【Kafka】2.在SpringBoot中使用官方原生java版Kafka客户端
目 录
- 1. 新建一个消息生产者
- 2. 新建一个消息消费者
- 3. 测 试
在开始之前,需要先做点准备工作,用 IDEA 新建一个 Maven 项目,取名 kafka-study,然后删掉它的 src 目录,接着在 pom.xml 里面引入下面的依赖。这个项目的作用是作为整个工程的父项目,后面的项目都在此基础上新建 module 即可。
这里用到的环境信息如下:
- JDK1.8
- SpringBoot2.7.1
- IDEA
- Maven3.6.3
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><packaging>pom</packaging><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.1</version><relativePath/></parent><groupId>org.yuhuofei</groupId><artifactId>kafka-study</artifactId><version>1.0-SNAPSHOT</version><name>kafka-study</name><description>Study project for Kafka</description><properties><java.version>1.8</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build>
</project>
1. 新建一个消息生产者
使用 IDEA 在 kafka-study 的基础上新建一个 Maven 类型的 module ,命名为 producer-01,直至完成。接着,我们改造这个 module ,把它变成我们想要的消息生产者。
1、在 java 目录下,新建一个包 com.yuhuofei ,然后再创建一个启动类 ProducerApplication.java ,内容如下:
package com.yuhuofei;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication
public class ProducerApplication {public static void main(String[] args) {SpringApplication.run(ProducerApplication.class, args);}}2、在 resources 目录下,新建配置文件 application.properties ,内容如下:
server.port=8080
server.servlet.context-path=/producer-01
#Kafka配置
topic.name=my-kafka-topic
3、在自己的 pom.xml 文件中,引入 Kafka 客户端的依赖。这里需要注意的是,由于我们在上一篇博客里安装的是 kafka_2.11-2.2.1 版本的服务端,所以引入的 Kafka 客户端的版本最好对应,也选择 2.2.1 版本的。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><artifactId>kafka-study</artifactId><groupId>org.yuhuofei</groupId><version>1.0-SNAPSHOT</version></parent><modelVersion>4.0.0</modelVersion><artifactId>producer-01</artifactId><dependencies><!--官方原生的java版kafka客户端依赖--><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.2.1</version></dependency><!--fastjson依赖--><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>2.0.11.graal</version></dependency></dependencies></project>
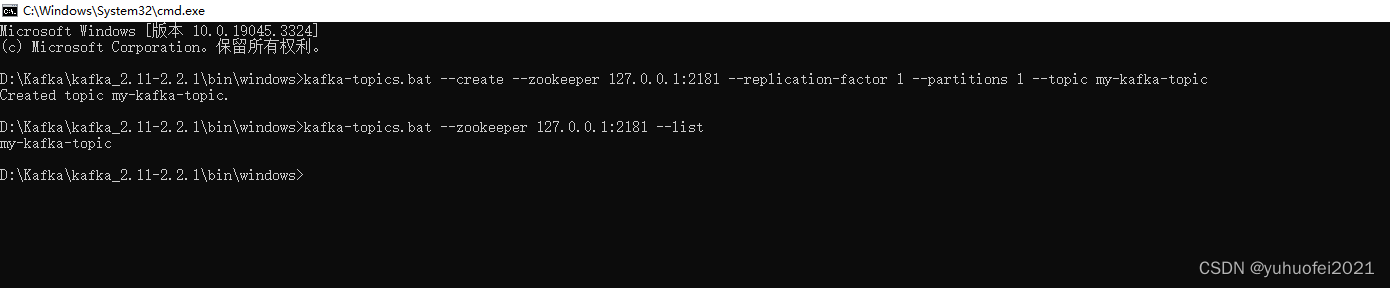
4、由于 Kafka 进行消息的发布或者消费是需要有 Topic 的,因此我们需要要创建一个 Topic。在 zookeeper 和 Kafka 服务端都启动的情况下,打开 D:\Kafka\kafka_2.11-2.2.1\bin\windows 文件夹,在地址栏输入 cmd,打开控制台,然后用下面的命令创建、查看、删除 topic 。
如下图所示,我已经创建了一个名字为 my-kafka-topic 的 topic ,这个 topic 的分区为 1,副本也是 1。
# 创建topic
kafka-topics.bat --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 1 --topic my-kafka-topic
# 查询topic列表
kafka-topics.bat --zookeeper 127.0.0.1:2181 --list
# 删除topic
kafka-topics.bat --delete --zookeeper 127.0.0.1:2181 --topic my-kafka-topic
# 查询某个topic信息
kafka-topics.bat --describe --zookeeper localhost:2181 --topic my-kafka-topic
#kafka查看topic数据内容
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic my-kafka-topic --from-beginning
5、实现生产者发送消息
- controller层
package com.yuhuofei.controller;import com.yuhuofei.service.ProducerInterface;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import javax.annotation.Resource;/*** @Description* @ClassName ProducerController* @Author yuhuofei* @Date 2023/8/13 16:38* @Version 1.0*/
@RequestMapping("/info")
@RestController
public class ProducerController {@Resourceprivate ProducerInterface producerInterface;@GetMapping("/create-message")public void createTopic() {producerInterface.createMessage();}
}- service层
package com.yuhuofei.service;/*** @Description* @InterfaceName ProducerController* @Author yuhuofei* @Date 2023/8/13 16:39* @Version 1.0*/
public interface ProducerInterface {void createMessage();
}- serviceImpl层
package com.yuhuofei.service.impl;import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.yuhuofei.service.ProducerInterface;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;import javax.annotation.Resource;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;/*** @Description* @ClassName ProducerInterfaceImpl* @Author yuhuofei* @Date 2023/8/13 16:39* @Version 1.0*/
@Service
public class ProducerInterfaceImpl implements ProducerInterface {@Value("${topic.name}")private String topicName;@Resourceprivate Producer producer;@Overridepublic void createMessage() {//创建测试数据JSONObject jsonObject = new JSONObject();jsonObject.put("word", "这是生产者生产的测试消息");String jsonString = JSON.toJSONString(jsonObject);//使用kafka发送消息ProducerRecord<String, String> producerRecord = new ProducerRecord<>(topicName, jsonString);producer.send(producerRecord);}
}- 客户端配置类
package com.yuhuofei.config;import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.Properties;/*** @Description 配置生产者客户端参数* @ClassName KafkaProperties* @Author yuhuofei* @Date 2023/8/13 22:18* @Version 1.0*/
@Configuration
public class KafkaConfig {@Bean("producer")public Producer<String, String> getKafkaProducer() {Properties properties = new Properties();//配置Kafka的服务端IP和端口properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");//指定key使用的序列化类properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());//指定value使用的序列化类properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());return new KafkaProducer<>(properties);}
}6、启动服务,调用接口 http://localhost:8080/producer-01/info/create-message ,然后在控制台用命令查看一下消息是否写入,如下图所见,虽然是乱码,但是已经可以看出消息成功写入到 Kafka
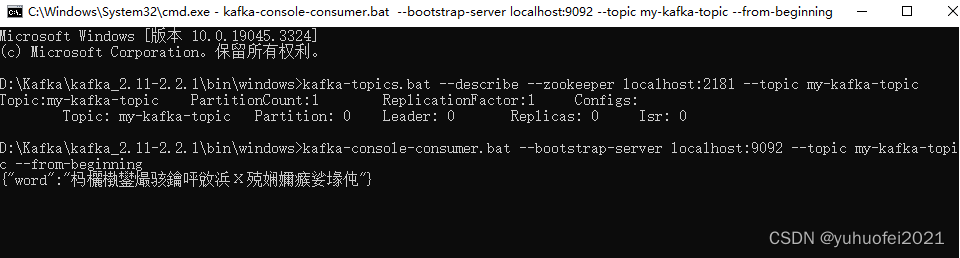
到这里,消息生产者的创建暂时告一段落。
2. 新建一个消息消费者
和前面建立生产者类似的步骤,只是文件信息和名字不一样,这里步骤就不重复了,直接给出相关的配置和类。这个消费者,取名 consumer-01 。
- pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><artifactId>kafka-study</artifactId><groupId>org.yuhuofei</groupId><version>1.0-SNAPSHOT</version></parent><modelVersion>4.0.0</modelVersion><artifactId>consumer-01</artifactId><dependencies><!--官方原生的java版kafka客户端依赖--><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.2.1</version></dependency><!--fastjson依赖--><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>2.0.11.graal</version></dependency></dependencies>
</project>
- properties文件
server.port=8081
server.servlet.context-path=/consumer-01
#Kafka配置
topic.name=my-kafka-topic
- 启动类 ConsumerApplication.java
package com.yuhuofei;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication
public class ConsumerApplication {public static void main(String[] args) {SpringApplication.run(ConsumerApplication.class, args);}}- 控制层ConsumerController.java
package com.yuhuofei.controller;import com.yuhuofei.service.ConsumerInterface;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import javax.annotation.Resource;/*** @Description* @ClassName ConsumerController* @Author yuhuofei* @Date 2023/8/14 0:19* @Version 1.0*/
@RestController
@RequestMapping("/consumer")
public class ConsumerController {@Resourceprivate ConsumerInterface consumerInterface;@GetMapping("/getData")public void getData() {consumerInterface.getData();}
}
- service层
package com.yuhuofei.service;/*** @Description* @ClassName ConsumerInterface* @Author yuhuofei* @Date 2023/8/14 0:20* @Version 1.0*/
public interface ConsumerInterface {void getData();
}- serviceImpl层
package com.yuhuofei.service.impl;import com.yuhuofei.service.ConsumerInterface;
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;import javax.annotation.Resource;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Collections;
import java.util.List;/*** @Description* @ClassName ConsumerInterfaceImpl* @Author yuhuofei* @Date 2023/8/14 0:20* @Version 1.0*/
@Service
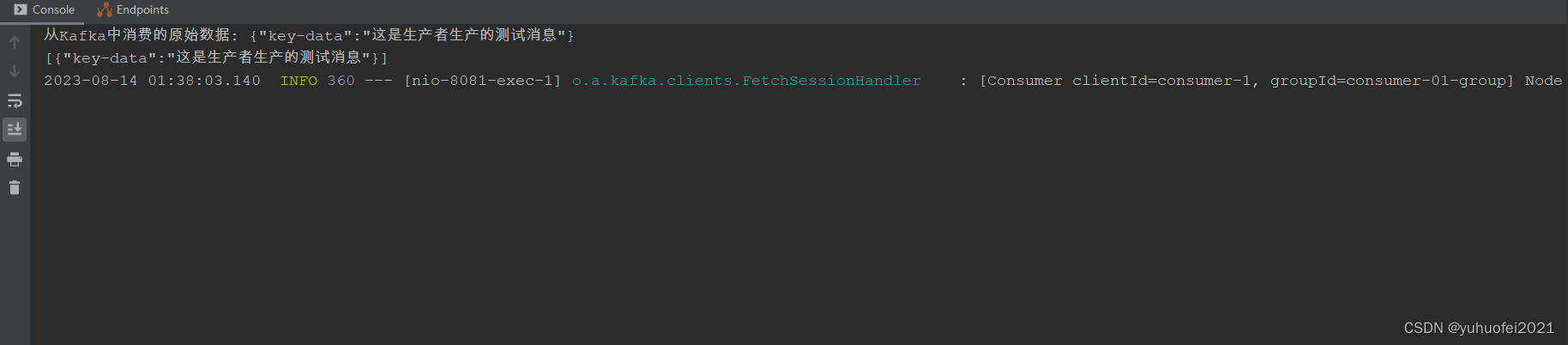
public class ConsumerInterfaceImpl implements ConsumerInterface {@Value("${topic.name}")private String topicName;@Resourceprivate Consumer consumer;@Overridepublic void getData() {Collection<String> topics = Collections.singletonList(topicName);consumer.subscribe(topics);List<String> result = new ArrayList<>();while (true) {ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord consumerRecord : consumerRecords) {//从ConsumerRecord中获取消费数据String res = (String) consumerRecord.value();System.out.println("从Kafka中消费的原始数据: " + res);result.add(res);System.out.println(result);}}}
}
- config配置类
package com.yuhuofei.config;import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.Properties;/*** @Description 配置消费者参数* @ClassName KafkaConsumerConfig* @Author yuhuofei* @Date 2023/8/14 0:08* @Version 1.0*/
@Configuration
public class KafkaConsumerConfig {@Bean("consumer")public Consumer<String, String> getKafkaConsumer() {Properties properties = new Properties();//配置Kafka的服务端IP和端口properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");//指定key使用的序列化类properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());//指定value使用的序列化类properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());//指定消费者组properties.put(ConsumerConfig.GROUP_ID_CONFIG, "consumer-01-group");properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true);properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,100);properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"latest");return new KafkaConsumer<>(properties);}
}最终整个项目目录如下图所示。
3. 测 试
1、检查 zookeeper 和 Kafka 服务端是否是启动的,没启动就先启动。
2、接着,启动消费者服务,然后调用一下接口 http://localhost:8081/consumer-01/consumer/getData ,这么做的目的启动一个线程,监听 topic 。
3、最后,启动生产者服务,调用接口 http://localhost:8080/producer-01/info/create-message ,向 Kafka 服务器写数据。
结果如下所示:
控制台看到的所有消息记录
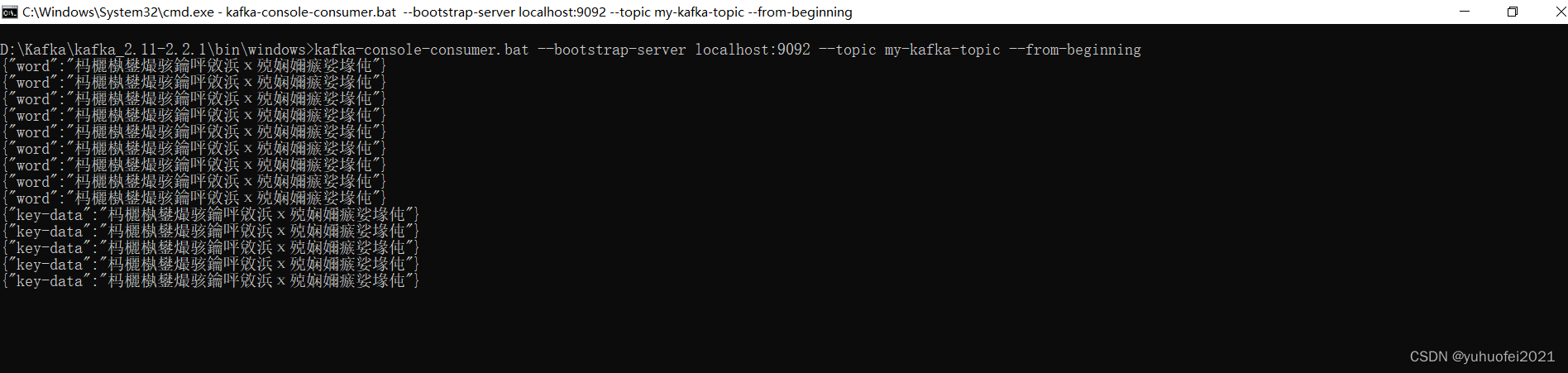
生产者发送一条消息

消费者监听到一条消息并接收
在 SpringBoot 中,使用官方原生 java 版 Kafka 客户端的入门介绍到这里结束,还有更多使用方式,等待挖掘。
相关文章:
【Kafka】2.在SpringBoot中使用官方原生java版Kafka客户端
目 录 1. 新建一个消息生产者2. 新建一个消息消费者3. 测 试 在开始之前,需要先做点准备工作,用 IDEA 新建一个 Maven 项目,取名 kafka-study,然后删掉它的 src 目录,接着在 pom.xml 里面引入下面的依赖。这个项目的作…...
使用腾讯云轻量服务器Matomo应用模板建网站流量统计系统
腾讯云百科分享使用腾讯云轻量应用服务器Matomo应用模板搭建网站流量统计系统,Matomo 是一款开源的网站数据统计软件,可以用于跟踪、分析您的网站的流量,同时充分保障数据安全性、隐私性。该镜像基于 CentOS 7.6 64位操作系统,已预…...
clickhouse-监控配置
一、概述 监控是运维的一大利器,要想运维好clickhouse,首先就要对其进行监控,clickhouse有几种监控数据的方式,一种是系统本身监控,一种是通过exporter来监控,下面分别描述一下 二、系统自带监控 我下面会对监控做一…...
互斥量概念、用法、死锁演示及解决详解)
C++11并发与多线程笔记(5)互斥量概念、用法、死锁演示及解决详解
C11并发与多线程笔记(5)互斥量概念、用法、死锁演示及解决详解 1、互斥量(mutex)的基本概念2、互斥量的用法2.1 lock(),unlock()2.2 lock_guard类模板 3、死锁3.1 死锁演示3.2 死锁的一般解决方案:3.3 std:…...
华为云classroom赋能--Devstar使应用开发无需从零开始
华为云DevStar为开发者提供业界主流框架代码初始化能力,通过GUI、API、CLI等多种方式,将按模板生成框架代码的能力推送至用户桌面。同时基于华为云服务资源、成熟的DevOps开发工具链和面向多场景的众多开发模板,提供一站式创建代码仓、自动生…...

软件的数据回滚
原理:所谓的数据回滚,就是数据备份 增量备份: 全量备份: 最简单的事全量备份。 就是spoon工具,完成把所有的表每天定时复制一份,表名“_日期”。 所以有实时表,每日备份表。 回滚就是把之前…...

git clone使用https协议报错OpenSSL SSL_read: Connection was reset, errno 10054
在使用git 下载github上的代码时, 一般有ssh协议和https协议两种。使用ssh协议可以成功clone代码, 但使用https协议时出错: $ git clone https://github.com/openai/improved-diffusion.git Cloning into improved-diffusion... fatal: unab…...
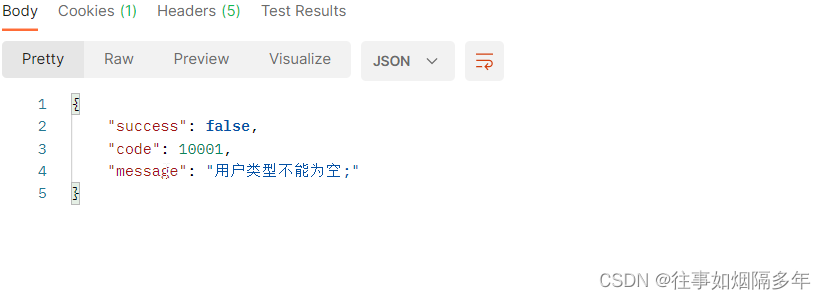
化繁为简,使用Hibernate Validator实现参数校验
前言 在之前的悦享校园的开发中使用了SSM框架,由于当时并没有使用参数参数校验工具,方法的入参判断使用了大量的if else语句,代码十分臃肿,因此最近在重构代码时,将框架改为SpringBoot后,引入了Hibernate V…...

【Qt】多线程
线程创建 自定义线程类 #ifndef CUSTOMETHREAD_H #define CUSTOMETHREAD_H#include <QObject> #include <QThread> #include "add.h"class CustomeThread : public QThread {Q_OBJECT public:// Bind the thread kernel function.explicit CustomeThre…...
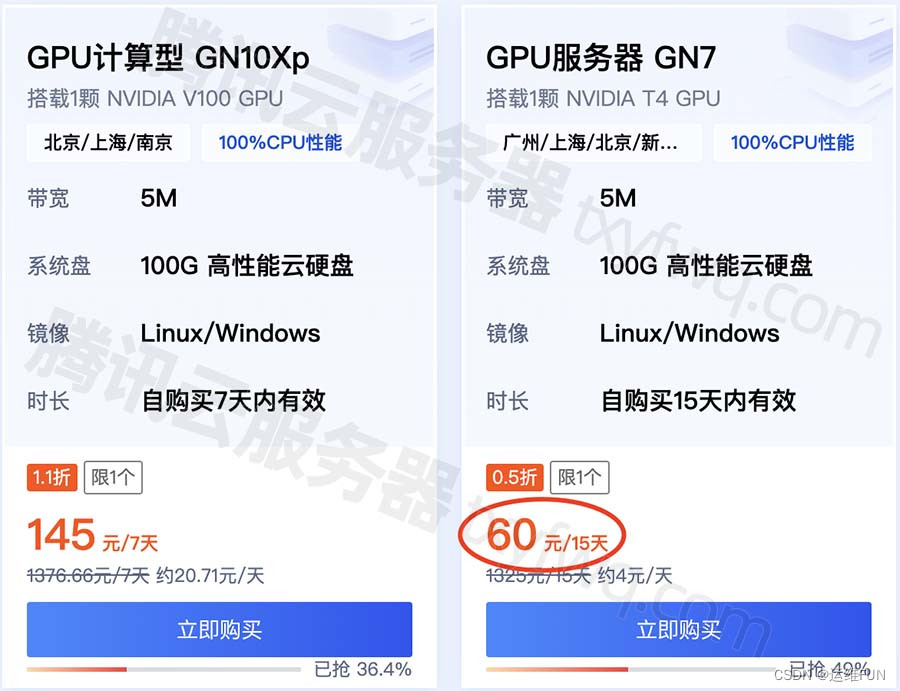
腾讯云GPU服务器GN7实例NVIDIA T4 GPU卡
腾讯云GPU服务器GN7实例搭载1颗 NVIDIA T4 GPU,8核32G配置,系统盘为100G 高性能云硬盘,自带5M公网带宽,系统镜像可选Linux和Windows,地域可选广州/上海/北京/新加坡/南京/重庆/成都/首尔/中国香港/德国/东京/曼谷/硅谷…...
3. 爬取自己CSDN博客列表(自动方式)(分页查询)(网站反爬虫策略,需要在代码中添加合适的请求头User-Agent,否则response返回空)
文章目录 步骤打开谷歌浏览器输入网址按F12进入调试界面点击网络,清除历史消息按F5刷新页面找到接口(community/home-api/v1/get-business-list)接口解读 撰写代码获取博客列表先明确返回信息格式json字段解读 Apipost测试接口编写python代码…...

利用HTTP代理实现请求路由
嘿,大家好!作为一名专业的爬虫程序员,我知道构建一个高效的分布式爬虫系统是一个相当复杂的任务。在这个过程中,实现请求的路由是非常关键的。今天,我将和大家分享一些关于如何利用HTTP代理实现请求路由的实用技巧&…...
深度学习(36)—— 图神经网络GNN(1)
深度学习(36)—— 图神经网络GNN(1) 这个系列的所有代码我都会放在git上,欢迎造访 文章目录 深度学习(36)—— 图神经网络GNN(1)1. 基础知识2.使用场景3. 图卷积神经网…...

深入理解JVM——垃圾回收与内存分配机制详细讲解
所谓垃圾回收,也就是要回收已经“死了”的对象。 那我们如何判断哪些对象“存活”,哪些已经“死去”呢? 一、判断对象已死 1、引用计数算法 给对象中添加一个引用计数器,每当有一个地方引用它时,计数器就加一&…...
基于SSH框架实现的管理系统(包含java源码+数据库)
资料下载链接 介绍 基于SSH框架的管理系统 简洁版 ; 实现 登录 、 注册 、 增 、 删 、 改 、 查 ; 可继续完善增加前端、校验、其他功能等; 可作为 SSH(Structs Spring Hibernate)项目 开发练习基础模型…...

图像识别代做服务:实现创新应用的新契机
导言: 随着人工智能和图像处理技术的不断进步,图像识别已经成为了许多领域中的关键应用。然而,图像识别技术的开发和应用往往需要庞大的团队和大量的资源。这就是为什么图像识别代做服务正在崭露头角。本文将探讨图像识别代做服务如何成为实现…...
Coreutils工具包,Windows下使用Linux命令
之前总结过两篇有关【如何在Windows系统下使用Linux的常用命令】的文章: GnuWin32,Windows下使用Linux命令 UnxUtils工具包,Windows下使用Linux命令 今天再推荐一个类似的工具包Coreutils 一、简介 GNU core utilities是GNU操作系统基本…...

神经网络基础-神经网络补充概念-13-python中的广播
概念 在 Python 中,广播(Broadcasting)是一种用于在不同形状的数组之间执行二元操作的机制。广播允许你在不显式复制数据的情况下,对不同形状的数组进行运算。这在处理数组的时候非常有用,尤其是在科学计算、数据分析…...
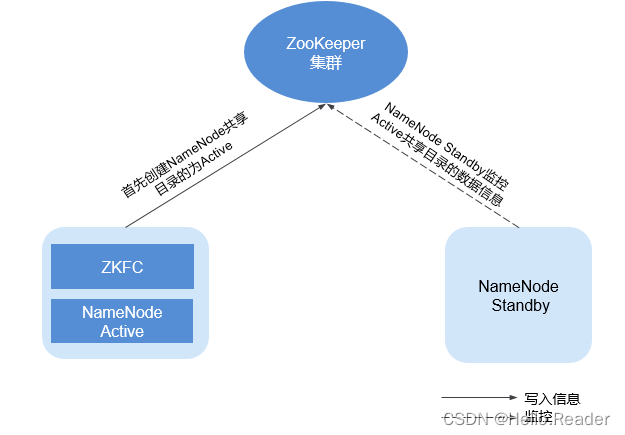
HDFS原理剖析
一、概述 HDFS是Hadoop的分布式文件系统(Hadoop Distributed File System),实现大规模数据可靠的分布式读写。HDFS针对的使用场景是数据读写具有“一次写,多次读”的特征,而数据“写”操作是顺序写,也就是…...

css学习2(利用id与class修改元素)
1、id选择器可以为标有特定id的html元素指定特定的样式。 2、选择器以#开头,后跟某id的属性值。 3、class选择器用于描述一组元素的样式,class可以在多个元素使用。 4、类选择器用.选择。 5、指定特定的元素使用class。 6、元素的多个类用空格分开&…...

B站视频转文字终极指南:如何用AI工具3步搞定视频内容整理
B站视频转文字终极指南:如何用AI工具3步搞定视频内容整理 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 你是否曾为了一段精彩的B站课程内容反复…...

别只仿真了!手把手教你将Proteus里的AT89C52温控风扇代码烧录进实物单片机
从Proteus仿真到实物落地:AT89C52温控风扇全流程实战指南 当你成功在Proteus中完成了AT89C52温控风扇的仿真,看到虚拟环境中风扇随着温度变化自动启停时,那种成就感不言而喻。但仿真终究只是第一步,真正的挑战在于如何将这个系统…...

突发!Gemini Ultra最新v1.5更新导致批量推理吞吐下降38%?我们48小时内完成全链路压测并定位CUDA内核缺陷
更多请点击: https://codechina.net 第一章:Gemini Ultra性能测试的背景与挑战 随着多模态大模型能力边界持续拓展,Gemini Ultra作为Google最新发布的旗舰级AI模型,在推理深度、上下文理解与跨模态协同方面提出了前所未有的工程验…...

C 读取RAW文件程序
C# 读取RAW文件程序 【下载地址】C读取RAW文件程序 本仓库提供了一个简单的C#程序,用于读取RAW文件。该程序已经过调试,确保功能正常运行。需要注意的是,此程序仅提供基本的RAW文件读取功能,不包含任何图像处理或转换功能 项目地…...

面试官最爱阴人的滑动窗口题,为啥你总是写崩?
面试官最爱阴人的滑动窗口题,为啥你总是写崩? 很多人刷算法的时候,都有一种错觉: 动态规划最难。 图论最恶心。 回溯最容易超时。 结果真正到了大厂面试现场。 面试官笑眯眯来一句: 给你一个字符串,求: 至多包含 K 个不同字符的最长子串然后。 一堆人开始原地去世…...

CVPR2021明星算法LoFTR实战:在Ubuntu 20.04上从零搭建Python 3.7+Pytorch 1.6.0环境,跑通第一个图像匹配Demo
CVPR2021明星算法LoFTR实战:在Ubuntu 20.04上从零搭建Python 3.7Pytorch 1.6.0环境,跑通第一个图像匹配Demo 计算机视觉领域每年都会涌现出大量创新算法,而CVPR2021上发表的LoFTR(Detector-Free Local Feature Matching with Tran…...

使用 curl 命令直接测试 Taotoken 聊天补全接口连通性与返回
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 curl 命令直接测试 Taotoken 聊天补全接口连通性与返回 在开发或调试过程中,有时你可能需要绕过高级 SDK…...

Linux密钥文件管理实战指南
Linux密钥文件管理实战指南本文面向具备一定 Linux 基础的技术人员,围绕密钥文件管理展开,重点讨论敏感文件权限、轮换流程和审计追踪。在中级运维和系统管理工作中,这类主题常常与配置变更、资源状态、权限边界、自动化任务和业务影响交织在…...

【LangChain 】从一行 LCEL 代码,理解 LangChain 管道操作符 `|` 的自动转换机制
从一行 LCEL 代码,理解 LangChain 管道操作符 | 的自动转换机制一、从一个代码片段说起 先看这段处理用户反馈的 LCEL 代码: processing_chain (extract_chain| RunnablePassthrough.assign(analysislambda x: analysis_chain.invoke(x["original_…...

从 XChat 到超级 APP 生态:小程序生态为什么成为了超级APP的最佳技术选型
2026年4月17日,XChat 正式登陆苹果 App Store。 马斯克一直想做一个美国版的微信的目标已经实现:端对端加密、无广告、无追踪,注册只需要一个 X 账号,不需要手机号。马斯克给它的目标也很直接——X 要从社交平台,变成「…...