根据一棵树的两种遍历构造二叉树

题目
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
示例 1:
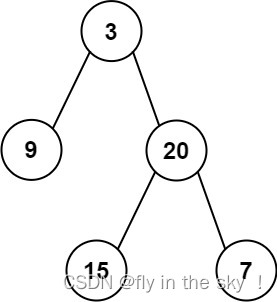
输入: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
输出: [3,9,20,null,null,15,7]
示例 2:
输入: preorder = [-1], inorder = [-1]
输出: [-1]
提示:
1 <= preorder.length <= 3000inorder.length == preorder.length-3000 <= preorder[i], inorder[i] <= 3000preorder和inorder均 无重复 元素inorder均出现在preorderpreorder保证 为二叉树的前序遍历序列inorder保证 为二叉树的中序遍历序列
前置知识:
preorder:前序遍历(Preorder Traversal 亦称先序遍历)——访问根结点--->根的左子树--->根的右子树。
inorder:中序遍历(Inorder Traversal)——根的左子树--->根节点--->根的右子树
前序遍历所得的第一个节点就是根节点,所以可以用来确定的是root根节点在中序遍历的位置,
再根据中序遍历,root根节点的左边是这棵二叉树的左树,root根节点的右边是这课二叉树的右树来构建这课二叉树
以示例1为例谈谈对题目的理解
示例1输入: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
preorder = [ 3, 9, 20, 15, 7 ] 3就为这棵二叉树的root根节点
inorder = [ 9, 3, 15, 20, 7 ] 9为root的左树,并且只有一个节点,所以9为root的左节点
15,20,7这三个节点为root的右树,再根据中序遍历根的左子树--->根节点--->根的右子树可得
root的右节点为20这个节点,20节点的左节点为15这个节点,右节点为7这个节点
画图演示上述文字说明

解题思路:
根据题目所给的前序遍历的节点顺序在中序遍历中进行递归来构建二叉树
1.根据前序遍历找到中序遍历根节点iRoot的位置,创建根节点,再确定iBegin,iEnd的位置,i++;
2.对iBegin和iEnd的位置进行判断,当iBegin>iEnd时,返回null,递归开始回退;
2.在中序遍历当中,根据iRoot ,iBegin,iEnd的位置,并进行左树和右树的构建;
对上述三步进行递归,递归完了之后,二叉树构建完成,返回根节点root
注:对前序遍历所得节点的利用才是本题代码的灵魂所在
图示:

解题代码
class Solution {public int i = 0;public TreeNode buildTree(int[] preorder, int[] inorder) {return create_a_binary_tree(preorder, inorder, 0, inorder.length - 1);}public TreeNode create_a_binary_tree(int[] preorder, int[] inorder, int inBegin, int inEnd) {if (inBegin > inEnd) {return null;//给定的数组int[] preorder, int[] inorder,遍历完了,没有子树了,该节点为空节点,返回null,递归开始回退}//先根据先序遍历创建根节点TreeNode root = new TreeNode(preorder[i]);//找到当前根节点,在中序遍历的位置int rootIndex = findIndex(inorder, inBegin, inEnd, preorder[i]);i++;//递归构建左树root.left = create_a_binary_tree(preorder, inorder, inBegin, rootIndex - 1);//递归构建右树root.right = create_a_binary_tree(preorder, inorder, rootIndex + 1, inEnd);//前序遍历完成,返回根节点return root;}private int findIndex(int[] inorder, int inBegin, int inEnd, int key) {for (int j = inBegin; j <= inEnd; j++) {if (inorder[j] == key) {return j;}}return -1;}
}运行结果

题目链接
https://leetcode.cn/problems/construct-binary-tree-from-preorder-and-inorder-traversal/submissions/
举一翻三,再来一道
根据一棵树的中序遍历与后序遍历构造二叉树
给定两个整数数组
inorder和postorder,其中inorder是二叉树的中序历,postorder是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
示例 1:

输入:inorder = [9,3,15,20,7], postorder = [9,15,7,20,3]
输出:[3,9,20,null,null,15,7]
示例 2:
输入:inorder = [-1], postorder = [-1]
输出:[-1]
后序遍历(Postorder Traversal)——根的左子树--->根的右子树--->根节点。
创建根节点后,先创建右数,再创建左树
根据示例1进行讲解,下图是代码递归过程

随着代码的递归,二叉树随之构建的过程

解题代码
public class Solution {public int i = 0;public TreeNode buildTree(int[] inorder, int[] postorder) {i = postorder.length - 1;return create_a_binary_tree(postorder, inorder, 0, inorder.length - 1);}public TreeNode create_a_binary_tree(int[] postorder, int[] inorder, int inBegin, int inEnd) {if (inBegin > inEnd) {return null;//给定的数组int[] postorder, int[] inorder,遍历完了,没有子树了,该节点为空节点,返回null,递归开始回退}//先根据先序遍历创建根节点TreeNode root = new TreeNode(postorder[i]);//找到当前根节点,在中序遍历的位置int rootIndex = findIndex(inorder, inBegin, inEnd, postorder[i]);i--;//递归先构建右树root.right = create_a_binary_tree(postorder, inorder, rootIndex + 1, inEnd);//递归后构建左树root.left = create_a_binary_tree(postorder, inorder, inBegin, rootIndex - 1);//前序遍历完成,返回根节点return root;}private int findIndex(int[] inorder, int inBegin, int inEnd, int key) {for (int j = inBegin; j <= inEnd; j++) {if (inorder[j] == key) {return j;}}return -1;}
}运行结果

题目链接:
https://leetcode.cn/problems/construct-binary-tree-from-inorder-and-postorder-traversal/submissions/
完结撒花✿✿ヽ(°▽°)ノ✿✿

相关文章:
根据一棵树的两种遍历构造二叉树
题目 给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。 示例 1: 输入: preorder [3,9,20,15,7], inorder [9,3,15,20,7] 输出: [3,9,20,null,null,…...
stack 、 queue的语法使用及底层实现以及deque的介绍【C++】
文章目录 stack的使用queue的使用适配器queue的模拟实现stack的模拟实现deque stack的使用 stack是一种容器适配器,具有后进先出,只能从容器的一端进行元素的插入与提取操作 #include <iostream> #include <vector> #include <stack&g…...

没学C++,如何从C语言丝滑过度到python【python基础万字详解】
大家好,我是纪宁。 文章将从C语言出发,深入介绍python的基础知识,也包括很多python的新增知识点详解。 文章目录 1.python的输入输出,重新认识 hello world,重回那个激情燃烧的岁月1.1 输出函数print的规则1.2 输入函…...

haproxy负载均衡
1、配置环境 作用环境windows测试 192.168.33.158 172.25.0.11 haproxy负载均衡haproxy:2.8.1,centos7172.25.0.31web服务器1--rs1Apache:2.4,redhat9172.25.0.32web服务器2--rs2Apache:2.4 , redhat9 2、…...
【数据结构】顺序队列模拟实现
💐 🌸 🌷 🍀 🌹 🌻 🌺 🍁 🍃 🍂 🌿 🍄🍝 🍛 🍤 📃个人主页 :阿然成长日记 …...
TiDB数据库从入门到精通系列之六:使用 TiCDC 将 TiDB 的数据同步到 Apache Kafka
TiDB数据库从入门到精通系列之六:使用 TiCDC 将 TiDB 的数据同步到 Apache Kafka 一、技术流程二、搭建环境三、创建Kafka changefeed四、写入数据以产生变更日志五、配置 Flink 消费 Kafka 数据 一、技术流程 快速搭建 TiCDC 集群、Kafka 集群和 Flink 集群创建 c…...
Spring对象装配
在spring中,Bean的执行流程为启动spring容器,实例化bean,将bean注册到spring容器中,将bean装配到需要的类中。 既然我们需要将bea装配到需要的类中,那么如何实现呢?这篇文章,将来阐述一下如何实…...
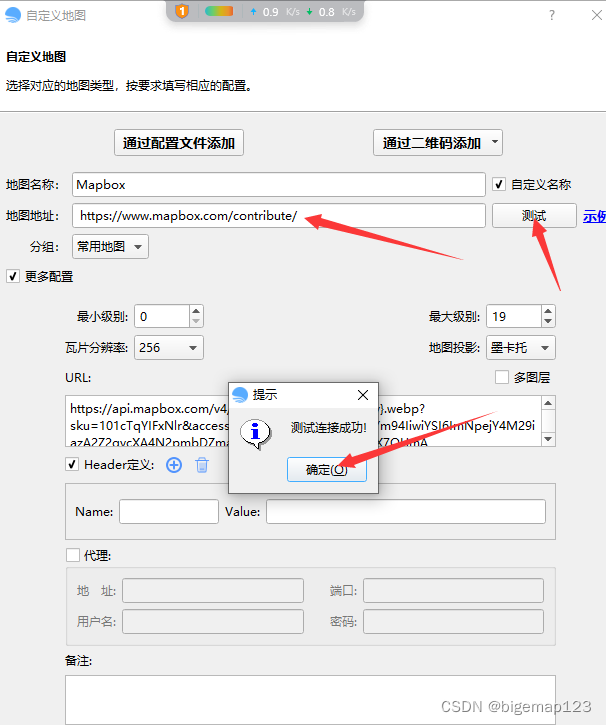
bigemap如何添加mapbox地图?
第一步 打开浏览器,找到你要访问的地图的URL地址,并且确认可以正常在浏览器中访问;浏览器中不能访问,同样也不能在软件中访问。 以下为常用地图源地址: 天地图: http://map.tianditu.gov.cn 包含&…...

python爬虫6:lxml库
python爬虫6:lxml库 前言 python实现网络爬虫非常简单,只需要掌握一定的基础知识和一定的库使用技巧即可。本系列目标旨在梳理相关知识点,方便以后复习。 申明 本系列所涉及的代码仅用于个人研究与讨论,并不会对网站产生不好…...

Linux查找命令
find find /dir -name filename 按名字查找 find . -name “*.c” 将当前目录及其子目录下所有文件后缀为 .c 的文件列出来 find . -type f 将当前目录及其子目录中的所有文件列出 find . -ctime 20 将当前目录及其子目录下所有最近 20 天内更新过的文件列出 find / -type f -…...
在 IntelliJ IDEA 中使用 Docker 开发指南
目录 一、IDEA安装Docker插件 二、IDEA连接Docker 1、Docker for Windows 连接 2、SSH 连接 3、Connection successful 连接成功 三、查看Docker面板 四、使用插件生成镜像 一、IDEA安装Docker插件 打开 IntelliJ IDEA,点击菜单栏中的 "File" -&g…...

【并发编程】自研数据同步工具的优化:创建线程池多线程异步去分页调用其他服务接口获取海量数据
文章目录 场景:解决方案 场景: 前段时间在做一个数据同步工具,其中一个服务的任务是调用A服务的接口,将数据库中指定数据请求过来,交给kafka去判断哪些数据是需要新增,哪些数据是需要修改的。 刚开始的设…...
)
python函数、运算符等简单介绍3(无顺序)
set(集合) 集合(set) -> 负责存储【不重复的数据】,并且是【无序存储】 的容器,主要用来去重和逻辑比较 set1 {1,2,3,4,58,7,4,1,2,3,5} print(set1) print(type(set1)) # 输出结果: {1, 2, 3, 4, 5, 7, 58} <…...
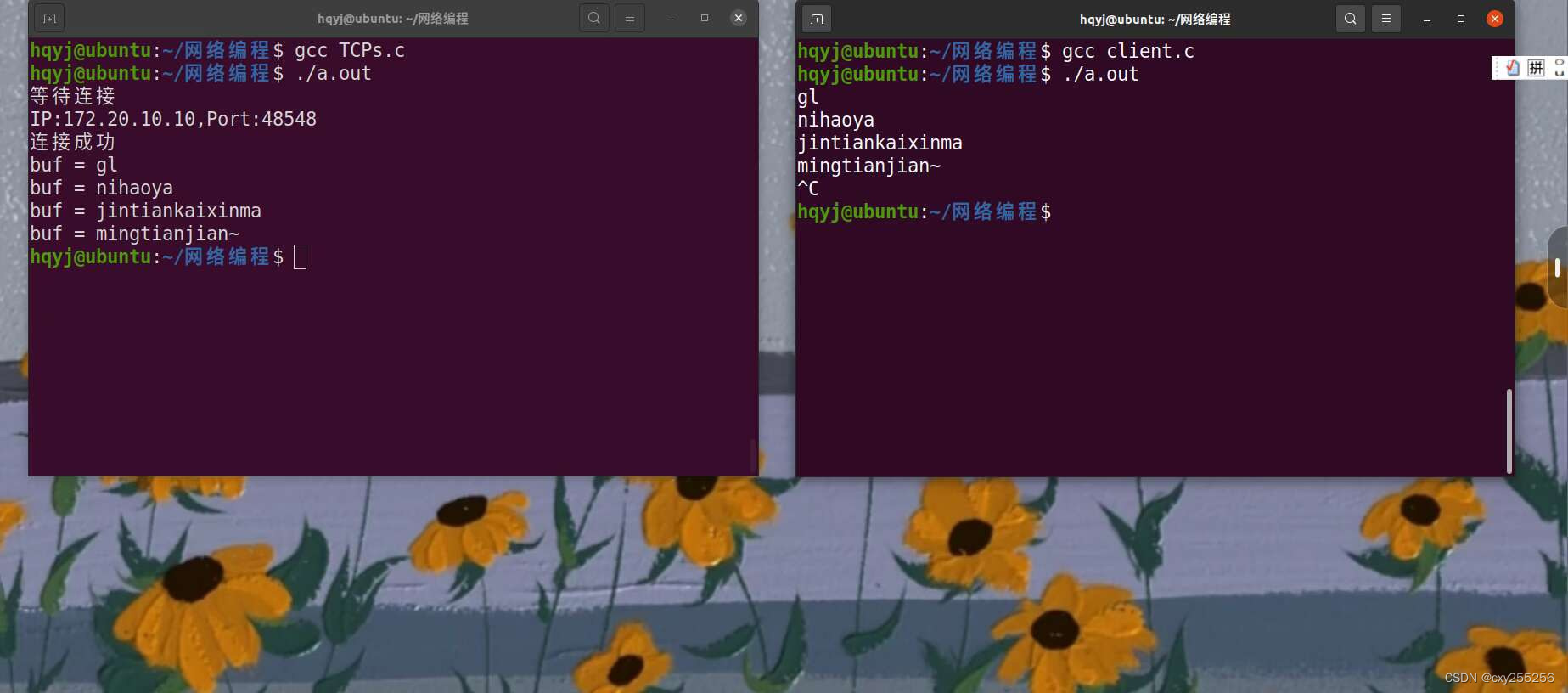
TCP服务器(套接字通信)
服务器 客户端 结果...
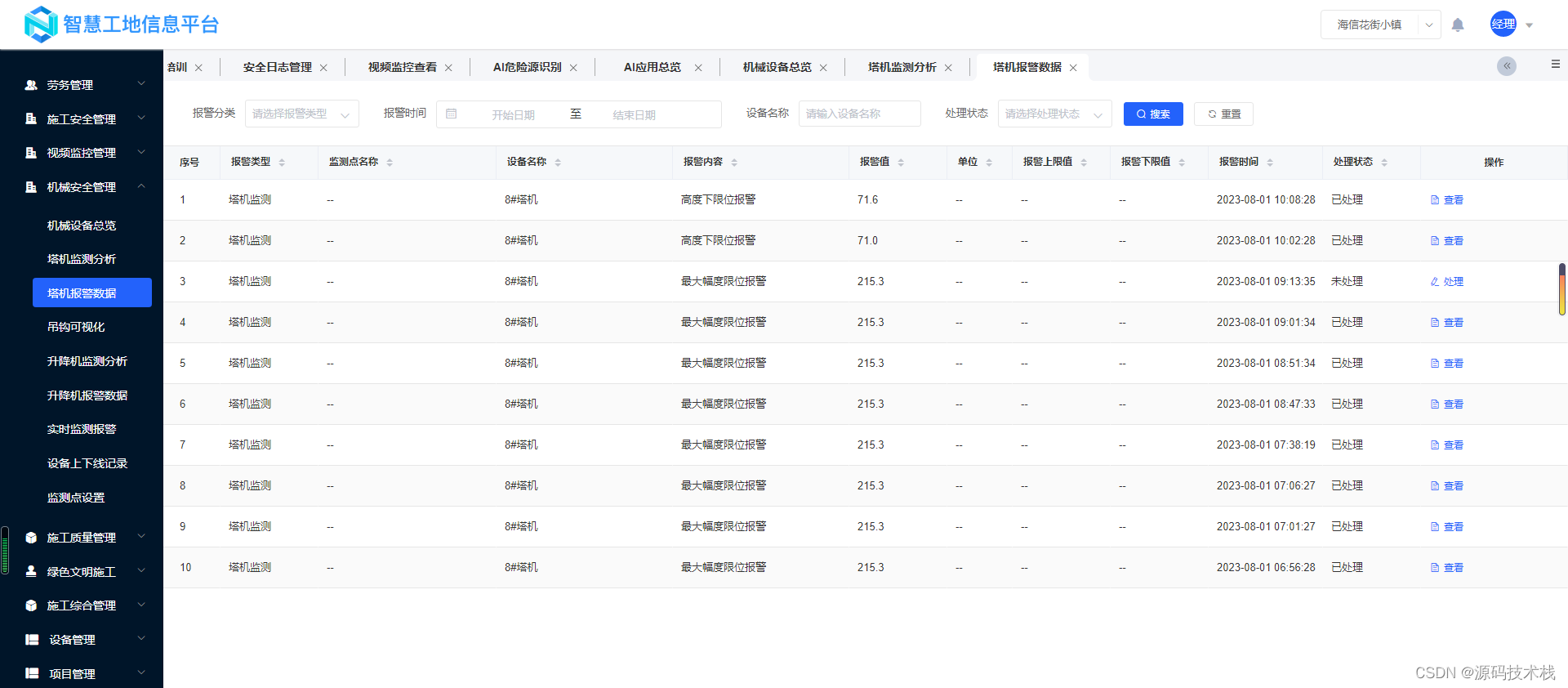
【智慧工地源码】:人工智能、BIM技术、机器学习在智慧工地的应用
智慧工地云平台是专为建筑施工领域所打造的一体化信息管理平台。通过大数据、云计算、人工智能、BIM、物联网和移动互联网等高科技技术手段,将施工区域各系统数据汇总,建立可视化数字工地。同时,围绕人、机、料、法、环等各方面关键因素&…...
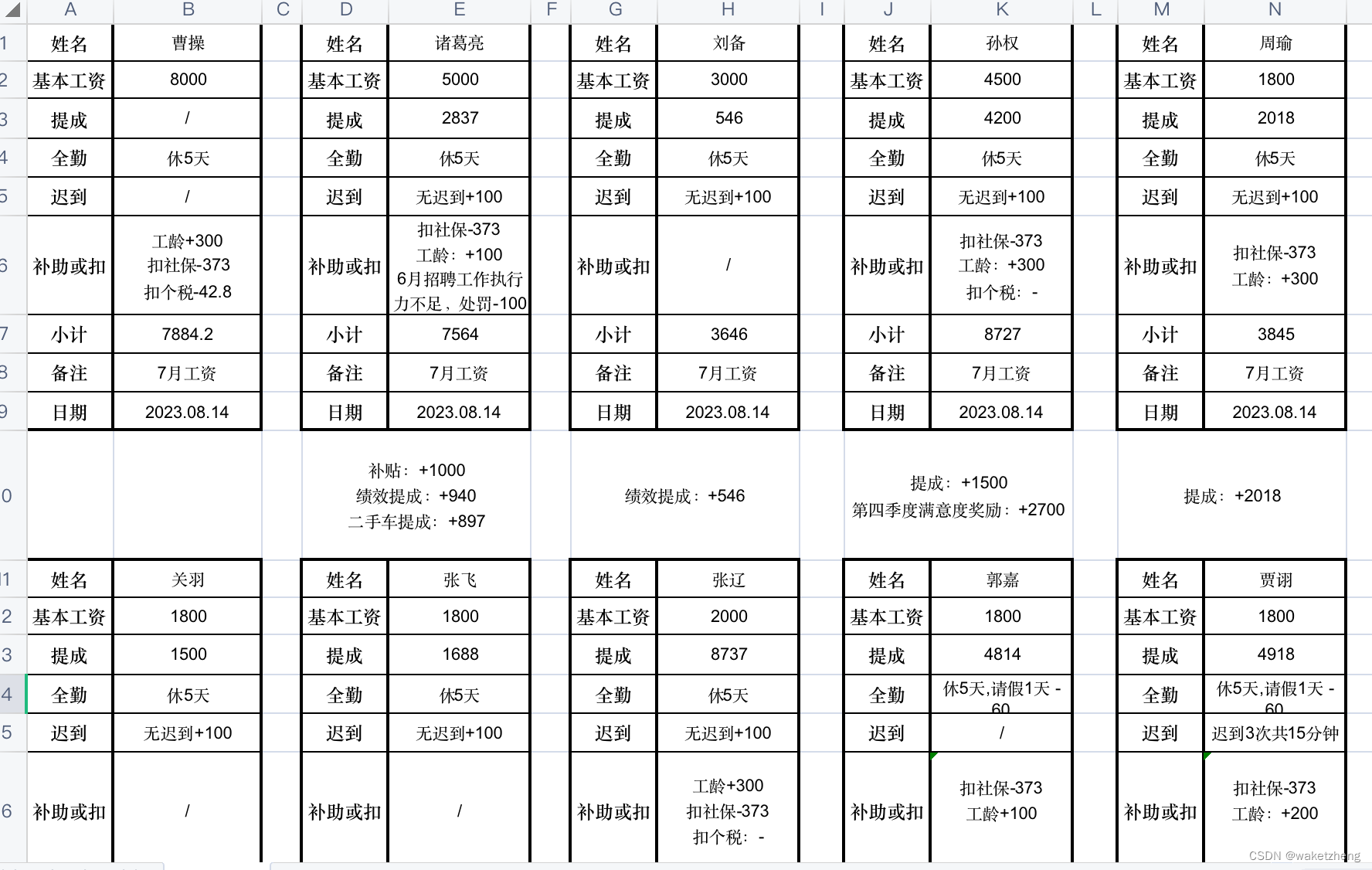
使用python读Excel文件并写入另一个xls模版
效果如下: 原文件内容 转化后的内容 大致代码如下: 1. load_it.py #!/usr/bin/env python import re from datetime import datetime from io import BytesIO from pathlib import Path from typing import List, Unionfrom fastapi import HTTPExcep…...

债务人去世,债权人要求其妻女承担还款责任,法院支持吗
债务人去世,债权人要求其妻女承担还款责任,法院支持吗 2019年9月20日,老张以公司资金周转为由向好友任某先后借款合计40万。2022年8月27日老张出具还款承诺书,承诺2022年11月30日前归还本息(本息90万元)到…...
arcgis pro3.0-3.0.1-3.0.2安装教程大全及安装包下载
一. 产品介绍: ArcGIS Pro 这一功能强大的单桌面 GIS 应用程序是一款功能丰富的软件,采用 ArcGIS Pro 用户社区提供的增强功能和创意进行开发。 ArcGIS Pro 支持 2D、3D 和 4D 模式下的数据可视化、高级分析和权威数据维护。 支持通过 Web GIS 在一系列 …...
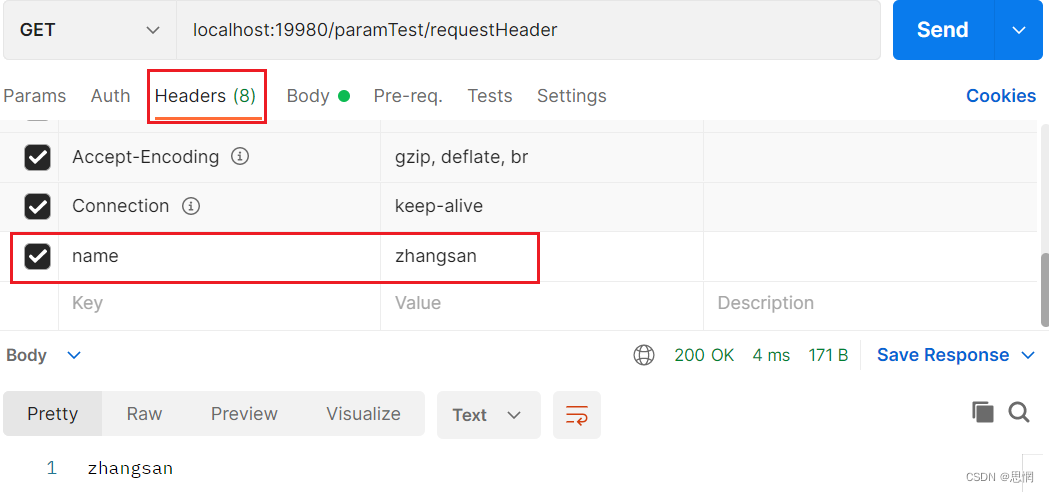
@RequestHeader使用
RequestHeader 请求头参数的设置 GetMapping("paramTest/requestHeader")public String requestHeaderTest(RequestHeader("name") String name){return name;} 在Postman的Headers中添加请求头参数,不过貌似不能加中文...
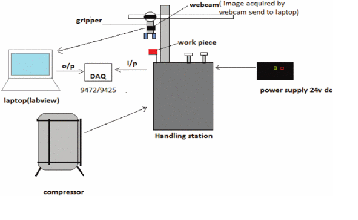
LabVIEW开发图像采集和基于颜色的隔离
LabVIEW开发图像采集和基于颜色的隔离 在当今的工业和工厂中,准确性和精度是决定特定行业生产力的两个重要关键点。为了优化生产力,各行各业正在从手动操作转向自动操作和控制。机器人技术在工业过程中的出现为人类提供了机械辅助。机器视觉在工业机器人…...
)
为什么你的/fast命令总被降级?Midjourney内部队列优先级算法首度曝光(含3个即时生效的Prompt签名技巧)
更多请点击: https://kaifayun.com 第一章:快速模式降级现象的本质解构 快速模式降级(Fast Mode Degradation)并非简单的性能衰减,而是现代异步I/O栈中多层协同机制在资源约束下触发的确定性状态迁移过程。其本质是内…...

【AI概念设计黄金标准】:NASA前可视化总监揭秘——如何用Midjourney输出符合影视工业管线的分镜资产
更多请点击: https://intelliparadigm.com 第一章:AI概念设计黄金标准的工业级定义 在高可靠性AI系统开发中,“概念设计”并非抽象构思阶段,而是承载可验证性、可追溯性与可部署性的工程锚点。工业级定义要求该阶段输出必须满足…...

BepInEx框架指南:从游戏玩家到模组开发者的完整升级路径
BepInEx框架指南:从游戏玩家到模组开发者的完整升级路径 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx 你是否曾经羡慕过那些能够为游戏添加新内容、修改界面、甚至创…...

避坑指南:PnetLab导入锐捷镜像时,关于qemu_options和权限的那些‘坑’
PnetLab锐捷镜像部署深度排障手册:从参数解析到权限修复实战 当你在深夜的机房里盯着屏幕上闪烁的命令行,第十次尝试启动PnetLab中的锐捷镜像却依然遭遇连接失败时,那种挫败感我深有体会。这不是又一篇按部就班的安装教程,而是一…...

深入Delphi二进制世界:用IDR揭开编译代码的神秘面纱
深入Delphi二进制世界:用IDR揭开编译代码的神秘面纱 【免费下载链接】IDR Interactive Delphi Reconstructor 项目地址: https://gitcode.com/gh_mirrors/id/IDR 你是否曾经面对一个Delphi编译的程序,却无法理解它的内部逻辑?或者需要…...

用Wave2Lip和GFP-GAN给老电影片段配音:从《秋天不回来》到自定义音频的完整实践
用Wave2Lip和GFP-GAN重塑经典影像:从技术原理到影视级修复实战 当黑白胶片中的玛丽莲梦露突然用AI生成的嘴唇同步唱起Billie Eilish的《Bad Guy》,或是《罗马假日》里的奥黛丽赫本开始用你录制的生日祝福开口说话——这种跨越时空的"数字口技"…...
)
Allegro PCB设计自查清单:用Quick Reports快速搞定投板前的关键检查(附Dangling Line定位技巧)
Allegro PCB设计投板前终极自查指南:用Quick Reports构建高效质检流水线 在PCB设计领域,最后的5%往往消耗50%的精力。当设计进入投板前的关键阶段,工程师们常陷入两难:要么因过度谨慎反复全盘检查导致项目延期,要么因遗…...

MIT Cheetah-Software编译手记:搞定Qt5.10.0路径、LCM依赖与那些诡异的C++报错
MIT Cheetah-Software编译实战:Qt路径配置、LCM依赖与C报错深度解析 1. 环境准备与依赖管理 在Ubuntu 20.04环境下编译MIT Cheetah-Software,首先需要确保系统基础环境配置正确。不同于普通开源项目,这个四足机器狗的控制系统对Qt版本、LCM消…...

OpCore Simplify:告别繁琐配置,轻松构建黑苹果OpenCore EFI的智能工具
OpCore Simplify:告别繁琐配置,轻松构建黑苹果OpenCore EFI的智能工具 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为黑…...

CANN/asc-devkit Div除法函数文档
Div 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/cann/a…...