HDFS原理剖析
一、概述
HDFS是Hadoop的分布式文件系统(Hadoop Distributed File System),实现大规模数据可靠的分布式读写。HDFS针对的使用场景是数据读写具有“一次写,多次读”的特征,而数据“写”操作是顺序写,也就是在文件创建时的写入或者在现有文件之后的添加操作。HDFS保证一个文件在一个时刻只被一个调用者执行写操作,而可以被多个调用者执行读操作。
二、HDFS结构
HDFS包含主、备NameNode和多个DataNode,如下图所示。
HDFS是一个Master/Slave的架构,在Master上运行NameNode,而在每一个Slave上运行DataNode,ZKFC需要和NameNode一起运行。
NameNode和DataNode之间的通信都是建立在TCP/IP的基础之上的。NameNode、DataNode、ZKFC和JournalNode能部署在运行Linux的服务器上。
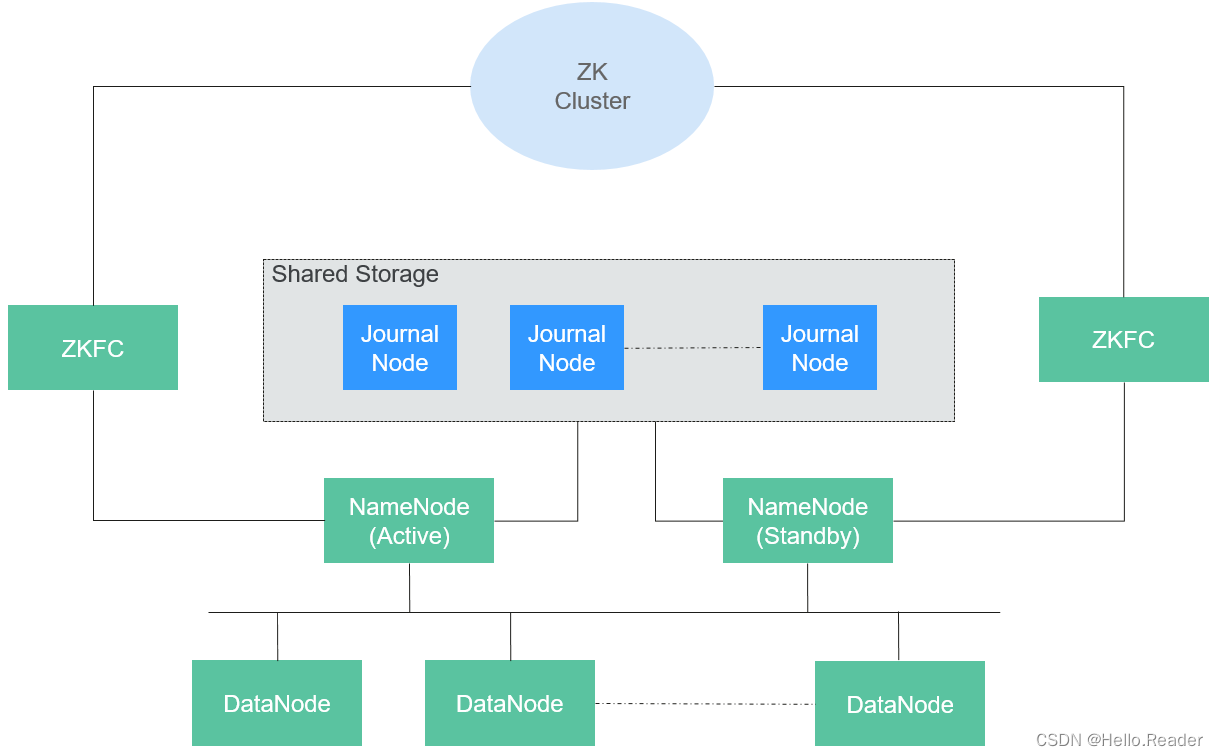
| 名称 | 描述 |
|---|---|
| NameNode | 用于管理文件系统的命名空间、目录结构、元数据信息以及提供备份机制等,分为:1. Active NameNode:管理文件系统的命名空间、维护文件系统的目录结构树以及元数据信息;记录写入的每个“数据块”与其归属文件的对应关系。2. Standby NameNode:与Active NameNode中的数据保持同步;随时准备在Active NameNode出现异常时接管其服务。3.Observer NameNode:与Active NameNode中的数据保持同步,处理来自客户端的读请求。 |
| DataNode | 用于存储每个文件的“数据块”数据,并且会周期性地向NameNode报告该DataNode的数据存放情况。 |
| JournalNode | HA集群下,用于同步主备NameNode之间的元数据信息。 |
| ZKFC | ZKFC是需要和NameNode一一对应的服务,即每个NameNode都需要部署ZKFC。它负责监控NameNode的状态,并及时把状态写入ZooKeeper。ZKFC也有选择谁作为Active NameNode的权利。 |
| ZK Cluster | ZooKeeper是一个协调服务,帮助ZKFC执行主NameNode的选举。 |
| HttpFS gateway | HttpFS是个单独无状态的gateway进程,对外提供webHDFS接口,对HDFS使用FileSystem接口对接。可用于不同Hadoop版本间的数据传输,及用于访问在防火墙后的HDFS(HttpFS用作gateway)。 |
HttpFS是个单独无状态的gateway进程,对外提供webHDFS接口,对HDFS使用FileSystem接口对接。可用于不同Hadoop版本间的数据传输,及用于访问在防火墙后的HDFS(HttpFS用作gateway)。
三、HDFS原理
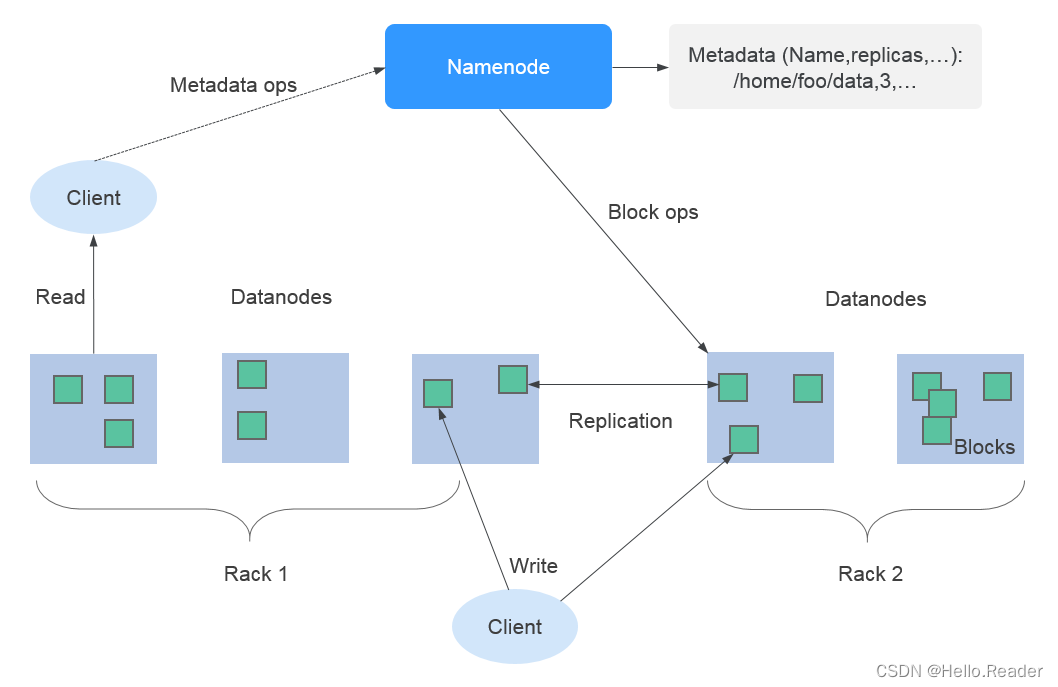
使用HDFS的副本机制来保证数据的可靠性,HDFS中每保存一个文件则自动生成1个备份文件,即共2个副本。HDFS副本数可通过“dfs.replication”参数查询。
- 当集群中Core节点规格选择为非本地盘(hdd)时,若集群中只有一个Core节点,则HDFS默认副本数为1。若集群中Core节点数大于等于2,则HDFS默认副本数为2。
- 当集群中Core节点规格选择为本地盘(hdd)时,若集群中只有一个Core节点,则HDFS默认副本数为1。若集群中有两个Core节点,则HDFS默认副本数为2。若集群中Core节点数大于等于3,则HDFS默认副本数为3。
HDFS组件支持以下部分特性:
- HDFS组件支持纠删码,使得数据冗余减少到50%,且可靠性更高,并引入条带化的块存储结构,最大化的利用现有集群单节点多磁盘的能力,使得数据写入性能在引入编码过程后,仍和原来多副本冗余的性能接近。
- 支持HDFS组件上节点均衡调度和单节点内的磁盘均衡调度,有助于扩容节点或扩容磁盘后的HDFS存储性能提升。
关于Hadoop的架构和详细原理介绍,请参见:http://hadoop.apache.org/。
四、HDFS HA方案背景
在Hadoop2.0.0之前,HDFS集群中存在单点故障问题。由于每个集群只有一个NameNode,如果NameNode所在机器发生故障,将导致HDFS集群无法使用,除非NameNode重启或者在另一台机器上启动。这在两个方面影响了HDFS的整体可用性:
- 当异常情况发生时,如机器崩溃,集群将不可用,除非重新启动NameNode。
- 计划性的维护工作,如软硬件升级等,将导致集群停止工作。
针对以上问题,HDFS高可用性方案通过自动或手动(可配置)的方式,在一个集群中为NameNode启动一个热替换的NameNode备份。当一台机器故障时,可以迅速地自动进行NameNode主备切换。或者当主NameNode节点需要进行维护时,通过集群管理员控制,可以手动进行NameNode主备切换,从而保证集群在维护期间的可用性。
有关HDFS自动故障转移功能,请参阅:
https://hadoop.apache.org/docs/r3.3.1/hadoop-project-dist/hadoophdfs/HDFSHighAvailabilityWithQJM.html#Automatic_Failover
五、HDFS HA实现方案
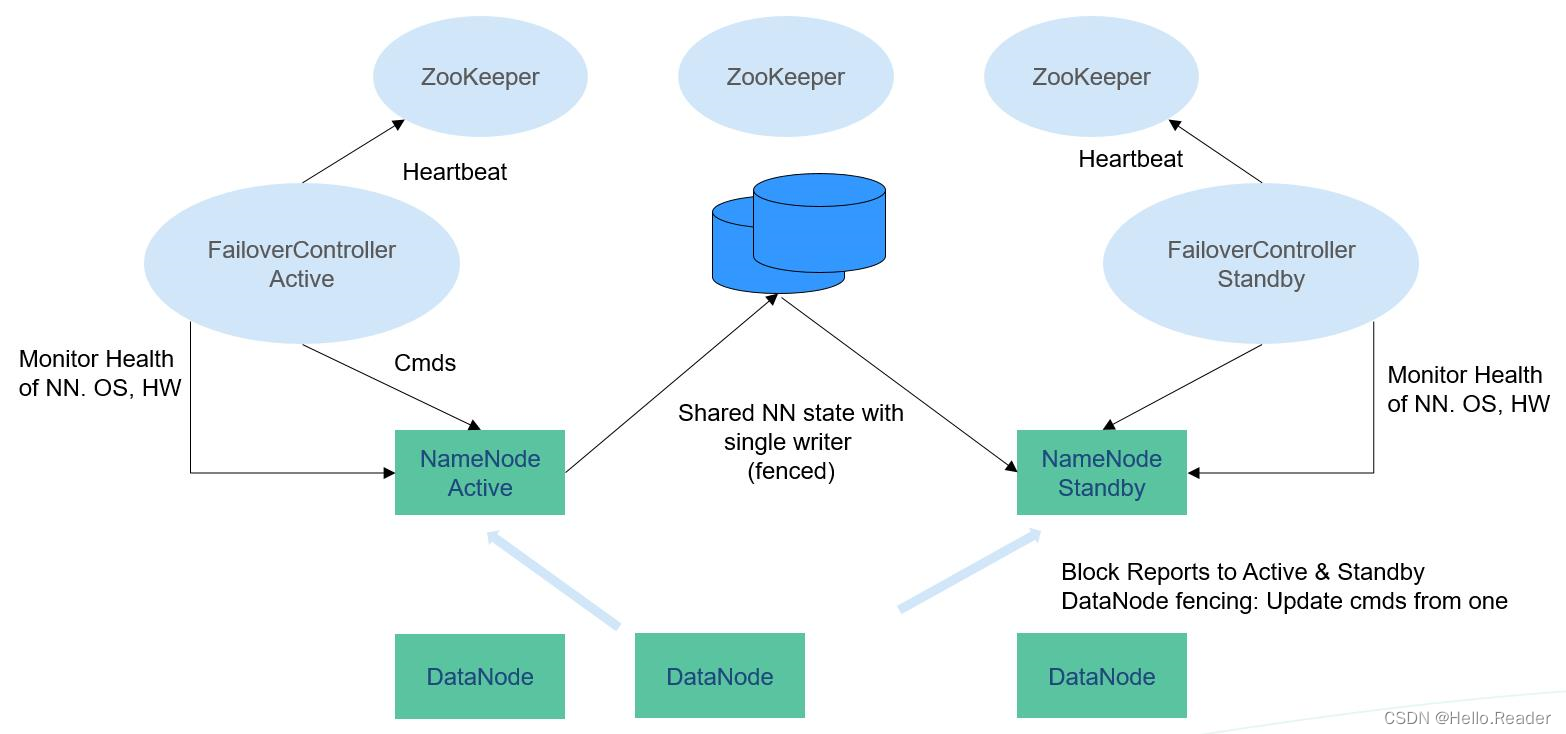
在一个典型的HA集群中(如上图所示),需要把两个NameNodes配置在两台独立的机器上。在任何一个时间点,只有一个NameNode处于Active状态,另一个处于Standby状态。Active节点负责处理所有客户端操作,Standby节点时刻保持与Active节点同步的状态以便在必要时进行快速主备切换。
为保持Active和Standby节点的数据一致性,两个节点都要与一组称为JournalNode的节点通信。当Active对文件系统元数据进行修改时,会将其修改日志保存到大多数的JournalNode节点中,例如有3个JournalNode,则日志会保存在至少2个节点中。Standby节点监控JournalNodes的变化,并同步来自Active节点的修改。根据修改日志,Standby节点将变动应用到本地文件系统元数据中。一旦发生故障转移,Standby节点能够确保与Active节点的状态是一致的。这保证了文件系统元数据在故障转移时在Active和Standby之间是完全同步的。
为保证故障转移快速进行,Standby需要时刻保持最新的块信息,为此DataNodes同时向两个NameNodes发送块信息和心跳。
对一个HA集群,保证任何时刻只有一个NameNode是Active状态至关重要。否则,命名空间会分为两部分,有数据丢失和产生其他错误的风险。为保证这个属性,防止“split-brain”问题的产生,JournalNodes在任何时刻都只允许一个NameNode写入。在故障转移时,将变为Active状态的NameNode获得写入JournalNodes的权限,这会有效防止其他NameNode的Active状态,使得切换安全进行。
关于HDFS高可用性方案的更多信息,可参考如下链接:
https://hadoop.apache.org/docs/r3.3.1/hadoop-project-dist/hadoophdfs/HDFSHighAvailabilityWithQJM.html
六、HDFS和HBase的关系
HDFS是Apache的Hadoop项目的子项目,HBase利用Hadoop HDFS作为其文件存储系统。HBase位于结构化存储层,Hadoop HDFS为HBase提供了高可靠性的底层存储支持。除了HBase产生的一些日志文件,HBase中的所有数据文件都可以存储在Hadoop HDFS文件系统上。
七、HDFS和MapReduce的关系
- HDFS是Hadoop分布式文件系统,具有高容错和高吞吐量的特性,可以部署在价格低廉的硬件上,存储应用程序的数据,适合有超大数据集的应用程序。
- 而MapReduce是一种编程模型,用于大数据集(大于1TB)的并行运算。在MapReduce程序中计算的数据可以来自多个数据源,如Local FileSystem、HDFS、数据库等。最常用的是HDFS,可以利用HDFS的高吞吐性能读取大规模的数据进行计算。同时在计算完成后,也可以将数据存储到HDFS。
八、HDFS和Spark的关系
通常,Spark中计算的数据可以来自多个数据源,如Local File、HDFS等。最常用的是HDFS,用户可以一次读取大规模的数据进行并行计算。在计算完成后,也可以将数据存储到HDFS。
分解来看,Spark分成控制端(Driver)和执行端(Executor)。控制端负责任务调度,执行端负责任务执行。
读取文件的过程如下图所示。
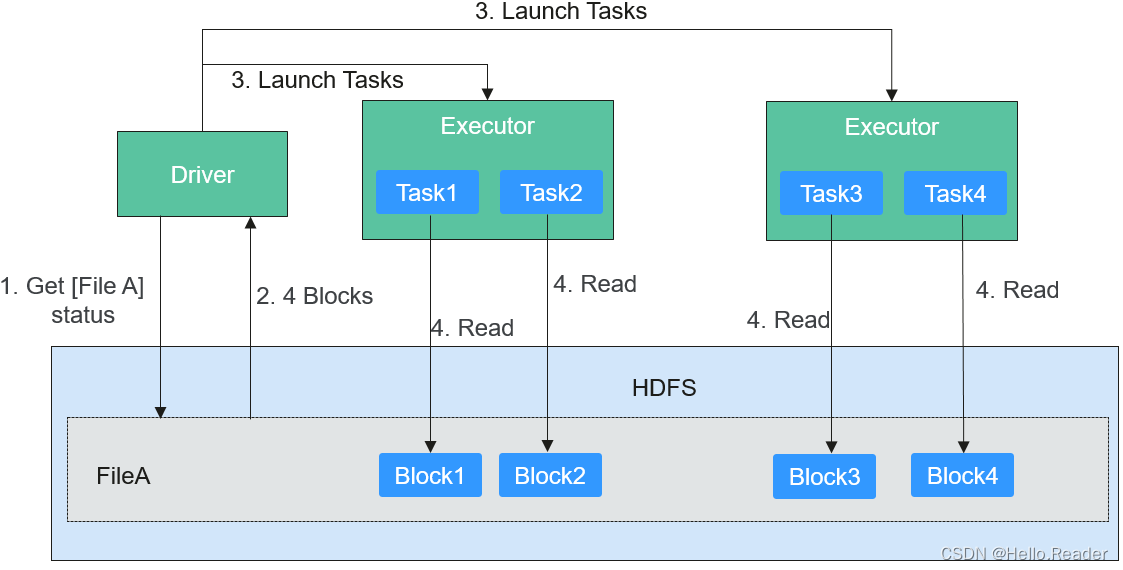
读取文件步骤的详细描述如下所示:
- Driver与HDFS交互获取File A的文件信息。
- HDFS返回该文件具体的Block信息。
- Driver根据具体的Block数据量,决定一个并行度,创建多个Task去读取这些文件Block。
- 在Executor端执行Task并读取具体的Block,作为RDD(弹性分布数据集)的一部分。
写入文件的过程如下图所示。
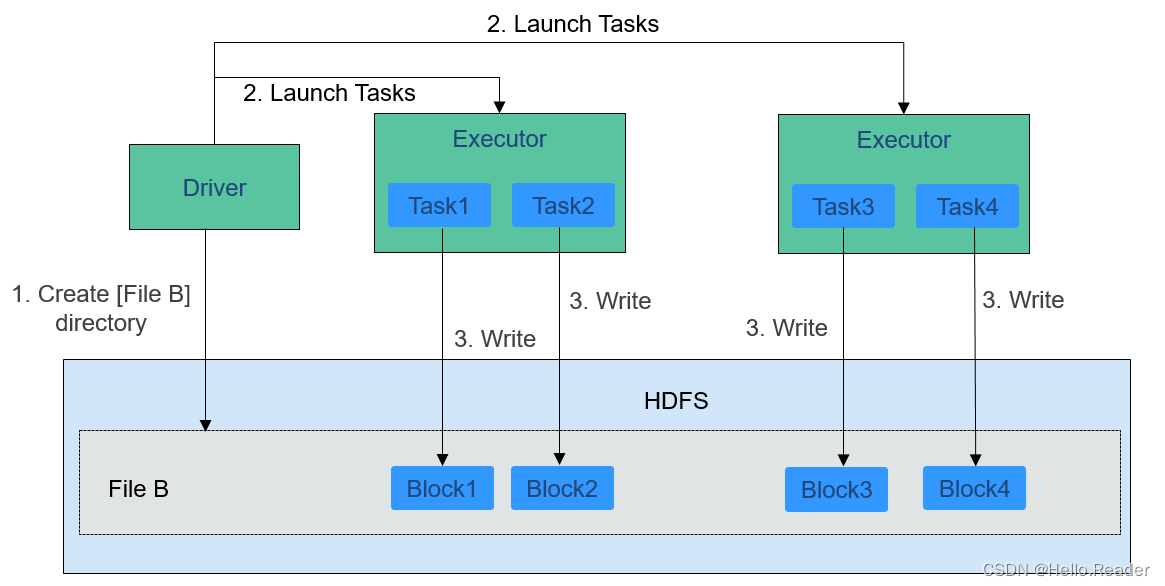
HDFS文件写入的详细步骤如下所示:
- Driver创建要写入文件的目录。
- 根据RDD分区分块情况,计算出写数据的Task数,并下发这些任务到Executor。
- Executor执行这些Task,将具体RDD的数据写入到步骤1创建的目录下。
九、HDFS和ZooKeeper的关系
ZooKeeper与HDFS的关系如下图所示
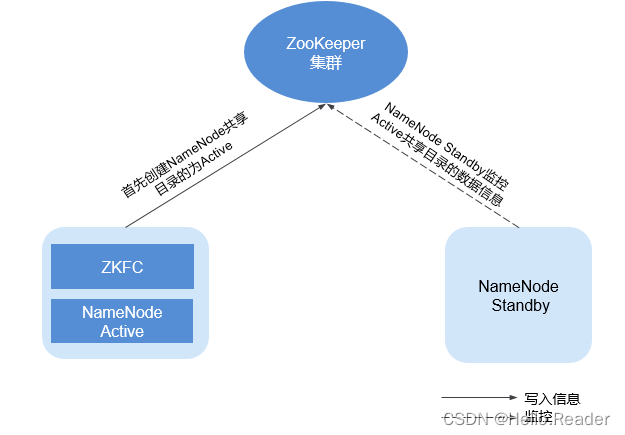
ZKFC(ZKFailoverController)作为一个ZooKeeper集群的客户端,用来监控NameNode的状态信息。ZKFC进程仅在部署了NameNode的节点中存在。HDFS NameNode的Active和Standby节点均部署有zkfc进程。
- HDFS NameNode的ZKFC连接到ZooKeeper,把主机名等信息保存到ZooKeeper中,即“/hadoop-ha”下的znode目录里。先创建znode目录的NameNode节点为主节点,另一个为备节点。HDFS NameNode Standby通过ZooKeeper定时读取NameNode信息。
- 当主节点进程异常结束时,HDFS NameNode Standby通过ZooKeeper感知“/hadoop-ha”目录下发生了变化,NameNode会进行主备切换。
相关文章:
HDFS原理剖析
一、概述 HDFS是Hadoop的分布式文件系统(Hadoop Distributed File System),实现大规模数据可靠的分布式读写。HDFS针对的使用场景是数据读写具有“一次写,多次读”的特征,而数据“写”操作是顺序写,也就是…...

css学习2(利用id与class修改元素)
1、id选择器可以为标有特定id的html元素指定特定的样式。 2、选择器以#开头,后跟某id的属性值。 3、class选择器用于描述一组元素的样式,class可以在多个元素使用。 4、类选择器用.选择。 5、指定特定的元素使用class。 6、元素的多个类用空格分开&…...
安装python的不同版本例如3.8)
wsl2(debian)安装python的不同版本例如3.8
要在Debian上安装 Python 3.8,可以按照以下步骤操作: 1.确保你的 Debian 系统已经更新到最新版本,可以使用以下命令更新: sudo apt update sudo apt upgrade2.安装 Python 3.8 的依赖项,以及构建 Python 时需要的工具…...
——Python变量类型列表list的用法介绍)
Python教程(9)——Python变量类型列表list的用法介绍
列表操作 创建列表访问列表更改列表元素增加列表元素修改列表元素删除列表元素 删除列表 在Python中,列表(list)是一种有序、可变的数据结构,用于存储多个元素。列表可以包含不同类型的元素,包括整数、浮点数、字符串等…...
springboot+VUE智慧公寓管理系统java web酒店民宿房屋住宿报修信息jsp源代码
本项目为前几天收费帮学妹做的一个项目,Java EE JSP项目,在工作环境中基本使用不到,但是很多学校把这个当作编程入门的项目来做,故分享出本项目供初学者参考。 一、项目描述 springbootVUE智慧公寓管理系统 系统有2权限…...

神经网络基础-神经网络补充概念-36-dropout正则化
概念 Dropout 是一种常用的正则化技术,用于减少深度神经网络中的过拟合问题。它在训练过程中随机地将一部分神经元的输出置为零,从而强制模型在训练过程中学习多个独立的子模型,从而减少神经元之间的依赖关系,提高模型的泛化能力…...

Go语言基础之变量和常量
标识符与关键字 标识符 在编程语言中标识符就是程序员定义的具有特殊意义的词,比如变量名、常量名、函数名等等。 Go语言中标识符由字母数字和_(下划线)组成,并且只能以字母和_开头。 举几个例子:abc, _, _123, a123 关键字 关…...

Spring Boot 项目实现 Spring AOP
【注】实现在SpringBoot项目中,同时给两个类的方法添加AOP前置通知 1、创建一个SpringBoot项目 2、创建两个目标类和方法 package com.tqazy.learn_spring_project.spring_aop;import org.springframework.stereotype.Service;/*** ClassName SpringAopUserServi…...
Baumer工业相机堡盟工业相机如何通过BGAPISDK设置相机的固定帧率(C#)
Baumer工业相机堡盟工业相机如何通过BGAPI SDK设置相机的固定帧率(C#) Baumer工业相机Baumer工业相机的固定帧率功能的技术背景CameraExplorer如何查看相机固定帧率功能在BGAPI SDK里通过函数设置相机固定帧率 Baumer工业相机通过BGAPI SDK设置相机固定帧…...

js拼接字符串
在js中,你可以使用字符串拼接的方式创建新的字符串。 下面是一些常用的方法: 1、使用运算符: var str1 "Hello"; var str2 "World"; var result str1 " " str2; console.log(result); // 输出…...

神经网络基础-神经网络补充概念-37-其他正则化方法
概念 L1 正则化(Lasso Regularization):L1 正则化通过在损失函数中添加参数的绝对值之和作为惩罚项,促使部分参数变为零,实现特征选择。适用于稀疏性特征选择问题。 L2 正则化(Ridge Regularization&…...

掌握Python的X篇_36_定义类、名称空间
本篇将会重新回到python语法的主线,并且开展新的篇章,那就是面向对象的编程。 文章目录 1. 面向对象2. 定义类3. 类的名称空间性质 1. 面向对象 面向对象是一种编程的思想,并不是限制在某一种语言上的,不同语言面向对象的表达能力…...

回归预测 | MATLAB实现GRU门控循环单元多输入多输出
回归预测 | MATLAB实现GRU门控循环单元多输入多输出 目录 回归预测 | MATLAB实现GRU门控循环单元多输入多输出预测效果基本介绍程序设计往期精彩参考资料 预测效果 基本介绍 MATLAB实现GRU门控循环单元多输入多输出,数据为多输入多输出预测数据,输入10个…...
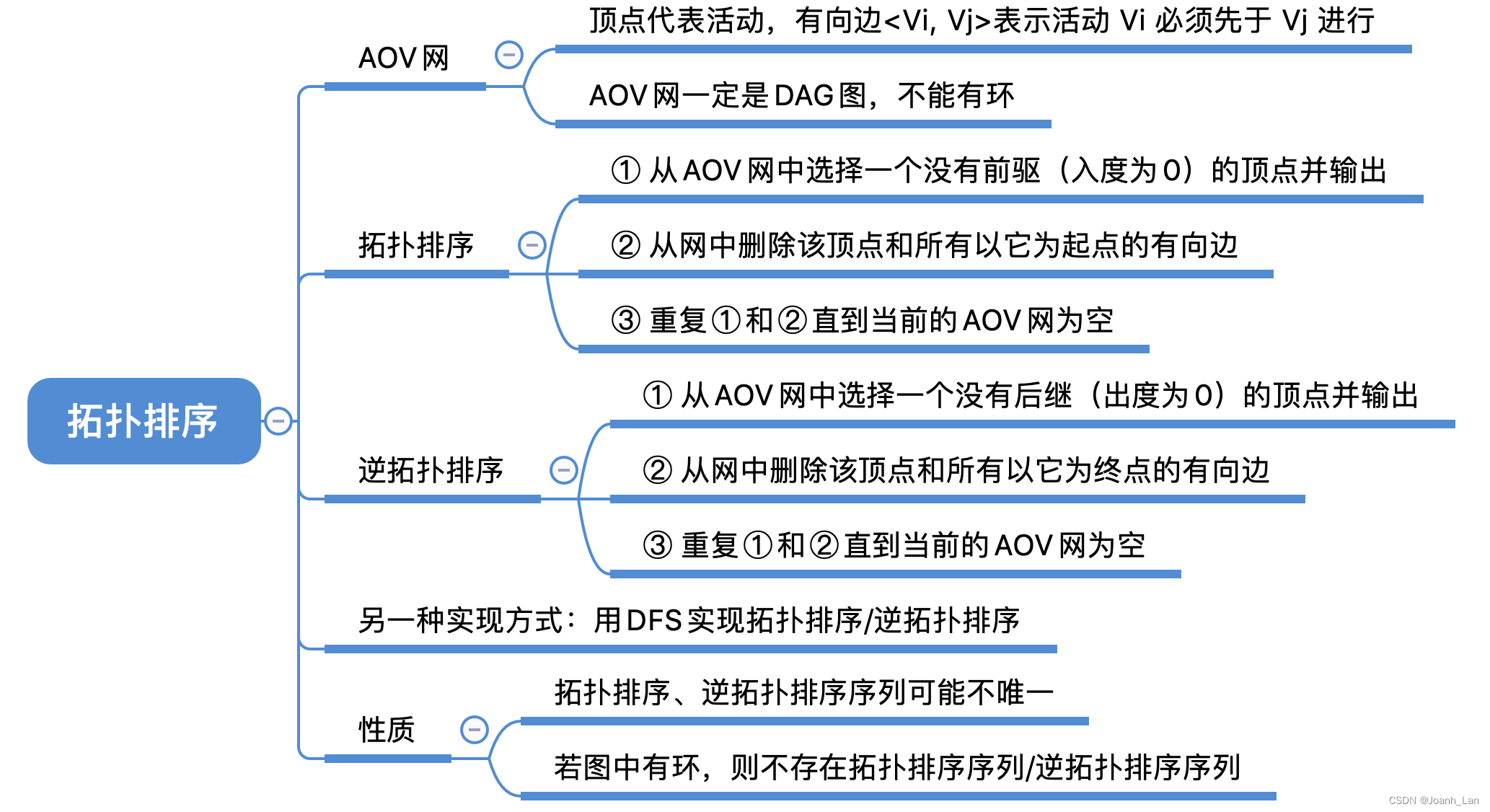
数据结构--拓扑排序
数据结构–拓扑排序 AOV⽹ A O V ⽹ \color{red}AOV⽹ AOV⽹(Activity On Vertex NetWork,⽤顶点表示活动的⽹): ⽤ D A G 图 \color{red}DAG图 DAG图(有向⽆环图)表示⼀个⼯程。顶点表示活动,有向边 < V i , V j …...

算法竞赛备赛之搜索与图论训练提升,暑期集训营培训
目录 1.DFS和BFS 1.1.DFS深度优先搜索 1.2.BFS广度优先搜索 2.树与图的遍历:拓扑排序 3.最短路 3.1.迪杰斯特拉算法 3.2.贝尔曼算法 3.3.SPFA算法 3.4.多源汇最短路Floy算法 4.最小生成树 4.1.普利姆算法 4.2.克鲁斯卡尔算法 5.二分图:染色法…...
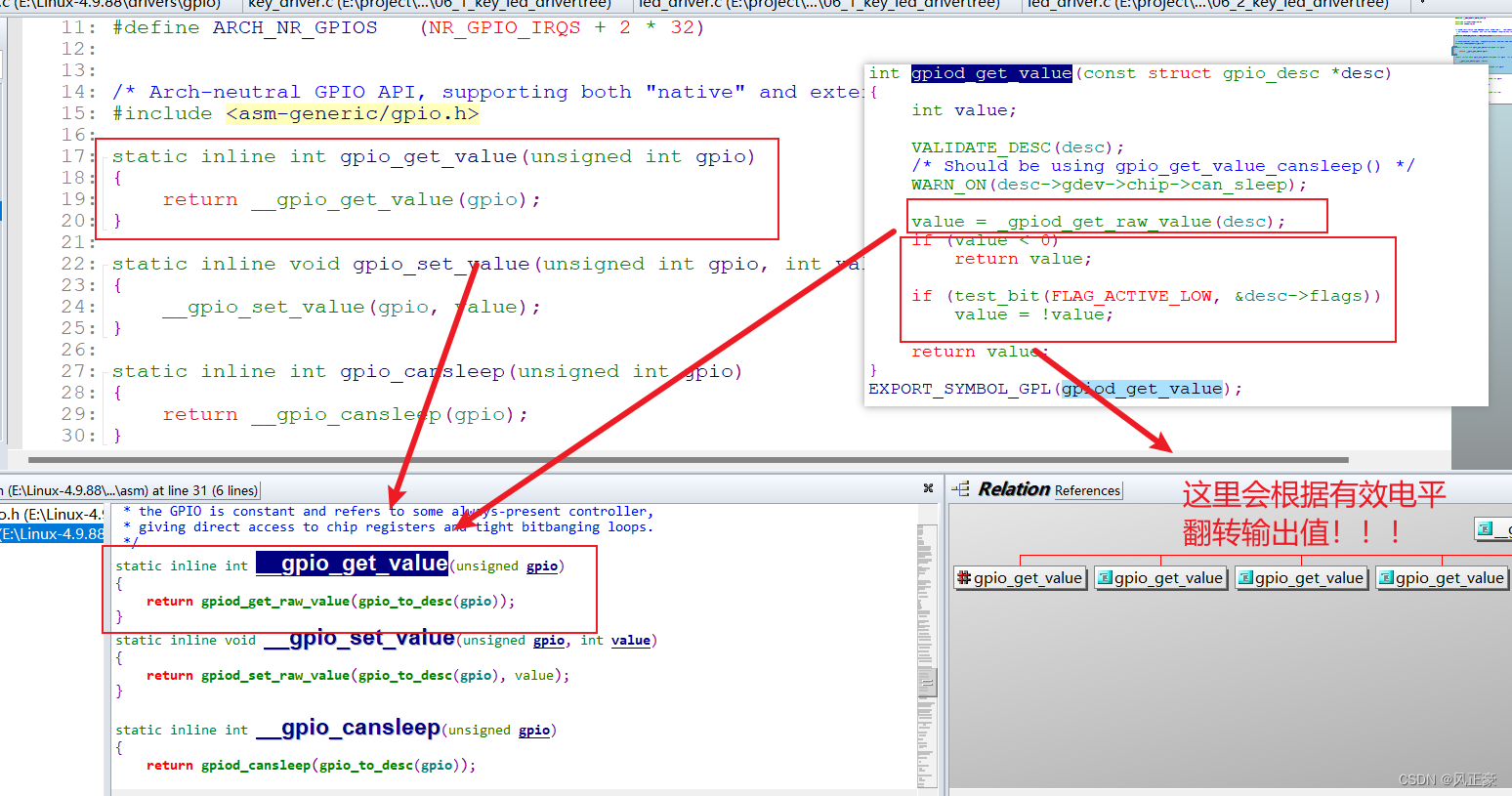
Linux驱动入门(6.2)按键驱动和LED驱动 --- 将逻辑电平与物理电平分离
前言 (1)在学习完Linux驱动入门(6)LED驱动—设备树之后,我们发现一个问题,设备树明明的gpios信息明明有三个元素gpios <&gpio5 3 GPIO_ACTIVE_LOW>; &gpio5 3 用来确定控制那个引脚…...
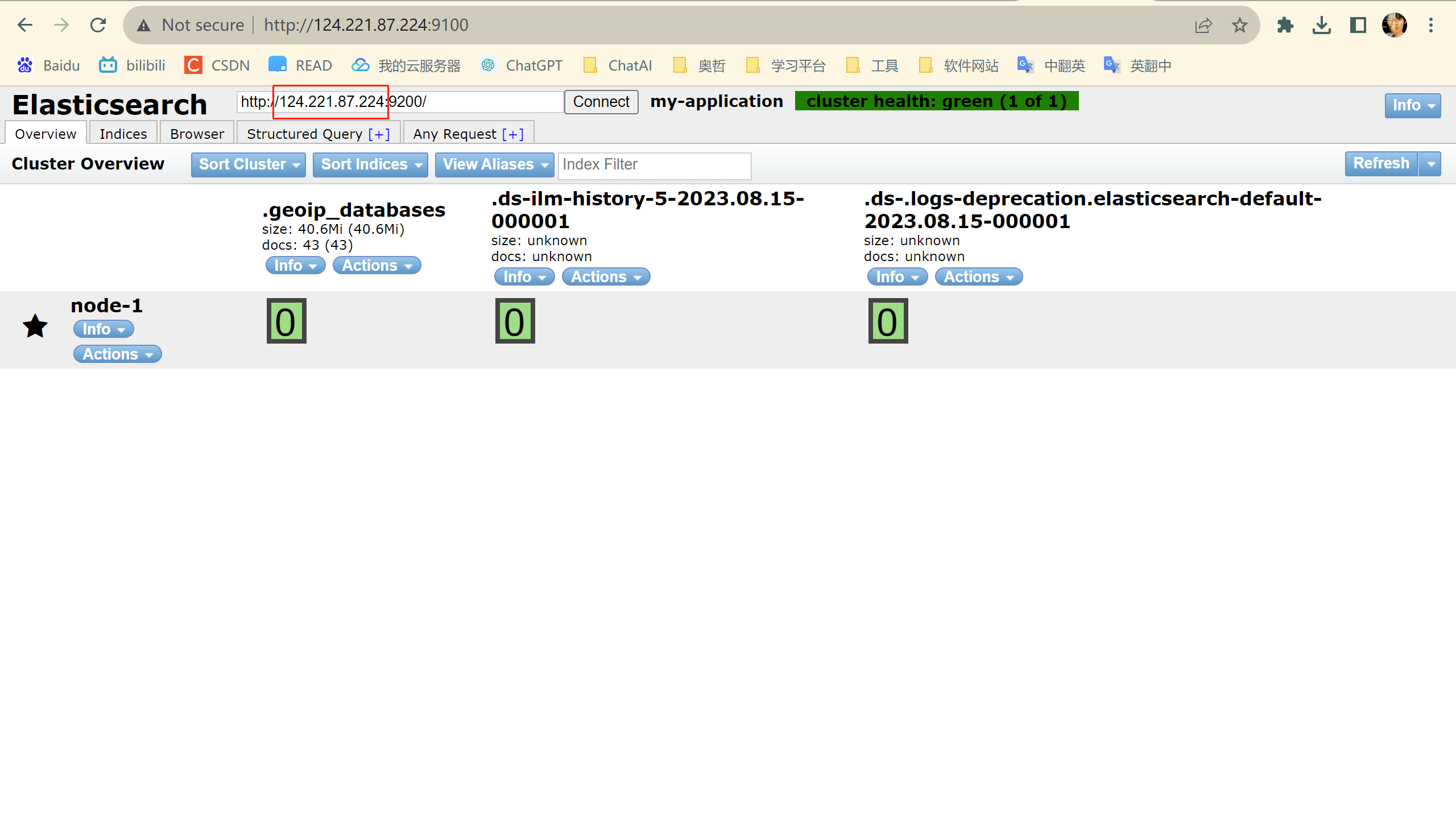
CentOS系统环境搭建(十四)——CentOS7.9安装elasticsearch-head
centos系统环境搭建专栏🔗点击跳转 关于node的安装请看上一篇CentOS系统环境搭建(十三)——CentOS7安装nvm,🔗点击跳转。 CentOS7.9安装elasticsearch-head 文章目录 CentOS7.9安装elasticsearch-head1.下载2.解压3.修…...
设计HTML5图像和多媒体
在网页中的文本信息直观、明了,而多媒体信息更富内涵和视觉冲击力。恰当使用不同类型的多媒体可以展示个性,突出重点,吸引用户。在HTML5之前,需要借助插件为网页添加多媒体,如Adobe Flash Player、苹果的QuickTime等。…...

基于YOLOv8模型和Caltech数据集的行人检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要 基于YOLOv8模型和Caltech数据集的行人检测系统可用于日常生活中检测与定位行人,利用深度学习算法可实现图片、视频、摄像头等方式的行人目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算法训练数据集…...

Flutter 宽高自适应
在Flutter开发中也需要宽高自适应,手动写一个工具类,集成之后在像素后面直接使用 px或者 rpx即可。 工具类代码如下: import dart:ui;class HYSizeFit {static double screenWidth 0.0;static double screenHeight 0.0;static double phys…...

2025届必备的五大AI辅助论文助手推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在当下人工智能范畴里身为重要参与者的DeepSeek,它所产出的论文常常展现出严谨的…...

华为擎云L420变身MCU开发主力机:VSCode + Cortex-Debug + 自编译工具链玩转雅特力AT32
华为擎云L420打造高效MCU开发环境:VSCodeCortex-Debug全流程实战 在嵌入式开发领域,效率工具的选择往往能决定项目的成败。当国产化浪潮席卷技术圈,越来越多的开发者开始尝试在纯国产硬件上构建完整的工作流。华为擎云L420作为一款基于ARM架构…...

CVPR2021明星算法LoFTR实战:在Ubuntu 20.04上从零搭建Python 3.7+Pytorch 1.6.0环境,跑通第一个图像匹配Demo
CVPR2021明星算法LoFTR实战:在Ubuntu 20.04上从零搭建Python 3.7Pytorch 1.6.0环境,跑通第一个图像匹配Demo 计算机视觉领域每年都会涌现出大量创新算法,而CVPR2021上发表的LoFTR(Detector-Free Local Feature Matching with Tran…...

3分钟解决Windows热键冲突:Hotkey Detective完全使用指南
3分钟解决Windows热键冲突:Hotkey Detective完全使用指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否…...

如何快速解锁WeMod高级功能:面向游戏玩家的完整免费方案
如何快速解锁WeMod高级功能:面向游戏玩家的完整免费方案 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否为WeMod免费版的诸多限制感到…...

NTN 长距离通信领域亮相
核心蜂窝解决方案亮相并带来Nordic NTN 核心解决方案深度分享。环节将全面解析 nRF9151 模组的核心特性与技术优势,详解卫星星座生态布局及 nRFCloud 平台的应用价值,为参会者勾勒 NTN 技术的整体框架与商业落地前景,为后续内容奠定专业基础。…...

【NotebookLM知识图谱构建权威白皮书】:基于127个企业POC验证的4层语义对齐框架
更多请点击: https://intelliparadigm.com 第一章:NotebookLM知识图谱构建概览 NotebookLM 是 Google 推出的面向研究者与开发者、基于用户自有文档构建可推理知识体的 AI 工具。其核心能力并非依赖通用语料,而是围绕上传文档(PD…...

别再乱设K值了!用sklearn的KFold做交叉验证,这3个参数和5个坑你必须知道
别再乱设K值了!用sklearn的KFold做交叉验证,这3个参数和5个坑你必须知道 交叉验证是机器学习模型评估的黄金标准,而K折交叉验证(KFold)作为其中最常用的方法,看似简单却暗藏玄机。许多数据科学家在Kaggle竞…...

Linux内核PCIe热插拔驱动开发实战:从IDT芯片到稳定运行
1. 项目概述与核心价值最近在搞一个嵌入式设备项目,需要实现PCIe设备的热插拔支持。这玩意儿在服务器、存储阵列和工业控制领域太常见了,但真要在Linux内核里把它做稳定、做可靠,里面的门道可不少。我这次折腾的,就是一个基于Linu…...

Apache RocketMQ 5.0 架构解析:如何基于云原生架构支撑多元化场景
本文将从技术角度了解 RocketMQ 的云原生架构,了解 RocketMQ 如何基于一套统一的架构支撑多元化的场景。 文章主要包含三部分内容。首先介绍 RocketMQ 5.0 的核心概念和架构概览;然后从集群角度出发,从宏观视角学习 RocketMQ 的管控链路、数…...