【大数据Hive】hive 事务表使用详解
目录
一、前言
二、Hive事务背景知识
hive事务实现原理
hive事务原理之 —— delta文件夹命名格式
_orc_acid_version 说明
bucket_00000
合并器(Compactor)
二、Hive事务使用限制
参数设置
客户端参数设置
客户端参数设置
三、Hive事务使用操作演示
操作步骤
客户端设置参数
创建一张事务表
插入几条数据
删除一条数据
针对事务表的增删改查操作演示
创建事务表
插入一条数据
修改数据
删除数据
一、前言
使用过mysql的同学对mysql的事务这个概念应该不陌生,当对mysql的表进行增删改的时候,mysql会开启一个事务,以确保本次操作的数据的安全性,在hive3.0之后,hive也开始支持了事务,以满足一些增删改的业务场景,接下来将对hive的事务操作做详细的说明。
二、Hive事务背景知识
Hive设计之初时,是不支持事务的,原因:
- Hive的核心目标是将已经存在的结构化数据文件映射成为表,然后提供基于表的SQL分析处理,是一款面向历史、面向分析的工具;
- Hive作为数据仓库,是分析数据规律的,而不是创造数据规律的;
- Hive中表的数据存储于HDFS上,而HDFS是不支持随机修改文件数据的,其常见的模型是一次写入,多次读取;
从Hive0.14版本开始,具有ACID语义的事务(支持INSERT,UPDATE和DELETE)已添加到Hive中,以解决以下场景下遇到的问题:
1)流式传输数据
使用如Apache Flume或Apache Kafka之类的工具将数据流式传输到现有分区中,可能会有脏读(开始查询后能看到写入的数据)
2)变化缓慢数据更新
星型模式数据仓库中,维度表随时间缓慢变化。例如,零售商将开设新商店,需要将其添加到商店表中,或者现有商店可能会更改其平方英尺或某些其他跟踪的特征。这些更改需要插入单个记录或更新记录(取决于所选策略)
3)数据修正
有时发现收集的数据不正确,需要局部更正
hive事务实现原理
Hive的文件是存储在HDFS上的,而HDFS上又不支持对文件的任意修改,只能是采取另外的手段来完成。具体来说:
- 用HDFS文件作为原始数据(基础数据),用delta保存事务操作的记录增量数据;
- 正在执行中的事务,是以一个staging开头的文件夹维护的,执行结束就是delta文件夹。每次执行一次事务操作都会有这样的一个delta增量文件夹;
- 当访问Hive数据时,根据HDFS原始文件和delta增量文件做合并,查询最新的数据;

对于insert,update,delete三种操作来说,
1、INSERT语句会直接创建delta目录;
2、DELETE目录的前缀是delete_delta;
3、UPDATE语句采用了split-update特性,即先删除、后插入;
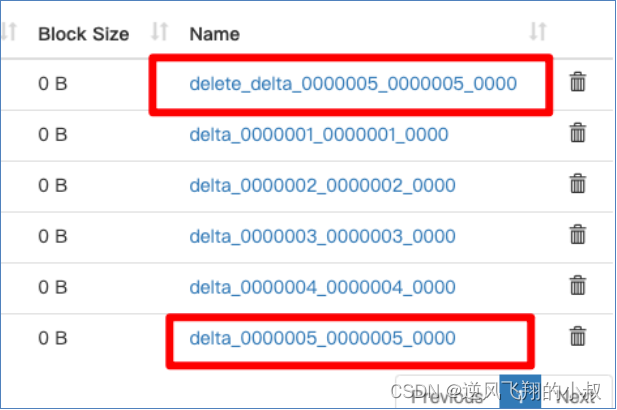
hive事务原理之 —— delta文件夹命名格式
通过上面的描述,大概了解到hive的事务在执行过程中,delta目录文件很重要,具体来说,一个delta文件的完整名称,可以拆开来看,各个部分的含义需要分别去理解,比如当我们执行一条delete语句开启一个事务时,将会出现类似下面第一条格式的文件;

对于这个文件来说,其完整的含义,可以类比为:delta_minWID_maxWID_stmtID,拆开来看即:
1、即delta前缀、写事务的ID范围、以及语句ID;删除时前缀是delete_delta,里面包含了要删除的文件;
2、Hive会为写事务(INSERT、DELETE等)创建一个写事务ID(Write ID),该ID在表范围内唯一;
3、语句ID(Statement ID)则是当一个事务中有多条写入语句时使用的,用作唯一标识;
而每个事务的delta文件夹下,都存在两个文件

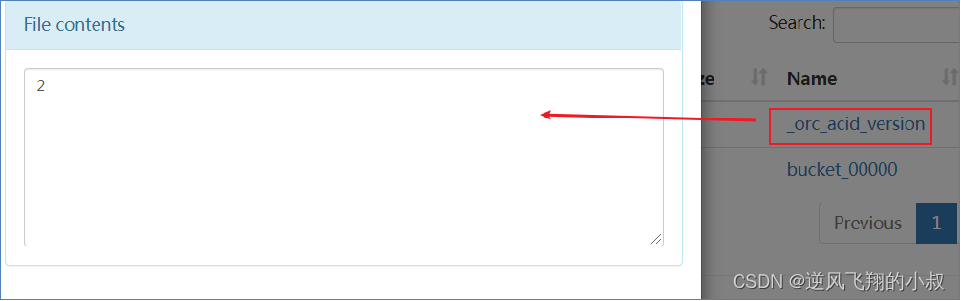
_orc_acid_version 说明
_orc_acid_version的内容是2,即当前ACID版本号是2。和版本1的主要区别是UPDATE语句采用了split-update特性,即先删除、后插入。这个文件不是ORC文件,可以下载下来直接查看。
bucket_00000
bucket_00000文件则是写入的数据内容。如果事务表没有分区和分桶,就只有一个这样的文件。文件都以ORC格式存储,底层二级制,需要使用ORC TOOLS查看,详见附件资料;
可以通过引入相关的依赖包进行查看

对于其中的内容做一下补充说明:
- operation:0 表示插入,1 表示更新,2 表示删除。由于使用了split-update,UPDATE是不会出现的,所以delta文件中的operation是0 , delete_delta 文件中的operation是2;
- originalTransaction、currentTransaction:该条记录的原始写事务ID,当前的写事务ID;
- rowId:一个自增的唯一ID,在写事务和分桶的组合中唯一;
- row:具体数据,对于DELETE语句,则为null,对于INSERT就是插入的数据,对于UPDATE就是更新后的数据;
合并器(Compactor)
随着表的修改操作,创建了越来越多的delta增量文件,就需要合并以保持足够的性能,合并器Compactor是一套在Hive Metastore内运行,支持ACID系统的后台进程。所有合并都是在后台完成的,不会阻止数据的并发读、写。合并后,系统将等待所有旧文件的读操作完成后,删除旧文件。
合并操作分为两种
- minor compaction(小合并),小合并会将一组delta增量文件重写为单个增量文件,默认触发条件为10个delta文件;
- major compaction(大合并),大合并将一个或多个增量文件和基础文件重写为新的基础文件,默认触发条件为delta文件相应于基础文件占比10%;

二、Hive事务使用限制
然Hive支持了具有ACID语义的事务,但是在使用起来,并没有像在MySQL中使用那样方便,有很多限制,归纳如下:
- 尚不支持BEGIN,COMMIT和ROLLBACK,所有语言操作都是自动提交的;
- 表文件存储格式仅支持ORC(STORED AS ORC);
- 需要配置参数开启事务使用;
- 外部表无法创建为事务表,因为Hive只能控制元数据,无法管理数据;
- 表属性参数transactional必须设置为true;
- 必须将Hive事务管理器设置为org.apache.hadoop.hive.ql.lockmgr.DbTxnManager才能使用ACID表;
- 事务表不支持LOAD DATA ...语句;
参数设置
在使用hive的事务表时,需要对部分参数做设置之后才能生效,参数的设置可以在客户端,也可以在服务端,两者任选其一;
客户端参数设置
# 可以使用set设置当前session生效 也可以配置在hive-site.xml中)
set hive.support.concurrency = true; --Hive是否支持并发
set hive.enforce.bucketing = true; --从Hive2.0开始不再需要 是否开启分桶功能
set hive.exec.dynamic.partition.mode = nonstrict; --动态分区模式 非严格
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; --事务管理器客户端参数设置
set hive.compactor.initiator.on = true; --是否在Metastore实例上运行启动压缩合并
set hive.compactor.worker.threads = 1; --在此metastore实例上运行多少个合并程序工作线程三、Hive事务使用操作演示
接下来通过实际操作演示下hive事务表的使用
操作步骤
客户端设置参数
打开一个客户端窗口后,执行下面的事务设置参数
set hive.support.concurrency = true; --Hive是否支持并发
set hive.enforce.bucketing = true; --从Hive2.0开始不再需要 是否开启分桶功能
set hive.exec.dynamic.partition.mode = nonstrict; --动态分区模式 非严格
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; --
set hive.compactor.initiator.on = true; --是否在Metastore实例上运行启动压缩合并
set hive.compactor.worker.threads = 1; --在此metastore实例上运行多少个压缩程序工作线程。
创建一张事务表
CREATE TABLE emp (id int, name string, salary int)
STORED AS ORC TBLPROPERTIES ('transactional' = 'true');

插入几条数据
INSERT INTO emp VALUES (1, 'Jerry', 5000);
INSERT INTO emp VALUES (2, 'Tom', 8000);
INSERT INTO emp VALUES (3, 'Kate', 6000);
执行过程可以看到走了M-R任务
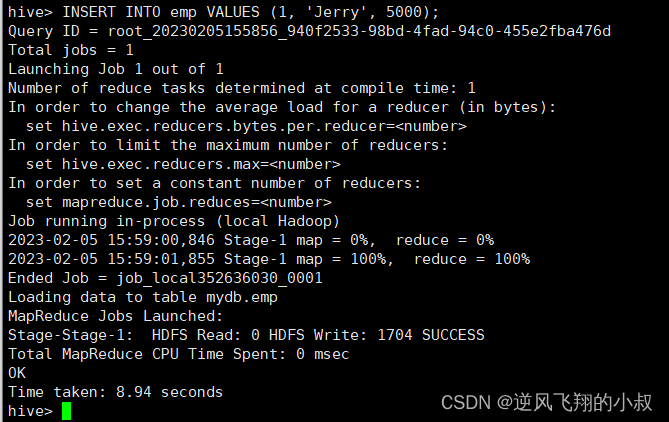
同时执行过程中,观察hdfs目录文件,可以看到产生了下面的staging文件


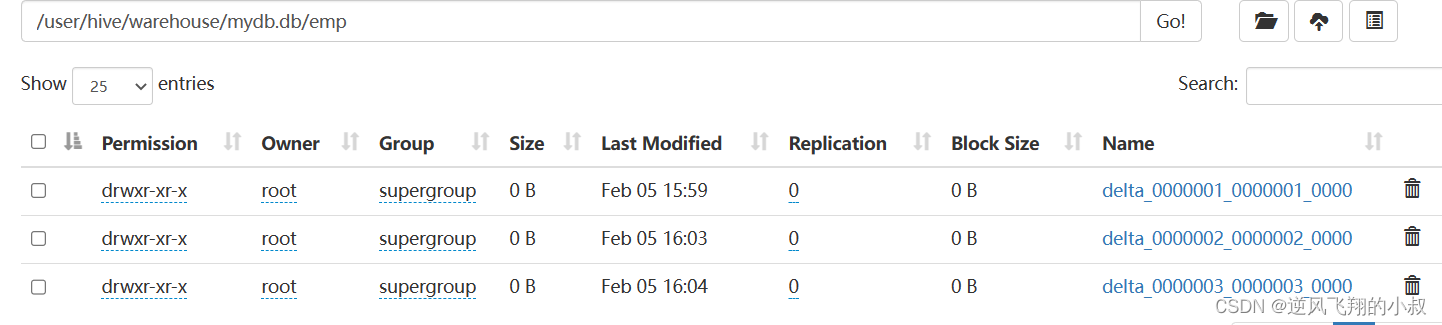
而执行完成后,正好产生了一个_orc_acid_version文件,以及bucket_00000文件;

如果执行多条数据的插入,就会产生多少个下面的文件目录;
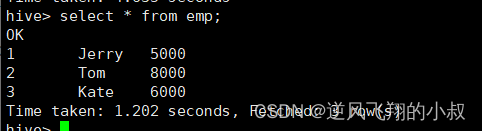
查询数据,可以看到已经完成数据的插入;
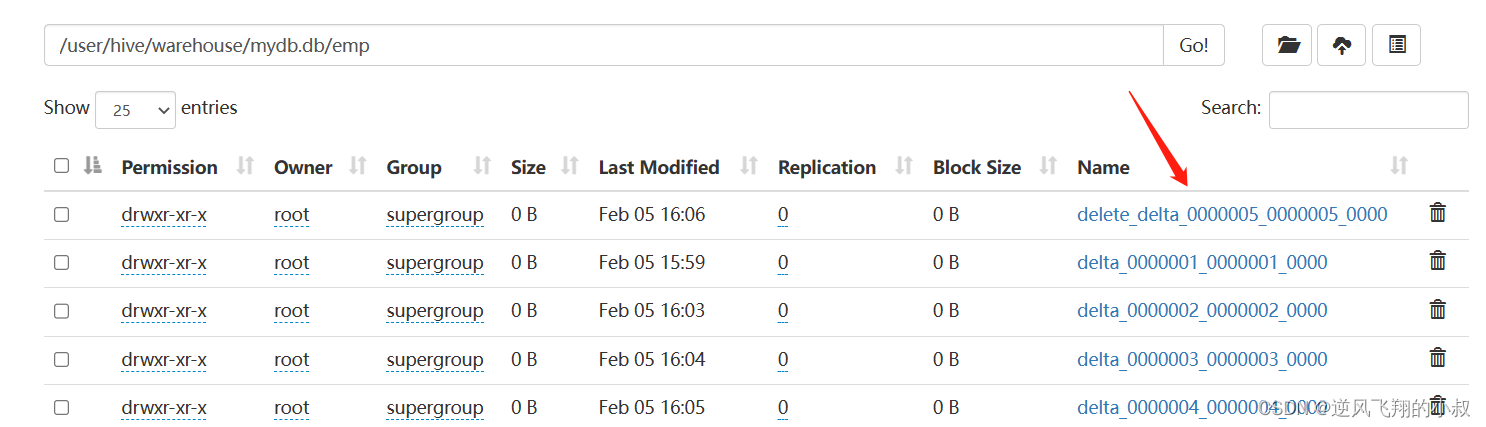
删除一条数据
delete from emp where id =2;
执行删除之后,再次查看hdfs文件目录,可以看到这里多了一个delete_delta文件,关于这个文件上面我们有详细的说明;
针对事务表的增删改查操作演示
创建事务表
create table trans_student(id int,name String,age int
)stored as orc TBLPROPERTIES('transactional'='true');可以通过describe命令查看表的详细信息
describe formatted trans_student;
插入一条数据
insert into trans_student (id, name, age) values (1,"allen",18);
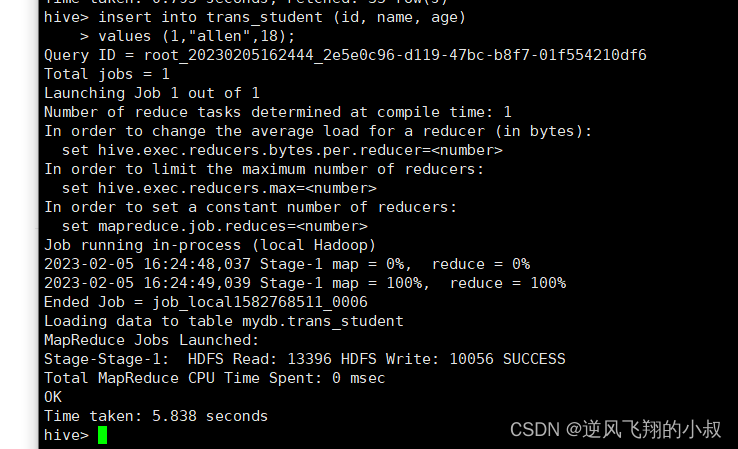
插入完成后,hdfs文件目录就生成了相关的事务文件

修改数据
update trans_student
set age = 20
where id = 1;
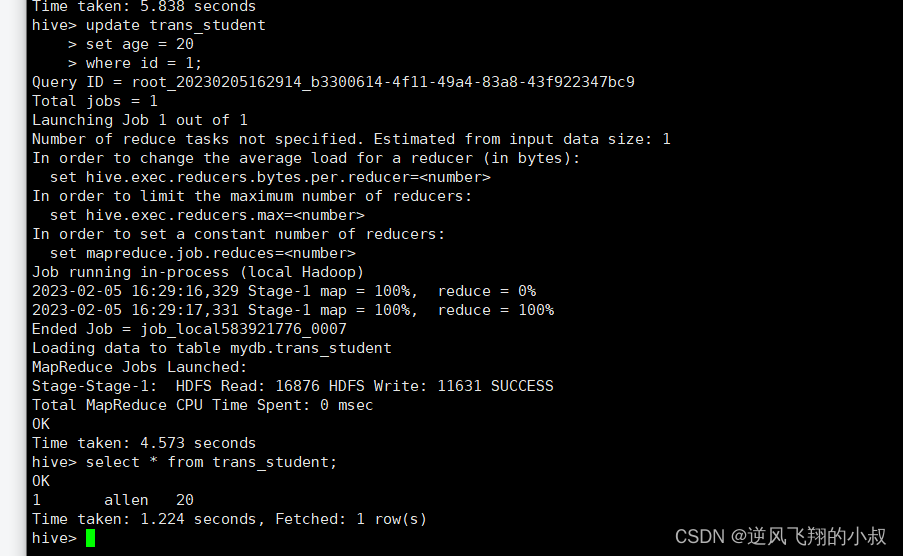
执行完成后,检查hdfs目录就多了一个delete_delta文件;
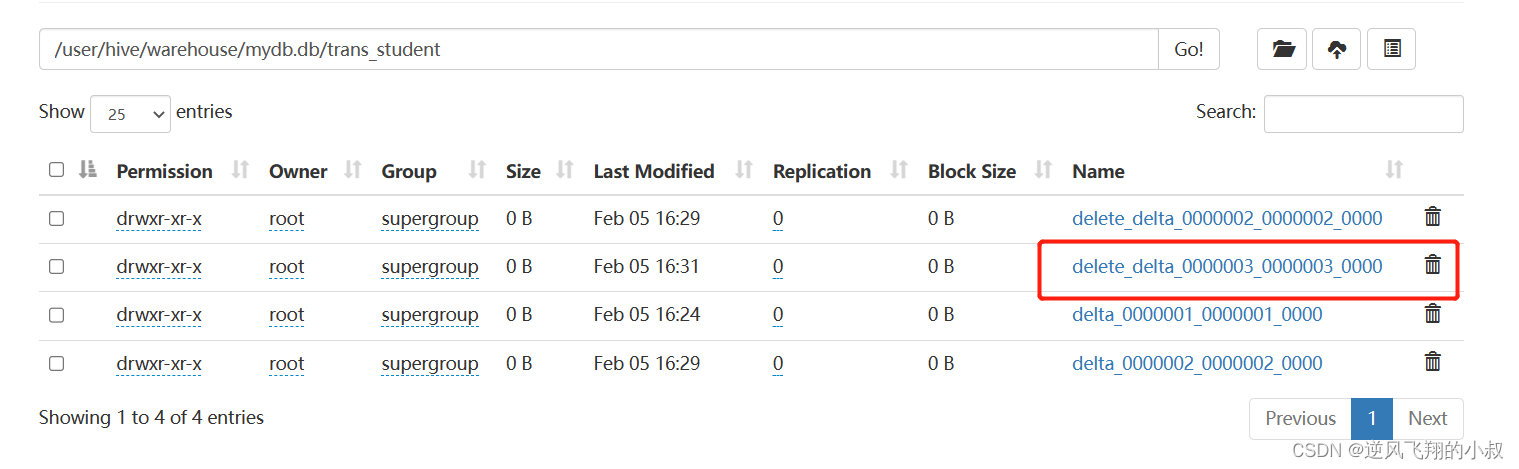
删除数据
delete from trans_student where id =1;

执行完成后,检查hdfs目录又多了一个delete_delta文件;
相关文章:
【大数据Hive】hive 事务表使用详解
目录 一、前言 二、Hive事务背景知识 hive事务实现原理 hive事务原理之 —— delta文件夹命名格式 _orc_acid_version 说明 bucket_00000 合并器(Compactor) 二、Hive事务使用限制 参数设置 客户端参数设置 客户端参数设置 三、Hive事务使用操作演示 操作步骤 客…...
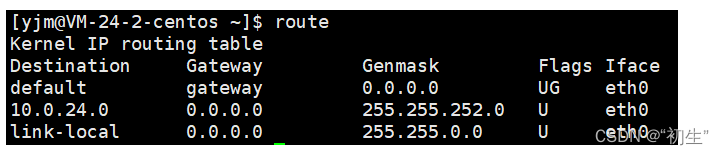
网络层协议
网络层协议 IP协议基本概念协议头格式网段划分特殊的IP地址IP地址的数量限制私有IP地址和公网IP地址路由IP协议头格式后续 在复杂的网络环境中确定一个合适的路径 IP协议 承接上文,TCP协议并不会直接将数据传递给对方,而是交付给下一层协议,…...
令牌)
JWT(JSON Web Token )令牌
1、介绍 jwt就是将原始的json数据格式进行了安全的封装,这样就可以直接基于jwt在通信双方安全的进行信息传输了。 2、jwt组成 第一部分:Header(头), 记录令牌类型、签名算法等。 例如:{"alg":"HS256…...
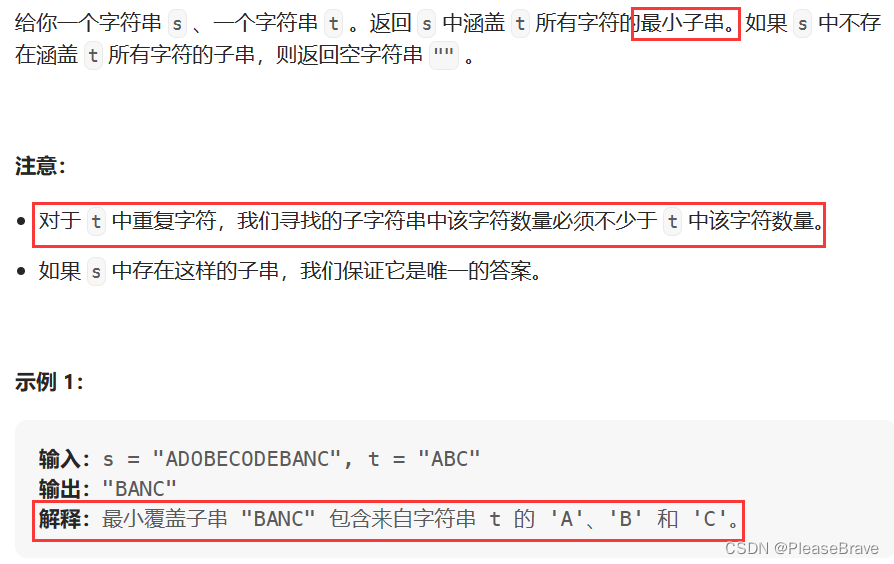
leetcode 力扣刷题 滑动窗口 部分题解(记录)
力扣刷题 滑动窗口相关的部分题解 209. 长度最小的子数组904. 水果成篮76. 最小覆盖子串 209. 长度最小的子数组 leetcode题目链接 209.长度最小的子数组 题目内容是这样的:给定一个含有 n个正整数的数组和一个正整数 target 。 找出该数组中满足其和 ≥ target 的…...

Intellij IDEA SBT依赖分析插件
可分析模块和传递依赖 安装完插件后,由于IDEA BUG,会出现两个分析按钮,一个是gradle的,一般是后者是新安装的sbt。 选择需要分析的模块 只需要在project/plugins.sbt中添加代码,启动官方分析插件addDependencyTreeP…...
MySQL中事务特性以及隔离机制
目录 一、什么是事务 二、事务特性——即ACID特性 三、事务的隔离级别 1、脏读 2、不可重复读 3、幻读 Read uncommitted: Read committed: Repeatable read: Serializable: 一、什么是事务 事务(Transaction)——一个最…...

Docker知识(详细笔记)
概览图 文章目录 概览图docker 知识速查1. 初识 Docker1.1 概念1.2 特点1.3 架构1.4 应用场景1.5 安装 Docker1.6 配置 Docker 镜像 2. Docker 命令2.1 Docker 进程相关命令2.2 Docker 镜像相关命令2.3 Docker 容器相关命令 3. Docker 容器的数据卷3.1 数据卷概念及作用3.1.1 概…...

【C#】获取已安装的NETFramework版本集合
代码 /// <summary>/// Windows信息/// </summary>public partial class WindowsInfo{/// <summary>/// 获取已安装的NETFramework版本集合/// </summary>/// <returns></returns>public static List<string> GetInstalledNETFramew…...

对字符串中所有单词进行倒排-C语言/Java
描述 输入一个字符串,输出字符串中单词的倒序。 要求 构成单词的字符只有26个大写或小写英文字母。非构成单词的字符均视为单词间隔符;倒排后的单词间隔符以一个空格表示;如果原字符串中相邻单词间有多个间隔符时,倒排转换后也只…...

Kubernetes入门 四、Pod核心
目录 什么是PodPod与容器不同Pod如何管理多个容器Pod的管理-工作负载K8s中的资源清单创建使用Pod直接创建Pod使用 Deployment 创建Pod 环境变量重启策略镜像拉取策略访问 DNS 的策略资源限制初始化容器临时容器(了解) 什么是Pod Pod 是可以在 Kubernete…...

【JAVA】数组练习
⭐ 作者:小胡_不糊涂 🌱 作者主页:小胡_不糊涂的个人主页 📀 收录专栏:浅谈Java 💖 持续更文,关注博主少走弯路,谢谢大家支持 💖 数组练习 1. 数组转字符串2. 数组拷贝3.…...
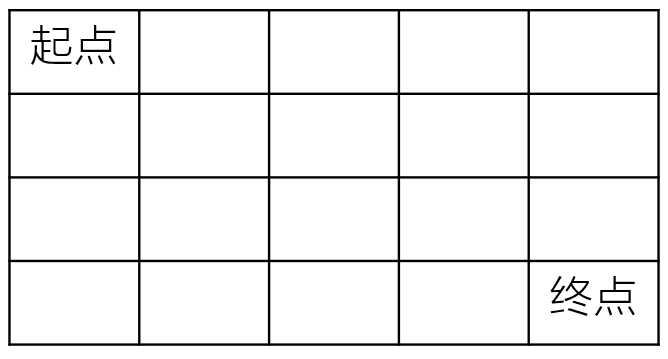
每日一题——不同路径的数目(一)
题目 一个机器人在mn大小的地图的左上角(起点)。 机器人每次可以向下或向右移动。机器人要到达地图的右下角(终点)。 可以有多少种不同的路径从起点走到终点? 数据范围:0<n,m≤100,保证计算结…...

innodb的锁
一致性锁定读和一致性非锁定读 Read Committed和Repetable Read级别下采用MVCC 实现非锁定读 但在一些情况下,要使用加锁来保障数据的逻辑一致性 自增列 锁的算法 唯一值 MySQL 中关于gap lock / next-key lock 的一个问题_呜呜呜啦啦啦的博客-CSDN博客 RR可以通过…...
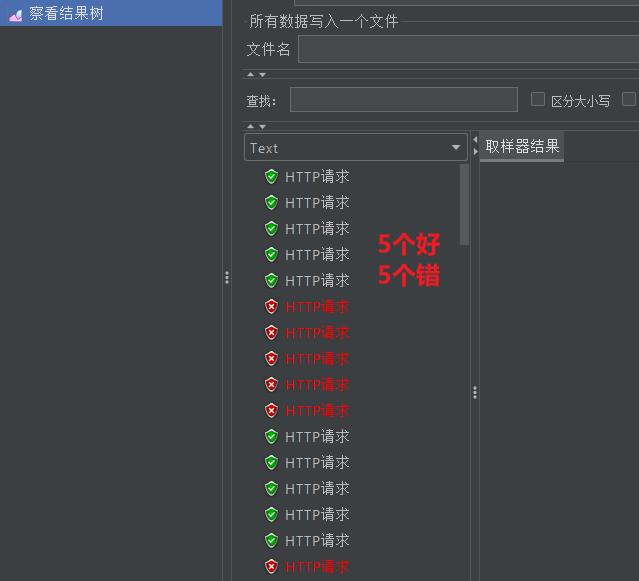
Jmeter-压力测试工具
文章目录 Jmeter快速入门1.1.下载1.2.解压1.3.运行 2.快速入门2.1.设置中文语言2.2.基本用法 Jmeter快速入门 1s内发送大量请求,模拟高QPS,用以测试网站能承受的压力有多大 Jmeter依赖于JDK,所以必须确保当前计算机上已经安装了JDK࿰…...
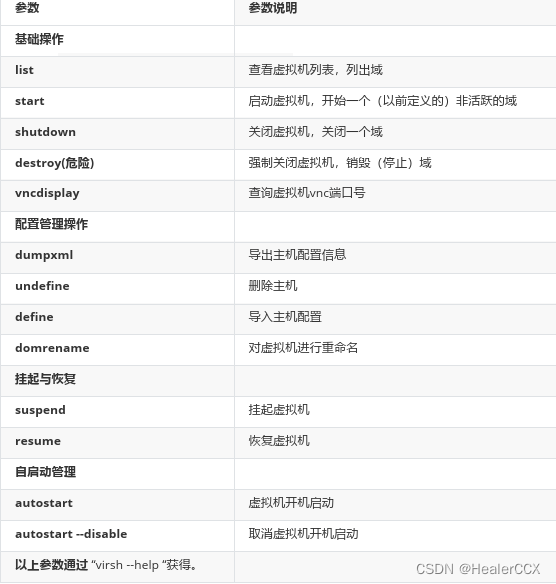
【KVM虚拟化环境部署】
环境部署 KVM虚拟化环境 1、装系统时手动选择安装 2、CentOS 7 最小化安装 yum install qemu-kvm qemu-img libvirt -y yum install virt-install libvirt-python virt-manager python-virtinst libvirt-client -y安装好CentOS 7后,去设置里面点击处理器&#x…...
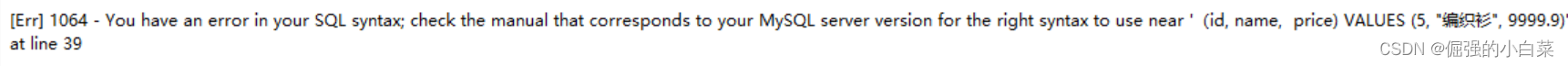
030 - 定点类型(精确值)
-DECIMAL,NUMERIC: 该DECIMAL和NUMERIC 类型的存储精确的数值数据。当保留精确度很重要时,例如使用货币数据,则可以使用这些类型。在MySQL中,NUMERIC实现为DECIMAL,因此以下有关的说明DECIMAL同样适用于 NU…...

生活随笔,记录我的日常点点滴滴.
前言 😘个人主页:曲终酣兴晚^R的小书屋🥱 😕作者介绍:一个莽莽撞撞的🐻 💖专栏介绍:日常生活&往事回忆 😶🌫️每日金句:被人暖一下就高热&…...
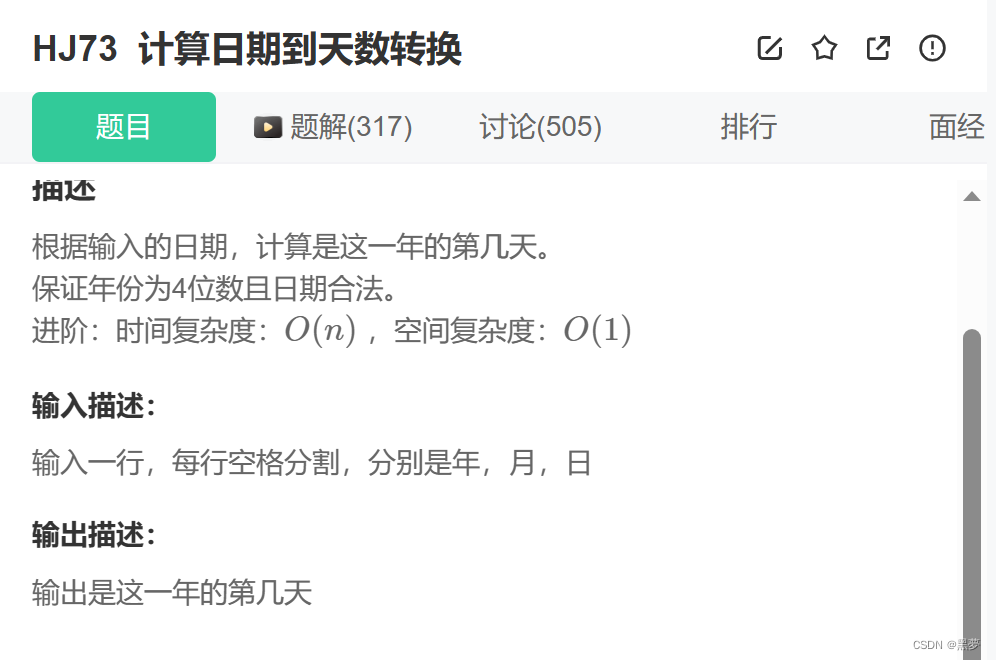
C语言:每日一练(选择+编程)
目录 选择题: 题一: 题二: 题三: 题四: 题五: 编程题: 题一:打印1到最大的n位数 示例1 思路一: 题二:计算日期到天数转换 示例1 思路一…...

Prompt、RAG、微调还是重新训练?选择正确的生成式 AI 的方法指南
文章目录 一、前言二、主要内容三、总结 🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 这篇博客试图根据一些常见的可量化指标,为您选择适合您用例的生成式人工智能方法提供指导。 生成式 AI 正在以惊人的速度发展,…...

Java实现单例模式的几种方法
单例模式作为23中设计模式中最基础的设计模式,一般实现方式为 ①私有化构造方法 ②提供一个获取对象的静态方法 除此之外,实现单例模式的方法还有很多种,这篇文章主要介绍实现单例模式的几种方法。 目录 一、懒汉式单例 二、懒汉式单例优化…...

如何用applera1n免费绕过iOS激活锁:完整指南与操作教程
如何用applera1n免费绕过iOS激活锁:完整指南与操作教程 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 你是否购买了一部二手iPhone或iPad,却发现设备被原主人的Apple ID锁定&a…...

终极指南:如何使用Autoclick实现Mac自动点击900次/秒
终极指南:如何使用Autoclick实现Mac自动点击900次/秒 【免费下载链接】Autoclick A simple Mac app that simulates mouse clicks 项目地址: https://gitcode.com/gh_mirrors/au/Autoclick 你是否厌倦了重复性的鼠标点击工作?无论是游戏中的重复操…...

SmarterRouter:基于软件定义与模块化构建智能路由器系统
1. 项目概述:一个更聪明的路由器,它到底想做什么?如果你和我一样,折腾过家里的网络,从刷第三方固件到组软路由,那你肯定对“路由器”这三个字有复杂的感情。它本该是默默无闻的网络基石,却常常因…...

Java 大厂面试 200 题完整版含答案解析
前言本文整理了近两年从阿里、腾讯、字节、美团、京东、拼多多等大厂面试中高频出现的 200 道 Java 面试题,覆盖 Java 基础、集合、并发、JVM、Spring、MySQL、Redis、消息队列、分布式、场景设计 等核心模块,每题都附有简明扼要的答案解析,助…...

开源银行API模拟器Bankr Buddy:金融科技开发的本地化测试解决方案
1. 项目概述:一个为开发者准备的银行API模拟器如果你正在开发一个需要与银行账户数据打交道的应用,无论是个人财务管理工具、预算分析软件,还是企业级的财务聚合服务,你肯定遇到过同一个难题:如何在不触碰真实用户敏感…...

基于Sovereign-MCP-Servers构建私有AI工具链:从协议原理到Docker化部署
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想给Claude、Cursor这类工具加上“联网”和“执行”能力时,绕不开一个概念:MCP(Model Context Protocol)。简单说,MCP就是一套标准协议,它能让…...

DIY便携FPV地面站:从电路设计到3D打印的完整制作指南
1. 项目概述:为什么需要一个便携式FPV地面站?玩FPV(第一人称视角)飞行,无论是竞速穿越还是航拍探索,最核心的体验就是那块屏幕。大多数飞手依赖FPV眼镜带来的沉浸感,但在很多场景下,…...

OCT-X算法:早期胃癌AI检测的技术突破与应用
1. OCT-X算法:早期胃癌AI检测的技术突破在医疗影像分析领域,胃癌早期检测一直面临着巨大挑战。传统内窥镜检查依赖医生经验判断,存在主观性强、漏诊率高等问题。我们团队开发的OCT-X(One Class Twin Cross Learning)算…...

基于Electron的ChatGPT桌面客户端开发:架构、功能与进阶实践
1. 项目概述:一个开源桌面客户端的诞生与价值如果你和我一样,在日常开发、写作或者处理一些需要深度思考的任务时,经常需要和ChatGPT这样的AI助手对话,那你一定对在浏览器里反复切换标签页、刷新页面、管理冗长的对话历史感到厌烦…...

可逆计算与量子电路合成:改进QM算法与全局优化
1. 可逆计算与量子电路合成基础在量子计算领域,可逆计算是一项关键技术,它不仅是实现低功耗设计的核心方法,更是量子电路合成的基础。传统计算机中的逻辑门大多是不可逆的,这意味着计算过程中会丢失信息并产生热量。而量子计算由于…...