Connection successful 连接成功 三、查看Docker面板 四、使用插件生成镜像 一、IDEA安装Docker插件 打开 IntelliJ IDEA,点击菜单栏中的 "File" -&g…...

【并发编程】自研数据同步工具的优化:创建线程池多线程异步去分页调用其他服务接口获取海量数据
文章目录 场景:解决方案 场景: 前段时间在做一个数据同步工具,其中一个服务的任务是调用A服务的接口,将数据库中指定数据请求过来,交给kafka去判断哪些数据是需要新增,哪些数据是需要修改的。 刚开始的设…...
)
python函数、运算符等简单介绍3(无顺序)
set(集合) 集合(set) -> 负责存储【不重复的数据】,并且是【无序存储】 的容器,主要用来去重和逻辑比较 set1 {1,2,3,4,58,7,4,1,2,3,5} print(set1) print(type(set1)) # 输出结果: {1, 2, 3, 4, 5, 7, 58} <…...
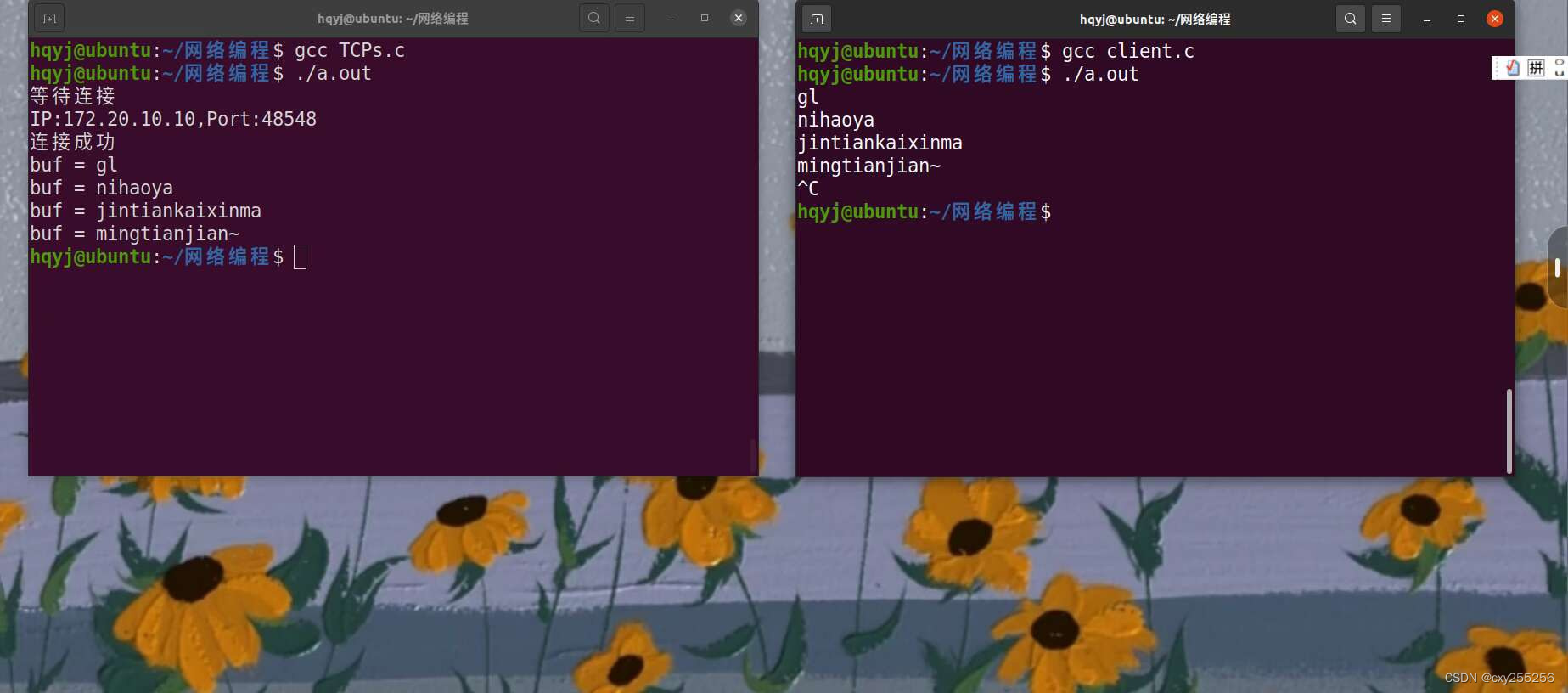
TCP服务器(套接字通信)
服务器 客户端 结果...
【智慧工地源码】:人工智能、BIM技术、机器学习在智慧工地的应用
智慧工地云平台是专为建筑施工领域所打造的一体化信息管理平台。通过大数据、云计算、人工智能、BIM、物联网和移动互联网等高科技技术手段,将施工区域各系统数据汇总,建立可视化数字工地。同时,围绕人、机、料、法、环等各方面关键因素&…...
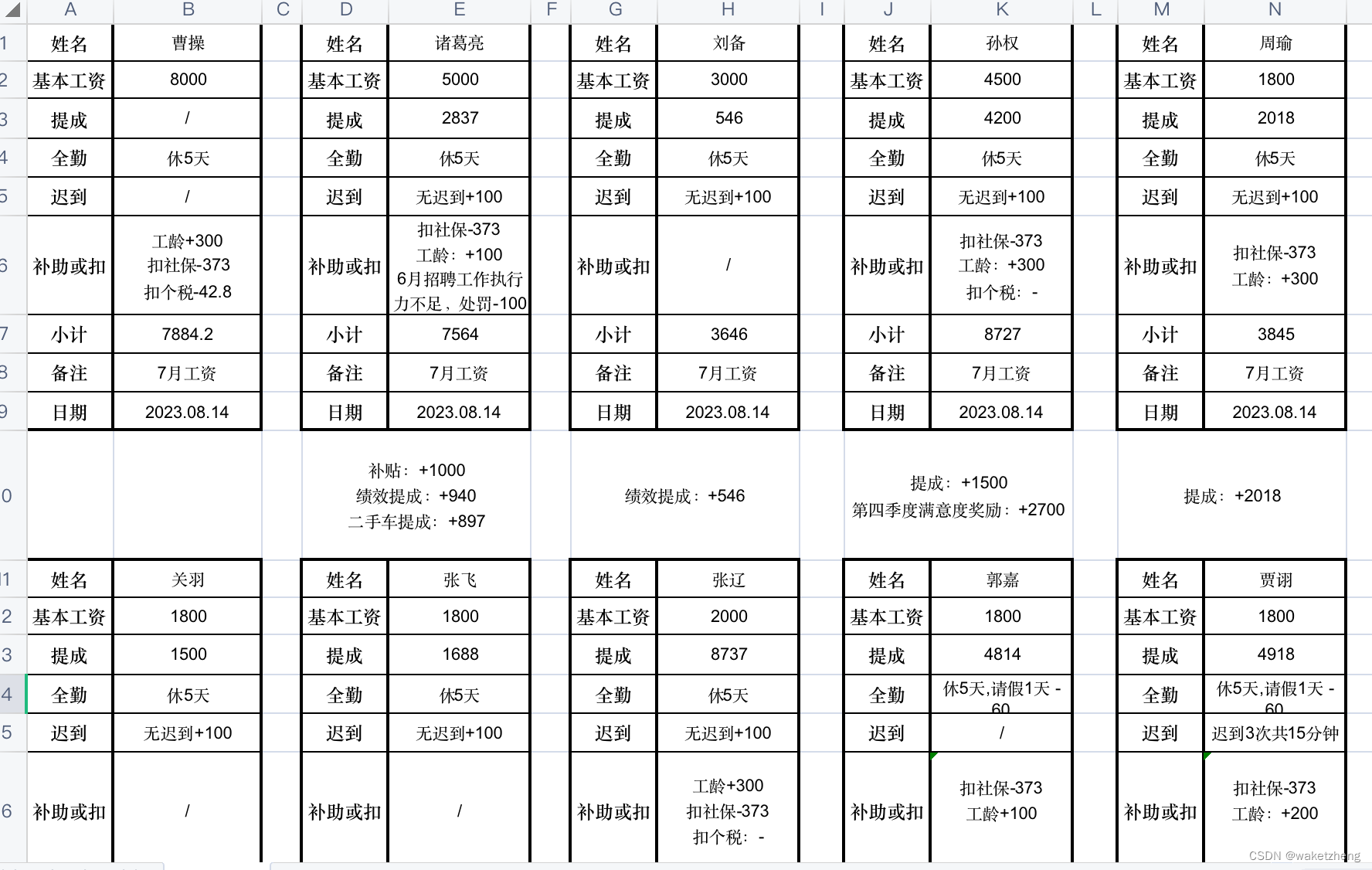
使用python读Excel文件并写入另一个xls模版
效果如下: 原文件内容 转化后的内容 大致代码如下: 1. load_it.py #!/usr/bin/env python import re from datetime import datetime from io import BytesIO from pathlib import Path from typing import List, Unionfrom fastapi import HTTPExcep…...

债务人去世,债权人要求其妻女承担还款责任,法院支持吗
债务人去世,债权人要求其妻女承担还款责任,法院支持吗 2019年9月20日,老张以公司资金周转为由向好友任某先后借款合计40万。2022年8月27日老张出具还款承诺书,承诺2022年11月30日前归还本息(本息90万元)到…...
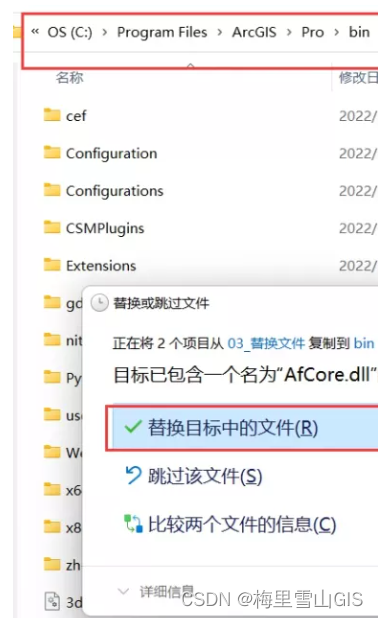
arcgis pro3.0-3.0.1-3.0.2安装教程大全及安装包下载
一. 产品介绍: ArcGIS Pro 这一功能强大的单桌面 GIS 应用程序是一款功能丰富的软件,采用 ArcGIS Pro 用户社区提供的增强功能和创意进行开发。 ArcGIS Pro 支持 2D、3D 和 4D 模式下的数据可视化、高级分析和权威数据维护。 支持通过 Web GIS 在一系列 …...
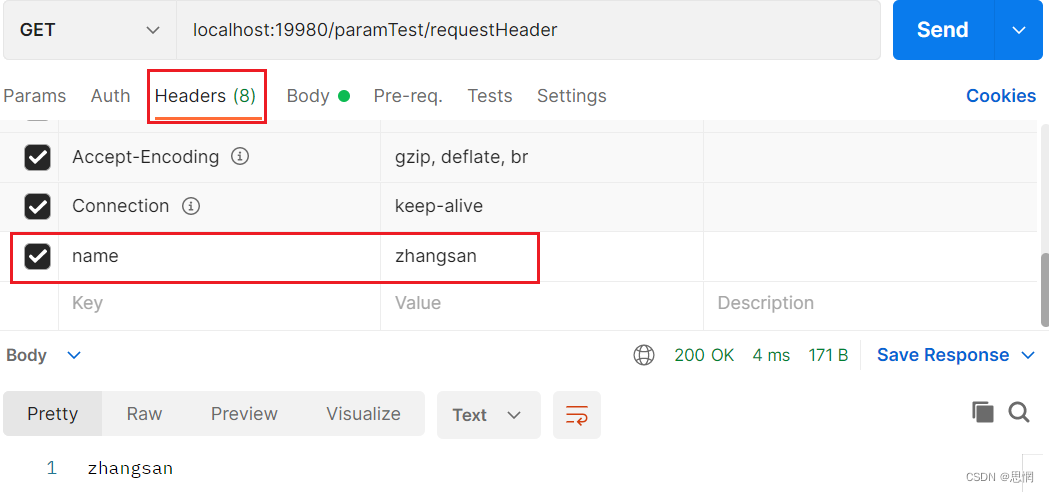
@RequestHeader使用
RequestHeader 请求头参数的设置 GetMapping("paramTest/requestHeader")public String requestHeaderTest(RequestHeader("name") String name){return name;} 在Postman的Headers中添加请求头参数,不过貌似不能加中文...
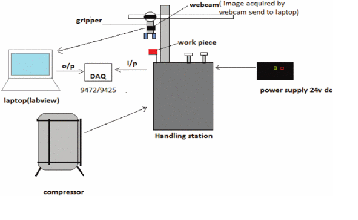
LabVIEW开发图像采集和基于颜色的隔离
LabVIEW开发图像采集和基于颜色的隔离 在当今的工业和工厂中,准确性和精度是决定特定行业生产力的两个重要关键点。为了优化生产力,各行各业正在从手动操作转向自动操作和控制。机器人技术在工业过程中的出现为人类提供了机械辅助。机器视觉在工业机器人…...

站长公益主机,免费主机➕免费域名➕博客申请➕论坛申请
站长公益主机,免费主机➕免费域名➕博客申请➕论坛申请 在出教程之前准备好久,测试搭建轻量论坛无压力 选用稳定免费域名➕免费主机分销给,可以套CDN使用 坚持免费时间是大厂不能媲美,刚开始做网站时用的是这个分销,独…...
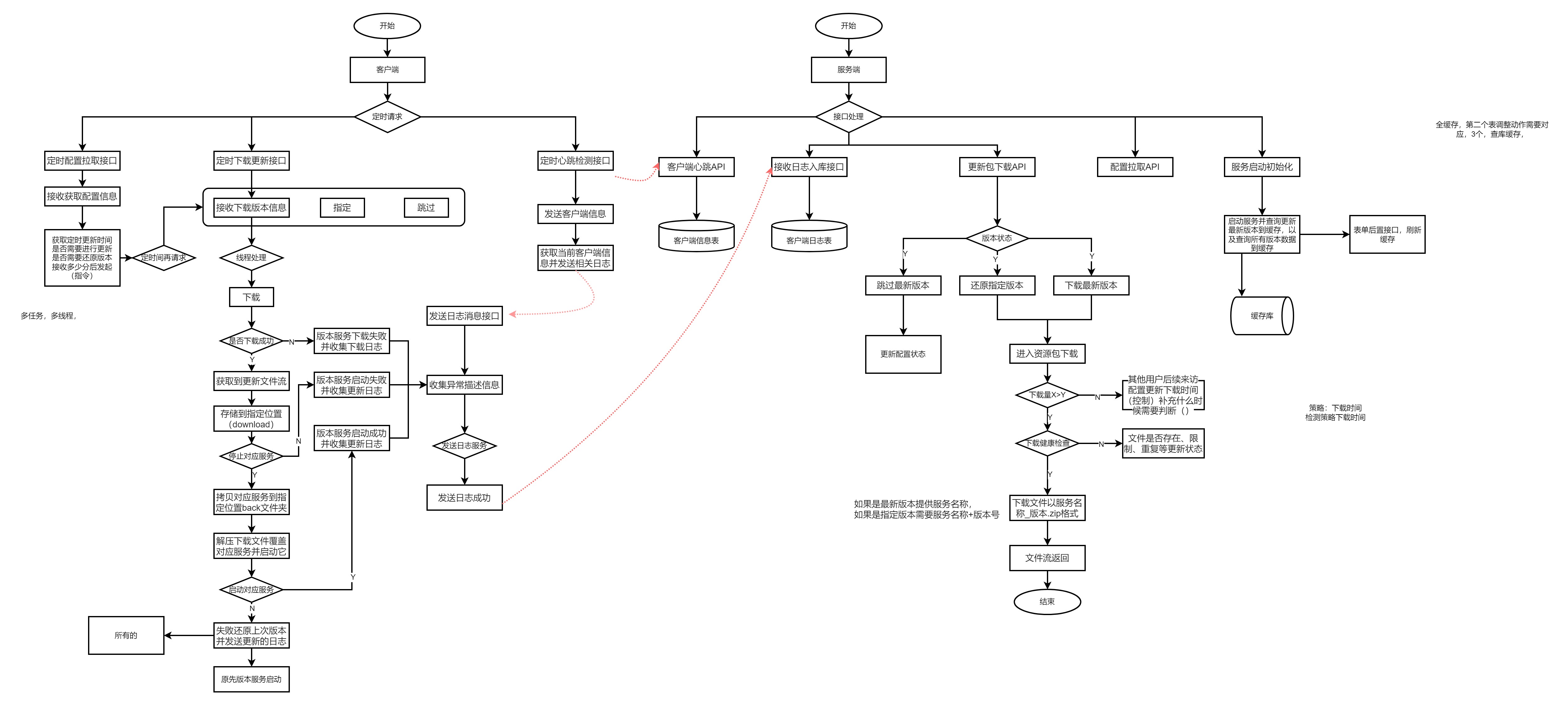
【PRO-UPDATE】自动更新程序图形小记
大纲流程 设计流程 v0.1 v1.0...

flume系列之:监控Systemctl托管的flume agent组
flume系列之:监控Systemctl托管的flume agent组 一、需求背景二、相关技术博客三、远程登陆flume机器四、发送飞书告警五、监控flume agent组状态一、需求背景 flume接kafka集群,一个kafka集群对应一个flume agent组,会把一组flume agent用systemctl托管每接一个kafka集群会…...

16.3.1 【Linux】程序的观察
既然程序这么重要,那么我们如何查阅系统上面正在运行当中的程序呢?利用静态的 ps 或者是动态的 top,还能以 pstree 来查阅程序树之间的关系。 ps :将某个时间点的程序运行情况撷取下来 仅观察自己的 bash 相关程序: p…...

HarmonyOS 设置全屏NoTitleBar
这篇很有用:玩转HarmonyOS 状态栏&标题栏&导航栏相关操作方法整理 配置页面全屏显示(在config.json中配置): "metaData": {"customizeData": [{"name": "hwc-theme","value": "androi…...

Java 模块解耦的设计策略
Java 平台模块系统 (JPMS) 提供了更强的封装、更高的可靠性和更好的关注点分离,有些同学可能没注意到。 不过呢,也是有利有弊。由于模块化应用程序构建在依赖其他模块才能正常工作的模块网络上,因此在许多情况下,模块彼此紧密耦合…...
支持https访问
文章目录 1. 打开自己的云服务器的 80 和 443 端口2. 安装 nginx3. 安装 snapd4. 安装 certbot5. 生成证书6. 拷贝生成的证书到项目工作目录7. 修改 main.go 程序如下8. 编译程序9. 启动程序10. 使用 https 和端口 8081 访问页面成功11. 下面修改程序,支持 https 和…...

JavaScript 中常用简写技巧总结
平时我们写代码时最高级的境界是自己写的东西别人看不懂!哈哈哈!分享一些自己常用的js简写技巧,长期更新,会着重挑选一些实用的简写技巧,使自己的代码更简洁优雅~ 这里只会收集一些大多数人不知道的用法,但…...

FanControl:Windows平台终极风扇控制解决方案
FanControl:Windows平台终极风扇控制解决方案 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/FanCont…...

BIN文件操作指南:从字节视角到实战应用
1. 项目概述:为什么我们需要系统性地掌握BIN文件操作?在嵌入式开发、固件逆向、游戏修改乃至数据恢复这些领域里,我们经常会遇到一个后缀名为.bin的文件。很多新手朋友第一次接触时可能会有点懵,这既不是文本文件可以直接打开看&a…...

开发AI应用时如何利用Taotoken实现模型的快速选型与A/B测试
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发AI应用时如何利用Taotoken实现模型的快速选型与A/B测试 在开发AI应用的过程中,选择合适的模型是影响最终效果与成本…...

暗黑破坏神2存档修改器:释放你的游戏创造力
暗黑破坏神2存档修改器:释放你的游戏创造力 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否曾想过,如果能让暗黑破坏神2中的角色拥有完美的装备组合?如果…...

智能汽车人机交互与ADAS系统融合:架构、场景与工程实践
1. 项目概述:当驾驶舱的“大脑”与“眼睛”开始对话“集成人机交互和ADAS系统”——这个标题听起来像是一个纯粹的工程命题,但在我过去十多年的汽车电子开发经历中,我越来越深刻地体会到,这其实是一个关于“人、车、路”三者关系如…...

Desktop Postflop:免费开源的德州扑克GTO求解器完整指南
Desktop Postflop:免费开源的德州扑克GTO求解器完整指南 【免费下载链接】desktop-postflop [Development suspended] Advanced open-source Texas Holdem GTO solver with optimized performance 项目地址: https://gitcode.com/gh_mirrors/de/desktop-postflop …...
)
不是模型不行,是你没做好特征工程(附完整步骤)
来源:DeepHub IMBA 本文约1800字,建议阅读5分钟本文介绍了特征工程全流程,含数据处理、特征构造与选择。Feature engineering 是机器学习 pipeline 里最关键的一环。算法再好,如果输入数据噪声大、不一致或者缺乏有意义的特征&…...

力扣算法面试150题——个人笔记——复习用
双指针 第一题: 125. 验证回文串https://leetcode.cn/problems/valid-palindrome/ 题目内容 如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个 回文串 。 字母和数字都属于字母…...

为什么我劝你放弃FLANN 1.9.2?聊聊源码编译那些坑与1.9.1版的真香选择
为什么FLANN 1.9.1才是开发者更明智的选择:深度解析编译陷阱与版本决策 在开源库的世界里,"最新版本"往往被默认为"最佳选择",但FLANN 1.9.2却打破了这个常规认知。作为一名经历过无数次深夜调试的开发者,我必…...

量子计算中数据驱动的哈密顿修正方法研究
1. 量子门控中的哈密顿修正挑战在量子计算领域,超导transmon比特因其相对较长的相干时间和可扩展性,成为当前最有前景的量子处理器实现方案之一。然而,实际硬件中存在的器件间差异和串扰效应,使得基于理论模型的脉冲设计与真实硬件…...