基于MapReduce的Hive数据倾斜场景以及调优方案
文章目录
- 1 Hive数据倾斜的现象
- 1.1 Hive数据倾斜的场景
- 1.2 解决数据倾斜问题的优化思路
- 2 解决Hive数据倾斜问题的方法
- 2.1 开启负载均衡
- 2.2 引入随机性
- 2.3 使用MapJoin或Broadcast Join
- 2.4 调整数据存储格式
- 2.5 分桶表、分区表
- 2.6 使用抽样数据进行优化
- 2.7 过滤倾斜join单独进行join
1 Hive数据倾斜的现象
通常认为当所有的map task全部完成,并且99%的reduce task完成,只剩下一个或者少数几个reduce task一直在执行,这种情况下一般都是发生了数据倾斜。
即为在整个计算过程中,大量相同的key被分配到了同一个reduce任务上造成。Hive的数据倾斜本质上是MapReduce计算引擎的数据倾斜,一般来说容易发生在reduce阶段,map阶段的数据倾斜多是由于HDFS存储数据文件源的问题,reduce阶段则多是开发过程中程序员引起,需要通过手段进行优化。
本文仅讨论基于MR引擎的Hive数据倾斜现象,另外Spark、Flink中的数据倾斜择日再论。
1.1 Hive数据倾斜的场景
Hive数据倾斜是指在数据分布中存在不均匀的情况,业务问题或者业务数据本身的问题,某些数据比较集中,导致某些节点或分区上的数据量远远大于其他节点或分区,从而影响查询性能和任务的均衡执行,尤其是join。以下是一些可能导致Hive数据倾斜的场景:
-
连接操作中的键值倾斜:在进行join连接操作时,如果连接的键存在不均匀分布、数据类型不一致,会导致某些键对应的数据量远大于其他键,造成倾斜。表中作为关联条件的字段值为0或空值的较多,会造成shuffle时进入到一个reduce任务中。为什么是空值?因为空值在根据hash计算分区时,会在内存中被视为同样的hash,进而被放入一个分区进行计算。
-
分桶表和分区表的数据倾斜:如果在分桶表或分区表中,某些分桶或分区的数据量过大,超过了其他分桶或分区的数据量,就会造成倾斜。
-
聚合操作的倾斜:在执行聚合操作(如GROUP BY、COUNT、SUM等)时,如果被聚合的列数据分布不均匀,会导致聚合操作的任务负载不平衡,Count(distinct id ) 去重统计要慎用。
-
高基数列的倾斜:某些列的基数(唯一值的数量)很高,而其他列的基数较低,可能导致以高基数列为基准进行的连接或聚合操作产生数据倾斜。
-
随机写入场景:当数据随机写入分区表或分桶表时,可能会导致某些分区或分桶的数据量增长迅速,从而引发倾斜。
-
数据导入方式不均匀:如果使用了多个任务同时导入数据,而这些任务在导入数据时的输入源数据分布不均匀,就会导致数据倾斜。
1.2 解决数据倾斜问题的优化思路
1.2.1 代码层面:
-
检查连接键和分区键:检查连接和分组操作的键,确保数据分布均匀,避免倾斜。可以考虑在键中引入随机数,或者对键进行散列操作。
-
使用MapJoin和Broadcast Join:对于连接操作,使用MapJoin或Broadcast Join可以将小表复制到每个节点上,避免数据倾斜。
-
检查聚合操作:如果有聚合操作,尤其是GROUP BY,确保被聚合的列数据分布均匀,可以考虑使用采样数据进行预估。
-
调整存储格式:选择合适的列式存储格式(如ORC、Parquet),可以减少数据读取,提高性能。
-
数据倾斜监控和日志:在代码中添加数据倾斜监控和日志,便于发现和定位倾斜的数据。
-
group by 代替 distinct:当要统计某一列的去重数时,如果数据量很大,count(distinct)就会非常慢,原因与order by类似,count(distinct)逻辑只会有很少的reducer来处理。
-
列裁剪和分区裁剪:所谓列裁剪就是在查询时只读取需要的列,分区裁剪就是只读取需要的分区。Hive中与列裁剪优化相关的配置项是
hive.optimize.cp,与分区裁剪优化相关的则是hive.optimize.pruner,默认都是true。
1.2.2 配置层面:
-
动态分桶和分区:对于分桶和分区表,使用动态分桶和分区可以根据数据分布情况进行自动优化。
-
并行度设置:根据集群的规模和硬件配置,适当调整并行度,避免某些任务负载过重。
-
调整资源分配:分配合适的资源给任务,避免资源争夺导致倾斜。
1.2.3 参数调整:
-
调整shuffle参数:调整shuffle相关的参数,如mapreduce.reduce.shuffle.input.buffer.percent、mapreduce.reduce.shuffle.parallelcopies等。
-
调整内存参数:根据任务的实际需求,调整内存参数,避免内存不足引发倾斜。
1.2.4 其他思路:
-
数据抽样分析:使用抽样数据进行分析,了解数据分布情况,有助于更好地优化查询。
-
使用中间表:将复杂的查询过程分解成多个步骤,将中间结果保存在临时表中,减少大查询的复杂性。
-
使用UDF和UDAF:编写自定义函数和聚合函数,对倾斜数据进行特殊处理,分散数据分布。
-
数据重分布:通过数据重分布操作,将倾斜数据均匀地分布到不同节点上。
-
增加节点数:如果集群规模允许,可以考虑增加节点数,从而分担负载,减轻数据倾斜。
2 解决Hive数据倾斜问题的方法
解决方案需要具体问题具体分析,综合考虑资源、数据量等多种因素,以下方案有相互交叉的内容,需要研判考虑:
2.1 开启负载均衡
-- map端的Combiner,默认为ture
set hive.map.aggr=true;
-- 开启负载均衡
set hive.groupby.skewindata=true (默认为false)
这行代码是在Hive中用于处理数据倾斜的配置代码。它的作用是开启Hive中的负载均衡优化,以应对数据倾斜的情况。
具体来说:
-
hive.map.aggr=true:默认情况下,Hive在执行聚合操作时(如GROUP BY、SUM、AVG等),会在Map端进行部分聚合(Partial Aggregation),以减少数据的传输量。这个配置项开启了Map端的部分聚合,可以在Map阶段对部分数据进行聚合,减少数据传输到Reducer的量。 -
hive.groupby.skewindata=true:这个配置项是为了应对数据倾斜的情况。数据倾斜指的是在进行聚合操作时,部分数据分布不均匀,导致部分Reducer处理的数据量远大于其他Reducer。开启此配置项会在数据倾斜的情况下,将数据倾斜的Key单独划分到一个Reducer,以实现负载均衡,减少单个Reducer的负载。
总体来说,这两个配置项的作用是在MapReduce过程中,优化聚合操作和应对数据倾斜,从而提高作业的执行效率和稳定性。但是,这只是配置项的作用描述,具体的优化效果还需要根据实际数据和作业情况进行实验和观察。
2.2 引入随机性
通过在连接键或分区键中引入随机数、数据加盐等方式,将倾斜的数据打散,使其分布均匀化,减少倾斜。
- 使用随机前缀:
-- 创建分桶表,内部外部表也行
CREATE TABLE skewed_table (id INT,value STRING
)
CLUSTERED BY (id) INTO 4 BUCKETS;-- 插入数据到分桶表
INSERT INTO TABLE skewed_table
SELECT id, value FROM source_data;-- 添加随机前缀列
-- 这里使用FLOOR(rand() * 100)生成一个0到99的随机整数,作为随机前缀
SELECT id, value, FLOOR(rand() * 100) AS random_prefix
FROM skewed_table;
- 使用哈希函数:
-- 创建分桶表,内部外部表也行
CREATE TABLE skewed_table (id INT,value STRING
)
CLUSTERED BY (id) INTO 4 BUCKETS;-- 插入数据到分桶表
INSERT INTO TABLE skewed_table
SELECT id, value FROM source_data;-- 使用哈希函数生成分桶列
-- 这里使用MD5哈希函数将id列哈希为一个字符串,然后将哈希字符串转换为整数
SELECT id, value, CAST(CONV(SUBSTRING(MD5(CAST(id AS STRING)), 1, 8), 16, 10) % 4 AS INT) AS hash_bucket
FROM skewed_table;
- 使用窗口函数和随机数:
-- 创建分桶表,内部外部表也行
CREATE TABLE skewed_table (id INT,value STRING
)
CLUSTERED BY (id) INTO 4 BUCKETS;-- 插入数据到分桶表
INSERT INTO TABLE skewed_table
SELECT id, value FROM source_data;-- 使用窗口函数和随机数生成分桶列
-- 这里使用ROW_NUMBER()窗口函数和FLOOR(rand() * 4)生成一个随机分桶号
SELECT id, value, FLOOR(rand() * 4) AS random_bucket
FROM (SELECT id, value, ROW_NUMBER() OVER (PARTITION BY id) AS row_numFROM skewed_table
) t;
- 使用分桶表解决连接数据倾斜:
-- 创建两个分桶表
CREATE TABLE table1 (id INT,value STRING
)
CLUSTERED BY (id) INTO 4 BUCKETS;CREATE TABLE table2 (id INT,data STRING
)
CLUSTERED BY (id) INTO 4 BUCKETS;-- 插入数据到分桶表
INSERT INTO TABLE table1
SELECT id, value FROM source_data1;INSERT INTO TABLE table2
SELECT id, data FROM source_data2;-- 使用分桶表解决连接数据倾斜
-- 对两个表都使用相同的分桶列,并且分桶数也相同,可以减少连接时的数据倾斜
SELECT t1.id, t1.value, t2.data
FROM table1 t1
JOIN table2 t2 ON t1.id = t2.id;
2.3 使用MapJoin或Broadcast Join
对于连接操作,reduce join 转换成 MapJoin,使用MapJoin或Broadcast Join可以将小表复制到每个节点上,避免数据倾斜。
Map-side Join(MapJoin)是一种用于处理数据倾斜问题的方法,特别适用于一个小表和一个大表进行连接的场景。在MapJoin中,小表被缓存在内存中,并与大表进行连接操作,以减少大表的数据复制和数据倾斜问题。以下是如何使用MapJoin来解决数据倾斜问题的步骤:
-
准备数据: 假设有一个大表
big_table和一个小表small_table,需要根据某个共同的列进行连接。 -
设置MapJoin: 在Hive中,可以通过设置参数来启用MapJoin。
-- 设置MapJoin
set hive.auto.convert.join=true;
set hive.mapjoin.smalltable.filesize=25000000; -- 小表的大小阈值,单位为字节
set hive.auto.convert.join.noconditionaltask=true; -- 仅进行MapJoin,不使用Reduce阶段
- 对小表进行Bucket操作: 将小表进行Bucket操作,使其和大表具有相同的Bucket数量。
-- 对小表进行Bucket操作
CREATE TABLE small_table_bucketed
CLUSTERED BY (join_column) INTO N BUCKETS
AS
SELECT * FROM small_table;
- 执行MapJoin查询: 编写查询语句,使用MapJoin来连接大表和经过Bucket操作的小表。
SELECT /*+ MAPJOIN(small_table_bucketed) */ big_table.*, small_table_bucketed.*
FROM big_table
JOIN small_table_bucketed ON big_table.join_column = small_table_bucketed.join_column;
在这个过程中,MapJoin会将小表的数据加载到内存中,并在Map阶段进行连接操作,从而避免了大表的数据复制和数据倾斜问题。需要注意的是,MapJoin适用于小表和大表的大小阈值适当的情况下,如果小表过大,可能会导致内存不足的问题。
总之,MapJoin是一种有效的方法来解决数据倾斜问题,特别适用于小表和大表的连接操作,通过在Map阶段进行连接,减少了数据复制和数据倾斜的可能性。
2.4 调整数据存储格式
调整存储格式,如使用ORC或Parquet等列式存储格式,或者开启输出压缩,可以减少不必要的数据读取,改善数据倾斜。
// 开启Map端输出压缩
Configuration conf = job.getConfiguration();
conf.setBoolean("mapreduce.map.output.compress", true);
conf.setClass("mapreduce.map.output.compress.codec", GzipCodec.class, CompressionCodec.class);
这行代码是在MapReduce程序中使用Hadoop的Configuration类来配置Map端的输出压缩。虽然这行代码本身并不直接处理数据倾斜,但它可以在一定程度上优化作业的性能,从而减轻数据倾斜造成的影响。
数据倾斜可能导致部分Reducer的负载过重,而启用Map端输出压缩可以在一定程度上减小传输数据量,从而减轻Reducer的负担。具体来说,这段代码的作用是:
-
conf.setBoolean("mapreduce.map.output.compress", true);:这一行代码启用了Map端输出的压缩。MapReduce作业产生的中间数据(Map输出数据)在传输到Reducer之前可以进行压缩,减小数据的传输量,从而加快数据传输速度。 -
conf.setClass("mapreduce.map.output.compress.codec", GzipCodec.class, CompressionCodec.class);:这一行代码指定了使用的压缩编解码器。在这个例子中,使用的是Gzip压缩编解码器(GzipCodec.class),它可以对中间数据进行Gzip压缩。
通过开启Map端输出压缩,可以减小Map输出数据的传输量,从而减轻了网络传输的压力。这在数据倾斜的情况下可能会有一定的帮助,因为数据倾斜往往会导致部分Reducer需要处理较多的数据,通过减小传输数据量,可以加快数据的传输速度,从而在一定程度上减轻了数据倾斜带来的影响。然而,需要注意的是,这只是优化的一部分,实际情况可能还需要结合其他优化策略来解决数据倾斜问题。
2.5 分桶表、分区表
通过调整查询计划,如使用分桶表、分区表等,可以将任务负载均衡分配,减少数据倾斜。
分桶表是Hive中一种用于优化查询性能的技术,它可以在一定程度上帮助解决数据倾斜问题。分桶表将数据按照指定的列进行哈希分桶存储,每个分桶都包含了一部分数据,使得数据更加均匀地分布在不同的分桶中。当进行Join操作时,如果参与Join的两个表都是分桶表并且使用相同的分桶列,那么可以通过哈希分桶的方式来提高Join的效率,减轻数据倾斜问题。
下面是分桶表如何解决Join中的数据倾斜问题的基本步骤:
-
选择合适的分桶列: 首先,需要根据实际情况选择合适的列作为分桶列。通常情况下,可以选择参与Join的列作为分桶列。
-
创建分桶表: 将需要进行Join的表创建为分桶表,并指定分桶列和分桶数量。分桶数量应该根据数据量来合理设置,以确保数据能够均匀地分布在各个分桶中。
-- 创建分桶表A,指定分桶列bucket_col和分桶数量4
CREATE TABLE table_A (id INT,value STRING
)
CLUSTERED BY (bucket_col) INTO 4 BUCKETS;-- 创建分桶表B,同样指定分桶列bucket_col和分桶数量4
CREATE TABLE table_B (id INT,data STRING
)
CLUSTERED BY (bucket_col) INTO 4 BUCKETS;
- 插入数据: 将数据插入到分桶表中。Hive会根据分桶列的哈希值将数据均匀地分配到不同的分桶中。
-- 插入数据到分桶表A
INSERT INTO TABLE table_A
SELECT id, value FROM source_data_A;-- 插入数据到分桶表B
INSERT INTO TABLE table_B
SELECT id, data FROM source_data_B;
- 进行Join操作: 当需要进行Join操作时,如果两个参与Join的表都是分桶表并且使用相同的分桶列,Hive会自动利用分桶信息来进行优化。在Join时,Hive会根据分桶列的哈希值将相同哈希值的数据分配到同一个节点上,从而减少数据的传输和倾斜的问题。
-- 进行基于分桶表的Join操作
SELECT a.id, a.value, b.data
FROM table_A a
JOIN table_B b ON a.id = b.id;在这个示例中,我们创建了两个分桶表table_A和table_B,分别用于存储两个数据源的数据。然后通过插入数据,将源数据插入到分桶表中。最后,我们进行了一个基于分桶表的Join操作,通过分桶列id来进行Join。由于两个表都是分桶表,Hive会根据分桶列的哈希值将相同哈希值的数据分配到同一个节点上,从而优化Join操作。
请注意,实际使用中需要根据数据的特点和需求来选择分桶列和分桶数量。分桶表的使用需要结合具体场景来考虑,以达到优化查询性能的目的。
分桶表的优势在于,通过合理设置分桶数量和选择适当的分桶列,可以使数据更加均匀地分布在不同的分桶中,从而减轻数据倾斜的影响。但需要注意的是,分桶表并不能完全消除数据倾斜,特别是在数据分布不均匀的情况下,仍然可能会出现倾斜的问题。在实际应用中,还可以结合其他优化技术,如使用Combiner、调整分桶数量、使用随机前缀等,来更全面地解决数据倾斜的影响。
2.6 使用抽样数据进行优化
对于大数据表,可以先对数据进行抽样,分析抽样数据的分布情况,再进行优化,避免全表扫描导致的倾斜。
// 采样数据
InputSampler.writePartitionFile(job, new InputSampler.RandomSampler(0.1, 10000));
这段代码是在MapReduce程序中使用Hadoop的InputSampler来采样数据,用于优化数据倾斜问题。具体来说,这段代码的作用是:
InputSampler.writePartitionFile(job, new InputSampler.RandomSampler(0.1, 10000));:这行代码使用随机采样器来创建一个分区文件。分区文件包含了采样的数据信息以及相应的分区信息,这可以用来指导MapReduce作业在进行Shuffle操作时将数据分配到不同的Reducer上。
在优化数据倾斜时,采样数据的目的是识别哪些数据可能会导致倾斜。通过对数据进行采样,可以分析采样数据的分布情况,进而确定哪些数据量较大或者分布不均匀。在这个例子中,使用了随机采样器,从输入数据中随机选择一定比例的数据(0.1,即10%),并采样的数据量为10000条。
通过分析采样数据,可以有助于识别数据倾斜的情况,从而采取相应的优化策略。例如,可以根据采样数据的分布情况来调整分区策略,使得数据更加均匀地分配到不同的Reducer上,从而减轻数据倾斜问题。
需要注意的是,虽然采样数据可以帮助识别数据倾斜问题,但它并不是解决数据倾斜的唯一方法。在实际应用中,可能还需要结合其他优化策略,如使用Combiner、使用合适的分区键、使用随机前缀等,来更全面地解决数据倾斜的影响。
2.7 过滤倾斜join单独进行join
假设有两个表:orders 和 customers,其中 orders 表中的 customer_id 列是高基数列,可能导致数据倾斜。我们可以使用过滤倾斜Key单独进行Join的方式来解决这个问题。
下面是一个示例的SQL代码:
-- 识别倾斜Key
SELECT customer_id
FROM orders
GROUP BY customer_id
HAVING COUNT(*) > 10000; -- 举例,根据实际情况设定阈值-- 拆分倾斜Key
CREATE TABLE skewed_orders AS
SELECT *
FROM orders
WHERE customer_id IN (identified_skewed_keys);CREATE TABLE non_skewed_orders AS
SELECT *
FROM orders
WHERE customer_id NOT IN (identified_skewed_keys);-- 单独处理倾斜Key
CREATE TABLE skewed_result AS
SELECT o.*, c.name
FROM skewed_orders o
JOIN customers c ON o.customer_id = c.customer_id;CREATE TABLE non_skewed_result AS
SELECT o.*, c.name
FROM non_skewed_orders o
JOIN customers c ON o.customer_id = c.customer_id;-- 合并结果
CREATE TABLE final_result AS
SELECT * FROM skewed_result
UNION ALL
SELECT * FROM non_skewed_result;
在这个示例中,我们首先识别出可能导致数据倾斜的 customer_id 值。然后,我们根据倾斜和非倾斜的情况,分别创建了两个临时表。接下来,对倾斜数据和非倾斜数据分别进行Join操作,并将结果存储在临时表中。最后,我们通过 UNION ALL 合并了倾斜和非倾斜数据的结果,得到最终的查询结果。
这种方法也适用于处理空值,思路是用where将空值过滤掉,再使用union all将带空值的数据进行关联。
相关文章:

基于MapReduce的Hive数据倾斜场景以及调优方案
文章目录 1 Hive数据倾斜的现象1.1 Hive数据倾斜的场景1.2 解决数据倾斜问题的优化思路 2 解决Hive数据倾斜问题的方法2.1 开启负载均衡2.2 引入随机性2.3 使用MapJoin或Broadcast Join2.4 调整数据存储格式2.5 分桶表、分区表2.6 使用抽样数据进行优化2.7 过滤倾斜join单独进行…...

mysql 02 数据库的约束
为防止错误的数据被插入到数据表,MySQL中定义了一些维护数据库完整性的规则;这些规则常称为表的约束。常见约束如下: 主键约束 主键约束即primary key用于唯一的标识表中的每一行。被标识为主键的数据在表中是唯一的且其值不能为空。这点类似…...
Quivr 基于GPT和开源LLMs构建本地知识库 (更新篇)
一、前言 自从大模型被炒的越来越火之后,似乎国内涌现出很多希望基于大模型构建本地知识库的需求,大概在5月底的时候,当时Quivr发布了第一个0.0.1版本,第一个版本仅仅只是使用LangChain技术结合OpenAI的GPT模型实现了一个最基本的…...

Unity如何制作声音控制条(控制音量大小)
一:UGUI制作 1. 首先在【层级】下面创建UI里面的Slider组件。设置好它对应的宽度和高度。 2.调整Slider滑动条的填充颜色。一般声音颜色我黄色,所以我们也调成黄色。 我们尝试滑动Slider里面的value。 a.滑动前。 b.滑动一半。 c.滑动完。 从以上滑动va…...

非计算机科班如何顺利转行计算机领域?
文章目录 每日一句正能量前言如何规划才能实现转计算机?计算机岗位发展前景?现阶段转计算机的建议后记 每日一句正能量 改变思路,改变习惯,改变一种活的方式,往往会创造无限,风景无限! 前言 近年…...
Android音视频剪辑器自定义View实战!
Android音视频剪辑器自定义View实战! - 掘金 /*** Created by zhouxuming on 2023/3/30** descr 音视频剪辑器*/ public class AudioViewEditor extends View {//进度文本显示格式-数字格式public static final int HINT_FORMAT_NUMBER 0;//进度文本显示格式-时间…...

stm32_ADC电源、通道、工作模式
0、ADC功能框图 1、ADC的电源 1.1、工作电源 VSSAVSS,VDDAVDD,简单来说,通常stm32是3.3V,ADC的工作电源也是3.3V; 1.2、参考电压 VREF和VREF-并不一定引出,取决于封装,如果没有引出则VREF连接到…...

Vue编程式路由导航
目录 一、使用 一、使用 不使用<router-link>标签,利用$router中的api实现跳转,更灵活 <template><div><ul><li v-for"m in messageList" :key"m.id"><!-- 跳转路由并携带params参数,…...

LVS-DR模式
目录 1、概述 2、LVS-DR模式的工作原理: 3、在LVS-DR模式下,数据包的流向分析如下: 4、LVS-DR是一种用于构建高可用性负载均衡集群的技术模式。LVS-DR模式具有以下特点: 5、LVS-DR中的ARP问题 6、配置LVS-DR需要以下几个关键…...
 的原理和基于Pytorch源码的实现)
详细介绍生成对抗网络 (GAN) 的原理和基于Pytorch源码的实现
介绍 GAN 是一种使用 CNN(卷积神经网络)等深度学习方法进行生成建模的方法。生成建模是一种无监督学习方法,涉及自动发现和学习输入数据中的模式,以便该模型可用于从原始数据集中生成新示例。 GAN 是一种通过将问题构建为具有两个子模型的监督学习问题来训练生成模型的方…...

高性能数据处理选型
1、Redis(高性能) 2、Elasticsearch/HBase( 大数据 ) 3、MongoDB(海量数据)...

【深入理解C语言】-- 关键字2
🐇 🔥博客主页: 云曦 📋系列专栏:深入理解C语言 💨吾生也有涯,而知也无涯 💛 感谢大家👍点赞 😋关注📝评论 文章目录 前言一、关键字 - static&…...
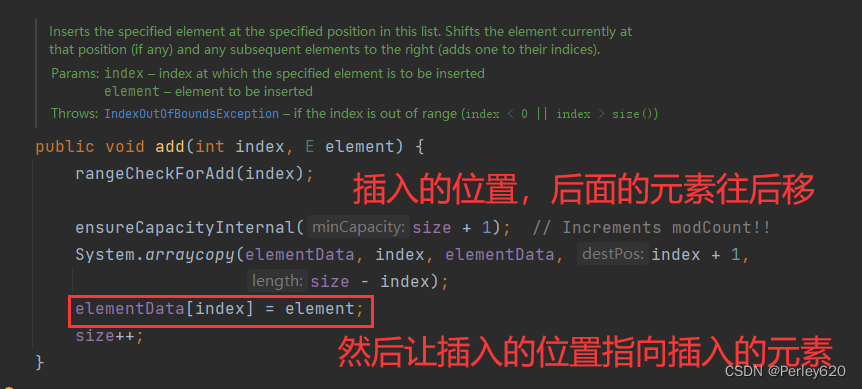
Java进阶(3)——手动实现ArrayList 源码的初步理解分析 数组插入数据和删除数据的问题
目录 引出手动实现ArrayList定义接口MyList<T>写ArrayList的实现类增加元素删除元素 写测试类进行测试数组插入数据? 总结 引出 1.ArrayList的结构分析,可迭代接口,是List的实现; 2.数组增加元素和删除元素的分析,何时扩容…...

若依前端npm run dev启动时报错
本文主要解决问题:若依前端npm run dev启动时报错,解决办法。 目录 1、第1种解决方案(亲测有效) 2、第2种解决方案(亲测有效) Error: error:0308010C:digital envelope routines::unsupportedat new Hash (node:internal/crypto/hash:67:19)at Object.createHash (node…...
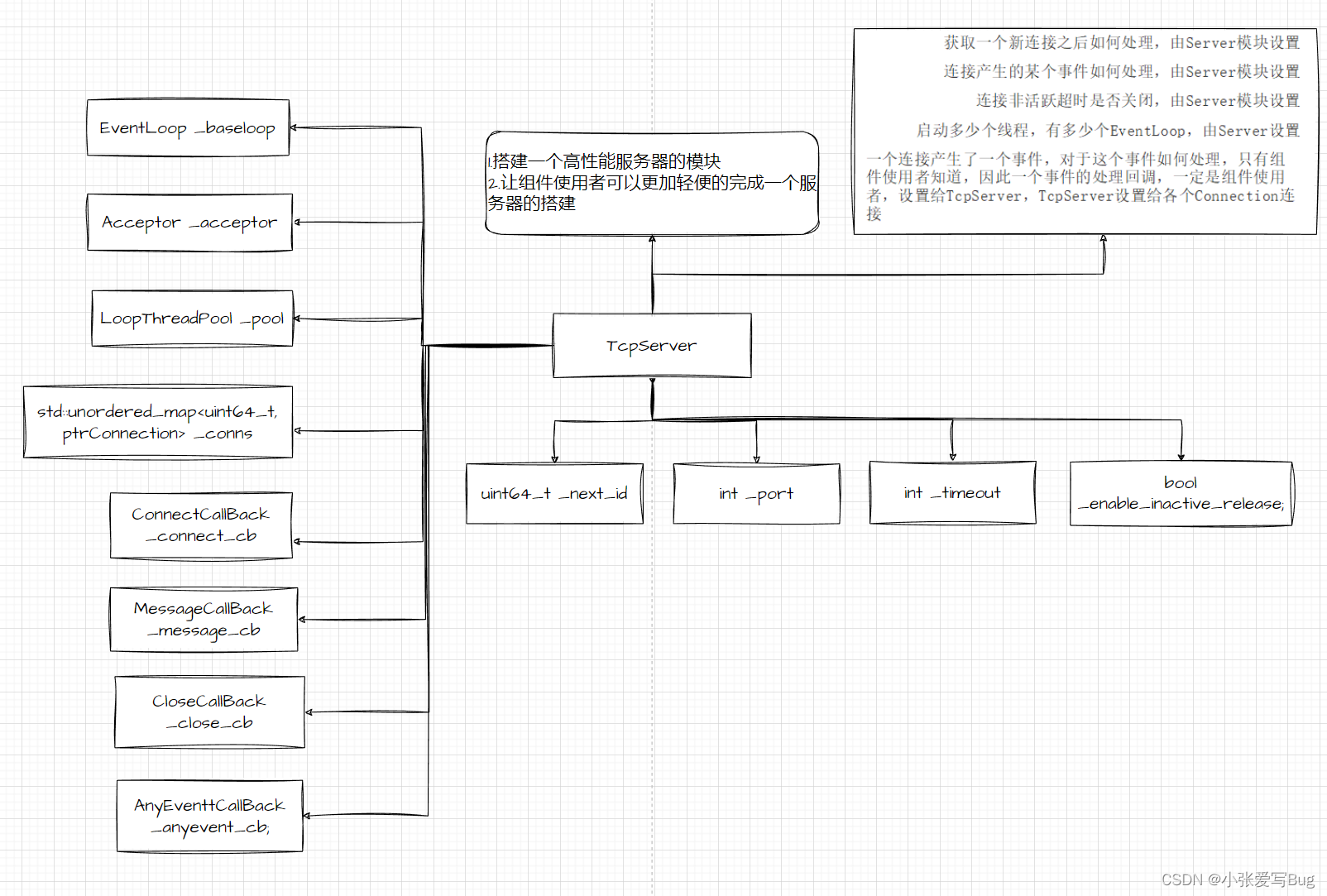
实战项目:基于主从Reactor模型实现高并发服务器
项目完整代码仿mudou库one thread one loop式并发服务器实现: 仿muduo库One Thread One Loop式主从Reactor模型实现⾼并发服务器:通过模拟实现的⾼并发服务器组件,可以简洁快速的完成⼀个⾼性能的服务器搭建。并且,通过组件内提供的不同应⽤层…...

iTOP-RK3568开发板ubuntu环境下安装Eclipse
eclipse 是使用 Java 语言开发的,一个 Java 应用程序,这意味着 eclipse 只能运行在 Java虚拟机上。倘若没有安装 JDK(Java Development Kit),即使在 ubuntu 上安装了 eclipse,也不能运行,所以要…...

大气热力学
大气稳定度 大气稳定度又称为大气层结稳定度(贺德馨,2006)。大气层结指的是大气温度和湿度在垂直方向上的分布,对大气中污染物的扩散起着重要的作用。在静止大气中,假定气团受到垂直方向的扰动后,有一个向上的微小位移,如果大气层…...

【RabbitMQ】消息队列-RabbitMQ篇章
文章目录 1、RabbitMQ是什么2、Dokcer安装RabbitMQ2.1安装Dokcer2.2安装rabbitmq 3、RabbitMQ入门案例 - Simple 简单模式4、RabbitMQ的核心组成部分4.1 RabbitMQ整体架构4.2RabbitMQ的运行流程 5、RabbitMQ的模式5.1 发布订阅模式--fanout 1、RabbitMQ是什么 RabbitMQ是一个开…...
W5100S-EVB-PICO 做UDP Server进行数据回环测试(七)
前言 前面我们用W5100S-EVB-PICO 开发板在TCP Client和TCP Server模式下,分别进行数据回环测试,本章我们将用开发板在UDP Server模式下进行数据回环测试。 UDP是什么?什么是UDP Server?能干什么? UDP (User Dataqram …...

Redis如何处理内存溢出的情况?
当Redis的内存使用达到上限时,会出现内存溢出的情况。Redis提供了几种处理内存溢出的机制: 内存淘汰策略:Redis提供了多种内存淘汰策略,用于在内存不足时选择要移除的键。常见的淘汰策略包括: LRU(Least Re…...

深入解析Arm Cortex-A53 Cache架构:从原理到多核一致性与性能优化实践
1. 项目概述:为什么我们需要深入理解A53的Cache?在嵌入式系统和移动计算领域,Arm Cortex-A53处理器是一个绕不开的名字。作为Armv8-A架构下的“小核”常青树,它以其出色的能效比,广泛存在于从智能手表到智能电视&#…...

2026年青岛GEO优化排名前五,你选对了吗?
行业痛点分析随着AI大模型成为企业获客与品牌传播的核心入口,GEO(生成式引擎优化)已成为抢占AI流量红利的必争之地。然而,当前青岛企业在GEO优化领域面临三大核心挑战:地域匹配精准度低,测试显示65%本地企业…...

寒战1994电影完整版免费看,网盘在线观看完整版
寒战1994电影完整版免费看,转存到自己网盘后,可以网盘在线观看完整版链接:https://pan.baidu.com/s/1U7-U0Csp2BCc9NYXEHuQZw 提取码:8888操作方法:复制链接,打开百度网盘,便会自动跳转,转存到自己网盘就…...

实在Agent实战录:解决委外加工成本核算不准,实现项目利润精准统计的架构演进路径
摘要: 步入2026年,离散制造与复杂供应链体系下的“委外加工”已成为企业调节产能的核心手段,但随之而来的“成本黑盒”与“利润虚标”依然是首席财务官(CFO)与首席信息官(CIO)的头号难题。本文由…...

为什么你的Perplexity搜不出科学健身计划?NIST认证信息检索模型原理首度公开
更多请点击: https://intelliparadigm.com 第一章:为什么你的Perplexity搜不出科学健身计划? Perplexity 作为一款以“实时网络检索大模型推理”为特色的AI搜索工具,其底层机制决定了它并非专为结构化健康决策而优化。当你输入“…...

Skill 不是 Prompt 模板,而是 Code Agent 的领域知识接口
很多人第一次把 Code Agent 接进老项目,都会经历一个落差: Demo 里它能十分钟写完一个 CRUD;一进真实业务系统,它开始犯一些“刚入职新人”才会犯的错。 它能看懂 Controller,却不知道这个字段为什么不能改ÿ…...

AArch64虚拟内存系统架构与硬件自动更新机制详解
1. AArch64虚拟内存系统架构概述AArch64是ARMv8及ARMv9架构的64位执行状态,其虚拟内存系统架构(Virtual Memory System Architecture)是现代ARM处理器的核心组成部分。这套系统通过多级页表机制实现虚拟地址到物理地址的转换,为操…...
)
【独家逆向分析】:Perplexity招聘页埋点数据如何被提取?附Python自动化脚本(限24小时领取)
更多请点击: https://kaifayun.com 第一章:Perplexity薪资数据查询 Perplexity 作为一家以 AI 原生搜索和研究工具著称的科技公司,其薪酬结构长期未公开披露,但可通过多源交叉验证方式获取合理估算。目前主流可信渠道包括 Levels…...

不只是F5隐写:一次CTF解题,带你深入理解ZIP伪加密的底层原理与手动修复
深入解析ZIP伪加密:从CTF实战到二进制手动修复 在CTF竞赛中,ZIP伪加密一直是Misc类题目的经典考点。不同于常规的加密破解,伪加密巧妙地利用了ZIP文件格式的设计特性,在不实际加密数据的情况下制造出需要密码的假象。本文将带您深…...

基于SUMO与PPO的智能换道决策实战:从环境构建到模型部署
1. 环境准备与基础配置 在开始构建智能换道决策系统之前,我们需要先搭建好开发环境。这里我推荐使用Anaconda来管理Python环境,它能很好地解决不同项目之间的依赖冲突问题。我习惯为每个项目创建独立的环境,比如这次我们可以命名为"sumo…...