深度学习入门-3-计算机视觉-图像分类
1.概述
图像分类是根据图像的语义信息对不同类别图像进行区分,是计算机视觉的核心,是物体检测、图像分割、物体跟踪、行为分析、人脸识别等其他高层次视觉任务的基础。图像分类在许多领域都有着广泛的应用,如:安防领域的人脸识别和智能视频分析等,交通领域的交通场景识别,互联网领域基于内容的图像检索和相册自动归类,医学领域的图像识别等。
这里对图像分类领域的经典卷积神经网络进行剖析,介绍如何应用这些基础模块构建卷积神经网络,解决图像分类问题。按照被提出的时间顺序,涵盖如下卷积神经网络:
-
LeNet:Yan LeCun等人于1998年第一次将卷积神经网络应用到图像分类任务上[1],在手写数字识别任务上取得了巨大成功。
-
AlexNet:Alex Krizhevsky等人在2012年提出了AlexNet[2], 并应用在大尺寸图片数据集ImageNet上,获得了2012年ImageNet比赛冠军(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)。
-
VGG:Simonyan和Zisserman于2014年提出了VGG网络结构[3],是当前最流行的卷积神经网络之一,由于其结构简单、应用性极强而深受广大研究者欢迎。
-
GoogLeNet:Christian Szegedy等人在2014提出了GoogLeNet[4],并取得了2014年ImageNet比赛冠军。
-
ResNet:Kaiming He等人在2015年提出了ResNet[5],通过引入残差模块加深网络层数,在ImagNet数据集上的错误率降低到3.6%,超越了人眼识别水平。ResNet的设计思想深刻地影响了后来的深度神经网络的设计。
图像分类处理基本流程,先使用卷积神经网络提取图像特征,然后再用这些特征预测分类概率,根据训练样本标签建立起分类损失函数,开启端到端的训练,如下图所示。

2.LeNet卷积神经网络
LeNet是最早的卷积神经网络之一。1998年,Yann LeCun第一次将LeNet卷积神经网络应用到图像分类上,在手写数字识别任务中取得了巨大成功。LeNet通过连续使用卷积和池化层的组合提取图像特征,其架构如图1所示,这里展示的是用于MNIST手写体数字识别任务中的LeNet-5模型:

- 第一模块:包含5×5的6通道卷积和2×2的池化。卷积提取图像中包含的特征模式(激活函数使用Sigmoid),图像尺寸从28减小到24。经过池化层可以降低输出特征图对空间位置的敏感性,图像尺寸减到12。
- 第二模块:和第一模块尺寸相同,通道数由6增加为16。卷积操作使图像尺寸减小到8,经过池化后变成4。
- 第三模块:包含4×4的120通道卷积。卷积之后的图像尺寸减小到1,但是通道数增加为120。将经过第3次卷积提取到的特征图输入到全连接层。第一个全连接层的输出神经元的个数是64,第二个全连接层的输出神经元个数是分类标签的类别数,对于手写数字识别的类别数是10。然后使用Softmax激活函数即可计算出每个类别的预测概率。
卷积层的输出特征图如何当作全连接层的输入使用呢?
卷积层的输出数据格式是[N,C,H,W],在输入全连接层的时候,会自动将数据拉平,也就是对每个样本,自动将其转化为长度为K的向量,其中K=C×H×W,一个mini-batch的数据维度变成了N×K的二维向量。
3.AlexNet卷积神经网络
自从1998年LeNet问世以来,接下来十几年的时间里,神经网络并没有在计算机视觉领域取得很好的结果,反而一度被其它算法所超越。原因主要有两方面,一是神经网络的计算比较复杂,对当时计算机的算力来说,训练神经网络是件非常耗时的事情;另一方面,当时还没有专门针对神经网络做算法和训练技巧的优化,神经网络的收敛是件非常困难的事情。
随着技术的进步和发展,计算机的算力越来越强大,尤其是在GPU并行计算能力的推动下,复杂神经网络的计算也变得更加容易实施。另一方面,互联网上涌现出越来越多的数据,极大的丰富了数据库。同时也有越来越多的研究人员开始专门针对神经网络做算法和模型的优化,Alex Krizhevsky等人提出的AlexNet以很大优势获得了2012年ImageNet比赛的冠军。
AlexNet与LeNet相比,具有更深的网络结构,包含5层卷积和3层全连接,同时使用了如下三种方法改进模型的训练过程:
-
数据增广:深度学习中常用的一种处理方式,通过对训练随机加一些变化,比如平移、缩放、裁剪、旋转、翻转或者增减亮度等,产生一系列跟原始图片相似但又不完全相同的样本,从而扩大训练数据集。通过这种方式,可以随机改变训练样本,避免模型过度依赖于某些属性,能从一定程度上抑制过拟合。
-
使用Dropout抑制过拟合。
-
使用ReLU激活函数减少梯度消失现象。
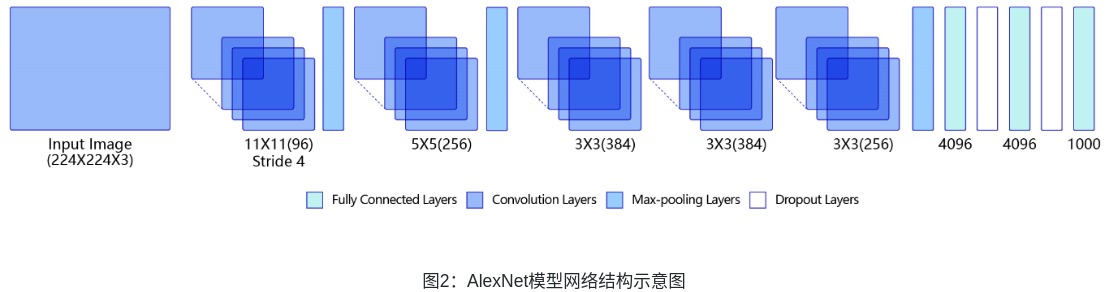
4.VGG卷积神经网络
VGG是当前最流行的CNN模型之一,2014年由Simonyan和Zisserman提出,其命名来源于论文作者所在的实验室Visual Geometry Group。AlexNet模型通过构造多层网络,取得了较好的效果,但是并没有给出深度神经网络设计的方向。VGG通过使用一系列大小为3x3的小尺寸卷积核和池化层构造深度卷积神经网络,并取得了较好的效果。VGG模型因为结构简单、应用性极强而广受研究者欢迎,尤其是它的网络结构设计方法,为构建深度神经网络提供了方向。
图3是VGG-16的网络结构示意图,有13层卷积和3层全连接层。VGG网络的设计严格使用3×3的卷积层和池化层来提取特征,并在网络的最后面使用三层全连接层,将最后一层全连接层的输出作为分类的预测。 在VGG中每层卷积将使用ReLU作为激活函数,在全连接层之后添加dropout来抑制过拟合。使用小的卷积核能够有效地减少参数的个数,使得训练和测试变得更加有效。比如使用两层3×3卷积层,可以得到感受野为5的特征图,而比使用5×5的卷积层需要更少的参数。由于卷积核比较小,可以堆叠更多的卷积层,加深网络的深度,这对于图像分类任务来说是有利的。VGG模型的成功证明了增加网络的深度,可以更好的学习图像中的特征模式。

5.GoogLeNet卷积神经网络
GoogLeNet是2014年ImageNet比赛的冠军,它的主要特点是网络不仅有深度,还在横向上具有“宽度”。由于图像信息在空间尺寸上的巨大差异,如何选择合适的卷积核来提取特征就显得比较困难了。空间分布范围更广的图像信息适合用较大的卷积核来提取其特征;而空间分布范围较小的图像信息则适合用较小的卷积核来提取其特征。为了解决这个问题,GoogLeNet提出了一种被称为Inception模块的方案,如图4所示。
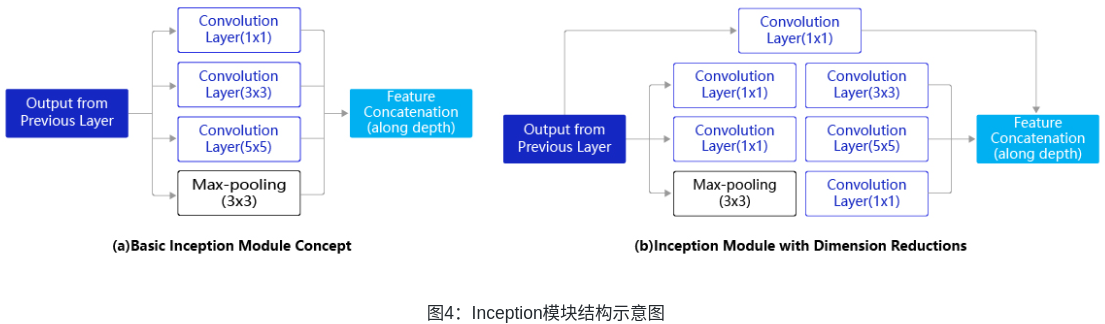
图4(a)是Inception模块的设计思想,使用3个不同大小的卷积核对输入图片进行卷积操作,并附加最大池化,将这4个操作的输出沿着通道这一维度进行拼接,构成的输出特征图将会包含经过不同大小的卷积核提取出来的特征,从而达到捕捉不同尺度信息的效果。Inception模块采用多通路(multi-path)的设计形式,每个支路使用不同大小的卷积核,最终输出特征图的通道数是每个支路输出通道数的总和,这将会导致输出通道数变得很大,尤其是使用多个Inception模块串联操作的时候,模型参数量会变得非常大。为了减小参数量,Inception模块使用了图(b)中的设计方式,在每个3x3和5x5的卷积层之前,增加1x1的卷积层来控制输出通道数;在最大池化层后面增加1x1卷积层减小输出通道数。基于这一设计思想,形成了上图(b)中所示的结构。
GoogLeNet的架构如图5所示,在主体卷积部分中使用5个模块(block),每个模块之间使用步幅为2的3 ×3最大池化层来减小输出高宽。
- 第一模块使用一个64通道的7 × 7卷积层。
- 第二模块使用2个卷积层:首先是64通道的1 × 1卷积层,然后是将通道增大3倍的3 × 3卷积层。
- 第三模块串联2个完整的Inception块。
- 第四模块串联了5个Inception块。
- 第五模块串联了2 个Inception块。
- 第五模块的后面紧跟输出层,使用全局平均池化层来将每个通道的高和宽变成1,最后接上一个输出个数为标签类别数的全连接层。
说明: 在原作者的论文中添加了图中所示的softmax1和softmax2两个辅助分类器,如下图所示,训练时将三个分类器的损失函数进行加权求和,以缓解梯度消失现象。这里的程序作了简化,没有加入辅助分类器。

图5:GoogLeNet模型网络结构示意图
6.ResNet卷积神经网络
ResNet是2015年ImageNet比赛的冠军,将识别错误率降低到了3.6%,这个结果甚至超出了正常人眼识别的精度。
通过前面几个经典模型学习,我们可以发现随着深度学习的不断发展,模型的层数越来越多,网络结构也越来越复杂。那么是否加深网络结构,就一定会得到更好的效果呢?从理论上来说,假设新增加的层都是恒等映射,只要原有的层学出跟原模型一样的参数,那么深模型结构就能达到原模型结构的效果。换句话说,原模型的解只是新模型的解的子空间,在新模型解的空间里应该能找到比原模型解对应的子空间更好的结果。但是实践表明,增加网络的层数之后,训练误差往往不降反升。
Kaiming He等人提出了残差网络ResNet来解决上述问题,其基本思想如图6所示。
- 图6(a):表示增加网络的时候,将x映射成y = F(x)输出。
- 图6(b):对图6(a)作了改进,输出y = F(x)+x。这时不是直接学习输出特征 y 的表示,而是学习y−x。
- 如果想学习出原模型的表示,只需将F(x)的参数全部设置为0,则y=x是恒等映射。
- F(x)=y−x也叫做残差项,如果x→y的映射接近恒等映射,图6(b)中通过学习残差项也比图6(a)学习完整映射形式更加容易。
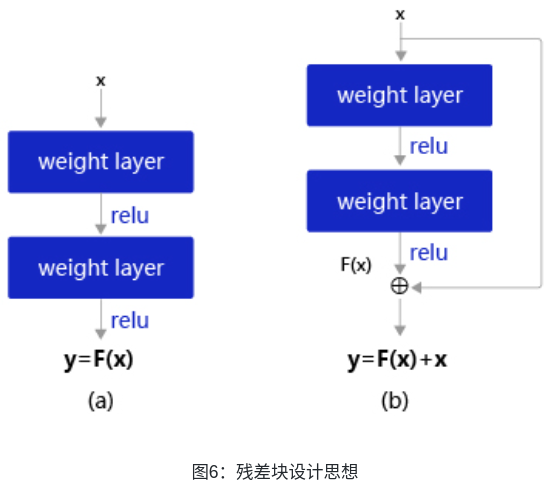
图6(b)的结构是残差网络的基础,这种结构也叫做残差块(Residual block)。输入x通过跨层连接,能更快的向前传播数据,或者向后传播梯度。
通俗的比喻,如“传声筒”的游戏。我们常常会发现刚开始的嘉宾往往表演出最多的信息(类似于Loss),而随着表演的传递,有效的表演信息越来越少(类似于梯度弥散)。类似的,由于ResNet每层都存在直连的旁路,相当于每一层都和最终的损失有“直接对话”的机会,自然可以更好的解决梯度弥散的问题。
残差块的具体设计方案如图7所示,这种设计方案也常称作瓶颈结构(BottleNeck)。1*1的卷积核可以非常方便的调整中间层的通道数,在进入3*3的卷积层之前减少通道数(256->64),经过该卷积层后再恢复通道数(64->256),可以显著减少网络的参数量。这个结构(256->64->256)像一个中间细,两头粗的瓶颈,所以被称为“BottleNeck”。
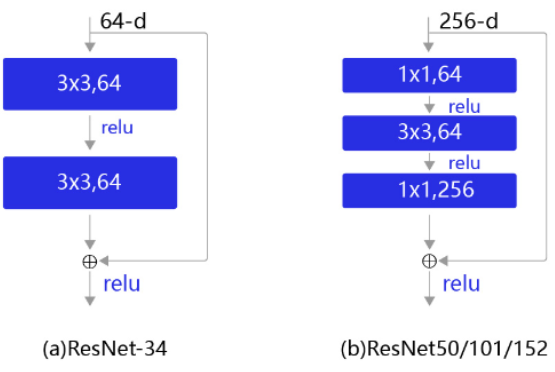
图7:残差块结构示意图
下图表示出了ResNet-50的结构,一共包含49层卷积和1层全连接,所以被称为ResNet-50。

相关文章:
深度学习入门-3-计算机视觉-图像分类
1.概述 图像分类是根据图像的语义信息对不同类别图像进行区分,是计算机视觉的核心,是物体检测、图像分割、物体跟踪、行为分析、人脸识别等其他高层次视觉任务的基础。图像分类在许多领域都有着广泛的应用,如:安防领域的人脸识别…...

shopee运营新手入门教程!Shopee运营技巧!
随着跨境电商行业的蓬勃发展,越来越多的人开始关注Shopee这个平台。短视频等渠道也成为了人们了解Shopee的途径。因此,对于许多新手来说,在Shopee上开店成为了一种吸引人的选择。为了帮助这些新手更好地入门,下面将介绍一下Shop…...

Python Web框架:Django、Flask和FastAPI巅峰对决
今天,我们将深入探讨Python Web框架的三巨头:Django、Flask和FastAPI。无论你是Python小白还是老司机,本文都会为你解惑,带你领略这三者的魅力。废话不多说,让我们开始这场终极对比! Django:百…...

机器学习线性代数基础
本文是斯坦福大学CS 229机器学习课程的基础材料,原始文件下载 原文作者:Zico Kolter,修改:Chuong Do, Tengyu Ma 翻译:黄海广 备注:请关注github的更新,线性代数和概率论已经更新完毕…...
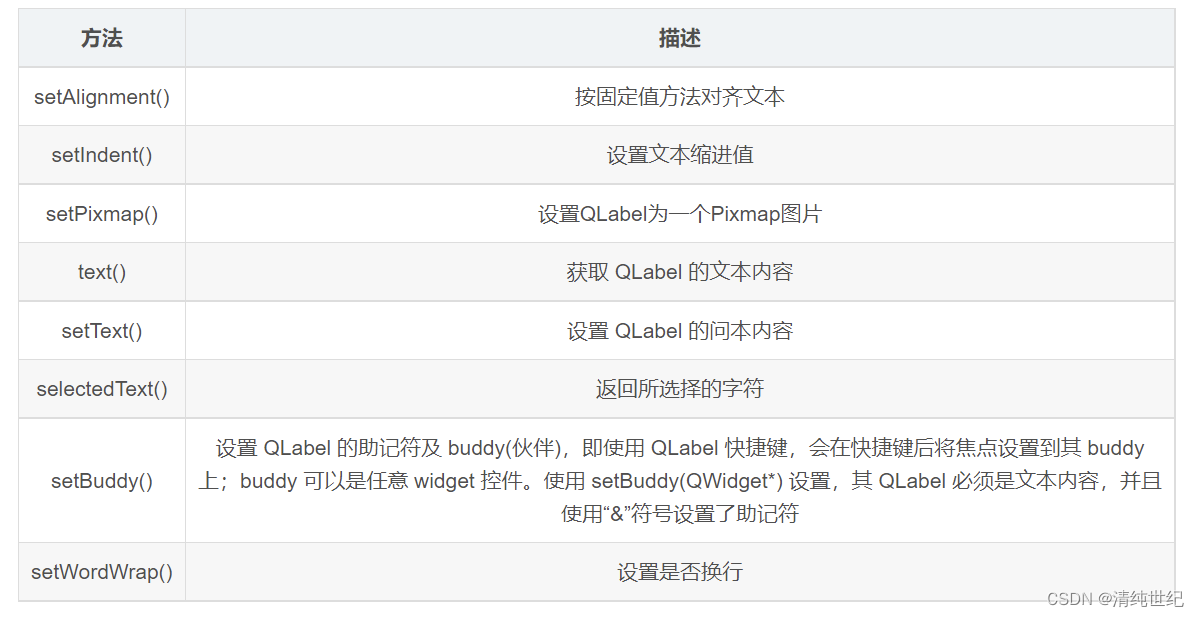
PyQt5组件之QLabel显示图像和视频
目录 一、显示图像和视频 1、显示图像 2、显示视频 二、QtDesigner 窗口简单介绍 三、相关函数 1、打开本地图片 2、保存图片到本地 3、打开文件夹 4、打开本地文本文件并显示 5、保存文本到本地 6、关联函数 7、图片 “.png” | “.jpn” Label 自适应显示 8、Q…...
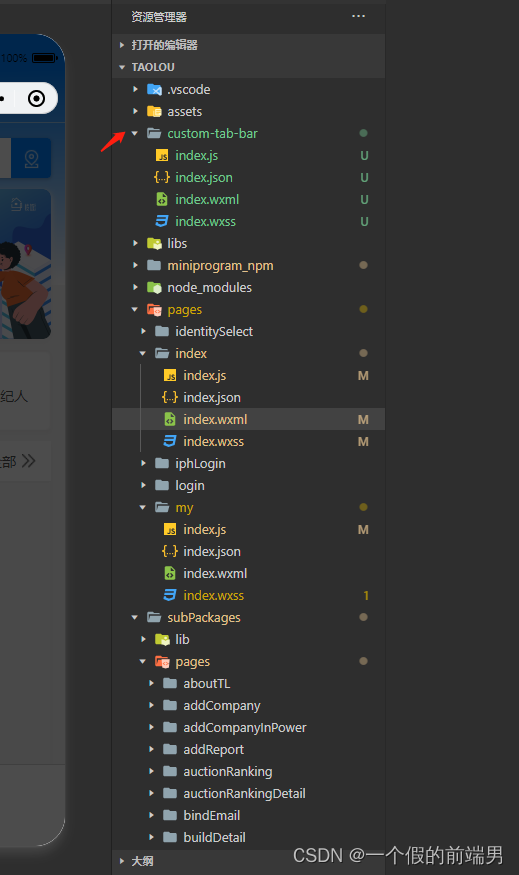
微信程序 自定义遮罩层遮不住底部tabbar解决
一、先上效果 二 方法 1、自定义底部tabbar 实现: https://developers.weixin.qq.com/miniprogram/dev/framework/ability/custom-tabbar.html 官网去抄 简单写下:在代码根目录下添加入口文件 除了js 文件的list 需要调整 其他原封不动 代码…...

Python简易部署方法
一.安装Python解释器和vscode或者其他开发工具 下载地址: 1.下载vscode 链接: https://code.visualstudio.com/. 2.下载python解释器 链接: https://www.python.org/downloads/. 二.安装包 打开cmd,输入命令:pip install 包名 三.配置…...
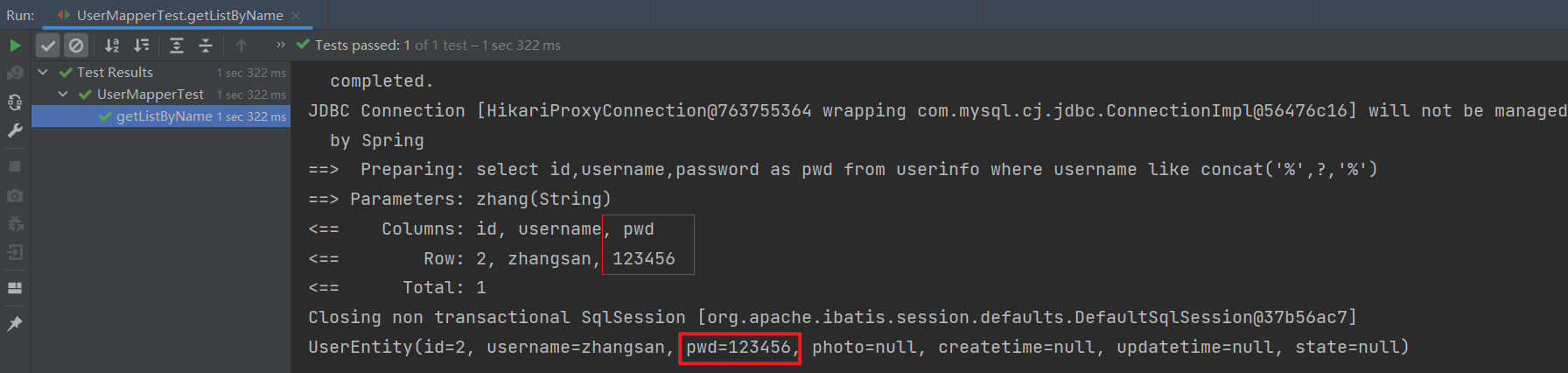
Spring Boot单元测试与Mybatis单表增删改查
目录 1. Spring Boot单元测试 1.1 什么是单元测试? 1.2 单元测试有哪些好处? 1.3 Spring Boot 单元测试使用 单元测试的实现步骤 1. 生成单元测试类 2. 添加单元测试代码 简单的断言说明 2. Mybatis 单表增删改查 2.1 单表查询 2.2 参数占位符 ${} 和 #{} ${} 和 …...

机器学习样本数据划分的典型Python方法
机器学习样本数据划分的典型Python方法 DateAuthorVersionNote2023.08.16Dog TaoV1.0完成文档撰写。 文章目录 机器学习样本数据划分的典型Python方法样本数据的分类Training DataValidation DataTest Data numpy.ndarray类型数据直接划分交叉验证基于KFold基于RepeatedKFold基…...

重建与突破,探讨全链游戏的现在与未来
全链游戏(On-Chain Game)是指将游戏内资产通过虚拟货币或 NFT 形式记录上链的游戏类型。除此以外,游戏的状态存储、计算与执行等皆被部署在链上,目的是为用户打造沉浸式、全方位的游戏体验,超越传统游戏玩家被动控制的…...
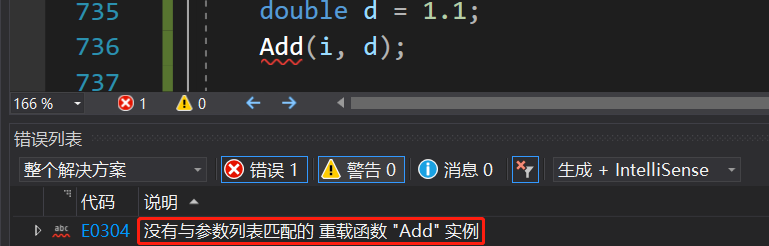
[C++] 模板template
目录 1、函数模板 1.1 函数模板概念 1.2 函数模板格式 1.3 函数模板的原理 1.4 函数模板的实例化 1.4.1 隐式实例化 1.4.2 显式实例化 1.5 模板参数的匹配原则 2、类模板 2.1 类模板的定义格式 2.2 类模板的实例化 讲模板之前呢,我们先来谈谈泛型编程&am…...
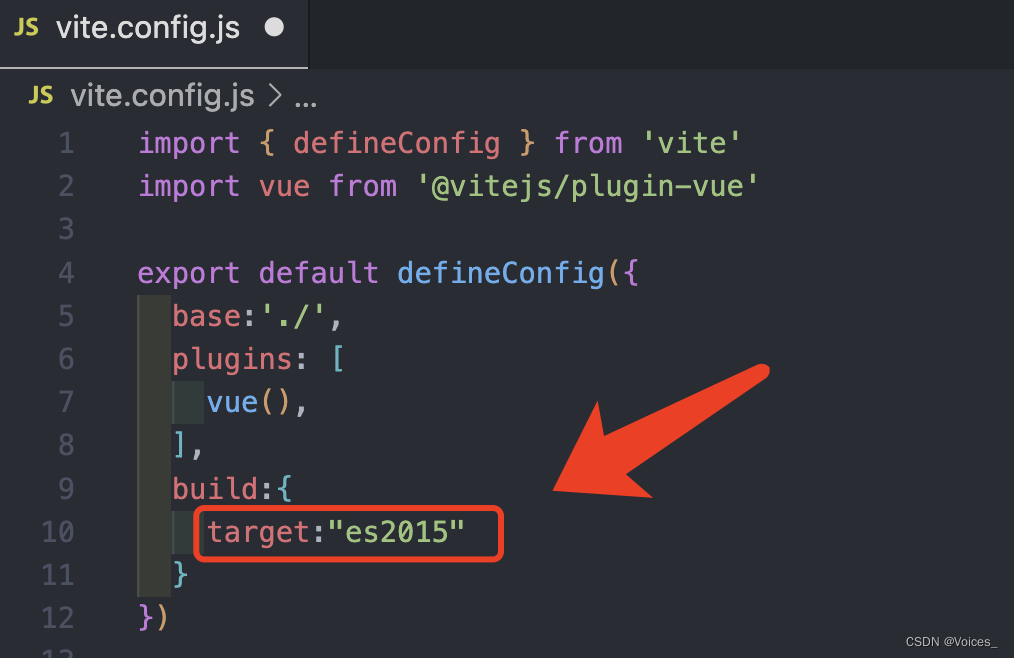
[vite] 项目打包后页面空白,配置了base后也不生效
记录下解决问题的过程和思路 首先打开看打包后的 dist/index.html 文件,和页面上的报错 这里就发现了第一个问题 报错的意思是 index.html中引用的 css文件 和 js文件 找不到 为了解决这个问题,在vite.config.js配置中,增加一项 base:./ …...

springboot整合kafka-笔记
springboot整合kafka-笔记 配置pom.xml 这里我的springboot版本是2.3.8.RELEASE,使用的kafka-mq的版本是2.12 <dependencyManagement><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>s…...

Rust软件外包开发语言的特点
Rust 是一种系统级编程语言,强调性能、安全性和并发性的编程语言,适用于广泛的应用领域,特别是那些需要高度可靠性和高性能的场景。下面和大家分享 Rust 语言的一些主要特点以及适用的场合,希望对大家有所帮助。北京木奇移动技术有…...
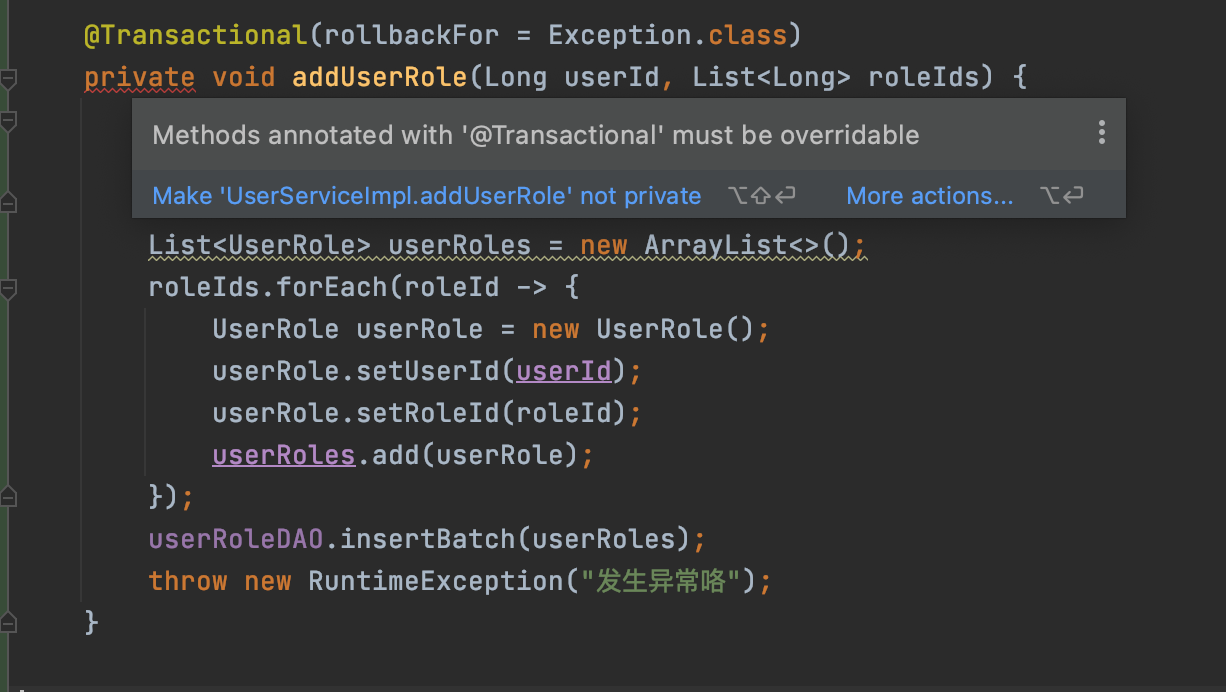
Spring Boot业务代码中使用@Transactional事务失效踩坑点总结
1.概述 接着之前我们对Spring AOP以及基于AOP实现事务控制的上文,今天我们来看看平时在项目业务开发中使用声明式事务Transactional的失效场景,并分析其失效原因,从而帮助开发人员尽量避免踩坑。 我们知道 Spring 声明式事务功能提供了极其…...
知识体系总结(九)设计原则、设计模式、分布式、高性能、高可用
文章目录 架构设计为什么要进行技术框架的设计 六大设计原则一、单一职责原则二、开闭原则三、依赖倒置原则四、接口分离原则五、迪米特法则(又称最小知道原则)六、里氏替换原则案例诠释 常见设计模式构造型单例模式工厂模式简单工厂工厂方法 生成器模式…...
Springboot 集成Beetl模板
一、在启动类下的pom.xml中导入依赖: <!--beetl模板引擎--><dependency><groupId>com.ibeetl</groupId><artifactId>beetl</artifactId><version>2.9.8</version></dependency> 二、 配置 beetl需要的Beetl…...

RabbitMQ查询队列使用情况和消费者详情实现
spring-boot-starter-amqp spring-boot-starter-amqp是Spring Boot框架中与AMQP(高级消息队列协议)相关的自动配置启动器。它提供了使用AMQP进行消息传递和异步通信的功能。 以下是spring-boot-starter-amqp的主要特性和功能: 自动配置:spring-boot-starter-amqp通过自动…...
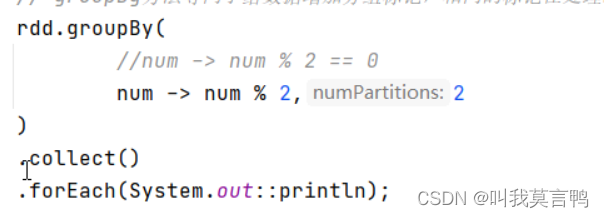
Spark第二课RDD的详解
1.前言 RDD JAVA中的IO 1.小知识点穿插 1. 装饰者设计模式 装饰者设计模式:本身功能不变,扩展功能. 举例: 数据流的读取 一层一层的包装,进而将功能进行进一步的扩展 2.sleep和wait的区别 本质区别是字体不一样,sleep斜体,wait正常 斜体是静态方法…...
人工智能学习框架—飞桨Paddle人工智能
1.人工智能框架 机器学习的三要素:模型、学习策略、优化算法。 当我们用机器学习来解决一些模式识别任务时,一般的流程包含以下几个步骤: 1.1.浅层学习和深度学习 浅层学习(Shallow Learning):不涉及特征学习,其特征…...

从零到告警:用Prometheus+SNMP监控华为交换机,并配置Grafana看板与告警规则
从零构建华为交换机智能监控体系:PrometheusSNMP实战指南 当机房里的华为交换机突然宕机时,运维团队往往要面对业务部门的连环追问。传统的人工巡检方式就像用体温计量火山喷发——既滞后又无力。本文将手把手带您搭建从数据采集到告警响应的完整监控闭环…...
)
手把手教你搭建低成本雷达测试环境:从暗室搭建到模拟器参数设置(基于国产设备实战)
低成本雷达测试环境搭建实战:国产设备方案与操作指南 在车载毫米波雷达研发领域,测试环节往往占据着项目预算的显著部分。传统方案依赖进口设备和专业暗室,动辄数百万元的投入让许多中小型团队望而却步。本文将揭示一个行业内的真实情况&…...

AI Agent Harness Engineering 与组织结构重塑:未来公司将变成什么样
AI Agent Harness Engineering 与组织结构重塑:未来公司将变成什么样 摘要/引言 你有没有在深夜刷到过这样的“科技黑话式”创业视频?创始人拍着桌子喊:“我们公司90%的活都是AI干的!产品上线从3个月缩短到3天!利润率翻了10倍!”旁边的工位要么是空的,要么坐着手忙脚乱…...

别再只盯着p值和FC了!用DisGeNET给你的Hub Gene打分,提升下游验证成功率
别再只盯着p值和FC了!用DisGeNET给你的Hub Gene打分,提升下游验证成功率 在基因功能研究的海洋中,Hub Gene如同灯塔般指引着研究方向。然而,许多研究者仍被困在传统筛选方法的局限中——过度依赖差异表达基因的p值和fold change阈…...

如何用Element React构建企业级React应用:完整组件库实战指南
如何用Element React构建企业级React应用:完整组件库实战指南 【免费下载链接】element-react Element UI 项目地址: https://gitcode.com/gh_mirrors/el/element-react Element React作为一套基于React框架的企业级UI组件库,为开发者提供了50余种…...

LATENCY和INITIATION_INTERVAL同时约束时HLS决策
一、关于Latency和II同时约束 1.对同一个设计的II和latency同时约束,这两者在很多情况下是存在冲突的。 2.对同一个函数或者循环,使用HLS调度器来优化,HLS调度器内置设置了一些优先级的规则, 这种规则大多情况和设计者的直觉不一样…...

Perplexity实时新闻查询效率翻倍:从API调用到结果过滤的7个隐藏技巧
更多请点击: https://codechina.net 第一章:Perplexity实时新闻查询效率翻倍:从API调用到结果过滤的7个隐藏技巧 Perplexity 的实时新闻 API(如 /search/news 端点)在默认配置下常因冗余字段、未压缩响应和同步阻塞而…...
)
昇腾310开发板内存告急?手把手教你在Ubuntu虚拟机上离线转换YOLOv5模型(非root用户避坑指南)
昇腾310开发板内存告急?Ubuntu虚拟机离线转换YOLOv5模型全攻略 当开发者手头只有一块内存有限的昇腾310开发板时,模型转换工作往往会遇到硬件资源不足的困境。本文将详细介绍如何在普通x86架构的Ubuntu虚拟机上,完成YOLOv5模型的离线转换全流…...

如何用韭菜盒子打造你的VSCode投资信息中心:5大实用功能深度体验
如何用韭菜盒子打造你的VSCode投资信息中心:5大实用功能深度体验 【免费下载链接】leek-fund :chart_with_upwards_trend: 韭菜盒子VSCode插件,可以看股票、基金、期货等实时数据。 LeekFund turns your VS Code and Cursor into a real-time stock, fun…...
)
Perplexity教育信息检索效率提升70%:从零到精通的4步优化法(附实测数据)
更多请点击: https://kaifayun.com 第一章:Perplexity教育信息检索效率提升70%:从零到精通的4步优化法(附实测数据) Perplexity 作为面向研究与教育场景的AI原生搜索引擎,其语义理解深度与引用溯源能力显著…...