自己动手写数据库系统:实现一个小型SQL解释器(中)
我们接上节内容继续完成SQL解释器的代码解析工作。下面我们实现对update语句的解析,其语法如下:
UpdateCmd -> INSERT | DELETE | MODIFY | CREATE
Create -> CreateTable | CreateView | CreateIndex
Insert -> INSERT INTO ID LEFT_PARAS FieldList RIGHT_PARAS VALUES LEFT_PARS ConstList RIGHT_PARAS
FieldList -> Field ( COMMA FieldList)?
ConstList -> Constant ( COMMA ConstList)?
Delete -> DELETE FROM ID [WHERE Predicate)?
Modify -> UPDATE ID SET Field ASSIGN_OPERATOR Expression (WHERE Predicate)?
CreateTable -> CREATE TABLE ID (FieldDefs)?
FieldDefs -> FieldDef ( COMMA FieldDefs)?
FieldDef -> ID TypeDef
TypeDef -> INT | VARCHAT LEFT_PARAS NUM RIGHT_PARAS
CreateView -> CREATE VIEW ID AS Query
CreateIndex -> CREATE INDEX ID ON ID LEFT_PARAS Field RIGHT_PARAS
我们对上面的语法做一些基本说明:
UpdateCmd -> INSERT | DELETE | MODIFY | CREATE
这句语法表明SQL语言中用于更新表的语句一定由insert, delete, modify , create等几个命令开始。insert 语句由关键字insert开始,然后跟着insert into两个关键字,接着是左括号,跟着是由列名(column)组成的字符串,他们之间由逗号隔开,然后跟着右括号,接着是关键字VALUES,然后是左括号,接着是一系列常量和逗号组成的序列,最后以又括号结尾,其他语法大家可以参照SQL相关命令来理解,下面我们看看代码的实现,继续在parser.go中添加如下代码:
func (p *SQLParser) UpdateCmd() interface{} {tok, err := p.sqlLexer.Scan()if err != nil {panic(err)}if tok.Tag == lexer.INSERT {p.sqlLexer.ReverseScan()return p.Insert()} else if tok.Tag == lexer.DELETE {p.sqlLexer.ReverseScan()return p.Delete()} else if tok.Tag == lexer.UPDATE {p.sqlLexer.ReverseScan()return p.Update()} else {p.sqlLexer.ReverseScan()return p.Create()}
}func (p *SQLParser) Create() interface{} {tok, err := p.sqlLexer.Scan()if err != nil {panic(err)}if tok.Tag != lexer.CREATE {panic("token is not create")}tok, err = p.sqlLexer.Scan()if err != nil {panic(err)}if tok.Tag == lexer.TABLE {return p.CreateTable()} else if tok.Tag == lexer.VIEW {return p.CreateView()} else {return p.CreateIndex()}
}func (p *SQLParser) CreateView() interface{} {return nil
}func (p *SQLParser) CreateIndex() interface{} {return nil
}func (p *SQLParser) CreateTable() interface{} {tok, err := p.sqlLexer.Scan()if err != nil {panic(err)}if tok.Tag != lexer.ID {panic("token should be ID for table name")}tblName := p.sqlLexer.Lexemetok, err = p.sqlLexer.Scan()if err != nil {panic(err)}if tok.Tag != lexer.LEFT_BRACKET {panic("missing left bracket")}sch := p.FieldDefs()tok, err = p.sqlLexer.Scan()if err != nil {panic(err)}if tok.Tag != lexer.RIGHT_BRACKET {panic("missing right bracket")}return NewCreateTableData(tblName, sch)
}func (p *SQLParser) FieldDefs() *record_manager.Schema {schema := p.FieldDef()tok, err := p.sqlLexer.Scan()if err != nil {panic(err)}if tok.Tag == lexer.COMMA {schema2 := p.FieldDefs()schema.AddAll(schema2)} else {p.sqlLexer.ReverseScan()}return schema
}func (p *SQLParser) FieldDef() *record_manager.Schema {_, fldName := p.Field()return p.FieldType(fldName)
}func (p *SQLParser) FieldType(fldName string) *record_manager.Schema {schema := record_manager.NewSchema()tok, err := p.sqlLexer.Scan()if err != nil {panic(err)}if tok.Tag == lexer.INT {schema.AddIntField(fldName)} else if tok.Tag == lexer.VARCHAR {tok, err := p.sqlLexer.Scan()if err != nil {panic(err)}if tok.Tag != lexer.LEFT_BRACKET {panic("missing left bracket")}tok, err = p.sqlLexer.Scan()if err != nil {panic(err)}if tok.Tag != lexer.NUM {panic("it is not a number for varchar")}num := p.sqlLexer.LexemefldLen, err := strconv.Atoi(num)if err != nil {panic(err)}schema.AddStringField(fldName, fldLen)tok, err = p.sqlLexer.Scan()if err != nil {panic(err)}if tok.Tag != lexer.RIGHT_BRACKET {panic("missing right bracket")}}return schema
}
在上面代码中我们需要定义一个CreateTableData结构,因此增加一个create_data.go文件,添加代码如下:
package parserimport ("record_manager"
)type CreateTableData struct {tblName stringsch *record_manager.Schema
}func NewCreateTableData(tblName string, sch *record_manager.Schema) *CreateTableData {return &CreateTableData{tblName: tblName,sch: sch,}
}func (c *CreateTableData) TableName() string {return c.tblName
}func (c *CreateTableData) NewSchema() *record_manager.Schema {return c.sch
}最后我们在main.go中添加代码,调用上面的代码实现:
package main//import (
// bmg "buffer_manager"
// fm "file_manager"
// "fmt"
// lm "log_manager"
// "math/rand"
// mm "metadata_management"
// record_mgr "record_manager"
// "tx"
//)import ("parser"
)func main() {sql := "create table person (PersonID int, LastName varchar(255), FirstName varchar(255)," +"Address varchar(255), City varchar(255) )"sqlParser := parser.NewSQLParser(sql)sqlParser.UpdateCmd()}
在main中,我们定义了一个create table的sql语句,然后调用UpdateCmd接口实现语法解析,大家可以在b站搜索”coding迪斯尼“,查看代码的调试演示视频,由于上面语法解析的逻辑稍微复杂和繁琐,因此通过视频来跟踪代码的单步调试过程才能更简单省力的理解实现逻辑。
下面我们看看insert语句的解析实现,在parser.go中添加代码如下:
func (p *SQLParser) checkWordTag(wordTag lexer.Tag) {tok, err := p.sqlLexer.Scan()if err != nil {panic(err)}if tok.Tag != wordTag {panic("token is not match")}
}func (p *SQLParser) isMatchTag(wordTag lexer.Tag) bool {tok, err := p.sqlLexer.Scan()if err != nil {panic(err)}if tok.Tag == wordTag {return true} else {p.sqlLexer.ReverseScan()return false}
}func (p *SQLParser) fieldList() []string {L := make([]string, 0)_, field := p.Field()L = append(L, field)if p.isMatchTag(lexer.COMMA) {fields := p.fieldList()L = append(L, fields...)}return L
}func (p *SQLParser) constList() []*query.Constant {L := make([]*query.Constant, 0)L = append(L, p.Constant())if p.isMatchTag(lexer.COMMA) {consts := p.constList()L = append(L, consts...)}return L
}func (p *SQLParser) Insert() interface{} {/*根据语法规则:Insert -> INSERT INTO ID LEFT_PARAS FieldList RIGHT_PARAS VALUES LEFT_PARS ConstList RIGHT_PARAS我们首先要匹配四个关键字,分别为insert, into, id, 左括号,然后就是一系列由逗号隔开的field,接着就是右括号,然后是关键字values接着是常量序列,最后以右括号结尾*/p.checkWordTag(lexer.INSERT)p.checkWordTag(lexer.INTO)p.checkWordTag(lexer.ID)tblName := p.sqlLexer.Lexemep.checkWordTag(lexer.LEFT_BRACKET)flds := p.fieldList()p.checkWordTag(lexer.RIGHT_BRACKET)p.checkWordTag(lexer.VALUES)p.checkWordTag(lexer.LEFT_BRACKET)vals := p.constList()p.checkWordTag(lexer.RIGHT_BRACKET)return NewInsertData(tblName, flds, vals)
}我们调用上面代码测试一下解析效果:
func main() {sql := "INSERT INTO Customers (CustomerName, ContactName, Address, City, PostalCode, Country) " +"VALUES (\"Cardinal\", \"Tom B. Erichsen\", \"Skagen 21\", \"Stavanger\", 4006, \"Norway\")"sqlParser := parser.NewSQLParser(sql)sqlParser.UpdateCmd()}
请大家在b站搜索coding迪斯尼,通过视频调试演示的方式能更直白和有效的了解代码逻辑。接下来我们看看 create 命令如何创建 view 和 index 两个对象,首先我们看看 view 的创建,根据 create view 的语法:
CreateView -> CREATE VIEW ID AS QUERY
首先我们要判断语句的前两个 token 是否对应 关键字 CREATE, VIEW,然后接着的token 必须是 ID类型,然后跟着关键字 AS,最后我们调用 QUERY 对应的解析规则来解析后面的字符串,我们看看代码实现,在 parser.go 中添加如下代码:
func (p *SQLParser) CreateView() interface{} {p.checkWordTag(lexer.ID)viewName := p.sqlLexer.Lexemep.checkWordTag(lexer.AS)qd := p.Query()vd := NewViewData(viewName, qd)vdDef := fmt.Sprintf("vd def: %s", vd.ToString())fmt.Println(vdDef)return vd
}
然后新增文件 create_view.go,添加如下代码:
package parserimport "fmt"type ViewData struct {viewName stringqueryData *QueryData
}func NewViewData(viewName string, qd *QueryData) *ViewData {return &ViewData{viewName: viewName,queryData: qd,}
}func (v *ViewData) ViewName() string {return v.viewName
}func (v *ViewData) ViewDef() string {return v.queryData.ToString()
}func (v *ViewData) ToString() string {s := fmt.Sprintf("view name %s, viewe def: %s", v.viewName, v.ViewDef())return s
}最后我们在 main.go 中添加如下测试代码:
func main() {//sql := "create table person (PersonID int, LastName varchar(255), FirstName varchar(255)," +// "Address varchar(255), City varchar(255) )"sql := "create view Customer as select CustomerName, ContactName from customers where country=\"China\""sqlParser := parser.NewSQLParser(sql)sqlParser.UpdateCmd()}
上面代码运行后结果如下:
vd def: view name Customer, viewe def: select CustomerName, ContactName, from customers, where and country=China
更详细的内容请在 b 站搜索 coding 迪斯尼。下面我们看看索引创建的语法解析,其对应的语法为:
CreateIndex -> CREATE INDEX ID ON ID LEFT_BRACKET Field RIGHT_BRACKET
从语法规则可以看出,在解析时我们需要判断语句必须以 CREATE INDEX 这两个关键字开头,然后接着的字符串要能满足 ID 的定义,然后又需要跟着关键字 ON, 然后跟着的字符串要满足 ID 定义,接下来读入的字符必须是左括号,然后接着的内容要满足 Field 的定义,最后要以右括号结尾,我们看看代码实现在 parser.go 中添加如下代码:
func (p *SQLParser) Create() interface{} {tok, err := p.sqlLexer.Scan()if err != nil {panic(err)}if tok.Tag != lexer.CREATE {panic("token is not create")}tok, err = p.sqlLexer.Scan()if err != nil {panic(err)}if tok.Tag == lexer.TABLE {return p.CreateTable()} else if tok.Tag == lexer.VIEW {return p.CreateView()} else if tok.Tag == lexer.INDEX {return p.CreateIndex()}panic("sql string with create should not end here")
}func (p *SQLParser) CreateIndex() interface{} {p.checkWordTag(lexer.ID)idexName := p.sqlLexer.Lexemep.checkWordTag(lexer.ON)p.checkWordTag(lexer.ID)tableName := p.sqlLexer.Lexemep.checkWordTag(lexer.LEFT_BRACKET)_, fldName := p.Field()p.checkWordTag(lexer.RIGHT_BRACKET)idxData := NewIndexData(idexName, tableName, fldName)fmt.Printf("create index result: %s", idxData.ToString())return idxData
}
新建 create_index_data.go 文件,在里面添加代码如下:
package parserimport "fmt"type IndexData struct {idxName stringtblName stringfldName string
}func NewIndexData(idxName string, tblName string, fldName string) *IndexData {return &IndexData{idxName: idxName,tblName: tblName,fldName: fldName,}
}func (i *IndexData) IdexName() string {return i.idxName
}func (i *IndexData) tableName() string {return i.tblName
}func (i *IndexData) fieldName() string {return i.fldName
}func (i *IndexData) ToString() string {str := fmt.Sprintf("index name: %s, table name: %s, field name: %s", i.idxName, i.tblName, i.fldName)return str
}在 main.go 中我们使用 sql 语句中的 create index 语句测试一下上面代码实现:
func main() {//sql := "create table person (PersonID int, LastName varchar(255), FirstName varchar(255)," +// "Address varchar(255), City varchar(255) )"sql := "create index idxLastName on persons (lastname)"sqlParser := parser.NewSQLParser(sql)sqlParser.UpdateCmd()}
上面代码运行后所得结果如下:
create index result: index name: idxLastName, table name: persons, field name: lastname
到这里所有有关 create 语句的解析就基本完成,更多的调试演示和代码逻辑的讲解,请在 b 站搜索 coding 迪斯尼
相关文章:
)
自己动手写数据库系统:实现一个小型SQL解释器(中)
我们接上节内容继续完成SQL解释器的代码解析工作。下面我们实现对update语句的解析,其语法如下: UpdateCmd -> INSERT | DELETE | MODIFY | CREATE Create -> CreateTable | CreateView | CreateIndex Insert -> INSERT INTO ID LEFT_PARAS Fie…...

HTML 与 XHTML 二者有什么区别
HTML 与 XHTML 二者有什么区别,你觉得应该使用哪一个并说出理由。 HTML 与 XHTML 之间的差别,主要分为功能上的差别和书写习惯的差别两方面。 关于功能上的差别,主要是 XHTML 可兼容各大浏览器、手机以及 PDA,并且浏览器也能快速正…...
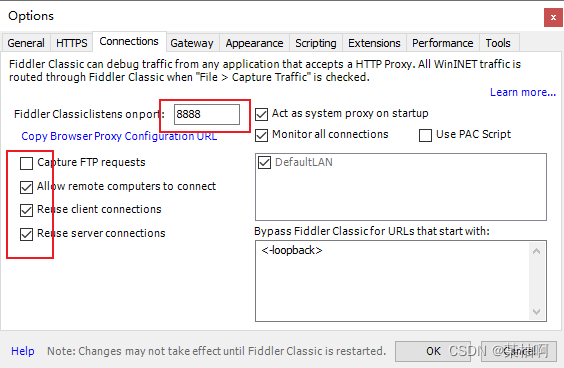
fiddler抓包问题记录,支持https、解决 tunnel to 443
fiddler下载安装步骤及基本配置 fiddler抓包教程,如何抓取HTTPS请求,详细教程 可能遇到的问题及解决方案 1. 不能正常访问页面(所有https都无法访问) 解决方案:查看下面配置是否正确 Rules-customization 找到 OnB…...
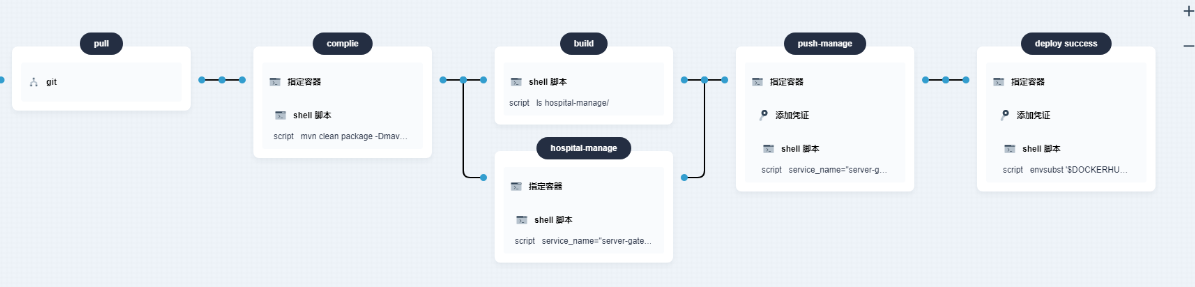
Kubesphere中DevOps流水线无法部署/部署失败
摘要 总算能让devops运行以后,流水线却卡在了deploy这一步。碰到了两个比较大的问题,一个是无法使用k8sp自带的kubeconfig认证去部署;一个是部署好了以后但是没有办法解析镜像名。 版本信息 k8s:v1.21.5 k8sp:v3.3.…...

使用Nginx解决跨域问题
前言: 项目是公司的老项目,只有部署在服务器上的时候,项目才可以正常运行(接口是通的);现在需求:在现有的项目代码上进行修改,请求接口是第三方给的。接口是正常的,通过A…...
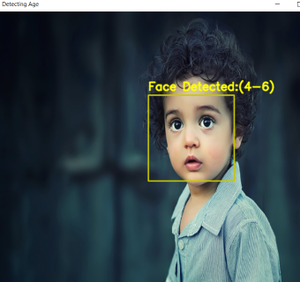
在 OpenCV 中使用深度学习进行年龄检测-附源码
文末附完整源码和模型文件下载链接 在本教程中,我们将了解使用 OpenCV 创建年龄预测器和性别分类器项目的整个过程。 年龄检测 我们的目标是创建一个程序,使用图像来预测人的性别和年龄。但预测年龄可能并不像你想象的那么简单,为什么呢?您可能会认为年龄预测是一个回归问…...
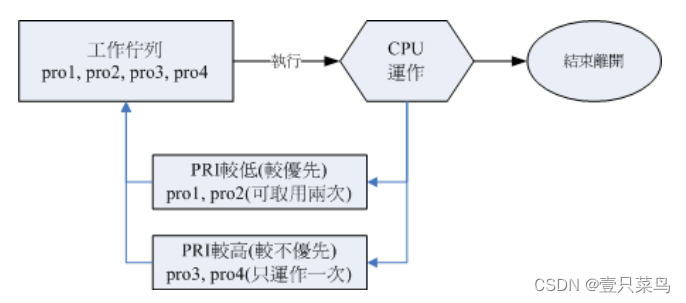
【BASH】回顾与知识点梳理(三十一)
【BASH】回顾与知识点梳理 三十一 三十一. 进程的管理31.1 给进程发送讯号kill -signal PIDlinux系统后台常驻进程killall -signal 指令名称 31.2 关于进程的执行顺序Priority 与 Nice 值nice :新执行的指令即给予新的 nice 值renice :已存在进程的 nice…...

Linux 终端命令之文件浏览(3) less
Linux 文件浏览命令 cat, more, less, head, tail,此五个文件浏览类的命令皆为外部命令。 hannHannYang:~$ which cat /usr/bin/cat hannHannYang:~$ which more /usr/bin/more hannHannYang:~$ which less /usr/bin/less hannHannYang:~$ which head /usr/bin/he…...

【精通性能优化:解锁JMH微基准测试】一基本用法
文章目录 1. 什么是JMH1.1 用JMH进行微基准测试1. JmhExample01.java2. 程序输出JmhExample01.java 2.2 JMH的基本用法2.1 Benchmark标记基准测试方法2.2 Warmup以及Measurement1. 设置全局的Warmup和Measurement(一)2. 设置全局的Warmup和Measurement&a…...
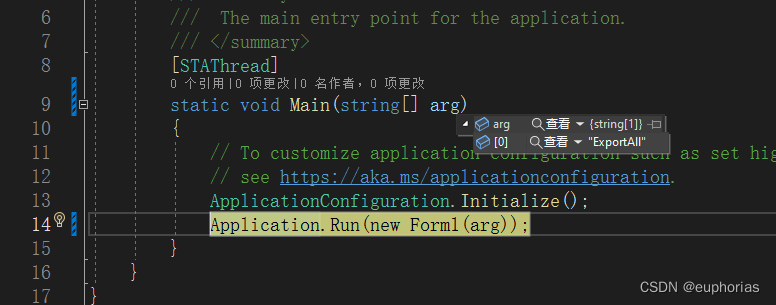
.Net程序调试时接受外部命令行参数方式
1.对项目右键,属性 2.在调试中打开常规,打开调试启动配置文件UI 3.输入需要的命令行参数...
Mariadb高可用MHA (四十二)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 一、概述 1.1 概念 1.2 组成 1.3 特点 1.4 工作原理 二、构建MHA 2.1 ssh免密登录 2.2 主从复制 2.3 MHA安装 2.3.1所有节点安装perl环境 2.3..2 node 2.3.…...
Vue3 setup中使用$refs
在 Vue 3 中的 Composition API 中,$refs 并不直接可用于 setup 函数。这是因为 $refs 是 Vue 2 的实例属性,而在 Vue 3 中,setup 函数是与模板实例分离的,不再使用实例属性。 实际工作中确实有需求,在setup 函数使用…...
?如何使用和传递上下文信息?)
什么是React的上下文(Context)?如何使用和传递上下文信息?
1、什么是React的上下文(Context)?如何使用和传递上下文信息? React上下文(Context)是React提供的一种功能,允许你在组件之间传递数据和状态。通过使用上下文,你无需通过props一层一层地传递数据,从而减少了代码的复杂…...

CentOS Linux 78安全基线检查
阿里云标准-CentOS Linux 7/8安全基线检查 检查项类别描述加固建议等级密码复杂度检查身份鉴别检查密码长度和密码是否使用多种字符类型编辑/etc/security/pwquality.conf,把minlen(密码最小长度)设置为8-32位,把minclass(至少包含小写字母、大写字母、数…...
Java之SpringCloud Alibaba【四】【微服务 Sentinel服务熔断】
Java之SpringCloud Alibaba【四】【微服务 Sentinel服务熔断】 一、分布式系统遇到的问题1、服务挂掉的一些原因 二、解决方案三、Sentinel:分布式系统的流量防卫兵1、Sentinel是什么2、Sentinel和Hystrix对比3、Sentinel快速开发4、通过注解的方式来控流5、启动Sen…...
Kubernetes 企业级高可用部署
目录 1、Kubernetes高可用项目介绍 2、项目架构设计 2.1、项目主机信息 2.2、项目架构图 2.3、项目实施思路 3、项目实施过程 3.1、系统初始化 3.2、配置部署keepalived服务 3.3、配置部署haproxy服务 3.4、配置部署Docker服务 3.5、部署kubelet kubeadm kubectl工具…...

8.1 C++ STL 变易拷贝算法
C STL中的变易算法(Modifying Algorithms)是指那些能够修改容器内容的算法,主要用于修改容器中的数据,例如插入、删除、替换等操作。这些算法同样定义在头文件 <algorithm> 中,它们允许在容器之间进行元素的复制…...

攻击LNMP架构Web应用
环境配置(centos7) 1.php56 php56-fpm //配置epel yum install epel-release rpm -ivh http://rpms.famillecollet.com/enterprise/remi-release-7.rpm//安装php56,php56-fpm及其依赖 yum --enablereporemi install php56-php yum --enablereporemi install php…...

深度学习入门-3-计算机视觉-图像分类
1.概述 图像分类是根据图像的语义信息对不同类别图像进行区分,是计算机视觉的核心,是物体检测、图像分割、物体跟踪、行为分析、人脸识别等其他高层次视觉任务的基础。图像分类在许多领域都有着广泛的应用,如:安防领域的人脸识别…...

shopee运营新手入门教程!Shopee运营技巧!
随着跨境电商行业的蓬勃发展,越来越多的人开始关注Shopee这个平台。短视频等渠道也成为了人们了解Shopee的途径。因此,对于许多新手来说,在Shopee上开店成为了一种吸引人的选择。为了帮助这些新手更好地入门,下面将介绍一下Shop…...

MATLAB实战:从SSE到R方,手把手教你用误差指标评估预测模型
1. 为什么需要误差指标? 在数据分析和预测建模中,我们经常需要评估模型的预测效果。想象一下,你开发了一个房价预测模型,输入房屋面积、地段等信息后,模型会输出预测价格。但你怎么知道这个预测准不准呢?这…...
)
告别BurpSuite自带Intruder的龟速:用Turbo Intruder插件30倍速爆破验证码(附Python脚本)
突破传统限制:Turbo Intruder在验证码爆破中的高效实践 在渗透测试和安全评估工作中,验证码爆破是一个常见但极具挑战性的任务。传统的BurpSuite Intruder模块虽然功能强大,但在处理高并发请求时往往显得力不从心,速度成为制约效率…...

AIGC 检测算法 1.0 到 4.0 升级了什么?嘎嘎降 AI 实测 80% AI 率降到 6% 答辩稳过
AIGC 检测算法 1.0 到 4.0 升级了什么?嘎嘎降 AI 实测 80% AI 率降到 6% 答辩稳过 很多同学不理解——为什么 2024 年用换同义词就能降下 AI 率、2025 年开始这招就半失效了、2026 年完全没用了?真相是——AIGC 检测算法从 1.0 升级到 4.0 经历了 4 次大…...

【语音检测】基于matlab GUI短时自相关的基音周期检测【含Matlab源码 15451期】
💥💥💥💥💥💥💞💞💞💞💞💞💞💞欢迎来到海神之光博客之家💞💞💞Ὁ…...

构建高效电商后台管理系统:SpringBoot 项目推荐
构建高效电商后台管理系统:SpringBoot 项目推荐 【下载地址】SpringBoot电商后台管理系统项目介绍 本项目基于SpringBoot框架实现,提供了一套完整的电商后台管理系统解决方案。系统专注于用户管理和权限管理两大核心功能模块,旨在帮助开发者快…...

ADI CodeFusion Studio:图形化系统规划与数据溯源重塑嵌入式开发
1. 项目概述:当嵌入式开发遇上“系统规划”与“数据信任”在智能边缘设备爆炸式增长的今天,嵌入式开发者正面临着一个前所未有的“甜蜜的烦恼”。一方面,芯片性能越来越强,多核异构架构成为主流,这让我们能在更小的空间…...

GoogleTest 使用指南 | 测试模板函数
GoogleTest 使用指南 | 测试模板函数GoogleTest 使用指南 | 测试模板函数GoogleTest 使用指南 | 测试模板函数 模板类和函数由于其泛型特性,需要在不同类型下进行测试,以确保其通用性和正确性。 下面是一个示例。 m…...

Perplexity突然禁用Chrome扩展权限:技术团队未公开的5项合规改造倒计时,开发者窗口仅剩72小时
更多请点击: https://codechina.net 第一章:Perplexity突然禁用Chrome扩展权限:技术团队未公开的5项合规改造倒计时,开发者窗口仅剩72小时 Perplexity AI 技术团队于 2024 年 6 月 18 日凌晨通过后台策略悄然撤销了所有第三方 Ch…...

终极指南:5分钟搞定MASA模组全家桶中文汉化,告别英文困扰
终极指南:5分钟搞定MASA模组全家桶中文汉化,告别英文困扰 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 还在为Minecraft技术模组的英文界面而头疼吗࿱…...

使用 TaoToken CLI 工具一键配置多开发环境接入参数
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 TaoToken CLI 工具一键配置多开发环境接入参数 在团队协作或个人多项目开发中,为不同的 AI 应用工具配置 API 密钥…...