TiDB数据库从入门到精通系列之六:使用 TiCDC 将 TiDB 的数据同步到 Apache Kafka
TiDB数据库从入门到精通系列之六:使用 TiCDC 将 TiDB 的数据同步到 Apache Kafka
- 一、技术流程
- 二、搭建环境
- 三、创建Kafka changefeed
- 四、写入数据以产生变更日志
- 五、配置 Flink 消费 Kafka 数据
一、技术流程
- 快速搭建 TiCDC 集群、Kafka 集群和 Flink 集群
- 创建 changefeed,将 TiDB 增量数据输出至 Kafka
- 使用 go-tpc 写入数据到上游 TiDB
- 使用 Kafka console consumer 观察数据被写入到指定的 Topic
- (可选)配置 Flink 集群消费 Kafka 内数据
二、搭建环境
部署包含 TiCDC 的 TiDB 集群
在实验或测试环境中,可以使用 TiUP Playground 功能,快速部署 TiCDC,命令如下:
tiup playground --host 0.0.0.0 --db 1 --pd 1 --kv 1 --tiflash 0 --ticdc 1
# 查看集群状态
tiup status
三、创建Kafka changefeed
1.创建 changefeed 配置文件
根据 Flink 的要求和规范,每张表的增量数据需要发送到独立的 Topic 中,并且每个事件需要按照主键值分发 Partition。因此,需要创建一个名为 changefeed.conf 的配置文件,填写如下内容:
[sink]
dispatchers = [
{matcher = ['*.*'], topic = "tidb_{schema}_{table}", partition="index-value"},
]
2.创建一个 changefeed,将增量数据输出到 Kafka
tiup ctl:v<CLUSTER_VERSION> cdc changefeed
create --server="http://127.0.0.1:8300"
--sink-uri="kafka://127.0.0.1:9092/kafka-topic-name?protocol=canal-json"
--changefeed-id="kafka-changefeed"
--config="changefeed.conf"
如果命令执行成功,将会返回被创建的 changefeed 的相关信息,包含被创建的 changefeed 的 ID 以及相关信息,内容如下:
Create changefeed successfully!
ID: kafka-changefeed
Info: {... changfeed info json struct ...}
如果命令长时间没有返回,你需要检查当前执行命令所在服务器到 sink-uri 中指定的 Kafka 机器的网络可达性,保证二者之间的网络连接正常。
生产环境下 Kafka 集群通常有多个 broker 节点,你可以在 sink-uri 中配置多个 broker 的访问地址,这有助于提升 changefeed 到 Kafka 集群访问的稳定性,当部分被配置的 Kafka 节点故障的时候,changefeed 依旧可以正常工作。假设 Kafka 集群中有 3 个 broker 节点,地址分别为 127.0.0.1:9092 / 127.0.0.2:9092 / 127.0.0.3:9092,可以参考如下 sink-uri 创建 changefeed:
tiup ctl:v<CLUSTER_VERSION> cdc changefeed create
--server="http://127.0.0.1:8300"
--sink-uri="kafka://127.0.0.1:9092,127.0.0.2:9092,127.0.0.3:9092/kafka-topic-name?protocol=canal-json&partition-num=3&replication-factor=1&max-message-bytes=1048576"
--config="changefeed.conf"
3.Changefeed 创建成功后,执行如下命令,查看 changefeed 的状态
tiup ctl:v<CLUSTER_VERSION> cdc changefeed list --server="http://127.0.0.1:8300"
四、写入数据以产生变更日志
完成以上步骤后,TiCDC 会将上游 TiDB 的增量数据变更日志发送到 Kafka,下面对 TiDB 写入数据,以产生增量数据变更日志。
1.模拟业务负载
在测试实验环境下,可以使用 go-tpc 向上游 TiDB 集群写入数据,以让 TiDB 产生事件变更数据。如下命令,首先在上游 TiDB 创建名为 tpcc 的数据库,然后使用 TiUP bench 写入数据到这个数据库中。
tiup bench tpcc -H 127.0.0.1 -P 4000 -D tpcc --warehouses 4 prepare
tiup bench tpcc -H 127.0.0.1 -P 4000 -D tpcc --warehouses 4 run --time 300s
2.消费 Kafka Topic 中的数据
changefeed 正常运行时,会向 Kafka Topic 写入数据,你可以通过由 Kafka 提供的 kafka-console-consumer.sh,观测到数据成功被写入到 Kafka Topic 中:
./bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --from-beginning --topic `${topic-name}`
至此,TiDB 的增量数据变更日志就实时地复制到了 Kafka。下一步,你可以使用 Flink 消费 Kafka 数据。当然,你也可以自行开发适用于业务场景的 Kafka 消费端。
五、配置 Flink 消费 Kafka 数据
1.安装 Flink Kafka Connector
在 Flink 生态中,Flink Kafka Connector 用于消费 Kafka 中的数据并输出到 Flink 中。Flink Kafka Connector 并不是内建的,因此在 Flink 安装完毕后,还需要将 Flink Kafka Connector 及其依赖项添加到 Flink 安装目录中。下载下列 jar 文件至 Flink 安装目录下的 lib 目录中,如果你已经运行了 Flink 集群,请重启集群以加载新的插件。
- flink-connector-kafka-1.17.1.jar
- flink-sql-connector-kafka-1.17.1.jar
- kafka-clients-3.5.1.jar
2.创建一个表
可以在 Flink 的安装目录执行如下命令,启动 Flink SQL 交互式客户端:
[root@flink flink-1.15.0]# ./bin/sql-client.sh
随后,执行如下语句创建一个名为 tpcc_orders 的表:
CREATE TABLE tpcc_orders (o_id INTEGER,o_d_id INTEGER,o_w_id INTEGER,o_c_id INTEGER,o_entry_d STRING,o_carrier_id INTEGER,o_ol_cnt INTEGER,o_all_local INTEGER
) WITH (
'connector' = 'kafka',
'topic' = 'tidb_tpcc_orders',
'properties.bootstrap.servers' = '127.0.0.1:9092',
'properties.group.id' = 'testGroup',
'format' = 'canal-json',
'scan.startup.mode' = 'earliest-offset',
'properties.auto.offset.reset' = 'earliest'
)
请将 topic 和 properties.bootstrap.servers 参数替换为环境中的实际值。
3.查询表内容
执行如下命令,查询 tpcc_orders 表中的数据:
SELECT * FROM tpcc_orders;
执行成功后,可以观察到有数据输出,如下图
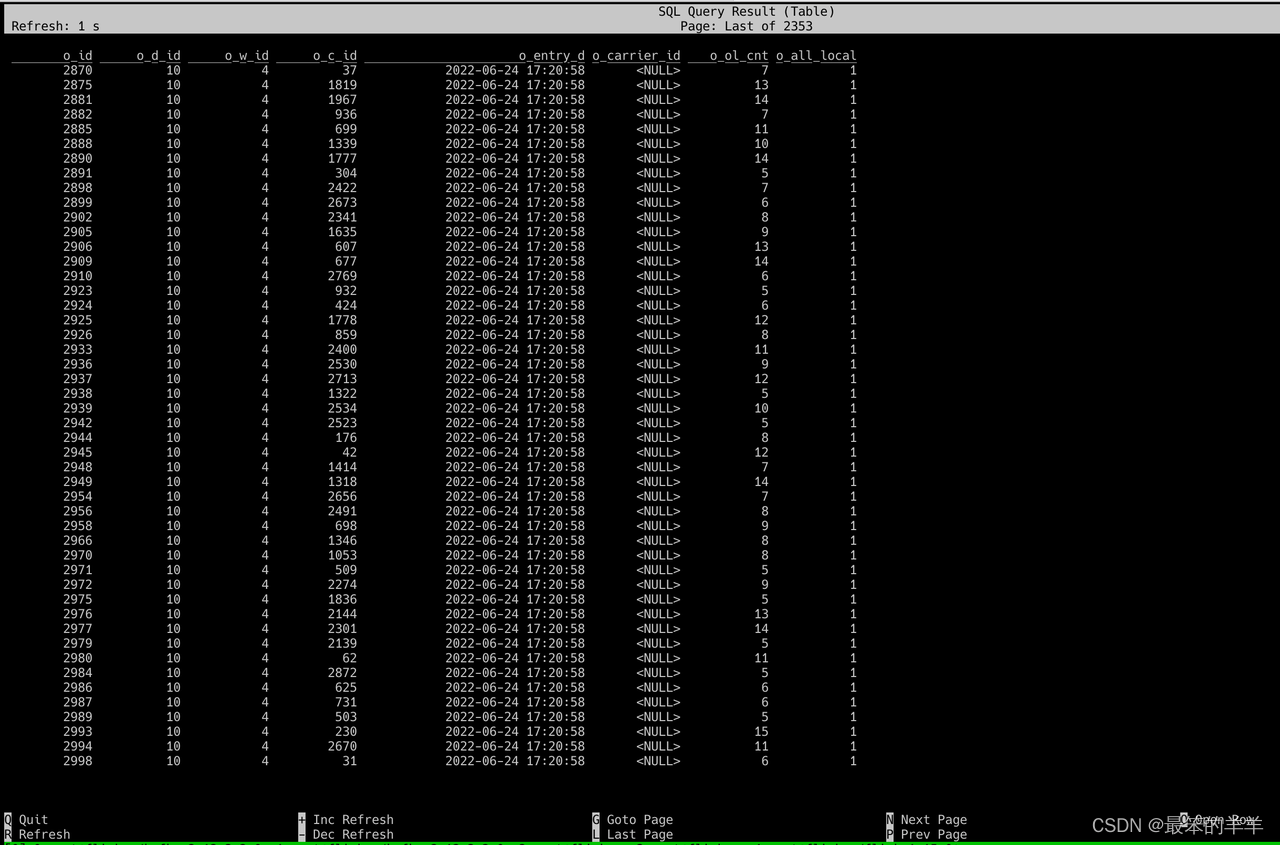
至此,就完成了 TiDB 与 Flink 的数据集成。
相关文章:
TiDB数据库从入门到精通系列之六:使用 TiCDC 将 TiDB 的数据同步到 Apache Kafka
TiDB数据库从入门到精通系列之六:使用 TiCDC 将 TiDB 的数据同步到 Apache Kafka 一、技术流程二、搭建环境三、创建Kafka changefeed四、写入数据以产生变更日志五、配置 Flink 消费 Kafka 数据 一、技术流程 快速搭建 TiCDC 集群、Kafka 集群和 Flink 集群创建 c…...
Spring对象装配
在spring中,Bean的执行流程为启动spring容器,实例化bean,将bean注册到spring容器中,将bean装配到需要的类中。 既然我们需要将bea装配到需要的类中,那么如何实现呢?这篇文章,将来阐述一下如何实…...
bigemap如何添加mapbox地图?
第一步 打开浏览器,找到你要访问的地图的URL地址,并且确认可以正常在浏览器中访问;浏览器中不能访问,同样也不能在软件中访问。 以下为常用地图源地址: 天地图: http://map.tianditu.gov.cn 包含&…...

python爬虫6:lxml库
python爬虫6:lxml库 前言 python实现网络爬虫非常简单,只需要掌握一定的基础知识和一定的库使用技巧即可。本系列目标旨在梳理相关知识点,方便以后复习。 申明 本系列所涉及的代码仅用于个人研究与讨论,并不会对网站产生不好…...

Linux查找命令
find find /dir -name filename 按名字查找 find . -name “*.c” 将当前目录及其子目录下所有文件后缀为 .c 的文件列出来 find . -type f 将当前目录及其子目录中的所有文件列出 find . -ctime 20 将当前目录及其子目录下所有最近 20 天内更新过的文件列出 find / -type f -…...
在 IntelliJ IDEA 中使用 Docker 开发指南
目录 一、IDEA安装Docker插件 二、IDEA连接Docker 1、Docker for Windows 连接 2、SSH 连接 3、Connection successful 连接成功 三、查看Docker面板 四、使用插件生成镜像 一、IDEA安装Docker插件 打开 IntelliJ IDEA,点击菜单栏中的 "File" -&g…...

【并发编程】自研数据同步工具的优化:创建线程池多线程异步去分页调用其他服务接口获取海量数据
文章目录 场景:解决方案 场景: 前段时间在做一个数据同步工具,其中一个服务的任务是调用A服务的接口,将数据库中指定数据请求过来,交给kafka去判断哪些数据是需要新增,哪些数据是需要修改的。 刚开始的设…...
)
python函数、运算符等简单介绍3(无顺序)
set(集合) 集合(set) -> 负责存储【不重复的数据】,并且是【无序存储】 的容器,主要用来去重和逻辑比较 set1 {1,2,3,4,58,7,4,1,2,3,5} print(set1) print(type(set1)) # 输出结果: {1, 2, 3, 4, 5, 7, 58} <…...
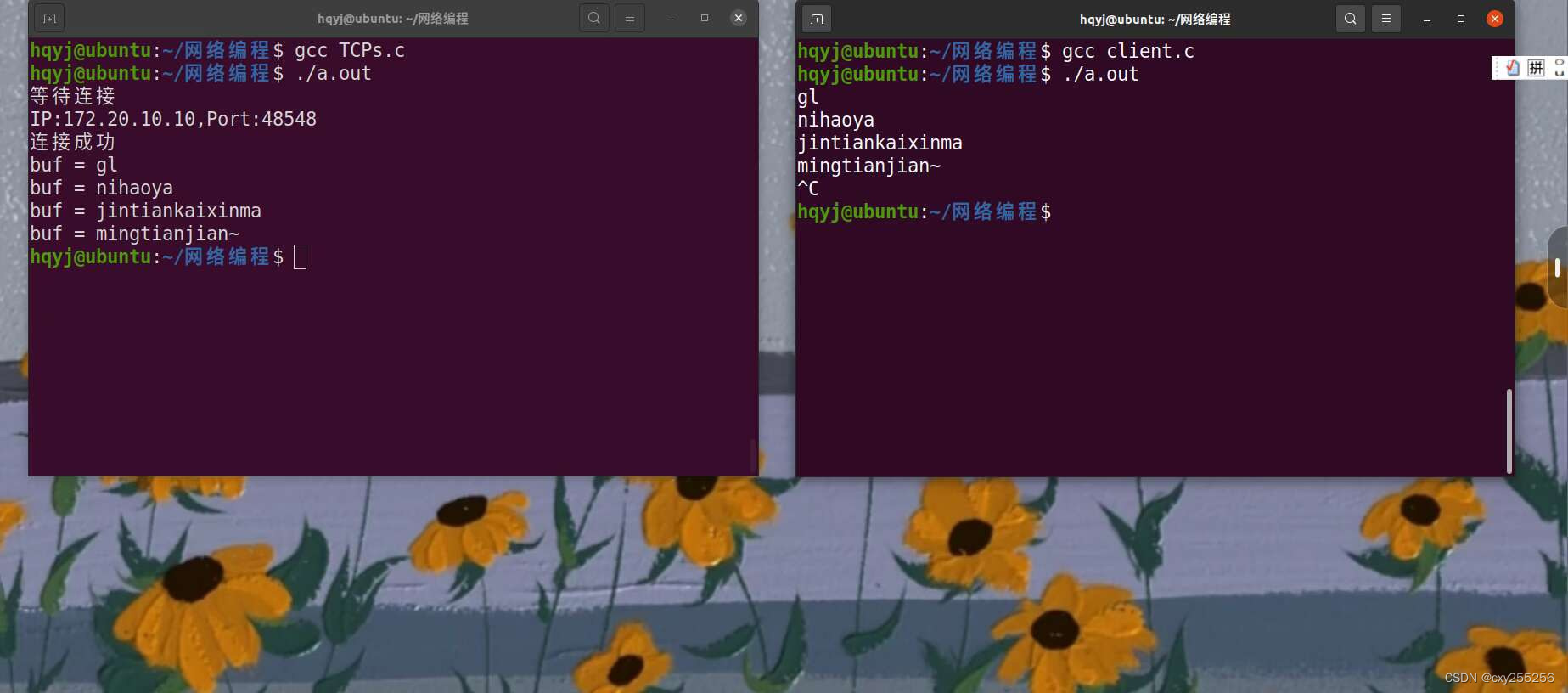
TCP服务器(套接字通信)
服务器 客户端 结果...
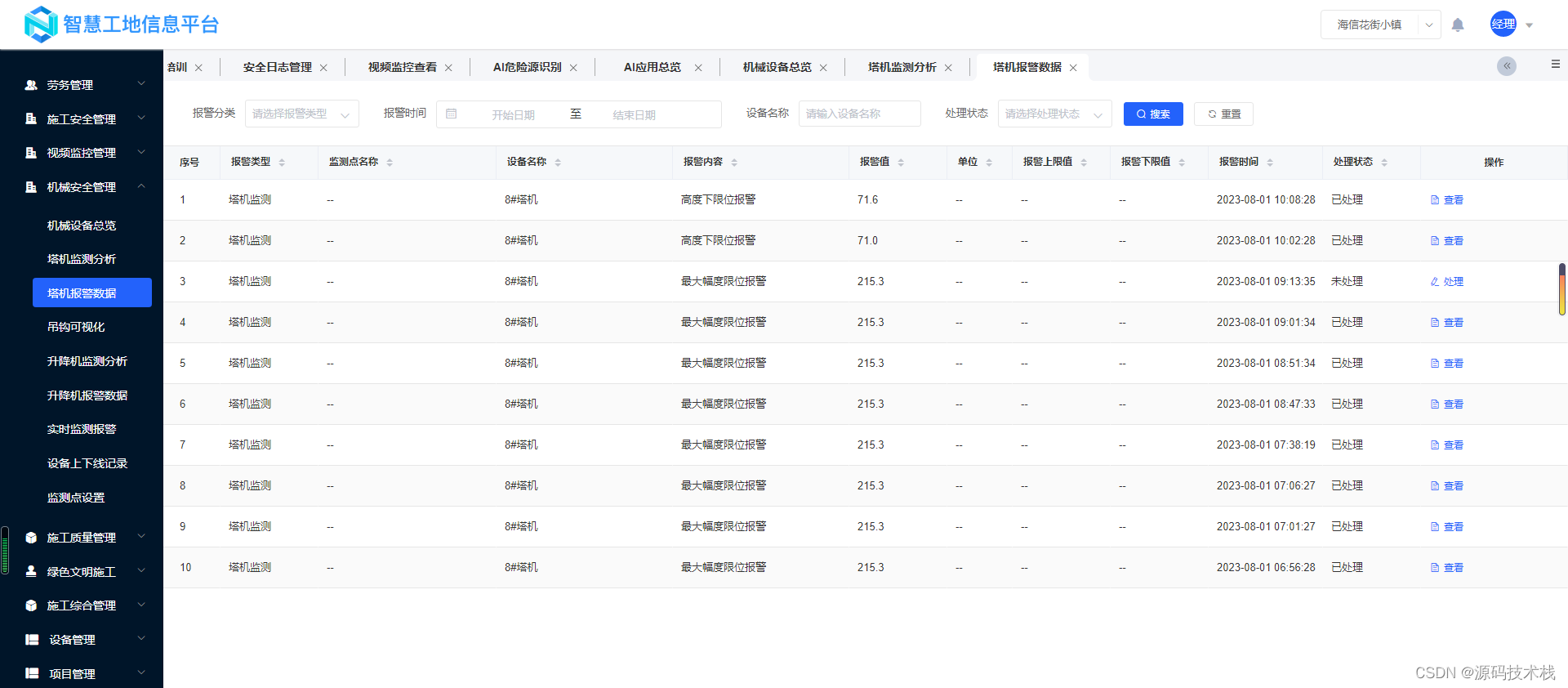
【智慧工地源码】:人工智能、BIM技术、机器学习在智慧工地的应用
智慧工地云平台是专为建筑施工领域所打造的一体化信息管理平台。通过大数据、云计算、人工智能、BIM、物联网和移动互联网等高科技技术手段,将施工区域各系统数据汇总,建立可视化数字工地。同时,围绕人、机、料、法、环等各方面关键因素&…...
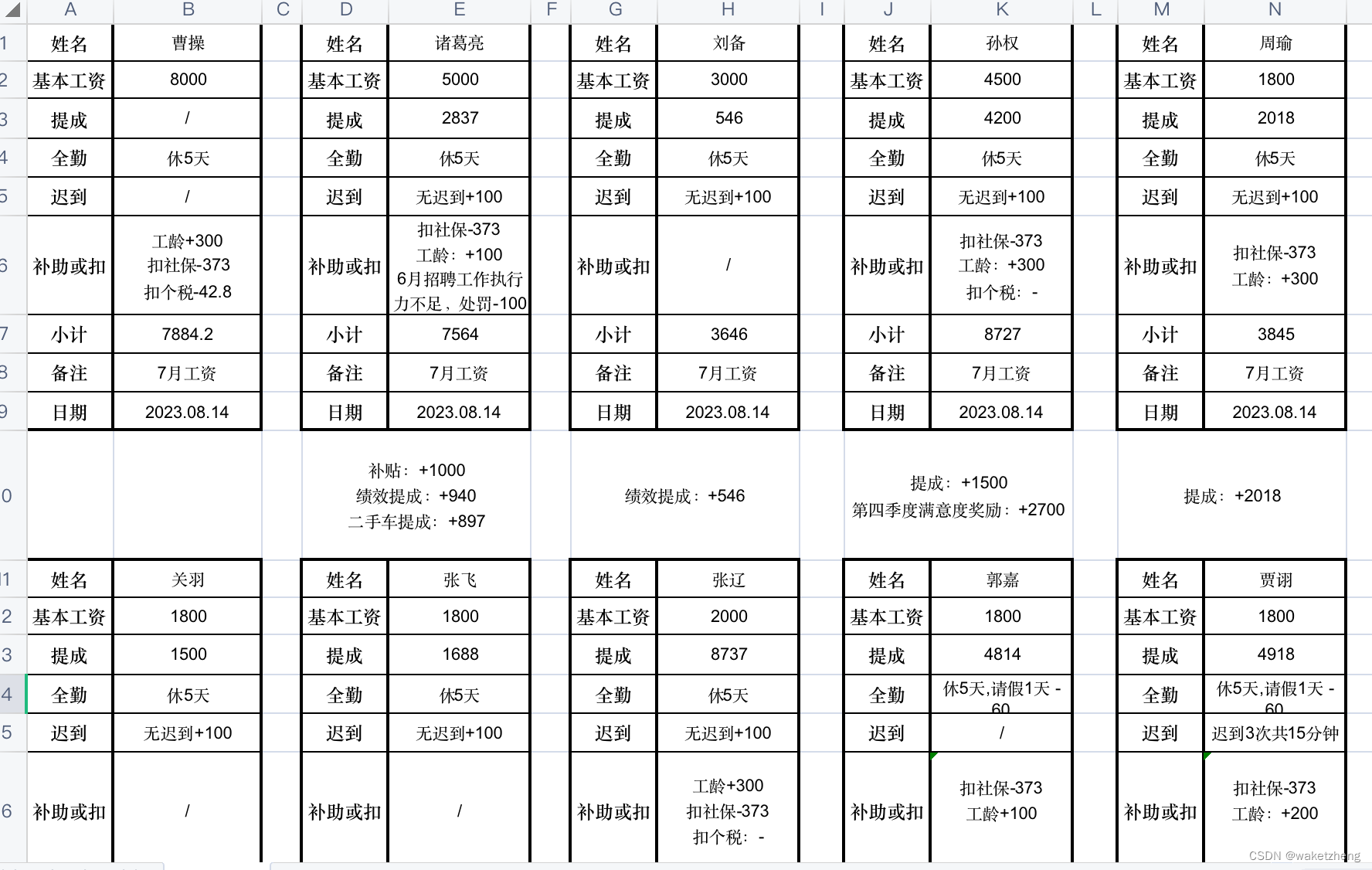
使用python读Excel文件并写入另一个xls模版
效果如下: 原文件内容 转化后的内容 大致代码如下: 1. load_it.py #!/usr/bin/env python import re from datetime import datetime from io import BytesIO from pathlib import Path from typing import List, Unionfrom fastapi import HTTPExcep…...

债务人去世,债权人要求其妻女承担还款责任,法院支持吗
债务人去世,债权人要求其妻女承担还款责任,法院支持吗 2019年9月20日,老张以公司资金周转为由向好友任某先后借款合计40万。2022年8月27日老张出具还款承诺书,承诺2022年11月30日前归还本息(本息90万元)到…...
arcgis pro3.0-3.0.1-3.0.2安装教程大全及安装包下载
一. 产品介绍: ArcGIS Pro 这一功能强大的单桌面 GIS 应用程序是一款功能丰富的软件,采用 ArcGIS Pro 用户社区提供的增强功能和创意进行开发。 ArcGIS Pro 支持 2D、3D 和 4D 模式下的数据可视化、高级分析和权威数据维护。 支持通过 Web GIS 在一系列 …...
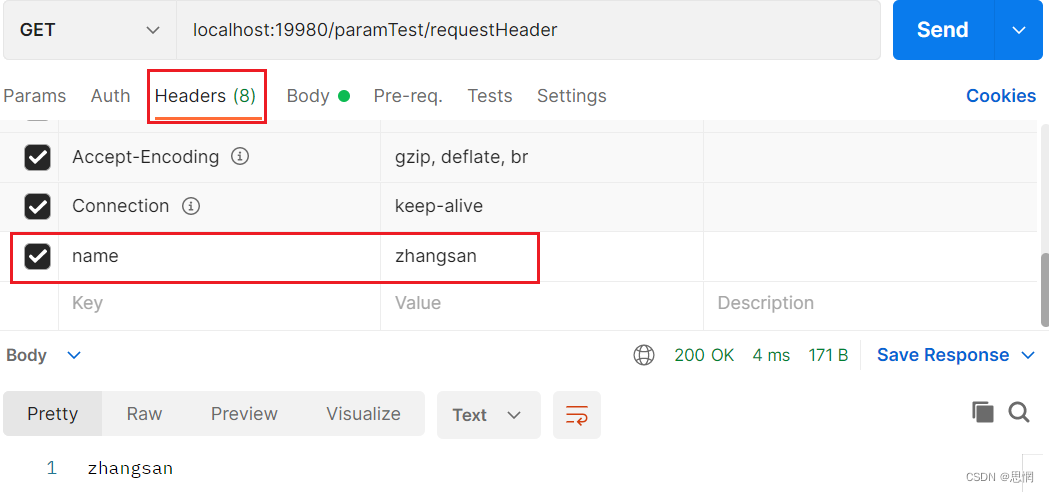
@RequestHeader使用
RequestHeader 请求头参数的设置 GetMapping("paramTest/requestHeader")public String requestHeaderTest(RequestHeader("name") String name){return name;} 在Postman的Headers中添加请求头参数,不过貌似不能加中文...
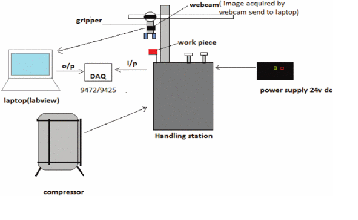
LabVIEW开发图像采集和基于颜色的隔离
LabVIEW开发图像采集和基于颜色的隔离 在当今的工业和工厂中,准确性和精度是决定特定行业生产力的两个重要关键点。为了优化生产力,各行各业正在从手动操作转向自动操作和控制。机器人技术在工业过程中的出现为人类提供了机械辅助。机器视觉在工业机器人…...

站长公益主机,免费主机➕免费域名➕博客申请➕论坛申请
站长公益主机,免费主机➕免费域名➕博客申请➕论坛申请 在出教程之前准备好久,测试搭建轻量论坛无压力 选用稳定免费域名➕免费主机分销给,可以套CDN使用 坚持免费时间是大厂不能媲美,刚开始做网站时用的是这个分销,独…...
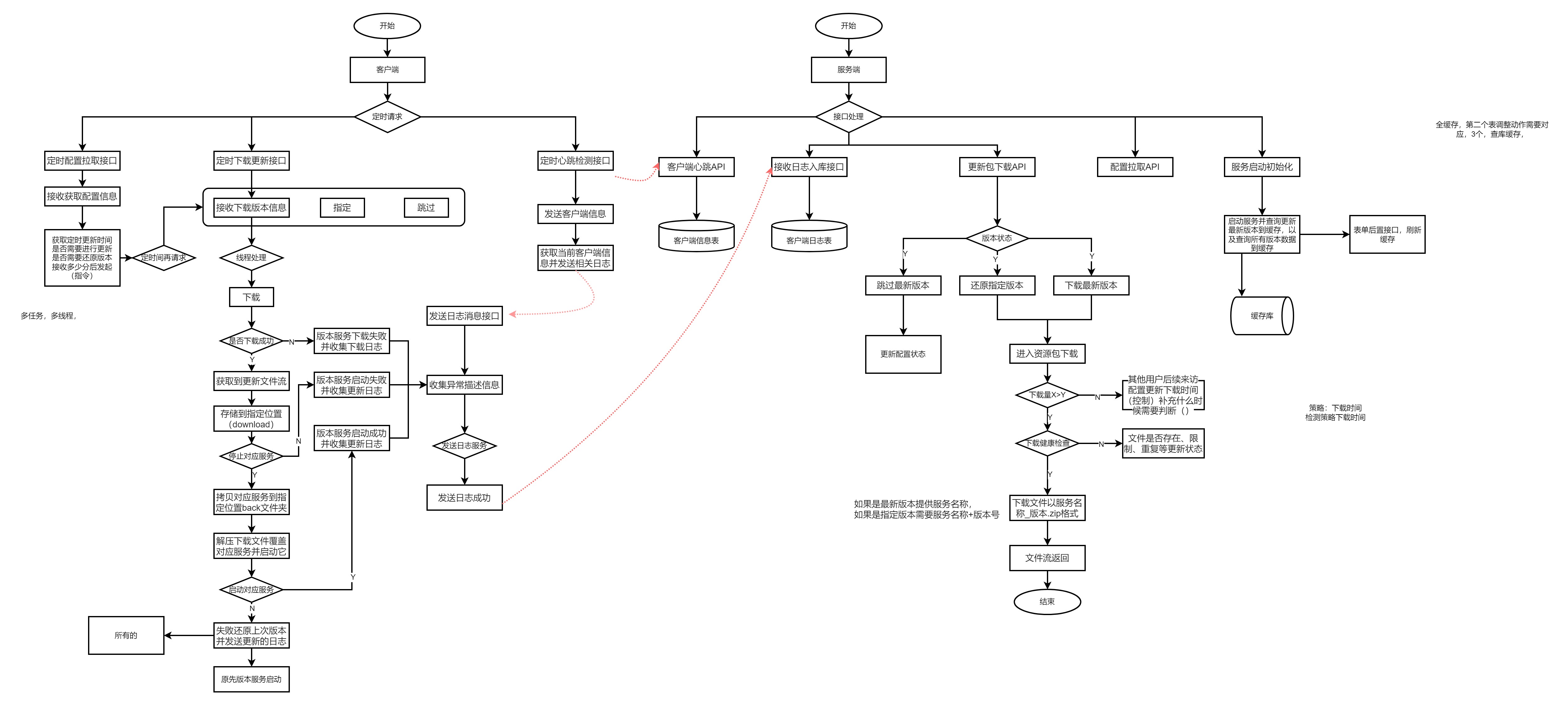
【PRO-UPDATE】自动更新程序图形小记
大纲流程 设计流程 v0.1 v1.0...

flume系列之:监控Systemctl托管的flume agent组
flume系列之:监控Systemctl托管的flume agent组 一、需求背景二、相关技术博客三、远程登陆flume机器四、发送飞书告警五、监控flume agent组状态一、需求背景 flume接kafka集群,一个kafka集群对应一个flume agent组,会把一组flume agent用systemctl托管每接一个kafka集群会…...

16.3.1 【Linux】程序的观察
既然程序这么重要,那么我们如何查阅系统上面正在运行当中的程序呢?利用静态的 ps 或者是动态的 top,还能以 pstree 来查阅程序树之间的关系。 ps :将某个时间点的程序运行情况撷取下来 仅观察自己的 bash 相关程序: p…...

HarmonyOS 设置全屏NoTitleBar
这篇很有用:玩转HarmonyOS 状态栏&标题栏&导航栏相关操作方法整理 配置页面全屏显示(在config.json中配置): "metaData": {"customizeData": [{"name": "hwc-theme","value": "androi…...

如何掌握Il2CppDumper:Unity逆向工程实战指南与深度解析
如何掌握Il2CppDumper:Unity逆向工程实战指南与深度解析 【免费下载链接】Il2CppDumper Unity il2cpp reverse engineer 项目地址: https://gitcode.com/gh_mirrors/il/Il2CppDumper 你是否曾面对Unity游戏的il2cpp二进制文件感到无从下手?是否在…...
)
基于 SOFAJRaft + Spring Boot 构建高可用 KV 存储集群(完整源码)
基于 SOFAJRaft + Spring Boot 构建高可用 KV 存储集群(完整源码) 引言 在分布式系统中,一致性 是核心难题。Raft 是比 Paxos 更易于理解的共识算法,而 SOFAJRaft 是蚂蚁集团开源的 Java 高性能 Raft 实现。 本文带你从零构建一个 3 节点高可用 KV 存储集群,包含完整源码、…...

无王无帝定乾坤,来自田间第一人:海棠铁哥定千秋
无王无帝定乾坤来自田间第一人序章山河叹岁月悠悠流转,山河几度浮沉。 历代豪杰争雄逐鹿,到头来霸业如烟,功名易逝。 终究难锁万古山河,难稳世代人心。第一章天命 世间最难得千秋基业,天下最珍贵万世清平。 恰逢天命归…...

2026年初中生赴新加坡留学,费用究竟几何?一文为你揭秘!
在教育全球化的今天,越来越多的家长将目光投向海外,新加坡凭借其优质的教育资源、安全的社会环境和多元的文化氛围,成为众多初中生留学的热门选择。那么,2026年初中生赴新加坡留学的费用到底是多少呢?本文将为你详细揭…...
别再死记硬背公式了!用大白话和动图拆解Transformer的注意力机制
用生活场景拆解Transformer:注意力机制就像一场高效会议 想象你正在主持一场跨国团队会议,成员们用不同语言讨论项目进展。作为主持人,你需要快速捕捉每个人的发言重点,判断谁的意见最关键,并协调不同观点之间的关系—…...

如何在Windows上快速挂载ISO镜像?WinCDEmu虚拟光驱终极指南
如何在Windows上快速挂载ISO镜像?WinCDEmu虚拟光驱终极指南 【免费下载链接】WinCDEmu 项目地址: https://gitcode.com/gh_mirrors/wi/WinCDEmu 还在为ISO、IMG等光盘镜像文件无法直接使用而烦恼吗?还在为没有物理光驱而无法读取光盘内容而困扰吗…...

云端开发新体验:code-server部署与多场景应用指南
1. 为什么你需要一个云端开发环境? 记得去年我同时参与三个项目时,每天要在办公室台式机、家里笔记本和平板电脑之间来回切换。每次换设备最头疼的就是开发环境不一致——Node.js版本不同、Python包缺失、配置文件没同步...有次紧急修复线上bug时&#x…...
)
离线地图项目救星:手把手教你用微图批量下载并管理多源瓦片(附避坑点)
离线地图实战指南:微图工具链与多源瓦片管理全解析 在智慧园区建设、车载导航系统开发或野外作业场景中,稳定可靠的地图服务往往是刚需。但现实情况是,这些场景常面临网络覆盖不稳定甚至完全离线的挑战。传统解决方案要么依赖预装商业地图数…...
:事件模型与五大类操作(文件/注册表/进程/网络/Profiling)
《Windows Sysinternals实战指南》Process Monitor 学习笔记(5.2):事件模型与五大类操作(文件/注册表/进程/网络/Profiling
🔥个人主页:杨利杰YJlio❄️个人专栏:《Sysinternals实战教程》《Windows PowerShell 实战》《WINDOWS教程《IOS教程》《微信助手》《锤子助手》 《Python》 《Kali Linux》 《那些年未解决的Windows疑难杂症》🌟 让复杂的事情更简…...

CANN/asc-devkit Mull乘法溢出API
Mull 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/cann/…...