Prompt、RAG、微调还是重新训练?选择正确的生成式 AI 的方法指南
文章目录
- 一、前言
- 二、主要内容
- 三、总结
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/
一、前言
这篇博客试图根据一些常见的可量化指标,为您选择适合您用例的生成式人工智能方法提供指导。
生成式 AI 正在以惊人的速度发展,许多组织都在尝试利用这项先进技术来解决业务问题。虽然有很多流行的方法可供选择,但是当涉及到选择正确的方法来实施生成式 AI 解决方案时,仍缺乏明确的指导。最常讨论的方法有:
- 提示工程(Prompt Engineering)
- 检索增强生成(Retrieval Augmented Generation,RAG)
- 微调(Fine-tuning)
- 从零开始训练自己的基础模型(Foundation Model)
这里不包括 “按原样使用模型” 选项,因为几乎没有任何业务用例可以有效地使用基础大模型。原封不动地使用基础大模型可以很好地用于一般搜索,但如果要做好特定的业务,则需要考虑上述选项之一。
二、主要内容
比较是如何进行的?分析是基于以下指标进行的:
- 准确性(回答的准确程度如何?)
- 实施复杂性(实施过程有多复杂?)
- 工作量(需要多少努力来实现?)
- 总拥有成本(TCO)(拥有解决方案的总成本是多少?)
- 更新和更改的便利性(架构是否耦合度低?替换 / {/} /升级组件是否容易?)
假设:我们将根据这些指标对每种解决方案进行评估,并且分析仅适用于比较,而不是普遍适用。例如:如果针对某个指标,提示工程被评为低分,意味着它在该指标上的表现低于其他选项,并不一定意味着它在该指标上普遍表现差。
首先让我们来谈谈最受关注的问题:哪种方法提供了最准确的回答?
- 提示工程(Prompt Engineering)的核心是在提供尽可能多的上下文信息的同时,通过提供少量示例(few-shot learning)来更好地让大模型了解您的用例。虽然结果在孤立情况下看起来令人印象深刻,但与本文中讨论的其他方法相比,它产生的结果最不准确。
- 检索增强生成(Retrieval Augmented Generation,RAG)的高质量结果是由于直接来自向量化信息存储的增强用例特定上下文。与 提示工程相比,它产生了大幅改善的结果,并且极低几率出现幻觉。
- 微调(Fine-tuning)在准确性方面提供了相当高的结果,其输出质量与 RAG 相媲美。由于我们正在使用特定领域的数据更新模型权重,因此该模型能够产生更具上下文的回复。与 RAG 相比,质量可能会稍微好一些,这取决于使用情况。因此,评估是否真的值得花时间在两者之间进行权衡分析非常重要。通常选择微调的原因不仅仅是准确性,还包括数据变化频率、控制模型工件以符合监管、合规和可复现性等方面的考虑。
- 从头开始训练可以产生最高质量的结果。由于模型是根据特定用例的数据进行训练,幻觉的可能性几乎为零,并且输出的准确性也是很高的。

实施复杂性。让我们看看实施这些方法有多容易或困难。
- 提示工程(Prompt Engineering)的实施复杂度相对较低,因为它几乎不需要编程。需要具备良好的英语(或其他人类解释)语言技能和领域专业知识,以制定一个带有上下文学习方法和少样本学习方法的良好提示。
- 检索增强生成(Retrieval Augmented Generation,RAG) 比提示工程更复杂,因为你需要具备编码和架构技能来实现这个解决方案。根据在 RAG 架构中选择的工具不同,复杂度可能会更高。
- 微调(Fine-tuning)的复杂性甚至比提示工程和 RAG 还要高,因为模型的权重 / {/} /参数是通过调整脚本进行更改的,这需要数据科学和机器学习专业知识。
- 从头开始训练具有最高的实施复杂性,因为它需要大量的数据整理和处理,并且需要深入的数据科学和机器学习专业知识来训练一个相当大的 Foundation Model。

努力,让我们了解每个解决方案需要多少努力。请注意,实施复杂性和付出的努力并不总是成正比。
- 提示工程(Prompt Engineering)需要大量的反复努力才能做到完美。大语言模型对提示的用词比较敏感,有时候改变一个词甚至动词都会导致完全不同的回应。因此,为了让相应的大语言模型输出期望的结果,需要进行多次迭代才能做到准确无误。
- 检索增强生成(Retrieval Augmented Generation,RAG) 还需要适度的努力,比提示工程稍微高一些,因为涉及到创建 Embeddings 和设置向量存储的任务。
- 微调(Fine-tuning)是一项比提示工程和 RAG 更费力的任务。虽然 Fine-tuning 可以使用很少的数据进行(在某些情况下甚至只需 30 个或更少的示例),但是设置 Fine-tuning 并正确获取可调参数值需要时间。
- 从头开始训练是所有方法中最费力的。它需要大量的迭代开发,以获得具有正确技术和业务结果的最佳模型。该过程始于收集和整理数据,设计模型架构,并尝试不同的建模方法,以找到适用于特定用例的最佳模型。这个过程可能非常漫长(几周到几个月),并且需要大量的计算资源。

总拥有成本(TCO),接下来是关于 TCO 的比较。
请注意,我们不仅仅谈论的是服务 / {/} /组件的费用,而是完全拥有解决方案所需的成本,包括构建和维护解决方案所花费的熟练工程师时间、自行维护基础设施的成本、为执行补丁和更新而进行停机时间、设置支持渠道、招聘、提升技能以及其他杂项费用。
- 提示工程(Prompt Engineering) 的成本可以非常低,因为您只需要维护提示工程模板,并在大模型版本更改或完全新的大模型出现时及时更新它们。除此之外,还会有一些通常与托管大模型或通过无服务器 API 使用它相关的费用。
- 检索增强生成(Retrieval Augmented Generation,RAG) 的成本会比提示工程高一些,这是因为架构中涉及到多个组件。这将取决于使用的 Embedding 模型、向量存储和大模型。因此,它与提示工程相比成本更高,因为您需要支付三个不同的组件而不只是一个大模型。
- 微调(Fine-tuning)的成本将高于 RAG 和提示工程,因为您正在调整一个需要强大计算能力、深度机器学习技能和对模型架构的理解的模型。特别是,由于每次基础模型版本更新或新批次数据进来时都需要进行调优,维护这样的解决方案的成本较高,并携带有关用例最新信息。
- 从头开始训练的总体成本最高,因为团队需要负责整个数据处理和机器学习训练、调优和部署过程。这将需要一群高技能的机器学习专业人员来完成。由于需要频繁重新训练模型以使其与使用案例周围的新信息保持更新,因此维护这样的解决方案的成本非常高。

灵活应对变化,让我们来看一下在更新和更改方面的选择。
- 提示工程(Prompt Engineering) 具有非常高的灵活性,因为您只需要根据大模型和用例的变化来更改提示模板即可。
- 检索增强生成(Retrieval Augmented Generation,RAG) 在架构变更方面具有最高的灵活性。您可以独立地改变 Embedding 模型、向量存储和 LLMs,对其他组件的影响很小到中等程度。它还具备在过程中添加更多组件(如复杂授权)而不影响其他组件的灵活性。
- 微调(Fine-tuning)对于变化的适应性较低,因为任何数据和输入的更改都需要进行另一轮微调,这可能会非常复杂且耗时。此外,将同一个经过微调的模型适应到不同用例中也需要付出很大努力,因为相同的模型权重 / {/} /参数在其他领域上可能表现不佳。
- 从头开始训练的灵活性最小。因为在这种情况下,模型是从头构建的,对模型进行更新会触发另一个重新训练周期。可以说,我们也可以对模型进行微调而不是从头重新训练,但准确性会有所变化。

三、总结
正如上面的所有比较所显示的那样,其实没有明确的赢家。实际应用取决于在设计基于生成式 AI 解决方案时对您的组织最重要的指标是什么。
总结以上内容,选择正确的生成式 AI 的方法指南:
- 您希望在更改大模型和提示模板方面具有更高的灵活性,并且您的使用案例不包含大量领域上下文时,请使用提示工程(Prompt Engineering)。
- 使用检索增强生成(Retrieval Augmented Generation,RAG)时,您可以在保持输出质量高的同时,获得最高程度的灵活性来更改不同组件(数据源、Embeddings、大模型、向量引擎)。
- 使用微调(Fine-tuning)时,您可以更好地控制模型的构件和版本管理。当领域特定术语非常与数据相关(比如法律、生物学等)时,它也许会非常有用。
- 如果以上方法都不适用于您,并且您有能力构建一个拥有数万亿个经过精心筛选的标记化数据样本、先进硬件基础设施和一支高技能机器学习专家团队,那么您可以从头开始训练一个基础大模型。当然,这需要相当昂贵的预算和时间成本来实现和落地应用。
📚️ 参考链接:
- Vikesh Pandey:Should you Prompt, RAG, Tune, or Train? A Guide to Choose the Right Generative AI Approach
- 2023 如何成为 Prompt Engineering 提示工程高手终极指南,从入门到高级
- 提升 ChatGPT 性能的实用指南:Prompt Engineering 的艺术
- RAG:使用检索增强生成构建特定行业的大型语言模型
- LLM 回答更加准确的秘密:为检索增强生成(RAG)添加引用源
- 吴恩达 x OpenAI Prompt Engineering 教程中文笔记
- 吴恩达和 OpenAI 的《面向开发者的 ChatGPT 提示工程》精华笔记
- 通俗解读大模型微调(Fine Tuning)
- 探索,基于开源大语言通用模型训练垂直业务模型——模型参数、微调 Fine-tuning、嵌入Embedding、基础概念学习
- 大模型微调技术:fine-tune、parameter-efficient fine-tune 和 prompt-tune
- 大模型的三大法宝:Fine-tuning, Prompt Engineering, Reward
- 仅用 61 行代码,你也能从零训练大模型
相关文章:
Prompt、RAG、微调还是重新训练?选择正确的生成式 AI 的方法指南
文章目录 一、前言二、主要内容三、总结 🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 这篇博客试图根据一些常见的可量化指标,为您选择适合您用例的生成式人工智能方法提供指导。 生成式 AI 正在以惊人的速度发展,…...

Java实现单例模式的几种方法
单例模式作为23中设计模式中最基础的设计模式,一般实现方式为 ①私有化构造方法 ②提供一个获取对象的静态方法 除此之外,实现单例模式的方法还有很多种,这篇文章主要介绍实现单例模式的几种方法。 目录 一、懒汉式单例 二、懒汉式单例优化…...
VIOOVI:标准的作业规范要求是什么?标准化作业规范怎么写?
本文围绕“标准化作业”展开论述,分享一些关于标准化作业以及标准的作业规范等相关知识。 什么是标准化作业? 标准化作业是一种以人的行为为中心,在一个操作序列中有效地进行生产而没有浪费的操作方法。 标准化作业的前提即:关注…...

WPF中的GridSplitter使用原则
WPF中的GridSplitter使用原则 GridSplitter对象必须放在Grid单元格中。可以预留一行或者列的Height或Width属性设置为auto。GridSplitter对象总是改变整行或整列的尺寸,为使该对象外观和行为保持一致,需要拉伸GridSplitter对象使其穿越整行或整列&#…...
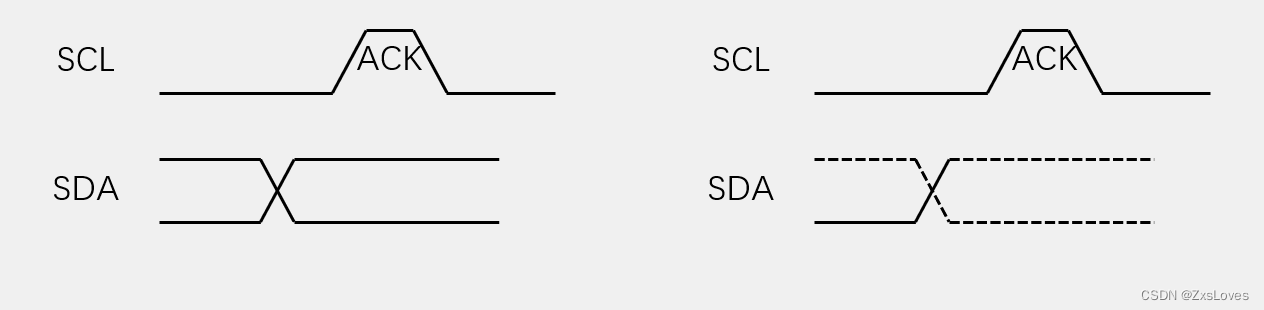
【【STM32----I2C通信协议】】
STM32----I2C通信协议 我们会发现I2C有两根通信线: SCL和SDA 同步 半双工 带数据应答 支持总线挂载多设备(一主多从,多主多从) 硬件电路 所有I2C设备的SCL连在一起,SDA连在一起 设备的SCL和SDA均要配置成开漏输出模式 …...
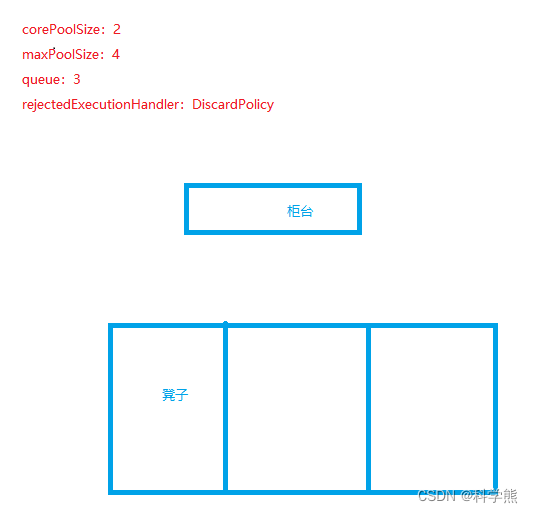
【JUC】线程池ThreadPoolTaskExecutor与面试题解读
1、ThreadPoolTaskExecutor 创建线程池 从它的创建和使用说起,创建和使用的代码如下: 创建: ThreadPoolTaskExecutor executor new ThreadPoolTaskExecutor();executor.setCorePoolSize(corePoolSize);executor.setMaxPoolSize(maxPoolSize…...

也许你正处于《孤注一掷》中的“团队”,要留心了
看完这部电影,心情久久不能平静,想了很多,倒不是担心自己哪天也成为“消失的yaozi”,而是在想,我们每天所赖以生存的工作,跟电影里他们的工作比,差别在哪里呢? 目录 1. 产品的本质…...
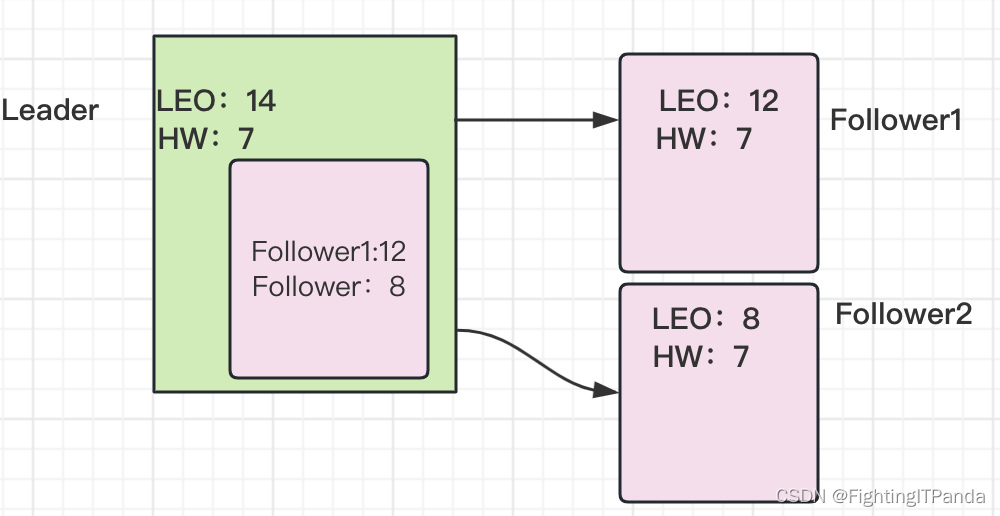
Kafka 入门到起飞 - 什么是 HW 和 LEO?何时更新HW和LEO呢?
上文我们已经学到, 一个Topic(主题)会有多个Partition(分区)为了保证高可用,每个分区有多个Replication(副本)副本分为Leader 和 Follower 两个角色,Leader副本对外提供读…...

go入门实践五-实现一个https服务
文章目录 前言生成证书申请免费的证书使用Go语言生成自签CA证书 https的客户端和服务端服务端代码客户端代码 tls的客户端和服务端服务端客户端 前言 在公网中,我想加密传输的数据。(1)很自然,我想到了把数据放到http的请求中,然后通过tls确…...

面试之快速学习STL-set
set 和 map、multimap 容器不同,使用 set 容器存储的各个键值对,要求键 key 和值 value 必须相等使用 set 容器存储的各个元素的值必须各不相同从语法上讲 set 容器并没有强制对存储元素的类型做 const 修饰, 即 set 容器中存储的元素的值是可以修改的。…...

leetcode 1614.括号的最大嵌套深度
⭐️ 题目描述 🌟leetcode链接:括号的最大嵌套深度 ps: 使用数据结构栈来存储 ( 在使用 maxDepth 变量记录栈顶 top 的最大值,当遇到 ) 时删除栈顶元素。举个例子 (1)((2))(((3))),当遇到第一个 ( 时 top 1ÿ…...
Ajax 笔记(四)—— Ajax 进阶
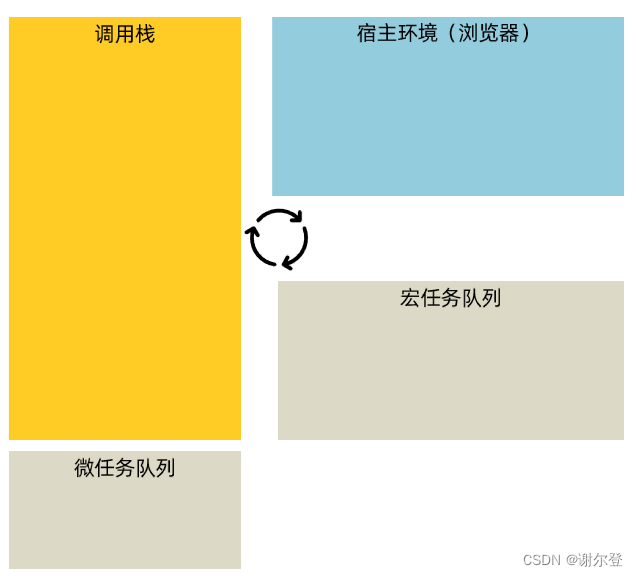
笔记目录 4. Ajax 进阶4.1 同步代码和异步代码4.2 回调函数地狱4.2.1 解决方法一:Promise 链式调用4.2.2 解决方法二:async 函数和 await 4.3 Promise.all 静态方法4.4 事件循环4.4.1 事件循环4.4.2 宏任务与微任务 4.5 案例4.5.1 案例一-商品分类4.5.2 …...
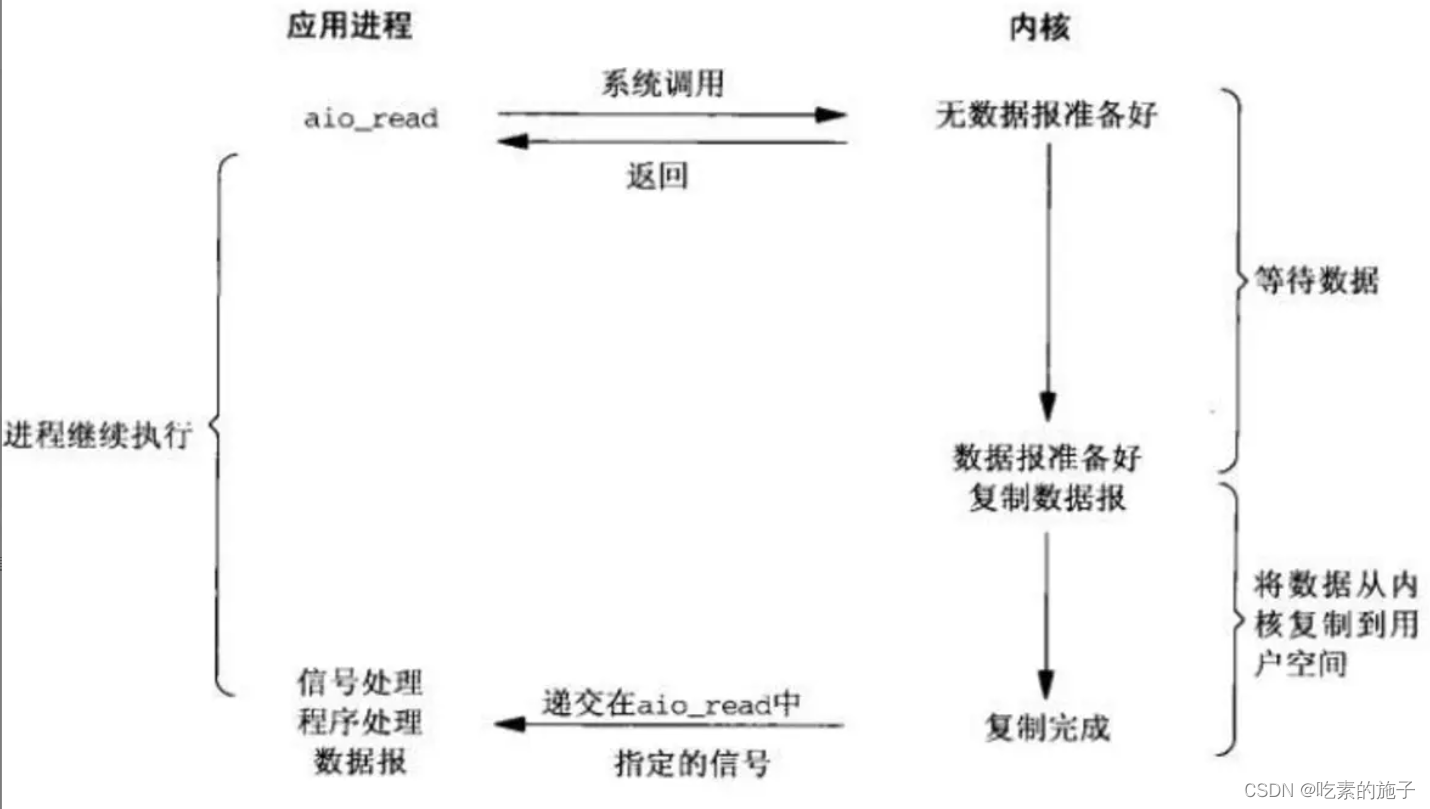
Linux 5种网络IO模型
Linux IO模型 网络IO的本质是socket的读取,socket在linux系统被抽象为流,IO可以理解为对流的操作。刚才说了,对于一次IO访问(以read举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操…...

Linux多线程【初识线程】
✨个人主页: 北 海 🎉所属专栏: Linux学习之旅 🎃操作环境: CentOS 7.6 阿里云远程服务器 文章目录 🌇前言🏙️正文1、什么是线程?1.1、基本概念1.2、线程理解1.3、进程与线程的关系…...

Python爬虫的应用场景与技术难点:如何提高数据抓取的效率与准确性
作为专业爬虫程序员,我们在数据抓取过程中常常面临效率低下和准确性不高的问题。但不用担心!本文将与大家分享Python爬虫的应用场景与技术难点,并提供一些实际操作价值的解决方案。让我们一起来探索如何提高数据抓取的效率与准确性吧…...
)
Spring Cloud Gateway系例—参数配置(CORS 配置、SSL、元数据)
一、CORS 配置 你可以配置网关来控制全局或每个路由的 CORS 行为。两者都提供同样的可能性。 1. Global CORS 配置 “global” CORS配置是对 Spring Framework CorsConfiguration 的URL模式的映射。下面的例子配置了 CORS。 Example 77. application.yml spring:cloud:gat…...

QT:UI控件(按设计师界面导航界面排序)
基础部分 创建新项目:QWidget,QMainWindow,QDialog QMainWindow继承自QWidget,多了菜单栏; QDialog继承自QWidget,多了对话框 QMainWindow 菜单栏和工具栏: Bar: 菜单栏:QMenuBar࿰…...

AtCoder Beginner Contest 314-A/B/C
A - 3.14 题目要求输出圆周率保留小数几位后的结果 用字符串来存储长串的圆周率,截取字符串就可以了。 #include<iostream> using namespace std; int main() {string s"3.1415926535897932384626433832795028841971693993751058209749445923078164062…...
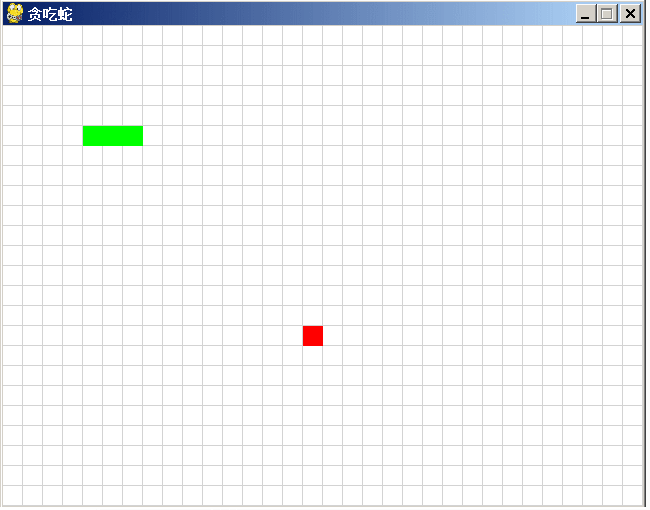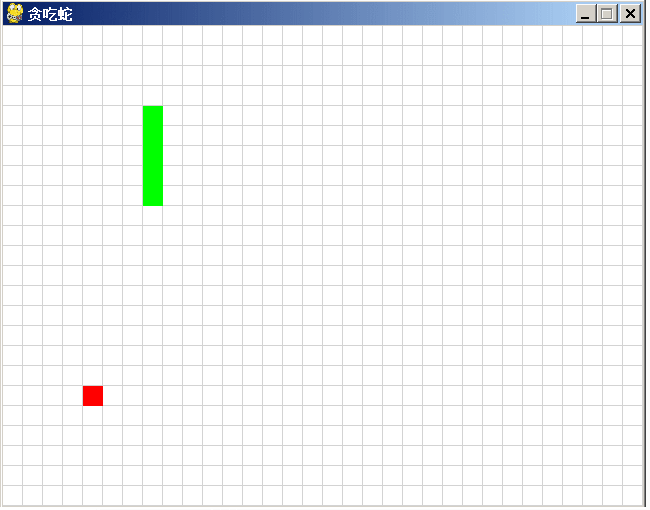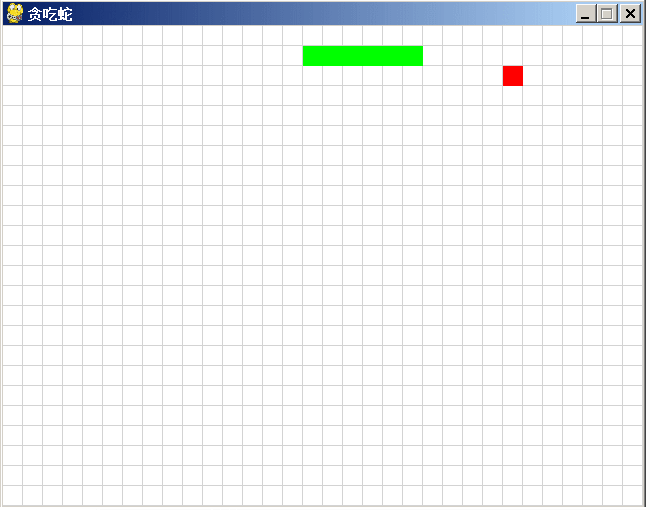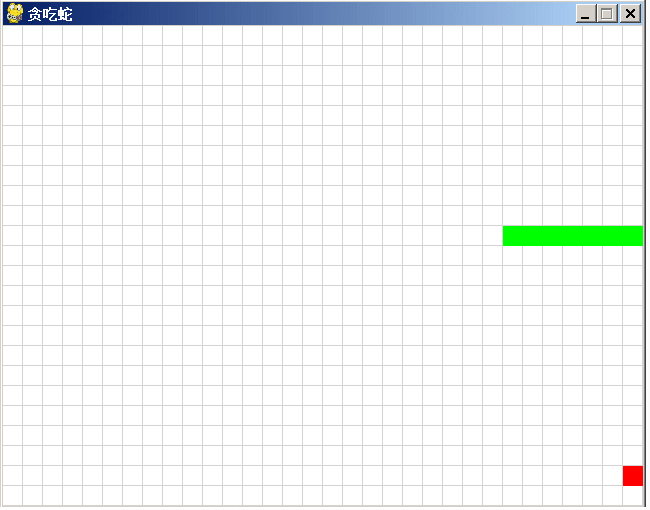
讯飞星火、文心一言和通义千问同时编“贪吃蛇”游戏,谁会胜出?
同时向讯飞星火、文心一言和通义千问三个国产AI模型提个相同的问题: “python 写一个贪吃蛇的游戏代码” 看哪一家AI写的程序直接能用,谁就胜出! 讯飞星火 讯飞星火给出的代码: import pygame import sys import random# 初…...
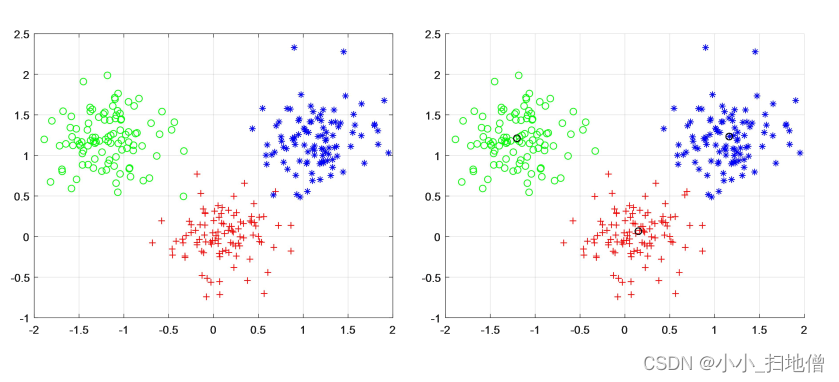
数学建模之“聚类分析”原理详解
一、聚类分析的概念 1、聚类分析(又称群分析)是研究样品(或指标)分类问题的一种多元统计法。 2、主要方法:系统聚类法、有序样品聚类法、动态聚类法、模糊聚类法、图论聚类法、聚类预报法等。这里主要介绍系统聚类法…...

别再死记硬背了!用Python模拟超前进位加法器,直观理解其速度优势
用Python模拟超前进位加法器:从硬件原理到算法思维的跨越 在计算机科学和电子工程交叉领域,加法器是最基础却又最精妙的设计之一。传统教学中,我们往往通过抽象的电路图来理解超前进位加法器(CLA)的速度优势࿰…...

SimulinkVeriStandLabVIEW协同开发——从模型编译到交互式仪表盘部署
1. 工具链协同开发的核心价值 在电力电子和工业控制领域,快速原型开发往往需要跨越建模、实时测试和人机交互三个关键环节。Simulink、VeriStand和LabVIEW组成的工具链,就像汽车制造的流水线——Simulink是设计图纸的工程师,VeriStand是组装车…...

如何通过Jellyfin Android TV客户端打造家庭影院级媒体体验?
如何通过Jellyfin Android TV客户端打造家庭影院级媒体体验? 【免费下载链接】jellyfin-androidtv Android TV Client for Jellyfin 项目地址: https://gitcode.com/gh_mirrors/je/jellyfin-androidtv 想要在智能电视上享受专业的媒体管理体验吗?…...

ViGEmBus终极指南:Windows游戏控制器模拟驱动完全解析
ViGEmBus终极指南:Windows游戏控制器模拟驱动完全解析 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus ViGEmBus是一款运行在Windows内核模式的驱…...

UEFITool深度解析:实战指南与高效使用技巧
UEFITool深度解析:实战指南与高效使用技巧 【免费下载链接】UEFITool UEFI firmware image viewer and editor 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITool UEFITool是一款专为UEFI固件分析设计的开源工具,能够将复杂的二进制固件映像…...

DriveBench:面向真实驾驶场景的长序列多智能体交互基准测试框架
1. 项目概述:从“世界基准”到“驾驶基准”的演进如果你在自动驾驶或者计算机视觉领域摸爬滚打过几年,一定对“基准测试”(Benchmark)这个词又爱又恨。爱的是,它提供了一个相对公平的擂台,让不同算法、不同…...

MySQL 视图使用场景与限制
视图是把查询封装成「虚拟表」的方式,用对了简化查询,用错了性能爆炸。这篇说说视图的用法和注意事项。 什么是视图? -- 视图:保存好的 SQL 查询,像表一样使用 CREATE VIEW view_name AS SELECT column1, column2 FROM…...

CircuitPython Web Workflow实战:无线开发Yoto Mini与I2C硬件验证
1. 项目概述与核心价值如果你玩过像树莓派Pico或者ESP32这类微控制器,肯定对“插拔-编程-调试”这个循环不陌生。每次改几行代码,就得拔下USB线,重新上电,然后盯着串口监视器看输出。这个过程在项目初期调试硬件时,尤其…...

5分钟掌握浏览器串口调试:提升嵌入式开发效率300%的终极指南
5分钟掌握浏览器串口调试:提升嵌入式开发效率300%的终极指南 【免费下载链接】SerialAssistant A serial port assistant that can be used directly in the browser. 项目地址: https://gitcode.com/gh_mirrors/se/SerialAssistant 你是否还在为串口调试工具…...

基于RAG与智能体技术构建专业客服AI:从知识注入到流程执行
1. 项目概述:一个面向客服场景的AI智能体指南最近在GitHub上看到一个挺有意思的项目,叫mrqhocungdungai-vn/hermes-cskh-guide。从名字就能猜个大概,这是一个关于“Hermes”的客服(CSKH)指南,而且看起来是越…...