3. 爬取自己CSDN博客列表(自动方式)(分页查询)(网站反爬虫策略,需要在代码中添加合适的请求头User-Agent,否则response返回空)
文章目录
- 步骤
- 打开谷歌浏览器
- 输入网址
- 按F12进入调试界面
- 点击网络,清除历史消息
- 按F5刷新页面
- 找到接口(community/home-api/v1/get-business-list)
- 接口解读
- 撰写代码获取博客列表
- 先明确返回信息格式
- json字段解读
- Apipost测试接口
- 编写python代码(注意有反爬虫策略,需要设置请求头)(成功)
1. 如何爬取自己的CSDN博客文章列表(获取列表)(博客列表)(手动+python代码方式)
2. 获取自己CSDN文章列表并按质量分由小到大排序(文章质量分、博客质量分、博文质量分)(阿里云API认证)
步骤
打开谷歌浏览器
输入网址
https://dontla.blog.csdn.net/?type=blog
按F12进入调试界面
点击网络,清除历史消息
按F5刷新页面
找到接口(community/home-api/v1/get-business-list)
https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=&noMore=false&year=&month=&username=Dontla
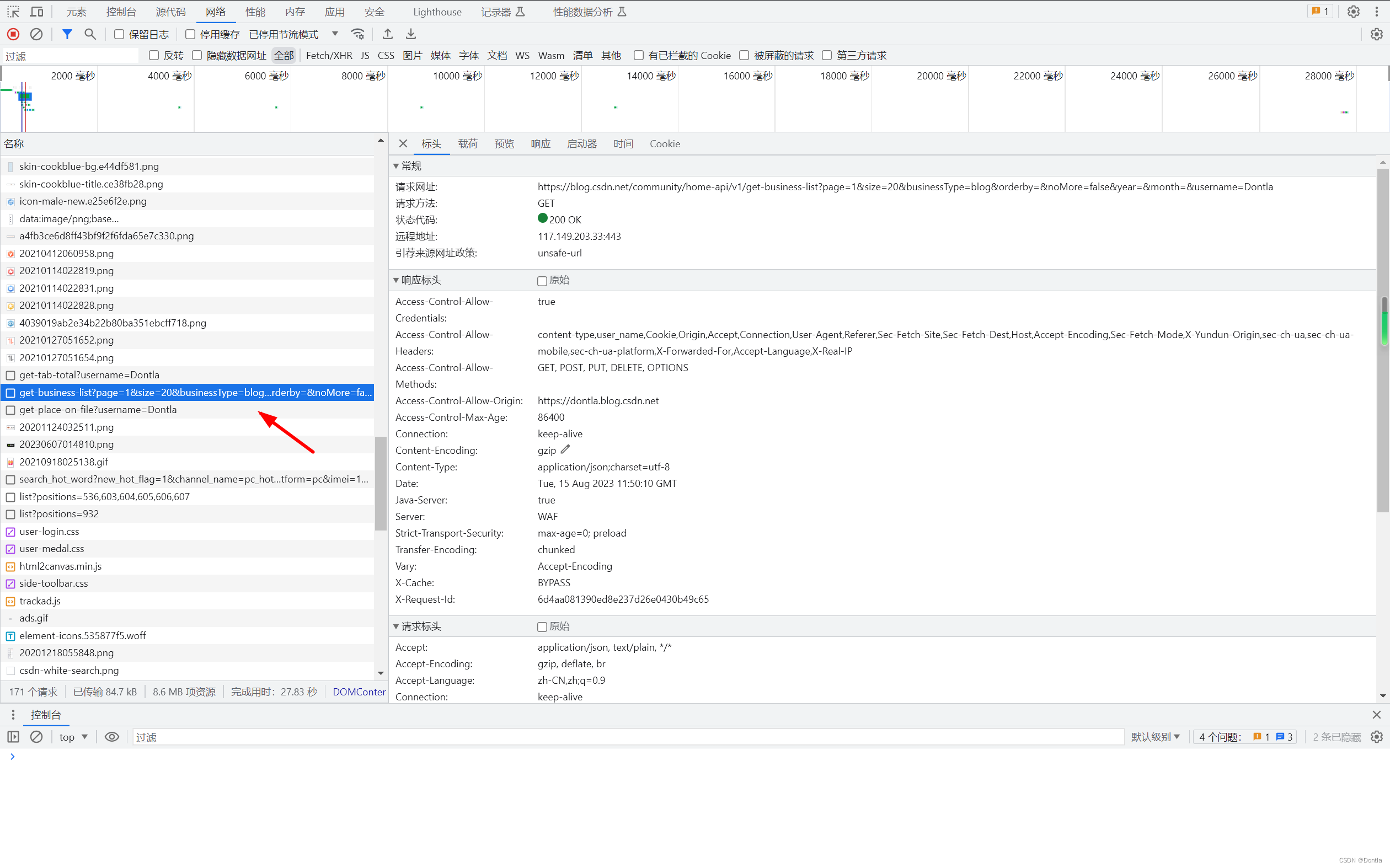
接口解读
https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=&noMore=false&year=&month=&username=Dontla
https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=&noMore=false&year=&month=&username=Dontla
这是一个HTTP GET请求的接口,用于获取CSDN博客网站上的业务列表信息。具体来说,它是用于获取某个用户的博客文章列表。让我们逐个分析URL中的参数:
-
page=1:这个参数表示请求的页面编号,设为1意味着请求第一页的数据。
-
size=20:这个参数表示每页显示的记录数。这里,每页显示20条记录。
-
businessType=blog:这个参数指定了业务类型,此处为"blog",所以它应该是用来获取博客文章的。
-
orderby=:这个参数应该是用来指定排序方式的,但在这个请求中并没有具体值,可能默认为某种排序方式,如按发布时间降序等。
-
noMore=false:这个参数可能是用来判断是否还有更多的记录可以获取。如果设置为false,表示可能还有更多的记录。
-
year= & month=:这两个参数可能是用来筛选特定年份和月份的博客文章,但在这个请求中并没有具体值,因此可能会返回所有时间段的文章。
-
username=Dontla:这个参数指定了用户名,意味着这个请求可能用来获取名为"Dontla"的用户的博客文章列表。
撰写代码获取博客列表
先明确返回信息格式
我们将https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=1&businessType=blog&orderby=&noMore=false&year=&month=&username=Dontla拷贝到浏览器url栏打开:

全选拷贝,将文字粘贴到编辑器并格式化:

{“code”:200,“message”:“success”,“traceId”:“47d3f9ad-bfc0-4604-b386-48b0e0b40c8d”,“data”:{“list”:[{“articleId”:132295415,“title”:“shellcheck警告:Declare and assign separately to avoid masking return values.shellcheck(SC2155)”,“description”:“ShellCheck的SC2155警告是关于在shell脚本中正确处理命令返回值的一个重要提示。通过将声明和赋值分开进行,我们可以确保命令的返回值不会被误导,并且在命令执行失败时,脚本能够正确地捕获并处理错误。”,“url”:“https://dontla.blog.csdn.net/article/details/132295415”,“type”:1,“top”:false,“forcePlan”:false,“viewCount”:8,“commentCount”:0,“editUrl”:“https://editor.csdn.net/md?articleId=132295415”,“postTime”:“2023-08-15 13:16:23”,“diggCount”:0,“formatTime”:“8 小时前”,“picList”:[“https://img-blog.csdnimg.cn/a0eb894421994488a27fd20a767d00de.png”],“collectCount”:0}],“total”:2557}}

{"code": 200,"message": "success","traceId": "47d3f9ad-bfc0-4604-b386-48b0e0b40c8d","data": {"list": [{"articleId": 132295415,"title": "shellcheck警告:Declare and assign separately to avoid masking return values.shellcheck(SC2155)","description": "ShellCheck的SC2155警告是关于在shell脚本中正确处理命令返回值的一个重要提示。通过将声明和赋值分开进行,我们可以确保命令的返回值不会被误导,并且在命令执行失败时,脚本能够正确地捕获并处理错误。","url": "https://dontla.blog.csdn.net/article/details/132295415","type": 1,"top": false,"forcePlan": false,"viewCount": 8,"commentCount": 0,"editUrl": "https://editor.csdn.net/md?articleId=132295415","postTime": "2023-08-15 13:16:23","diggCount": 0,"formatTime": "8 小时前","picList": ["https://img-blog.csdnimg.cn/a0eb894421994488a27fd20a767d00de.png"],"collectCount": 0}],"total": 2557}
}
目前已知的是:原创对应type值为1,转载对应为2。
json字段解读
这是一个JSON格式的HTTP响应,用于传输具体的数据信息。以下是对每个字段的解读:
-
code: 这是HTTP响应状态码,200通常表示请求成功。
-
message: 这是响应的描述信息,"success"表示请求处理成功。
-
traceId: 这可能是此次请求的唯一标识符,用于追踪和调试。
-
data: 这是实际返回的数据对象,包含以下字段:
- list: 这是一个数组,包含请求的业务列表。由于在请求中指定了
size=1,所以此处只有一个对象。该对象包含以下属性:- articleId: 文章的唯一标识符。
- title: 文章的标题。
- description: 文章的描述。
- url: 文章的网址链接。
- type: 文章的类型,具体代表什么需要参考API文档或者询问API提供者。
- top: 是否置顶,false表示未置顶。
- forcePlan: 不清楚这个字段的具体含义,可能需要参考API文档或者询问API提供者。
- viewCount: 文章的浏览次数。
- commentCount: 文章的评论数量。
- editUrl: 编辑文章的链接。
- postTime: 文章的发布时间。
- diggCount: 文章的点赞数。
- formatTime: 格式化后的发布时间。
- picList: 文章中的图片列表。
- collectCount: 文章的收藏数量。
- total: 在满足请求条件(如用户名、业务类型等)的情况下,总的记录数量。
- list: 这是一个数组,包含请求的业务列表。由于在请求中指定了
综上,这个JSON响应表示成功获取了用户"Dontla"的博客文章列表(因为设置了size=1,所以只返回了一个结果)。该用户共有2557篇博客文章,最新的一篇文章的标题、描述、链接、类型、浏览次数、评论数量、编辑链接、发布时间、点赞数、图片列表和收藏数量都在响应中给出。
点赞为什么是digg?
digg"这个词在网络社区中经常被用来表示“点赞”或者“投票”。这个词的来源是一家名为Digg的美国新闻网站,用户可以对他们喜欢的文章进行“digg”,也就是投票,最受欢迎的文章会被推送到首页。因此,"digg"在很多网站和应用中都被用作代表用户点赞或者投票的动作。
Apipost测试接口
GET https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=1&businessType=blog&orderby=&noMore=false&year=&month=&username=Dontla
(Apipost接口元数据)
{"parent_id": "0","project_id": "-1","target_id": "fdb84824-e558-48f1-9456-219ea5e9950e","target_type": "api","name": "新建接口","sort": 1,"version": 0,"mark": "developing","create_dtime": 1692028800,"update_dtime": 1692109242,"update_day": 1692028800000,"status": 1,"modifier_id": "-1","method": "GET","mock": "{}","mock_url": "/community/home-api/v1/get-business-list","url": "https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=&noMore=false&year=&month=&username=Dontla","request": {"url": "https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=&noMore=false&year=&month=&username=Dontla","description": "","auth": {"type": "noauth","kv": {"key": "","value": ""},"bearer": {"key": ""},"basic": {"username": "","password": ""},"digest": {"username": "","password": "","realm": "","nonce": "","algorithm": "","qop": "","nc": "","cnonce": "","opaque": ""},"hawk": {"authId": "","authKey": "","algorithm": "","user": "","nonce": "","extraData": "","app": "","delegation": "","timestamp": "","includePayloadHash": -1},"awsv4": {"accessKey": "","secretKey": "","region": "","service": "","sessionToken": "","addAuthDataToQuery": -1},"ntlm": {"username": "","password": "","domain": "","workstation": "","disableRetryRequest": 1},"edgegrid": {"accessToken": "","clientToken": "","clientSecret": "","nonce": "","timestamp": "","baseURi": "","headersToSign": ""},"oauth1": {"consumerKey": "","consumerSecret": "","signatureMethod": "","addEmptyParamsToSign": -1,"includeBodyHash": -1,"addParamsToHeader": -1,"realm": "","version": "1.0","nonce": "","timestamp": "","verifier": "","callback": "","tokenSecret": "","token": ""}},"body": {"mode": "none","parameter": [],"raw": "","raw_para": [],"raw_schema": {"type": "object"}},"event": {"pre_script": "","test": ""},"header": {"parameter": []},"query": {"parameter": [{"description": "","is_checked": 1,"key": "page","type": "Text","not_null": 1,"field_type": "String","value": "1"},{"description": "","is_checked": 1,"key": "size","type": "Text","not_null": 1,"field_type": "String","value": "20"},{"description": "","is_checked": 1,"key": "businessType","type": "Text","not_null": 1,"field_type": "String","value": "blog"},{"description": "","is_checked": 1,"key": "orderby","type": "Text","not_null": 1,"field_type": "String","value": ""},{"description": "","is_checked": 1,"key": "noMore","type": "Text","not_null": 1,"field_type": "String","value": "false"},{"description": "","is_checked": 1,"key": "year","type": "Text","not_null": 1,"field_type": "String","value": ""},{"description": "","is_checked": 1,"key": "month","type": "Text","not_null": 1,"field_type": "String","value": ""},{"description": "","is_checked": 1,"key": "username","type": "Text","not_null": 1,"field_type": "String","value": "Dontla"}]},"cookie": {"parameter": []},"resful": {"parameter": []}},"response": {"success": {"raw": "","parameter": [],"expect": {"name": "成功","isDefault": 1,"code": 200,"contentType": "json","verifyType": "schema","mock": "","schema": {}}},"error": {"raw": "","parameter": [],"expect": {"name": "失败","isDefault": -1,"code": 404,"contentType": "json","verifyType": "schema","mock": "","schema": {}}}},"is_first_match": 1,"ai_expect": {"list": [],"none_math_expect_id": "error"},"enable_ai_expect": -1,"enable_server_mock": -1,"is_example": -1,"is_locked": -1,"is_check_result": 1,"check_result_expectId": "","is_changed": -1,"is_saved": -1
}
编写python代码(注意有反爬虫策略,需要设置请求头)(成功)
网站反爬虫策略:一些网站会通过识别请求头(User-Agent)来判断是否为机器人行为。解决方法是添加合适的请求头:
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36"
}
response = requests.get(url, headers=headers)完整代码:
import requests
import json# 定义变量存储所有文章信息
articles = []# 设置初始分页
page = 1# 设置每页查询数量
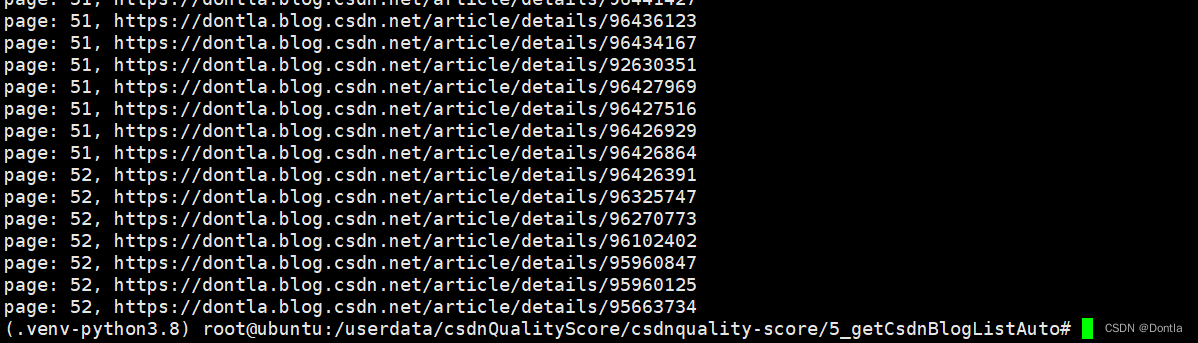
page_size = 50while True:# 构建请求urlurl = f"https://blog.csdn.net/community/home-api/v1/get-business-list?page={page}&size={page_size}&businessType=blog&orderby=&noMore=false&year=&month=&username=Dontla"# 发送GET请求# response = requests.get(url)# 防止反爬虫策略headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36"}response = requests.get(url, headers=headers)# 如果请求成功if response.status_code == 200:# print(f'response.content: {response.content}')# print(f'response.text: {response.text}')# 检查响应是否为空if response.text:# 解析JSON响应try:data = response.json()except json.JSONDecodeError:print(f"Error parsing JSON: {response.text}")break# 遍历每个文章for article in data['data']['list']:print(f"page: {page}, {article['url']}")# 获取并保存需要的信息articles.append({'title': article['title'],'url': article['url'],'type': article['type'],'postTime': article['postTime']})# 判断是否还有更多文章,如果没有则结束循环if len(data['data']['list']) < page_size:break# 增加分页数以获取下一页的文章page += 1else:print("Response is empty")breakelse:print(f"Error: {response.status_code}")break# 将结果保存为json文件
with open('articles.json', 'w') as f:json.dump(articles, f, ensure_ascii = False, indent = 4)注意,最大单次查询上限为100,我一开始把每页查询数量page_size设置成200,发现不行,后来设置成100以下就ok了,为了保证速度,我就设置成100:
这是代码运行结果:
这是生成的j’son文件:
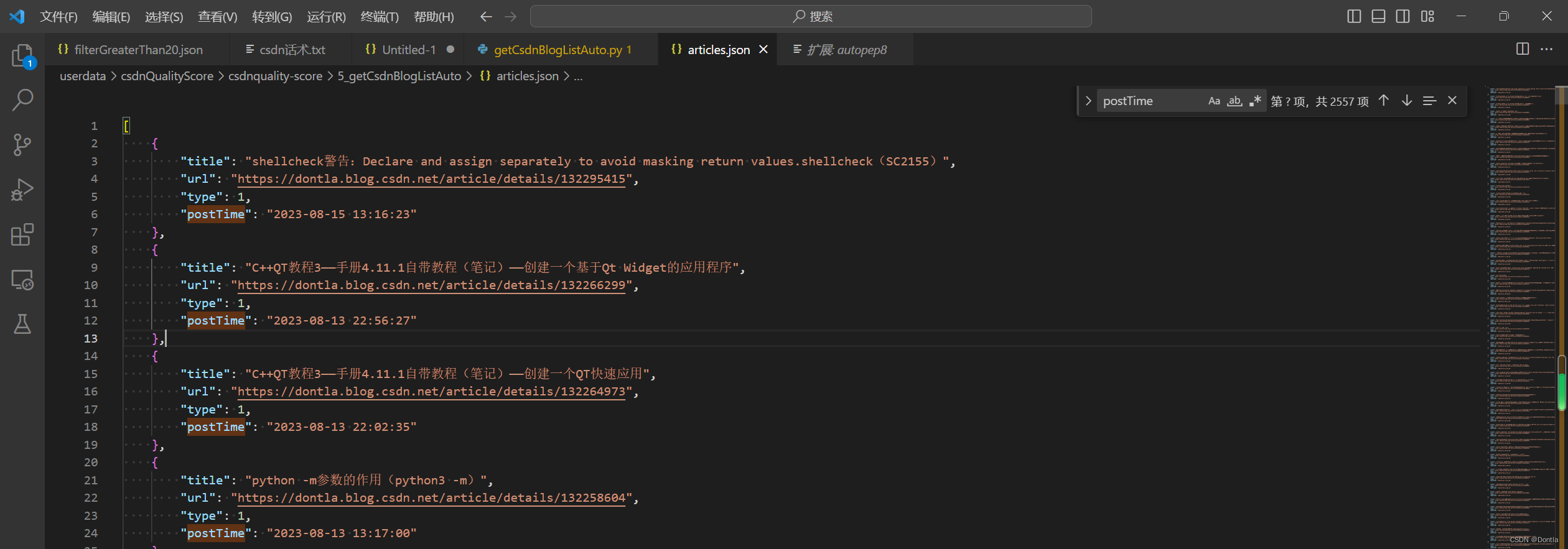
总共2557个元素,跟我的博文数量相符:
相关文章:
3. 爬取自己CSDN博客列表(自动方式)(分页查询)(网站反爬虫策略,需要在代码中添加合适的请求头User-Agent,否则response返回空)
文章目录 步骤打开谷歌浏览器输入网址按F12进入调试界面点击网络,清除历史消息按F5刷新页面找到接口(community/home-api/v1/get-business-list)接口解读 撰写代码获取博客列表先明确返回信息格式json字段解读 Apipost测试接口编写python代码…...

利用HTTP代理实现请求路由
嘿,大家好!作为一名专业的爬虫程序员,我知道构建一个高效的分布式爬虫系统是一个相当复杂的任务。在这个过程中,实现请求的路由是非常关键的。今天,我将和大家分享一些关于如何利用HTTP代理实现请求路由的实用技巧&…...
深度学习(36)—— 图神经网络GNN(1)
深度学习(36)—— 图神经网络GNN(1) 这个系列的所有代码我都会放在git上,欢迎造访 文章目录 深度学习(36)—— 图神经网络GNN(1)1. 基础知识2.使用场景3. 图卷积神经网…...

深入理解JVM——垃圾回收与内存分配机制详细讲解
所谓垃圾回收,也就是要回收已经“死了”的对象。 那我们如何判断哪些对象“存活”,哪些已经“死去”呢? 一、判断对象已死 1、引用计数算法 给对象中添加一个引用计数器,每当有一个地方引用它时,计数器就加一&…...
基于SSH框架实现的管理系统(包含java源码+数据库)
资料下载链接 介绍 基于SSH框架的管理系统 简洁版 ; 实现 登录 、 注册 、 增 、 删 、 改 、 查 ; 可继续完善增加前端、校验、其他功能等; 可作为 SSH(Structs Spring Hibernate)项目 开发练习基础模型…...

图像识别代做服务:实现创新应用的新契机
导言: 随着人工智能和图像处理技术的不断进步,图像识别已经成为了许多领域中的关键应用。然而,图像识别技术的开发和应用往往需要庞大的团队和大量的资源。这就是为什么图像识别代做服务正在崭露头角。本文将探讨图像识别代做服务如何成为实现…...
Coreutils工具包,Windows下使用Linux命令
之前总结过两篇有关【如何在Windows系统下使用Linux的常用命令】的文章: GnuWin32,Windows下使用Linux命令 UnxUtils工具包,Windows下使用Linux命令 今天再推荐一个类似的工具包Coreutils 一、简介 GNU core utilities是GNU操作系统基本…...

神经网络基础-神经网络补充概念-13-python中的广播
概念 在 Python 中,广播(Broadcasting)是一种用于在不同形状的数组之间执行二元操作的机制。广播允许你在不显式复制数据的情况下,对不同形状的数组进行运算。这在处理数组的时候非常有用,尤其是在科学计算、数据分析…...
HDFS原理剖析
一、概述 HDFS是Hadoop的分布式文件系统(Hadoop Distributed File System),实现大规模数据可靠的分布式读写。HDFS针对的使用场景是数据读写具有“一次写,多次读”的特征,而数据“写”操作是顺序写,也就是…...

css学习2(利用id与class修改元素)
1、id选择器可以为标有特定id的html元素指定特定的样式。 2、选择器以#开头,后跟某id的属性值。 3、class选择器用于描述一组元素的样式,class可以在多个元素使用。 4、类选择器用.选择。 5、指定特定的元素使用class。 6、元素的多个类用空格分开&…...
安装python的不同版本例如3.8)
wsl2(debian)安装python的不同版本例如3.8
要在Debian上安装 Python 3.8,可以按照以下步骤操作: 1.确保你的 Debian 系统已经更新到最新版本,可以使用以下命令更新: sudo apt update sudo apt upgrade2.安装 Python 3.8 的依赖项,以及构建 Python 时需要的工具…...
——Python变量类型列表list的用法介绍)
Python教程(9)——Python变量类型列表list的用法介绍
列表操作 创建列表访问列表更改列表元素增加列表元素修改列表元素删除列表元素 删除列表 在Python中,列表(list)是一种有序、可变的数据结构,用于存储多个元素。列表可以包含不同类型的元素,包括整数、浮点数、字符串等…...
springboot+VUE智慧公寓管理系统java web酒店民宿房屋住宿报修信息jsp源代码
本项目为前几天收费帮学妹做的一个项目,Java EE JSP项目,在工作环境中基本使用不到,但是很多学校把这个当作编程入门的项目来做,故分享出本项目供初学者参考。 一、项目描述 springbootVUE智慧公寓管理系统 系统有2权限…...

神经网络基础-神经网络补充概念-36-dropout正则化
概念 Dropout 是一种常用的正则化技术,用于减少深度神经网络中的过拟合问题。它在训练过程中随机地将一部分神经元的输出置为零,从而强制模型在训练过程中学习多个独立的子模型,从而减少神经元之间的依赖关系,提高模型的泛化能力…...

Go语言基础之变量和常量
标识符与关键字 标识符 在编程语言中标识符就是程序员定义的具有特殊意义的词,比如变量名、常量名、函数名等等。 Go语言中标识符由字母数字和_(下划线)组成,并且只能以字母和_开头。 举几个例子:abc, _, _123, a123 关键字 关…...

Spring Boot 项目实现 Spring AOP
【注】实现在SpringBoot项目中,同时给两个类的方法添加AOP前置通知 1、创建一个SpringBoot项目 2、创建两个目标类和方法 package com.tqazy.learn_spring_project.spring_aop;import org.springframework.stereotype.Service;/*** ClassName SpringAopUserServi…...
Baumer工业相机堡盟工业相机如何通过BGAPISDK设置相机的固定帧率(C#)
Baumer工业相机堡盟工业相机如何通过BGAPI SDK设置相机的固定帧率(C#) Baumer工业相机Baumer工业相机的固定帧率功能的技术背景CameraExplorer如何查看相机固定帧率功能在BGAPI SDK里通过函数设置相机固定帧率 Baumer工业相机通过BGAPI SDK设置相机固定帧…...

js拼接字符串
在js中,你可以使用字符串拼接的方式创建新的字符串。 下面是一些常用的方法: 1、使用运算符: var str1 "Hello"; var str2 "World"; var result str1 " " str2; console.log(result); // 输出…...

神经网络基础-神经网络补充概念-37-其他正则化方法
概念 L1 正则化(Lasso Regularization):L1 正则化通过在损失函数中添加参数的绝对值之和作为惩罚项,促使部分参数变为零,实现特征选择。适用于稀疏性特征选择问题。 L2 正则化(Ridge Regularization&…...

掌握Python的X篇_36_定义类、名称空间
本篇将会重新回到python语法的主线,并且开展新的篇章,那就是面向对象的编程。 文章目录 1. 面向对象2. 定义类3. 类的名称空间性质 1. 面向对象 面向对象是一种编程的思想,并不是限制在某一种语言上的,不同语言面向对象的表达能力…...

C++ inline函数深度解析:从链接属性到性能优化的实战指南
1. 项目概述:为什么我们需要关注inline函数?在C项目里,尤其是那些对性能有极致追求的系统、游戏引擎或者高频交易框架中,你经常会看到代码里散落着inline关键字。新手可能会觉得它只是个“建议编译器内联”的提示符,有…...

2026年电钢琴避坑指南|高性价比品牌型号推荐,新手必看!
电钢琴选购核心要点(快速避坑) 在推荐具体机型前,先明确4个选购关键指标,确保不踩坑: 1.键盘:必须88键逐级配重重锤键盘,避免毁手型。 2.复音数:至少128复音(避免弹奏复杂曲目时丢…...

别再傻傻用FFT了!用MATLAB的czt函数5分钟搞定频谱细化,精准定位98Hz和99Hz信号
别再被FFT分辨率坑了!MATLAB工程师的频谱细化实战指南 当你在分析一段包含98Hz和99Hz混合信号的频谱时,是否遇到过这样的尴尬:明明知道有两个频率成分存在,但FFT给出的结果却像被打了马赛克,两个峰值糊成一团…...

嘎嘎降AI和去AIGC深度对比:2026年按次计费和按篇计费哪个更划算完整评测分析
嘎嘎降AI和去AIGC深度对比:2026年按次计费和按篇计费哪个更划算完整评测分析 总有人问嘎嘎降AI,这篇文章把主流几款对比清楚。 综合推荐嘎嘎降AI(www.aigcleaner.com),4.8元,99.26%达标率。不同需求有不同…...

高通QCC3084-QCC518X蓝牙耳机项目
高通QCC3084-QCC518X蓝牙耳机项目...

XNBCLI深度解析:掌握星露谷物语XNB文件解包打包的完全手册
XNBCLI深度解析:掌握星露谷物语XNB文件解包打包的完全手册 【免费下载链接】xnbcli A CLI tool for XNB packing/unpacking purpose built for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/xn/xnbcli 想要深度定制星露谷物语游戏体验…...

避坑指南:STM32CubeMX配置高级定时器PWM时,时钟源、ARR重载和DMA传输的那些坑
STM32高级定时器PWM配置实战:从时钟陷阱到DMA优化的深度解析 引言 深夜的实验室里,示波器上跳动的波形总是不尽如人意——这可能是许多嵌入式开发者使用STM32高级定时器输出PWM时的共同经历。不同于基础定时器,高级定时器(如TIM1/…...

从 XChat 到超级 APP 生态:小程序生态为什么成为了超级APP的最佳技术选型
2026年4月17日,XChat 正式登陆苹果 App Store。 马斯克一直想做一个美国版的微信的目标已经实现:端对端加密、无广告、无追踪,注册只需要一个 X 账号,不需要手机号。马斯克给它的目标也很直接——X 要从社交平台,变成「…...

激光雷达仿真:禾赛与NVIDIA联手,如何用数字孪生重塑自动驾驶研发?
1. 项目概述:当激光雷达遇上数字孪生最近,禾赛科技和NVIDIA的合作又往前迈了一大步,这事儿在自动驾驶圈子里挺受关注的。简单来说,就是禾赛的激光雷达模型,现在可以直接在NVIDIA的DRIVE Sim仿真平台里调用了。这意味着…...

IMX8QX MEK开发板烧录实战:手把手教你从官方BSP包到定制uuu脚本的全流程
IMX8QX MEK开发板烧录实战:从BSP解析到定制化uuu脚本全指南 拿到一块崭新的IMX8QX MEK开发板时,官方提供的BSP包往往像一座未经探索的金矿——资源丰富但路径复杂。本文将带你深入这座金矿,从文件定位到脚本定制,完成一次完整的烧…...